Gestionar etiquetas de política en distintas ubicaciones
En este documento se describe cómo gestionar las etiquetas de política en distintas ubicaciones regionales para la seguridad a nivel de columna y el enmascaramiento dinámico de datos en BigQuery.
BigQuery proporciona control de acceso granular y enmascaramiento de datos dinámico para columnas de tablas sensibles mediante etiquetas de política, lo que permite clasificar los datos por tipo.
Después de crear una taxonomía de clasificación de datos y aplicar etiquetas de política a tus datos, puedes gestionar las etiquetas de política en diferentes ubicaciones.
Consideraciones de ubicación
Las taxonomías son recursos regionales, como los conjuntos de datos y las tablas de BigQuery. Cuando creas una taxonomía, especificas la región o la ubicación de la taxonomía.
Puede crear una taxonomía y aplicar etiquetas de política a las tablas de todas las regiones en las que BigQuery está disponible. Sin embargo, para aplicar etiquetas de política de una taxonomía a una columna de una tabla, la taxonomía y la tabla deben estar en la misma ubicación regional.
Aunque no puedes aplicar una etiqueta de política a una columna de una tabla que se encuentre en otra ubicación, puedes copiar la taxonomía a otra ubicación replicándola explícitamente allí.
Usar taxonomías en varias ubicaciones
Puedes copiar (o replicar) explícitamente una taxonomía y sus definiciones de etiquetas de políticas en otras ubicaciones sin tener que crear manualmente una nueva taxonomía en cada ubicación. Cuando replicas taxonomías, puedes usar las mismas etiquetas de política para la seguridad a nivel de columna en varias ubicaciones, lo que simplifica su gestión.
Cuando las replicas, la taxonomía y las etiquetas de política conservan los mismos IDs en cada ubicación.
La taxonomía y las etiquetas de política se pueden volver a sincronizar para que sean las mismas en varias ubicaciones. La replicación explícita de una taxonomía se lleva a cabo mediante una llamada a la API Data Catalog. En las sincronizaciones posteriores de la taxonomía replicada, se usa el mismo comando de API, que sobrescribe la taxonomía anterior.
Para facilitar la sincronización de la taxonomía, puedes usar Cloud Scheduler para sincronizar periódicamente la taxonomía en todas las regiones, ya sea según una programación establecida o pulsando un botón manualmente. Para usar Cloud Scheduler, debes configurar una cuenta de servicio.
Replicar una taxonomía en una nueva ubicación
Permisos obligatorios
Las credenciales de usuario o la cuenta de servicio que repliquen la taxonomía deben tener el rol Administrador de etiquetas de políticas de Data Catalog.
Consulta más información sobre cómo asignar el rol Administrador de etiquetas de política en Restringir el acceso con la seguridad a nivel de columna de BigQuery.
Para obtener más información sobre los roles y permisos de IAM en BigQuery, consulta el artículo sobre funciones y permisos predefinidos.
Para replicar una taxonomía en varias ubicaciones, sigue estos pasos:
API
Llama al método projects.locations.taxonomies.import de la API Data Catalog, proporcionando una solicitud POST y el nombre del proyecto y la ubicación de destino en la cadena HTTP.
POST https://datacatalog.googleapis.com/{parent}/taxonomies:import
El parámetro de ruta parent es el proyecto y la ubicación de destino a los que quieres copiar la taxonomía. Ejemplo:
projects/MyProject/locations/eu
Sincronizar una taxonomía replicada
Para sincronizar una taxonomía que ya se ha replicado en varias ubicaciones, repita la llamada a la API Data Catalog tal como se describe en Replicar una taxonomía en una nueva ubicación.
También puedes usar una cuenta de servicio y Cloud Scheduler para sincronizar la taxonomía según una programación específica. Si configuras una cuenta de servicio en Cloud Scheduler, también podrás activar una sincronización bajo demanda (sin programar) a través de la página de Cloud Scheduler en la consola Google Cloud o con la CLI de Google Cloud.
Sincronizar una taxonomía replicada con Cloud Scheduler
Para sincronizar una taxonomía replicada en varias ubicaciones con Cloud Scheduler, necesitas una cuenta de servicio.
Cuentas de servicio
Puedes conceder permisos para la sincronización de la réplica a una cuenta de servicio que ya tengas o crear una.
Para crear una cuenta de servicio, consulta el artículo Crear cuentas de servicio.
Permisos obligatorios
La cuenta de servicio que sincroniza la taxonomía debe tener el rol Administrador de etiquetas de política de Data Catalog. Para obtener más información, consulta Conceder el rol de administrador de etiquetas de políticas.
Configurar una sincronización de taxonomías con Cloud Scheduler
Para sincronizar una taxonomía replicada en varias ubicaciones con Cloud Scheduler, sigue estos pasos:
Consola
Primero, crea la tarea de sincronización y su programación.
Sigue las instrucciones para crear un trabajo en Cloud Scheduler.
En Destino, consulta las instrucciones de Crear un trabajo de programador con autenticación.
A continuación, añade la autenticación necesaria para la sincronización programada.
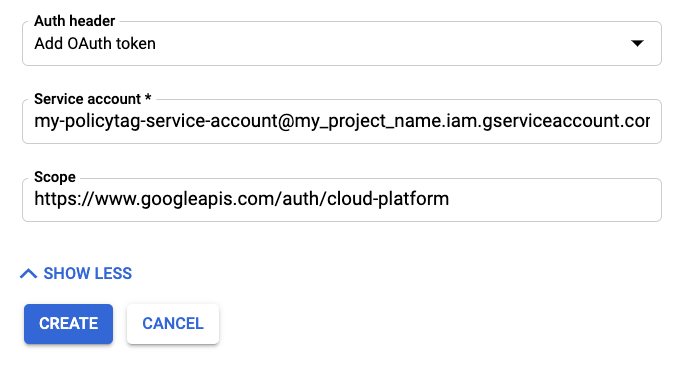
Haz clic en MOSTRAR MÁS para que se muestren los campos de autenticación.
En Encabezado de autorización, selecciona "Añadir token de OAuth".
Añade la información de tu cuenta de servicio.
En Scope (Ámbito), introduce "https://www.googleapis.com/auth/cloud-platform".
Haz clic en Crear para guardar la sincronización programada.
Ahora, comprueba que la tarea esté configurada correctamente.
Una vez creada la tarea, haz clic en Ejecutar ahora para comprobar que se ha configurado correctamente. Después, Cloud Scheduler activa la solicitud HTTP según la programación que hayas especificado.
gcloud
Sintaxis:
gcloud scheduler jobs create http "JOB_ID" --schedule="FREQUENCY" --uri="URI" --oath-service-account-email="CLIENT_SERVICE_ACCOUNT_EMAIL" --time-zone="TIME_ZONE" --message-body-from-file="MESSAGE_BODY"
Haz los cambios siguientes:
${JOB_ID}es el nombre del trabajo. Debe ser único en el proyecto. Ten en cuenta que no puedes volver a usar el nombre de un trabajo en un proyecto aunque elimines el trabajo asociado.${FREQUENCY}es la programación, también llamada intervalo de la tarea, que indica con qué frecuencia se debe ejecutar la tarea. Por ejemplo, "cada 3 horas". La cadena que proporciones aquí puede ser cualquier cadena compatible con crontab. Los desarrolladores que estén familiarizados con el formato cron de App Engine antiguo también pueden usar la sintaxis de cron de App Engine.${URI}es la URL completa del endpoint.--oauth-service-account-emaildefine el tipo de token. Ten en cuenta que las APIs de Google alojadas en*.googleapis.comesperan un token de OAuth.${CLIENT_SERVICE_ACCOUNT_EMAIL}es el correo de la cuenta de servicio del cliente.${MESSAGE_BODY}es la ruta al archivo que contiene el cuerpo de la solicitud POST.
Hay otros parámetros disponibles, que se describen en la referencia de Google Cloud CLI.
Ejemplo:
gcloud scheduler jobs create http cross_regional_copy_to_eu_scheduler --schedule="0 0 1 * *" --uri="https://datacatalog.googleapis.com/v1/projects/my-project/locations/eu/taxonomies:import" --oauth-service-account-email="policytag-manager-service-acou@my-project.iam.gserviceaccount.com" --time-zone="America/Los_Angeles" --message-body-from-file=request_body.json
Siguientes pasos
- Para obtener una descripción general de la seguridad a nivel de columna con etiquetas de política, consulta la introducción a la seguridad a nivel de columna de BigQuery.
- Para obtener más información sobre cómo crear y aplicar etiquetas de política, consulta el artículo Restringir el acceso con la seguridad a nivel de columna de BigQuery.
- Para obtener información sobre el impacto en las operaciones de escritura al usar la seguridad a nivel de columna de BigQuery, consulte el artículo Impacto en las operaciones de escritura con la seguridad a nivel de columna de BigQuery.
- Para obtener información sobre las prácticas recomendadas para usar etiquetas de política, consulta el artículo Usar etiquetas de política en BigQuery.