Introdução ao BigLake Metastore
O metastore do BigLake é unificado, gerenciado, sem servidor e escalonável. Ele conecta dados do lakehouse armazenados no Cloud Storage ou no BigQuery a vários ambientes de execução, incluindo ambientes de execução de código aberto (como Apache Spark e Apache Flink) e o BigQuery.
O metastore do BigLake oferece uma única fonte de verdade para gerenciar metadados de vários mecanismos. Ele oferece suporte a formatos de tabela de código aberto importantes, como o Apache Iceberg, usando tabelas do BigLake Iceberg e tabelas padrão do BigQuery. Além disso, o metastore do BigLake tem suporte para APIs abertas e um catálogo REST do Iceberg (prévia).
Use a tabela a seguir para determinar onde começar sua jornada no BigLake Metastore:
| Caso de uso | Recomendação |
|---|---|
| O mecanismo de código aberto precisa acessar dados no Cloud Storage. | Conheça o catálogo REST do Iceberg (prévia). |
| O mecanismo de código aberto precisa de interoperabilidade com o BigQuery. | Confira a integração do metastore do BigLake com mecanismos de código aberto (como o Spark) usando o plug-in de catálogo personalizado do Iceberg do BigQuery. |
Vantagens
O metastore do BigLake oferece várias vantagens para gerenciamento e análise de dados:
- Arquitetura sem servidor. O metastore do BigLake oferece uma arquitetura sem servidor, eliminando a necessidade de gerenciamento de servidores ou clusters. Isso ajuda a reduzir a sobrecarga operacional, simplifica a implantação e permite o escalonamento automático com base na demanda.
- Interoperabilidade do mecanismo. O metastore do BigLake oferece acesso direto a tabelas em mecanismos de código aberto (como Spark e Flink) e no BigQuery, permitindo que você consulte tabelas de formato aberto sem configuração adicional. Por exemplo, é possível criar uma tabela no Spark e consultá-la diretamente no BigQuery. Isso ajuda a simplificar seu fluxo de trabalho de análise e reduz a necessidade de processos complexos de movimentação de dados ou ETL.
Experiência do usuário unificada. O metastore do BigLake oferece um fluxo de trabalho unificado no BigQuery e em mecanismos de código aberto. Essa experiência unificada significa que você pode configurar um ambiente do Spark autohospedado ou hospedado pelo Dataproc usando o catálogo REST do Iceberg (pré-lançamento) ou configurar um ambiente do Spark em um notebook do BigQuery Studio para fazer a mesma coisa.
Por exemplo, no BigQuery Studio, é possível criar uma tabela no Spark com um notebook do BigQuery Studio.
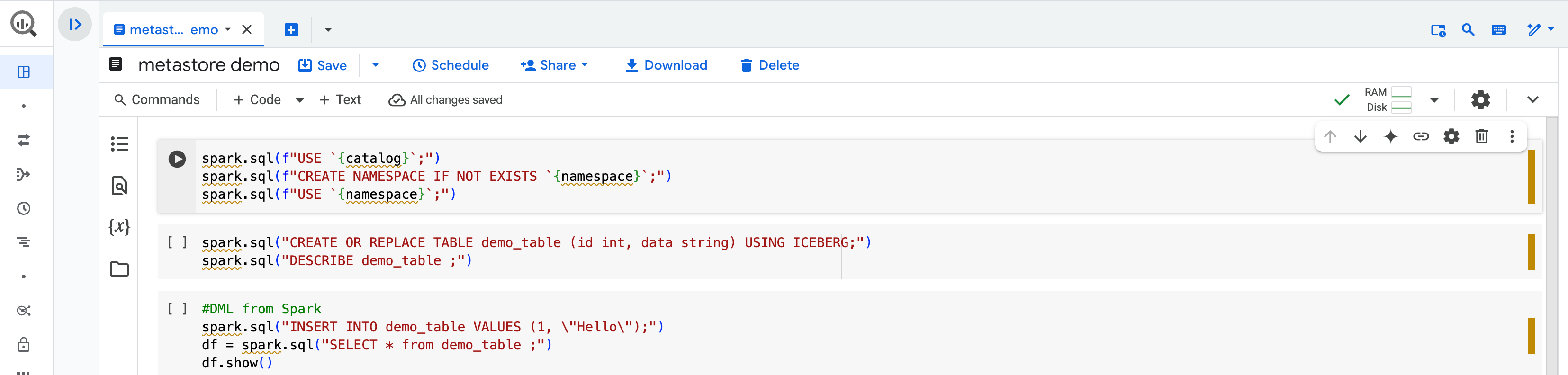
Em seguida, é possível consultar a mesma tabela do Spark no console doGoogle Cloud .
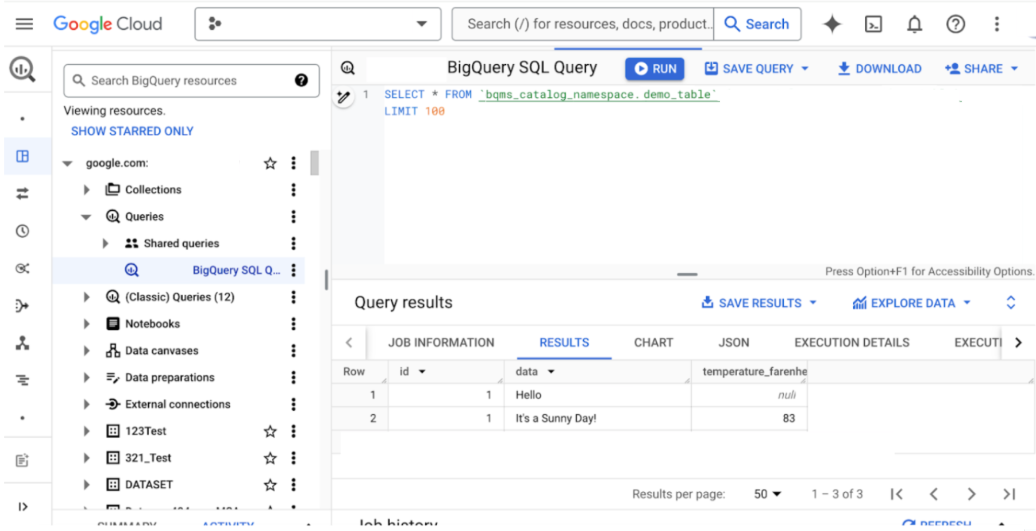
Formatos de tabela no BigLake Metastore
O BigLake é compatível com vários tipos de tabelas. Use a tabela a seguir para ajudar a selecionar o formato mais adequado ao seu caso de uso:
| Tabelas externas | Tabelas do BigLake Iceberg | Tabelas do BigLake Iceberg no BigQuery | Tabelas padrão do BigQuery | |
|---|---|---|---|---|
| Metastore | Metastore externa ou auto-hospedada | Metastore do BigLake | Metastore do BigLake | Metastore do BigLake |
| Armazenamento | Cloud Storage / Amazon S3 / Azure | Cloud Storage | Cloud Storage | BigQuery |
| Gerenciamento | Cliente ou terceiros | Google (experiência altamente gerenciada) | Google (experiência mais gerenciada) | |
| Leitura / gravação |
Mecanismos de código aberto (leitura/gravação) BigQuery (somente leitura) |
Mecanismos de código aberto (leitura/gravação) BigQuery (somente leitura) |
Mecanismos de código aberto (somente leitura com bibliotecas do Iceberg, interoperabilidade de leitura/gravação com a API BigQuery Storage)
BigQuery (leitura/gravação) |
Mecanismos de código aberto (interoperabilidade de leitura/gravação com a API BigQuery Storage) BigQuery (leitura/gravação) |
| Use cases | Migrações, tabelas de teste para cargas do BigQuery e autogestão | Open lakehouse | Lakehouse aberto, armazenamento de nível empresarial para análises, streaming e IA | Armazenamento de nível empresarial para análises, streaming e IA |
Diferenças com o BigLake Metastore (clássico)
O metastore do BigLake é o recomendado no Google Cloud.
As principais diferenças entre o BigLake Metastore e o BigLake Metastore (clássico) incluem os seguintes detalhes:
- O metastore do BigLake (clássico) é um serviço independente que é diferente do BigQuery e só oferece suporte a tabelas do Iceberg. Ele tem um modelo de recurso de três partes diferente. As tabelas da metastore do BigLake (clássico) não são descobertas automaticamente no BigQuery.
- As tabelas no metastore do BigLake podem ser acessadas de vários mecanismos de código aberto e do BigQuery. O BigLake Metastore oferece suporte à integração direta com o Spark, o que ajuda a reduzir a redundância ao armazenar metadados e executar jobs. O BigLake Metastore também é compatível com o catálogo REST do Iceberg (versão prévia), que conecta dados do lakehouse em vários tempos de execução.
Limitações
As seguintes limitações se aplicam às tabelas no BigLake Metastore:
- Não é possível criar ou modificar tabelas do metastore do BigLake com instruções DDL ou DML usando o mecanismo do BigQuery. É possível modificar as tabelas de metastore do BigLake usando a API BigQuery (com a ferramenta de linha de comando bq ou bibliotecas de cliente), mas isso pode causar mudanças incompatíveis com o mecanismo externo.
- As tabelas do metastore do BigLake não são compatíveis com operações de renomeação ou instruções
ALTER TABLE ... RENAME TOdo Spark SQL. - As tabelas do metastore do BigLake estão sujeitas às mesmas cotas e limites das tabelas padrão.
- O desempenho da consulta para tabelas de metastore do BigLake no mecanismo do BigQuery pode ser lento em comparação com a consulta de dados em uma tabela padrão do BigQuery. Em geral, o desempenho da consulta em uma tabela do metastore do BigLake precisa ser equivalente à leitura dos dados diretamente do Cloud Storage.
- Uma simulação de uma consulta que usa uma tabela de metastore do BigLake pode relatar um limite inferior de 0 bytes de dados, mesmo que as linhas sejam retornadas. Isso acontece porque a quantidade de dados processados da tabela não pode ser determinada até que a consulta real seja concluída. A execução da consulta gera um custo para o tratamento desses dados.
- Não é possível referenciar uma tabela do metastore do BigLake em uma consulta de tabela curinga.
- Não é possível usar o
método
tabledata.listpara recuperar dados das tabelas do metastore do BigLake. Em vez disso, salve os resultados da consulta em uma tabela de destino e use o métodotabledata.listnessa tabela. - As tabelas do metastore do BigLake não são compatíveis com clustering.
- As tabelas do metastore do BigLake não são compatíveis com nomes de colunas flexíveis.
- A exibição de estatísticas de armazenamento de tabelas do metastore do BigLake não é compatível.
A seguir
- Migrar dados do metastore do Dataproc para o metastore do BigLake
- Usar o metastore do BigLake com o Dataproc
- Usar o metastore BigLake com o Dataproc sem servidor