Der spark-bigquery-connector wird mit Apache Spark verwendet, um Daten aus BigQuery zu lesen und zu schreiben. Der Connector nutzt beim Lesen von Daten aus BigQuery die BigQuery Storage API.
In dieser Anleitung finden Sie Informationen zur Verfügbarkeit des vorinstallierten Connectors und erfahren, wie Sie eine bestimmte Connector-Version für Spark-Jobs verfügbar machen. Der Beispielcode zeigt, wie Sie den Spark BigQuery-Connector in einer Spark-Anwendung verwenden.
Vorinstallierten Connector verwenden
Der Spark-BigQuery-Connector ist auf Dataproc-Clustern, die mit Image-Versionen 2.1 und höher erstellt wurden, vorinstalliert und für Spark-Jobs verfügbar. Die vorinstallierte Connector-Version ist auf der Release-Seite jeder Image-Version aufgeführt. In der Zeile BigQuery Connector auf der Seite 2.2.x-Image-Releaseversionen wird beispielsweise die Connector-Version angezeigt, die in den neuesten 2.2-Image-Releases installiert ist.
Eine bestimmte Connector-Version für Spark-Jobs verfügbar machen
Wenn Sie eine Connector-Version verwenden möchten, die sich von einer vorinstallierten Version in einem Cluster mit einer Image-Version ab 2.1 unterscheidet, oder wenn Sie den Connector in einem Cluster mit einer Image-Version vor 2.1 installieren möchten, folgen Sie der Anleitung in diesem Abschnitt.
Wichtig:Die spark-bigquery-connector-Version muss mit der Dataproc-Cluster-Imageversion kompatibel sein. Weitere Informationen finden Sie in der Kompatibilitätsmatrix für Connector und Dataproc-Image.
2.1 und spätere Image-Versionen
Wenn Sie einen Dataproc-Cluster mit einer Image-Version 2.1 oder höher erstellen, geben Sie die Connector-Version als Clustermetadaten an.
Beispiel für die gcloud CLI:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=2.2 \ --metadata=SPARK_BQ_CONNECTOR_VERSION or SPARK_BQ_CONNECTOR_URL\ other flags
Hinweise:
SPARK_BQ_CONNECTOR_VERSION: Geben Sie eine Connector-Version an. Spark-BigQuery-Connector-Versionen sind auf der Seite spark-bigquery-connector/releases auf GitHub aufgeführt.
Beispiel:
--metadata=SPARK_BQ_CONNECTOR_VERSION=0.42.1
SPARK_BQ_CONNECTOR_URL: Geben Sie eine URL an, die auf die JAR-Datei in Cloud Storage verweist. Sie können die URL eines Connectors angeben, der in der Spalte link unter Downloading and Using the Connector (Connector herunterladen und verwenden) auf GitHub aufgeführt ist, oder den Pfad zu einem Cloud Storage-Speicherort, an dem Sie eine benutzerdefinierte Connector-JAR-Datei abgelegt haben.
Beispiele:
--metadata=SPARK_BQ_CONNECTOR_URL=gs://spark-lib/bigquery/spark-3.5-bigquery-0.42.1.jar --metadata=SPARK_BQ_CONNECTOR_URL=gs://PATH_TO_CUSTOM_JAR
2.0 und Cluster mit früheren Image-Versionen
Sie haben folgende Möglichkeiten, den Spark BigQuery-Connector für Ihre Anwendung verfügbar zu machen:
Installieren Sie den Spark-bigquery-Connector im Spark-JAR-Verzeichnis jedes Knotens. Verwenden Sie dazu beim Erstellen des Clusters die Initialisierungsaktion für Dataproc-Connectors.
Geben Sie die Connector-JAR-URL an, wenn Sie Ihren Job mit der Google Cloud Console, der gcloud CLI oder der Dataproc API an den Cluster senden.
Konsole
Verwenden Sie das Element JAR-Dateien des Spark-Jobs auf der Dataproc-Seite Job senden.
gcloud
Verwenden Sie das
gcloud dataproc jobs submit spark --jars-Flag.API
Verwenden Sie das Feld
SparkJob.jarFileUris.Connector-JAR beim Ausführen von Spark-Jobs in Clustern mit Image-Versionen vor 2.0 angeben
- Geben Sie die Connector-JAR-Datei an, indem Sie die Informationen zur Scala- und Connector-Version im folgenden URI-String ersetzen:
gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- Scala
2.12mit Dataproc-Image-Versionen1.5+verwendengs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.23.2.jar \ -- job args
- Scala
2.11mit Dataproc-Image-Versionen1.4und früher verwenden:gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-CONNECTOR_VERSION.jar
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.11-0.23.2.jar \ -- job-args
- Geben Sie die Connector-JAR-Datei an, indem Sie die Informationen zur Scala- und Connector-Version im folgenden URI-String ersetzen:
Schließen Sie die Connector-JAR-Datei in Ihre Scala- oder Java Spark-Anwendung als Abhängigkeit ein (siehe Für den Connector kompilieren).
Kosten berechnen
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Dataproc
- BigQuery
- Cloud Storage
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Daten aus BigQuery lesen und in BigQuery schreiben
In diesem Beispiel werden Daten aus BigQuery in einen Spark-DataFrame eingelesen und dann mit der Standard-Datenquellen-API einer Wortzählung unterzogen.
Der Connector schreibt die Daten in BigQuery, indem er die Daten zuerst in einer temporären Cloud Storage-Tabelle zwischenspeichert. Anschließend werden alle Daten in einem Vorgang in BigQuery kopiert. Sobald der BigQuery-Ladevorgang erfolgreich war, versucht der Connector, die temporären Dateien zu löschen.
Wenn der Job fehlschlägt, entfernen Sie alle verbleibenden temporären Cloud Storage-Dateien. Temporäre BigQuery-Dateien befinden sich in der Regel in gs://[bucket]/.spark-bigquery-[jobid]-[UUID].
Abrechnung konfigurieren
Standardmäßig wird das Projekt, das mit den Anmeldedaten oder dem Dienstkonto verbunden ist, für die API-Nutzung abgerechnet. Wenn Sie ein anderes Projekt in Rechnung stellen möchten, legen Sie die folgende Konfiguration fest: spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
Sie kann auch folgendermaßen einem Lese- oder Schreibvorgang hinzugefügt werden: .option("parentProject", "<BILLED-GCP-PROJECT>").
Code ausführen
Bevor Sie dieses Beispiel ausführen, erstellen Sie ein Dataset mit dem Namen „wordcount_dataset“ oder ändern Sie das Ausgabe-Dataset im Code in ein vorhandenes BigQuery-Dataset in IhremGoogle Cloud -Projekt.
Verwenden Sie den bq-Befehl zum Erstellen des wordcount_dataset:
bq mk wordcount_dataset
Verwenden Sie den Google Cloud CLI-Befehl zum Erstellen eines Cloud Storage-Bucket, der für den Export nach BigQuery verwendet wird:
gcloud storage buckets create gs://[bucket]
Scala
- Untersuchen Sie den Code und ersetzen Sie den Platzhalter [bucket] durch den zuvor erstellten Cloud Storage-Bucket.
/* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-bigquery-demo") .getOrCreate() */ // Use the Cloud Storage bucket for temporary BigQuery export data used // by the connector. val bucket = "[bucket]" spark.conf.set("temporaryGcsBucket", bucket) // Load data in from BigQuery. See // https://github.com/GoogleCloudDataproc/spark-bigquery-connector/tree/0.17.3#properties // for option information. val wordsDF = spark.read.bigquery("bigquery-public-data:samples.shakespeare") .cache() wordsDF.createOrReplaceTempView("words") // Perform word count. val wordCountDF = spark.sql( "SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word") wordCountDF.show() wordCountDF.printSchema() // Saving the data to BigQuery. (wordCountDF.write.format("bigquery") .save("wordcount_dataset.wordcount_output"))
- Code in einem Cluster ausführen
- Stellen Sie eine SSH-Verbindung zum Masterknoten des Dataproc-Clusters her.
- Rufen Sie in der Google Cloud Console die Seite Dataproc-Cluster auf und klicken Sie auf den Namen des Clusters.
- Wählen Sie auf der Seite Clusterdetails den Tab „VM-Instanzen“ aus. Klicken Sie dann rechts neben dem Namen des Masterknotens des Clusters auf
SSH.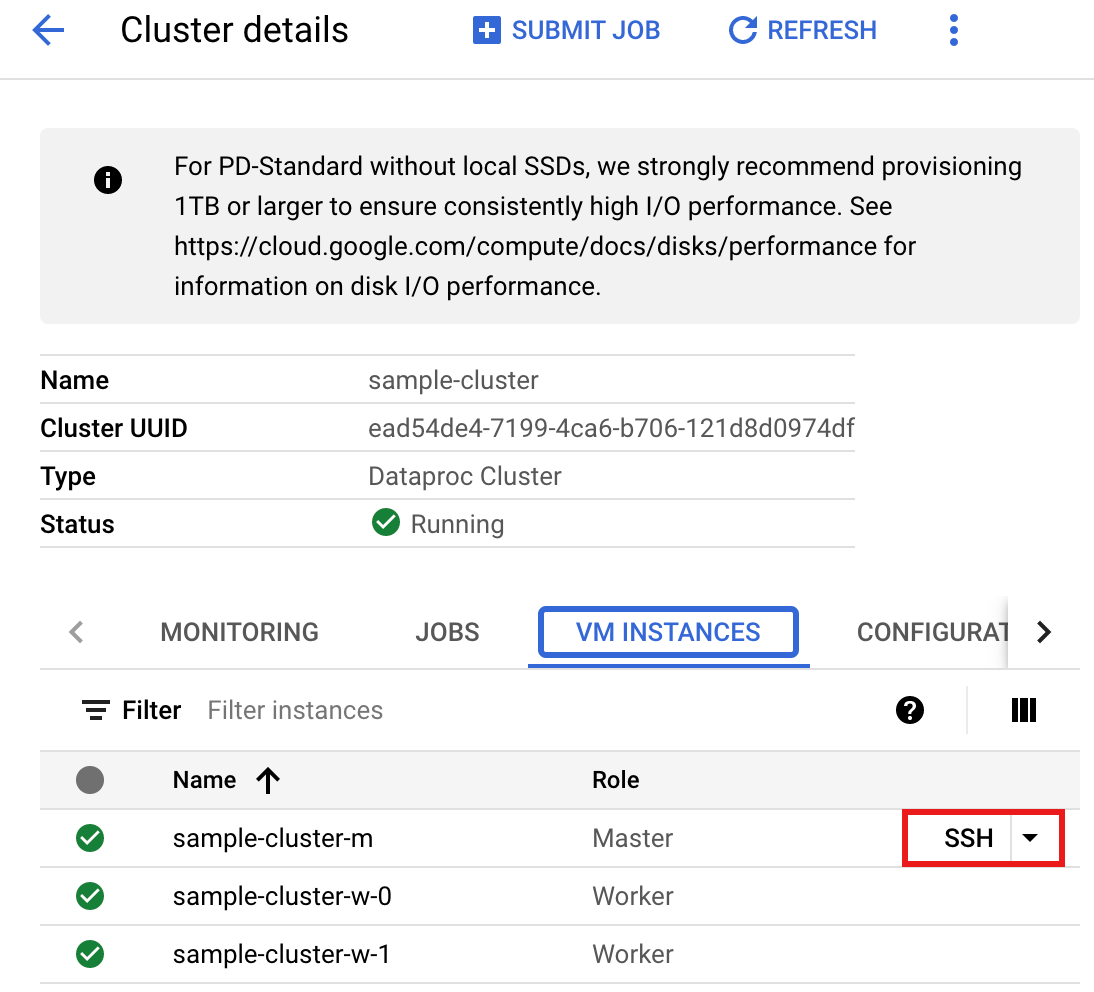
Ein Browserfenster wird in Ihrem Basisverzeichnis auf dem Masterknoten geöffnet.Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Rufen Sie in der Google Cloud Console die Seite Dataproc-Cluster auf und klicken Sie auf den Namen des Clusters.
- Erstellen Sie
wordcount.scalamit dem vorinstallierten Texteditorvi,vimodernanound fügen Sie dann den Scala-Code aus der Scala-Code-Liste ein.nano wordcount.scala
- Starten Sie die
spark-shell-REPL.$ spark-shell --jars=gs://spark-lib/bigquery/spark-bigquery-latest.jar ... Using Scala version ... Type in expressions to have them evaluated. Type :help for more information. ... Spark context available as sc. ... SQL context available as sqlContext. scala>
- Führen Sie wordcount.scala mit dem
:load wordcount.scala-Befehl aus, um die BigQuery-wordcount_output-Tabelle zu erstellen. Die Ausgabeliste zeigt 20 Zeilen von der Wordcount-Ausgabe an.:load wordcount.scala ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Wenn Sie eine Vorschau der Ausgabetabelle aufrufen möchten, öffnen Sie die SeiteBigQuery, wählen Sie die Tabellewordcount_outputaus und klicken Sie dann auf Vorschau.
- Stellen Sie eine SSH-Verbindung zum Masterknoten des Dataproc-Clusters her.
PySpark
- Untersuchen Sie den Code und ersetzen Sie den Platzhalter [bucket] durch den zuvor erstellten Cloud Storage-Bucket.
#!/usr/bin/env python """BigQuery I/O PySpark example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-bigquery-demo') \ .getOrCreate() # Use the Cloud Storage bucket for temporary BigQuery export data used # by the connector. bucket = "[bucket]" spark.conf.set('temporaryGcsBucket', bucket) # Load data from BigQuery. words = spark.read.format('bigquery') \ .load('bigquery-public-data:samples.shakespeare') \ words.createOrReplaceTempView('words') # Perform word count. word_count = spark.sql( 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word') word_count.show() word_count.printSchema() # Save the data to BigQuery word_count.write.format('bigquery') \ .save('wordcount_dataset.wordcount_output')
- Code in Ihrem Cluster ausführen
- Stellen Sie eine SSH-Verbindung zum Masterknoten des Dataproc-Clusters her.
- Rufen Sie in der Google Cloud Console die Seite Dataproc-Cluster auf und klicken Sie auf den Namen des Clusters.
- Wählen Sie auf der Seite Clusterdetails den Tab „VM-Instanzen“ aus. Klicken Sie dann rechts neben dem Namen des Masterknotens des Clusters auf
SSH.
Ein Browserfenster wird in Ihrem Basisverzeichnis auf dem Masterknoten geöffnet.Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Rufen Sie in der Google Cloud Console die Seite Dataproc-Cluster auf und klicken Sie auf den Namen des Clusters.
- Erstellen Sie
wordcount.pymit dem vorinstallierten Texteditorvi,vimodernanound fügen Sie dann den PySpark-Code aus der PySpark-Codeliste ein.nano wordcount.py
- Führen Sie Wordcount mit
spark-submitaus, um die BigQuery-wordcount_output-Tabelle zu erstellen. Die Ausgabeliste zeigt 20 Zeilen von der Wordcount-Ausgabe an.spark-submit --jars gs://spark-lib/bigquery/spark-bigquery-latest.jar wordcount.py ... +---------+----------+ | word|word_count| +---------+----------+ | XVII| 2| | spoil| 28| | Drink| 7| |forgetful| 5| | Cannot| 46| | cures| 10| | harder| 13| | tresses| 3| | few| 62| | steel'd| 5| | tripping| 7| | travel| 35| | ransom| 55| | hope| 366| | By| 816| | some| 1169| | those| 508| | still| 567| | art| 893| | feign| 10| +---------+----------+ only showing top 20 rows root |-- word: string (nullable = false) |-- word_count: long (nullable = true)
Wenn Sie eine Vorschau der Ausgabetabelle aufrufen möchten, öffnen Sie die SeiteBigQuery, wählen Sie die Tabellewordcount_outputaus und klicken Sie dann auf Vorschau.
- Stellen Sie eine SSH-Verbindung zum Masterknoten des Dataproc-Clusters her.
Nächste Schritte
- Weitere Informationen finden Sie unter BigQuery Storage und Spark SQL – Python.
- Tabellendefinitionsdatei für eine externe Datenquelle erstellen
- Extern partitionierte Daten abfragen
- Weitere Informationen finden Sie unter Tipps zur Feinabstimmung von Spark-Jobs.