Stream table updates with change data capture
BigQuery change data capture (CDC) updates your BigQuery tables by processing and applying streamed changes to existing data. This synchronization is accomplished through upsert and delete row operations that are streamed in real time by the BigQuery Storage Write API, which you should be familiar with before proceeding.
Before you begin
Grant Identity and Access Management (IAM) roles that give users the necessary permissions to perform each task in this document, and ensure that your workflow meets each prerequisite.
Required permissions
To get the permission that
you need to use the Storage Write API,
ask your administrator to grant you the
BigQuery Data Editor (roles/bigquery.dataEditor)
IAM role.
For more information about granting roles, see Manage access to projects, folders, and organizations.
This predefined role contains the
bigquery.tables.updateData
permission,
which is required to
use the Storage Write API.
You might also be able to get this permission with custom roles or other predefined roles.
For more information about IAM roles and permissions in BigQuery, see Introduction to IAM.
Prerequisites
To use BigQuery CDC, your workflow must meet the following conditions:
- You must use the Storage Write API in the default stream.
- You must use the protobuf format as the ingestion format. The Apache Arrow format isn't supported.
- You must declare primary keys for the destination table in BigQuery. Composite primary keys containing up to 16 columns are supported.
- Sufficient BigQuery compute resources must be available to perform the CDC row operations. Be aware that if CDC row modification operations fail, you might unintentionally retain data that you intended to delete. For more information, see Deleted data considerations.
Specify changes to existing records
In BigQuery CDC, the pseudocolumn _CHANGE_TYPE indicates the
type of change to be processed for each row. To use CDC, set _CHANGE_TYPE when
you stream row modifications using the Storage Write API. The
pseudocolumn _CHANGE_TYPE only accepts the values UPSERT and DELETE.
A table is considered CDC-enabled while the Storage Write API is
streaming row modifications to the table in this manner.
Example with UPSERT and DELETE values
Consider the following table in BigQuery:
| ID | Name | Salary |
|---|---|---|
| 100 | Charlie | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5000 |
The following row modifications are streamed by the Storage Write API:
| ID | Name | Salary | _CHANGE_TYPE |
|---|---|---|---|
| 100 | DELETE | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
The updated table is now the following:
| ID | Name | Salary |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5000 |
| 105 | Izumi | 6000 |
Manage table staleness
By default, every time you run a query, BigQuery returns the most
up-to-date results. To provide the freshest results when querying a CDC-enabled
table, BigQuery must apply each streamed row modification up to
the query start time, so that the most up-to-date version of the table is being
queried. Applying these row modifications at query run time increases query
latency and cost. However, if you don't require fully up-to-date query results,
you can reduce cost and latency on your queries by setting the max_staleness
option on your table. When this option is set, BigQuery applies
row modifications at least once within the interval defined by the
max_staleness value, letting you run queries without waiting for updates to be
applied, at the cost of some data staleness.
This behavior is especially useful for dashboards and reports for which data freshness isn't essential. It is also helpful for cost management by giving you more control over how frequently BigQuery applies row modifications.
Query tables with the max_staleness option set
When you query a table with the max_staleness option set,
BigQuery returns the result based on the value of max_staleness
and the time at which the last apply job occurred, which is represented by
the table's upsert_stream_apply_watermark timestamp.
Consider the following example, in which a table has the max_staleness option
set to 10 minutes, and the most recent apply job occurred at T20:
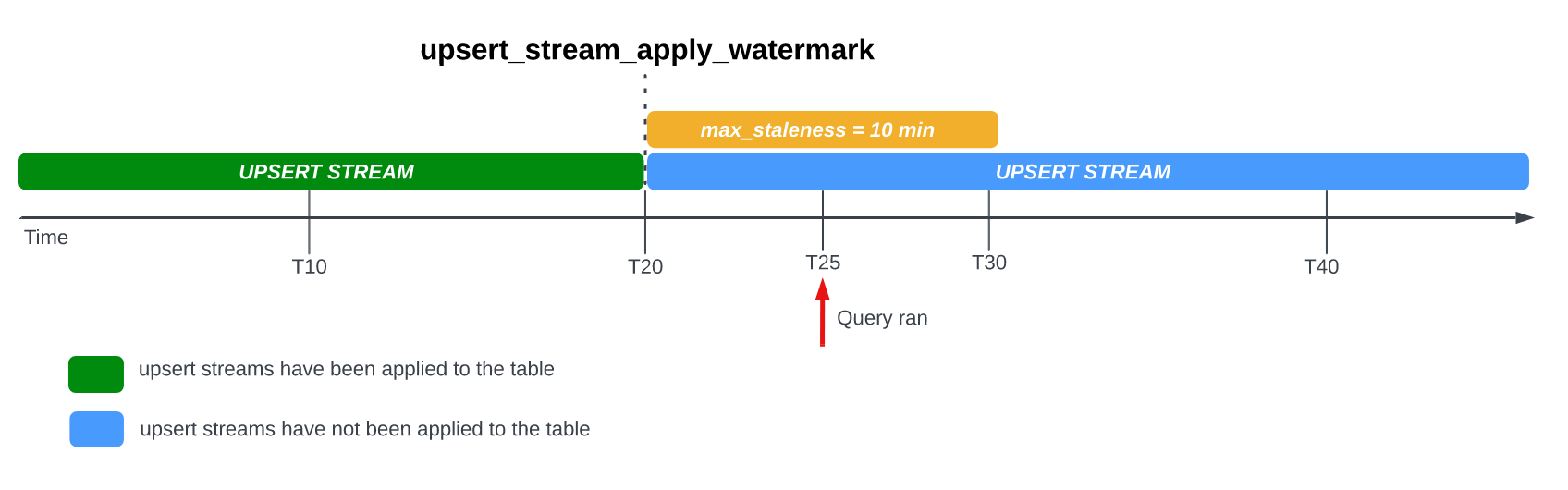
If you query the table at T25, then the current version of the table is 5
minutes stale, which is less than the max_staleness interval of 10 minutes. In
this case, BigQuery returns the version of the table at T20,
meaning the data returned is also 5 minutes stale.
When you set the max_staleness option on your table, BigQuery
applies pending row modifications at least once within the max_staleness
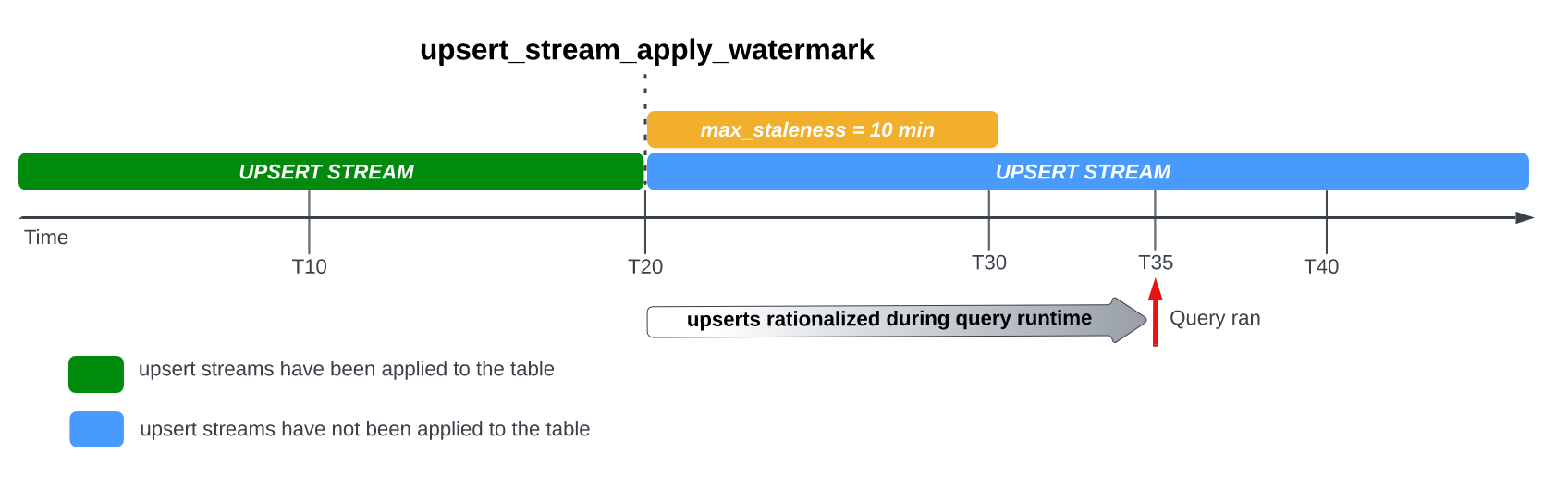
interval. In some cases, however, BigQuery might not complete the
process of applying these pending row modifications within the interval.
For example, if you query the table at T35, and the process of applying pending
row modifications has not completed, then the current version of the table is 15
minutes stale, which is greater than the max_staleness interval of 10 minutes.
In this case, at query run time, BigQuery applies all row
modifications between T20 and T35 for the current query, meaning the queried
data is completely up to date, at the cost of some additional query latency.
This is considered a runtime merge job.
Recommended table max_staleness value
A table's max_staleness value should generally be the higher of the following
two values:
- The maximum tolerable data staleness for your workflow.
- Twice the maximum time it takes to apply upserted changes into your table, plus some additional buffer.
To calculate the time it takes to apply upserted changes to an existing table, use the following SQL query to determine the 95th percentile duration of background apply jobs, plus a seven-minute buffer to allow for the BigQuery write-optimized storage (streaming buffer) conversion.
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
Replace the following:
REGION: the region name where your project is located. For example,us.PROJECT_ID: the ID of the project containing the BigQuery tables that are being modified by BigQuery CDC.
The duration of background apply jobs is affected by several factors including the number and complexity of CDC operations issued within the staleness interval, the table size, and BigQuery resource availability. For more information about resource availability, see Size and monitor BACKGROUND reservations.
Create a table with the max_staleness option
To create a table with the max_staleness option, use the
CREATE TABLE statement.
The following example creates the table employees with a max_staleness limit
of 10 minutes:
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
Modify the max_staleness option for an existing table
To add or modify a max_staleness limit in an existing table, use the
ALTER TABLE statement.
The following example changes the max_staleness limit of the employees table
to 15 minutes:
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
Determine the current max_staleness value of a table
To determine the current max_staleness value of a table, query the
INFORMATION_SCHEMA.TABLE_OPTIONS view.
The following example checks the current max_staleness value of the table
mytable:
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
Replace the following:
DATASET_NAME: the name of the dataset in which the CDC-enabled table resides.TABLE_NAME: the name of the CDC-enabled table.
The results show that the max_staleness value is 10 minutes:
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
Monitor table upsert operation progress
To monitor the state of a table and to check when row modifications were
last applied, query the
INFORMATION_SCHEMA.TABLES view
to get the upsert_stream_apply_watermark timestamp.
The following example checks the upsert_stream_apply_watermark value of
the table mytable:
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
Replace the following:
DATASET_NAME: the name of the dataset in which the CDC-enabled table resides.TABLE_NAME: the name of the CDC-enabled table.
The result is similar to the following:
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
Upsert operations are performed by the bigquery-adminbot@system.gserviceaccount.com
service account and appear within the job history of the project containing the
CDC-enabled table.
Manage custom ordering
When streaming upserts to BigQuery, the default behavior of ordering records with identical primary keys is determined by the BigQuery system time at which the record was ingested into BigQuery. In other words, the record most recently ingested with the latest timestamp takes precedence over the record previously ingested with an older timestamp. For certain use cases, such as those where very frequent upserts can occur to the same primary key in a very short time window, or where the upsert order is not guaranteed, this might not be sufficient. For these scenarios, a user-supplied ordering key might be necessary.
To configure user-supplied ordering keys, the pseudocolumn
_CHANGE_SEQUENCE_NUMBER is used to indicate the order in which
BigQuery should apply records, based on the larger
_CHANGE_SEQUENCE_NUMBER between two matching records with the same primary
key. The pseudocolumn _CHANGE_SEQUENCE_NUMBER is an optional column and only
accepts values in a fixed format STRING.
_CHANGE_SEQUENCE_NUMBER format
The pseudocolumn _CHANGE_SEQUENCE_NUMBER only accepts STRING values,
written in a fixed format. This fixed format uses STRING values written in
hexadecimal, separated into sections by a forward slash /. Each section can be
expressed in at most 16 hexadecimal characters, and up to four sections are
allowed per _CHANGE_SEQUENCE_NUMBER. The allowable range of the
_CHANGE_SEQUENCE_NUMBER supports values between 0/0/0/0 and
FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF.
_CHANGE_SEQUENCE_NUMBER values support both uppercase and lowercase
characters.
Expressing basic ordering keys can be done by using a single section. For
example, to order keys solely based on a record's processing timestamp from an
application server, you could use one section: '2024-04-30 11:19:44 UTC',
expressed as hexadecimal by converting the timestamp to the milliseconds from
Epoch, '18F2EBB6480' in this case. The logic to convert data into hexadecimal
is the responsibility of the client issuing the write to BigQuery
using the Storage Write API.
Supporting multiple sections lets you combine several processing-logic values
into one key for more complex use cases. For example, to order keys based on a
record's processing timestamp from an application server, a log sequence
number, and the record's status, you could use three sections:
'2024-04-30 11:19:44 UTC' / '123' / 'complete', each expressed as hexadecimal.
The ordering of sections is an important consideration for ranking your
processing-logic. BigQuery compares _CHANGE_SEQUENCE_NUMBER
values by comparing the first section, then comparing the next section only if
the previous sections were equal.
BigQuery uses the _CHANGE_SEQUENCE_NUMBER to perform ordering
by comparing two or more _CHANGE_SEQUENCE_NUMBER fields as unsigned numeric
values.
Consider the following _CHANGE_SEQUENCE_NUMBER comparison examples and
their precedence results:
Example 1:
- Record #1:
_CHANGE_SEQUENCE_NUMBER= '77' - Record #2:
_CHANGE_SEQUENCE_NUMBER= '7B'
Result: Record #2 is considered the latest record because '7B' > '77' (i.e. '123' > '119')
- Record #1:
Example 2:
- Record #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/B' - Record #2:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC'
Result: Record #2 is considered the latest record because 'FFF/ABC' > 'FFF/B' (i.e. '4095/2748' > '4095/11')
- Record #1:
Example 3:
- Record #1:
_CHANGE_SEQUENCE_NUMBER= 'BA/FFFFFFFF' - Record #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
Result: Record #2 is considered the latest record because 'ABC' > 'BA/FFFFFFFF' (i.e. '2748' > '186/4294967295')
- Record #1:
Example 4:
- Record #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC' - Record #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
Result: Record #1 is considered the latest record because 'FFF/ABC' > 'ABC' (i.e. '4095/2748' > '2748')
- Record #1:
If two _CHANGE_SEQUENCE_NUMBER values are identical, then the record with the
latest BigQuery system ingestion time has precedence over
previously ingested records.
When custom ordering is used for a table, the _CHANGE_SEQUENCE_NUMBER value
should always be supplied. Any write requests that don't specify the
_CHANGE_SEQUENCE_NUMBER value, leading to a mix of rows with and without
_CHANGE_SEQUENCE_NUMBER values, result in unpredictable ordering.
Configure a BigQuery reservation for use with CDC
You can use BigQuery reservations to allocate dedicated BigQuery compute resources for CDC row modification operations. Reservations let you set a cap on the cost of performing these operations. This approach is particularly useful for workflows with frequent CDC operations against large tables, which otherwise would have high on-demand costs due to the large number of bytes processed when performing each operation.
BigQuery CDC jobs that apply pending row modifications within
the max_staleness interval are considered background jobs and use the
BACKGROUND assignment type,
rather than the QUERY assignment type.
In contrast, queries outside of the max_staleness interval that require row
modifications to be applied at query run time use the
QUERY assignment type. Tables without a max_staleness setting or tables with max_staleness set to 0 also use the QUERY assignment type.
BigQuery CDC background jobs performed without a BACKGROUND
assignment use on-demand pricing.
This consideration is important when designing your workload management
strategy for BigQuery CDC.
To configure a BigQuery reservation for use with CDC, start by
configuring a reservation
in the region where your BigQuery
tables are located. For guidance on the size of your reservation, see
Size and monitor BACKGROUND reservations.
Once you have created a reservation,
assign the BigQuery
project to the reservation, and set the job_type option to BACKGROUND by
running the following
CREATE ASSIGNMENT statement:
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
Replace the following:
ADMIN_PROJECT_ID: the ID of the administration project that owns the reservation.REGION: the region name where your project is located. For example,us.RESERVATION_NAME: the name of the reservation.ASSIGNMENT_ID: the ID of the assignment. The ID must be unique to the project and location, start and end with a lowercase letter or a number, and contain only lowercase letters, numbers, and dashes.PROJECT_ID: the ID of the project containing the BigQuery tables that are being modified by BigQuery CDC. This project is assigned to the reservation.
Size and monitor BACKGROUND reservations
Reservations determine the amount of compute resources available to perform
BigQuery compute operations. Undersizing a reservation can
increase the processing time of CDC row modification operations. To size a
reservation accurately, monitor historical slot consumption for the project that
performs the CDC operations by querying the
INFORMATION_SCHEMA.JOBS_TIMELINE view:
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
Replace REGION with the
region name where your project is located. For
example, us.
Deleted data considerations
- BigQuery CDC operations use BigQuery
compute resources. If the CDC operations are configured to use
on-demand billing, CDC operations are
performed regularly using internal BigQuery resources. If the
CDC operations are configured with a
BACKGROUNDreservation, CDC operations are instead subject to the configured reservation's resource availability. If there are not enough resources available within the configured reservation, processing CDC operations, including deletion, might take longer than anticipated. - A CDC
DELETEoperation is considered to be applied only when theupsert_stream_apply_watermarktimestamp has passed the timestamp at which the Storage Write API streamed the operation. For more information on theupsert_stream_apply_watermarktimestamp, see Monitor table upsert operation progress. - To apply CDC
DELETEoperations that arrive out of order, BigQuery maintains a delete retention window of two days. TableDELETEoperations are stored for this period before the standard Google Cloud data deletion process begins.DELETEoperations within the delete retention window use standard BigQuery storage pricing.
Limitations
- BigQuery CDC does not perform key enforcement, so it's essential that your primary keys are unique.
- Primary keys cannot exceed 16 columns.
- CDC-enabled tables cannot have more than 2,000 top-level columns defined by the table's schema.
- CDC-enabled tables don't support the following:
- Mutating
data manipulation language (DML)
statements such as
DELETE,UPDATE, andMERGE - Querying wildcard tables
- Search indexes
- Mutating
data manipulation language (DML)
statements such as
- CDC-enabled tables that perform runtime merge jobs because the table's
max_stalenessvalue is too low cannot support the following: - BigQuery export
operations on CDC-enabled tables don't export recently streamed row
modifications that have yet to be applied by a background job. To export the
full table, use an
EXPORT DATAstatement. - If your query triggers a runtime merge on a partitioned table, then the entire table is scanned whether or not the query is restricted to a subset of the partitions.
- If you are using the Standard edition,
BACKGROUNDreservations are not available, so applying pending row modifications uses the on-demand pricing model. However, you can query CDC-enabled tables regardless of your edition. - Pseudocolumns
_CHANGE_TYPEand_CHANGE_SEQUENCE_NUMBERare not queryable columns when performing a table read. - Mixing rows that have
UPSERTorDELETEvalues for_CHANGE_TYPEwith rows that haveINSERTor unspecified values for_CHANGE_TYPEin the same connection isn't supported and results in the following validation error:The given value is not a valid CHANGE_TYPE.
BigQuery CDC pricing
BigQuery CDC uses the Storage Write API for data ingestion, BigQuery storage for data storage, and BigQuery compute for row modification operations, all of which incur costs. For pricing information, see BigQuery pricing.
Estimate BigQuery CDC costs
In addition to
general BigQuery cost estimation best practices,
estimating the costs of BigQuery CDC might be important for
workflows that have large amounts of data, a low
max_staleness configuration, or frequently changing
data.
BigQuery data ingestion pricing and BigQuery storage pricing are directly calculated by the amount of data that you ingest and store, including pseudocolumns. However, BigQuery compute pricing can be harder to estimate, as it relates to the consumption of compute resources that are used to run BigQuery CDC jobs.
BigQuery CDC jobs are split into three categories:
- Background apply jobs: jobs that run in the background at regular
intervals that are defined by the table's
max_stalenessvalue. These jobs apply recently streamed row modifications into the CDC-enabled table. - Query jobs: GoogleSQL queries that run within the
max_stalenesswindow and only read from the CDC baseline table. - Runtime merge jobs: jobs that are triggered by ad hoc GoogleSQL
queries that run outside the
max_stalenesswindow. These jobs must perform an on-the-fly merge of the CDC baseline table and the recently streamed row modifications at query runtime.
Only query jobs take advantage of BigQuery partitioning. Background apply jobs and runtime merge jobs can't use partitioning because, when applying recently streamed row modifications, there is no guarantee to which table partition the recently streamed upserts are applied to. In other words, the full baseline table is read during background apply jobs and runtime merge jobs. For the same reason, only query jobs can benefit from filters on BigQuery clustering columns. Understanding the amount of data that is being read to perform CDC operations is helpful in estimating the total cost.
If the amount of data being read from the table baseline is high, consider using the BigQuery capacity pricing model, which is not based on the amount of processed data.
BigQuery CDC cost best practices
In addition to general BigQuery cost best practices, use the following techniques to optimize the costs of BigQuery CDC operations:
- Unless necessary, avoid configuring a table's
max_stalenessoption with a very low value. Themax_stalenessvalue can increase the occurrence of background apply jobs and runtime merge jobs, which are more expensive and slower than query jobs. For detailed guidance, see Recommended tablemax_stalenessvalue. - Consider configuring a
BigQuery reservation for use with CDC tables.
Otherwise background apply jobs and runtime merge jobs use on-demand pricing,
which can be more costly due to more data processing. For more details, learn
about
BigQuery reservations and
follow the guidance on
how to size and monitor a
BACKGROUNDreservation for use with BigQuery CDC.
What's next
- Learn how to implement the Storage Write API default stream.
- Learn about best practices for the Storage Write API.
- Learn how to use Datastream to replicate transactional databases to BigQuery with BigQuery CDC.