在 BigQuery Studio 筆記本中執行 PySpark 程式碼
本文說明如何在 BigQuery Python 筆記本中執行 PySpark 程式碼。
事前準備
請建立 Google Cloud 專案和 Cloud Storage bucket。
設定專案
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 如果沒有可用的 Cloud Storage bucket,請在專案中建立一個。
設定筆記本
- 筆記本憑證:根據預設,筆記本工作階段會使用您的使用者憑證。或者,也可以使用工作階段服務帳戶憑證。
- 使用者憑證:您的使用者帳戶必須具備下列 Identity and Access Management 角色:
- Dataproc 編輯者 (
roles/dataproc.editor角色) - BigQuery Studio 使用者 (
roles/bigquery.studioUser角色) - 工作階段服務帳戶的服務帳戶使用者 (roles/iam.serviceAccountUser) 角色。這個角色包含模擬服務帳戶所需的
iam.serviceAccounts.actAs權限。
- Dataproc 編輯者 (
- 服務帳戶憑證:如要為筆記本工作階段指定服務帳戶憑證,而非使用者憑證,工作階段服務帳戶必須具備下列角色:
- 使用者憑證:您的使用者帳戶必須具備下列 Identity and Access Management 角色:
- 筆記本執行階段:除非您選取其他執行階段,否則筆記本會使用預設的 Vertex AI 執行階段。如要自行定義執行階段,請在 Google Cloud 控制台的「執行階段」頁面建立執行階段。注意,使用 NumPy 程式庫時,請在筆記本執行階段使用 Spark 3.5 支援的 NumPy 1.26 版。
- 筆記本憑證:根據預設,筆記本工作階段會使用您的使用者憑證。或者,也可以使用工作階段服務帳戶憑證。
前往 Google Cloud 控制台的「BigQuery」頁面。
在詳細資料窗格的分頁列中,按一下「+」符號旁的箭頭 ,然後按一下「記事本」。
- 在筆記本中設定及建立單一工作階段。
- 在互動式工作階段範本中設定 Spark 工作階段,然後使用範本在筆記本中設定及建立工作階段。BigQuery 提供
Query using Spark功能,可協助您開始編寫範本化工作階段的程式碼,如「範本化 Spark 工作階段」分頁標籤所述。 在編輯器窗格的分頁列中,按一下「+」符號旁的向下箭頭,然後點選「筆記本」。
在筆記本儲存格中複製並執行下列程式碼,即可設定及建立基本 Spark 工作階段。
- APP_NAME:工作階段的選用名稱。
- 選用工作階段設定:您可以新增 Dataproc API
Session設定,自訂工作階段。以下舉幾個例子說明:RuntimeConfig: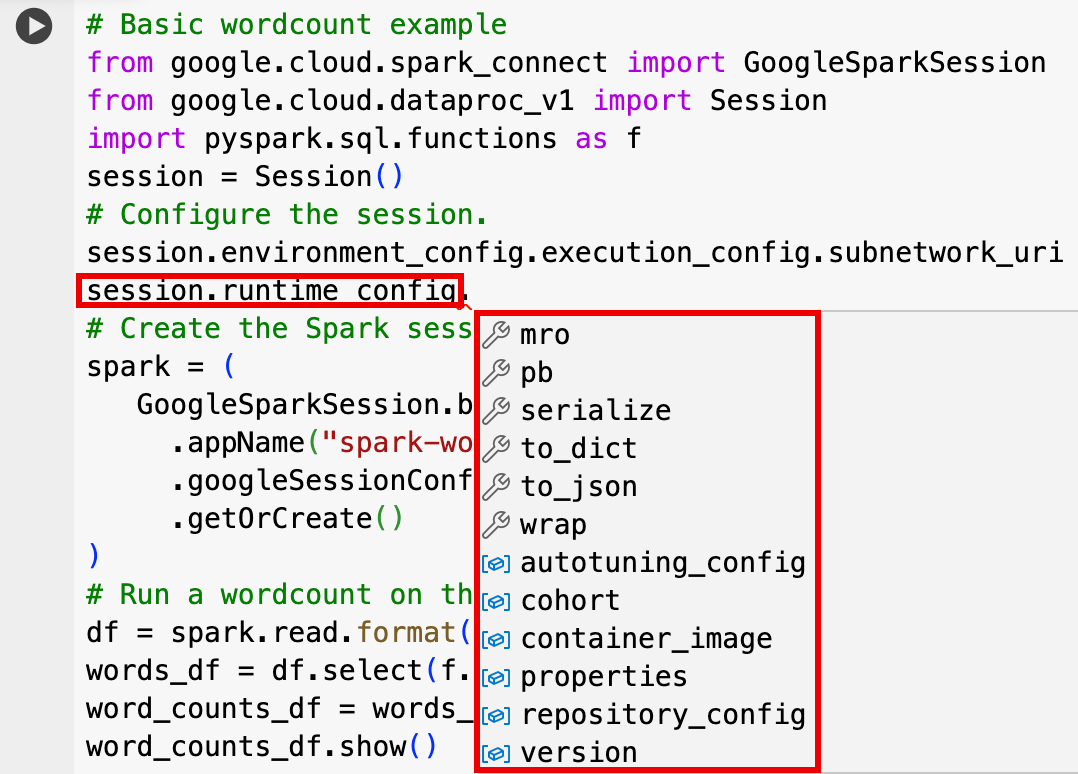
session.runtime_config.properties={spark.property.key1:VALUE_1,...,spark.property.keyN:VALUE_N}session.runtime_config.container_image = path/to/container/image
EnvironmentConfig: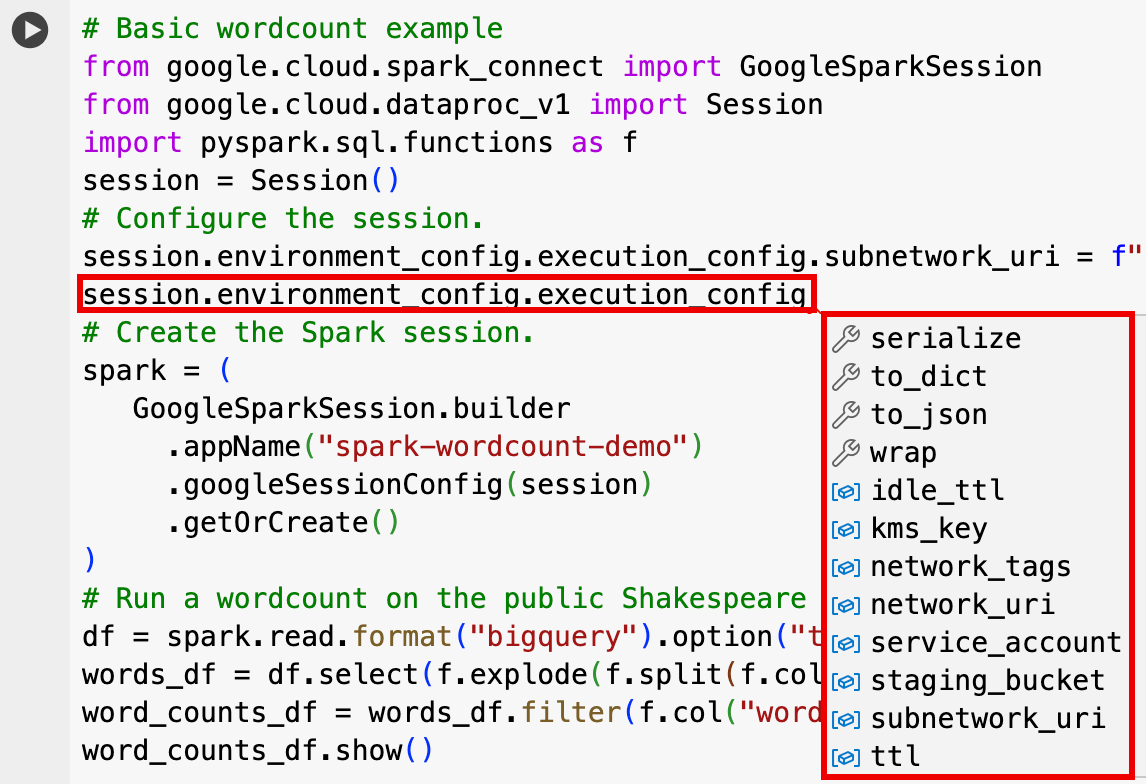
- session.environment_config.execution_config.subnetwork_uri = "SUBNET_NAME"
session.environment_config.execution_config.ttl = {"seconds": VALUE}session.environment_config.execution_config.service_account = SERVICE_ACCOUNT
- 在編輯器窗格的分頁列中,按一下「+」符號旁的向下箭頭 ,然後點選「筆記本」。
- 在「從範本開始」下方,按一下「使用 Spark 查詢」,然後點選「使用範本」,將程式碼插入筆記本。
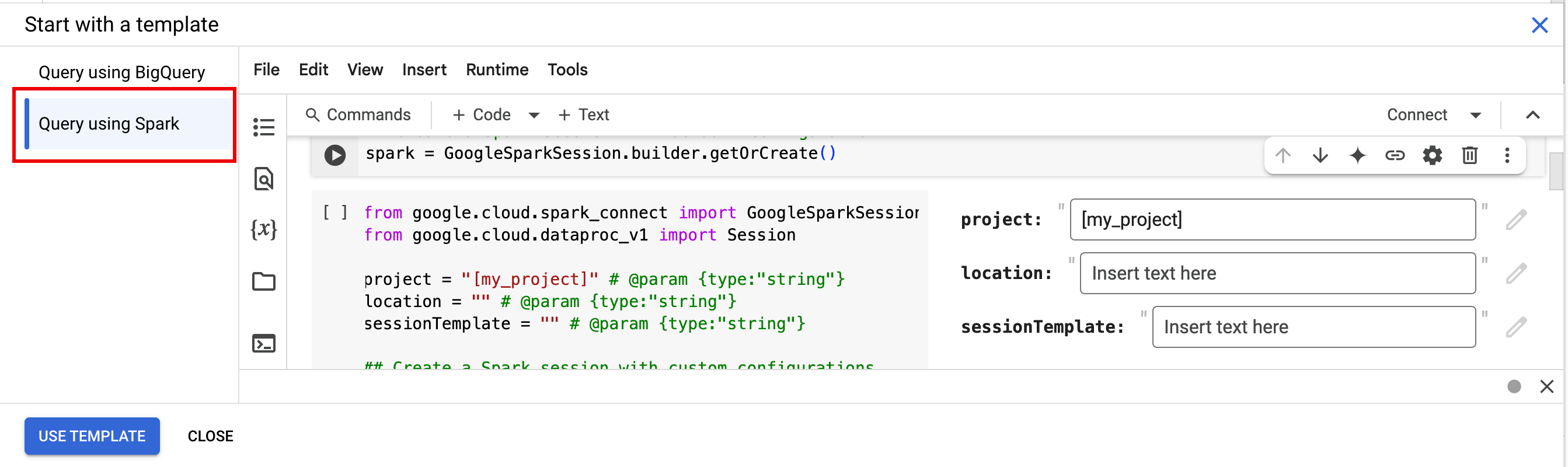
- 請按照「附註」一節的說明指定變數。
- 您可以刪除筆記本中插入的任何額外範例程式碼儲存格。
- PROJECT:您的專案 ID,列於Google Cloud 控制台資訊主頁的「專案資訊」部分。
- LOCATION:筆記本工作階段執行的 Compute Engine 區域。如未提供,預設位置是建立筆記本的 VM 所在區域。
SESSION_TEMPLATE:現有互動式工作階段範本的名稱。 系統會從範本取得工作階段設定。 範本也必須指定下列設定:
- 執行階段版本
2.3+ 筆記本類型:
Spark Connect範例:
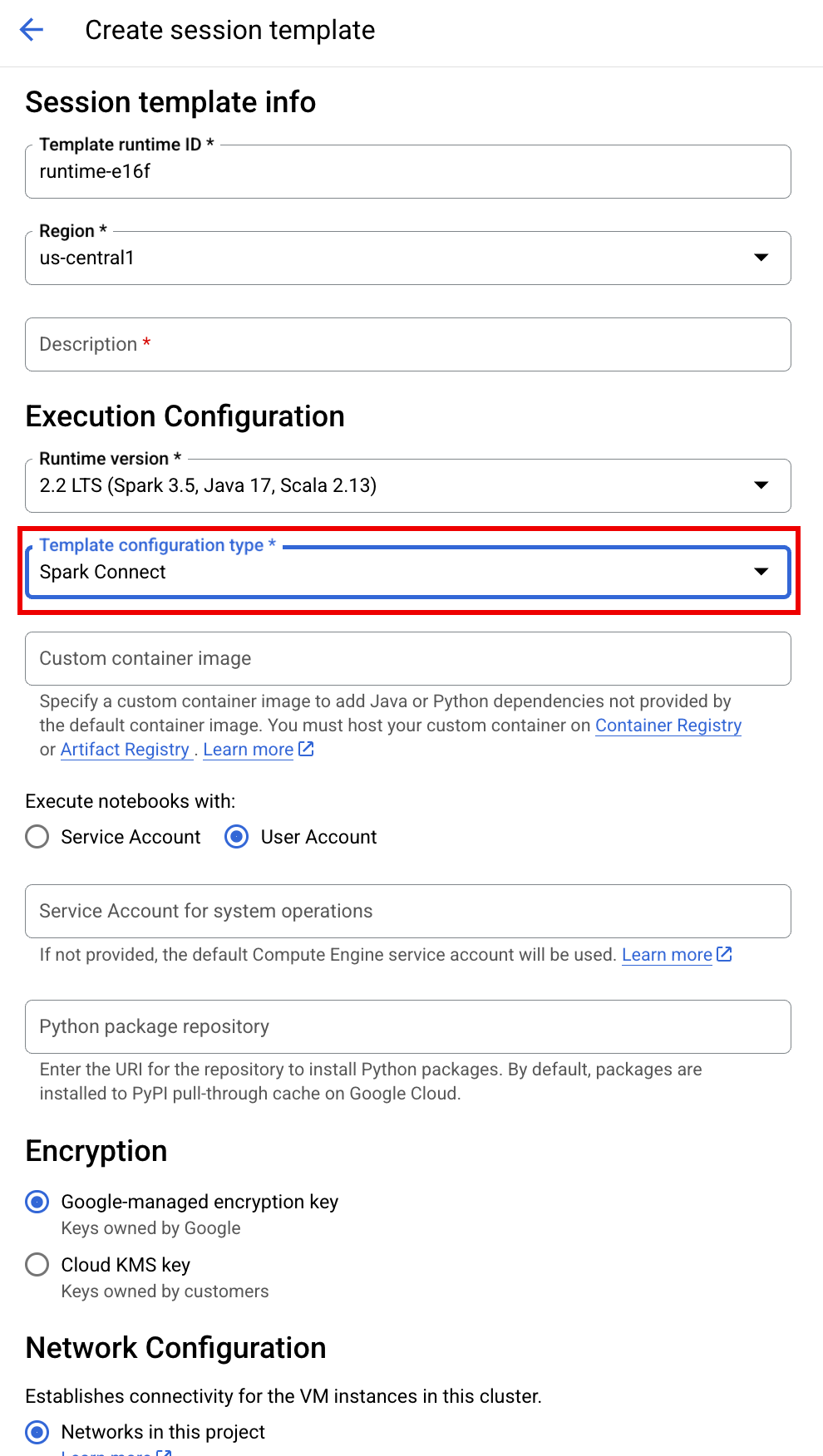
- 執行階段版本
APP_NAME:工作階段的選用名稱。
- 對莎士比亞公開資料集執行字詞計算。
- 建立 Iceberg 資料表,並將中繼資料儲存在 BigLake metastore 中。
- APP_NAME:工作階段的選用名稱。
- PROJECT:您的專案 ID,列於Google Cloud 控制台資訊主頁的「專案資訊」部分。
- REGION 和 SUBNET_NAME:指定 Compute Engine 地區,以及工作階段地區中的子網路名稱。Serverless for Apache Spark 會在指定的子網路上啟用私人 Google 存取權 (PGA)。
- LOCATION:預設值為
US,但您可以選擇任何支援的 BigQuery 位置。BigQuery_metastore_config.locationspark.sql.catalog.{catalog}.gcp_location - BUCKET 和 WAREHOUSE_DIRECTORY:用於 Iceberg 倉庫目錄的 Cloud Storage 值區和資料夾。
- CATALOG_NAME 和 NAMESPACE:Iceberg 目錄名稱和命名空間會合併,用於識別 Iceberg 資料表 (
catalog.namespace.table_name)。 - APP_NAME:工作階段的選用名稱。
前往 Google Cloud 控制台的「BigQuery」頁面。
在專案資源窗格中,按一下專案,然後按一下命名空間,列出
sample_iceberg_table資料表。按一下「詳細資料」資料表,即可查看「開啟目錄資料表設定」資訊。輸入和輸出格式是 Iceberg 使用的標準 Hadoop
InputFormat和OutputFormat類別格式。
按一下工具列中的「+ 程式碼」,插入新的程式碼儲存格。 新的程式碼儲存格會顯示
Start coding or generate with AI。 點選「生成」。在「生成」編輯器中輸入自然語言提示,然後按一下
enter。請務必在提示中加入spark或pyspark關鍵字。提示範例:
create a spark dataframe from order_items and filter to orders created in 2024
輸出內容範例:
spark.read.format("bigquery").option("table", "sqlgen-testing.pysparkeval_ecommerce.order_items").load().filter("year(created_at) = 2024").createOrReplaceTempView("order_items") df = spark.sql("SELECT * FROM order_items")為了讓 Gemini Code Assist 擷取相關的資料表和結構定義,請為 Dataproc Metastore 執行個體啟用 Data Catalog 同步處理功能。
請確保使用者帳戶可以存取 Data Catalog 的查詢資料表,做法是指派
DataCatalog.Viewer角色。- 在筆記本儲存格中執行
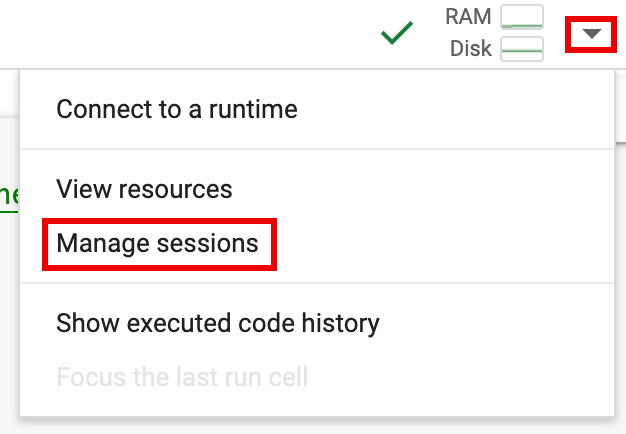
spark.stop()。 - 終止筆記本中的執行階段:
- 按一下執行階段選取器,然後按一下「管理工作階段」。
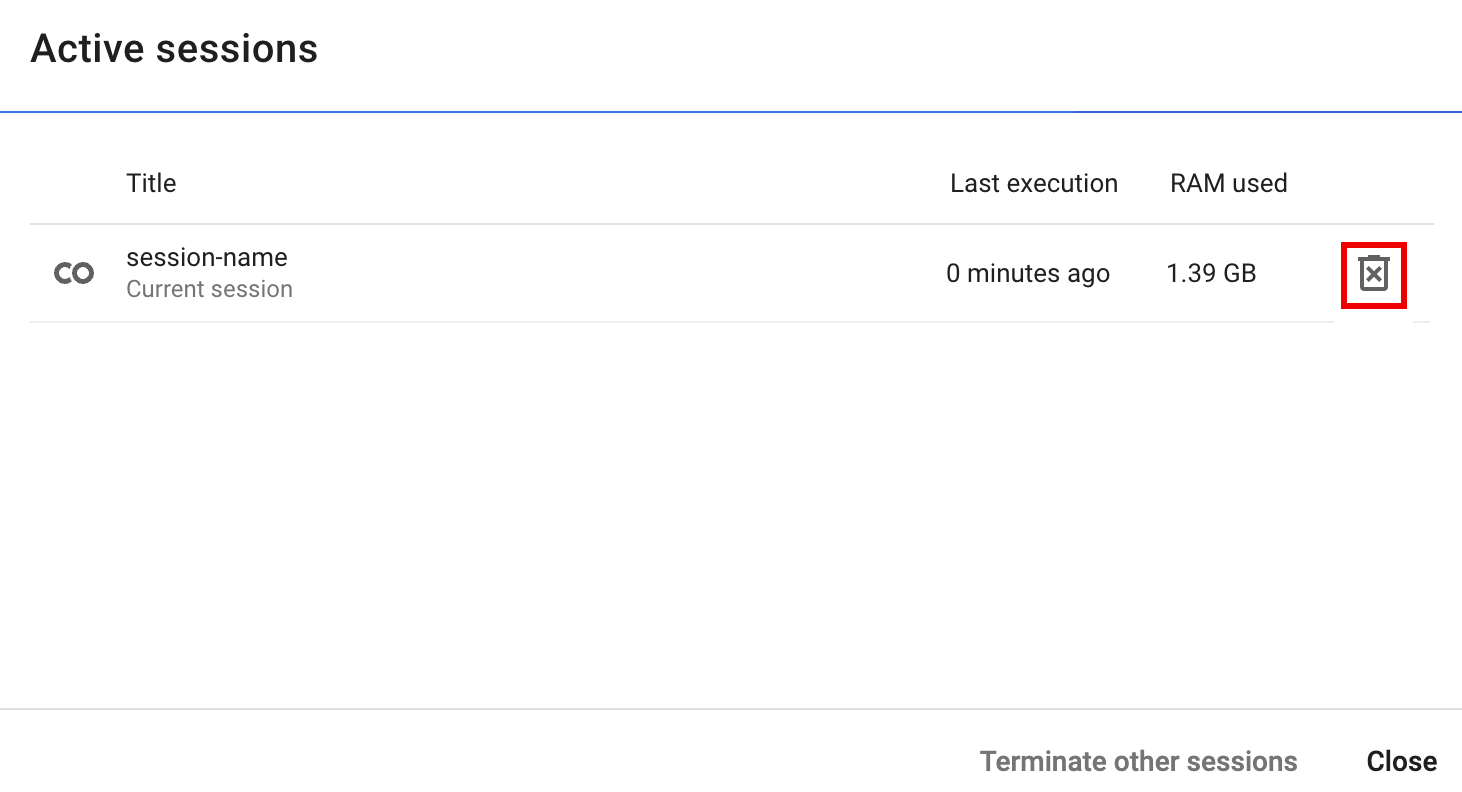
- 在「Active sessions」(有效工作階段) 對話方塊中,按一下終止圖示,然後點選「Terminate」(終止)。
- 按一下執行階段選取器,然後按一下「管理工作階段」。
從 Google Cloud 控制台排定筆記本程式碼 (適用筆記本價格)。
以批次工作負載形式執行筆記本程式碼 (適用 Serverless for Apache Spark 定價)。
將筆記本程式碼下載到本機終端機或 Cloud Shell 的檔案中。
在 Google Cloud 控制台的「BigQuery Studio」頁面上,開啟「Explorer」窗格中的筆記本。
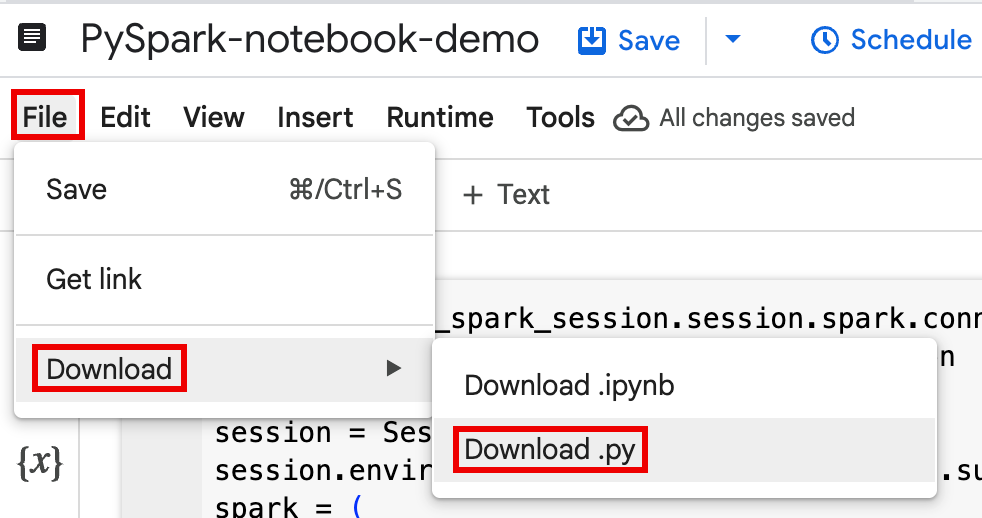
如要展開選單列,請按一下「keyboard_arrow_down」keyboard_arrow_down「切換標題顯示設定」。
依序點選「File」>「Download」,然後點選「Download.py」。
生成
requirements.txt。- 在儲存
.py檔案的目錄中安裝pipreqs。pip install pipreqs
執行
pipreqs即可生成requirements.txt。pipreqs filename.py
使用 Google Cloud CLI 將本機
requirements.txt檔案複製到 Cloud Storage 的 bucket。gcloud storage cp requirements.txt gs://BUCKET/
- 在儲存
編輯下載的
.py檔案,更新 Spark 工作階段程式碼。移除或註解排除任何 Shell 指令碼指令。
移除設定 Spark 工作階段的程式碼,然後將設定參數指定為批次工作負載提交參數。(請參閱「提交 Spark 批次工作負載」)。
範例:
從程式碼中移除下列工作階段子網路設定行:
session.environment_config.execution_config.subnetwork_uri = "{subnet_name}"執行批次工作負載時,請使用
--subnet旗標指定子網路。gcloud dataproc batches submit pyspark \ --subnet=SUBNET_NAME
使用簡單的工作階段建立程式碼片段。
簡化前下載的筆記本程式碼範例。
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session
session = Session() spark = DataprocSparkSession \ .builder \ .appName("CustomSparkSession") .dataprocSessionConfig(session) \ .getOrCreate()
簡化後的批次工作負載程式碼。
from pyspark.sql import SparkSession
spark = SparkSession \ .builder \ .getOrCreate()
-
如需操作說明,請參閱「提交 Spark 批次工作負載」。
請務必加入 --deps-bucket 標記,指向包含 Your
requirements.txt檔案的 Cloud Storage bucket。範例:
gcloud dataproc batches submit pyspark FILENAME.py \ --region=REGION \ --deps-bucket=BUCKET \ --version=2.3
注意:
- FILENAME:下載並編輯的筆記本程式碼檔案名稱。
- REGION:叢集所在的 Compute Engine 地區。
- BUCKET:包含
requirements.txt檔案的 Cloud Storage 值區名稱。 --version:選取 Spark 執行階段 2.3 版,執行批次工作負載。
提交程式碼。
- 測試批次工作負載程式碼後,您可以使用
git用戶端 (例如 GitHub、GitLab 或 Bitbucket) 將.ipynb或.py檔案提交至存放區,做為 CI/CD pipeline 的一部分。
- 測試批次工作負載程式碼後,您可以使用
使用 Cloud Composer 排定批次工作負載。
- YouTube 影片示範:善用與 BigQuery 整合的 Apache Spark 強大功能。
- 將 BigLake metastore 搭配 Dataproc 使用
- 搭配使用 BigLake Metastore 與 Serverless for Apache Spark
定價
如需價格資訊,請參閱 BigQuery Notebook 執行階段價格。
開啟 BigQuery Studio Python 筆記本
在 BigQuery Studio 筆記本中建立 Spark 工作階段
您可以使用 BigQuery Studio Python 筆記本建立 Spark Connect 互動式工作階段。每個 BigQuery Studio 筆記本只能有一個相關聯的有效 Spark 工作階段。
您可以在 BigQuery Studio Python 筆記本中,透過下列方式建立 Spark 工作階段:
單次
如要在新筆記本中建立 Spark 工作階段,請按照下列步驟操作:
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )更改下列內容:
範本 Spark 工作階段
您可以在筆記本儲存格中輸入及執行程式碼,根據現有的工作階段範本建立 Spark 工作階段。您在筆記本程式碼中提供的任何
session設定,都會覆寫在工作階段範本中設定的相同設定。如要快速上手,請使用
Query using Spark範本預先填入 Spark 工作階段範本程式碼至筆記本:from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Configure the session with an existing session template. session_template = "SESSION_TEMPLATE" session.session_template = f"projects/{project}/locations/{location}/sessionTemplates/{session_template}" # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )在 BigQuery Studio 筆記本中編寫及執行 PySpark 程式碼
在筆記本中建立 Spark 工作階段後,即可使用該工作階段在筆記本中執行 Spark 筆記本程式碼。
支援 Spark Connect PySpark API:Spark Connect 筆記本工作階段支援大多數 PySpark API,包括 DataFrame、Functions 和 Column,但不支援 SparkContext 和 RDD 等其他 PySpark API。詳情請參閱「Spark 3.5 支援的項目」。
Spark Connect 筆記本直接寫入:BigQuery Studio 筆記本中的 Spark 工作階段會預先設定 Spark BigQuery 連接器,以便直接寫入資料。DIRECT 寫入方法會使用 BigQuery Storage Write API,將資料直接寫入 BigQuery;INDIRECT 寫入方法 (適用於 Apache Spark 無伺服器批次作業的預設方法) 會將資料寫入中繼 Cloud Storage 值區,然後將資料寫入 BigQuery (如要進一步瞭解 INDIRECT 寫入,請參閱「在 BigQuery 中讀取和寫入資料」)。
Dataproc 專屬 API:Dataproc 擴充了
addArtifacts方法,可簡化將PyPI套件動態新增至 Spark 工作階段的程序。您可以採用version-scheme格式指定清單 (類似於pip install)。這會指示 Spark Connect 伺服器在所有叢集節點上安裝套件及其依附元件,讓工作站可將這些套件用於 UDF。以下範例會在叢集上安裝指定的
textdistance版本和最新相容的random2程式庫,讓使用textdistance和random2的 UDF 在工作節點上執行。spark.addArtifacts("textdistance==4.6.1", "random2", pypi=True)筆記本程式碼說明:在 BigQuery Studio 筆記本中,將指標懸停在類別或方法名稱上時,系統會提供程式碼說明;輸入程式碼時,系統會提供程式碼自動完成說明。
在以下範例中,輸入
DataprocSparkSession。並將指標懸停在這個類別名稱上,即可顯示程式碼完成和文件說明。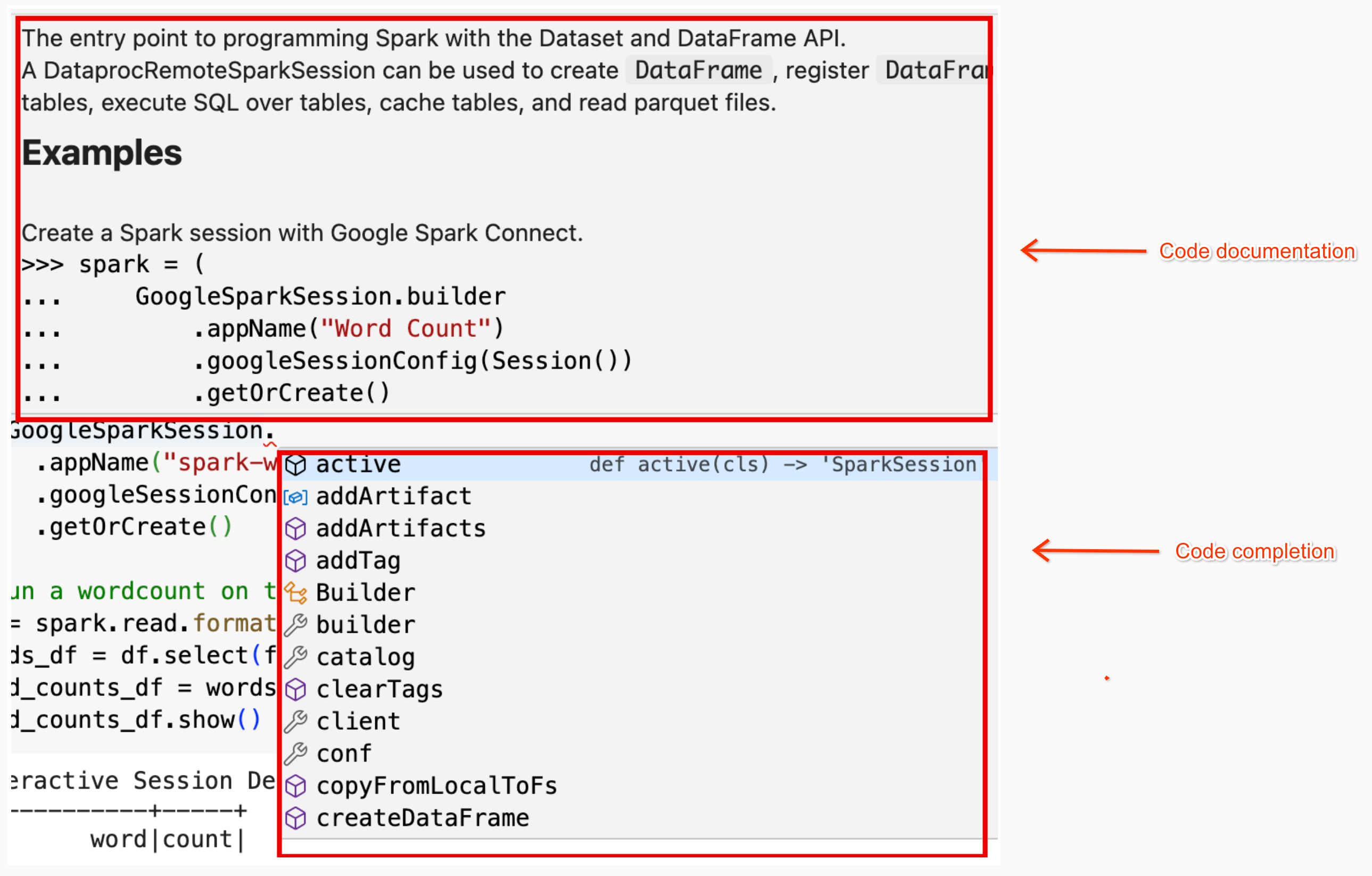
BigQuery Studio 筆記本 PySpark 範例
本節提供 BigQuery Studio Python 筆記本範例,其中包含 PySpark 程式碼,可執行下列工作:
Wordcount
下列 Pyspark 範例會建立 Spark 工作階段,然後計算公開
bigquery-public-data.samples.shakespeare資料集中出現的字詞次數。# Basic wordcount example from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Run a wordcount on the public Shakespeare dataset. df = spark.read.format("bigquery").option("table", "bigquery-public-data.samples.shakespeare").load() words_df = df.select(f.explode(f.split(f.col("word"), " ")).alias("word")) word_counts_df = words_df.filter(f.col("word") != "").groupBy("word").agg(f.count("*").alias("count")).orderBy("word") word_counts_df.show()更改下列內容:
輸出內容:
儲存格輸出內容會列出字數統計輸出內容的範例。如要在 Google Cloud 控制台中查看工作階段詳細資料,請按一下「Interactive Session Detail View」(互動式工作階段詳細資料檢視畫面) 連結。如要監控 Spark 工作階段,請在工作階段詳細資料頁面點選「View Spark UI」(查看 Spark UI)。

Interactive Session Detail View: LINK +------------+-----+ | word|count| +------------+-----+ | '| 42| | ''All| 1| | ''Among| 1| | ''And| 1| | ''But| 1| | ''Gamut'| 1| | ''How| 1| | ''Lo| 1| | ''Look| 1| | ''My| 1| | ''Now| 1| | ''O| 1| | ''Od's| 1| | ''The| 1| | ''Tis| 4| | ''When| 1| | ''tis| 1| | ''twas| 1| | 'A| 10| |'ARTEMIDORUS| 1| +------------+-----+ only showing top 20 rows
Iceberg 資料表
執行 PySpark 程式碼,使用 BigLake metastore 中繼資料建立 Iceberg 資料表
下列範例程式碼會建立
sample_iceberg_table,其中包含儲存在 BigLake Metastore 中的資料表中繼資料,然後查詢該資料表。from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f # Create the Dataproc Serverless session. session = Session() # Set the session configuration for BigLake Metastore with the Iceberg environment. project_id = "PROJECT" region = "REGION" subnet_name = "SUBNET_NAME" location = "LOCATION" session.environment_config.execution_config.subnetwork_uri = f"{subnet_name}" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY" catalog = "CATALOG_NAME" namespace = "NAMESPACE" session.runtime_config.properties[f"spark.sql.catalog.{catalog}"] = "org.apache.iceberg.spark.SparkCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.catalog-impl"] = "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_project"] = f"{project_id}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_location"] = f"{location}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.warehouse"] = f"{warehouse_dir}" # Create the Spark Connect session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Create the namespace in BigQuery. spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create the Iceberg table. spark.sql("DROP TABLE IF EXISTS `sample_iceberg_table`"); spark.sql("CREATE TABLE sample_iceberg_table (id int, data string) USING ICEBERG;") spark.sql("DESCRIBE sample_iceberg_table;") # Insert table data and query the table. spark.sql("INSERT INTO sample_iceberg_table VALUES (1, \"first row\");") # Alter table, then query and display table data and schema. spark.sql("ALTER TABLE sample_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE sample_iceberg_table;") df = spark.sql("SELECT * FROM sample_iceberg_table") df.show() df.printSchema()注意:
儲存格輸出內容會列出
sample_iceberg_table,並顯示 Google Cloud 控制台的「互動式工作階段詳細資料」頁面連結。您可以在工作階段詳細資料頁面中按一下「查看 Spark UI」,監控 Spark 工作階段。
Interactive Session Detail View: LINK +---+---------+------------+ | id| data|newDoubleCol| +---+---------+------------+ | 1|first row| NULL| +---+---------+------------+ root |-- id: integer (nullable = true) |-- data: string (nullable = true) |-- newDoubleCol: double (nullable = true)
在 BigQuery 中查看資料表詳細資料
如要在 BigQuery 中查看 Iceberg 資料表詳細資料,請按照下列步驟操作:
其他範例
從 Pandas DataFrame (
df) 建立 SparkDataFrame(sdf)。sdf = spark.createDataFrame(df) sdf.show()在 Spark
DataFrames上執行匯總作業。from pyspark.sql import functions as F sdf.groupby("segment").agg( F.mean("total_spend_per_user").alias("avg_order_value"), F.approx_count_distinct("user_id").alias("unique_customers") ).show()使用 Spark-BigQuery 連接器從 BigQuery 讀取資料。
spark.conf.set("viewsEnabled","true") spark.conf.set("materializationDataset","my-bigquery-dataset") sdf = spark.read.format('bigquery') \ .load(query)使用 Gemini Code Assist 撰寫 Spark 程式碼
您可以要求 Gemini Code Assist 在筆記本中生成 PySpark 程式碼。Gemini Code Assist 會擷取並使用相關的 BigQuery 和 Dataproc Metastore 資料表及其結構定義,生成程式碼回覆。
如要在筆記本中生成 Gemini Code Assist 程式碼,請按照下列步驟操作:
使用 Gemini Code Assist 生成程式碼的提示
結束問答時間
如要在 BigQuery Studio 筆記本中停止 Spark Connect 工作階段,可以採取下列任一動作:
協調 BigQuery Studio 筆記本程式碼
您可以透過下列方式協調 BigQuery Studio 筆記本程式碼:
透過 Google Cloud 控制台排定筆記本程式碼執行時間
您可以透過下列方式排定筆記本程式碼:
以批次工作負載的形式執行筆記本程式碼
請完成下列步驟,以批次工作負載的形式執行 BigQuery Studio 筆記本程式碼。
排解筆記本錯誤
如果含有 Spark 程式碼的儲存格發生失敗,您可以按一下儲存格輸出內容中的「互動式工作階段詳細資料檢視畫面」連結,排解錯誤 (請參閱「字數統計和 Iceberg 表格範例」)。
已知問題和解決方案
錯誤:使用 Python 版本
3.10建立的 Notebook 執行階段嘗試連線至 Spark 工作階段時,可能會導致PYTHON_VERSION_MISMATCH錯誤。解決方案:使用 Python 版本
3.11重新建立執行階段。後續步驟