Visualiza gráficos con BigQuery DataFrames
En este documento, se muestra cómo generar gráficos de varios tipos con la biblioteca de visualización de BigQuery DataFrames.
La API de bigframes.pandas proporciona un ecosistema completo de herramientas para Python. La API admite operaciones estadísticas avanzadas, y puedes visualizar las agregaciones generadas a partir de BigQuery DataFrames. También puedes cambiar de BigQuery DataFrames a un DataFrame pandas con operaciones de muestreo integradas.
Histograma
En el siguiente ejemplo, se leen datos de la tabla bigquery-public-data.ml_datasets.penguins para generar un histograma sobre la distribución de las profundidades del culmen de los pingüinos:

Gráfico de líneas
En el siguiente ejemplo, se usan datos de la tabla bigquery-public-data.noaa_gsod.gsod2021 para generar un gráfico de líneas de los cambios en la temperatura media a lo largo del año:

Gráfico de áreas
En el siguiente ejemplo, se usa la tabla bigquery-public-data.usa_names.usa_1910_2013 para hacer un seguimiento de la popularidad de los nombres en la historia de EE.UU. y se enfoca en los nombres Mary, Emily y Lisa:

Gráfico de barras
En el siguiente ejemplo, se usa la tabla bigquery-public-data.ml_datasets.penguins para visualizar la distribución de los sexos de los pingüinos:

Diagrama de dispersión
En el siguiente ejemplo, se usa la tabla bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2021 para explorar la relación entre los importes de las tarifas de taxi y las distancias de los viajes:

Visualiza un conjunto de datos grande
BigQuery DataFrames descarga datos en tu máquina local para la visualización. De forma predeterminada, la cantidad de puntos de datos que se pueden descargar está limitada a 1,000. Si la cantidad de puntos de datos supera el límite, los DataFrames de BigQuery toman una muestra aleatoria de la cantidad de puntos de datos igual al límite.
Puedes anular este límite configurando el parámetro sampling_n cuando traces un gráfico, como se muestra en el siguiente ejemplo:

Gráficos avanzados con parámetros de Pandas y Matplotlib
Puedes pasar más parámetros para ajustar tu gráfico, como lo harías con Pandas, ya que la biblioteca de trazado de BigQuery DataFrames se basa en Pandas y Matplotlib. En las siguientes secciones, se describen algunos ejemplos.
Tendencia de popularidad de nombres con gráficos secundarios
Con los datos del historial de nombres del ejemplo de gráfico de área, el siguiente ejemplo crea gráficos individuales para cada nombre configurando subplots=True en la llamada a la función plot.area():

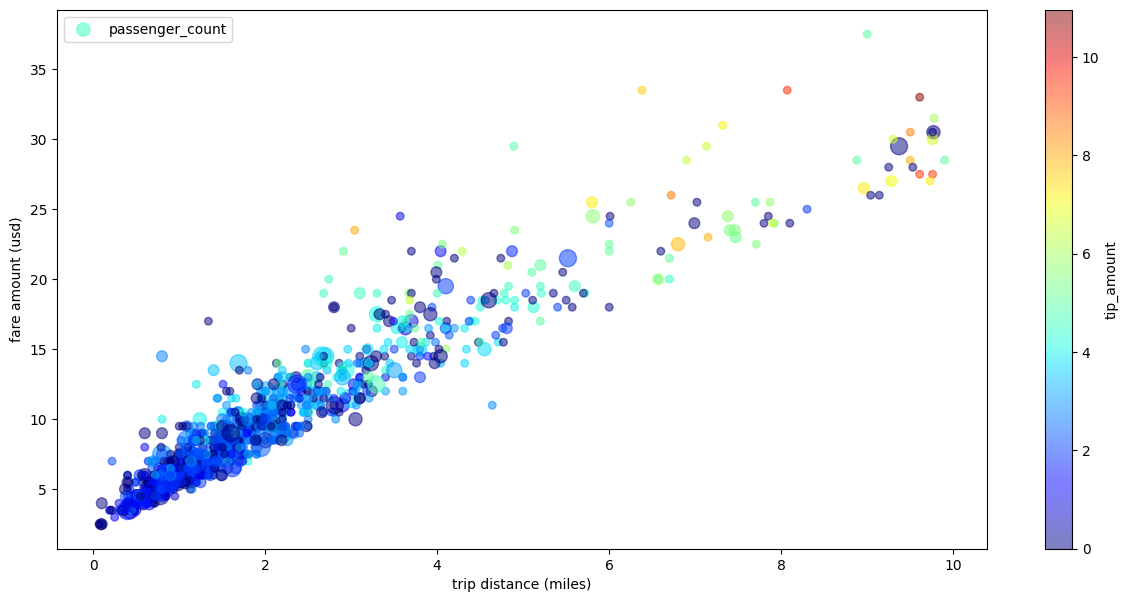
Diagrama de dispersión de viajes en taxi con múltiples dimensiones
Con los datos del ejemplo de diagrama de dispersión, el siguiente ejemplo cambia el nombre de las etiquetas de los ejes X e Y, usa el parámetro passenger_count para los tamaños de los puntos, usa puntos de color con el parámetro tip_amount y cambia el tamaño de la figura:
¿Qué sigue?
- Aprende a usar BigQuery DataFrames.
- Aprende a usar BigQuery DataFrames en dbt.
- Explora la referencia de la API de BigQuery DataFrames.