Load Blob Storage data into BigQuery
You can load data from Blob Storage to BigQuery using the BigQuery Data Transfer Service for Blob Storage connector. With the BigQuery Data Transfer Service, you can schedule recurring transfer jobs that add your latest data from Blob Storage to BigQuery.
Before you begin
Before you create a Blob Storage data transfer, do the following:
- Verify that you have completed all actions that are required to enable the BigQuery Data Transfer Service.
- Choose an existing BigQuery dataset or create a new dataset to store your data.
- Choose an existing BigQuery table or create a new destination table for your data transfer, and specify the schema definition. The destination table must follow the table naming rules. Destination table names also support parameters.
- Retrieve your Blob Storage storage account name, container name, data path (optional), and SAS token. For information about granting access to Blob Storage using a shared access signature (SAS), see Shared access signature (SAS).
- If you restrict access to your Azure resources using an Azure Storage firewall, add BigQuery Data Transfer Service workers to your list of allowed IPs.
- If you plan on specifying a customer-managed encryption key (CMEK), ensure that your service account has permissions to encrypt and decrypt, and that you have the Cloud KMS key resource ID required to use CMEK. For information about how CMEK works with the BigQuery Data Transfer Service, see Specify encryption key with transfers.
Required permissions
Ensure that you have granted the following permissions.
Required BigQuery roles
To get the permissions that
you need to create a BigQuery Data Transfer Service data transfer,
ask your administrator to grant you the
BigQuery Admin (roles/bigquery.admin)
IAM role on your project.
For more information about granting roles, see Manage access to projects, folders, and organizations.
This predefined role contains the permissions required to create a BigQuery Data Transfer Service data transfer. To see the exact permissions that are required, expand the Required permissions section:
Required permissions
The following permissions are required to create a BigQuery Data Transfer Service data transfer:
-
BigQuery Data Transfer Service permissions:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
BigQuery permissions:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
You might also be able to get these permissions with custom roles or other predefined roles.
For more information, see Grant bigquery.admin access.
Required Blob Storage roles
For information about the required permissions in Blob Storage to enable the data transfer, see Shared access signature (SAS).
Limitations
Blob Storage data transfers are subject to the following limitations:
- The minimum interval time between recurring data transfers is 1 hour. The default interval is 24 hours.
- Depending on the format of your Blob Storage source data, there may be additional limitations:
- Data transfers to BigQuery Omni locations are not supported.
Set up a Blob Storage data transfer
Select one of the following options:
Console
Go to the Data transfers page in the Google Cloud console.
Click Create transfer.
On the Create transfer page, do the following:
In the Source type section, for Source, select Azure Blob Storage & ADLS:
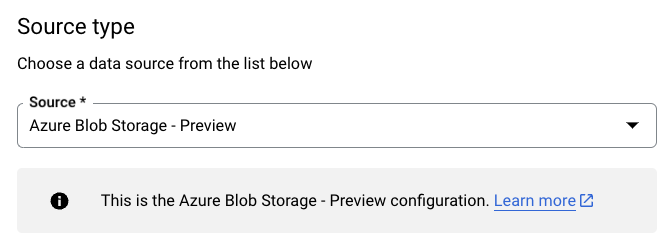
In the Transfer config name section, for Display name, enter a name for the data transfer.
In the Schedule options section:
- Select a Repeat frequency. If you select Hours, Days, Weeks, or Months, you must also specify a frequency. You can also select Custom to specify a custom repeat frequency. If you select On-demand, then this data transfer runs when you manually trigger the transfer.
- If applicable, select either Start now or Start at set time and provide a start date and run time.
In the Destination settings section, for Dataset, choose the dataset that you created to store your data.
In the Data source details section, do the following:
- For Destination table, enter the name of the table you created to store the data in BigQuery. Destination table names support parameters.
- For Azure storage account name, enter the Blob Storage account name.
- For Container name, enter the Blob Storage container name.
- For Data path, enter the path to filter files to be transferred. See examples.
- For SAS token, enter the Azure SAS token.
- For File format, choose your source data format.
- For Write disposition, select
WRITE_APPENDto incrementally append new data to the destination table, orWRITE_TRUNCATEto overwrite data in the destination table during each transfer run.WRITE_APPENDis the default value for Write disposition.
For more information about how BigQuery Data Transfer Service ingests data using either
WRITE_APPENDorWRITE_TRUNCATE, see Data ingestion for Azure Blob transfers. For more information about thewriteDispositionfield, seeJobConfigurationLoad.
In the Transfer options section, do the following:
- For Number of errors allowed, enter an integer value for the maximum number of bad records that can be ignored. The default value is 0.
- (Optional) For Decimal target types, enter a comma-separated
list of possible SQL data types that decimal values in the source
data are converted to. Which SQL data type is selected for
conversion depends on the following conditions:
- In the order of
NUMERIC,BIGNUMERIC, andSTRING, a type is picked if it is in your specified list and if it supports the precision and the scale. - If none of your listed data types support the precision and the scale, the data type supporting the widest range in your specified list is selected. If a value exceeds the supported range when reading the source data, an error is thrown.
- The data type
STRINGsupports all precision and scale values. - If this field is left empty, the data type defaults to
NUMERIC,STRINGfor ORC, andNUMERICfor other file formats. - This field cannot contain duplicate data types.
- The order of the data types that you list is ignored.
- In the order of
If you chose CSV or JSON as your file format, in the JSON, CSV section, check Ignore unknown values to accept rows that contain values that don't match the schema.
If you chose CSV as your file format, in the CSV section enter any additional CSV options for loading data.
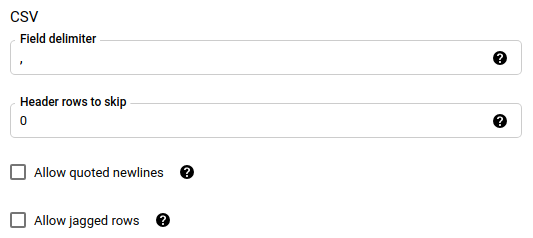
In the Notification options section, you can choose to enable email notifications and Pub/Sub notifications.
- When you enable email notifications, the transfer administrator receives an email notification when a transfer run fails.
- When you enable Pub/Sub notifications, choose a topic name to publish to or click Create a topic to create one.
If you use CMEKs, in the Advanced options section, select Customer-managed key. A list of your available CMEKs appears for you to choose from. For information about how CMEKs work with the BigQuery Data Transfer Service, see Specify encryption key with transfers.
Click Save.
bq
Use the
bq mk --transfer_config command
to create a Blob Storage transfer:
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=DISPLAY_NAME \ --target_dataset=DATASET \ --destination_kms_key=DESTINATION_KEY \ --params=PARAMETERS
Replace the following:
PROJECT_ID: (Optional) the project ID containing your target dataset. If not specified, your default project is used.DATA_SOURCE:azure_blob_storage.DISPLAY_NAME: the display name for the data transfer configuration. The transfer name can be any value that lets you identify the transfer if you need to modify it later.DATASET: the target dataset for the data transfer configuration.DESTINATION_KEY: (Optional) the Cloud KMS key resource ID— for example,projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name.PARAMETERS: the parameters for the data transfer configuration, listed in JSON format. For example,--params={"param1":"value1", "param2":"value2"}. The following are the parameters for a Blob Storage data transfer:destination_table_name_template: Required. The name of your destination table.storage_account: Required. The Blob Storage account name.container: Required. The Blob Storage container name.data_path: Optional. The path to filter files to be transferred. See examples.sas_token: Required. The Azure SAS token.file_format: Optional. The type of files you want to transfer:CSV,JSON,AVRO,PARQUET, orORC. The default value isCSV.write_disposition: Optional. SelectWRITE_APPENDto append data to the destination table, orWRITE_TRUNCATE, to overwrite data in the destination table. The default value isWRITE_APPEND.max_bad_records: Optional. The number of allowed bad records. The default value is 0.decimal_target_types: Optional. A comma-separated list of possible SQL data types that decimal values in the source data are converted to. If this field is not provided, the data type defaults toNUMERIC,STRINGfor ORC, andNUMERICfor the other file formats.ignore_unknown_values: Optional, and ignored iffile_formatis notJSONorCSV. Set totrueto accept rows that contain values that don't match the schema.field_delimiter: Optional, and applies only whenfile_formatisCSV. The character that separates fields. The default value is,.skip_leading_rows: Optional, and applies only whenfile_formatisCSV. Indicates the number of header rows that you don't want to import. The default value is 0.allow_quoted_newlines: Optional, and applies only whenfile_formatisCSV. Indicates whether to allow newlines within quoted fields.allow_jagged_rows: Optional, and applies only whenfile_formatisCSV. Indicates whether to accept rows that are missing trailing optional columns. The missing values are filled in withNULL.
For example, the following creates a Blob Storage data transfer
called mytransfer:
bq mk \ --transfer_config \ --data_source=azure_blob_storage \ --display_name=mytransfer \ --target_dataset=mydataset \ --destination_kms_key=projects/myproject/locations/us/keyRings/mykeyring/cryptoKeys/key1 --params={"destination_table_name_template":"mytable", "storage_account":"myaccount", "container":"mycontainer", "data_path":"myfolder/*.csv", "sas_token":"my_sas_token_value", "file_format":"CSV", "max_bad_records":"1", "ignore_unknown_values":"true", "field_delimiter":"|", "skip_leading_rows":"1", "allow_quoted_newlines":"true", "allow_jagged_rows":"false"}
API
Use the projects.locations.transferConfigs.create
method and supply an instance of the TransferConfig
resource.
Java
Before trying this sample, follow the Java setup instructions in the BigQuery quickstart using client libraries. For more information, see the BigQuery Java API reference documentation.
To authenticate to BigQuery, set up Application Default Credentials. For more information, see Set up authentication for client libraries.
Specify encryption key with transfers
You can specify customer-managed encryption keys (CMEKs) to encrypt data for a transfer run. You can use a CMEK to support transfers from Azure Blob Storage.When you specify a CMEK with a transfer, the BigQuery Data Transfer Service applies the CMEK to any intermediate on-disk cache of ingested data so that the entire data transfer workflow is CMEK compliant.
You cannot update an existing transfer to add a CMEK if the transfer was not originally created with a CMEK. For example, you cannot change a destination table that was originally default encrypted to now be encrypted with CMEK. Conversely, you also cannot change a CMEK-encrypted destination table to have a different type of encryption.
You can update a CMEK for a transfer if the transfer configuration was originally created with a CMEK encryption. When you update a CMEK for a transfer configuration, the BigQuery Data Transfer Service propagates the CMEK to the destination tables at the next run of the transfer, where the BigQuery Data Transfer Service replaces any outdated CMEKs with the new CMEK during the transfer run. For more information, see Update a transfer.
You can also use project default keys. When you specify a project default key with a transfer, the BigQuery Data Transfer Service uses the project default key as the default key for any new transfer configurations.
Troubleshoot transfer setup
If you are having issues setting up your data transfer, see Blob Storage transfer issues.
What's next
- Learn more about runtime parameters in transfers.
- Learn more about the BigQuery Data Transfer Service.
- Learn how to load data with cross-cloud operations.