PySpark-Code in BigQuery Studio-Notebooks ausführen
In diesem Dokument wird beschrieben, wie Sie PySpark-Code in einem BigQuery-Python-Notebook ausführen.
Hinweise
Erstellen Sie ein Google Cloud Projekt und einen Cloud Storage-Bucket, falls noch nicht geschehen.
Projekt einrichten
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Cloud Storage-Bucket erstellen in Ihrem Projekt, falls Sie noch keinen haben.
Notebook einrichten
- Notebook-Anmeldedaten: Standardmäßig werden in Ihrer Notebook-Sitzung Ihre Nutzeranmeldedaten verwendet. Alternativ können die Anmeldedaten des Sitzungsdienstkontos verwendet werden.
- Nutzeranmeldedaten: Ihrem Nutzerkonto müssen die folgenden IAM-Rollen (Identity and Access Management) zugewiesen sein:
- Dataproc-Bearbeiter (
roles/dataproc.editor-Rolle) - BigQuery Studio-Nutzer (Rolle
roles/bigquery.studioUser) - Rolle „Dienstkontonutzer“ (roles/iam.serviceAccountUser) für das Sitzungsdienstkonto.
Diese Rolle enthält die erforderliche Berechtigung
iam.serviceAccounts.actAs, um die Identität des Dienstkontos zu übernehmen.
- Dataproc-Bearbeiter (
- Anmeldedaten für Dienstkonten: Wenn Sie für Ihre Notebook-Sitzung Anmeldedaten für Dienstkonten anstelle von Nutzeranmeldedaten angeben möchten, muss das Sitzungsdienstkonto die folgende Rolle haben:
- Nutzeranmeldedaten: Ihrem Nutzerkonto müssen die folgenden IAM-Rollen (Identity and Access Management) zugewiesen sein:
- Notebook-Laufzeit: Ihr Notebook verwendet eine standardmäßige Vertex AI-Laufzeit, sofern Sie keine andere Laufzeit auswählen. Wenn Sie eine eigene Laufzeit definieren möchten, erstellen Sie sie in der Google Cloud -Konsole auf der Seite Laufzeiten.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie in der Tableiste des Detailbereichs auf den Pfeil neben dem +-Zeichen und dann auf Notebook.
- Konfigurieren und erstellen Sie eine einzelne Sitzung im Notebook.
- Konfigurieren Sie eine Spark-Sitzung in einer Dataproc Serverless for Spark-Vorlage für interaktive Sitzungen und verwenden Sie dann die Vorlage, um eine Sitzung im Notebook zu konfigurieren und zu erstellen.
BigQuery bietet eine
Query using Spark-Funktion, mit der Sie mit dem Programmieren der Vorlagensitzung beginnen können, wie auf dem Tab Templated Spark session (Spark-Sitzung mit Vorlage) beschrieben. Klicken Sie in der Tableiste des Editorbereichs auf den Drop-down-Pfeil neben dem +-Zeichen und dann auf Notebook.
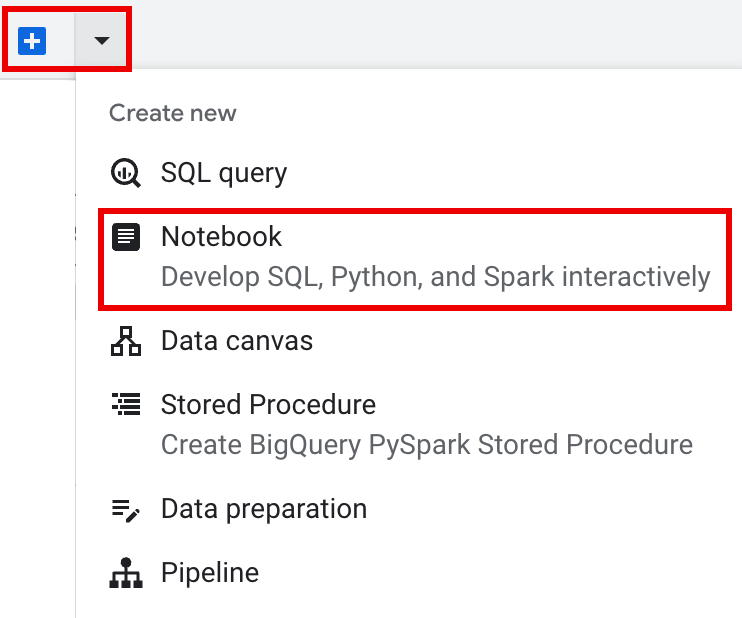
Kopieren Sie den folgenden Code und führen Sie ihn in einer Notebook-Zelle aus, um eine einfache Spark-Sitzung zu konfigurieren und zu erstellen.
- APP_NAME: Ein optionaler Name für Ihre Sitzung.
- Optionale Sitzungseinstellungen:Sie können Dataproc API-Einstellungen
Sessionhinzufügen, um Ihre Sitzung anzupassen. Beispiele:RuntimeConfig:
session.runtime_config.properties={spark.property.key1:VALUE_1,...,spark.property.keyN:VALUE_N}session.runtime_config.container_image = path/to/container/image
EnvironmentConfig: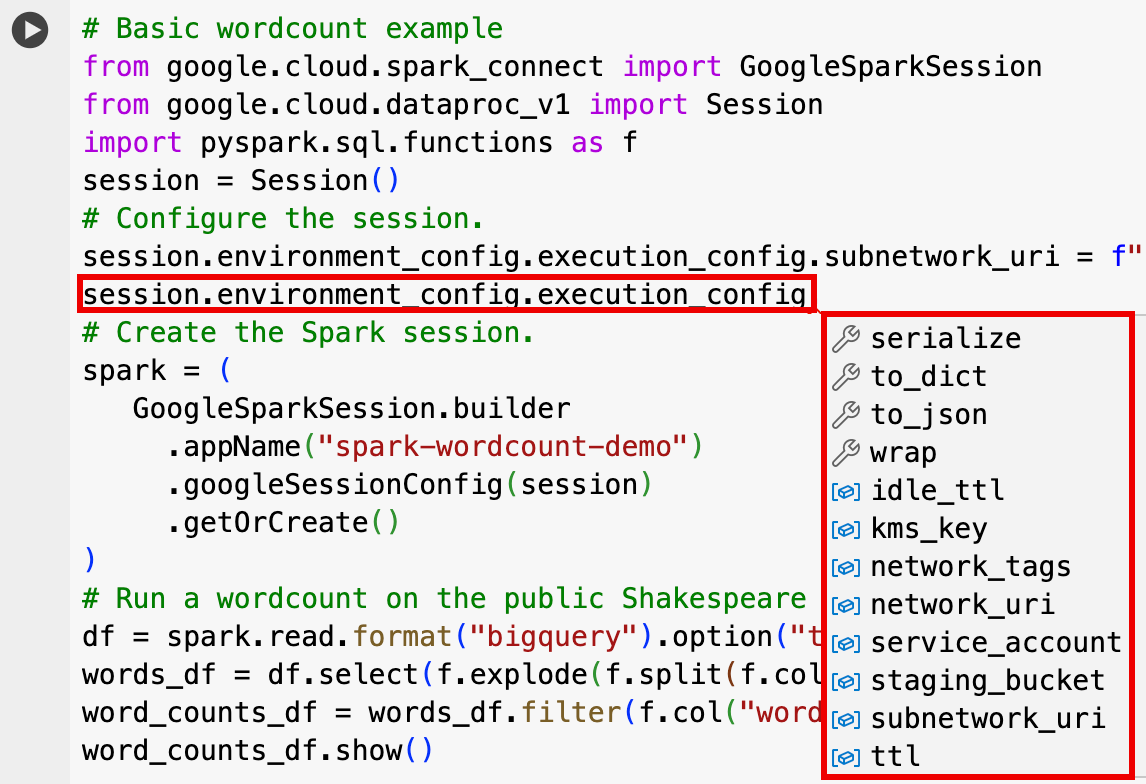
- session.environment_config.execution_config.subnetwork_uri = "SUBNET_NAME"
session.environment_config.execution_config.ttl = {"seconds": VALUE}session.environment_config.execution_config.service_account = SERVICE_ACCOUNT
- Klicken Sie in der Tableiste des Editorbereichs auf den Drop-down-Pfeil neben dem +-Zeichen und dann auf Notebook.
- Klicken Sie unter Mit einer Vorlage beginnen auf Mit Spark abfragen und dann auf Vorlage verwenden, um den Code in Ihr Notebook einzufügen.
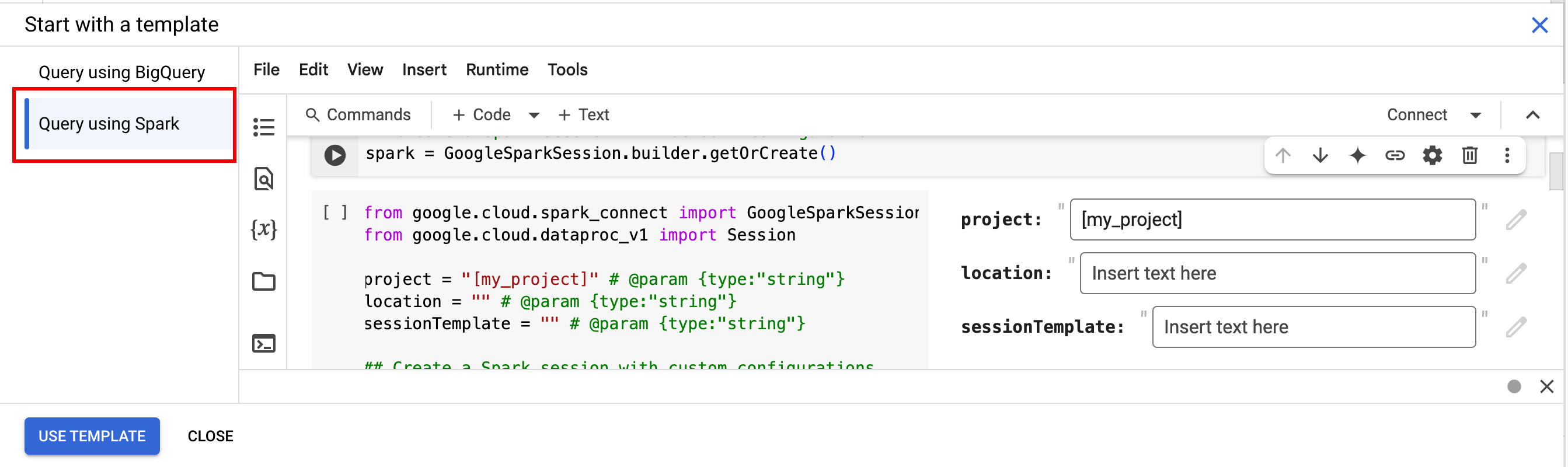
- Geben Sie die Variablen wie in den Hinweisen beschrieben an.
- Sie können alle zusätzlichen Beispielcodezellen löschen, die in das Notebook eingefügt wurden.
- PROJECT: Ihre Projekt-ID, die im Bereich Projektinformationen des Google Cloud Konsolen-Dashboards aufgeführt ist.
- LOCATION: Die Compute Engine-Region, in der Ihre Notebook-Sitzung ausgeführt wird. Wenn kein Speicherort angegeben wird, ist der Standardspeicherort die Region der VM, mit der das Notebook erstellt wird.
SESSION_TEMPLATE: Der Name einer vorhandenen Dataproc Serverless-Vorlage für interaktive Sitzungen. Die Einstellungen für die Sitzungskonfiguration werden aus der Vorlage abgerufen. In der Vorlage müssen auch die folgenden Einstellungen angegeben werden:
- Laufzeitversion
2.3+ Notebook-Typ:
Spark ConnectBeispiel:

- Laufzeitversion
APP_NAME: Ein optionaler Name für Ihre Sitzung.
- Führen Sie eine Wortzählung für ein öffentliches Shakespeare-Dataset aus.
- Erstellen Sie eine Iceberg-Tabelle, deren Metadaten im BigLake Metastore gespeichert sind.
- APP_NAME: Ein optionaler Name für Ihre Sitzung.
- PROJECT: Ihre Projekt-ID, die im Bereich Projektinformationen des Google Cloud Konsolen-Dashboards aufgeführt ist.
- REGION und SUBNET_NAME: Geben Sie die Compute Engine-Region und den Namen eines Subnetzes in der Sitzungsregion an. Dataproc Serverless aktiviert den privaten Google-Zugriff für das angegebene Subnetz.
- LOCATION: Der Standardwert für
BigQuery_metastore_config.locationundspark.sql.catalog.{catalog}.gcp_locationistUS. Sie können aber einen beliebigen unterstützten BigQuery-Standort auswählen. - BUCKET und WAREHOUSE_DIRECTORY: Der Cloud Storage-Bucket und -Ordner, die für das Iceberg-Warehouse-Verzeichnis verwendet werden.
- CATALOG_NAME und NAMESPACE: Der Name und der Namespace des Iceberg-Katalogs werden kombiniert, um die Iceberg-Tabelle (
catalog.namespace.table_name) zu identifizieren. - APP_NAME: Ein optionaler Name für Ihre Sitzung.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Bereich „Projektressourcen“ auf Ihr Projekt und dann auf Ihren Namespace, um die Tabelle
sample_iceberg_tableaufzurufen. Klicken Sie auf die Tabelle Details, um die Informationen unter Konfiguration für Katalogtabelle öffnen aufzurufen.Die Ein- und Ausgabeformate sind die Standardklassenformate
InputFormatundOutputFormatvon Hadoop, die von Iceberg verwendet werden.
Fügen Sie eine neue Codezelle ein, indem Sie in der Symbolleiste auf + Code klicken. In der neuen Codezelle wird
Start coding or generate with AIangezeigt. Klicken Sie auf Generieren.Geben Sie im Editor für die Generierung einen Natural Language Prompt ein und klicken Sie auf
enter. Achten Sie darauf, dass Sie das Keywordsparkoderpysparkin Ihren Prompt aufnehmen.Beispiel-Prompt:
create a spark dataframe from order_items and filter to orders created in 2024
Beispielausgabe:
spark.read.format("bigquery").option("table", "sqlgen-testing.pysparkeval_ecommerce.order_items").load().filter("year(created_at) = 2024").createOrReplaceTempView("order_items") df = spark.sql("SELECT * FROM order_items")Aktivieren Sie die Data Catalog-Synchronisierung für Dataproc Metastore-Instanzen, damit Gemini Code Assist relevante Tabellen und Schemas abrufen kann.
Ihr Nutzerkonto muss Zugriff auf Data Catalog haben, um die Tabellen abzufragen. Weisen Sie dazu die Rolle
DataCatalog.Viewerzu.- Führen Sie
spark.stop()in einer Notebook-Zelle aus. - Beenden Sie die Laufzeit im Notebook:
- Klicken Sie auf die Laufzeitauswahl und dann auf Sitzungen verwalten.

- Klicken Sie im Dialogfeld Aktive Sitzungen auf das Symbol zum Beenden und dann auf Beenden.

- Klicken Sie auf die Laufzeitauswahl und dann auf Sitzungen verwalten.
Planen Sie die Ausführung von Notebook-Code über die Google Cloud Konsole (es gelten die Notebook-Preise).
Notebook-Code als serverlose Dataproc-Batcharbeitslast ausführen (Dataproc Serverless-Preise).
- Notebook planen
- Wenn die Ausführung von Notebook-Code Teil eines Workflows ist, planen Sie das Notebook als Teil einer Pipeline.
Laden Sie Notebook-Code in eine Datei in einem lokalen Terminal oder in Cloud Shell herunter.
Öffnen Sie das Notebook in der Google Cloud Console auf der Seite BigQuery Studio im Bereich Explorer.
Laden Sie den Notebook-Code herunter, indem Sie im Menü Datei die Option Herunterladen und dann
Download .pyauswählen.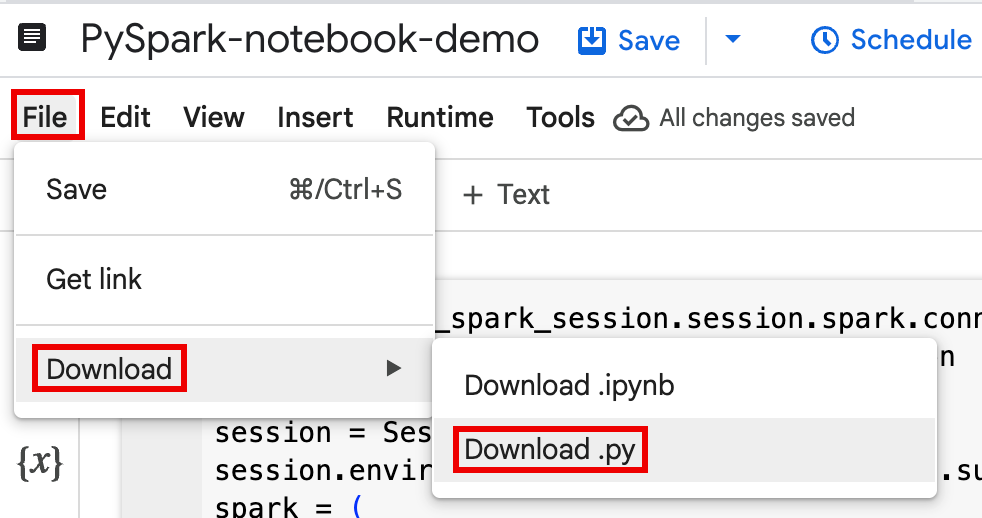
Generiere
requirements.txt.- Installieren Sie
pipreqsin dem Verzeichnis, in dem Sie Ihre.py-Datei gespeichert haben.pip install pipreqs
Führen Sie
pipreqsaus, umrequirements.txtzu generieren.pipreqs filename.py
Kopieren Sie die lokale Datei
requirements.txtmit der Google Cloud CLI in einen Bucket in Cloud Storage.gcloud storage cp requirements.txt gs://BUCKET/
- Installieren Sie
Aktualisieren Sie den Code für die Spark-Sitzung, indem Sie die heruntergeladene Datei
.pybearbeiten.Entfernen oder kommentieren Sie alle Shell-Skriptbefehle aus.
Entfernen Sie den Code, mit dem die Spark-Sitzung konfiguriert wird, und geben Sie dann Konfigurationsparameter als Parameter für die Batcharbeitslast an. Weitere Informationen finden Sie unter Spark-Batcharbeitslast senden.
Beispiel:
Entfernen Sie die folgende Zeile mit der Konfiguration des Sitzungssubnetzes aus dem Code:
session.environment_config.execution_config.subnetwork_uri = "{subnet_name}"Wenn Sie Ihren Batch-Arbeitslast ausführen, geben Sie das Subnetz mit dem Flag
--subnetan.gcloud dataproc batches submit pyspark \ --subnet=SUBNET_NAME
Verwenden Sie ein einfaches Code-Snippet zum Erstellen von Sitzungen.
Beispiel für heruntergeladenen Notebook-Code vor der Vereinfachung.
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session
session = Session() spark = DataprocSparkSession \ .builder \ .appName("CustomSparkSession") .dataprocSessionConfig(session) \ .getOrCreate()
Code für Batcharbeitslast nach der Vereinfachung.
from pyspark.sql import SparkSession
spark = SparkSession \ .builder \ .getOrCreate()
Führen Sie die Batcharbeitslast aus.
Eine Anleitung finden Sie unter Spark-Batcharbeitslast senden.
Achten Sie darauf, das Flag „--deps-bucket“ anzugeben, um auf den Cloud Storage-Bucket zu verweisen, der Ihre
requirements.txt-Datei enthält.Beispiel:
gcloud dataproc batches submit pyspark FILENAME.py \ --region=REGION \ --deps-bucket=BUCKET \ --version=2.3
Hinweise:
- FILENAME: Der Name der heruntergeladenen und bearbeiteten Notebook-Codedatei.
- REGION: Die Compute Engine-Region, in der sich der Cluster befindet.
- BUCKET: Der Name des Cloud Storage-Buckets, der Ihre
requirements.txt-Datei enthält. --version: Spark-Laufzeitversion 2.3 ist für die Ausführung der Batcharbeitslast ausgewählt.
Führen Sie einen Commit für Ihren Code durch.
- Nachdem Sie den Code für die Batch-Arbeitslast getestet haben, können Sie die Datei
.ipynboder.pymit Ihremgit-Client, z. B. GitHub, GitLab oder Bitbucket, im Rahmen Ihrer CI/CD-Pipeline in Ihrem Repository committen.
- Nachdem Sie den Code für die Batch-Arbeitslast getestet haben, können Sie die Datei
Batch-Arbeitslast mit Cloud Composer planen
- Eine Anleitung finden Sie unter Dataproc Serverless-Arbeitslasten mit Cloud Composer ausführen.
- YouTube-Videodemo: Unleashing the power of Apache Spark integrated with BigQuery.
- BigLake Metastore mit Dataproc verwenden
- BigLake Metastore mit Dataproc Serverless verwenden
Preise
Preisinformationen finden Sie unter Preise für BigQuery-Notebook-Laufzeiten.
Python-Notebook in BigQuery Studio öffnen
Spark-Sitzung in einem BigQuery Studio-Notebook erstellen
Sie können ein BigQuery Studio-Python-Notebook verwenden, um eine interaktive Spark Connect-Sitzung zu erstellen. Jedem BigQuery Studio-Notebook kann nur eine aktive serverlose Dataproc-Sitzung zugeordnet sein.
Sie haben folgende Möglichkeiten, eine Spark-Sitzung in einem Python-Notebook in BigQuery Studio zu erstellen:
Einzelne Sitzung
So erstellen Sie eine Spark-Sitzung in einem neuen Notebook:
from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.connect.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )Ersetzen Sie Folgendes:
Spark-Sitzung mit Vorlage
Sie können den Code in eine Notebook-Zelle eingeben und ausführen, um eine Spark-Sitzung auf Grundlage einer vorhandenen Dataproc Serverless-Sitzungsvorlage zu erstellen. Alle
session-Konfigurationseinstellungen, die Sie in Ihrem Notebook-Code angeben, überschreiben alle entsprechenden Einstellungen, die in der Sitzungsvorlage festgelegt sind.Verwenden Sie die Vorlage
Query using Spark, um Ihr Notebook mit Vorlagencode für die Spark-Sitzung vorab auszufüllen:from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.connect.functions as f session = Session() # Configure the session with an existing session template. session_template = "SESSION_TEMPLATE" session.session_template = f"projects/{project}/locations/{location}/sessionTemplates/{session_template}" # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() )PySpark-Code in Ihrem BigQuery Studio-Notebook schreiben und ausführen
Nachdem Sie eine Spark-Sitzung in Ihrem Notebook erstellt haben, können Sie damit Spark-Notebook-Code im Notebook ausführen.
Unterstützung der Spark Connect PySpark API:Ihre Spark Connect-Notebooksitzung unterstützt die meisten PySpark APIs, einschließlich DataFrame, Functions und Column, aber nicht SparkContext, RDD und andere PySpark APIs. Weitere Informationen finden Sie unter Was wird in Spark 3.5 unterstützt?.
Dataproc-spezifische APIs:Dataproc vereinfacht das dynamische Hinzufügen von
PyPI-Paketen zu Ihrer Spark-Sitzung durch Erweitern deraddArtifacts-Methode. Sie können die Liste im Formatversion-schemeangeben (ähnlich wiepip install). Dadurch wird der Spark Connect-Server angewiesen, Pakete und ihre Abhängigkeiten auf allen Clusterknoten zu installieren, damit sie für Worker für Ihre UDFs verfügbar sind.Beispiel, in dem die angegebene
textdistance-Version und die neuesten kompatiblenrandom2-Bibliotheken im Cluster installiert werden, damit UDFs, dietextdistanceundrandom2verwenden, auf Worker-Knoten ausgeführt werden können.spark.addArtifacts("textdistance==4.6.1", "random2", pypi=True)Hilfe zum Notebook-Code:Das BigQuery Studio-Notebook bietet Hilfe zum Code, wenn Sie den Mauszeiger auf einen Klassen- oder Methodennamen bewegen, und Hilfe zur Vervollständigung von Code, wenn Sie Code eingeben.
Im folgenden Beispiel wird
DataprocSparkSessioneingegeben. Wenn Sie den Mauszeiger auf diesen Klassennamen bewegen, werden Vorschläge zur automatischen Vervollständigung des Codes und Dokumentationshilfe angezeigt.
PySpark-Beispiele für BigQuery Studio-Notebooks
In diesem Abschnitt finden Sie Beispiele für BigQuery Studio-Python-Notebooks mit PySpark-Code für die folgenden Aufgaben:
Wordcount
Im folgenden PySpark-Beispiel wird eine Spark-Sitzung erstellt und dann die Anzahl der Wortvorkommen in einem öffentlichen
bigquery-public-data.samples.shakespeare-Dataset gezählt.# Basic wordcount example from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.connect.functions as f session = Session() # Create the Spark session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Run a wordcount on the public Shakespeare dataset. df = spark.read.format("bigquery").option("table", "bigquery-public-data.samples.shakespeare").load() words_df = df.select(f.explode(f.split(f.col("word"), " ")).alias("word")) word_counts_df = words_df.filter(f.col("word") != "").groupBy("word").agg(f.count("*").alias("count")).orderBy("word") word_counts_df.show()Ersetzen Sie Folgendes:
Ausgabe:
In der Zellausgabe wird ein Beispiel für die Wordcount-Ausgabe aufgeführt. Wenn Sie Sitzungsdetails in der Google Cloud -Konsole aufrufen möchten, klicken Sie auf den Link Interaktive Sitzungsdetailansicht. Wenn Sie Ihre Spark-Sitzung überwachen möchten, klicken Sie auf der Seite mit den Sitzungsdetails auf Spark-UI ansehen.

Interactive Session Detail View: LINK +------------+-----+ | word|count| +------------+-----+ | '| 42| | ''All| 1| | ''Among| 1| | ''And| 1| | ''But| 1| | ''Gamut'| 1| | ''How| 1| | ''Lo| 1| | ''Look| 1| | ''My| 1| | ''Now| 1| | ''O| 1| | ''Od's| 1| | ''The| 1| | ''Tis| 4| | ''When| 1| | ''tis| 1| | ''twas| 1| | 'A| 10| |'ARTEMIDORUS| 1| +------------+-----+ only showing top 20 rows
Iceberg-Tabelle
PySpark-Code ausführen, um eine Iceberg-Tabelle mit BigLake Metastore-Metadaten zu erstellen
Im folgenden Beispielcode wird eine
sample_iceberg_tablemit Tabellenmetadaten erstellt, die im BigLake Metastore gespeichert sind. Anschließend wird die Tabelle abgefragt.from google.cloud.dataproc_spark_connect import DataprocSparkSession from google.cloud.dataproc_v1 import Session import pyspark.sql.connect.functions as f # Create the Dataproc Serverless session. session = Session() # Set the session configuration for BigLake Metastore with the Iceberg environment. project_id = "PROJECT" region = "REGION" subnet_name = "SUBNET_NAME" location = "LOCATION" session.environment_config.execution_config.subnetwork_uri = f"{subnet_name}" warehouse_dir = "gs://BUCKET/WAREHOUSE_DIRECTORY" catalog = "CATALOG_NAME" namespace = "NAMESPACE" session.runtime_config.properties[f"spark.sql.catalog.{catalog}"] = "org.apache.iceberg.spark.SparkCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.catalog-impl"] = "org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_project"] = f"{project_id}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.gcp_location"] = f"{location}" session.runtime_config.properties[f"spark.sql.catalog.{catalog}.warehouse"] = f"{warehouse_dir}" # Create the Spark Connect session. spark = ( DataprocSparkSession.builder .appName("APP_NAME") .dataprocSessionConfig(session) .getOrCreate() ) # Create the namespace in BigQuery. spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create the Iceberg table. spark.sql("DROP TABLE IF EXISTS `sample_iceberg_table`"); spark.sql("CREATE TABLE sample_iceberg_table (id int, data string) USING ICEBERG;") spark.sql("DESCRIBE sample_iceberg_table;") # Insert table data and query the table. spark.sql("INSERT INTO sample_iceberg_table VALUES (1, \"first row\");") # Alter table, then query and display table data and schema. spark.sql("ALTER TABLE sample_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE sample_iceberg_table;") df = spark.sql("SELECT * FROM sample_iceberg_table") df.show() df.printSchema()Hinweise:
In der Zellausgabe wird
sample_iceberg_tablemit der hinzugefügten Spalte aufgeführt und ein Link zur Seite Details zur interaktiven Sitzung in der Google Cloud -Konsole angezeigt. Auf der Seite mit den Sitzungsdetails können Sie auf Spark-UI ansehen klicken, um Ihre Spark-Sitzung zu überwachen.
Interactive Session Detail View: LINK +---+---------+------------+ | id| data|newDoubleCol| +---+---------+------------+ | 1|first row| NULL| +---+---------+------------+ root |-- id: integer (nullable = true) |-- data: string (nullable = true) |-- newDoubleCol: double (nullable = true)
Tabellendetails in BigQuery ansehen
Führen Sie die folgenden Schritte aus, um die Details von Iceberg-Tabellen in BigQuery zu prüfen:
Weitere Beispiele
Erstellen Sie einen Spark-
DataFrame(sdf) aus einem Pandas-DataFrame (df).sdf = spark.createDataFrame(df) sdf.show()Aggregationen für Spark-
DataFramesausführen.from pyspark.sql import functions as F sdf.groupby("segment").agg( F.mean("total_spend_per_user").alias("avg_order_value"), F.approx_count_distinct("user_id").alias("unique_customers") ).show()Daten mit dem Spark-BigQuery-Connector aus BigQuery lesen.
spark.conf.set("viewsEnabled","true") spark.conf.set("materializationDataset","my-bigquery-dataset") sdf = spark.read.format('bigquery') \ .load(query)Spark-Code mit Gemini Code Assist schreiben
Sie können Gemini Code Assist bitten, PySpark-Code in Ihrem Notebook zu generieren. Gemini Code Assist ruft relevante BigQuery- und Dataproc Metastore-Tabellen und deren Schemas ab und verwendet sie, um eine Codeantwort zu generieren.
So generieren Sie Gemini Code Assist-Code in Ihrem Notebook:
Tipps zur Codegenerierung mit Gemini Code Assist
Spark-Sitzung beenden
Sie haben folgende Möglichkeiten, die Spark Connect-Sitzung in Ihrem BigQuery Studio-Notebook zu beenden:
BigQuery Studio-Notebook-Code orchestrieren
Sie haben folgende Möglichkeiten, BigQuery Studio-Notebook-Code zu orchestrieren:
Notebook-Code über die Google Cloud Console planen
Sie haben folgende Möglichkeiten, Notebook-Code zu planen:
Notebook-Code als serverlose Dataproc-Batcharbeitslast ausführen
Führen Sie die folgenden Schritte aus, um BigQuery Studio-Notebook-Code als Dataproc Serverless-Batcharbeitslast auszuführen.
Fehlerbehebung bei Notebooks
Wenn in einer Zelle mit Spark-Code ein Fehler auftritt, können Sie ihn beheben, indem Sie in der Zellenausgabe auf den Link Interactive Session Detail View (Detailansicht für interaktive Sitzungen) klicken (siehe Beispiele für Wortanzahl und Iceberg-Tabelle).
Bekannte Probleme und Lösungen
Fehler: Eine Notebook-Laufzeit, die mit der Python-Version
3.10erstellt wurde, kann einenPYTHON_VERSION_MISMATCH-Fehler verursachen, wenn versucht wird, eine Verbindung zur Spark-Sitzung herzustellen.Lösung: Erstellen Sie die Laufzeit mit der Python-Version
3.11neu.Nächste Schritte