Visualizar gráficos usando DataFrames do BigQuery
Este documento demonstra como criar vários tipos de gráficos usando a biblioteca de visualização de DataFrames do BigQuery.
A API bigframes.pandas
oferece um ecossistema completo de ferramentas para Python. A API permite operações estatísticas avançadas, e é possível ver as agregações geradas pelo BigQuery DataFrames. Também é possível alternar do BigQuery DataFrames para um DataFrame pandas com operações de amostragem integradas.
Histograma
O exemplo a seguir lê dados da tabela bigquery-public-data.ml_datasets.penguins para criar um histograma sobre a distribuição das profundidades do bico dos pinguins:

Gráfico de linhas
O exemplo a seguir usa dados da tabela bigquery-public-data.noaa_gsod.gsod2021 para criar um gráfico de linhas das mudanças na temperatura mediana ao longo do ano:

Gráfico de área
O exemplo a seguir usa a tabela bigquery-public-data.usa_names.usa_1910_2013 para
acompanhar a popularidade dos nomes na história dos EUA e se concentra nos nomes Mary, Emily
e Lisa:

Gráfico de barras
O exemplo a seguir usa a tabela bigquery-public-data.ml_datasets.penguins para visualizar a distribuição de sexos de pinguins:

Gráfico de dispersão
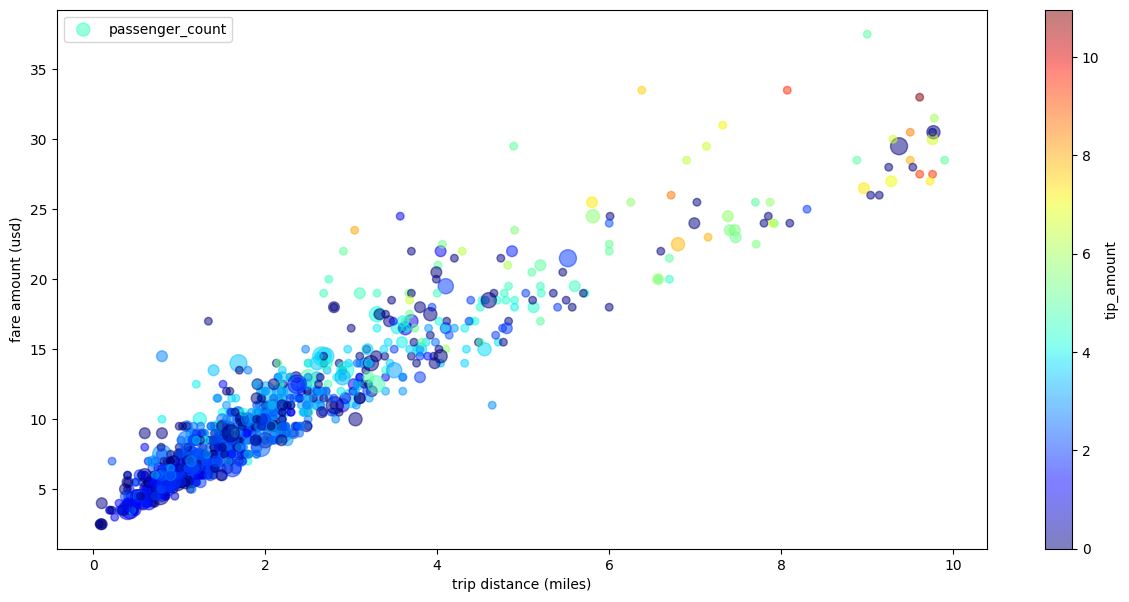
O exemplo a seguir usa a tabela bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2021 para analisar a relação entre os valores das tarifas de táxi e as distâncias percorridas:

Como visualizar um conjunto de dados grande
O BigQuery DataFrames baixa dados para sua máquina local para visualização. Por padrão,o número de pontos de dados a serem baixados é limitado a 1.000. Se o número de pontos de dados exceder o limite, os DataFrames do BigQuery vão amostrar aleatoriamente o número de pontos de dados igual ao limite.
É possível substituir esse limite definindo o parâmetro sampling_n ao criar um gráfico, conforme mostrado no exemplo a seguir:

Plotagem avançada com parâmetros do pandas e do Matplotlib
É possível transmitir mais parâmetros para ajustar o gráfico, assim como no pandas, porque a biblioteca de geração de gráficos do BigQuery DataFrames é alimentada pelo pandas e pelo Matplotlib. As seções a seguir descrevem exemplos.
Tendência de popularidade de nomes com subgráficos
Usando os dados do histórico de nomes do exemplo de gráfico de área, o exemplo a seguir cria gráficos individuais para cada nome definindo subplots=True na chamada da função plot.area():

Diagrama de dispersão de viagens de táxi com várias dimensões
Usando dados do exemplo de diagrama de dispersão, o exemplo a seguir renomeia os rótulos dos eixos x e y, usa o parâmetro passenger_count para tamanhos de pontos, usa pontos de cor com o parâmetro tip_amount e redimensiona a figura:
A seguir
- Saiba como usar o BigQuery DataFrames.
- Saiba como usar o BigQuery DataFrames no dbt.
- Confira a referência da API BigQuery DataFrames.