Migrar tablas de un lago de datos de HDFS
En este documento se explica cómo migrar las tablas de tu lago de datos de Apache Hadoop Distributed File System (HDFS) a Google Cloud.
Puede usar el conector de migración de data lake de HDFS en BigQuery Data Transfer Service para migrar sus tablas de Hive e Iceberg desde varias distribuciones de Hadoop, tanto en entornos on-premise como en la nube, a Google Cloud.
Con el conector de lago de datos de HDFS, puedes registrar tus tablas de lago de datos de HDFS en Dataproc Metastore y BigLake Metastore mientras usas Cloud Storage como almacenamiento subyacente de tus archivos.
En el siguiente diagrama se muestra un resumen del proceso de migración de tablas desde un clúster de Hadoop.
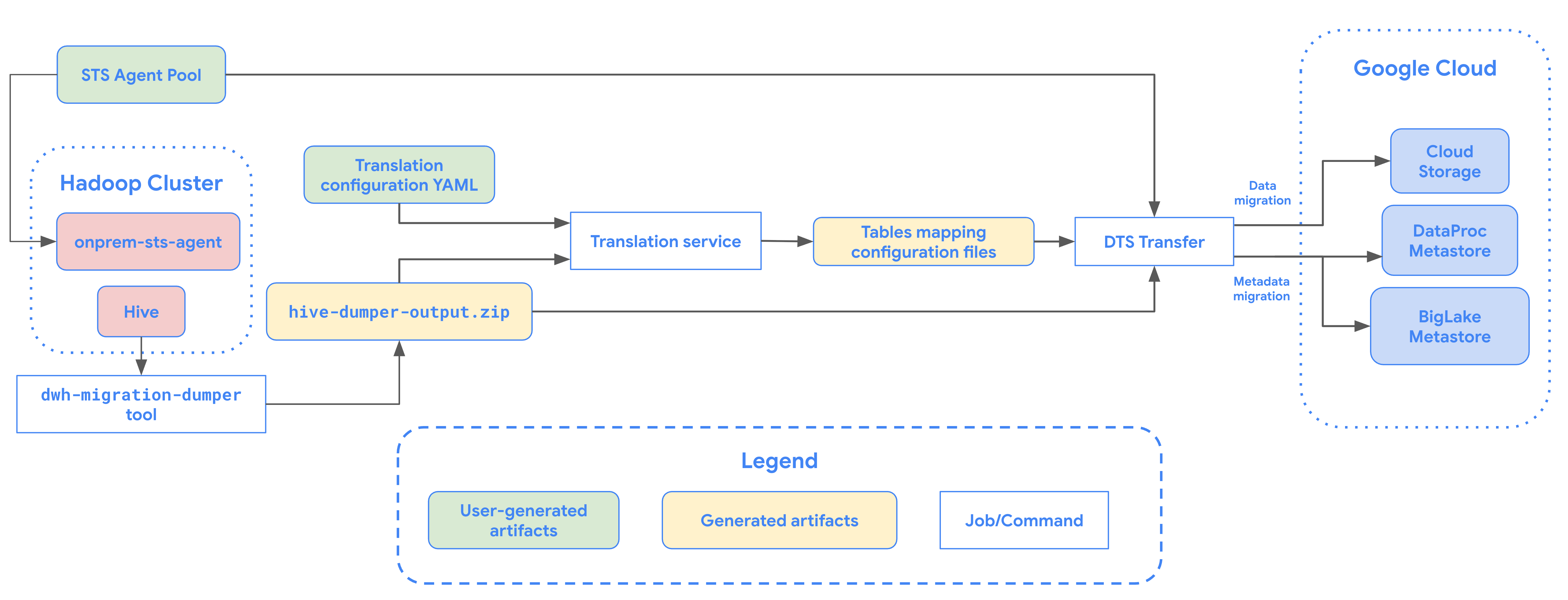
Limitaciones
Las transferencias de data lakes de HDFS están sujetas a las siguientes limitaciones:
- Para migrar tablas de Iceberg, debes registrarlas en BigLake Metastore para permitir el acceso de escritura a los motores de código abierto (como Spark o Flink) y el acceso de lectura a BigQuery.
- Para migrar tablas de Hive, debes registrarlas en Dataproc Metastore para permitir el acceso de escritura a los motores de código abierto y el acceso de lectura a BigQuery.
- Debes usar la herramienta de línea de comandos bq para migrar una tabla de un lago de datos de HDFS a BigQuery.
Antes de empezar
Antes de programar una transferencia de lago de datos de HDFS, debe hacer lo siguiente:
Crear un segmento de Cloud Storage para los archivos migrados
Crea un segmento de Cloud Storage que será el destino de los archivos de tu lago de datos migrados. En este documento, nos referiremos a este contenedor como MIGRATION_BUCKET.
Generar un archivo de metadatos para Apache Hive
Ejecuta la herramienta dwh-migration-dumper para extraer metadatos
de Apache Hive. La herramienta genera un archivo llamado hive-dumper-output.zip
en un segmento de Cloud Storage, al que se hace referencia en este documento como DUMPER_BUCKET.
Habilitar APIs
Habilita las siguientes APIs en tu proyectoGoogle Cloud :
- API de transferencia de datos
- API Transfer de Storage
Se crea un agente de servicio cuando habilitas la API Data Transfer.
Configurar permisos
- Crea una cuenta de servicio y concédele el rol Administrador de BigQuery (
roles/bigquery.admin). Esta cuenta de servicio se usa para crear la configuración de la transferencia. - Cuando se habilita la API Data Transfer, se crea un agente de servicio (P4SA). Concédele los siguientes roles:
roles/metastore.metadataOwnerroles/storagetransfer.adminroles/serviceusage.serviceUsageConsumerroles/storage.objectViewer- Si vas a migrar metadatos de tablas Iceberg de BigLake, asigna los roles
roles/storage.objectAdminyroles/bigquery.adminen lugar deroles/storage.objectViewer.
- Si vas a migrar metadatos de tablas Iceberg de BigLake, asigna los roles
Asigna el rol
roles/iam.serviceAccountTokenCreatoral agente de servicio con el siguiente comando:gcloud iam service-accounts add-iam-policy-binding SERVICE_ACCOUNT --member serviceAccount:service-PROJECT_NUMBER@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com --role roles/iam.serviceAccountTokenCreator
Configurar Storage Transfer Agent
Para configurar el agente de transferencia de Storage necesario para transferir un lago de datos de HDFS, haz lo siguiente:
- Configura los permisos para ejecutar el agente de transferencia de almacenamiento en tu clúster de Hadoop.
- Instala Docker en las máquinas de agente locales.
- Crea un pool de agentes del Servicio de transferencia de Storage en tu Google Cloud proyecto.
- Instala agentes en tus máquinas de agentes locales.
Programar una transferencia de data lake de HDFS
Para programar una transferencia de lago de datos de HDFS, introduce el comando bq mk
y proporciona la marca de creación de transferencia --transfer_config:
bq mk --transfer_config --data_source=hadoop --display_name='TRANSFER_NAME' --service_account_name='SERVICE_ACCOUNT' --project_id='PROJECT_ID' --location='REGION' --params='{"table_name_patterns":"LIST_OF_TABLES", "agent_pool_name":"AGENT_POOL_NAME", "table_metadata_path":"gs://DUMPER_BUCKET/hive-dumper-output.zip", "target_gcs_file_path":"gs://MIGRATION_BUCKET", "destination_dataproc_metastore":"DATAPROC_METASTORE", "destination_bigquery_dataset":"BIGLAKE_METASTORE", "translation_output_gcs_path":"gs://TRANSLATION_OUTPUT_BUCKET/metadata/config/default_database/" }'
Haz los cambios siguientes:
TRANSFER_NAME: el nombre visible de la configuración de la transferencia. El nombre de la transferencia puede ser cualquier valor que te permita identificarla si necesitas modificarla más adelante.SERVICE_ACCOUNT: el nombre de la cuenta de servicio que se usa para autenticar la transferencia. La cuenta de servicio debe ser propiedad del mismoproject_idque se ha usado para crear la transferencia y debe tener todos los permisos necesarios.PROJECT_ID: tu ID de proyecto Google Cloud . Si no se proporciona--project_idpara especificar un proyecto concreto, se usará el proyecto predeterminado.REGION: ubicación de esta configuración de transferencia.LIST_OF_TABLES: una lista de entidades que se van a transferir. Usa una especificación de nomenclatura jerárquica:database.table. Este campo admite expresiones regulares RE2 para especificar tablas. Por ejemplo:db1..*: especifica todas las tablas de la base de datos.db1.table1;db2.table2: una lista de tablas
AGENT_POOL_NAME: el nombre del grupo de agentes que se usa para crear agentes.DUMPER_BUCKET: el segmento de Cloud Storage que contiene el archivohive-dumper-output.zip.MIGRATION_BUCKET: ruta de GCS de destino a la que se cargarán todos los archivos subyacentes.Los metadatos se pueden migrar a Dataproc Metastore o a BigLake Metastore, y los datos subyacentes se almacenan en Cloud Storage. Puede especificar el destino mediante uno de los siguientes parámetros:
- Para transferir metadatos a Dataproc Metastore, usa el parámetro
destination_dataproc_metastorey especifica la URL de tu almacén de metadatos enDATAPROC_METASTORE. - Para transferir metadatos al metastore de BigLake, usa el parámetro
destination_bigquery_datasety especifica el conjunto de datos de BigQuery enBIGLAKE_METASTORE.
- Para transferir metadatos a Dataproc Metastore, usa el parámetro
TRANSLATION_OUTPUT_BUCKET: (Opcional) Especifica un segmento de Cloud Storage para la salida de la traducción. Para obtener más información, consulta Usar la salida de traducción.
Ejecuta este comando para crear la configuración de la transferencia e iniciar la transferencia del lago de datos de HDFS. Las transferencias se programan para que se ejecuten cada 24 horas de forma predeterminada, pero se pueden configurar con las opciones de programación de transferencias.
Cuando se complete la transferencia, las tablas del clúster de Hadoop se migrarán a MIGRATION_BUCKET.
Opciones de ingestión de datos
En las siguientes secciones se ofrece más información sobre cómo puede configurar sus transferencias de lagos de datos de HDFS.
Transferencias incrementales
Cuando se configura una transferencia con una programación periódica, cada transferencia posterior actualiza la tabla de Google Cloud con los últimos cambios realizados en la tabla de origen. Por ejemplo, todas las operaciones de inserción, eliminación o actualización con cambios en el esquema se reflejan en Google Cloud con cada transferencia.
Opciones de programación de transferencias
De forma predeterminada, las transferencias se programan para ejecutarse cada 24 horas. Para configurar la frecuencia con la que se ejecutan las transferencias, añade la marca --schedule a la configuración de la transferencia y especifica una programación de la transferencia con la sintaxis schedule.
Las transferencias de lagos de datos de HDFS deben tener un mínimo de 24 horas entre ejecuciones.
En el caso de las transferencias únicas, puedes añadir la marca end_time a la configuración de la transferencia para que solo se ejecute una vez.
Configurar la salida de Traducción
Puedes configurar una ruta de Cloud Storage y una base de datos únicas para cada tabla migrada. Para ello, sigue estos pasos para generar un archivo YAML de asignación de tablas que puedas usar en la configuración de la transferencia.
Crea un archivo YAML de configuración (con el sufijo
config.yaml) en el directorioDUMPER_BUCKETque contenga lo siguiente:type: object_rewriter relation: - match: relationRegex: ".*" external: location_expression: "'gs://MIGRATION_BUCKET/' + table.schema + '/' + table.name"
- Sustituye
MIGRATION_BUCKETpor el nombre del segmento de Cloud Storage de destino de los archivos de tabla migrados. El campolocation_expressiones una expresión del lenguaje de expresión común (CEL).
- Sustituye
Crea otro archivo YAML de configuración (con el sufijo
config.yaml) enDUMPER_BUCKETque contenga lo siguiente:type: experimental_object_rewriter relation: - match: schema: SOURCE_DATABASE outputName: database: null schema: TARGET_DATABASE
- Sustituye
SOURCE_DATABASEyTARGET_DATABASEpor el nombre de la base de datos de origen y la base de datos de Dataproc Metastore o el conjunto de datos de BigQuery, según el metastore elegido. Asegúrate de que el conjunto de datos de BigQuery exista si vas a configurar la base de datos para BigLake Metastore.
Para obtener más información sobre estos archivos YAML de configuración, consulta las directrices para crear un archivo YAML de configuración.
- Sustituye
Genera el archivo YAML de asignación de tablas con el siguiente comando:
curl -d '{ "tasks": { "string": { "type": "HiveQL2BigQuery_Translation", "translation_details": { "target_base_uri": "TRANSLATION_OUTPUT_BUCKET", "source_target_mapping": { "source_spec": { "base_uri": "DUMPER_BUCKET" } }, "target_types": ["metadata"] } } } }' \ -H "Content-Type:application/json" \ -H "Authorization: Bearer TOKEN" -X POST https://bigquerymigration.googleapis.com/v2alpha/projects/PROJECT_ID/locations/LOCATION/workflows
Haz los cambios siguientes:
TRANSLATION_OUTPUT_BUCKET: (Opcional) Especifica un segmento de Cloud Storage para la salida de la traducción. Para obtener más información, consulta Usar la salida de traducción.DUMPER_BUCKET: el URI base del bucket de Cloud Storage que contiene el archivohive-dumper-output.zipy el archivo YAML de configuración.TOKEN: el token de OAuth. Puedes generar este archivo en la línea de comandos con el comandogcloud auth print-access-token.PROJECT_ID: el proyecto para procesar la traducción.LOCATION: la ubicación en la que se procesa el trabajo. Por ejemplo,euous.
Monitoriza el estado de este trabajo. Cuando se completa, se genera un archivo de asignación para cada tabla de la base de datos en una ruta predefinida de
TRANSLATION_OUTPUT_BUCKET.
Monitorizar las transferencias de data lakes de HDFS
Después de programar una transferencia de un lago de datos de HDFS, puedes monitorizar la tarea de transferencia con comandos de la herramienta de línea de comandos bq. Para obtener información sobre cómo monitorizar tus trabajos de transferencia, consulta Ver tus transferencias.
Hacer un seguimiento del estado de la migración de tablas
También puedes ejecutar la herramienta dwh-dts-status para monitorizar el estado de todas las tablas transferidas en una configuración de transferencia o en una base de datos concreta. También puedes usar la herramienta dwh-dts-status
para enumerar todas las configuraciones de transferencia de un proyecto.
Antes de empezar
Para poder usar la herramienta dwh-dts-status, haz lo siguiente:
Obtén la herramienta
dwh-dts-statusdescargando el paquetedwh-migration-tooldel repositorio de GitHubdwh-migration-tools.Autentica tu cuenta en Google Cloud con el siguiente comando:
gcloud auth application-default loginPara obtener más información, consulta Cómo funcionan las credenciales predeterminadas de la aplicación.
Comprueba que el usuario tenga los roles
bigquery.adminylogging.viewer. Para obtener más información sobre los roles de gestión de identidades y accesos, consulta la referencia de control de acceso.
Mostrar todas las configuraciones de transferencia de un proyecto
Para enumerar todas las configuraciones de transferencia de un proyecto, usa el siguiente comando:
./dwh-dts-status --list-transfer-configs --project-id=[PROJECT_ID] --location=[LOCATION]
Haz los cambios siguientes:
PROJECT_ID: el ID del proyecto Google Cloud que está ejecutando las transferencias.LOCATION: la ubicación en la que se creó la configuración de la transferencia.
Este comando genera una tabla con una lista de nombres e IDs de configuración de transferencia.
Ver los estados de todas las tablas de una configuración
Para ver el estado de todas las tablas incluidas en una configuración de transferencia, usa el siguiente comando:
./dwh-dts-status --list-status-for-config --project-id=[PROJECT_ID] --config-id=[CONFIG_ID] --location=[LOCATION]
Haz los cambios siguientes:
PROJECT_ID: el ID del proyecto Google Cloud que está ejecutando las transferencias.LOCATION: la ubicación en la que se creó la configuración de la transferencia.CONFIG_ID: el ID de la configuración de transferencia especificada.
Este comando genera una tabla con una lista de tablas y su estado de transferencia en la configuración de transferencia especificada. El estado de la transferencia puede ser uno de los siguientes valores: PENDING, RUNNING, SUCCEEDED, FAILED o CANCELLED.
Ver los estados de todas las tablas de una base de datos
Para ver el estado de todas las tablas transferidas de una base de datos específica, usa el siguiente comando:
./dwh-dts-status --list-status-for-database --project-id=[PROJECT_ID] --database=[DATABASE]
Haz los cambios siguientes:
PROJECT_ID: el ID del proyecto Google Cloud que está ejecutando las transferencias.DATABASE:el nombre de la base de datos especificada.
Este comando genera una tabla con una lista de tablas y su estado de transferencia en la base de datos especificada. El estado de la transferencia puede ser uno de los siguientes valores: PENDING, RUNNING, SUCCEEDED, FAILED o CANCELLED.