Tables BigLake pour Apache Iceberg dans BigQuery
Les tables BigLake pour Apache Iceberg dans BigQuery (ci-après dénommées tables BigLake Iceberg dans BigQuery) constituent la base de la création de lakehouses au format ouvert sur Google Cloud. Les tables BigLake Iceberg dans BigQuery offrent la même expérience entièrement gérée que les tables BigQuery standards, mais stockent les données dans des buckets de stockage détenus par le client. Les tables BigLake Iceberg dans BigQuery sont compatibles avec le format de table Iceberg ouvert pour une meilleure interopérabilité avec les moteurs de calcul Open Source et tiers sur une seule copie des données.
Les tables BigLake pour Apache Iceberg dans BigQuery sont différentes des tables externes Apache Iceberg. Les tables BigLake pour Apache Iceberg dans BigQuery sont des tables entièrement gérées qui peuvent être modifiées directement dans BigQuery, tandis que les tables externes Apache Iceberg sont gérées par le client et offrent un accès en lecture seule depuis BigQuery.
Les tables BigLake Iceberg dans BigQuery sont compatibles avec les fonctionnalités suivantes :
- Mutations de table à l'aide du langage de manipulation de données (LMD) GoogleSQL.
- Traitement par lot et par flux unifié, à haut débit, à l'aide de l'API Storage Write via les connecteurs BigLake tels que Spark, Dataflow et d'autres moteurs.
- Exportation d'instantanés Iceberg V2 et actualisation automatique à chaque mutation de table pour un accès direct aux requêtes avec des moteurs de requêtes open source et tiers.
- Évolution du schéma, qui vous permet d'ajouter, de supprimer et de renommer des colonnes en fonction de vos besoins. Cette fonctionnalité vous permet également de modifier le type de données d'une colonne existante et le mode de la colonne. Pour en savoir plus, consultez les règles de conversion de type.
- Optimisation automatique du stockage, y compris la mise à l'échelle adaptative des fichiers, le clustering automatique, la récupération de mémoire et l'optimisation des métadonnées.
- Fonctionnalité temporelle pour accéder aux données historiques dans BigQuery.
- Sécurité au niveau des colonnes et masquage des données.
- Transactions multi-instructions (en version Preview)
Architecture
Les tables BigLake Iceberg dans BigQuery offrent la simplicité de la gestion des ressources BigQuery aux tables qui se trouvent dans vos propres buckets cloud. Vous pouvez utiliser BigQuery et des moteurs de calcul Open Source sur ces tables sans avoir à déplacer les données hors des buckets que vous contrôlez. Vous devez configurer un bucket Cloud Storage avant de commencer à utiliser les tables BigLake Iceberg dans BigQuery.
Les tables BigLake Iceberg dans BigQuery utilisent BigLake Metastore comme metastore d'exécution unifié pour toutes les données Iceberg. Le metastore BigLake fournit une source unique de vérité pour gérer les métadonnées de plusieurs moteurs et permet l'interopérabilité des moteurs.
Le schéma suivant illustre l'architecture générale des tables gérées :
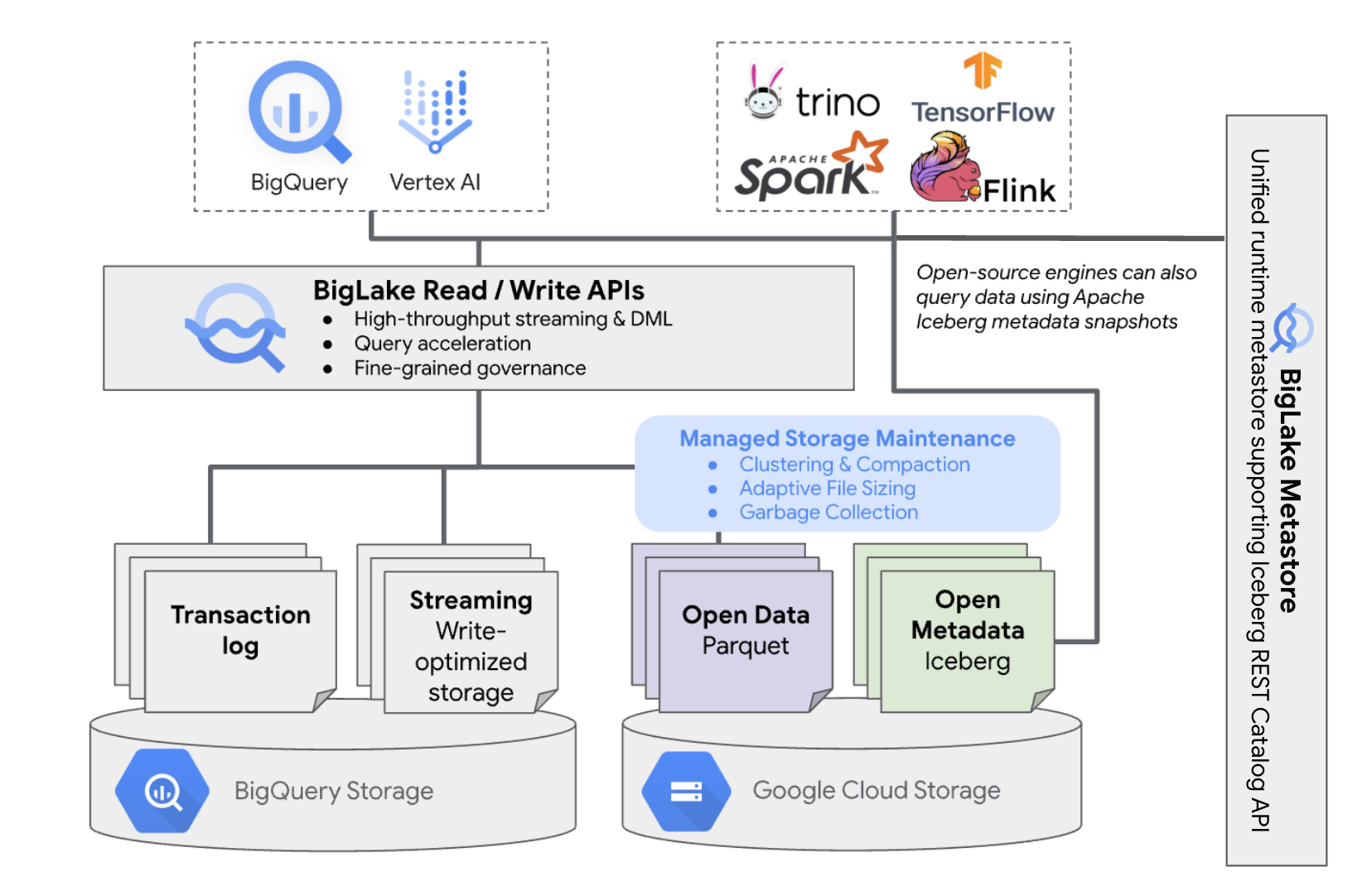
Cette gestion des tables a les implications suivantes sur votre bucket :
- BigQuery crée des fichiers de données dans le bucket en réponse aux requêtes d'écriture et aux optimisations de l'espace de stockage en arrière-plan, telles que les instructions LMD et le traitement par flux.
- Lorsque vous supprimez une table gérée dans BigQuery, BigQuery collecte les fichiers de données associés dans Cloud Storage après l'expiration de la période de voyage temporel.
La création d'une table BigLake Iceberg dans BigQuery est semblable à la création de tables BigQuery. Comme une table externe stocke les données dans des formats ouverts sur Cloud Storage, vous devez effectuer les opérations suivantes :
- Spécifiez la connexion de ressources Cloud avec
WITH CONNECTIONpour configurer les identifiants de connexion de BigLake afin d'accéder à Cloud Storage. - Spécifiez le format de fichier pour le stockage de données en tant que
PARQUETavec l'instructionfile_format = PARQUET. - Spécifiez le format de la table de métadonnées Open Source en tant que
ICEBERGavec l'instructiontable_format = ICEBERG.
Bonnes pratiques
La modification ou l'ajout direct de fichiers au bucket en dehors de BigQuery peut entraîner une perte de données ou des erreurs irrécupérables. Le tableau suivant décrit les scénarios possibles :
| Opération | Conséquences | Prévention |
|---|---|---|
| Ajout de fichiers au bucket en dehors de BigQuery. | Perte de données : les nouveaux fichiers ou objets ajoutés en dehors de BigQuery ne sont pas intégrés au processus de suivi assuré par BigQuery. Les fichiers non suivis sont supprimés par les processus de récupération de mémoire en arrière-plan. | Ajout de données exclusivement via BigQuery. Cela permet à BigQuery de suivre les fichiers et d'empêcher leur suppression par le processus de récupération de mémoire. Pour éviter les ajouts accidentels et la perte de données, nous vous recommandons également de limiter les autorisations d'écriture des outils externes sur les buckets contenant des tables BigLake Iceberg dans BigQuery. |
| Créez une table BigLake Iceberg dans BigQuery dans un préfixe non vide. | Perte de données : les données existantes ne sont pas soumis au suivi effectué par BigQuery. Ces fichiers sont donc considérés comme non suivis et supprimés par les processus de récupération de mémoire en arrière-plan. | Ne créez des tables BigLake Iceberg dans BigQuery que dans des préfixes vides. |
| Modifier ou remplacer une table BigLake Iceberg dans les fichiers de données BigQuery | Perte de données : en cas de modification ou de remplacement externe, la table ne passe pas la vérification de la cohérence et devient illisible. Les requêtes sur la table échouent. Il n'existe alors aucun moyen permettant de revenir à une situation normale en autonomie. Contactez l'assistance pour obtenir de l'aide sur la récupération des données. |
Modifiez les données exclusivement via BigQuery. Cela permet à BigQuery de suivre les fichiers et d'empêcher leur suppression par le processus de récupération de mémoire. Pour éviter les ajouts accidentels et la perte de données, nous vous recommandons également de limiter les autorisations d'écriture des outils externes sur les buckets contenant des tables BigLake Iceberg dans BigQuery. |
| Création de deux tables BigLake Iceberg dans BigQuery sur les mêmes URI ou sur des URI qui se chevauchent. | Perte de données : BigQuery ne crée pas de pont entre des instances d'URI identiques de tables BigLake Iceberg dans BigQuery. Les processus de récupération de mémoire en arrière-plan pour chaque table considèrent les fichiers de la table opposée comme étant non suivis, et vont donc les supprimer, ce qui entraîne une perte de données. | Utilisez des URI uniques pour chaque table BigLake Iceberg dans BigQuery. |
Bonnes pratiques de configuration des bucket Cloud Storage
La configuration de votre bucket Cloud Storage et sa connexion à BigLake ont un impact direct sur les performances, les coûts, l'intégrité des données, la sécurité et la gouvernance de vos tables BigLake Iceberg dans BigQuery. Voici quelques bonnes pratiques pour vous aider à effectuer cette configuration :
Choisissez un nom qui indique clairement que le bucket est uniquement destiné aux tables BigLake Iceberg dans BigQuery.
Choisissez des buckets Cloud Storage à région unique qui se trouvent dans la même région que votre ensemble de données BigQuery. Cette coordination améliore les performances et réduit les coûts en évitant les frais de transfert de données.
Par défaut, Cloud Storage stocke les données dans la classe de stockage Standard, qui offre des performances suffisantes. Pour optimiser les coûts de stockage des données, vous pouvez activer la classe automatique afin de gérer automatiquement les transitions entre les classes de stockage. La classe automatique commence par la classe de stockage Standard et déplace les objets auxquels personne n'accède vers des classes de plus en plus froides afin de réduire les coûts de stockage. Lorsque l'objet est lu à nouveau, il est replacé dans la classe Standard.
Activez l'accès uniforme au niveau du bucket et la protection contre l'accès public.
Vérifiez que les rôles requis sont attribués aux utilisateurs et comptes de service appropriés.
Pour éviter toute suppression ou corruption accidentelle des données Iceberg dans votre bucket Cloud Storage, limitez les autorisations d'écriture et de suppression pour la plupart des utilisateurs de votre organisation. Pour ce faire, vous pouvez définir une règle d'autorisation de bucket avec des conditions qui refusent les requêtes
PUTetDELETEpour tous les utilisateurs, à l'exception de ceux que vous spécifiez.Appliquez des clés de chiffrement gérées par Google ou gérées par le client pour renforcer la protection des données sensibles.
Activez la journalisation d'audit pour la transparence opérationnelle, le dépannage et la surveillance de l'accès aux données.
Conservez la règle de suppression réversible par défaut (conservation de sept jours) pour vous protéger contre les suppressions accidentelles. Toutefois, si vous constatez que des données Iceberg ont été supprimées, contactez l'assistance au lieu de restaurer les objets manuellement. En effet, les objets ajoutés ou modifiés en dehors de BigQuery ne sont pas suivis par les métadonnées BigQuery.
La mise à l'échelle adaptative des fichiers, le clustering automatique et la récupération de mémoire sont activés automatiquement et permettent d'optimiser les performances et les coûts des fichiers.
Évitez les fonctionnalités Cloud Storage suivantes, car elles ne sont pas compatibles avec les tables BigLake Iceberg dans BigQuery :
- Espaces de noms hiérarchiques
- Régions doubles et multirégions
- Listes de contrôle d'accès (LCA) aux objets
- Clés de chiffrement fournies par le client
- Gestion des versions des objets
- Verrouillage des objets
- Verrou de bucket
- Restaurer des objets supprimés de manière réversible avec l'API BigQuery ou l'outil de ligne de commande bq
Vous pouvez mettre en œuvre ces bonnes pratiques en créant votre bucket à l'aide de la commande suivante :
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
Remplacez les éléments suivants :
BUCKET_NAME: nom de votre nouveau bucketPROJECT_ID: ID de votre projetLOCATION: emplacement de votre nouveau bucket
Table BigLake Iceberg dans les workflows BigQuery
Les sections suivantes expliquent comment créer, charger, gérer et interroger des tables gérées.
Avant de commencer
Avant de créer et d'utiliser des tables BigLake Iceberg dans BigQuery, assurez-vous d'avoir configuré une connexion à une ressource cloud sur un bucket de stockage. Votre connexion a besoin d'autorisations en écriture sur le bucket de stockage, comme indiqué dans la section Rôles requis ci-dessous. Pour en savoir plus sur les rôles et autorisations requis pour les connexions, consultez Gérer les connexions.
Rôles requis
Pour obtenir les autorisations nécessaires pour autoriser BigQuery à gérer les tables de votre projet, demandez à votre administrateur de vous accorder les rôles IAM suivants :
-
Pour créer des tables BigLake Iceberg dans BigQuery :
-
Propriétaire de données BigQuery (
roles/bigquery.dataOwner) sur votre projet -
Administrateur de connexion BigQuery (
roles/bigquery.connectionAdmin) sur votre projet
-
Propriétaire de données BigQuery (
-
Pour interroger des tables BigLake Iceberg dans BigQuery :
-
Lecteur de données BigQuery (
roles/bigquery.dataViewer) sur votre projet -
Utilisateur BigQuery (
roles/bigquery.user) sur votre projet
-
Lecteur de données BigQuery (
-
Attribuez les rôles suivants au compte de service de connexion pour qu'il puisse lire et écrire des données dans Cloud Storage :
-
Utilisateur d'objets Storage (
roles/storage.objectUser) sur le bucket -
Lecteur des anciens buckets de l'espace de stockage (
roles/storage.legacyBucketReader) sur le bucket
-
Utilisateur d'objets Storage (
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Ces rôles prédéfinis contiennent les autorisations requises pour permettre à BigQuery de gérer les tables de votre projet. Pour connaître les autorisations exactes requises, développez la section Autorisations requises :
Autorisations requises
Les autorisations suivantes sont requises pour autoriser BigQuery à gérer les tables de votre projet :
bigquery.connections.delegatesur votre projetbigquery.jobs.createsur votre projetbigquery.readsessions.createsur votre projetbigquery.tables.createsur votre projetbigquery.tables.getsur votre projetbigquery.tables.getDatasur votre projet-
storage.buckets.getsur votre bucket -
storage.objects.createsur votre bucket -
storage.objects.deletesur votre bucket -
storage.objects.getsur votre bucket -
storage.objects.listsur votre bucket
Vous pouvez également obtenir ces autorisations avec des rôles personnalisés ou d'autres rôles prédéfinis.
Créer des tables BigLake Iceberg dans BigQuery
Pour créer une table BigLake Iceberg dans BigQuery, sélectionnez l'une des méthodes suivantes :
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
Remplacez les éléments suivants :
- PROJECT_ID : projet contenant l'ensemble de données. Si cet élément n'est pas défini, la commande utilise le projet par défaut.
- DATASET_ID : ensemble de données existant.
- TABLE_NAME : nom de la table que vous créez.
- DATA_TYPE : type de données des informations contenues dans la colonne.
- CLUSTER_COLUMN_LIST (facultatif) : liste de quatre colonnes au maximum, séparées par des virgules. Ces colonnes doivent être des colonnes uniques de premier niveau.
CONNECTION_NAME : nom de la connexion. Exemple :
myproject.us.myconnection.Pour utiliser une connexion par défaut, spécifiez
DEFAULTau lieu de la chaîne de connexion contenant PROJECT_ID.REGION.CONNECTION_ID.STORAGE_URI : URI Cloud Storage complet. Par exemple,
gs://mybucket/table.
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
Remplacez les éléments suivants :
- PROJECT_ID : projet contenant l'ensemble de données. Si cet élément n'est pas défini, la commande utilise le projet par défaut.
- CONNECTION_NAME : nom de la connexion. Exemple :
myproject.us.myconnection. - STORAGE_URI : URI Cloud Storage complet.
Par exemple,
gs://mybucket/table. - COLUMN_NAME : nom de la colonne.
- DATA_TYPE : type de données des informations contenues dans la colonne.
- CLUSTER_COLUMN_LIST (facultatif) : liste de quatre colonnes au maximum, séparées par des virgules. Ces colonnes doivent être des colonnes uniques de premier niveau.
- DATASET_ID : ID d'un ensemble de données existant.
- MANAGED_TABLE_NAME : nom de la table que vous créez.
API
Appelez la méthode tables.insert avec une ressource de table définie, comme suit :
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
Remplacez les éléments suivants :
- TABLE_NAME : nom de la table que vous créez.
- CONNECTION_NAME : nom de la connexion. Exemple :
myproject.us.myconnection. - STORAGE_URI : URI Cloud Storage complet.
Les caractères génériques sont également acceptés. Par exemple,
gs://mybucket/table. - COLUMN_NAME : nom de la colonne.
- DATA_TYPE : type de données des informations contenues dans la colonne.
Importer des données dans des tables BigLake Iceberg dans BigQuery
Les sections suivantes expliquent comment importer des données depuis des tables de différents formats dans des tables BigLake Iceberg dans BigQuery.
Chargement standard de données à partir de fichiers plats
Les tables BigLake Iceberg dans BigQuery utilisent des jobs de chargement BigQuery pour charger des fichiers externes dans des tables BigLake Iceberg dans BigQuery. Si vous disposez d'une table BigLake Iceberg dans BigQuery, suivez le guide de la CLI bq load ou le guide SQL LOAD pour charger des données externes. Après le chargement des données, de nouveaux fichiers Parquet sont écrits dans le dossier STORAGE_URI/data.
Si les instructions précédentes sont utilisées sans table BigLake Iceberg existante dans BigQuery, une table BigQuery est créée à la place.
Consultez les sections suivantes pour obtenir des exemples de chargement par lot dans des tables gérées, spécifiques aux différents outils :
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
Remplacez les éléments suivants :
- MANAGED_TABLE_NAME : nom d'une table BigLake Iceberg existante dans BigQuery.
- STORAGE_URI : URI Cloud Storage complet ou liste d'URI séparés par des virgules.
Les caractères génériques sont également acceptés. Par exemple,
gs://mybucket/table. - FILE_FORMAT : format de la table source. Pour connaître les formats acceptés, consultez la ligne
formatdeload_option_list.
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
Remplacez les éléments suivants :
- FILE_FORMAT : format de la table source. Pour connaître les formats acceptés, consultez la ligne
formatdeload_option_list. - MANAGED_TABLE_NAME : nom d'une table BigLake Iceberg existante dans BigQuery.
- STORAGE_URI : URI Cloud Storage complet ou liste d'URI séparés par des virgules.
Les caractères génériques sont également acceptés. Par exemple,
gs://mybucket/table.
Chargement standard à partir de fichiers partitionnés avec Hive
Vous pouvez charger des fichiers partitionnés avec Hive dans des tables BigLake Iceberg dans BigQuery à l'aide de jobs de chargement BigQuery standards. Pour en savoir plus, consultez la page Charger des données partitionnées externes.
Charger des données de traitement par flux à partir de Pub/Sub
Vous pouvez charger des données de traitement par flux dans des tables BigLake Iceberg dans BigQuery à l'aide d'un abonnement Pub/Sub BigQuery.
Exporter des données depuis des tables BigLake Iceberg dans BigQuery
Les sections suivantes expliquent comment exporter des données à partir de tables BigLake Iceberg dans BigQuery vers différents formats de table.
Exporter des données vers des formats de fichiers plats
Pour exporter une table BigLake Iceberg dans BigQuery vers un format de fichier plat, utilisez l'instruction EXPORT DATA et sélectionnez un format de destination. Pour en savoir plus, consultez la section Exporter des données.
Créer une table BigLake Iceberg dans les instantanés de métadonnées BigQuery
Pour créer une table BigLake Iceberg dans un instantané de métadonnées BigQuery, procédez comme suit :
Exportez les métadonnées au format Iceberg V2 avec l'instruction SQL
EXPORT TABLE METADATA.Facultatif : Planifiez l'actualisation des instantanés de métadonnées Iceberg. Pour actualiser un instantané de métadonnées Iceberg en fonction d'un intervalle de temps défini, utilisez une requête programmée.
Facultatif : Activez l'actualisation automatique des métadonnées pour votre projet afin de mettre à jour automatiquement l'instantané des métadonnées de votre table Iceberg à chaque mutation de table. Pour activer l'actualisation automatique des métadonnées, contactez bigquery-tables-for-apache-iceberg-help@google.com. Les
EXPORT METADATAsont appliqués à chaque opération d'actualisation.
L'exemple suivant crée une requête programmée nommée My Scheduled Snapshot Refresh Query à l'aide de l'instruction LDD EXPORT TABLE METADATA FROM mydataset.test. L'instruction DDL s'exécute toutes les 24 heures.
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
Afficher une table BigLake Iceberg dans un instantané de métadonnées BigQuery
Après avoir actualisé l'instantané des métadonnées de la table BigLake Iceberg dans BigQuery, vous pouvez le trouver dans l'URI Cloud Storage dans lequel la table BigLake Iceberg dans BigQuery a été créée à l'origine. Le dossier /data contient les partitions de données du fichier Parquet, et le dossier /metadata contient l'instantané des métadonnées de la table BigLake Iceberg dans BigQuery.
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
Notez que mydataset et table_name sont des espaces réservés pour votre ensemble de données et votre tableau.
Lire des tables BigLake Iceberg dans BigQuery avec Apache Spark
L'exemple suivant configure votre environnement pour utiliser Spark SQL avec Apache Iceberg, puis exécute une requête pour extraire les données d'une table BigLake Iceberg spécifiée dans BigQuery.
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
Remplacez les éléments suivants :
- ICEBERG_VERSION_NUMBER : version actuelle de l'environnement d'exécution Apache Spark/Iceberg. Téléchargez la dernière version sur la page Spark Releases (versions Spark).
- CATALOG_NAME : catalogue permettant de référencer votre table BigLake Iceberg dans BigQuery.
- BUCKET_PATH : chemin d'accès au bucket contenant les fichiers de table. Exemple :
gs://mybucket/ - FOLDER_NAME : dossier contenant les fichiers de table.
Exemple :
myfolder
Modifier des tables BigLake Iceberg dans BigQuery
Pour modifier une table BigLake Iceberg dans BigQuery, suivez la procédure décrite dans la section Modifier des schémas de table.
Utiliser des transactions multi-instructions
Pour accéder aux transactions contenant plusieurs instructions pour les tables BigLake Iceberg dans BigQuery, remplissez le formulaire d'inscription.
Tarifs
La tarification des tables BigLake Iceberg dans BigQuery comprend le stockage, l'optimisation du stockage, ainsi que les requêtes et les jobs.
Stockage
Les tables BigLake Iceberg dans BigQuery stockent toutes les données dans Cloud Storage. Vous êtes facturé pour toutes les données stockées, y compris les données historiques des tables. Des frais de traitement des données et de transfert, liés à Cloud Storage, peuvent également s'appliquer. Certains frais d'opération Cloud Storage peuvent être exonérés pour les opérations traitées via BigQuery ou l'API BigQuery Storage. Il n'y a pas de frais de stockage spécifiques à BigQuery. Pour en savoir plus, consultez la page Tarifs de Cloud Storage.
Optimisation du stockage
Les tables BigLake Iceberg dans BigQuery effectuent une gestion automatique des tables, y compris la compaction, le clustering, le garbage collection et la génération/l'actualisation des métadonnées BigQuery, afin d'optimiser les performances des requêtes et de réduire les coûts de stockage. L'utilisation des ressources de calcul pour la gestion des tables BigLake est facturée en unités de calcul des données (DCU) au fil du temps, par tranches d'une seconde. Pour en savoir plus, consultez Tarifs des tables BigLake Iceberg dans BigQuery.
Les opérations d'exportation de données qui ont lieu lors du traitement par flux via l'API BigQuery Storage Write sont incluses dans les tarifs de l'API Storage Write, et ne sont pas facturées comme des opérations de maintenance en arrière-plan. Pour en savoir plus, consultez la page Tarifs de l'ingestion de données.
L'optimisation du stockage et l'utilisation de EXPORT TABLE METADATA sont visibles dans la vue INFORMATION_SCHEMA.JOBS.
Requêtes et jobs
Comme pour les tables BigQuery, vous êtes facturé pour les requêtes et les octets lus (par Tio), si vous utilisez la tarification à la demande de BigQuery, ou bien pour la consommation d'emplacements (par emplacement et par heure), si vous utilisez la tarification par capacité de calcul de BigQuery.
Les tarifs BigQuery s'appliquent également à l'API BigQuery Storage Read et à l'API BigQuery Storage Write.
Les opérations de chargement et d'exportation (telles que EXPORT METADATA) utilisent des emplacements Enterprise Edition soumis au paiement à l'usage.
Cela diffère des tables BigQuery, pour lesquelles ces opérations ne sont pas facturées. Si des réservations PIPELINE avec des emplacements Enterprise ou Enterprise Plus sont disponibles, les opérations de chargement et d'exportation utilisent de préférence ces emplacements de réservation.
Limites
Les tables BigLake Iceberg dans BigQuery présentent les limites suivantes :
- Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les opérations de changement de nom ni les instructions
ALTER TABLE RENAME TO. - Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les copies de tables ni les instructions
CREATE TABLE COPY. - Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les clones de tables ni les instructions
CREATE TABLE CLONE. - Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les instantanés de table ni les instructions
CREATE SNAPSHOT TABLE. - Les tables BigLake Iceberg dans BigQuery n'acceptent pas le schéma de table suivant :
- Schéma vide.
- Schéma comportant les types de données
BIGNUMERIC,INTERVAL,JSON,RANGEouGEOGRAPHY. - Schéma comportant des classements de champs.
- Schéma comportant des expressions de valeur par défaut.
- Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les cas d'évolution de schéma suivants :
- Coercitions du type
NUMERICen typeFLOAT - Coercitions du type
INTen typeFLOAT - Ajout de champs imbriqués à des colonnes
RECORDexistantes à l'aide d'instructions LDD SQL
- Coercitions du type
- Les tables BigLake Iceberg dans BigQuery affichent une taille de stockage de 0 octet lorsqu'elles sont interrogées par la console ou les API.
- Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les vues matérialisées.
- Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les vues autorisées, mais le contrôle des accès au niveau des colonnes l'est.
- Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les mises à jour de capture des données modifiées (CDC).
- Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec la reprise après sinistre gérée.
- Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec le partitionnement. Vous pouvez à la place envisager d'utiliser le clustering.
- Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec la sécurité au niveau des lignes.
- Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les périodes de prévention des défaillances.
- Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les jobs d'extraction.
- La vue
INFORMATION_SCHEMA.TABLE_STORAGEn'inclut pas les tables BigLake Iceberg dans BigQuery. - Les tables BigLake Iceberg dans BigQuery ne sont pas acceptées comme destinations des résultats de requête. Vous pouvez utiliser l'instruction
CREATE TABLEavec l'argumentAS query_statementpour créer une table comme destination des résultats de la requête. CREATE OR REPLACEn'est pas compatible avec le remplacement des tables standards par des tables BigLake Iceberg dans BigQuery, ni avec le remplacement des tables BigLake Iceberg dans BigQuery par des tables standards.- Le chargement par lots et les instructions
LOAD DATAne permettent que d'ajouter des données aux tables BigLake Iceberg existantes dans BigQuery. - Le chargement par lot et les instructions
LOAD DATAne sont pas compatibles avec les mises à jour de schéma. TRUNCATE TABLEn'est pas compatible avec les tables BigLake Iceberg dans BigQuery. Il existe deux alternatives :CREATE OR REPLACE TABLE, en utilisant les mêmes options de création de table.- L'instruction
DELETE FROMtableWHEREtrue.
- La fonction de valeur de table
APPENDSn'est pas compatible avec les tables BigLake Iceberg dans BigQuery. - Il est possible que les métadonnées Iceberg ne contiennent pas les données diffusées dans BigQuery par l'API Storage Write au cours des 90 dernières minutes.
- L'accès paginé basé sur les enregistrements à l'aide de
tabledata.listn'est pas compatible avec les tables BigLake Iceberg dans BigQuery. - Les tables BigLake Iceberg dans BigQuery ne sont pas compatibles avec les ensembles de données associés.
- Une seule instruction LMD en mutation simultanée (
UPDATE,DELETEetMERGE) s'exécute pour chaque table BigLake Iceberg dans BigQuery. Les autres instructions LMD en mutation sont mises en file d'attente.