Exécuter du code PySpark dans les notebooks BigQuery Studio
Ce document vous explique comment exécuter du code PySpark dans un notebook Python BigQuery.
Avant de commencer
Si ce n'est pas déjà fait, créez un projet Google Cloud et un bucket Cloud Storage.
Configurer votre projet
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Créez un bucket Cloud Storage dans votre projet si vous n'en avez pas déjà un.
Configurer votre notebook
- Identifiants du notebook : par défaut, votre session de notebook utilise vos identifiants utilisateur. Il peut également utiliser les identifiants du compte de service de session.
- Identifiants utilisateur : votre compte utilisateur doit disposer des rôles Identity and Access Management suivants :
- Éditeur Dataproc (rôle
roles/dataproc.editor) - Utilisateur BigQuery Studio (rôle
roles/bigquery.studioUser) - Le rôle Utilisateur du compte de service (roles/iam.serviceAccountUser) sur le compte de service de session.
Ce rôle contient l'autorisation
iam.serviceAccounts.actAsrequise pour emprunter l'identité du compte de service.
- Éditeur Dataproc (rôle
- Identifiants du compte de service : si vous souhaitez spécifier des identifiants de compte de service au lieu d'identifiants utilisateur pour votre session de notebook, le compte de service de session doit disposer du rôle suivant :
- Identifiants utilisateur : votre compte utilisateur doit disposer des rôles Identity and Access Management suivants :
- Environnement d'exécution du notebook : votre notebook utilise un environnement d'exécution Vertex AI par défaut, sauf si vous en sélectionnez un autre. Si vous souhaitez définir votre propre environnement d'exécution, créez-le sur la page Environnements d'exécution de la console Google Cloud . Remarque : Lorsque vous utilisez la bibliothèque NumPy, utilisez la version 1.26 de NumPy, qui est compatible avec Spark 3.5, dans l'environnement d'exécution du notebook.
- Identifiants du notebook : par défaut, votre session de notebook utilise vos identifiants utilisateur. Il peut également utiliser les identifiants du compte de service de session.
Dans la console Google Cloud , accédez à la page BigQuery.
Dans la barre d'onglets du volet "Détails", cliquez sur la flèche à côté du signe +, puis sur Notebook.
- Configurez et créez une session unique dans le notebook.
- Configurez une session Spark dans un modèle de session interactive, puis utilisez le modèle pour configurer et créer une session dans le notebook.
BigQuery fournit une fonctionnalité
Query using Sparkqui vous aide à commencer à coder la session basée sur un modèle, comme expliqué dans l'onglet Session Spark basée sur un modèle. Dans la barre d'onglets du volet de l'éditeur, cliquez sur la flèche vers le bas à côté du signe +, puis sur Notebook.
Copiez et exécutez le code suivant dans une cellule de notebook pour configurer et créer une session Spark de base.
- APP_NAME : nom facultatif de votre session.
- Paramètres de session facultatifs : vous pouvez ajouter des paramètres
Sessionde l'API Dataproc pour personnaliser votre session. Voici quelques exemples :RuntimeConfig:
session.runtime_config.properties={spark.property.key1:VALUE_1,...,spark.property.keyN:VALUE_N}session.runtime_config.container_image = path/to/container/image
EnvironmentConfig: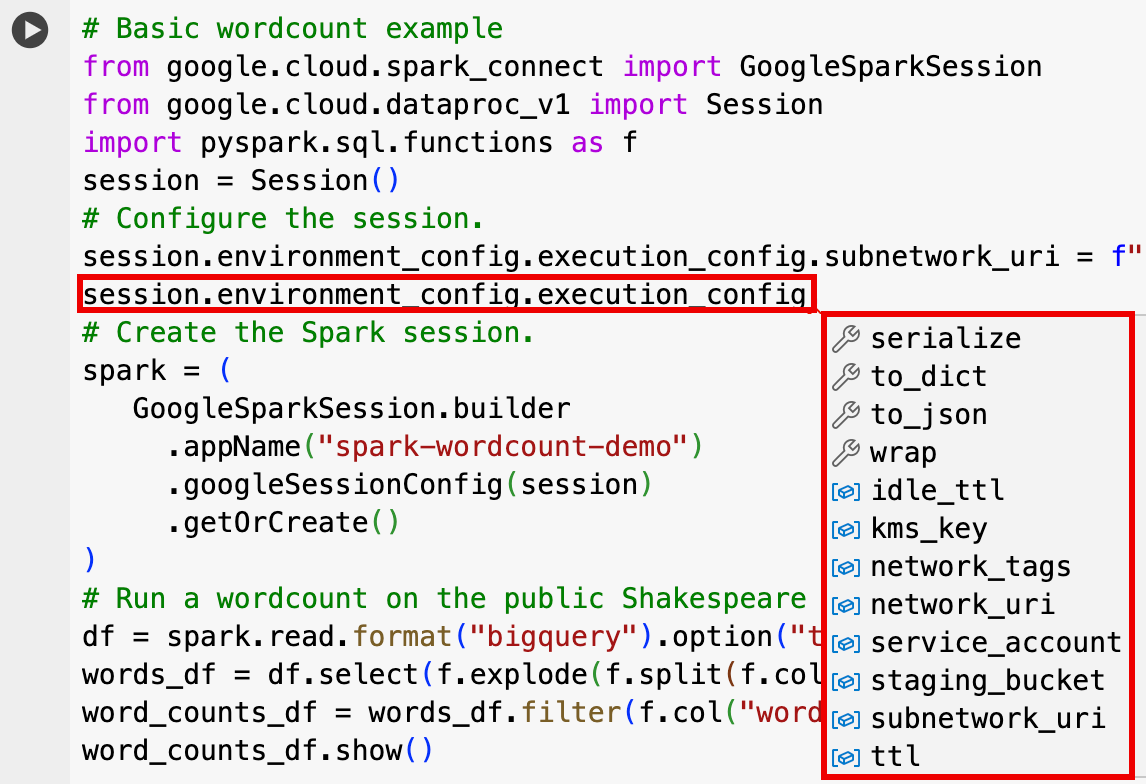
- session.environment_config.execution_config.subnetwork_uri = "SUBNET_NAME"
session.environment_config.execution_config.ttl = {"seconds": VALUE}session.environment_config.execution_config.service_account = SERVICE_ACCOUNT
- Dans la barre d'onglets du volet de l'éditeur, cliquez sur la flèche vers le bas à côté du signe +, puis sur Notebook.
- Sous Commencer avec un modèle, cliquez sur Interroger à l'aide de Spark, puis sur Utiliser le modèle pour insérer le code dans votre notebook.
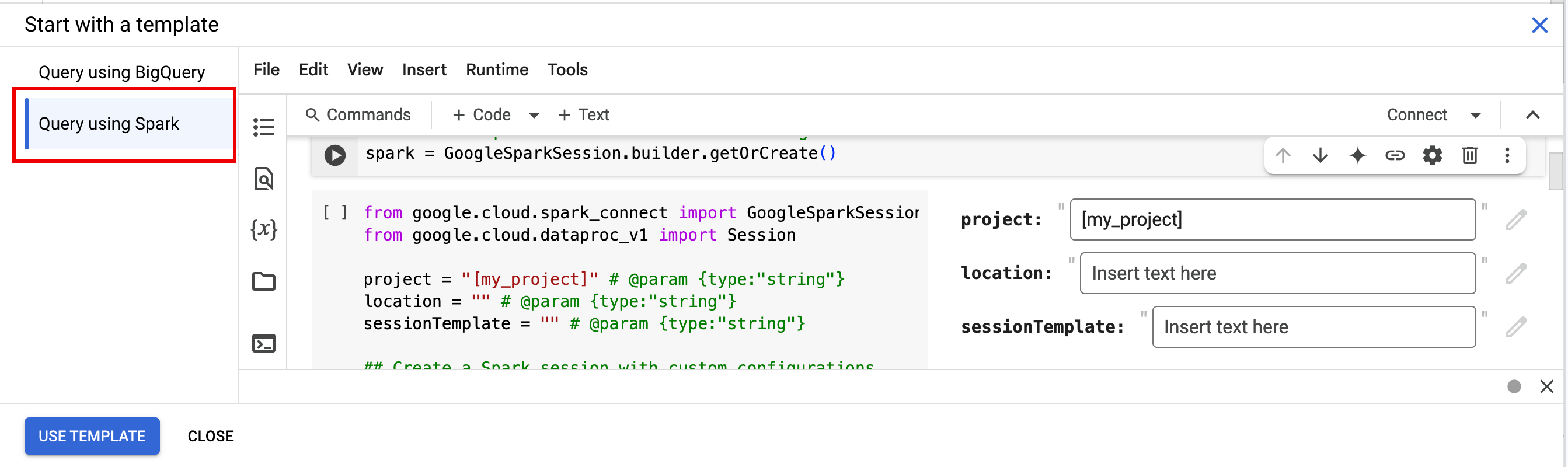
- Spécifiez les variables comme expliqué dans les Remarques.
- Vous pouvez supprimer toutes les cellules de code d'exemple supplémentaires insérées dans le notebook.
- PROJECT : ID de votre projet, indiqué dans la section Informations sur le projet du tableau de bord de la consoleGoogle Cloud .
- LOCATION : région Compute Engine dans laquelle votre session de notebook sera exécutée. Si vous ne fournissez aucune valeur, l'emplacement par défaut est la région de la VM qui crée le notebook.
SESSION_TEMPLATE : nom d'un modèle de session interactive existant. Les paramètres de configuration de la session sont obtenus à partir du modèle. Le modèle doit également spécifier les paramètres suivants :
- Version du runtime
2.3+ Type de notebook :
Spark ConnectExemple :

- Version du runtime
APP_NAME : nom facultatif de votre session.
- Exécutez un décompte de mots sur un ensemble de données Shakespeare public.
- Créez une table Iceberg avec des métadonnées enregistrées dans BigLake Metastore.
- APP_NAME : nom facultatif de votre session.
- PROJECT : ID de votre projet, indiqué dans la section Informations sur le projet du tableau de bord de la consoleGoogle Cloud .
- REGION et SUBNET_NAME : spécifiez la région Compute Engine et le nom d'un sous-réseau dans la région de la session. Serverless pour Apache Spark active l'accès privé à Google sur le sous-réseau spécifié.
- LOCATION : les valeurs par défaut de
BigQuery_metastore_config.locationetspark.sql.catalog.{catalog}.gcp_locationsontUS, mais vous pouvez choisir n'importe quel emplacement BigQuery compatible. - BUCKET et WAREHOUSE_DIRECTORY : bucket et dossier Cloud Storage utilisés pour le répertoire de l'entrepôt Iceberg.
- CATALOG_NAME et NAMESPACE : le nom et l'espace de noms du catalogue Iceberg sont combinés pour identifier la table Iceberg (
catalog.namespace.table_name). - APP_NAME : nom facultatif de votre session.
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le volet des ressources du projet, cliquez sur votre projet, puis sur votre espace de noms pour lister la table
sample_iceberg_table. Cliquez sur le tableau Détails pour afficher les informations de Configuration de la table du catalogue ouvert.Les formats d'entrée et de sortie sont les formats de classe Hadoop standards
InputFormatetOutputFormatutilisés par Iceberg.
Insérez une nouvelle cellule de code en cliquant sur + Code dans la barre d'outils. La nouvelle cellule de code affiche
Start coding or generate with AI. Cliquez sur Générer.Dans l'éditeur "Générer", saisissez une requête en langage naturel, puis cliquez sur
enter. Veillez à inclure le mot clésparkoupysparkdans votre requête.Exemple de requête :
create a spark dataframe from order_items and filter to orders created in 2024
Exemple de résultat :
spark.read.format("bigquery").option("table", "sqlgen-testing.pysparkeval_ecommerce.order_items").load().filter("year(created_at) = 2024").createOrReplaceTempView("order_items") df = spark.sql("SELECT * FROM order_items")Pour permettre à Gemini Code Assist de récupérer les tables et les schémas pertinents, activez la synchronisation Data Catalog pour les instances Dataproc Metastore.
Votre compte utilisateur doit avoir accès aux tables de requêtes de Data Catalog. Pour cela, attribuez-vous le rôle
DataCatalog.Viewer.- Exécutez
spark.stop()dans une cellule de notebook. - Arrêtez l'environnement d'exécution dans le notebook :
- Cliquez sur le sélecteur d'exécution, puis sur Gérer les sessions.

- Dans la boîte de dialogue Sessions actives, cliquez sur l'icône de fin de session, puis sur Arrêter.

- Cliquez sur le sélecteur d'exécution, puis sur Gérer les sessions.
Planifiez le code du notebook à partir de la console Google Cloud (la tarification des notebooks s'applique).
Exécutez le code du notebook en tant que charge de travail par lot (les tarifs Serverless pour Apache Spark s'appliquent).
- Programmez le notebook.
- Si l'exécution du code du notebook fait partie d'un workflow, planifiez le notebook dans un pipeline.
Téléchargez le code du notebook dans un fichier dans un terminal local ou dans Cloud Shell.
Dans la console Google Cloud , sur la page BigQuery Studio, ouvrez le notebook dans le volet Explorateur.
Pour développer la barre de menu, cliquez sur keyboard_arrow_down Afficher/Masquer l'en-tête.
Cliquez sur Fichier > Télécharger, puis sur Download.py.
Générer des
requirements.txt- Installez
pipreqsdans le répertoire où vous avez enregistré votre fichier.py.pip install pipreqs
Exécutez
pipreqspour générerrequirements.txt.pipreqs filename.py
Utilisez la Google Cloud CLI pour copier le fichier
requirements.txtlocal dans un bucket Cloud Storage.gcloud storage cp requirements.txt gs://BUCKET/
- Installez
Mettez à jour le code de la session Spark en modifiant le fichier
.pytéléchargé.Supprimez ou mettez en commentaire les commandes de script shell.
Supprimez le code qui configure la session Spark, puis spécifiez les paramètres de configuration en tant que paramètres d'envoi de la charge de travail par lot. (consultez Envoyer une charge de travail par lot Spark).
Exemple :
Supprimez la ligne de configuration du sous-réseau de session suivante du code :
session.environment_config.execution_config.subnetwork_uri = "{subnet_name}"Lorsque vous exécutez votre charge de travail par lot, utilisez l'indicateur
--subnetpour spécifier le sous-réseau.gcloud dataproc batches submit pyspark \ --subnet=SUBNET_NAME
Utilisez un extrait de code simple pour créer une session.
Exemple de code de notebook téléchargé avant simplification.
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session
session = Session() spark = DataprocSparkSession \ .builder \ .appName("CustomSparkSession") .dataprocSessionConfig(session) \ .getOrCreate()
Code de charge de travail par lot après simplification.
from pyspark.sql import SparkSession
spark = SparkSession \ .builder \ .getOrCreate()
Exécutez la charge de travail par lot.
Pour obtenir des instructions, consultez Envoyer la charge de travail par lot Spark.
Veillez à inclure l'option --deps-bucket pour pointer vers le bucket Cloud Storage contenant votre fichier
requirements.txt.Exemple :
gcloud dataproc batches submit pyspark FILENAME.py \ --region=REGION \ --deps-bucket=BUCKET \ --version=2.3
Remarques :
- FILENAME : nom du fichier de code du notebook que vous avez téléchargé et modifié.
- REGION : région Compute Engine dans laquelle se trouve votre cluster.
- BUCKET : nom du bucket Cloud Storage contenant votre fichier
requirements.txt. --version: la version d'exécution Spark 2.3 est sélectionnée pour exécuter la charge de travail par lot.
Validez votre code.
- Après avoir testé le code de votre charge de travail par lot, vous pouvez valider le fichier
.ipynbou.pydans votre dépôt à l'aide de votre clientgit, tel que GitHub, GitLab ou Bitbucket, dans le cadre de votre pipeline CI/CD.
- Après avoir testé le code de votre charge de travail par lot, vous pouvez valider le fichier
Planifiez votre charge de travail par lot avec Cloud Composer.
- Pour obtenir des instructions, consultez Exécuter des charges de travail Serverless pour Apache Spark avec Cloud Composer.
- Démonstration vidéo YouTube : Exploiter la puissance d'Apache Spark intégré à BigQuery
- Utiliser BigLake Metastore avec Dataproc
- Utiliser BigLake Metastore avec Serverless pour Apache Spark
Tarifs
Pour en savoir plus sur les tarifs, consultez la page Tarifs du runtime de notebook BigQuery.
Ouvrir un notebook Python BigQuery Studio
Créer une session Spark dans un notebook BigQuery Studio
Vous pouvez utiliser un notebook Python BigQuery Studio pour créer une session interactive Spark Connect. Chaque notebook BigQuery Studio ne peut être associé qu'à une seule session Spark active.
Vous pouvez créer une session Spark dans un notebook Python BigQuery Studio de différentes manières :
Session unique
Pour créer une session Spark dans un notebook, procédez comme suit :
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )Remplacez les éléments suivants :
Session Spark basée sur un modèle
Vous pouvez saisir et exécuter le code dans une cellule de notebook pour créer une session Spark basée sur un modèle de session existant. Tous les paramètres de configuration
sessionque vous fournissez dans le code de votre notebook remplaceront les paramètres identiques définis dans le modèle de session.Pour commencer rapidement, utilisez le modèle
Query using Sparkpour préremplir votre notebook avec le code du modèle de session Spark :from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Configure the session with an existing session template. session_template = "SESSION_TEMPLATE" session.session_template = f"projects/{project}/locations/{location}/sessionTemplates/{session_template}" # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )Remplacez les éléments suivants :
Écrire et exécuter du code PySpark dans votre notebook BigQuery Studio
Après avoir créé une session Spark dans votre notebook, utilisez-la pour exécuter le code du notebook Spark.
Compatibilité de l'API PySpark Spark Connect : votre session de notebook Spark Connect est compatible avec la plupart des API PySpark, y compris DataFrame, Functions et Column, mais pas avec SparkContext, RDD ni d'autres API PySpark. Pour en savoir plus, consultez Fonctionnalités compatibles avec Spark 3.5.
Écriture directe dans les notebooks Spark Connect : les sessions Spark d'un notebook BigQuery Studio préconfigurent le connecteur Spark BigQuery pour effectuer des écritures directes de données. La méthode d'écriture DIRECT utilise l'API BigQuery Storage Write, qui écrit les données directement dans BigQuery. La méthode d'écriture INDIRECT, qui est la méthode par défaut pour les lots Serverless pour Apache Spark, écrit les données dans un bucket Cloud Storage intermédiaire, puis les écrit dans BigQuery (pour en savoir plus sur les écritures INDIRECT, consultez Lire et écrire des données depuis et vers BigQuery).
API spécifiques à Dataproc : Dataproc simplifie l'ajout dynamique de packages
PyPIà votre session Spark en étendant la méthodeaddArtifacts. Vous pouvez spécifier la liste au formatversion-scheme(semblable àpip install). Cela indique au serveur Spark Connect d'installer les packages et leurs dépendances sur tous les nœuds du cluster, ce qui les rend disponibles pour les nœuds de calcul de vos UDF.Exemple qui installe la version
textdistancespécifiée et les dernières bibliothèquesrandom2compatibles sur le cluster pour permettre aux UDF utilisanttextdistanceetrandom2de s'exécuter sur les nœuds de calcul.spark.addArtifacts("textdistance==4.6.1", "random2", pypi=True)Aide pour le code de notebook : le notebook BigQuery Studio fournit une aide pour le code lorsque vous pointez sur le nom d'une classe ou d'une méthode, et une aide pour la complétion du code lorsque vous saisissez du code.
Dans l'exemple suivant, saisissez
DataprocSparkSession. et en pointant sur le nom de cette classe, vous pouvez afficher l'aide à la complétion de code et la documentation.
Exemples PySpark de notebooks BigQuery Studio
Cette section fournit des exemples de notebooks Python BigQuery Studio avec du code PySpark pour effectuer les tâches suivantes :
Nombre de mots
L'exemple Pyspark suivant crée une session Spark, puis compte les occurrences de mots dans un ensemble de données
bigquery-public-data.samples.shakespearepublic.# Basic wordcount example from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Run a wordcount on the public Shakespeare dataset. df = spark.read.format("bigquery").option("table", "bigquery-public-data.samples.shakespeare").load() words_df = df.select(f.explode(f.split(f.col("word"), " ")).alias("word")) word_counts_df = words_df.filter(f.col("word") != "").groupBy("word").agg(f.count("*").alias("count")).orderBy("word") word_counts_df.show()Remplacez les éléments suivants :
Résultat :
La sortie de la cellule liste un échantillon de la sortie du décompte de mots. Pour afficher les détails d'une session dans la console Google Cloud , cliquez sur le lien Vue détaillée de la session interactive. Pour surveiller votre session Spark, cliquez sur Afficher l'UI Spark sur la page des détails de la session.

Interactive Session Detail View: LINK +------------+-----+ | word|count| +------------+-----+ | '| 42| | ''All| 1| | ''Among| 1| | ''And| 1| | ''But| 1| | ''Gamut'| 1| | ''How| 1| | ''Lo| 1| | ''Look| 1| | ''My| 1| | ''Now| 1| | ''O| 1| | ''Od's| 1| | ''The| 1| | ''Tis| 4| | ''When| 1| | ''tis| 1| | ''twas| 1| | 'A| 10| |'ARTEMIDORUS| 1| +------------+-----+ only showing top 20 rows
Table Iceberg
Exécuter du code PySpark pour créer une table Iceberg avec des métadonnées BigLake Metastore
L'exemple de code suivant crée une
sample_iceberg_tableavec des métadonnées de table stockées dans le metastore BigLake, puis interroge la table.from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f # Create the Dataproc Serverless session. session = Session() # Set the session configuration for BigLake Metastore with the Iceberg environment. project_id = "PROJECT" region = "REGION" subnet_name = "SUBNET_NAME" location = "LOCATION" session.environment_config.execution_config.subnetwork_uri = f"{subnet_name}" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY" catalog = "CATALOG_NAME" namespace = "NAMESPACE" session.runtime_config.properties[f"spark.sql.catalog.{catalog}"] = "org.apache.iceberg.spark.SparkCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.catalog-impl"] = "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_project"] = f"{project_id}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_location"] = f"{location}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.warehouse"] = f"{warehouse_dir}" # Create the Spark Connect session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Create the namespace in BigQuery. spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create the Iceberg table. spark.sql("DROP TABLE IF EXISTS `sample_iceberg_table`"); spark.sql("CREATE TABLE sample_iceberg_table (id int, data string) USING ICEBERG;") spark.sql("DESCRIBE sample_iceberg_table;") # Insert table data and query the table. spark.sql("INSERT INTO sample_iceberg_table VALUES (1, \"first row\");") # Alter table, then query and display table data and schema. spark.sql("ALTER TABLE sample_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE sample_iceberg_table;") df = spark.sql("SELECT * FROM sample_iceberg_table") df.show() df.printSchema()Remarques :
La sortie de la cellule liste le
sample_iceberg_tableavec la colonne ajoutée et affiche un lien vers la page Détails de la session interactive dans la console Google Cloud . Vous pouvez cliquer sur Afficher l'UI Spark sur la page d'informations sur la session pour surveiller votre session Spark.
Interactive Session Detail View: LINK +---+---------+------------+ | id| data|newDoubleCol| +---+---------+------------+ | 1|first row| NULL| +---+---------+------------+ root |-- id: integer (nullable = true) |-- data: string (nullable = true) |-- newDoubleCol: double (nullable = true)
Afficher les détails d'une table dans BigQuery
Pour vérifier les détails d'une table Iceberg dans BigQuery, procédez comme suit :
Autres exemples
Créez un Spark
DataFrame(sdf) à partir d'un DataFrame Pandas (df).sdf = spark.createDataFrame(df) sdf.show()Exécutez des agrégations sur le
DataFramesSpark.from pyspark.sql import functions as F sdf.groupby("segment").agg( F.mean("total_spend_per_user").alias("avg_order_value"), F.approx_count_distinct("user_id").alias("unique_customers") ).show()Lisez des données depuis BigQuery à l'aide du connecteur Spark-BigQuery.
spark.conf.set("viewsEnabled","true") spark.conf.set("materializationDataset","my-bigquery-dataset") sdf = spark.read.format('bigquery') \ .load(query)Écrire du code Spark avec Gemini Code Assist
Vous pouvez demander à Gemini Code Assist de générer du code PySpark dans votre notebook. Gemini Code Assist récupère et utilise les tables BigQuery et Dataproc Metastore pertinentes, ainsi que leurs schémas, pour générer une réponse de code.
Pour générer du code Gemini Code Assist dans votre notebook, procédez comme suit :
Conseils pour générer du code avec Gemini Code Assist
Mettre fin à la session Spark
Vous pouvez effectuer l'une des actions suivantes pour arrêter votre session Spark Connect dans votre notebook BigQuery Studio :
Orchestrer le code de notebook BigQuery Studio
Vous pouvez orchestrer le code de notebook BigQuery Studio de différentes manières :
Programmer du code de notebook depuis la console Google Cloud
Vous pouvez planifier le code d'un notebook de différentes manières :
Exécuter du code de notebook en tant que charge de travail par lot
Pour exécuter le code du notebook BigQuery Studio en tant que charge de travail par lot, procédez comme suit.
Résoudre les problèmes liés aux notebooks
Si un échec se produit dans une cellule contenant du code Spark, vous pouvez résoudre le problème en cliquant sur le lien Vue détaillée de la session interactive dans la sortie de la cellule (voir les exemples de nombre de mots et de table Iceberg).
Problèmes connus et solutions
Erreur : Un environnement d'exécution de notebook créé avec la version Python
3.10peut entraîner une erreurPYTHON_VERSION_MISMATCHlorsqu'il tente de se connecter à la session Spark.Solution : Recréez l'environnement d'exécution avec la version Python
3.11.Étapes suivantes