En este tutorial, aprenderás a acelerar significativamente el entrenamiento de un conjunto de ARIMA_PLUSmodelos de series temporales univariantes para realizar varias previsiones de series temporales con una sola consulta. También aprenderá a evaluar la precisión de las previsiones.
En este tutorial se hacen previsiones de varias series temporales. Los valores previstos se calculan para cada punto temporal y para cada valor de una o varias columnas especificadas. Por ejemplo, si quieres predecir el tiempo y especificas una columna que contenga datos de ciudades, los datos previstos incluirán las predicciones de todos los puntos temporales de la ciudad A, los valores previstos de todos los puntos temporales de la ciudad B, etc.
En este tutorial se usan datos de las tablas públicas
bigquery-public-data.new_york.citibike_trips
y
iowa_liquor_sales.sales. Los datos de los trayectos en bicicleta solo contienen unos cientos de series temporales, por lo que se usan para ilustrar varias estrategias para acelerar el entrenamiento de modelos.
Los datos de ventas de bebidas alcohólicas tienen más de un millón de series temporales, por lo que se usan para mostrar la previsión de series temporales a gran escala.
Antes de leer este tutorial, debes consultar los artículos Previsión de varias series temporales con un modelo univariante y Prácticas recomendadas para la previsión de series temporales a gran escala.
Crear conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de aprendizaje automático.
Consola
En la Google Cloud consola, ve a la página BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haga clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, introduce
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, a continuación, EE. UU. (varias regiones de Estados Unidos).
Deje el resto de los ajustes predeterminados como están y haga clic en Crear conjunto de datos.
bq
Para crear un conjunto de datos, usa el comando
bq mk
con la marca --location. Para ver una lista completa de los parámetros posibles, consulta la referencia del comando bq mk --dataset.
Crea un conjunto de datos llamado
bqml_tutorialcon la ubicación de los datos definida comoUSy la descripciónBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
En lugar de usar la marca
--dataset, el comando usa el acceso directo-d. Si omite-dy--dataset, el comando creará un conjunto de datos de forma predeterminada.Confirma que se ha creado el conjunto de datos:
bq ls
API
Llama al método datasets.insert con un recurso de conjunto de datos definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
Crear una tabla de datos de entrada
La instrucción SELECT de la siguiente consulta usa la función EXTRACT para extraer la información de la fecha de la columna starttime. La consulta usa la cláusula COUNT(*) para obtener el número total diario de viajes de Citi Bike.
table_1 tiene 679 series temporales. La consulta usa lógica INNER JOIN adicional
para seleccionar todas las series temporales que tienen más de 400 puntos temporales, lo que da como resultado
un total de 383 series temporales.
Sigue estos pasos para crear la tabla de datos de entrada:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE TABLE `bqml_tutorial.nyc_citibike_time_series` AS WITH input_time_series AS ( SELECT start_station_name, EXTRACT(DATE FROM starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY start_station_name, date ) SELECT table_1.* FROM input_time_series AS table_1 INNER JOIN ( SELECT start_station_name, COUNT(*) AS num_points FROM input_time_series GROUP BY start_station_name) table_2 ON table_1.start_station_name = table_2.start_station_name WHERE num_points > 400;
Crear un modelo para varias series temporales con parámetros predeterminados
Quieres predecir el número de trayectos en bicicleta de cada estación de Citi Bike, lo que requiere muchos modelos de series temporales, uno por cada estación de Citi Bike incluida en los datos de entrada. Puedes escribir varias consultas CREATE MODEL
para hacerlo, pero puede ser un proceso tedioso y largo,
sobre todo si tienes un gran número de series temporales. En su lugar, puede usar una sola consulta para crear y ajustar un conjunto de modelos de series temporales con el fin de predecir varias series temporales a la vez.
La cláusula OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica que vas a crear un conjunto de modelos de series temporales ARIMAARIMA_PLUS. La opción time_series_timestamp_col especifica la columna que contiene las series temporales, la opción time_series_data_col especifica la columna para la que se va a hacer la previsión y la opción time_series_id_col especifica una o varias dimensiones para las que se van a crear series temporales.
En este ejemplo , se omiten los puntos temporales de la serie temporal posteriores al 1 de junio del 2016 para que se puedan usar para evaluar la precisión de las previsiones más adelante con la función ML.EVALUATE.
Sigue estos pasos para crear el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_default` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name' ) AS SELECT * FROM bqml_tutorial.nyc_citibike_time_series WHERE date < '2016-06-01';
La consulta tarda unos 15 minutos en completarse.
Evaluar la precisión de las previsiones de cada serie temporal
Evalúa la precisión de las previsiones del modelo con la función ML.EVALUATE.
Sigue estos pasos para evaluar el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Esta consulta genera un informe con varias métricas de previsión, entre las que se incluyen las siguientes:
Los resultados deberían ser similares a los siguientes:
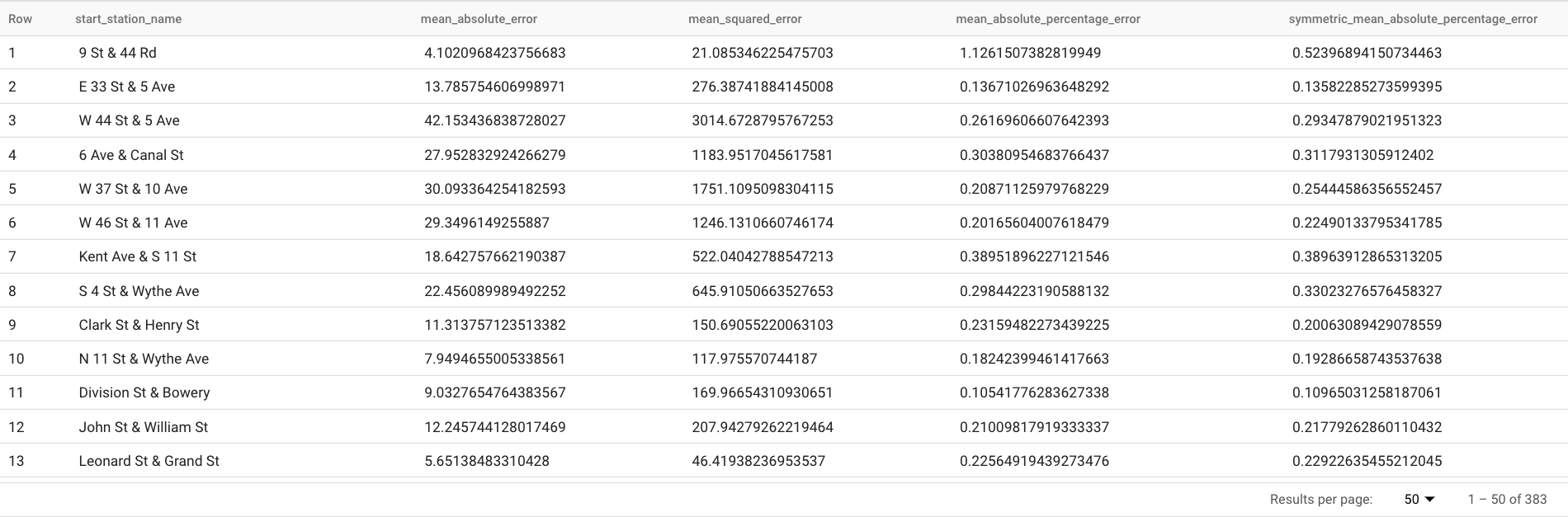
La cláusula
TABLEde la funciónML.EVALUATEidentifica una tabla que contiene los datos validados. Los resultados de las previsiones se comparan con los datos validados en el terreno para calcular las métricas de precisión. En este caso,nyc_citibike_time_seriescontiene los puntos de la serie temporal que son anteriores y posteriores al 1 de junio del 2016. Los puntos posteriores al 1 de junio del 2016 son los datos de referencia. Los puntos anteriores al 1 de junio del 2016 se usan para entrenar el modelo y generar previsiones después de esa fecha. Solo se necesitan los puntos posteriores al 1 de junio del 2016 para calcular las métricas. Los puntos anteriores al 1 de junio del 2016 no se tienen en cuenta en el cálculo de las métricas.La cláusula
STRUCTde la funciónML.EVALUATEespecificaba los parámetros de la función. El valor dehorizones7, lo que significa que la consulta calcula la precisión de la previsión basándose en una previsión de siete puntos. Nota: Si los datos validados en el terreno tienen menos de siete puntos para la comparación, las métricas de precisión se calculan únicamente en función de los puntos disponibles. El valor deperform_aggregationesTRUE, lo que significa que las métricas de precisión de las previsiones se agregan en función de las métricas de los puntos temporales. Si especificas el valorFALSEenperform_aggregation, se devuelve la precisión de la previsión para cada punto temporal previsto.Para obtener más información sobre las columnas de salida, consulta la función
ML.EVALUATE.
Evaluar la precisión general de las previsiones
Evalúa la precisión de las previsiones de las 383 series temporales.
De las métricas de previsión devueltas por ML.EVALUATE, solo error absoluto medio porcentual y error absoluto medio porcentual simétrico son independientes del valor de la serie temporal. Por lo tanto, para evaluar la precisión de la previsión de todo el conjunto de series temporales, solo es útil la agregación de estas dos métricas.
Sigue estos pasos para evaluar el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_default`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Esta consulta devuelve un valor MAPE de 0.3471 y un valor sMAPE de 0.2563.
Crear un modelo para predecir varias series temporales con un espacio de búsqueda de hiperparámetros más pequeño
En la sección Crear un modelo para varias series temporales con parámetros predeterminados, ha usado los valores predeterminados de todas las opciones de entrenamiento, incluida la opción auto_arima_max_order. Esta opción controla el espacio de búsqueda para el ajuste de hiperparámetros en el algoritmo auto.ARIMA.
En el modelo creado por la siguiente consulta, se usa un espacio de búsqueda más pequeño para los hiperparámetros. Para ello, se cambia el valor de la opción auto_arima_max_order de 5 (valor predeterminado) a 2.
Sigue estos pasos para evaluar el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
La consulta tarda unos 2 minutos en completarse. Recuerda que el modelo anterior tardaba unos 15 minutos en completarse cuando el valor de
auto_arima_max_orderera5, por lo que este cambio mejora la velocidad de entrenamiento del modelo unas 7 veces. Si te preguntas por qué la ganancia de velocidad no es5/2=2.5x, es porque, cuando aumenta el valor deauto_arima_max_order, no solo aumenta el número de modelos candidatos, sino también la complejidad. Esto provoca que aumente el tiempo de entrenamiento del modelo.
Evaluar la precisión de las previsiones de un modelo con un espacio de búsqueda de hiperparámetros más pequeño
Sigue estos pasos para evaluar el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Esta consulta devuelve un valor MAPE de 0.3337 y un valor sMAPE de 0.2337.
En la sección Evaluar la precisión general de las previsiones, has evaluado un modelo con un espacio de búsqueda de hiperparámetros más grande, donde el valor de la opción auto_arima_max_order es 5. Esto dio como resultado un valor de MAPE de 0.3471 y un valor de sMAPE de 0.2563. En este caso, puedes ver que un espacio de búsqueda de hiperparámetros más pequeño ofrece una mayor precisión de las previsiones. Una de las razones es que el algoritmo auto.ARIMA solo ajusta los hiperparámetros del módulo de tendencia de toda la canalización de modelización. Es posible que el mejor modelo de ARIMA seleccionado por el algoritmo auto.ARIMA no genere los mejores resultados de previsión para todo el flujo de trabajo.
Crea un modelo para predecir varias series temporales con un espacio de búsqueda de hiperparámetros más pequeño y estrategias de entrenamiento rápidas e inteligentes
En este paso, se utiliza un espacio de búsqueda de hiperparámetros más pequeño y la estrategia de entrenamiento rápido inteligente mediante una o varias de las opciones de entrenamiento max_time_series_length, max_time_series_length o time_series_length_fraction.
Mientras que los modelos periódicos, como la estacionalidad, requieren un número determinado de puntos temporales, los modelos de tendencias necesitan menos puntos temporales. Por otro lado, la creación de modelos de tendencias es mucho más costosa desde el punto de vista computacional que otros componentes de series temporales, como la estacionalidad. Si usas las opciones de entrenamiento rápido que se indican arriba, puedes modelizar de forma eficiente el componente de tendencia con un subconjunto de la serie temporal, mientras que los demás componentes de la serie temporal usan la serie temporal completa.
En el siguiente ejemplo se usa la opción max_time_series_length para conseguir un entrenamiento rápido. Si asigna el valor 30 a la opción max_time_series_length, solo se usarán los 30 puntos temporales más recientes para modelar el componente de tendencia. Las 383 series temporales se siguen usando para modelar los componentes no tendenciales.
Sigue estos pasos para crear el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 2, max_time_series_length = 30 ) AS SELECT * FROM `bqml_tutorial.nyc_citibike_time_series` WHERE date < '2016-06-01';
La consulta tarda unos 35 segundos en completarse. Es tres veces más rápido que la consulta que has usado en la sección Crea un modelo para predecir varias series temporales con un espacio de búsqueda de hiperparámetros más pequeño. Debido a la sobrecarga de tiempo constante de la parte de la consulta que no es de entrenamiento, como el preprocesamiento de datos, la ganancia de velocidad es mucho mayor cuando el número de series temporales es mucho mayor que en este ejemplo. En el caso de un millón de series temporales, el aumento de la velocidad se aproxima a la proporción entre la longitud de las series temporales y el valor de la opción
max_time_series_length. En ese caso, el aumento de velocidad es superior a 10 veces.
Evaluar la precisión de las previsiones de un modelo con un espacio de búsqueda de hiperparámetros más pequeño y estrategias de entrenamiento rápido inteligentes
Sigue estos pasos para evaluar el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT AVG(mean_absolute_percentage_error) AS MAPE, AVG(symmetric_mean_absolute_percentage_error) AS sMAPE FROM ML.EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_max_order_2_fast_training`, TABLE `bqml_tutorial.nyc_citibike_time_series`, STRUCT(7 AS horizon, TRUE AS perform_aggregation));
Esta consulta devuelve un valor MAPE de 0.3515 y un valor sMAPE de 0.2473.
Recuerda que, si no se usan estrategias de entrenamiento rápido, la precisión de las previsiones da como resultado un valor MAPE de 0.3337 y un valor sMAPE de 0.2337.
La diferencia entre los dos conjuntos de valores de métricas es inferior al 3%, por lo que no es estadísticamente significativa.
En resumen, has usado un espacio de búsqueda de hiperparámetros más pequeño y estrategias de entrenamiento rápidas e inteligentes para que el entrenamiento de tu modelo sea más de 20 veces más rápido sin sacrificar la precisión de las previsiones. Como hemos mencionado anteriormente, con más series temporales, el aumento de velocidad de las estrategias de entrenamiento rápido inteligentes puede ser significativamente mayor. Además, la biblioteca ARIMA subyacente que usan los modelos ARIMA_PLUS se ha optimizado para que funcione 5 veces más rápido que antes. En conjunto, estas mejoras permiten predecir millones de series temporales en cuestión de horas.
Crear un modelo para predecir un millón de series temporales
En este paso, pronosticarás las ventas de más de un millón de productos de bebidas alcohólicas en diferentes tiendas usando los datos públicos de ventas de bebidas alcohólicas de Iowa. El entrenamiento del modelo utiliza un espacio de búsqueda de hiperparámetros pequeño, así como la estrategia de entrenamiento rápido inteligente.
Sigue estos pasos para evaluar el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_by_product` OPTIONS( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'item_description'], HOLIDAY_REGION = 'US', AUTO_ARIMA_MAX_ORDER = 2, MAX_TIME_SERIES_LENGTH = 30 ) AS SELECT store_number, item_description, date, SUM(bottles_sold) as total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE("2015-01-01") AND DATE("2021-12-31") GROUP BY store_number, item_description, date;
La consulta tarda aproximadamente 1 hora y 16 minutos en completarse.