Questo tutorial ti insegna a utilizzare un modello di serie temporale multivariata per prevedere il valore futuro di una determinata colonna, in base al valore storico di più funzionalità di input.
Questo tutorial esegue previsioni per più serie temporali. I valori previsti vengono calcolati per ogni punto temporale, per ogni valore in una o più colonne specificate. Ad esempio, se vuoi prevedere il meteo e hai specificato una colonna contenente dati statali, i dati previsti conterranno le previsioni per tutti i punti temporali per lo stato A, poi i valori previsti per tutti i punti temporali per lo stato B e così via. Se volessi prevedere il meteo e specificassi colonne contenenti dati di stato e città, i dati previsti conterrebbero previsioni per tutti i punti temporali per lo stato A e la città A, poi i valori previsti per tutti i punti temporali per lo stato A e la città B e così via.
Questo tutorial utilizza i dati delle tabelle pubbliche
bigquery-public-data.iowa_liquor_sales.sales
e
bigquery-public-data.covid19_weathersource_com.postal_code_day_history. La tabella bigquery-public-data.iowa_liquor_sales.sales contiene
dati sulle vendite di alcolici raccolti da più città dello stato dell'Iowa. La
tabella bigquery-public-data.covid19_weathersource_com.postal_code_day_history
contiene dati meteo storici, come temperatura e umidità, provenienti da
tutto il mondo.
Prima di leggere questo tutorial, ti consigliamo vivamente di leggere Previsione di una singola serie temporale con un modello multivariato.
Crea un set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML.
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Multi-regione e poi Stati Uniti (più regioni negli Stati Uniti).
Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
bq
Per creare un nuovo set di dati, utilizza il
comando bq mk
con il flag --location. Per un elenco completo dei possibili parametri, consulta la
documentazione di riferimento del
comando bq mk --dataset.
Crea un set di dati denominato
bqml_tutorialcon la località dei dati impostata suUSe una descrizione diBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anziché utilizzare il flag
--dataset, il comando utilizza la scorciatoia-d. Se ometti-de--dataset, il comando crea per impostazione predefinita un dataset.Verifica che il set di dati sia stato creato:
bq ls
API
Chiama il metodo datasets.insert con una risorsa dataset definita.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Crea una tabella di dati di input
Crea una tabella di dati che puoi utilizzare per addestrare e valutare il modello. Questa
tabella combina le colonne delle tabelle
bigquery-public-data.iowa_liquor_sales.sales e
bigquery-public-data.covid19_weathersource_com.postal_code_day_history
per analizzare in che modo il meteo influisce sul tipo e sul numero di articoli ordinati dai negozi di liquori. Crea anche le seguenti colonne aggiuntive che puoi utilizzare come
variabili di input per il modello:
date: la data dell'ordinestore_number: il numero univoco del negozio che ha effettuato l'ordineitem_number: il numero univoco dell'articolo ordinatobottles_sold: il numero di bottiglie ordinate dell'articolo associatotemperature: la temperatura media nella sede del negozio alla data dell'ordinehumidity: l'umidità media nella sede del negozio alla data dell'ordine
Per creare la tabella dei dati di input:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE TABLE `bqml_tutorial.iowa_liquor_sales_with_weather` AS WITH sales AS ( SELECT DATE, store_number, item_number, bottles_sold, SAFE_CAST(SAFE_CAST(zip_code AS FLOAT64) AS INT64) AS zip_code FROM `bigquery-public-data.iowa_liquor_sales.sales` AS sales WHERE SAFE_CAST(zip_code AS FLOAT64) IS NOT NULL ), aggregated_sales AS ( SELECT DATE, store_number, item_number, ANY_VALUE(zip_code) AS zip_code, SUM(bottles_sold) AS bottles_sold, FROM sales GROUP BY DATE, store_number, item_number ), weather AS ( SELECT DATE, SAFE_CAST(postal_code AS INT64) AS zip_code, avg_temperature_air_2m_f AS temperature, avg_humidity_specific_2m_gpkg AS humidity, FROM `bigquery-public-data.covid19_weathersource_com.postal_code_day_history` WHERE country = 'US' AND SAFE_CAST(postal_code AS INT64) IS NOT NULL ) SELECT aggregated_sales.date, aggregated_sales.store_number, aggregated_sales.item_number, aggregated_sales.bottles_sold, weather.temperature AS temperature, weather.humidity AS humidity FROM aggregated_sales LEFT JOIN weather ON aggregated_sales.zip_code=weather.zip_code AND aggregated_sales.DATE=weather.DATE;
Crea il modello di serie temporali
Crea un modello di serie temporale per prevedere le bottiglie vendute per ogni combinazione
di ID negozio e ID articolo, per ogni data nella
tabella bqml_tutorial.iowa_liquor_sales_with_weather prima del
1° settembre 2022. Utilizza la temperatura e l'umidità medie della sede del negozio
in ogni data come caratteristiche da valutare durante la previsione. Nella tabella bqml_tutorial.iowa_liquor_sales_with_weather sono presenti circa 1 milione di combinazioni distinte di numero articolo e numero negozio, il che significa che ci sono 1 milione di serie temporali diverse da prevedere.
Per creare il modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.multi_time_series_arimax_model` OPTIONS( model_type = 'ARIMA_PLUS_XREG', time_series_id_col = ['store_number', 'item_number'], time_series_data_col = 'bottles_sold', time_series_timestamp_col = 'date' ) AS SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE < DATE('2022-09-01');
Il completamento della query richiede circa 38 minuti, dopodiché puoi accedere al modello
multi_time_series_arimax_model. Poiché la query utilizza un'istruzioneCREATE MODELper creare un modello, non vengono visualizzati i risultati della query.
Utilizzare il modello per prevedere i dati
Prevedi i valori futuri delle serie temporali utilizzando la funzione ML.FORECAST.
Nella seguente query GoogleSQL, la
clausola STRUCT(5 AS horizon, 0.8 AS confidence_level) indica che la
query prevede 5 punti temporali futuri e genera un intervallo di previsione
con un livello di confidenza dell'80%.
La firma dei dati di input per la funzione ML.FORECAST è
la stessa dei dati di addestramento che hai utilizzato per creare
il modello. La colonna bottles_sold non è inclusa nell'input perché
contiene i dati che il modello sta cercando di prevedere.
Per prevedere i dati con il modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE>=DATE('2022-09-01') ) );
I risultati dovrebbero essere simili ai seguenti:
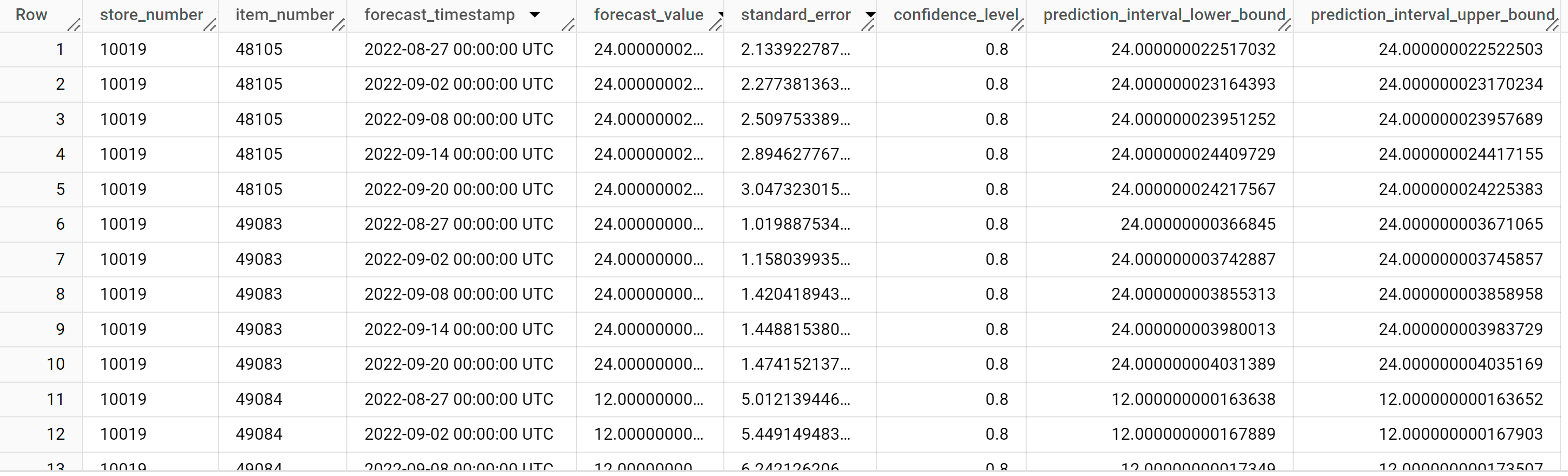
Le righe di output sono ordinate in base al valore
store_number, poi in base al valoreitem_IDe infine in ordine cronologico in base al valore della colonnaforecast_timestamp. Nella previsione delle serie temporali, l'intervallo di previsione, rappresentato dai valori delle colonneprediction_interval_lower_boundeprediction_interval_upper_bound, è importante quanto il valore della colonnaforecast_value. Il valoreforecast_valueè il punto medio dell'intervallo di previsione. L'intervallo di previsione dipende dai valori delle colonnestandard_erroreconfidence_level.Per ulteriori informazioni sulle colonne di output, vedi
ML.FORECAST.
Spiegare i risultati delle previsioni
Puoi ottenere metriche di interpretabilità oltre ai dati di previsione utilizzando la
funzione ML.EXPLAIN_FORECAST. La funzione ML.EXPLAIN_FORECAST prevede
i valori futuri delle serie temporali e restituisce anche tutti i componenti separati delle
serie temporali.
Analogamente alla funzione ML.FORECAST, la clausola STRUCT(5 AS horizon, 0.8 AS confidence_level) utilizzata nella funzione ML.EXPLAIN_FORECAST indica che la query prevede 30 punti temporali futuri e genera un intervallo di previsione con un livello di confidenza dell'80%.
La funzione ML.EXPLAIN_FORECAST fornisce sia dati storici sia
dati di previsione. Per visualizzare solo i dati di previsione, aggiungi l'opzione time_series_type
alla query e specifica forecast come valore dell'opzione.
Per spiegare i risultati del modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.EXPLAIN_FORECAST ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (5 AS horizon, 0.8 AS confidence_level), ( SELECT * EXCEPT (bottles_sold) FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
I risultati dovrebbero essere simili ai seguenti:
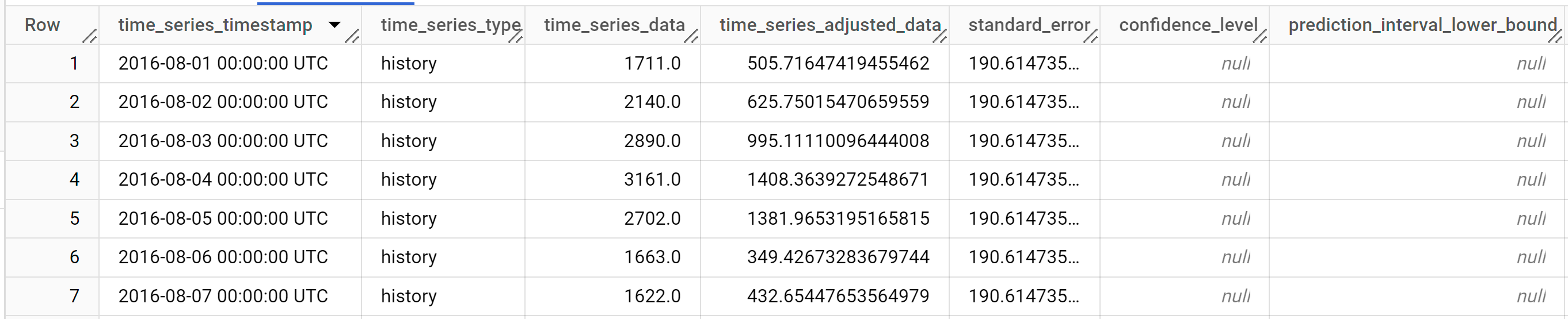
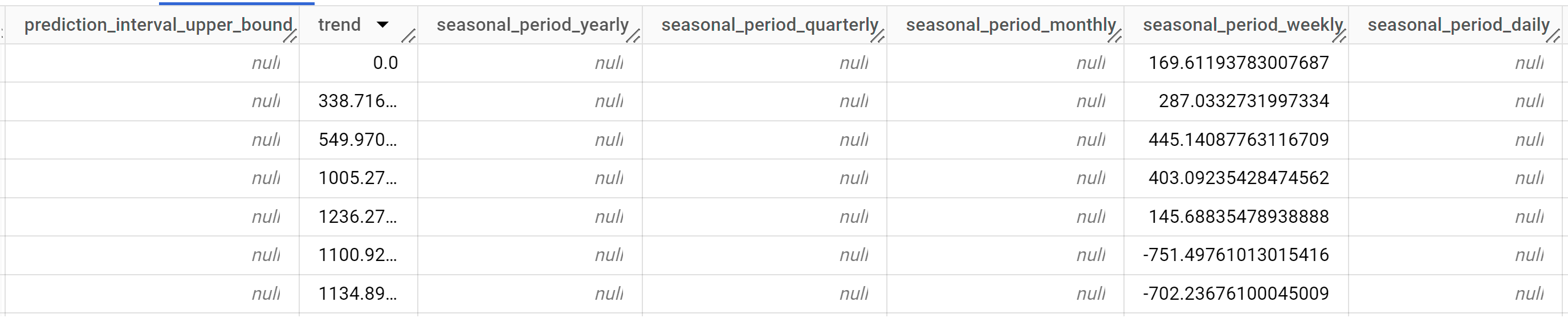
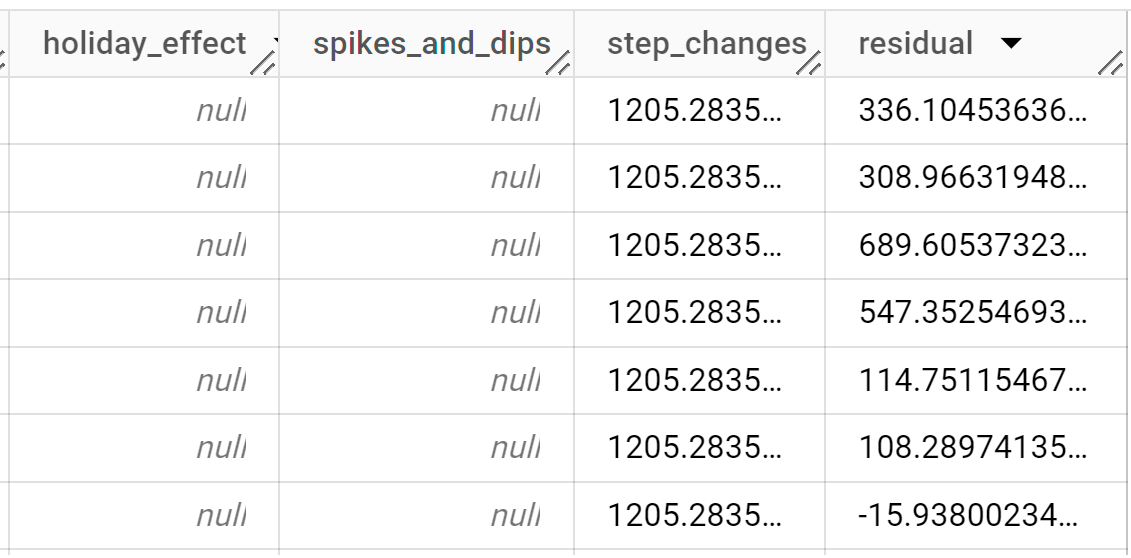
Le righe di output sono ordinate cronologicamente in base al valore della colonna
time_series_timestamp.Per ulteriori informazioni sulle colonne di output, vedi
ML.EXPLAIN_FORECAST.
Valutare l'accuratezza delle previsioni
Valuta l'accuratezza della previsione del modello eseguendolo su dati su cui non è stato addestrato. Puoi farlo utilizzando la funzione ML.EVALUATE. La funzione ML.EVALUATE valuta ogni serie temporale in modo indipendente.
Nella seguente query GoogleSQL, la seconda istruzione SELECT
fornisce i dati con le funzionalità future, che vengono utilizzati
per prevedere i valori futuri da confrontare con i dati effettivi.
Per valutare l'accuratezza del modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.EVALUATE ( model `bqml_tutorial.multi_time_series_arimax_model`, ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
I risultati dovrebbero essere simili ai seguenti:
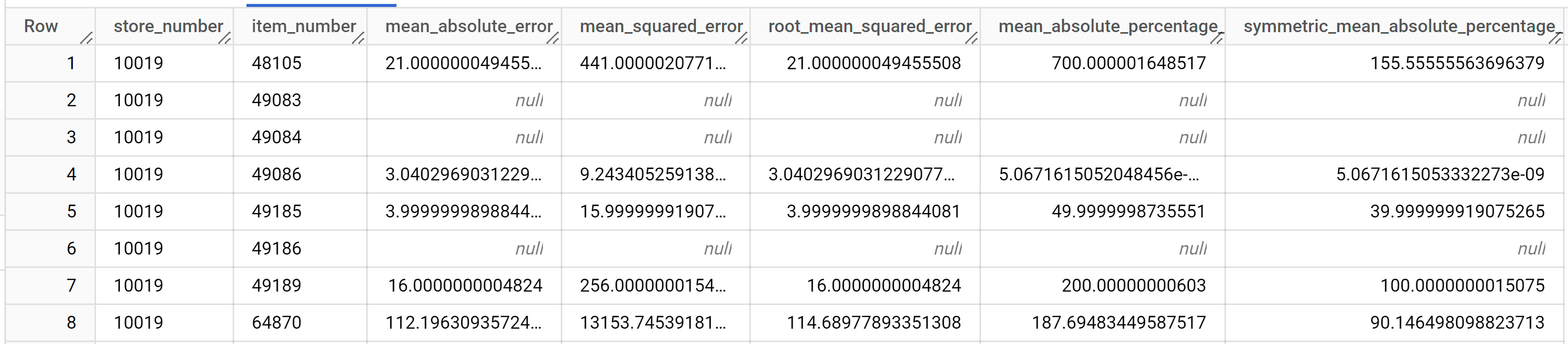
Per ulteriori informazioni sulle colonne di output, vedi
ML.EVALUATE.
Utilizzare il modello per rilevare le anomalie
Rileva le anomalie nei dati di addestramento utilizzando la funzione ML.DETECT_ANOMALIES.
Nella query seguente, la clausola STRUCT(0.95 AS anomaly_prob_threshold)
fa sì che la funzione ML.DETECT_ANOMALIES identifichi i punti dati anomali
con un livello di confidenza del 95%.
Per rilevare anomalie nei dati di addestramento:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold) );
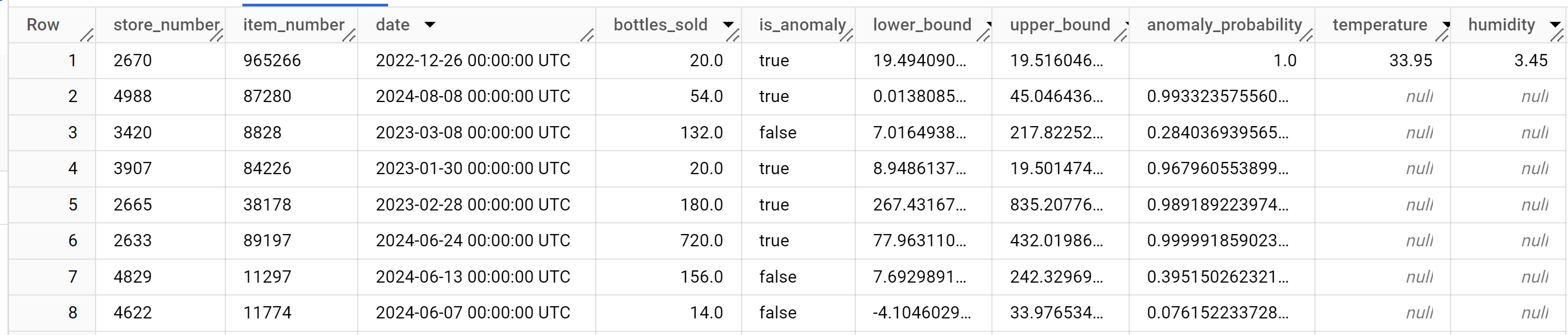
I risultati dovrebbero essere simili ai seguenti:
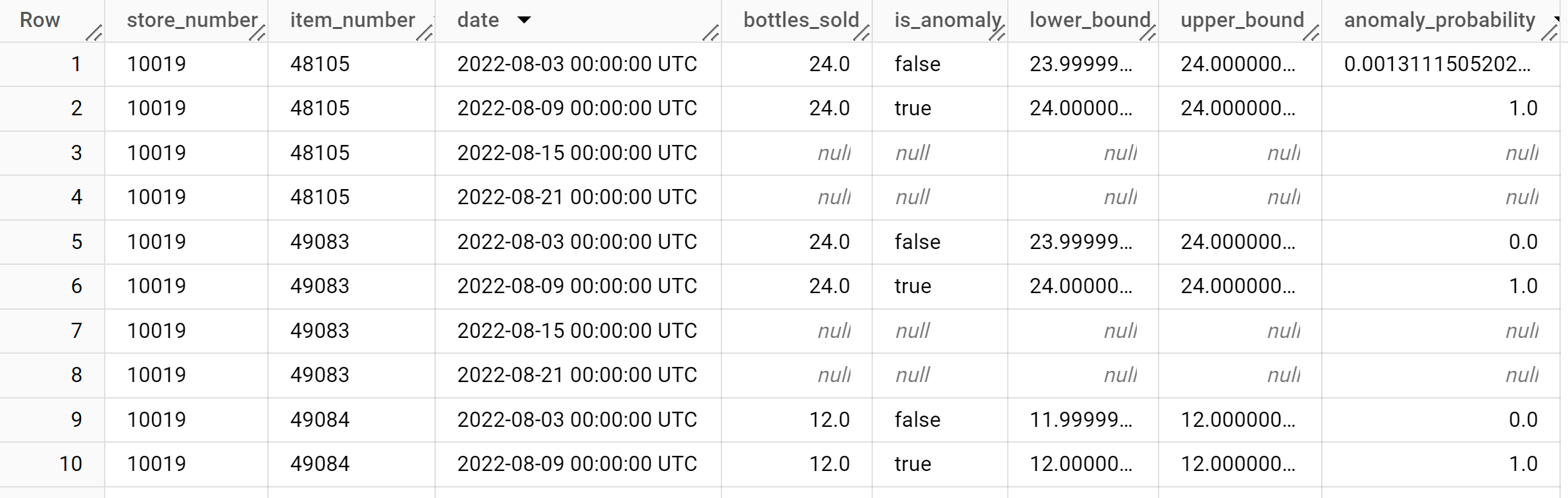
La colonna
anomaly_probabilitynei risultati identifica la probabilità che un determinato valore della colonnabottles_soldsia anomalo.Per ulteriori informazioni sulle colonne di output, vedi
ML.DETECT_ANOMALIES.
Rilevare anomalie nei nuovi dati
Rileva le anomalie nei nuovi dati fornendo i dati di input alla funzione
ML.DETECT_ANOMALIES. I nuovi dati devono avere la stessa firma
dei dati di addestramento.
Per rilevare le anomalie nei nuovi dati:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.DETECT_ANOMALIES ( model `bqml_tutorial.multi_time_series_arimax_model`, STRUCT (0.95 AS anomaly_prob_threshold), ( SELECT * FROM `bqml_tutorial.iowa_liquor_sales_with_weather` WHERE DATE >= DATE('2022-09-01') ) );
I risultati dovrebbero essere simili ai seguenti: