In diesem Leitfaden wird beschrieben, wie Sie die Bereitstellung von SAP HANA in einem RHEL-Cluster (Red Hat Enterprise Linux) oder einem SLES-Cluster (SUSE Linux Enterprise Server) für Hochverfügbarkeit (High Availability, HA) mit einem internen Passthrough-Network-Load-Balancer automatisieren, um die virtuelle IP-Adresse zu verwalten.
In diesem Leitfaden wird Cloud Deployment Manager verwendet, um zwei virtuelle Compute Engine-Maschinen (VMs), zwei SAP HANA-Systeme mit vertikaler Skalierung, eine virtuelle IP-Adresse (VIP) mit interner Passthrough-Network-Load-Balancer-Implementierung und einen betriebssystembasierten Hochverfügbarkeits-Cluster bereitzustellen – alles gemäß den Best Practices von Google Cloud, SAP und dem Betriebssystemanbieter.
Eines der SAP HANA-Systeme dient als primäres, aktives System und das andere als sekundäres Standby-System. Sie stellen beide SAP HANA-Systeme in derselben Region bereit, idealerweise in verschiedenen Zonen.

Der bereitgestellte Cluster enthält die folgenden Funktionen und Features:
- Hochverfügbarkeitsclusterressourcen-Manager von Pacemaker
- Ein Google Cloud Fencing-Mechanismus.
- Eine virtuelle IP-Adresse (VIP), die die Implementierung eines internen TCP-Load-Balancers der Ebene 4 verwendet, einschließlich:
- Eine Reservierung der IP-Adresse, die Sie für die VIP auswählen
- Zwei Compute Engine-Instanzgruppen
- Ein interner TCP-Load-Balancer
- Eine Compute Engine-Systemdiagnose
- In RHEL-HA-Clustern:
- Das Red Hat-Hochverfügbarkeitsmuster
- Der Red Hat-Ressourcen-Agent und die Fencing-Pakete
- In SLES-HA-Clustern:
- SUSE-Hochverfügbarkeitsmuster
- SUSE SAPHanaSR-Ressourcen-Agent-Paket
- Synchrone Systemreplikation
- Vorab in den Arbeitsspeicher laden
- Automatischer Neustart der fehlgeschlagenen Instanz als neue sekundäre Instanz
Wenn Sie ein SAP HANA-System ohne Linux-Hochverfügbarkeitscluster oder Standby-Hosts bereitstellen möchten, verwenden Sie die Bereitstellungsanleitung für SAP HANA.
Diese Anleitung richtet sich an fortgeschrittene SAP HANA-Nutzer, die mit Linux-Hochverfügbarkeitskonfigurationen für SAP HANA vertraut sind.
Vorbereitung
Vor dem Erstellen eines SAP HANA-Hochverfügbarkeitsclusters sind die folgenden Voraussetzungen zu erfüllen:
- Sie haben den Planungsleitfaden für SAP HANA und den Planungsleitfaden für SAP HANA – Hochverfügbarkeit gelesen.
- Sie oder Ihre Organisation haben ein Google Cloud -Konto und Sie haben ein Projekt für die SAP HANA-Bereitstellung erstellt. Informationen zum Erstellen vonGoogle Cloud -Konten undGoogle Cloud -Projekten finden Sie unter Google-Konto einrichten in der Bereitstellungsanleitung für SAP HANA.
- Wenn Ihre SAP-Arbeitslast die Anforderungen an den Datenstandort, die Zugriffssteuerung oder die Supportmitarbeiter oder gesetzliche Anforderungen erfüllen muss, müssen Sie den erforderlichen Assured Workloads-Ordner erstellen. Weitere Informationen finden Sie unter Compliance und Steuerung der Datenhoheit für SAP in Google Cloud.
Die SAP HANA-Installationsmedien sind in einem Cloud Storage-Bucket gespeichert, der in Ihrem Bereitstellungsprojekt und Ihrer Region verfügbar ist. Informationen zum Hochladen von SAP HANA-Installationsmedien in einen Cloud Storage-Bucket finden Sie in der Anleitung zur Bereitstellung von SAP HANA unter SAP HANA herunterladen.
Wenn OS Login in den Projektmetadaten aktiviert ist, müssen Sie OS Login vorübergehend deaktivieren, bis die Bereitstellung abgeschlossen ist. Für die Bereitstellung konfiguriert dieses Verfahren SSH-Schlüssel in Instanzmetadaten. Bei aktiviertem OS Login sind metadatenbasierte SSH-Schlüsselkonfigurationen deaktiviert und diese Bereitstellung schlägt fehl. Nach Abschluss der Bereitstellung können Sie die OS Login-Funktion wieder aktivieren.
Weitere Informationen finden Sie unter:
Bei einem internen VPC-DNS muss der Wert der Variable
vmDnsSettingin Ihren Projektmetadaten entwederGlobalOnlyoderZonalPreferredsein, damit die Knotennamen zonenübergreifend aufgelöst werden können. Die Standardeinstellung vonvmDnsSettingistZonalOnly. Weitere Informationen finden Sie unter:
Netzwerk erstellen
Erstellen Sie aus Sicherheitsgründen ein neues Netzwerk. Durch das Festlegen von Firewallregeln oder die Nutzung eines anderen Verfahrens der Zugriffskontrolle steuern Sie, wer Zugriff hat.
Wenn Ihr Projekt ein Standard-VPC-Netzwerk (Virtual Private Cloud) hat, verwenden Sie es nicht. Erstellen Sie stattdessen Ihr eigenes VPC-Netzwerk, sodass nur die von Ihnen explizit formulierten Firewallregeln gelten.
Während der Bereitstellung müssen Compute Engine-Instanzen normalerweise auf das Internet zugreifen können, um den Agenten für SAP von Google Cloudherunterzuladen. Wenn Sie eines der von SAP zertifizierten Linux-Images verwenden, die auf Google Cloudverfügbar sind, benötigt die Compute-Instanz außerdem einen Internetzugang, um die Lizenz zu registrieren und auf Repositories von Betriebssystemanbietern zuzugreifen. Eine Konfiguration mit einem NAT-Gateway und VM-Netzwerk-Tags unterstützt diesen Zugriff selbst dann, wenn die Ziel-Compute-Instanzen keine externen IP-Adressen haben.
So richten Sie das Netzwerk ein:
Console
- Rufen Sie in der Google Cloud -Console die Seite VPC-Netzwerke auf.
- Klicken Sie auf VPC-Netzwerk erstellen.
- Geben Sie einen Namen für das Netzwerk ein.
Der Name muss der Namenskonvention entsprechen. VPC-Netzwerke verwenden die Namenskonvention von Compute Engine.
- Wählen Sie unter Modus für Subnetzerstellung die Option Benutzerdefiniert aus.
- Legen Sie im Abschnitt Neues Subnetz folgende Konfigurationsparameter für das Subnetz fest:
- Geben Sie einen Namen für das Subnetz ein.
- Wählen Sie unter Region die Compute Engine-Region aus, in der Sie das Subnetz erstellen möchten.
- Wählen Sie für IP-Stack-Typ die Option IPv4 (einzelner Stack) aus und geben Sie dann einen IP-Adressbereich im CIDR-Format ein, z. B.
10.1.0.0/24.Dies ist der primäre IPv4-Bereich für das Subnetz. Wenn Sie mehrere Subnetze erstellen möchten, weisen Sie den Subnetzen im Netzwerk nicht überlappende CIDR-IP-Adressbereiche zu. Beachten Sie, dass jedes Subnetz und seine internen IP-Adressbereiche einer einzelnen Region zugeordnet sind.
- Klicken Sie auf Fertig.
- Klicken Sie auf Subnetz hinzufügen und wiederholen Sie die vorherigen Schritte, um weitere Subnetze zu erstellen. Sie können dem Netzwerk weitere Subnetze hinzufügen, nachdem Sie das Netzwerk erstellt haben.
- Klicken Sie auf Erstellen.
gcloud
- Rufen Sie Cloud Shell auf.
- Führen Sie den folgenden Befehl aus, um ein neues Netzwerk im benutzerdefinierten Subnetzwerkmodus zu erstellen:
gcloud compute networks create NETWORK_NAME --subnet-mode custom
Ersetzen Sie
NETWORK_NAMEdurch den Namen des neuen Clusters. Der Name muss der Namenskonvention entsprechen. VPC-Netzwerke verwenden die Namenskonvention von Compute Engine.Geben Sie
--subnet-mode customan und deaktivieren Sie so den standardmäßigen automatischen Modus. Ansonsten würde durch diesen Modus automatisch in jeder Compute Engine-Region ein Subnetz erstellt werden. Weitere Informationen dazu finden Sie unter Modus für Subnetzerstellung. - Erstellen Sie ein Subnetzwerk und geben Sie die Region und den IP-Adressbereich an:
gcloud compute networks subnets create SUBNETWORK_NAME \ --network NETWORK_NAME --region REGION --range RANGEDabei gilt:
SUBNETWORK_NAME: der Name des neuen Subnetzwerks.NETWORK_NAME: der Name des Netzwerks, das Sie im vorherigen Schritt erstellt haben.REGION: die Region, in der sich das Subnetzwerk befinden sollRANGE: der im CIDR-Format angegebene IP-Adressbereich, z. B.10.1.0.0/24Wenn Sie mehrere Subnetzwerke hinzufügen möchten, weisen Sie den Subnetzwerken im Netzwerk nicht überlappende CIDR-IP-Adressbereiche zu. Beachten Sie, dass jedes Subnetzwerk und seine internen IP-Adressbereiche einer einzelnen Region zugeordnet sind.
- Wiederholen Sie den vorherigen Schritt, falls Sie weitere Subnetze erstellen möchten.
NAT-Gateway einrichten
Wenn Sie eine oder mehrere VMs ohne öffentliche IP-Adressen erstellen müssen, müssen Sie die Network Address Translation (NAT) verwenden, damit die VMs auf das Internet zugreifen können. Verwenden Sie Cloud NAT, einen Google Cloud verteilten, softwarebasierten verwalteten Dienst, der es VMs ermöglicht, ausgehende Pakete an das Internet zu senden und entsprechende eingehende Antwortpakete zu empfangen. Alternativ können Sie eine separate VM als NAT-Gateway einrichten.
Informationen zum Erstellen einer Cloud NAT-Instanz für Ihr Projekt finden Sie unter Cloud NAT verwenden.
Nachdem Sie Cloud NAT für Ihr Projekt konfiguriert haben, können Ihre VM-Instanzen ohne öffentliche IP-Adressen sicher auf das Internet zugreifen.
Firewallregeln hinzufügen
Standardmäßig verhindert eine implizite Firewallregel eingehende Verbindungen von außerhalb Ihres VPC-Netzwerks. Wenn Sie eingehende Verbindungen zulassen möchten, richten Sie für Ihre VM eine entsprechende Firewallregel ein. Wenn eine eingehende Verbindung zu einer VM hergestellt wurde, ist Traffic über diese Verbindung in beide Richtungen zulässig.
Für HA-Cluster für SAP HANA sind mindestens zwei Firewallregeln erforderlich. Mit einer Regel kann die Compute Engine-Systemdiagnose den Status der Clusterknoten prüfen und mit der anderen wird die Kommunikation zwischen den Clusterknoten ermöglicht.Wenn Sie kein freigegebenes VPC-Netzwerk verwenden, müssen Sie die Firewallregel für die Kommunikation zwischen den Knoten erstellen, jedoch nicht für die Systemdiagnosen. Die Deployment Manager-Vorlage erstellt die Firewallregel für die Systemdiagnosen, die Sie nach Abschluss der Bereitstellung bei Bedarf ändern können.
Wenn Sie ein freigegebenes VPC-Netzwerk verwenden, muss ein Netzwerkadministrator beide Firewallregeln im Hostprojekt erstellen.
Sie können auch eine Firewallregel erstellen, um externen Zugriff auf bestimmte Ports zuzulassen oder den Zugriff zwischen VMs im selben Netzwerk einzuschränken. Wenn der VPC-Netzwerktyp default verwendet wird, gelten auch einige zusätzliche Standardregeln. So etwa die Regel default-allow-internal, die den Zugriff zwischen VMs im selben Netzwerk an allen Ports erlaubt.
Abhängig von der für Ihre Umgebung geltenden IT-Richtlinie müssen Sie möglicherweise die Konnektivität zu Ihrem Datenbankhost isolieren oder anderweitig einschränken. Dazu erstellen Sie Firewallregeln.
Je nach Szenario können Sie Firewallregeln erstellen, die den Zugriff für Folgendes erlauben:
- SAP-Standardports, die unter TCP/IP-Ports aller SAP-Produkte aufgeführt sind.
- Verbindungen von Ihrem Computer oder dem Unternehmensnetzwerk aus zu Ihrer Compute Engine-VM-Instanz. Wenn Sie sich nicht sicher sind, welche IP-Adresse Sie verwenden sollen, wenden Sie sich an den Netzwerkadministrator Ihres Unternehmens.
- SSH-Verbindungen zu Ihrer VM-Instanz, einschließlich SSH-in-Browser.
- Verbindung zu Ihrer VM über ein Drittanbieter-Tool unter Linux. Erstellen Sie eine Regel, die dem Tool den Zugriff über Ihre Firewall ermöglicht.
So erstellen Sie eine Firewallregel:
Console
Rufen Sie in der Google Cloud -Console die Seite Firewall des VPC-Netzwerk auf.
Klicken Sie oben auf der Seite auf Firewallregel erstellen.
- Wählen Sie im Feld Netzwerk das Netzwerk aus, in dem sich die VM befindet.
- Geben Sie im Feld Ziele die Ressourcen in Google Cloudan, für die diese Regel gelten soll. Geben Sie beispielsweise Alle Instanzen im Netzwerk an. Sie können unter Angegebene Ziel-Tags auch Tags eingeben, um die Regel auf bestimmte Instanzen in Google Cloudzu beschränken.
- Wählen Sie im Feld Quellfilter eine der folgenden Optionen aus:
- IP-Bereiche, um eingehenden Traffic von bestimmten IP-Adressen zuzulassen. Geben Sie den IP-Adressbereich im Feld Quell-IP-Bereiche an.
- Subnetze, um eingehenden Traffic von einem bestimmten Subnetz zuzulassen. Geben Sie den Namen des Subnetzwerks im folgenden Feld Subnetze an. Mit dieser Option können Sie den Zugriff zwischen den VMs in einer dreistufigen oder einer horizontal skalierbaren Konfiguration zulassen.
- Wählen Sie im Bereich Protokolle und Ports die Option Angegebene Protokolle und Ports aus und geben Sie
tcp:PORT_NUMBERein.
Klicken Sie auf Erstellen, um die Firewallregel anzulegen.
gcloud
Erstellen Sie mit dem folgenden Befehl eine Firewallregel:
$ gcloud compute firewall-rules create FIREWALL_NAME
--direction=INGRESS --priority=1000 \
--network=NETWORK_NAME --action=ALLOW --rules=PROTOCOL:PORT \
--source-ranges IP_RANGE --target-tags=NETWORK_TAGSLinux-Hochverfügbarkeitscluster mit SAP HANA-Installation erstellen
In der folgenden Anleitung wird mit Cloud Deployment Manager ein RHEL- oder SLES-Cluster mit zwei SAP HANA-Systemen erstellt: ein primäres SAP HANA-System mit einem Host auf einer VM-Instanz und ein SAP HANA-Standby-System auf einer anderen VM-Instanz in derselben Compute Engine-Region. Die SAP HANA-Systeme verwenden die synchrone Systemreplikation. Die replizierten Daten werden vorab vom Standby-System geladen.
Die Konfigurationsoptionen für den SAP HANA-Hochverfügbarkeitscluster legen Sie in einer Konfigurationsdateivorlage in Deployment Manager fest.
In der folgenden Anleitung wird Cloud Shell verwendet, sie ist aber allgemein auf Google Cloud-CLI anwendbar.
Prüfen Sie, ob Ihre aktuellen Kontingente für Ressourcen wie nichtflüchtige Speicher und CPUs für das zu installierende SAP HANA-System ausreichen. Bei unzureichenden Kontingenten schlägt die Bereitstellung fehl. Welche Kontingente Sie für SAP HANA benötigen, erfahren Sie unter Überlegungen zu Preisen und Kontingenten für SAP HANA.
Öffnen Sie Cloud Shell. Wenn Sie das Google Cloud CLI auf Ihrer lokalen Workstation installiert haben, öffnen Sie stattdessen ein Terminal.
Laden Sie die Konfigurationsdateivorlage
template.yamlfür den SAP HANA-Hochverfügbarkeitscluster in Ihr Arbeitsverzeichnis herunter. Geben Sie dafür den folgenden Befehl in Cloud Shell oder in der gcloud CLI ein:$wget https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/latest/dm-templates/sap_hana_ha_ilb/template.yamlSie können die Datei
template.yamlso umbenennen, dass die von ihr definierte Konfiguration im Namen erkennbar ist.Öffnen Sie die Datei
template.yamlim Cloud Shell-Code-Editor bzw. bei Verwendung der gcloud CLI in Ihrem bevorzugten Texteditor.Klicken Sie zum Öffnen des Codeeditors auf das Stiftsymbol oben rechts im Cloud Shell-Terminalfenster.
Aktualisieren Sie in der Datei
template.yamldie Attributwerte. Ersetzen Sie dazu die Parameter in Klammern durch die Werte für Ihre Installation. Die Attribute sind in der folgenden Tabelle beschrieben.Wenn Sie die VM-Instanzen ohne Installation von SAP HANA erstellen möchten, löschen Sie alle Zeilen, die mit
sap_hana_beginnen, oder kommentieren Sie diese aus.Attribut Datentyp Beschreibung typeString Gibt Speicherort, Typ und Version der Deployment Manager-Vorlage an, die während der Bereitstellung verwendet werden sollen.
Die YAML-Datei enthält zwei
type-Spezifikationen, von denen eine auskommentiert ist. Für die standardmäßig aktivetype-Spezifikation ist die Vorlagenversion alslatestangegeben. Die auskommentiertetype-Spezifikation gibt eine bestimmte Vorlagenversion mit einem Zeitstempel an.Wenn Sie möchten, dass alle Ihre Bereitstellungen die gleiche Vorlagenversion nutzen, verwenden Sie die
type-Spezifikation, die den Zeitstempel enthält.primaryInstanceNameString Der Name der VM-Instanz für das primäre SAP HANA-System. Der Name darf nur Kleinbuchstaben, Zahlen und Bindestriche enthalten. secondaryInstanceNameString Der Name der VM-Instanz für das sekundäre SAP HANA-System. Der Name darf nur Kleinbuchstaben, Zahlen und Bindestriche enthalten. primaryZoneString Zone, in der das primäre SAP HANA-System bereitgestellt wird. Die primäre und die sekundäre Zone müssen sich in derselben Region befinden. secondaryZoneString Die Zone, in der das sekundäre SAP HANA-System bereitgestellt wird. Die primäre und die sekundäre Zone müssen sich in derselben Region befinden. instanceTypeString Der Typ der virtuellen Maschine in Compute Engine, auf der Sie SAP HANA ausführen müssen. Wenn Sie einen benutzerdefinierten VM-Typ benötigen, geben Sie einen vordefinierten VM-Typ mit einer Anzahl an vCPUs an, die der benötigten Anzahl am nächsten kommt, aber noch darüber liegt. Wenn die Bereitstellung abgeschlossen ist, ändern Sie die Anzahl der vCPUs und den Umfang des Arbeitsspeichers. networkString Der Name des Netzwerks, in dem der Load-Balancer erstellt werden soll, der die VIP verwaltet. Wenn Sie ein freigegebenes VPC-Netzwerk verwenden, müssen Sie die ID des Hostprojekts als übergeordnetes Verzeichnis des Netzwerknamens hinzufügen. Beispiel:
host-project-id/network-name.subnetworkString Der Name des Subnetzwerks, das Sie für Ihren HA-Cluster verwenden. Wenn Sie ein freigegebenes VPC-Netzwerk verwenden, müssen Sie die ID des Hostprojekts als übergeordnetes Verzeichnis des Subnetzwerknamens hinzufügen. Beispiel:
host-project-id/subnetwork-name.linuxImageString Der Name des Linux-Betriebssystem-Images bzw. der Linux-Image-Familie, die Sie mit SAP HANA verwenden. Wenn Sie eine Image-Familie angeben möchten, ergänzen Sie den Familiennamen durch das Präfix family/. Beispiel:family/rhel-8-2-sap-haoderfamily/sles-15-sp2-sap. Wenn Sie ein bestimmtes Image verwenden möchten, geben Sie nur dessen Namen an. Eine Liste der verfügbaren Imagefamilien finden Sie in der Cloud Console auf der Seite Images.linuxImageProjectString Das Google Cloud-Projekt, das das zu verwendende Image enthält. Dabei kann es sich um Ihr eigenes Projekt oder um ein Google Cloud -Imageprojekt handeln. Geben Sie für RHEL rhel-sap-cloudan. Geben Sie für SLESsuse-sap-cloudan. Eine Liste der Google Cloud Image-Projekte finden Sie auf der Seite Images in der Compute Engine-Dokumentation.sap_hana_deployment_bucketString Name des Cloud Storage-Buckets in Ihrem Projekt, der die von Ihnen in einem vorherigen Schritt hochgeladenen SAP HANA-Installationsdateien enthält. sap_hana_sidString Die SAP HANA-System-ID. Die ID muss aus drei alphanumerischen Zeichen bestehen und mit einem Buchstaben beginnen. Alle Buchstaben müssen Großbuchstaben sein. sap_hana_instance_numberGanzzahl Instanznummer (0 bis 99) des SAP HANA-Systems. Der Standardwert ist 0. sap_hana_sidadm_passwordString Ein temporäres Passwort für den Betriebssystemadministrator, das während der Bereitstellung verwendet werden soll. Ändern Sie das Passwort nach Abschluss der Bereitstellung. Passwörter müssen mindestens acht Zeichen lang sein und mindestens einen Großbuchstaben, einen Kleinbuchstaben und eine Ziffer enthalten. sap_hana_system_passwordString Ein temporäres Passwort für den Datenbank-Superuser. Ändern Sie das Passwort nach Abschluss der Bereitstellung. Passwörter müssen mindestens acht Zeichen lang sein und mindestens einen Großbuchstaben, einen Kleinbuchstaben und eine Ziffer enthalten. sap_vipString Die IP-Adresse, die Sie für Ihre VIP verwenden möchten. Die IP-Adresse muss im Bereich der Ihrem Subnetz zugewiesenen IP-Adressen liegen. Die Deployment Manager-Vorlage reserviert diese IP-Adresse für Sie. In einem aktiven HA-Cluster wird diese IP-Adresse immer der aktiven SAP HANA-Instanz zugewiesen. primaryInstanceGroupNameString Definiert den Namen der nicht verwalteten Instanzgruppe für den primären Knoten. Wenn Sie den Parameter weglassen, wird der Standardname ig-primaryInstanceNameverwendet.secondaryInstanceGroupNameString Definiert den Namen der nicht verwalteten Instanzgruppe für den sekundären Knoten. Wenn Sie diesen Parameter weglassen, wird der Standardname ig-secondaryInstanceNameverwendet.loadBalancerNameString Definiert den Namen des internen TCP-Load-Balancers. nic_typeString Optional, aber empfohlen, sofern für die Zielmaschine und die Betriebssystemversion verfügbar. Gibt die Netzwerkschnittstelle an, die mit der VM-Instanz verwendet werden soll. Sie können den Wert GVNICoderVIRTIO_NETangeben. Wenn Sie eine Google Virtual NIC (gVNIC) verwenden möchten, müssen Sie ein Betriebssystem-Image angeben, das gVNIC als Wert für das AttributlinuxImageunterstützt. Eine Liste der Betriebssystem-Images finden Sie unter Details zu Betriebssystemen.Wenn Sie für dieses Attribut keinen Wert angeben, wird die Netzwerkschnittstelle automatisch basierend auf dem Maschinentyp ausgewählt, den Sie für das Attribut
Dieses Argument ist in den Deployment Manager-VorlagenversioneninstanceTypeangeben.202302060649oder höher verfügbar.Folgende Beispiele zeigen eine abgeschlossene Konfigurationsdateivorlage, die einen Hochverfügbarkeitscluster für SAP HANA definiert. Der Cluster verwendet einen internen Passthrough-Netzwerk-Load-Balancer, um die VIP zu verwalten.
Deployment Manager stellt die Google Cloud-Ressourcen bereit, die in der Konfigurationsdatei definiert sind. Anschließend übernehmen Skripts die Konfiguration des Betriebssystems, die Installation von SAP HANA, die Konfiguration der Replikation und die Konfiguration des Linux-HA-Clusters.
Klicken Sie auf
RHELoderSLES, um das Beispiel aufzurufen, das für Ihr Betriebssystem spezifisch ist.RHEL
resources: - name: sap_hana_ha type: https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/latest/dm-templates/sap_hana_ha_ilb/sap_hana_ha.py # # By default, this configuration file uses the latest release of the deployment # scripts for SAP on Google Cloud. To fix your deployments to a specific release # of the scripts, comment out the type property above and uncomment the type property below. # # type: https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/yyyymmddhhmm/dm-templates/sap_hana_ha_ilb/sap_hana_ha.py # properties: primaryInstanceName: example-ha-vm1 secondaryInstanceName: example-ha-vm2 primaryZone: us-central1-a secondaryZone: us-central1-c instanceType: n2-highmem-32 network: example-network subnetwork: example-subnet-us-central1 linuxImage: family/rhel-8-1-sap-ha linuxImageProject: rhel-sap-cloud # SAP HANA parameters sap_hana_deployment_bucket: my-hana-bucket sap_hana_sid: HA1 sap_hana_instance_number: 00 sap_hana_sidadm_password: TempPa55word sap_hana_system_password: TempPa55word # VIP parameters sap_vip: 10.0.0.100 primaryInstanceGroupName: ig-example-ha-vm1 secondaryInstanceGroupName: ig-example-ha-vm2 loadBalancerName: lb-ha1 # Additional optional properties networkTag: hana-ha-ntwk-tag serviceAccount: sap-deploy-example@example-project-123456.SLES
resources: - name: sap_hana_ha type: https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/latest/dm-templates/sap_hana_ha_ilb/sap_hana_ha.py # # By default, this configuration file uses the latest release of the deployment # scripts for SAP on Google Cloud. To fix your deployments to a specific release # of the scripts, comment out the type property above and uncomment the type property below. # # type: https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/yyyymmddhhmm/dm-templates/sap_hana_ha_ilb/sap_hana_ha.py # properties: primaryInstanceName: example-ha-vm1 secondaryInstanceName: example-ha-vm2 primaryZone: us-central1-a secondaryZone: us-central1-c instanceType: n2-highmem-32 network: example-network subnetwork: example-subnet-us-central1 linuxImage: family/sles-15-sp1-sap linuxImageProject: suse-sap-cloud # SAP HANA parameters sap_hana_deployment_bucket: my-hana-bucket sap_hana_sid: HA1 sap_hana_instance_number: 00 sap_hana_sidadm_password: TempPa55word sap_hana_system_password: TempPa55word # VIP parameters sap_vip: 10.0.0.100 primaryInstanceGroupName: ig-example-ha-vm1 secondaryInstanceGroupName: ig-example-ha-vm2 loadBalancerName: lb-ha1 # Additional optional properties networkTag: hana-ha-ntwk-tag serviceAccount: sap-deploy-example@example-project-123456.Erstellen Sie die Instanzen:
$gcloud deployment-manager deployments create deployment-name --config template-name.yamlDer obige Befehl ruft Deployment Manager auf, um die Google Cloud -Infrastruktur einzurichten und dann die Kontrolle über ein Skript zu erteilen, das SAP HANA und den HA-Cluster installiert und konfiguriert.
Solange Deployment Manager die Kontrolle hat, werden Statusmeldungen in Cloud Shell geschrieben. Nach dem Aufrufen des Skripts werden Statusmeldungen in Logging geschrieben und können in der Google Cloud Console angezeigt werden, wie unter Logging-Logs überprüfen beschrieben.
Die Abschlusszeit kann variieren, aber der gesamte Vorgang dauert in der Regel weniger als 30 Minuten.
Bereitstellung des HANA-HA-Systems prüfen
Das Prüfen eines SAP HANA-HA-Clusters umfasst mehrere Schritte:
- Logging prüfen
- Konfiguration der VM und der SAP HANA-Installation prüfen
- Clusterkonfiguration prüfen
- Load-Balancer und Zustand der Instanzgruppen prüfen
- SAP HANA-System mit SAP HANA Studio prüfen
- Failover-Test durchführen
Log prüfen
Öffnen Sie in der Google Cloud Console Cloud Logging, um den Installationsfortschritt zu überwachen und nach Fehlern zu suchen.
Filtern Sie die Logs:
Log-Explorer
Wechseln Sie auf der Seite Log-Explorer zum Bereich Abfrage.
Wählen Sie im Drop-down-Menü Ressource die Option Global aus und klicken Sie dann auf Hinzufügen.
Wenn die Option Global nicht angezeigt wird, geben Sie im Abfrageeditor die folgende Abfrage ein:
resource.type="global" "Deployment"Klicken Sie auf Abfrage ausführen.
Legacy-Loganzeige
- Wählen Sie auf der Seite Legacy-Loganzeige im einfachen Auswahlmenü die Option Global als Logging-Ressource aus.
Analysieren Sie die gefilterten Logs:
- Wenn
"--- Finished"angezeigt wird, ist die Verarbeitung des Deployments abgeschlossen und Sie können mit dem nächsten Schritt fortfahren. Wenn ein Kontingentfehler auftritt:
Erhöhen Sie auf der Seite IAM & Verwaltung > Kontingente alle Kontingente, die nicht die im Planungsleitfaden für SAP HANA aufgeführten Anforderungen erfüllen.
Löschen Sie in Deployment Manager auf der Seite Deployments die Bereitstellung, um VMs und nichtflüchtige Speicher von der fehlgeschlagenen Installation zu bereinigen.
Führen Sie die Bereitstellung noch einmal aus.
- Wenn
Prüfen Sie die Konfiguration der VM und der SAP HANA-Installation
Wenn das SAP HANA-System fehlerfrei bereitgestellt wurde, stellen Sie eine SSH-Verbindung zu jeder VM her. Sie können hierfür wahlweise in Compute Engine auf der Seite mit den VM-Instanzen neben jeder VM-Instanz auf die Schaltfläche "SSH" klicken oder Ihre bevorzugte SSH-Methode verwenden.

Wechseln Sie zum Root-Nutzer.
sudo su -
Geben Sie bei der Eingabeaufforderung
df -hein. Prüfen Sie, ob die Ausgabe/hana-Verzeichnisse wie etwa/hana/dataenthält.RHEL
[root@example-ha-vm1 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 0 126G 0% /dev tmpfs 126G 54M 126G 1% /dev/shm tmpfs 126G 25M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda2 30G 5.4G 25G 18% / /dev/sda1 200M 6.9M 193M 4% /boot/efi /dev/mapper/vg_hana-shared 251G 52G 200G 21% /hana/shared /dev/mapper/vg_hana-sap 32G 477M 32G 2% /usr/sap /dev/mapper/vg_hana-data 426G 9.8G 417G 3% /hana/data /dev/mapper/vg_hana-log 125G 7.0G 118G 6% /hana/log /dev/mapper/vg_hanabackup-backup 512G 9.3G 503G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/899 tmpfs 26G 0 26G 0% /run/user/1003
SLES
example-ha-vm1:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 54M 189G 1% /dev/shm tmpfs 126G 34M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 30G 5.4G 25G 18% / /dev/sda2 20M 2.9M 18M 15% /boot/efi /dev/mapper/vg_hana-shared 251G 50G 202G 20% /hana/shared /dev/mapper/vg_hana-sap 32G 281M 32G 1% /usr/sap /dev/mapper/vg_hana-data 426G 8.0G 418G 2% /hana/data /dev/mapper/vg_hana-log 125G 4.3G 121G 4% /hana/log /dev/mapper/vg_hanabackup-backup 512G 6.4G 506G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/473 tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/0 tmpfs 26G 0 26G 0% /run/user/1003
Prüfen Sie den Status des neuen Clusters. Geben Sie dazu den für Ihr Betriebssystem spezifischen Statusbefehl ein:
RHEL
pcs statusSLES
crm statusDie Ausgabe sollte in etwa wie das folgende Beispiel aussehen. Darin werden beide VM-Instanzen gestartet und
example-ha-vm1ist die aktive primäre Instanz:RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.4-4b1f869f0f) - partition with quorum * Last updated: Wed Jul 7 23:05:11 2021 * Last change: Wed Jul 7 23:04:43 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ] Failed Resource Actions: * rsc_healthcheck_HA1_start_0 on example-ha-vm1 'error' (1): call=29, status='complete', exitreason='', last-rc-change='2021-07-07 21:07:35Z', queued=0ms, exec=2097ms * SAPHana_HA1_00_monitor_61000 on example-ha-vm1 'not running' (7): call=44, status='complete', exitreason='', last-rc-change='2021-07-07 21:09:49Z', queued=0ms, exec=0ms Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledSLES
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Wed Jul 7 22:57:59 2021 * Last change: Wed Jul 7 22:57:03 2021 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:external/gcpstonith): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:external/gcpstonith): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]Wechseln Sie zum SAP-Administrator. Ersetzen Sie hierfür im folgenden Befehl
SID_LCdurch den SID-Wert, den Sie in der Konfigurationsdateivorlage angegeben haben: Verwenden Sie Kleinbuchstaben für Buchstaben.su - SID_LCadmPrüfen Sie, ob die SAP HANA-Dienste wie u. a.
hdbnameserverundhdbindexserverauf der Instanz ausgeführt werden. Geben Sie dazu den folgenden Befehl ein:HDB infoWenn Sie RHEL für SAP 9.0 oder höher verwenden, achten Sie darauf, dass die Pakete
chkconfigundcompat-openssl11auf Ihrer VM-Instanz installiert sind.Weitere Informationen von SAP finden Sie im SAP-Hinweis 3108316 – Red Hat Enterprise Linux 9.x: Installation und Konfiguration.
Clusterkonfiguration prüfen
Prüfen Sie die Parametereinstellungen des Clusters. Prüfen Sie sowohl die Einstellungen, die von Ihrer Clustersoftware angezeigt werden, als auch die Parametereinstellungen in der Clusterkonfigurationsdatei. Vergleichen Sie Ihre Einstellungen mit den Einstellungen in den Beispielen unten, die von den in dieser Anleitung verwendeten Automatisierungsskripts erstellt wurden.
Klicken Sie auf den Tab für Ihr Betriebssystem.
RHEL
Rufen Sie die Clusterressourcenkonfigurationen auf:
pcs config show
Das folgende Beispiel zeigt die Ressourcenkonfigurationen, die von den Automatisierungsskripts in RHEL 8.1 und höher erstellt werden.
Wenn Sie RHEL 7.7 oder eine frühere Version ausführen, enthält die Ressourcendefinition
Clone: SAPHana_HA1_00-clonenichtMeta Attrs: promotable=true.Cluster Name: hacluster Corosync Nodes: example-rha-vm1 example-rha-vm2 Pacemaker Nodes: example-rha-vm1 example-rha-vm2 Resources: Group: g-primary Resource: rsc_healthcheck_HA1 (class=service type=haproxy) Operations: monitor interval=10s timeout=20s (rsc_healthcheck_HA1-monitor-interval-10s) start interval=0s timeout=100 (rsc_healthcheck_HA1-start-interval-0s) stop interval=0s timeout=100 (rsc_healthcheck_HA1-stop-interval-0s) Resource: rsc_vip_HA1_00 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=32 ip=10.128.15.100 nic=eth0 Operations: monitor interval=3600s timeout=60s (rsc_vip_HA1_00-monitor-interval-3600s) start interval=0s timeout=20s (rsc_vip_HA1_00-start-interval-0s) stop interval=0s timeout=20s (rsc_vip_HA1_00-stop-interval-0s) Clone: SAPHanaTopology_HA1_00-clone Meta Attrs: clone-max=2 clone-node-max=1 interleave=true Resource: SAPHanaTopology_HA1_00 (class=ocf provider=heartbeat type=SAPHanaTopology) Attributes: InstanceNumber=00 SID=HA1 Operations: methods interval=0s timeout=5 (SAPHanaTopology_HA1_00-methods-interval-0s) monitor interval=10 timeout=600 (SAPHanaTopology_HA1_00-monitor-interval-10) reload interval=0s timeout=5 (SAPHanaTopology_HA1_00-reload-interval-0s) start interval=0s timeout=600 (SAPHanaTopology_HA1_00-start-interval-0s) stop interval=0s timeout=300 (SAPHanaTopology_HA1_00-stop-interval-0s) Clone: SAPHana_HA1_00-clone Meta Attrs: promotable=true Resource: SAPHana_HA1_00 (class=ocf provider=heartbeat type=SAPHana) Attributes: AUTOMATED_REGISTER=true DUPLICATE_PRIMARY_TIMEOUT=7200 InstanceNumber=00 PREFER_SITE_TAKEOVER=true SID=HA1 Meta Attrs: clone-max=2 clone-node-max=1 interleave=true notify=true Operations: demote interval=0s timeout=3600 (SAPHana_HA1_00-demote-interval-0s) methods interval=0s timeout=5 (SAPHana_HA1_00-methods-interval-0s) monitor interval=61 role=Slave timeout=700 (SAPHana_HA1_00-monitor-interval-61) monitor interval=59 role=Master timeout=700 (SAPHana_HA1_00-monitor-interval-59) promote interval=0s timeout=3600 (SAPHana_HA1_00-promote-interval-0s) reload interval=0s timeout=5 (SAPHana_HA1_00-reload-interval-0s) start interval=0s timeout=3600 (SAPHana_HA1_00-start-interval-0s) stop interval=0s timeout=3600 (SAPHana_HA1_00-stop-interval-0s) Stonith Devices: Resource: STONITH-example-rha-vm1 (class=stonith type=fence_gce) Attributes: pcmk_delay_max=30 pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm1 project=sap-certification-env zone=us-central1-a Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm1-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm1-start-interval-0) Resource: STONITH-example-rha-vm2 (class=stonith type=fence_gce) Attributes: pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm2 project=sap-certification-env zone=us-central1-c Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm2-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm2-start-interval-0) Fencing Levels: Location Constraints: Resource: STONITH-example-rha-vm1 Disabled on: example-rha-vm1 (score:-INFINITY) (id:location-STONITH-example-rha-vm1-example-rha-vm1--INFINITY) Resource: STONITH-example-rha-vm2 Disabled on: example-rha-vm2 (score:-INFINITY) (id:location-STONITH-example-rha-vm2-example-rha-vm2--INFINITY) Ordering Constraints: start SAPHanaTopology_HA1_00-clone then start SAPHana_HA1_00-clone (kind:Mandatory) (non-symmetrical) (id:order-SAPHanaTopology_HA1_00-clone-SAPHana_HA1_00-clone-mandatory) Colocation Constraints: g-primary with SAPHana_HA1_00-clone (score:4000) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-g-primary-SAPHana_HA1_00-clone-4000) Ticket Constraints: Alerts: No alerts defined Resources Defaults: migration-threshold=5000 resource-stickiness=1000 Operations Defaults: timeout=600s Cluster Properties: cluster-infrastructure: corosync cluster-name: hacluster dc-version: 2.0.2-3.el8_1.2-744a30d655 have-watchdog: false stonith-enabled: true stonith-timeout: 300s Quorum: Options:Rufen Sie die Clusterkonfigurationsdatei
corosync.confauf:cat /etc/corosync/corosync.conf
Das folgende Beispiel zeigt die Parameter, die die Automatisierungsskripts für RHEL 8.1 und höher festgelegt haben.
Wenn Sie RHEL 7.7 oder früher verwenden, ist der Wert von
transport:udpu, nichtknet:totem { version: 2 cluster_name: hacluster transport: knet join: 60 max_messages: 20 token: 20000 token_retransmits_before_loss_const: 10 crypto_cipher: aes256 crypto_hash: sha256 } nodelist { node { ring0_addr: example-rha-vm1 name: example-rha-vm1 nodeid: 1 } node { ring0_addr: example-rha-vm2 name: example-rha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum two_node: 1 } logging { to_logfile: yes logfile: /var/log/cluster/corosync.log to_syslog: yes timestamp: on }
SLES
Rufen Sie die Clusterressourcenkonfigurationen auf:
crm config show
Die in dieser Anleitung verwendeten Automatisierungsskripts erstellen die Ressourcenkonfigurationen, die im folgenden Beispiel gezeigt werden:
node 1: example-ha-vm1 \ attributes hana_ha1_op_mode=logreplay lpa_ha1_lpt=1635380335 hana_ha1_srmode=syncmem hana_ha1_vhost=example-ha-vm1 hana_ha1_remoteHost=example-ha-vm2 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes lpa_ha1_lpt=30 hana_ha1_op_mode=logreplay hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 hana_ha1_srmode=syncmem hana_ha1_remoteHost=example-ha-vm1 primitive STONITH-example-ha-vm1 stonith:external/gcpstonith \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params instance_name=example-ha-vm1 gcloud_path="/usr/bin/gcloud" logging=yes pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 stonith:external/gcpstonith \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params instance_name=example-ha-vm2 gcloud_path="/usr/bin/gcloud" logging=yes pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHana \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Master timeout=700 \ op monitor interval=61 role=Slave timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary ms msl_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta notify=true clone-max=2 clone-node-max=1 target-role=Started interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 target-role=Started interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started msl_SAPHana_HA1_HDB00:Master order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 msl_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600Rufen Sie die Clusterkonfigurationsdatei
corosync.confauf:cat /etc/corosync/corosync.conf
Die in dieser Anleitung verwendeten Automatisierungsskripts geben Parametereinstellungen in der Datei
corosync.confan, wie im folgenden Beispiel gezeigt:totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
Load-Balancer und Zustand der Instanzgruppen prüfen
Prüfen Sie den Load Balancer und die Instanzgruppen in der Google Cloud Console, um festzustellen, ob der Load Balancer und die Systemdiagnose ordnungsgemäß eingerichtet wurden.
Öffnen Sie die Seite Load Balancing in der Google Cloud Console:
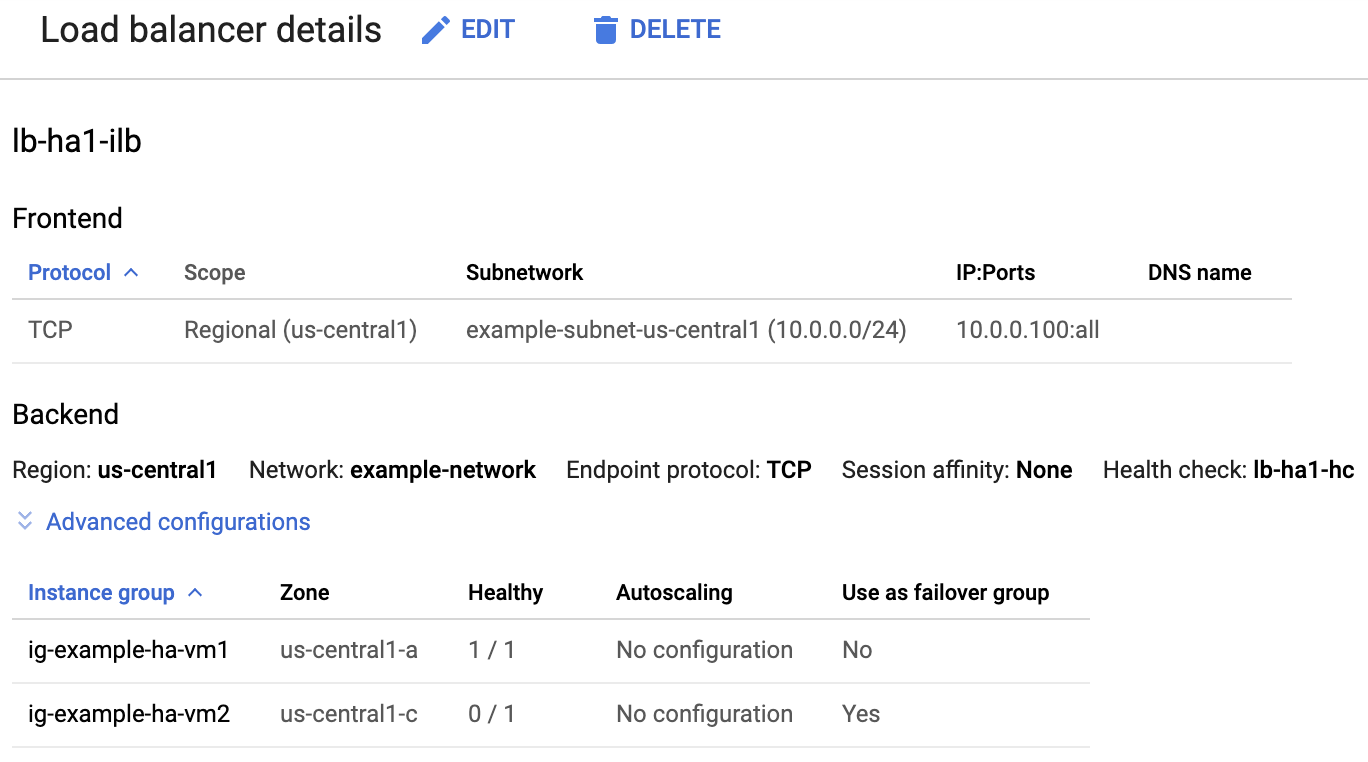
Prüfen Sie in der Liste der Load-Balancer, ob ein Load-Balancer für Ihren HA-Cluster erstellt wurde.
Prüfen Sie auf der Seite Details zum Load-Balancer in der Spalte Fehlerfrei unter Instanzgruppe im Abschnitt Backend, ob eine der Instanzgruppen „1/1“ und die andere „0/1“ anzeigt. Nach einem Failover wechselt die fehlerfreie Anzeige „1/1“ zur neuen aktiven Instanzgruppe.
SAP HANA-System mit SAP HANA Studio prüfen
Sie können SAP HANA Cockpit oder SAP HANA Studio verwenden, um SAP HANA-Systeme in Hochverfügbarkeitsclustern zu überwachen und zu verwalten.
Stellen Sie mit SAP HANA Studio eine Verbindung zum HANA-System her. Geben Sie beim Definieren der Verbindung die folgenden Werte an:
- Geben Sie im Bereich "Specify System" (System angeben) als Hostnamen die Floating-IP-Adresse an.
- Geben Sie im Bereich "Connection Properties" (Verbindungsattribute) für die Authentifizierung des Datenbanknutzers den Namen des Datenbank-Supernutzers und das Passwort an, den bzw. das Sie in der Datei "template.yaml" für das Attribut sap_hana_system_password festgelegt haben.
Informationen von SAP zur Installation von SAP HANA Studio finden Sie in der Installations- und Aktualisierungsanleitung von SAP HANA Studio.
Nachdem SAP HANA Studio mit dem HANA-HA-System verbunden ist, rufen Sie die Systemübersicht auf. Doppelklicken Sie hierfür im linken Navigationsbereich auf den Systemnamen.
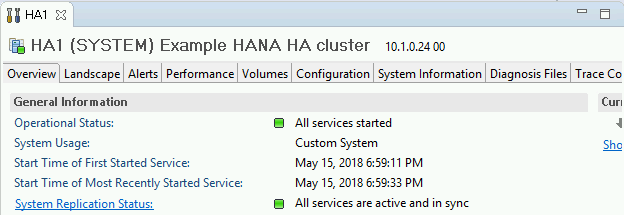
Prüfen Sie auf dem Tab "Overview" unter "General Information" Folgendes:
- Für den "Operational Status" (Betriebsstatus) wird "All services started" (Alle Dienste gestartet) angezeigt.
- Unter "System Replication Status" wird "All services are active and in sync" angezeigt.
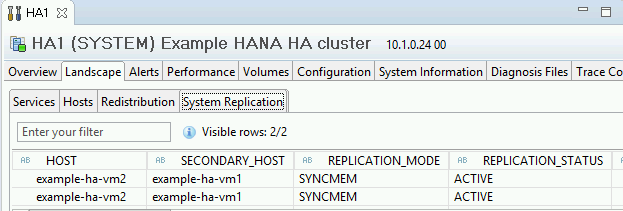
Klicken Sie zur Überprüfung des Replikationsmodus unter "General Information" (Allgemeine Informationen) auf den Link System Replication Status (Systemreplikationsstatus). Die synchrone Replikation wird von
SYNCMEMin der Spalte REPLICATION_MODE auf dem Tab "System Replication" (Systemreplikation) angegeben.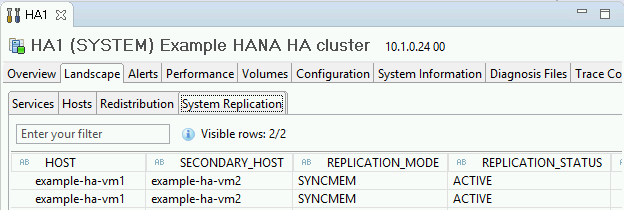
Wenn einer der Überprüfungsschritte auf eine fehlgeschlagene Installation hindeutet, gehen Sie so vor:
- Beheben Sie die Fehler.
- Löschen Sie die Bereitstellung auf der Seite Deployments.
- Erstellen Sie die Instanzen wie im letzten Schritt des vorherigen Abschnitts beschrieben neu.
Failover-Test durchführen
So führen Sie einen Failover-Test durch
Stellen Sie eine SSH-Verbindung zur primären VM her. Sie können hierfür wahlweise in Compute Engine auf der Seite mit den VM-Instanzen neben jeder VM-Instanz auf die Schaltfläche "SSH" klicken oder Ihre bevorzugte SSH-Methode verwenden.
Geben Sie bei der Eingabeaufforderung den folgenden Befehl ein:
sudo ip link set eth0 down
Der Befehl
ip link set eth0 downlöst ein Failover aus, da die Kommunikation mit dem primären Host unterbrochen wird.Stellen Sie eine SSH-Verbindung zu einem der Hosts her und wechseln Sie zum Root-Nutzer.
Bestätigen Sie, dass der primäre Host jetzt auf der VM aktiv ist, auf der sich zuvor der sekundäre Host befand. Da im Cluster der automatische Neustart aktiviert ist, wird der beendete Host neu gestartet und übernimmt dann die Rolle des sekundären Hosts.
RHEL
pcs statusSLES
crm statusDie folgenden Beispiele zeigen, dass die Rollen bei allen Hosts gewechselt wurden.
RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.3-4b1f869f0f) - partition with quorum * Last updated: Fri Mar 19 21:22:07 2021 * Last change: Fri Mar 19 21:21:28 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Thu Jul 8 17:33:44 2021 * Last change: Thu Jul 8 17:33:07 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:external/gcpstonith): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:external/gcpstonith): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]Prüfen Sie auf der Seite Details zum Load-Balancer, ob in der Spalte Healthy für die neue aktive primäre Instanz der Wert „1/1“ angezeigt wird. Aktualisieren Sie gegebenenfalls die Seite.
Beispiel:

Überprüfen Sie in SAP HANA Studio, ob die Systemverbindung noch immer besteht. Klicken Sie hierfür im Navigationsbereich doppelt auf den Systemeintrag, um die Systeminformationen zu aktualisieren.
Klicken Sie auf den Link System Replication Status (Systemreplikationsstatus), um zu prüfen, ob der primäre und der sekundäre Host die VMs gewechselt haben und aktiv sind.
Installation des Google Cloud-Agents für SAP prüfen
Nachdem Sie eine VM bereitgestellt und Ihr SAP-System installiert haben, prüfen Sie, ob der Agent für SAP vonGoogle Cloudordnungsgemäß funktioniert.
Prüfen, ob der Agent für SAP von Google Cloudausgeführt wird
So prüfen Sie, ob der Agent ausgeführt wird:
Stellen Sie eine SSH-Verbindung zu Ihrer Compute Engine-Instanz her.
Führen Sie dazu diesen Befehl aus:
systemctl status google-cloud-sap-agent
Wenn der Agent ordnungsgemäß funktioniert, enthält die Ausgabe
active (running). Beispiel:google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
Wenn der Agent nicht ausgeführt wird, starten Sie den Agent neu.
Prüfen, ob der SAP-Host-Agent Messwerte empfängt
Führen Sie die folgenden Schritte aus, um zu prüfen, ob die Infrastrukturmesswerte vom Agent vonGoogle Cloudfür SAP erfasst und korrekt an den SAP-Host-Agent gesendet werden:
- Geben Sie in Ihrem SAP-System Transaktion
ST06ein. Kontrollieren Sie im Übersichtsbereich die Verfügbarkeit und den Inhalt der folgenden Felder, um die korrekte End-to-End-Einrichtung der SAP- und Google-Monitoring-Infrastruktur zu überprüfen:
- Cloud-Anbieter:
Google Cloud Platform - Zugriff für erweitertes Monitoring:
TRUE - Details für erweitertes Monitoring:
ACTIVE
- Cloud-Anbieter:
Monitoring für SAP HANA einrichten
Optional können Sie Ihre SAP HANA-Instanzen mit dem Agenten für SAP vonGoogle Cloudüberwachen. Ab Version 2.0 können Sie den Agent so konfigurieren, dass er die SAP HANA-Monitoring-Messwerte erfasst und an Cloud Monitoring sendet. Mit Cloud Monitoring lassen sich Dashboards erstellen, um diese Messwerte zu visualisieren, Benachrichtigungen anhand von Messwertschwellen einzurichten und vieles mehr.
Folgen Sie der Anleitung unter Hochverfügbarkeitskonfiguration für den Agent, um einen HA-Cluster mit dem Agent für SAP von Google Cloudzu überwachen.Weitere Informationen zur Erfassung von SAP HANA-Monitoring-Messwerten mit dem Agenten für SAP vonGoogle Cloudfinden Sie unter SAP HANA-Monitoring-Messwerte erfassen.
SAP HANA Fast Restart aktivieren
Google Cloud Wir empfehlen dringend, SAP HANA Fast Restart für jede Instanz von SAP HANA zu aktivieren, insbesondere bei größeren Instanzen. SAP HANA Fast Restart verkürzt die Neustartzeit, wenn SAP HANA beendet wird, das Betriebssystem jedoch weiter ausgeführt wird.
In der Konfiguration der von Google Cloud bereitgestellten Automatisierungsscripts unterstützen die Betriebssystem- und Kerneleinstellungen bereits SAP HANA Fast Restart.
Sie müssen das tmpfs-Dateisystem definieren und SAP HANA konfigurieren.
Zum Definieren des Dateisystems tmpfs und zum Konfigurieren von SAP HANA können Sie den manuellen Schritten folgen oder das vonGoogle Cloud bereitgestellte Automatisierungsskript verwenden, um SAP HANA Fast Restart zu aktivieren. Weitere Informationen finden Sie hier:
- Manuelle Schritte: SAP HANA Fast Restart aktivieren
- Automatisierte Schritte: SAP HANA Fast Restart aktivieren
Die Anleitungen für SAP HANA Fast Restart finden Sie in der Dokumentation zu SAP HANA Fast Restart.
Manuelle Schritte
tmpfs-Dateisystem konfigurieren
Nachdem die Host-VMs und die SAP HANA-Basissysteme erfolgreich bereitgestellt wurden, müssen Sie Verzeichnisse für die NUMA-Knoten im tmpfs-Dateisystem erstellen und bereitstellen.
NUMA-Topologie Ihrer VM anzeigen lassen
Bevor Sie das erforderliche tmpfs-Dateisystem zuordnen können, müssen Sie wissen, wie viele NUMA-Knoten Ihre VM hat. Geben Sie den folgenden Befehl ein, um die verfügbaren NUMA-Knoten auf einer Compute Engine-VM anzeigen zu lassen:
lscpu | grep NUMA
Der VM-Typ m2-ultramem-208 hat beispielsweise vier NUMA-Knoten mit der Nummerierung 0–3, wie im folgenden Beispiel gezeigt:
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
NUMA-Knotenverzeichnisse erstellen
Erstellen Sie ein Verzeichnis für jeden NUMA-Knoten in Ihrer VM und legen Sie die Berechtigungen fest.
Beispiel für vier NUMA-Knoten mit der Nummerierung 0–3:
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDNUMA-Knotenverzeichnisse unter tmpfs bereitstellen
Stellen Sie die Verzeichnisse des tmpfs-Dateisystems bereit und geben Sie für mpol=prefer jeweils eine NUMA-Knoteneinstellung an:
SID: Geben Sie die SID in Großbuchstaben an.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
/etc/fstab aktualisieren
Fügen Sie der Dateisystemtabelle /etc/fstab Einträge hinzu, damit die Bereitstellungspunkte nach dem Neustart eines Betriebssystems verfügbar sind:
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
Optional: Limits für die Speichernutzung festlegen
Das tmpfs-Dateisystem kann dynamisch wachsen und schrumpfen.
Wenn Sie den vom tmpfs-Dateisystem verwendeten Speicher begrenzen möchten, können Sie mit der Option size eine Größenbeschränkung für ein NUMA-Knoten-Volume festlegen.
Beispiel:
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
Sie können auch die tmpfs-Speichernutzung für alle NUMA-Knoten für eine bestimmte SAP-HANA-Instanz und einen bestimmten Serverknoten begrenzen, indem Sie den Parameter persistent_memory_global_allocation_limit im Abschnitt [memorymanager] der Datei global.ini festlegen.
SAP HANA-Konfiguration für Fast Restart
Um SAP HANA für Fast Restart zu konfigurieren, aktualisieren Sie die Datei global.ini und geben Sie die Tabellen an, die im nichtflüchtigen Speicher gespeichert werden sollen.
Aktualisieren Sie den Abschnitt [persistence] in der Datei global.ini.
Konfigurieren Sie den Abschnitt [persistence] in der SAP HANA-Datei global.ini, um auf die tmpfs-Standorte zu verweisen. Trennen Sie die einzelnen tmpfs-Standorte durch ein Semikolon:
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
Im vorherigen Beispiel werden vier Arbeitsspeicher-Volumes für vier NUMA-Knoten angegeben, die m2-ultramem-208 entspricht. Bei der Ausführung auf m2-ultramem-416 müssten Sie acht Arbeitsspeicher-Volumes (0..7) konfigurieren.
Starten Sie SAP HANA neu, nachdem Sie die Datei global.ini geändert haben.
SAP HANA kann jetzt den Standort tmpfs als nichtflüchtigen Speicherbereich verwenden.
Tabellen angeben, die im nichtflüchtigen Speicher gespeichert werden sollen
Geben Sie bestimmte Spaltentabellen oder Partitionen an, die im nichtflüchtigen Speicher gespeichert werden sollen.
Wenn Sie beispielsweise nichtflüchtigen Speicher für eine vorhandene Tabelle aktivieren möchten, führen Sie diese SQL-Abfrage aus:
ALTER TABLE exampletable persistent memory ON immediate CASCADE
Um den Standardwert für neue Tabellen zu ändern, fügen Sie den Parameter table_default zur Datei indexserver.ini hinzu. Beispiel:
[persistent_memory] table_default = ON
Weitere Informationen zur Steuerung von Spalten, Tabellen und dazu, welche Monitoringansichten detaillierte Informationen enthalten, finden Sie unter Nichtflüchtiger SAP HANA-Speicher.
Automatisierte Schritte
Das von Google Cloud bereitgestellte Automatisierungsskript zum Aktivieren von SAP HANA Fast Restart nimmt Änderungen an den Verzeichnissen /hana/tmpfs*, der Datei /etc/fstab und der SAP HANA-Konfiguration vor. Wenn Sie das Script ausführen, müssen Sie möglicherweise zusätzliche Schritte ausführen, je nachdem, ob es sich um die anfängliche Bereitstellung Ihres SAP HANA-Systems handelt oder Sie die Größe Ihrer Maschine in eine andere NUMA-Größe ändern.
Achten Sie bei der ersten Bereitstellung Ihres SAP HANA-Systems oder bei der Größenanpassung der Maschine zur Erhöhung der Anzahl der NUMA-Knoten darauf, dass SAP HANA während der Ausführung des Automatisierungsskripts ausgeführt wird, das Google Cloudzur Aktivierung von SAP HANA Fast Restart bereitstellt.
Wenn Sie die Größe der Maschine ändern, um die Anzahl der NUMA-Knoten zu verringern, müssen Sie darauf achten, dass SAP HANA während der Ausführung des Automatisierungsskripts gestoppt wird, das Google Cloud zur Aktivierung von SAP HANA Fast Restart bereitstellt. Nachdem das Script ausgeführt wurde, müssen Sie die SAP HANA-Konfiguration manuell aktualisieren, um die Einrichtung von SAP HANA Fast Restart abzuschließen. Weitere Informationen finden Sie unter SAP HANA-Konfiguration für Fast Restart.
So aktivieren Sie SAP HANA Fast Restart:
Stellen Sie eine SSH-Verbindung zu Ihrer Host-VM her.
Wechseln Sie zum Root:
sudo su -
Laden Sie das
sap_lib_hdbfr.sh-Skript herunter:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
Machen Sie die Datei ausführbar:
chmod +x sap_lib_hdbfr.sh
Prüfen Sie, ob das Script Fehler enthält:
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
Wenn der Befehl einen Fehler zurückgibt, wenden Sie sich an Cloud Customer Care. Weitere Informationen zur Kontaktaufnahme mit Customer Care finden Sie unter Support für SAP in Google Cloud.
Führen Sie das Script aus, nachdem Sie die SAP HANA-System-ID (SID) und das Passwort für den SYSTEM-Nutzer der SAP HANA-Datenbank ersetzt haben. Damit Sie das Passwort sicher bereitstellen können, empfehlen wir die Verwendung eines Secrets in Secret Manager.
Führen Sie das Script mit dem Namen eines Secrets in Secret Manager aus. Dieses Secret muss in dem Google Cloud Projekt vorhanden sein, das Ihre Host-VM-Instanz enthält.
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
Ersetzen Sie Folgendes:
SID: Geben Sie die SID in Großbuchstaben an. Beispiel:AHA.SECRET_NAME: Geben Sie den Namen des Secrets an, das dem Passwort für den SYSTEM-Nutzer der SAP HANA-Datenbank entspricht. Dieses Secret muss in dem Google Cloud Projekt vorhanden sein, das Ihre Host-VM-Instanz enthält.
Alternativ können Sie das Script mit einem Nur-Text-Passwort ausführen. Nachdem SAP HANA Fast Restart aktiviert wurde, müssen Sie Ihr Passwort ändern. Die Verwendung eines Nur-Text-Passworts wird nicht empfohlen, da Ihr Passwort im Befehlszeilenverlauf Ihrer VM aufgezeichnet werden würde.
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
Ersetzen Sie Folgendes:
SID: Geben Sie die SID in Großbuchstaben an. Beispiel:AHA.PASSWORD: Geben Sie das Passwort für den SYSTEM-Nutzer der SAP HANA-Datenbank an.
Bei einer erfolgreichen ersten Ausführung sollte die Ausgabe in etwa so aussehen:
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
Google Monitoring-Agent für SAP HANA einrichten
Optional können Sie den Google Monitoring-Agent für SAP HANA einrichten, der Messwerte aus SAP HANA erfasst und an Monitoring sendet. Mit Monitoring lassen sich Dashboards für Ihre Messwerte erstellen, benutzerdefinierte Benachrichtigungen anhand von Messwertschwellen einrichten und vieles mehr.
Zum Überwachen eines Hochverfügbarkeitsclusters installieren Sie den Monitoring-Agent auf einer VM-Instanz außerhalb des Clusters. Geben Sie die Floating-IP-Adresse des Clusters als die IP-Adresse der zu überwachenden Hostinstanz an.
Weitere Informationen zum Einrichten und Konfigurieren des Google Monitoring-Agents für SAP HANA finden Sie im Nutzerhandbuch für SAP HANA – Monitoring-Agent.
Mit SAP HANA verbinden
Da in dieser Anleitung keine externe IP-Adresse für SAP HANA verwendet wird, können Sie nur über die Bastion-Instanz mit SSH oder über den Windows-Server mit SAP HANA Studio eine Verbindung zu den SAP HANA-Instanzen herstellen.
Wenn Sie die Verbindung zu SAP HANA über die Bastion-Instanz herstellen möchten, stellen Sie zuerst über einen SSH-Client Ihrer Wahl eine Verbindung zum Bastion Host und anschließend zu den SAP HANA-Instanzen her.
Zum Herstellen einer Verbindung mit der SAP HANA-Datenbank über SAP HANA Studio verwenden Sie einen Remote-Desktop-Client, um eine Verbindung zur Windows Server-Instanz herzustellen. Nach dem Verbindungsaufbau installieren Sie SAP HANA Studio manuell und greifen auf Ihre SAP HANA-Datenbank zu.
HANA Aktiv/Aktiv konfigurieren (Lesezugriff aktiviert)
Ab SAP HANA 2.0 SPS1 können Sie HANA Aktiv/Aktiv (Lesezugriff aktiviert) in einem Pacemaker-Cluster konfigurieren. Weitere Informationen finden Sie unter:
- HANA Aktiv/Aktiv (Lesezugriff aktiviert) in einem SUSE Pacemaker-Cluster konfigurieren
- HANA Aktiv/Aktiv (Lesezugriff aktiviert) in einem Red Hat Pacemaker-Cluster konfigurieren
Aufgaben nach dem Deployment ausführen
Bevor Sie Ihre SAP HANA-Instanz verwenden, sollten Sie nach der Bereitstellung diese Schritte ausführen: Weitere Informationen finden Sie in der Installations- und Aktualisierungsanleitung für SAP HANA.
Ändern Sie die temporären Passwörter für den SAP HANA-Systemadministrator und den Datenbank-Superuser.
Aktualisieren Sie die SAP HANA-Software mit den neuesten Patches.
Installieren Sie ggf. zusätzliche Komponenten wie AFLs (Application Function Libraries) oder SDA (Smart Data Access).
Konfigurieren und sichern Sie Ihre neue SAP HANA-Datenbank. Weitere Informationen finden Sie in der Betriebsanleitung für SAP HANA.
Weitere Informationen
- Weitere Informationen zu VM-Verwaltung und VM-Monitoring finden Sie in der Betriebsanleitung für SAP HANA.