在 BigQuery Studio 笔记本中运行 PySpark 代码
本文档介绍了如何在 BigQuery Python 笔记本中运行 PySpark 代码。
准备工作
如果您尚未创建项目和 Cloud Storage 存储桶,请先创建这些资源。 Google Cloud
设置项目
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 如果您没有可用的 Cloud Storage 存储桶,请在项目中创建 Cloud Storage 存储桶。
设置笔记本
- 笔记本凭证:默认情况下,笔记本会话会使用您的用户凭证。或者,它也可以使用会话服务账号凭证。
- 用户凭证:您的用户账号必须具有以下 Identity and Access Management 角色:
- Dataproc Editor(
roles/dataproc.editor角色) - BigQuery Studio User(
roles/bigquery.studioUser角色) - 会话服务账号的 Service Account User (roles/iam.serviceAccountUser) 角色。
此角色包含模拟服务账号所需的
iam.serviceAccounts.actAs权限。
- Dataproc Editor(
- 服务账号凭证:如果您想为笔记本会话指定服务账号凭证,而不是用户凭证,则会话服务账号必须具有以下角色:
- 用户凭证:您的用户账号必须具有以下 Identity and Access Management 角色:
- 笔记本运行时:除非您选择其他运行时,否则笔记本会使用默认的 Vertex AI 运行时。如果您想定义自己的运行时,请在 Google Cloud 控制台的运行时页面中创建运行时。请注意,使用 NumPy 库时,在笔记本运行时中使用 NumPy 1.26 版,该版本受 Spark 3.5 支持。
- 笔记本凭证:默认情况下,笔记本会话会使用您的用户凭证。或者,它也可以使用会话服务账号凭证。
在 Google Cloud 控制台中,前往 BigQuery 页面。
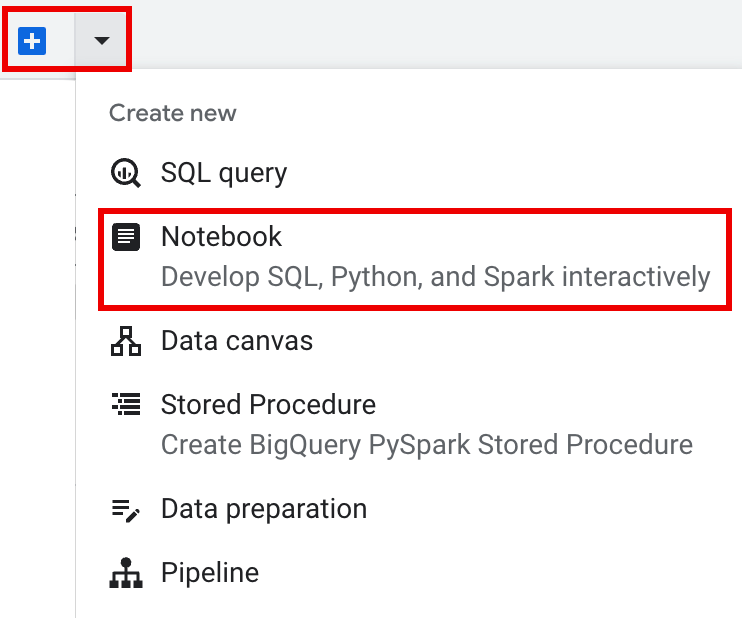
在详细信息窗格的标签页栏中,点击 + 号旁边的 箭头,然后点击笔记本。
- 在笔记本中配置并创建单个会话。
- 在互动式会话模板中配置 Spark 会话,然后使用该模板在笔记本中配置和创建会话。BigQuery 提供了一个
Query using Spark功能,可帮助您按照模板化 Spark 会话标签页下所述开始编写模板化会话的代码。 在编辑器窗格的标签页栏中,点击 + 号旁边的 下拉箭头,然后点击笔记本。
在笔记本单元中复制并运行以下代码,以配置和创建基本 Spark 会话。
- APP_NAME:会话的可选名称。
- 可选的会话设置:您可以添加 Dataproc API
Session设置来自定义会话。下面是一些示例:RuntimeConfig: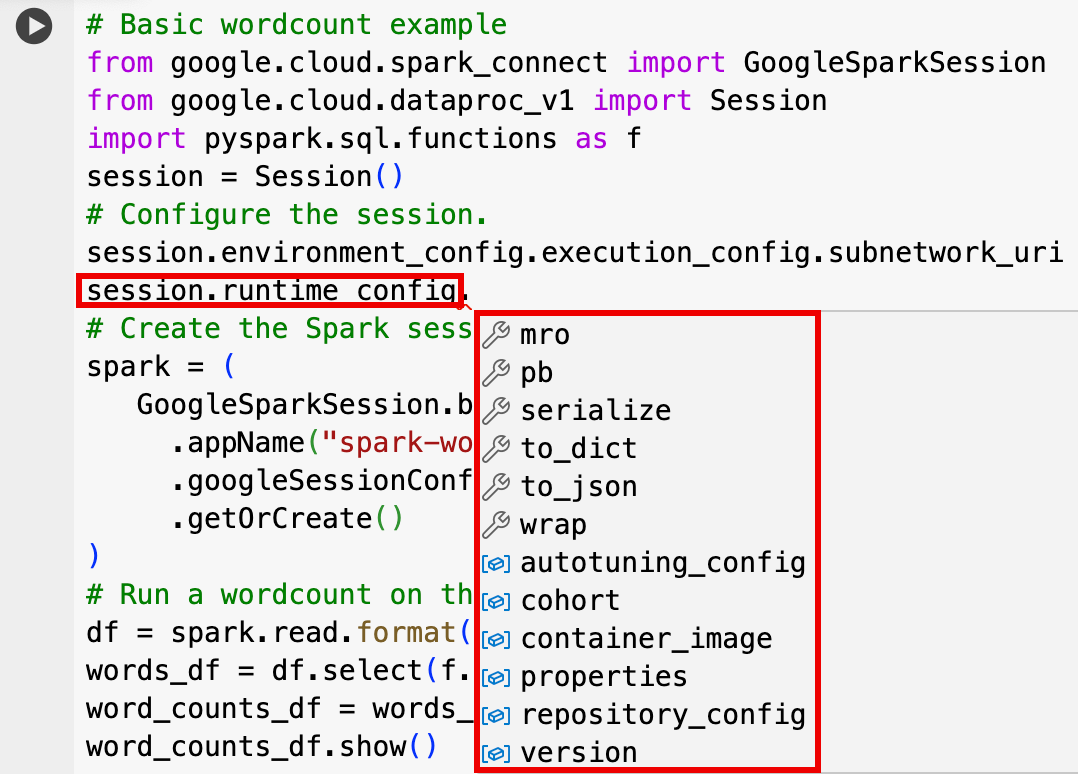
session.runtime_config.properties={spark.property.key1:VALUE_1,...,spark.property.keyN:VALUE_N}session.runtime_config.container_image = path/to/container/image
EnvironmentConfig: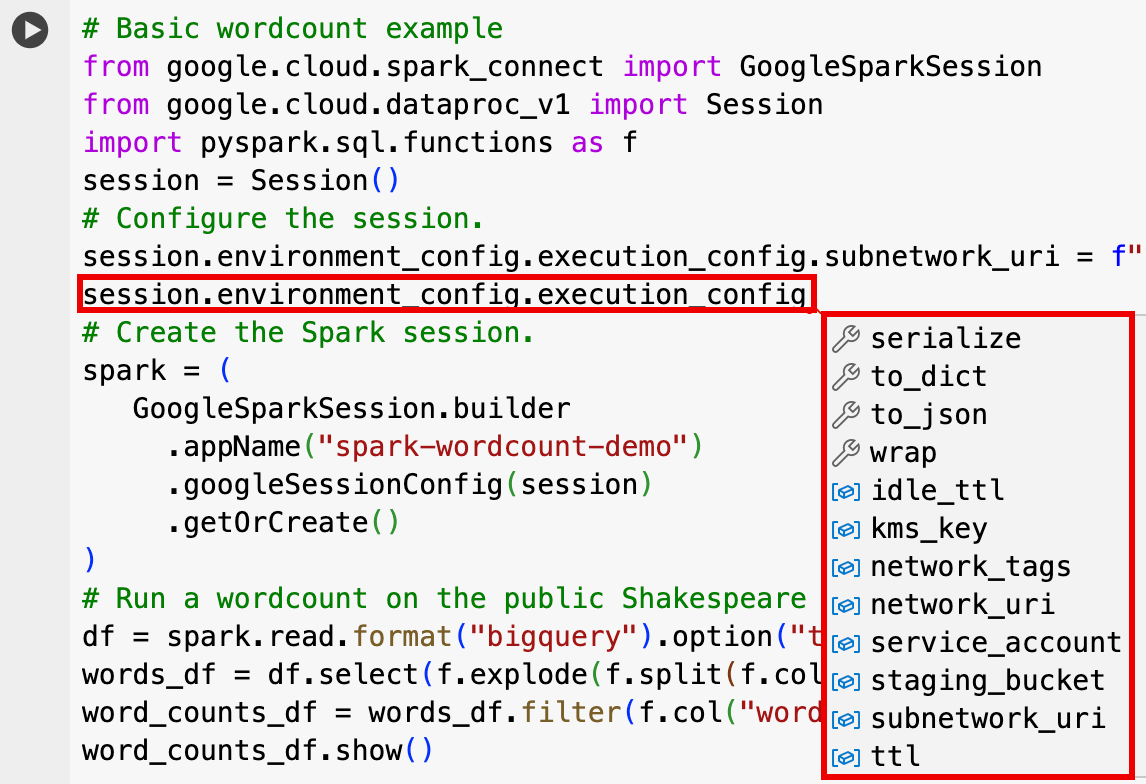
- session.environment_config.execution_config.subnetwork_uri = "SUBNET_NAME"
session.environment_config.execution_config.ttl = {"seconds": VALUE}session.environment_config.execution_config.service_account = SERVICE_ACCOUNT
- 在编辑器窗格的标签页栏中,点击 + 号旁边的 下拉箭头,然后点击笔记本。
- 在从模板开始下方,点击使用 Spark 查询,然后点击使用模板以将代码插入笔记本中。
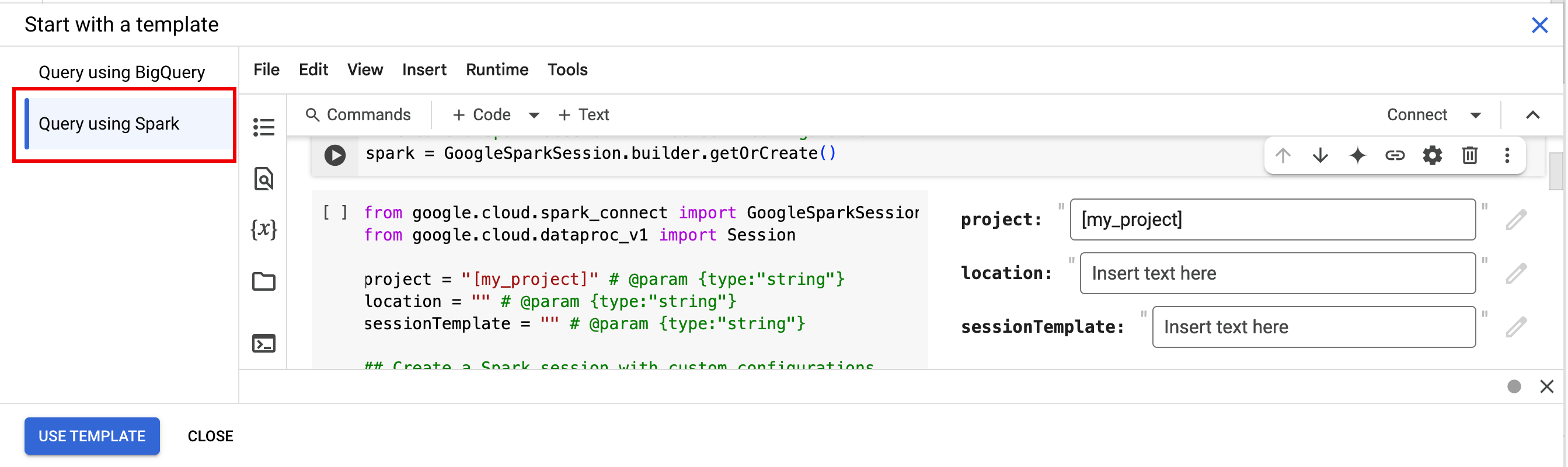
- 按照备注中所述指定变量。
- 您可以删除在笔记本中插入的任何其他示例代码单元。
- PROJECT:您的项目 ID,列在 Google Cloud 控制台信息中心的项目信息部分中。
- LOCATION:笔记本会话将在其中运行的 Compute Engine 区域。如果未提供,则默认位置为创建笔记本的虚拟机的区域。
SESSION_TEMPLATE:现有互动式会话模板的名称。会话配置设置是从模板中获取的。该模板还必须指定以下设置:
- 运行时版本
2.3+ 笔记本类型:
Spark Connect示例:
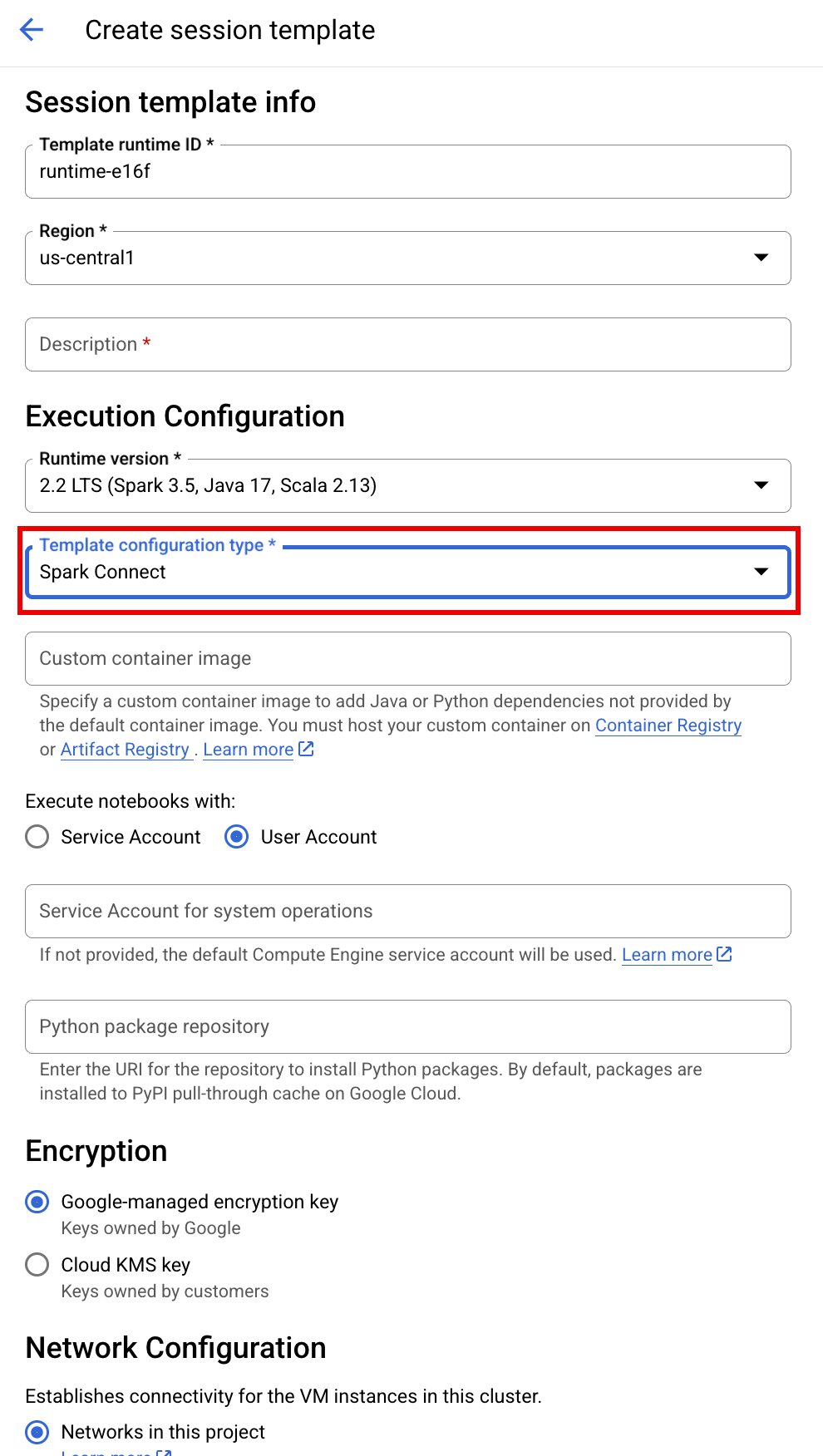
- 运行时版本
APP_NAME:会话的可选名称。
- 对公开的莎士比亚数据集运行字数统计。
- 创建一个包含保存在 BigLake metastore 中的元数据的 Iceberg 表。
- APP_NAME:会话的可选名称。
- PROJECT:您的项目 ID,列在 Google Cloud 控制台信息中心的项目信息部分中。
- REGION 和 SUBNET_NAME:指定 Compute Engine 区域和会话区域中子网的名称。 Serverless for Apache Spark 会在指定的子网中启用专用 Google 访问通道 (PGA)。
- LOCATION:默认的
BigQuery_metastore_config.location和spark.sql.catalog.{catalog}.gcp_location为US,但您可以选择任何受支持的 BigQuery 位置。 - BUCKET 和 WAREHOUSE_DIRECTORY:用于 Iceberg 数据仓库目录的 Cloud Storage 存储桶和文件夹。
- CATALOG_NAME 和 NAMESPACE:Iceberg 目录名称和命名空间组合起来,用于标识 Iceberg 表 (
catalog.namespace.table_name)。 - APP_NAME:会话的可选名称。
在 Google Cloud 控制台中,前往 BigQuery 页面。
在项目资源窗格中,点击您的项目,然后点击您的命名空间以列出
sample_iceberg_table表。点击详细信息表以查看打开目录表配置信息。输入和输出格式是 Iceberg 使用的标准 Hadoop
InputFormat和OutputFormat类格式。
点击工具栏中的 + 代码,插入新的代码单元。新的代码单元会显示
Start coding or generate with AI。点击生成。在生成编辑器中,输入自然语言提示,然后点击
enter。请务必在提示中添加关键字spark或pyspark。示例提示:
create a spark dataframe from order_items and filter to orders created in 2024
示例输出:
spark.read.format("bigquery").option("table", "sqlgen-testing.pysparkeval_ecommerce.order_items").load().filter("year(created_at) = 2024").createOrReplaceTempView("order_items") df = spark.sql("SELECT * FROM order_items")如需让 Gemini Code Assist 提取相关表和架构,请为 Dataproc Metastore 实例启用 Data Catalog 同步。
确保您的用户账号有权访问 Data Catalog 查询表。为此,请分配
DataCatalog.Viewer角色。- 在笔记本单元中运行
spark.stop()。 - 在笔记本中终止运行时:
- 点击运行时选择器,然后点击管理会话。
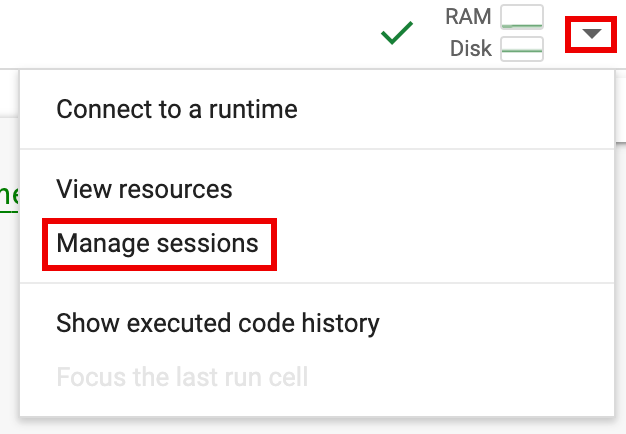
- 在活跃会话对话框中,点击终止图标,然后点击终止。

- 点击运行时选择器,然后点击管理会话。
从 Google Cloud 控制台安排笔记本代码(笔记本价格适用)。
将笔记本代码作为批量工作负载运行(按 Serverless for Apache Spark 价格付费)。
将笔记本代码下载到本地终端或 Cloud Shell 中的文件中。
在 Google Cloud 控制台的 BigQuery Studio 页面上的探索器面板中打开笔记本。
从文件菜单中选择下载来下载笔记本代码,然后选择
Download .py。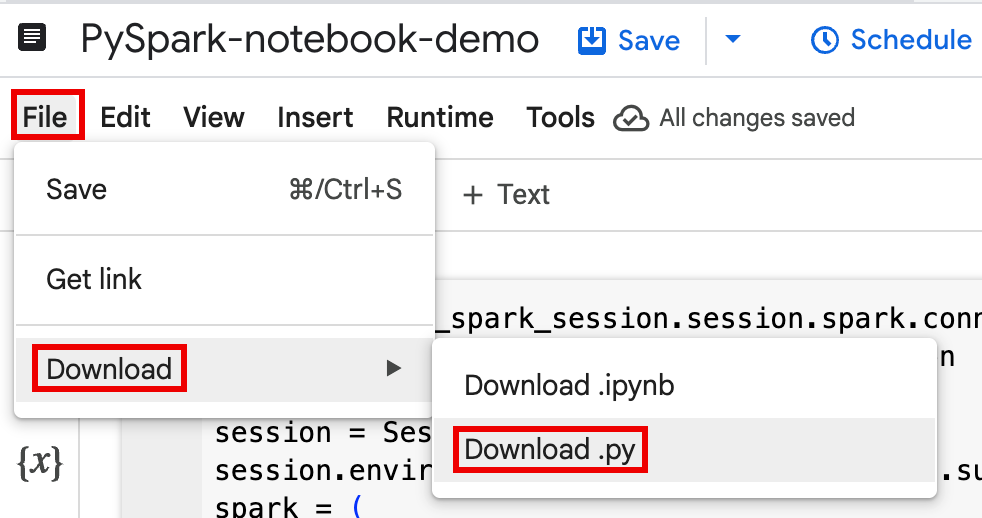
生成
requirements.txt。- 将
pipreqs安装到您保存.py文件的目录中。pip install pipreqs
运行
pipreqs以生成requirements.txt。pipreqs filename.py
使用 Google Cloud CLI 将本地
requirements.txt文件复制到 Cloud Storage 中的存储桶。gcloud storage cp requirements.txt gs://BUCKET/
- 将
通过修改下载的
.py文件来更新 Spark 会话代码。移除或注释掉所有 Shell 脚本命令。
移除用于配置 Spark 会话的代码,然后将配置参数指定为批量工作负载提交参数。(请参阅提交 Spark 批量工作负载)。
示例:
从代码中移除以下会话子网配置行:
session.environment_config.execution_config.subnetwork_uri = "{subnet_name}"运行批量工作负载时,请使用
--subnet标志指定子网。gcloud dataproc batches submit pyspark \ --subnet=SUBNET_NAME
使用简单的会话创建代码段。
简化前的下载笔记本代码示例。
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session
session = Session() spark = DataprocSparkSession \ .builder \ .appName("CustomSparkSession") .dataprocSessionConfig(session) \ .getOrCreate()
简化后的批量工作负载代码。
from pyspark.sql import SparkSession
spark = SparkSession \ .builder \ .getOrCreate()
-
如需查看相关说明,请参阅提交 Spark 批量工作负载。
请务必添加 --deps-bucket 标志,以指向包含您的
requirements.txt文件的 Cloud Storage 存储桶。示例:
gcloud dataproc batches submit pyspark FILENAME.py \ --region=REGION \ --deps-bucket=BUCKET \ --version=2.3
注意:
- FILENAME:您下载并修改的笔记本代码文件的名称。
- REGION:您的集群所在的 Compute Engine 区域。
- BUCKET 包含
requirements.txt文件的 Cloud Storage 存储桶的名称。 --version:选择 Spark 运行时版本 2.3 来运行批量工作负载。
提交代码。
- 测试批量工作负载代码后,您可以使用
git客户端(例如 GitHub、GitLab 或 Bitbucket)将.ipynb或.py文件提交到代码库,作为 CI/CD 流水线的一部分。
- 测试批量工作负载代码后,您可以使用
使用 Cloud Composer 安排批量工作负载。
- YouTube 视频演示:充分发挥与 BigQuery 集成的 Apache Spark 的强大功能。
- 将 BigLake metastore 与 Dataproc 搭配使用
- 将 BigLake metastore 与 Serverless for Apache Spark 搭配使用
价格
如需了解价格信息,请参阅 BigQuery 笔记本运行时价格。
打开 BigQuery Studio Python 笔记本
在 BigQuery Studio 笔记本中创建 Spark 会话
您可以使用 BigQuery Studio Python 笔记本创建 Spark Connect 交互式会话。每个 BigQuery Studio 笔记本只能有一个与之关联的活跃 Spark 会话。
您可以通过以下方式在 BigQuery Studio Python 笔记本中创建 Spark 会话:
单个会话
如需在新笔记本中创建 Spark 会话,请执行以下操作:
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )替换以下内容:
基于模板的 Spark 会话
您可以在笔记本单元中输入并运行代码,以根据现有的会话模板创建 Spark 会话。 您在笔记本代码中提供的任何
session配置设置都会覆盖会话模板中设置的任何相同设置。如需快速上手,请使用
Query using Spark模板,使用 Spark 会话模板代码预先填充笔记本:from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Configure the session with an existing session template. session_template = "SESSION_TEMPLATE" session.session_template = f"projects/{project}/locations/{location}/sessionTemplates/{session_template}" # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )在 BigQuery Studio 笔记本中编写和运行 PySpark 代码
在笔记本中创建 Spark 会话后,使用该会话在笔记本中运行 Spark 笔记本代码。
Spark Connect PySpark API 支持:Spark Connect 笔记本会话支持大多数 PySpark API,包括 DataFrame、Functions 和 Column,但不支持 SparkContext、RDD 和其他 PySpark API。如需了解详情,请参阅 Spark 3.5 支持的内容。
Spark Connect 笔记本直接写入:BigQuery Studio 笔记本中的 Spark 会话会预先配置 Spark BigQuery 连接器,以实现 DIRECT 数据写入。DIRECT 写入方法使用 BigQuery Storage Write API,该 API 可将数据直接写入 BigQuery;INDIRECT 写入方法(Serverless for Apache Spark 批处理的默认方法)将数据写入中间 Cloud Storage 存储桶,然后将数据写入 BigQuery(如需详细了解 INDIRECT 写入,请参阅从 BigQuery 读取数据以及将数据写入 BigQuery)。
Dataproc 特有的 API:Dataproc 通过扩展
addArtifacts方法,简化了向 Spark 会话动态添加PyPI软件包的操作。您可以使用version-scheme格式(类似于pip install)指定列表。这会指示 Spark Connect 服务器在所有集群节点上安装软件包及其依赖项,以便可供工作器用于 UDF。示例:在集群上安装指定的
textdistance版本和最新的兼容random2库,以允许使用textdistance和random2的 UDF 在 工作器节点上运行。spark.addArtifacts("textdistance==4.6.1", "random2", pypi=True)笔记本代码帮助:当您将指针悬停在类名称或方法名称上时,BigQuery Studio 笔记本会提供代码帮助;当您输入代码时,会提供代码补全帮助。
在以下示例中,输入
DataprocSparkSession,然后将指针悬停在该类名称上,系统会显示代码补全和文档帮助。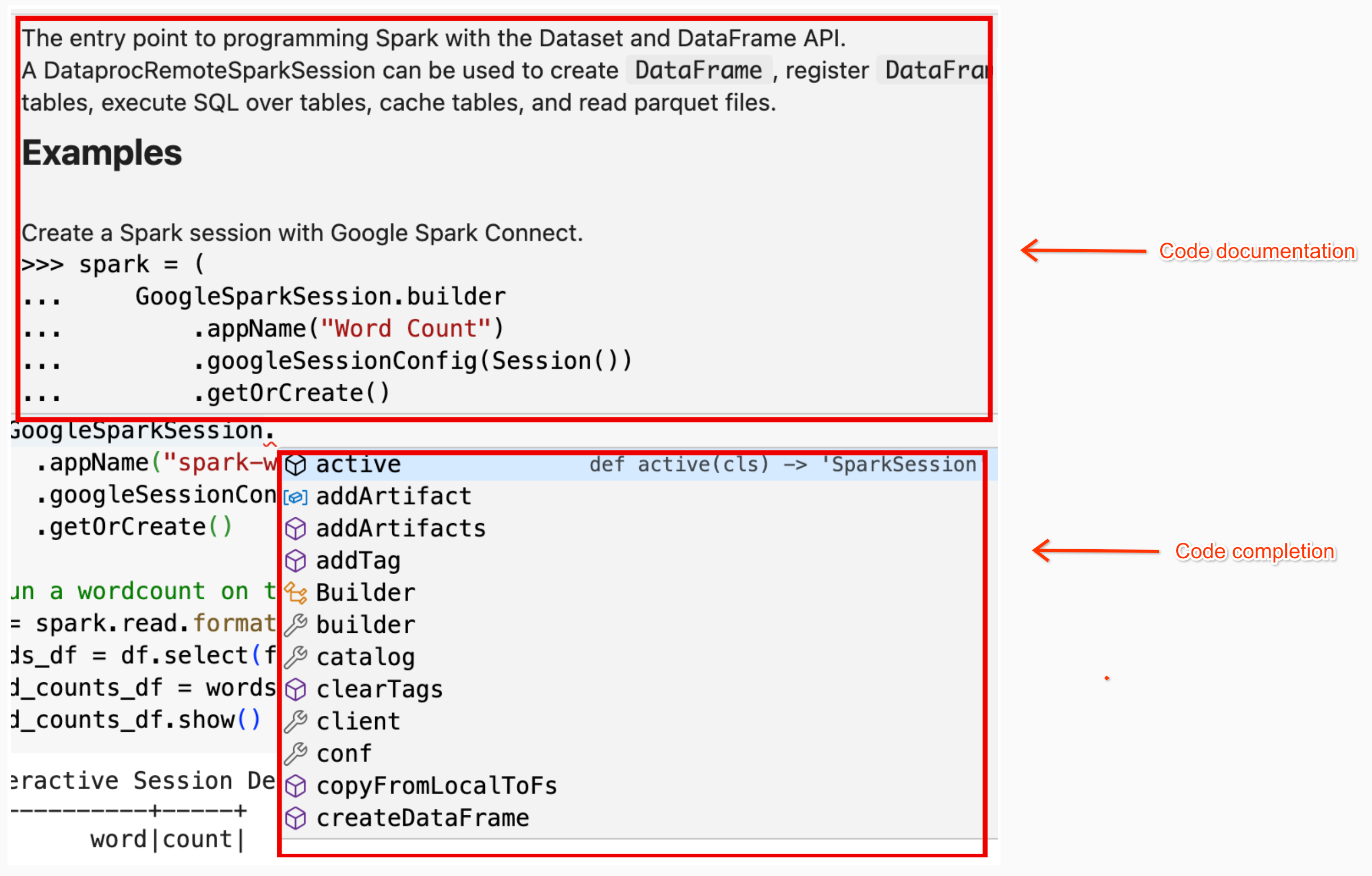
BigQuery Studio 笔记本 PySpark 示例
本部分提供了包含 PySpark 代码的 BigQuery Studio Python 笔记本示例,用于执行以下任务:
字数统计
以下 Pyspark 示例创建一个 Spark 会话,然后统计公开
bigquery-public-data.samples.shakespeare数据集中的字词出现次数。# Basic wordcount example from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Run a wordcount on the public Shakespeare dataset. df = spark.read.format("bigquery").option("table", "bigquery-public-data.samples.shakespeare").load() words_df = df.select(f.explode(f.split(f.col("word"), " ")).alias("word")) word_counts_df = words_df.filter(f.col("word") != "").groupBy("word").agg(f.count("*").alias("count")).orderBy("word") word_counts_df.show()替换以下内容:
输出:
单元输出列出了字数统计输出的示例。如需在 Google Cloud 控制台中查看会话详情,请点击交互式会话详情视图链接。如需监控 Spark 会话,请点击会话详情页面上的查看 Spark 界面。

Interactive Session Detail View: LINK +------------+-----+ | word|count| +------------+-----+ | '| 42| | ''All| 1| | ''Among| 1| | ''And| 1| | ''But| 1| | ''Gamut'| 1| | ''How| 1| | ''Lo| 1| | ''Look| 1| | ''My| 1| | ''Now| 1| | ''O| 1| | ''Od's| 1| | ''The| 1| | ''Tis| 4| | ''When| 1| | ''tis| 1| | ''twas| 1| | 'A| 10| |'ARTEMIDORUS| 1| +------------+-----+ only showing top 20 rows
Iceberg 表
运行 PySpark 代码以创建包含 BigLake metastore 元数据的 Iceberg 表
以下示例代码会创建一个
sample_iceberg_table,其中包含存储在 BigLake metastore 中的表元数据,然后查询该表。from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.functions as f # Create the Dataproc Serverless session. session = Session() # Set the session configuration for BigLake Metastore with the Iceberg environment. project_id = "PROJECT" region = "REGION" subnet_name = "SUBNET_NAME" location = "LOCATION" session.environment_config.execution_config.subnetwork_uri = f"{subnet_name}" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY" catalog = "CATALOG_NAME" namespace = "NAMESPACE" session.runtime_config.properties[f"spark.sql.catalog.{catalog}"] = "org.apache.iceberg.spark.SparkCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.catalog-impl"] = "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_project"] = f"{project_id}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_location"] = f"{location}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.warehouse"] = f"{warehouse_dir}" # Create the Spark Connect session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Create the namespace in BigQuery. spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create the Iceberg table. spark.sql("DROP TABLE IF EXISTS `sample_iceberg_table`"); spark.sql("CREATE TABLE sample_iceberg_table (id int, data string) USING ICEBERG;") spark.sql("DESCRIBE sample_iceberg_table;") # Insert table data and query the table. spark.sql("INSERT INTO sample_iceberg_table VALUES (1, \"first row\");") # Alter table, then query and display table data and schema. spark.sql("ALTER TABLE sample_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE sample_iceberg_table;") df = spark.sql("SELECT * FROM sample_iceberg_table") df.show() df.printSchema()注意:
单元输出列出了
sample_iceberg_table以及添加的列,并显示了指向控制台 Google Cloud 中交互式会话详情页面的链接。您可以点击会话详情页面上的查看 Spark 界面,以监控 Spark 会话。
Interactive Session Detail View: LINK +---+---------+------------+ | id| data|newDoubleCol| +---+---------+------------+ | 1|first row| NULL| +---+---------+------------+ root |-- id: integer (nullable = true) |-- data: string (nullable = true) |-- newDoubleCol: double (nullable = true)
在 BigQuery 中查看表详情
如需在 BigQuery 中查看 Iceberg 表详情,请执行以下步骤:
其他示例
从 Pandas DataFrame (
df) 创建 SparkDataFrame(sdf)。sdf = spark.createDataFrame(df) sdf.show()在 Spark
DataFrames上运行聚合。from pyspark.sql import functions as F sdf.groupby("segment").agg( F.mean("total_spend_per_user").alias("avg_order_value"), F.approx_count_distinct("user_id").alias("unique_customers") ).show()使用 Spark-BigQuery 连接器从 BigQuery 读取数据。
spark.conf.set("viewsEnabled","true") spark.conf.set("materializationDataset","my-bigquery-dataset") sdf = spark.read.format('bigquery') \ .load(query)使用 Gemini Code Assist 编写 Spark 代码
您可以让 Gemini Code Assist 在笔记本中生成 PySpark 代码。Gemini Code Assist 会提取并使用相关的 BigQuery 和 Dataproc Metastore 表及其架构来生成代码响应。
如需在笔记本中生成 Gemini Code Assist 代码,请执行以下操作:
Gemini Code Assist 代码生成提示
结束 Spark 会议
您可以在 BigQuery Studio 笔记本中执行以下任一操作来停止 Spark Connect 会话:
编排 BigQuery Studio 笔记本代码
您可以通过以下方式编排 BigQuery Studio 笔记本代码:
通过 Google Cloud 控制台安排笔记本代码
您可以通过以下方式安排笔记本代码:
将笔记本代码作为批量工作负载运行
如需将 BigQuery Studio 笔记本代码作为批量工作负载运行,请完成以下步骤。
排查笔记本错误
如果包含 Spark 代码的单元发生故障,您可以通过点击单元输出中的交互式会话详情视图链接来排查错误(请参阅 Wordcount 和 Iceberg 表示例)。
已知问题和解决方案
错误:使用 Python 版本
3.10创建的笔记本运行时在尝试连接到 Spark 会话时可能会导致PYTHON_VERSION_MISMATCH错误。解决方案:使用 Python 版本
3.11重新创建运行时。后续步骤