Blob 儲存體轉移作業簡介
您可以利用 Azure Blob 儲存體專用的 BigQuery 資料移轉服務,自動安排及管理從 Azure Blob 儲存體和 Azure Data Lake Storage Gen2 到 BigQuery 的週期性載入工作。
支援的檔案格式
目前,BigQuery 資料移轉服務可讓您透過以下格式從 Blob Storage 載入資料:
- 逗號分隔值 (CSV)
- JSON (以換行符號分隔)
- Avro
- Parquet
- ORC
支援的壓縮類型
Blob Storage 專用的 BigQuery 資料移轉服務支援載入壓縮資料。BigQuery 資料移轉服務支援的壓縮類型和 BigQuery 載入工作支援的相同。詳情請參閱載入壓縮與未壓縮資料。
轉移作業必備條件
如要從 Blob Storage 資料來源載入資料,請先收集下列資訊:
- 來源資料的 Blob 儲存體帳戶名稱、容器名稱和資料路徑 (選用)。資料路徑欄位為選用欄位,用於比對常見的物件前置字串和檔案副檔名。如果省略資料路徑,系統會傳輸容器中的所有檔案。
- 可授予資料來源讀取權的 Azure 共用存取簽章 (SAS) 權杖。如要進一步瞭解如何建立 SAS 權杖,請參閱「共用存取簽章 (SAS)」。
轉移執行階段參數化
Blob Storage 資料路徑和目的地資料表皆可參數化,讓您依日期順序從容器載入資料。Blob Storage 移轉作業使用的參數與 Cloud Storage 移轉作業使用的參數相同。詳情請參閱「在移轉作業中使用執行階段參數」。
Azure Blob 移轉作業的資料擷取
設定 Azure Blob 移轉作業時,您可以在移轉設定中選取寫入偏好設定,指定資料載入 BigQuery 的方式。
寫入偏好設定有兩種,分別是增量轉移和截斷轉移。增量轉移
使用 APPEND 或 WRITE_APPEND 寫入偏好設定的移轉設定 (也稱為增量移轉),會在先前成功將資料移轉至 BigQuery 目的地資料表後,逐漸附加新資料。當轉移設定搭配 APPEND 寫入偏好設定執行時,BigQuery 資料移轉服務會篩選自上次成功執行轉移作業以來已修改的檔案。為了判斷檔案修改時間,BigQuery 資料移轉服務會查看檔案中繼資料的「上次修改時間」屬性。舉例來說,BigQuery 資料移轉服務會查看 Cloud Storage 檔案中的 updated 時間戳記屬性。如果 BigQuery 資料移轉服務發現任何檔案的「上次修改時間」是在上次成功移轉作業的時間戳記之後,就會以增量移轉方式轉移這些檔案。
為說明漸進式轉移作業的運作方式,請參考以下 Cloud Storage 轉移作業範例。使用者在 2023-07-01T00:00Z 時間點在 Cloud Storage 值區中建立名為 file_1 的檔案。file_1 的 updated 時間戳記是檔案建立的時間。接著,使用者會從 Cloud Storage 儲存桶建立漸進式移轉作業,並排定每天在 03:00 協調世界時 (UTC) 執行一次,從 2023-07-01T03:00Z 開始。
- 在 2023-07-01T03:00Z,第一個轉移作業就會開始。由於這是此設定的首次移轉作業,BigQuery 資料移轉服務會嘗試將與來源 URI 相符的所有檔案載入目標 BigQuery 資料表。移轉作業執行成功,BigQuery 資料移轉服務已成功將
file_1載入至目的地 BigQuery 資料表。 - 在 2023-07-02T03:00Z 執行下一次轉移作業時,系統不會偵測到
updated時間戳記屬性大於上次成功執行轉移作業 (2023-07-01T03:00Z) 的檔案。移轉作業執行成功,但未將任何其他資料載入目標 BigQuery 資料表。
上例說明 BigQuery 資料移轉服務如何查看來源檔案的 updated 時間戳記屬性,判斷來源檔案是否有任何變更,並在偵測到變更時進行轉移。
同樣以上述範例為例,假設使用者在 2023-07-03T00:00Z 時,在 Cloud Storage 值區中建立另一個名為 file_2 的檔案。file_2 的 updated 時間戳記,是檔案建立的時間。
- 下一次轉移作業 (2023-07-03T03:00Z) 偵測到
file_2的updated時間戳記大於上次成功的轉移作業 (2023-07-01T03:00Z)。假設轉移作業在開始執行時,因暫時性錯誤而失敗。在這種情況下,file_2不會載入至目的地 BigQuery 資料表。上次成功執行轉移作業的時間戳記仍為 2023-07-01T03:00Z。 - 下次轉移作業 (2023-07-04T03:00Z) 偵測到
file_2的updated時間戳記比上次成功的轉移作業 (2023-07-01T03:00Z) 還要晚。這次移轉作業執行完畢後沒有問題,因此成功將file_2載入至目的地 BigQuery 資料表。 - 在 2023-07-05T03:00Z 執行下一次轉移作業時,系統不會偵測到
updated時間戳記大於上次成功執行轉移作業 (2023-07-04T03:00Z) 的檔案。轉移作業成功完成,但未將任何其他資料載入目的地 BigQuery 資料表。
上例顯示,當轉移作業失敗時,系統不會將任何檔案轉移至 BigQuery 目的地資料表。系統會在下次成功執行傳輸作業時,傳輸任何檔案變更。在失敗的轉移作業後,後續成功的轉移作業不會導致資料重複。如果轉移作業失敗,您也可以選擇在例行排程時間以外手動觸發轉移作業。
截斷的轉移作業
使用 MIRROR 或 WRITE_TRUNCATE 寫入偏好設定的移轉設定 (也稱為截斷移轉),會在每次移轉執行時,將與來源 URI 相符的所有檔案資料覆寫至 BigQuery 目的地資料表。MIRROR 會覆寫目的地資料表中資料的新副本。如果目的地資料表使用分區修飾符,轉移作業只會覆寫指定分區中的資料。含有分區修飾符的目標資料表格式為 my_table${run_date},例如 my_table$20230809。
在一天內重複執行相同的增量或截斷移轉作業,不會導致資料重複。不過,如果您執行多個不同的移轉設定,且這些設定會影響相同的 BigQuery 目的地資料表,則可能會導致 BigQuery 資料移轉服務產生資料重複。
Blob 儲存體資料路徑的萬用字元支援
您可以在資料路徑中指定一或多個星號 (*) 萬用字元,選取分成多個檔案的原始資料。
雖然資料路徑中可以使用多個萬用字元,但如果只使用單一萬用字元,就能進行一些最佳化:
- 每個轉移作業的檔案數量上限較高。
- 萬用字元會跨越目錄邊界。舉例來說,資料路徑
my-folder/*.csv會比對檔案my-folder/my-subfolder/my-file.csv。
Blob 儲存體資料路徑範例
以下是 Blob 儲存體移轉作業的有效資料路徑範例。請注意,資料路徑開頭並非 /。
範例:單一檔案
如要將 Blob Storage 中的單一檔案載入至 BigQuery,請指定 Blob Storage 檔案名稱:
my-folder/my-file.csv
範例:所有檔案
如要將 Blob Storage 容器中的所有檔案載入至 BigQuery,請將資料路徑設為單一萬用字元:
*
範例:含有共同前置字串的檔案
如要從 Blob Storage 載入共用通用前置字串的所有檔案,請指定通用前置字串 (可含或不含萬用字元):
my-folder/
或
my-folder/*
範例:路徑相似的檔案
如要從 Blob 儲存體載入所有具有相似路徑的檔案,請指定通用前置字串和後置字串:
my-folder/*.csv
如果只使用一個萬用字元,則會跨目錄。在這個範例中,系統會選取 my-folder 中的每個 CSV 檔案,以及 my-folder 每個子資料夾中的每個 CSV 檔案。
範例:路徑結尾的萬用字元
請考慮下列資料路徑:
logs/*
系統會選取下列所有檔案:
logs/logs.csv
logs/system/logs.csv
logs/some-application/system_logs.log
logs/logs_2019_12_12.csv
範例:路徑開頭的萬用字元
請考慮下列資料路徑:
*logs.csv
系統會選取下列所有檔案:
logs.csv
system/logs.csv
some-application/logs.csv
且未選取下列任何檔案:
metadata.csv
system/users.csv
some-application/output.csv
範例:多個萬用字元
使用多個萬用字元可讓您更精準地選擇檔案,但限制較低。使用多個萬用字元時,每個萬用字元只會跨越單一子目錄。
請考慮下列資料路徑:
*/*.csv
系統會選取下列兩個檔案:
my-folder1/my-file1.csv
my-other-folder2/my-file2.csv
且未選取下列任何檔案:
my-folder1/my-subfolder/my-file3.csv
my-other-folder2/my-subfolder/my-file4.csv
共用存取簽章 (SAS)
Azure SAS 權杖可用於代表您存取 Blob 儲存體資料。請按照下列步驟建立 SAS 權杖,以便進行轉移:
- 建立或使用現有的 Blob 儲存體使用者,存取 Blob 儲存體容器的儲存空間帳戶。
在儲存空間帳戶層級建立 SAS 權杖。如要使用 Azure 入口網站建立 SAS 權杖,請按照下列步驟操作:
- 在「Allowed services」(允許的服務) 中,選取「Blob」(Blob)。
- 在「Allowed resource types」(允許的資源類型) 中,選取「Container」和「Object」。
- 在「允許的權限」部分,選取「讀取」和「清單」。
- SAS 權杖的預設到期時間為 8 小時。設定符合轉移時間表的到期時間。
- 請勿在「Allowed IP addresses」欄位中指定任何 IP 位址。
- 在「Allowed protocols」中,選取「Only HTTPS」。
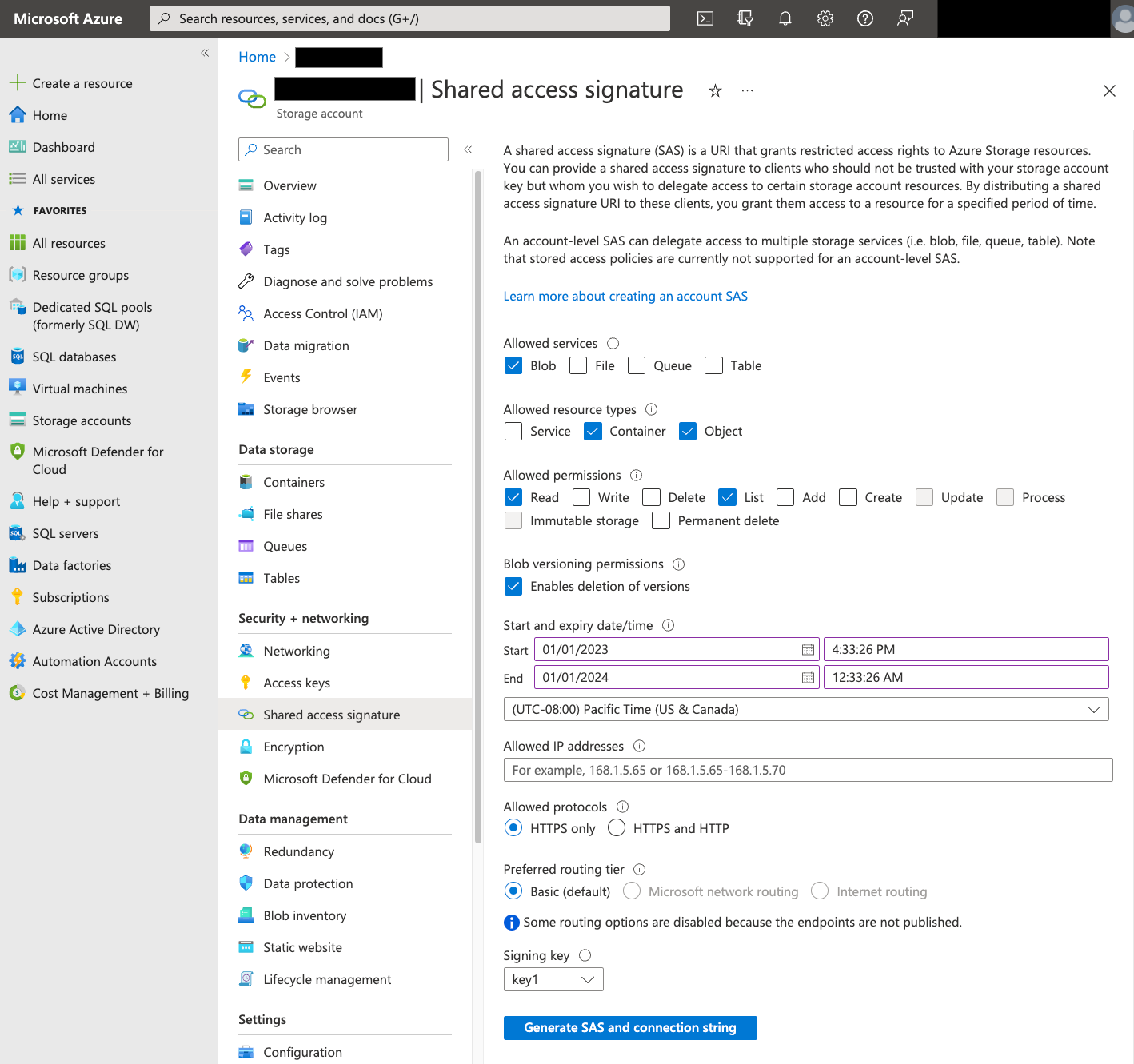
建立 SAS 權杖後,請記下系統傳回的 SAS 權杖值。設定轉移作業時,您需要使用這個值。
IP 限制
如果您使用 Azure Storage 防火牆限制 Azure 資源的存取權,請務必將 BigQuery 資料移轉服務 worker 使用的 IP 範圍加入許可 IP 清單。
如要將 IP 範圍新增為 Azure Storage 防火牆的允許 IP,請參閱「IP 限制」。
一致性考量
將檔案新增至 Blob Storage 容器後,BigQuery 資料移轉服務可能需要大約 5 分鐘才能提供該檔案。
控管出口費用的最佳做法
如果目的地資料表未正確設定,從 Blob 儲存體進行的轉移作業可能會失敗。設定不正確的可能原因包括:
- 目的地表格不存在。
- 未定義資料表結構定義。
- 資料表結構定義與要移轉的資料不相容。
為避免產生額外的 Blob Storage 輸出費用,請先使用一小部分代表性檔案進行測試。請確保這項測試的資料大小和檔案數量都很小。
請特別注意,資料路徑的前置字元比對會在檔案從 Blob Storage 傳輸前執行,但萬用字元比對會在 Google Cloud內執行。對於轉移至Google Cloud 但未載入至 BigQuery 的檔案,這項差異可能會增加 Blob Storage 的傳出費用。
舉例來說,請看以下資料路徑:
folder/*/subfolder/*.csv
下列兩個檔案都會轉移至 Google Cloud,因為它們都含有前置字串 folder/:
folder/any/subfolder/file1.csv
folder/file2.csv
不過,由於 folder/any/subfolder/file1.csv 檔案符合完整資料路徑,因此只會載入該檔案至 BigQuery。
定價
詳情請參閱 BigQuery 資料移轉服務定價。
使用這項服務時,也可能須支付其他產品 (非 Google) 的費用。詳情請參閱「Blob Storage 定價」。
配額與限制
BigQuery 資料移轉服務會使用載入工作,將 Blob Storage 資料載入至 BigQuery。所有 BigQuery 對載入工作的配額和限制均適用於 Blob Storage 的週期性移轉作業,但請注意下列額外事項:
| 限制 | 預設 |
|---|---|
| 每個負載工作傳輸執行作業的大小上限 | 15 TB |
| Blob 儲存體資料路徑包含 0 或 1 個萬用字元時,每次轉移作業的最大檔案數量 | 10,000,000 個檔案 |
| Blob 儲存空間資料路徑包含 2 個以上萬用字元時,每次轉移作業的最大檔案數量 | 10,000 個檔案 |
後續步驟
- 進一步瞭解如何設定 Blob 儲存體移轉作業。
- 進一步瞭解移轉作業中的執行階段參數。
- 進一步瞭解 BigQuery 資料移轉服務。