创建数据集
本文档介绍如何在 BigQuery 中创建数据集。
您可以通过以下方式创建数据集:
- 使用 Google Cloud 控制台。
- 使用 SQL 查询。
- 在 bq 命令行工具中使用
bq mk命令。 - 调用
datasets.insertAPI 方法。 - 使用客户端库。
- 复制现有数据集。
如需查看复制数据集的步骤(包括跨区域复制),请参阅复制数据集。
本文档介绍如何使用在 BigQuery 中存储数据的常规数据集。如需了解如何使用 Spanner 外部数据集,请参阅创建 Spanner 外部数据集。如需了解如何使用 AWS Glue 联合数据集,请参阅创建 AWS Glue 联合数据集。
如需了解如何查询公共数据集中的表,请参阅使用 Google Cloud 控制台查询公共数据集。
数据集限制
BigQuery 数据集有以下限制:
- 数据集位置只能在创建时设置。创建数据集后,就无法再更改其位置。
- 查询中引用的所有表必须存储在位于同一位置的数据集中。
外部数据集不支持表到期、副本、时间旅行、默认排序规则、默认舍入模式,或用于启用或停用不区分大小写的表名称的选项。
复制表时,包含源表和目标表的数据集必须位于同一位置。
各个项目的数据集名称不得重复。
如果您更改了数据集的存储空间结算模式,则必须等待 14 天才能再次更改存储空间结算模式。
如果您的任何现有旧版固定费率槽承诺位于数据集所在的区域,则无法将数据集加入物理存储空间结算。
准备工作
授予为用户提供执行本文档中的每个任务所需权限的 Identity and Access Management (IAM) 角色。
所需权限
如需创建数据集,您需要拥有 bigquery.datasets.create IAM 权限。
以下每个预定义 IAM 角色都包含创建数据集所需的权限:
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
如需详细了解 BigQuery 中的 IAM 角色,请参阅预定义的角色和权限。
创建数据集
要创建数据集,请执行以下操作:
控制台
- 在 Google Cloud 控制台中打开 BigQuery 页面。 转到 BigQuery 页面
- 在探索器面板中,选择您要在其中创建数据集的项目。
- 展开 查看操作选项,然后点击创建数据集。
- 在创建数据集页面中执行以下操作:
- 在数据集 ID 字段中,输入唯一的数据集名称。
- 在位置类型字段中,为数据集选择一个地理位置。创建数据集后,就无法再更改此位置。
- 可选:如果您要创建外部数据集,请选择指向外部数据集的链接。
- 如果您不需要配置标记和表到期时间等其他选项,请点击创建数据集。否则,请展开即可下部分以配置其他数据集选项。
- 可选:展开标签部分,为数据集添加标记。
- 如需应用现有标记,请执行以下操作:
- 点击选择范围旁边的下拉箭头,然后选择当前范围 - 选择当前组织或选择当前项目。
- 对于键 1 和值 1,请从列表中选择适当的值。
- 如需手动输入新标记,请执行以下操作:
- 点击选择范围旁边的下拉箭头,然后选择手动输入 ID > 组织、项目或标记。
- 如果您要为项目或组织创建标记,请在对话框中输入
PROJECT_ID或ORGANIZATION_ID,然后点击保存。 - 对于键 1 和值 1,请从列表中选择适当的值。
- 如需向表中添加其他标记,请点击添加标记,然后按照上面的步骤操作。
- 可选:展开高级选项部分,以配置以下的一个或多个选项。
- 如需更改加密选项,以将您自己的加密密钥与 Cloud Key Management Service 搭配使用,请选择 Cloud KMS 密钥。
- 如需使用不区分大小写的表名称,请选择启用不区分大小写的表名称。
- 如需更改默认排序规则规范,请从列表中选择排序规则类型。
- 如需为数据集中的表设置过期时间,请选择启用表过期时间,然后指定默认表存在时间上限(以天为单位)。
- 如需设置默认舍入模式,请从列表中选择舍入模式。
- 如需启用物理存储空间结算模式,请从列表中选择相应的结算模式。
- 如需设置数据集的时间旅行窗口,请从列表中选择窗口大小。
- 点击创建数据集。
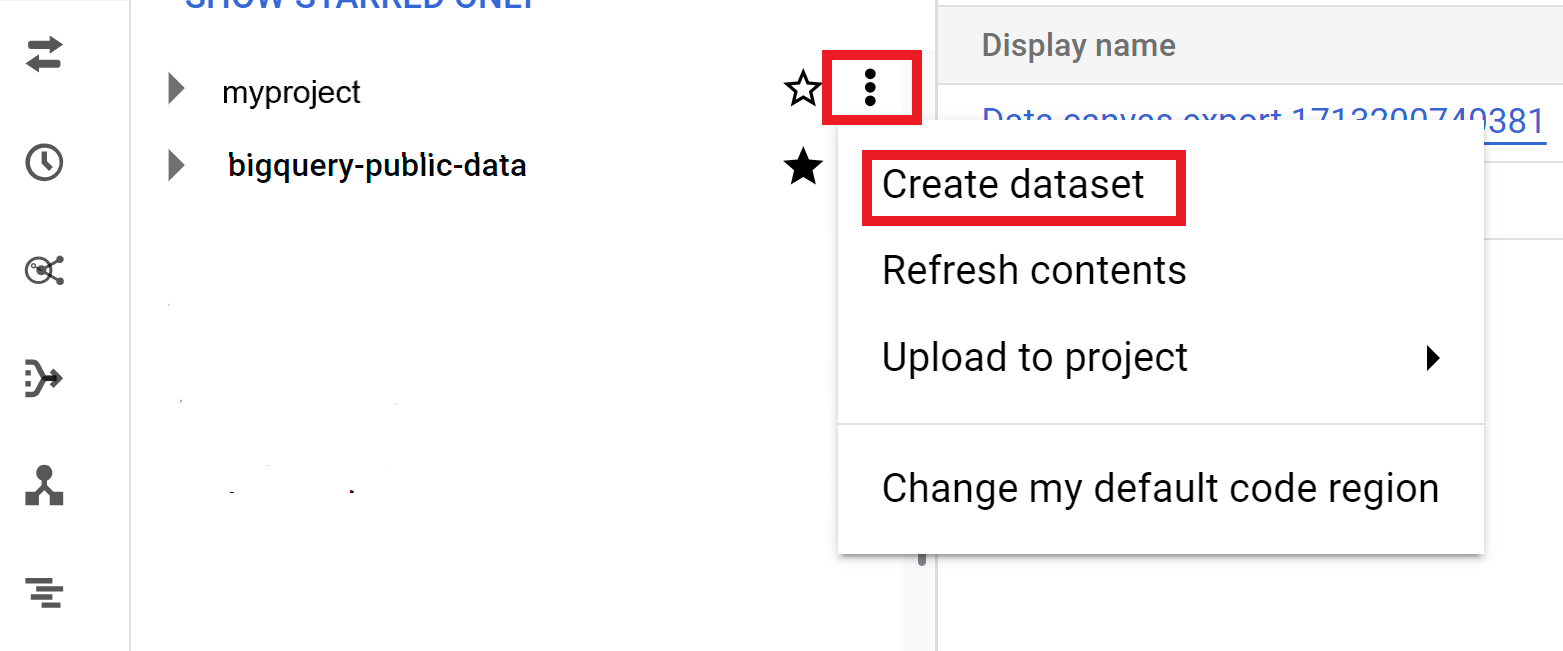
数据集的其他选项
或者,点击选择范围以搜索资源或查看当前资源列表。
更改数据集的结算模式后,更改需要 24 小时才能生效。
更改数据集的存储空间结算模式后,您必须等待 14 天才能再次更改存储空间结算模式。
SQL
使用 CREATE SCHEMA 语句。
如需在非默认项目中创建数据集,请按照以下格式将项目 ID 添加到数据集 ID:PROJECT_ID.DATASET_ID。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在查询编辑器中,输入以下语句:
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
替换以下内容:
PROJECT_ID:您的项目 IDDATASET_ID:您要创建的数据集的 IDKMS_KEY_NAME:默认 Cloud Key Management Service 密钥的名称,此密钥用于保护此数据集中新创建的表,除非在创建时提供了不同的密钥。您无法使用此参数集在数据集中创建 Google 加密表。PARTITION_EXPIRATION:新创建的分区表中的分区的默认生命周期(以天为单位)。默认分区到期时间没有最小值。到期时间以分区的日期加上这个整数值为准。在数据集分区表中创建的任何分区都会在自分区的日期起的PARTITION_EXPIRATION天后删除。如果在创建或更新分区表时提供time_partitioning_expiration选项,则表级分区到期时间优先于数据集级默认分区到期时间。TABLE_EXPIRATION:新创建的表的默认生命周期(以天为单位)。最小值为 0.042 天(一小时)。到期时间以当前时间加上这个整数值部分为准。在数据集中创建的任何表都会在自创建之时起的TABLE_EXPIRATION天后删除。如果您在创建表时未设置表到期时间,则系统会应用此值。DESCRIPTION:数据集的说明KEY_1:VALUE_1:您想要在此数据集上设置为第一个标签的键值对KEY_2:VALUE_2:您要设置为第二个标签的键值对LOCATION:数据集的位置。创建数据集后,此位置无法再更改。HOURS:新数据集的时间旅行窗口的时长(以小时为单位)。HOURS值必须是 48(2 天)到 168(7 天)之间以 24 的倍数(48、72、96、120、144、168)表示的整数。如果未指定此选项,则默认值为 168 小时。BILLING_MODEL:设置数据集的存储结算模式。您可以将BILLING_MODEL值设置为PHYSICAL以在计算存储费用时使用物理字节,或设置为LOGICAL以使用逻辑字节。默认值为LOGICAL。更改数据集的结算模式后,更改需要 24 小时才能生效。
更改数据集的存储结算模式后,您必须等待 14 天才能再次更改存储结算模式。
点击 运行。
如需详细了解如何运行查询,请参阅运行交互式查询。
bq
如需创建新数据集,请使用带有 --location 标志的 bq mk 命令。 如需查看完整的潜在参数列表,请参阅 bq mk --dataset 命令参考文档。
如需在非默认项目中创建数据集,请按照以下格式将项目 ID 添加到数据集名称:PROJECT_ID:DATASET_ID。
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
替换以下内容:
LOCATION:数据集的位置。创建数据集后,此位置无法再更改。您可以使用.bigqueryrc文件设置位置的默认值。KMS_KEY_NAME:默认 Cloud Key Management Service 密钥的名称,此密钥用于保护此数据集中新创建的表,除非在创建时提供了不同的密钥。您无法使用此参数集在数据集中创建 Google 加密表。PARTITION_EXPIRATION:新创建的分区表中的分区的默认生命周期(以秒为单位)。默认分区到期时间没有最小值。过期时间以分区的日期加上这个整数值为准。在数据集分区表中创建的任何分区都会在分区的日期起的PARTITION_EXPIRATION秒后删除。如果在创建或更新分区表时提供--time_partitioning_expiration标志,则表级分区到期时间优先于数据集级默认分区到期时间。TABLE_EXPIRATION:新创建的表的默认生命周期(以秒为单位)。最小值为 3600 秒(一小时)。到期时间以当前时间加上这个整数值为准。在数据集中创建的任何表都会在创建之时起的TABLE_EXPIRATION秒后删除。如果您在创建表时未设置表过期时间,则系统会应用此值。DESCRIPTION:数据集的说明KEY_1:VALUE_1:您想要在此数据集上设置为第一个标签的键值对,KEY_2:VALUE_2是您要设置为第二个标签的键值对。KEY_3:VALUE_3:您要将其设置为数据集标记的键值对。在同一标志下添加多个标记,并在键值对之间使用英文逗号。HOURS:新数据集的时间旅行窗口的时长(以小时为单位)。HOURS值必须是 48(2 天)到 168(7 天)之间以 24 的倍数(48、72、96、120、144、168)表示的整数。如果未指定此选项,则默认值为 168 小时。BILLING_MODEL:设置数据集的存储结算模式。您可以将BILLING_MODEL值设置为PHYSICAL以在计算存储费用时使用物理字节,或设置为LOGICAL以使用逻辑字节。默认值为LOGICAL。更改数据集的结算模式后,更改需要 24 小时才能生效。
更改数据集的存储结算模式后,您必须等待 14 天才能再次更改存储结算模式。
PROJECT_ID:您的项目 ID。DATASET_ID是您要创建的数据集的 ID。
例如,以下命令会创建一个名为 mydataset 的数据集,数据位置设置为 US,默认表到期时间为 3600 秒(1 小时),相应说明为 This is my dataset。该命令使用的不是 --dataset 标志,而是 -d 快捷方式。如果省略 -d 和 --dataset,该命令会默认创建一个数据集。
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
您可以输入 bq ls 命令来确认数据集已经创建。另外,您可以使用以下格式在创建新数据集时创建表:bq mk -t dataset.table。如需详细了解如何创建表,请参阅创建表。
Terraform
使用 google_bigquery_dataset 资源。
如需向 BigQuery 进行身份验证,请设置应用默认凭据。如需了解详情,请参阅为客户端库设置身份验证。
创建数据集
以下示例创建了一个名为 mydataset 的数据集。
当您使用 google_bigquery_dataset 资源创建数据集时,系统会自动向属于项目级层基本角色成员的所有账号授予对数据集的访问权限。如果您在创建数据集后运行 terraform show 命令,则数据集的 access 块类似于如下所示:
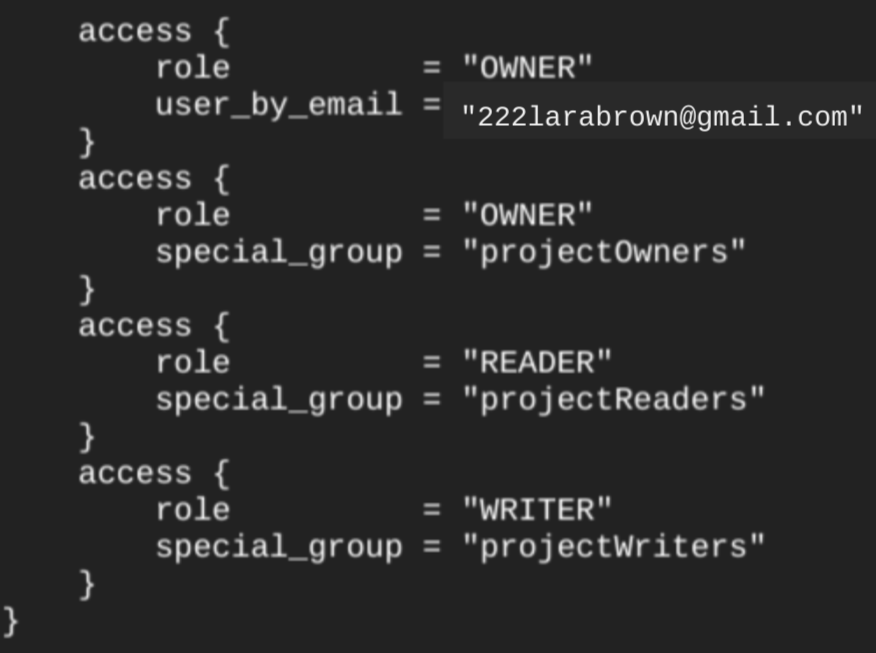
如需授予对数据集的访问权限,建议您使用 google_bigquery_iam 资源之一(如以下示例所示),除非您打算在数据集中创建已获授权的对象,例如已获授权的视图。在这种情况下,请使用 google_bigquery_dataset_access 资源。如需查看示例,请参阅该文档。
创建数据集并授予访问权限
以下示例创建一个名为 mydataset 的数据集,然后使用 google_bigquery_dataset_iam_policy 资源授予对该数据集的访问权限。
使用客户管理的加密密钥创建数据集
以下示例创建了一个名为 mydataset 的数据集,并且还会使用 google_kms_crypto_key 和 google_kms_key_ring 资源来指定数据集的 Cloud Key Management Service 密钥。您必须启用 Cloud Key Management Service API 才能运行此示例。
如需在 Google Cloud 项目中应用 Terraform 配置,请完成以下部分中的步骤。
准备 Cloud Shell
- 启动 Cloud Shell。
-
设置要应用 Terraform 配置的默认 Google Cloud 项目。
您只需为每个项目运行一次以下命令,即可在任何目录中运行它。
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
如果您在 Terraform 配置文件中设置显式值,则环境变量会被替换。
准备目录
每个 Terraform 配置文件都必须有自己的目录(也称为“根模块”)。
-
在 Cloud Shell 中,创建一个目录,并在该目录中创建一个新文件。文件名必须具有
.tf扩展名,例如main.tf。在本教程中,该文件称为main.tf。mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
如果您按照教程进行操作,可以在每个部分或步骤中复制示例代码。
将示例代码复制到新创建的
main.tf中。(可选)从 GitHub 中复制代码。如果端到端解决方案包含 Terraform 代码段,则建议这样做。
- 查看和修改要应用到您的环境的示例参数。
- 保存更改。
-
初始化 Terraform。您只需为每个目录执行一次此操作。
terraform init
(可选)如需使用最新的 Google 提供程序版本,请添加
-upgrade选项:terraform init -upgrade
应用更改
-
查看配置并验证 Terraform 将创建或更新的资源是否符合您的预期:
terraform plan
根据需要更正配置。
-
通过运行以下命令并在提示符处输入
yes来应用 Terraform 配置:terraform apply
等待 Terraform 显示“应用完成!”消息。
- 打开您的 Google Cloud 项目以查看结果。在 Google Cloud 控制台的界面中找到资源,以确保 Terraform 已创建或更新它们。
API
使用已定义的数据集资源调用 datasets.insert 方法。
C#
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 C# 设置说明进行操作。 如需了解详情,请参阅 BigQuery C# API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Go
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Go 设置说明进行操作。 如需了解详情,请参阅 BigQuery Go API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Node.js
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Node.js 设置说明进行操作。 如需了解详情,请参阅 BigQuery Node.js API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
PHP
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 PHP 设置说明进行操作。 如需了解详情,请参阅 BigQuery PHP API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Python
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Python 设置说明进行操作。 如需了解详情,请参阅 BigQuery Python API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
Ruby
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Ruby 设置说明进行操作。 如需了解详情,请参阅 BigQuery Ruby API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
命名数据集
在 BigQuery 中创建数据集时,每个项目的数据集名称不得重复。数据集名称可以包含以下内容:
- 不超过 1024 个字符。
- 字母(大写字母或小写字母)、数字和下划线。
默认情况下,数据集名称区分大小写。一个项目中可以同时存在 mydataset 和 MyDataset,除非其中一个关闭了区分大小写。如需查看示例,请参阅创建不区分大小写的数据集和资源:数据集。
数据集名称不能包含空格或特殊字符,例如 -、&、@ 或 %。
隐藏的数据集
隐藏的数据集是指名称以下划线开头的数据集。您可以按照与任何其他数据集中相同的方式查询隐藏数据集中的表和视图。隐藏的数据集具有以下限制:
- 在 Google Cloud 控制台的探索器面板中处于隐藏状态。
- 不会显示在任何
INFORMATION_SCHEMA视图中。 - 不能与关联的数据集搭配使用。
- 不能用作包含以下授权资源的源数据集:
- 不会显示在 Data Catalog(已弃用)或 Dataplex Universal Catalog 中。
数据集安全性
如需控制对 BigQuery 中数据集的访问权限,请参阅控制对数据集的访问权限。 如需了解数据加密,请参阅静态加密。
后续步骤
- 如需详细了解如何列出项目中的数据集,请参阅列出数据集。
- 如需详细了解数据集元数据,请参阅获取有关数据集的信息。
- 如需详细了解如何更改数据集属性,请参阅更新数据集。
- 如需详细了解如何创建和管理标签,请参阅创建和管理标签。
自行试用
如果您是 Google Cloud 新手,请创建一个账号来评估 BigQuery 在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
免费试用 BigQuery