從 IBM Netezza 遷移
本文件提供從 Netezza 遷移至 BigQuery 的概略指南。說明 Netezza 和 BigQuery 之間的基本架構差異,以及 BigQuery 提供的其他功能。這篇文章也會說明如何重新思考現有的資料模型和擷取、轉換及載入 (ETL) 程序,以便充分發揮 BigQuery 的效益。
這份文件適用於想從 Netezza 遷移至 BigQuery,並解決遷移過程中的技術問題的企業架構師、資料庫管理員、應用程式開發人員和 IT 安全專家。本文件將針對遷移程序的以下階段提供詳細資訊:
- 正在匯出資料
- 擷取資料
- 善用第三方工具
您也可以使用批次 SQL 翻譯大量遷移 SQL 指令碼,或是使用互動式 SQL 翻譯翻譯臨時查詢。預先發布版中的兩個工具都支援 IBM Netezza SQL/NZPLSQL。
架構比較
Netezza 是一項強大的系統,可協助您儲存及分析大量資料。不過,Netezza 等系統需要大量投資硬體、維護和授權。由於節點管理、每個來源的資料量和封存成本都存在挑戰,因此這項做法可能難以擴大規模。在 Netezza 中,儲存空間和處理能力受到硬體設備的限制。達到最高使用率後,擴充裝置容量的程序會變得複雜,甚至有時無法執行。
使用 BigQuery 時,您不必管理基礎架構,也不需要資料庫管理員。BigQuery 是全代管、PB 規模的無伺服器資料倉儲,可在幾十秒內掃描數十億個資料列,且不需索引。由於 BigQuery 共用 Google 的基礎架構,因此可以並行執行每項查詢,並同時在數萬部伺服器上執行。以下是 BigQuery 的核心技術:
- 資料欄儲存格式。資料是以資料欄而非資料列儲存,因此可達到極高的壓縮比和掃描處理量。
- 樹狀架構。查詢會在幾秒內分派,並在數千部機器上匯總結果。
Netezza 架構
Netezza 是硬體加速裝置,內建軟體資料抽象層。資料抽象層會管理機器中的資料分發作業,並在底層 CPU 和 FPGA 之間分散資料處理作業,以便最佳化查詢。
Netezza TwinFin 和 Striper 型號已於 2019 年 6 月停止支援。
下圖說明 Netezza 中的資料抽象層:
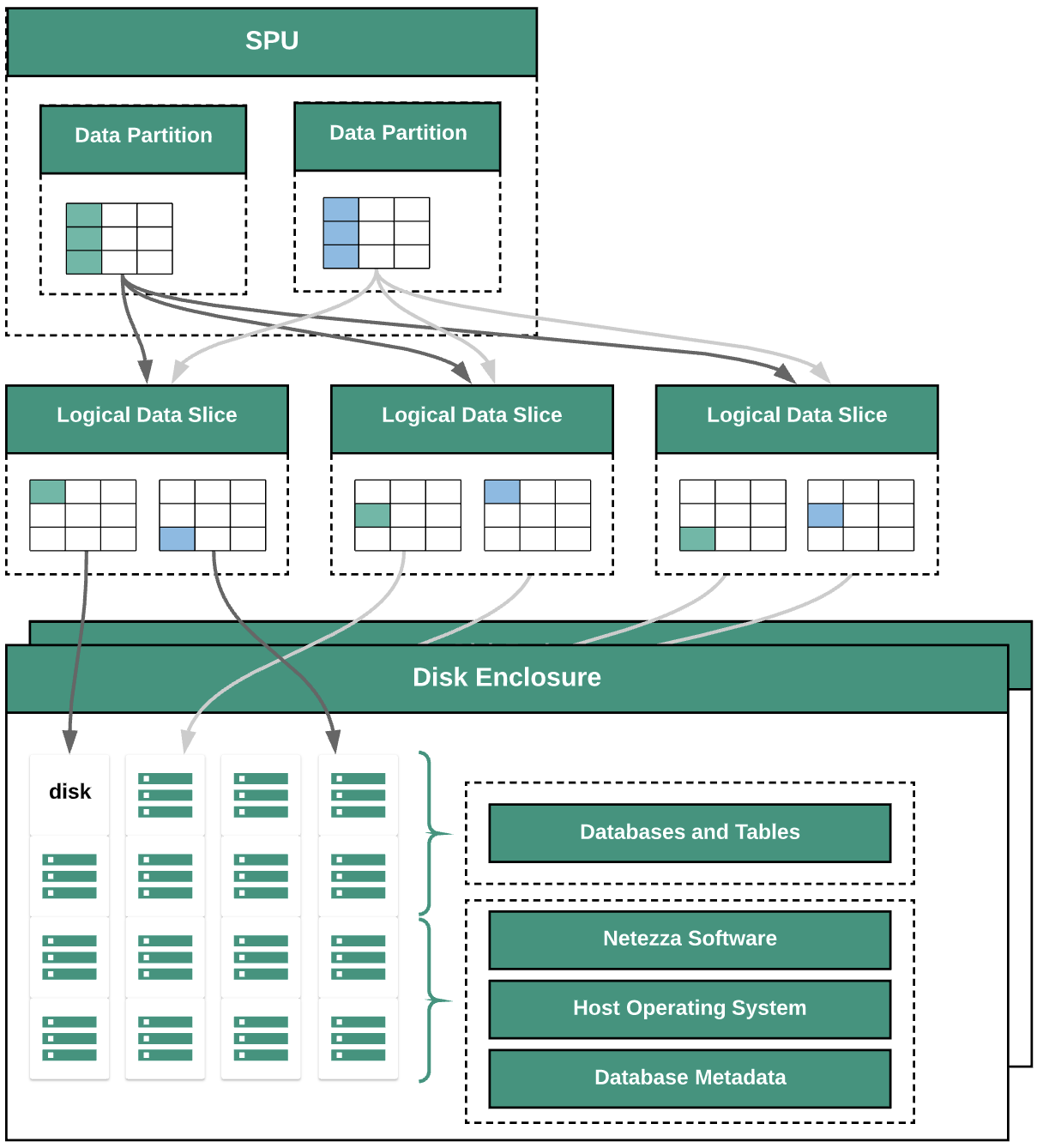
下圖顯示下列資料抽象層:
- 磁碟機箱。裝置內部用於掛載磁碟的實體空間。
- 磁碟:磁碟機箱內的實體磁碟會儲存資料庫和資料表。
- 資料切片。儲存在磁碟上的資料邏輯表示法。系統會使用分配鍵將資料分散至各資料區塊。您可以使用
nzds指令監控資料切片的狀態。 - 資料區隔。由特定 Snippet Processing Units (SPUs) 管理的資料切片邏輯表示法。每個 SPU 都擁有一或多個資料分區,其中包含 SPU 在查詢期間負責處理的使用者資料。
所有系統元件都透過網路結構連接。Netezza 機器會根據 IP 位址執行自訂通訊協定。
BigQuery 架構
BigQuery 是全代管的企業資料倉儲,內建機器學習、地理空間分析和商業智慧等功能,有助於管理及分析資料。詳情請參閱「什麼是 BigQuery?」。
BigQuery 會處理儲存空間和運算作業,提供持久的資料儲存空間,並針對數據分析查詢提供高效能的回應。詳情請參閱「BigQuery 簡介」。
如要瞭解 BigQuery 的定價,請參閱「瞭解 BigQuery 的快速擴充功能和簡單定價」。
遷移前
為確保資料倉儲遷移作業順利進行,請在專案時間表的早期開始規劃遷移策略。如要瞭解如何有系統地規劃遷移作業,請參閱「遷移的內容和方式:遷移作業架構」。
BigQuery 容量規劃
BigQuery 中的數據分析傳輸量以運算單元為單位。BigQuery 運算單元是 Google 專屬的運算、RAM 和網路傳輸量單位,用於執行 SQL 查詢。BigQuery 會依據查詢的大小和複雜程度,自動計算各項查詢所需的運算單元數量。
如要在 BigQuery 中執行查詢,請選取下列任一計費模式:
- 隨選。預設定價模式,系統會根據各項查詢處理作業的位元組數向您收費。
- 以容量為準的定價。您必須購買運算單元 (也就是虛擬 CPU)。購買運算單元時,您必須購買可用於執行查詢的專用處理容量。運算單元的使用承諾方案如下:
- 每年。承諾至少使用 365 天。
- 三年。承諾至少使用 365*3 天。
BigQuery 運算單元與 Netezza 的 SPU 有許多相似之處,例如 CPU、記憶體和資料處理,但兩者並非相同的測量單位。Netezza SPU 會固定對應至基礎硬體元件,而 BigQuery 運算單元則代表用於執行查詢的虛擬 CPU。為協助您估算時段,建議您使用 Cloud Monitoring 監控 BigQuery,並使用 BigQuery 分析稽核記錄。如要以圖表呈現 BigQuery 的空缺率,您也可以使用 Looker Studio 或 Looker 等工具。定期監控及分析時段使用率,有助您預估貴機構在 Google Cloud上成長時需要的總時段數。
舉例來說,假設您一開始預留 2,000 個 BigQuery 運算單元,以便同時執行 50 個中等複雜度的查詢。如果查詢執行時間一再超過數小時,且資訊主頁顯示運算單元使用率偏高,表示查詢可能未經過最佳化,或者您可能需要額外的 BigQuery 運算單元來支援工作負載。如要自行購買一年或三年承諾的運算單元,您可以使用 Google Cloud 主控台或 bq 指令列工具建立 BigQuery 預留空間。如果您是透過簽署離線協議的方式購買容量型方案,您的方案內容可能會不同於此處所述的詳細資料。
如要瞭解如何控管 BigQuery 的儲存空間和查詢處理費用,請參閱「最佳化工作負載」。
Google Cloud的安全防護
以下各節將說明常見的 Netezza 安全控管機制,以及如何在 Google Cloud 環境中保護資料倉儲。
身分與存取權管理
Netezza 資料庫包含一組完整整合的系統存取權控管功能,可讓使用者存取已授權的資源。
透過管理可登入作業系統的 Linux 使用者帳戶,即可透過網路控管 Netezza 的存取權。您可以使用 Netezza 資料庫使用者帳戶管理 Netezza 資料庫、物件和工作存取權,這些帳戶可建立與系統的 SQL 連線。
BigQuery 會使用 Google 的 身分與存取權管理 (IAM) 服務來管理資源的存取權限。BigQuery 提供的資源類型包括機構、專案、資料集、資料表和檢視表。在 IAM 政策階層中,資料集是專案的子項資源。資料表會繼承其所屬資料集的權限。
如要授予資源的存取權,請為使用者、群組或服務帳戶指派一或多個角色。機構和專案角色可控管執行工作或管理專案的存取權,而資料集角色則可控管查看或修改專案內資料的存取權。
IAM 提供以下類型的角色:
- 預先定義的角色。支援常見的用途和存取權控管模式。
- 基本角色。包含「擁有者」、「編輯者」和「檢視者」角色。基本角色針對特定服務提供精細的存取權,且由 Google Cloud管理。
- 自訂角色。根據使用者指定的權限清單,提供精細的存取權限。
當您同時把預先定義角色和基本角色指派給某個使用者時,您授予的權限就是這兩個角色權限的聯集。
資料列層級安全性
多層級安全性是一種抽象安全性模型,Netezza 會使用這項模型定義規則,以便控管使用者對列安全性表格 (RST) 的存取權。資料列安全性表格是指資料表,其資料列上設有安全性標籤,可篩除未具備適當權限的使用者。查詢的結果會因發出查詢的使用者權限而異。
如要在 BigQuery 中實現資料列層級安全防護機制,您可以使用授權的檢視表和資料列層級存取政策。如要進一步瞭解如何設計及實作這些政策,請參閱「BigQuery 資料列層級安全防護機制簡介」。
資料加密
Netezza 設備使用自加密硬碟 (SED),可強化設備中儲存資料的安全性和防護機制。SED 會在資料寫入磁碟時加密資料。每個磁碟都有磁碟加密金鑰 (DEK),該金鑰會在工廠設定並儲存在磁碟上。磁碟會在寫入資料時使用 DEK 加密資料,然後在從磁碟讀取資料時解密資料。磁碟的操作、加密和解密作業,對讀取和寫入資料的使用者而言是透明的。這個預設的加密和解密模式稱為安全擦除模式。
在安全擦除模式下,您不需要驗證金鑰或密碼就能解密及讀取資料。當磁碟必須因支援或保固問題而改作用途或退回時,SED 提供更強大的功能,可輕鬆快速地進行安全擦除。
Netezza 採用對稱式加密技術;如果您的資料是欄位層級加密,您可以使用下列解密函式來讀取及匯出資料:
varchar = decrypt(varchar text, varchar key [, int algorithm [, varchar IV]]); nvarchar = decrypt(nvarchar text, nvarchar key [, int algorithm[, varchar IV]]);
儲存在 BigQuery 中的所有資料都會採用靜態加密。如果您想自行控管加密作業,可以針對 BigQuery 使用客戶代管的加密金鑰 (CMEK)。使用 CMEK 時,您可以在 Cloud Key Management Service 中控制及管理用來保護您資料的金鑰加密金鑰,而不是由 Google 管理。詳情請參閱「靜態資料加密」。
效能基準測試
為了在遷移過程中追蹤進度和改善情形,請務必為目前狀態的 Netezza 環境建立基準效能。如要建立基準,請選取一組代表性查詢,這些查詢是從使用應用程式 (例如 Tableau 或 Cognos) 擷取。
| 環境 | Netezza | BigQuery |
|---|---|---|
| 資料大小 | size TB | - |
| 查詢 1:name (完整資料表掃描) | mm:ss.ms | - |
| 查詢 2:name | mm:ss.ms | - |
| 查詢 3:name | mm:ss.ms | - |
| 總計 | mm:ss.ms | - |
基礎專案設定
您必須先完成專案設定,才能為資料遷移作業佈建儲存空間資源。
- 如要設定專案並在專案層級啟用 IAM,請參閱 Google Cloud Well-Architected Framework。
- 如要設計基礎資源,讓雲端部署作業符合企業需求,請參閱「 Google Cloud中的登陸區設計」。
- 如要瞭解將內部部署資料倉儲遷移至 BigQuery 時所需的資料管理和控管機制,請參閱「資料安全性和管理的概略說明」。
網路連線
在內部部署資料中心 (Netezza 執行個體所在位置) 和 Google Cloud環境之間,必須建立可靠且安全的網路連線。如要瞭解如何確保連線安全,請參閱「BigQuery 資料治理簡介」。上傳資料擷取內容時,網路頻寬可能會成為限制因素。如要瞭解如何滿足資料傳輸需求,請參閱「增加網路頻寬」一文。
支援的資料類型和屬性
Netezza 資料類型與 BigQuery 資料類型不同。如要瞭解 BigQuery 資料類型,請參閱「資料類型」一文。如要進一步比較 Netezza 和 BigQuery 資料類型,請參閱 IBM Netezza SQL 翻譯指南。
SQL 比較
Netezza 資料 SQL 包含 DDL、DML 和 Netezza 專屬的資料控制語言 (DCL),這些語言與 GoogleSQL 不同。GoogleSQL 與 SQL 2011 標準相容,並具備可查詢巢狀和重複資料的擴充功能。如果您使用的是 BigQuery 舊版 SQL,請參閱「舊版 SQL 函式與運算子」一文。如要進一步比較 Netezza 和 BigQuery SQL 以及函式,請參閱 IBM Netezza SQL 翻譯指南。
如要協助 SQL 程式碼遷移作業,請使用批次 SQL 翻譯功能大量遷移 SQL 程式碼,或是使用互動式 SQL 翻譯功能翻譯臨時查詢。
函式比較
請務必瞭解 Netezza 函式如何對應至 BigQuery 函式。舉例來說,Netezza Months_Between 函式會輸出小數,而 BigQuery DateDiff 函式會輸出整數。因此,您必須使用自訂 UDF 函式才能輸出正確的資料類型。如需 Netezza SQL 和 GoogleSQL 函式之間的詳細比較,請參閱 IBM Netezza SQL 翻譯指南。
資料遷移
如要將資料從 Netezza 遷移至 BigQuery,您必須從 Netezza 匯出資料,並在 Google Cloud上轉移及暫存資料,然後將資料載入 BigQuery。本節將概略說明資料遷移程序。如需資料遷移程序的詳細說明,請參閱「結構定義和資料遷移程序」。如要詳細比較 Netezza 和 BigQuery 支援的資料類型,請參閱 IBM Netezza SQL 翻譯指南。
從 Netezza 匯出資料
如要探索 Netezza 資料庫資料表中的資料,建議您以 CSV 格式匯出至外部資料表。詳情請參閱「將資料卸載至遠端用戶端系統」。您也可以使用 JDBC/ODBC 連接器,透過第三方系統 (例如 Informatica 或自訂 ETL) 讀取資料,產生 CSV 檔案。
Netezza 僅支援匯出每個資料表的未壓縮平面檔案 (CSV)。不過,如果您要匯出大型資料表,未壓縮的 CSV 檔案可能會非常大。盡可能將 CSV 轉換為支援結構定義的格式,例如 Parquet、Avro 或 ORC,這樣匯出檔案的大小會比較小,可靠性也會提高。如果 CSV 是唯一可用的格式,建議您在將檔案上傳至 Google Cloud前先壓縮匯出檔案,以縮減檔案大小。縮減檔案大小有助於加快上傳速度,並提高傳輸的可靠性。如果您將檔案轉移至 Cloud Storage,可以在 gcloud storage cp 指令中使用 --gzip-local 標記,這樣系統會先壓縮檔案再上傳。
資料移轉和暫存
資料匯出後,需要在Google Cloud上轉移及暫存。您可以根據要轉移的資料量和可用的網路頻寬,選擇多種資料移轉方式。詳情請參閱「結構定義與資料移轉總覽」。
使用 Google Cloud CLI 時,您可以自動化並並行處理將檔案傳輸至 Cloud Storage 的作業。將檔案大小限制在 4 TB (未壓縮),以便加快載入至 BigQuery 的速度。不過,您必須先匯出結構定義。這是使用分割和分群功能,為 BigQuery 進行最佳化的絕佳時機。
使用 gcloud storage bucket create 建立暫存值區,以便儲存匯出的資料,然後使用 gcloud storage cp 將資料匯出檔案轉移至 Cloud Storage 值區。
gcloud CLI 會使用多執行緒和多重處理的組合,自動執行複製作業。
將資料載入 BigQuery
資料在 Google Cloud上完成階段後,您可以透過多種方式將資料載入 BigQuery。詳情請參閱「將結構定義和資料載入 BigQuery」一文。
合作夥伴工具和支援
您可以在遷移期間獲得合作夥伴的支援。如要協助 SQL 程式碼遷移作業,請使用批次 SQL 翻譯功能大量遷移 SQL 程式碼。
許多 Google Cloud 合作夥伴也提供資料倉儲遷移服務。如需合作夥伴和提供的解決方案清單,請參閱「與具備 BigQuery 專業知識的夥伴合作」。
遷移後
資料遷移完成後,您就可以開始調整Google Cloud 的使用方式,以滿足業務需求。這可能包括使用Google Cloud的探索和視覺化工具,為業務利益相關者找出洞見、改善成效不佳的查詢,或開發可協助使用者採用的計畫。
透過網際網路連線至 BigQuery API
下圖顯示外部應用程式如何使用 API 連線至 BigQuery:
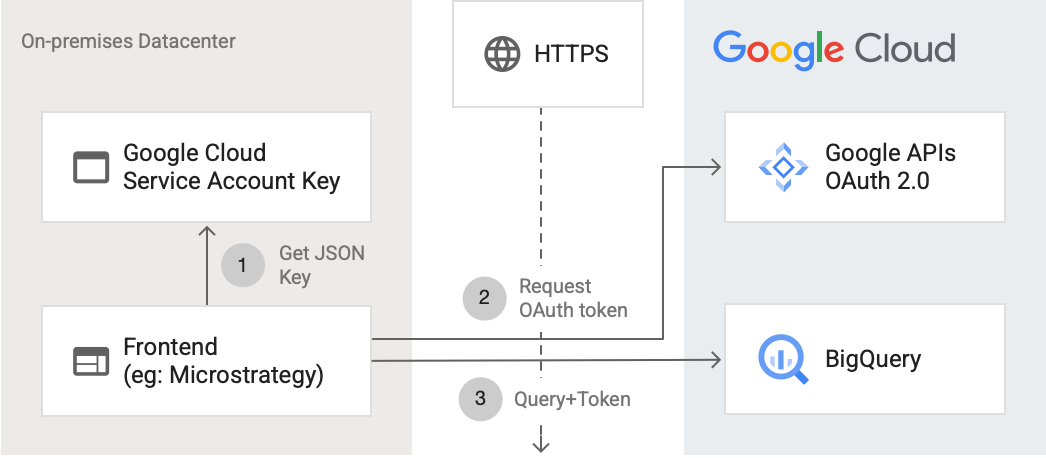
下圖顯示以下步驟:
- 在 Google Cloud中,系統會使用 IAM 權限建立服務帳戶。服務帳戶金鑰會以 JSON 格式產生,並複製到前端伺服器 (例如 MicroStrategy)。
- 前端會讀取金鑰,並透過 HTTPS 向 Google API 要求 OAuth 權杖。
- 前端隨後會將 BigQuery 要求連同符記傳送至 BigQuery。
詳情請參閱「授權 API 要求」。
針對 BigQuery 進行最佳化
GoogleSQL 支援 SQL 2011 標準,並提供可查詢巢狀和重複資料的擴充功能。為 BigQuery 最佳化查詢是改善效能和回應時間的關鍵。
使用 UDF 取代 BigQuery 中的 Months_Between 函式
Netezza 會將一個月的日期數設為 31 天。下列自訂 UDF 可重建 Netezza 函式,並提供相近的準確度,您可以從查詢中呼叫此函式:
CREATE TEMP FUNCTION months_between(date_1 DATE, date_2 DATE) AS ( CASE WHEN date_1 = date_2 THEN 0 WHEN EXTRACT(DAY FROM DATE_ADD(date_1, INTERVAL 1 DAY)) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(date_1,date_2, MONTH) WHEN EXTRACT(DAY FROM date_1) = 1 AND EXTRACT(DAY FROM DATE_ADD(date_2, INTERVAL 1 DAY)) = 1 THEN date_diff(DATE_ADD(date_1, INTERVAL -1 DAY), date_2, MONTH) + 1/31 ELSE date_diff(date_1, date_2, MONTH) - 1 + ((EXTRACT(DAY FROM date_1) + (31 - EXTRACT(DAY FROM date_2))) / 31) END );
遷移 Netezza 預存程序
如果您在 ETL 工作負載中使用 Netezza 儲存程序來建構事實資料表,則必須將這些儲存程序遷移至與 BigQuery 相容的 SQL 查詢。Netezza 會使用 NZPLSQL 指令碼語言搭配儲存程序運作。NZPLSQL 是以 Postgres PL/pgSQL 語言為基礎。詳情請參閱 IBM Netezza SQL 翻譯指南。
模擬 Netezza ASCII 的自訂 UDF
下列 BigQuery 自訂 UDF 會修正資料欄中的編碼錯誤:
CREATE TEMP FUNCTION ascii(X STRING) AS (TO_CODE_POINTS(x)[ OFFSET (0)]);
後續步驟
- 瞭解如何最佳化工作負載,以便整體提升效能並降低成本。
- 瞭解如何在 BigQuery 中最佳化儲存空間。
- 請參閱 IBM Netezza SQL 翻譯指南。