Questo tutorial ti insegna a utilizzare un modello di serie temporale multivariata per prevedere il valore futuro di una determinata colonna, in base al valore storico di più funzionalità di input.
Questo tutorial prevede una singola serie temporale. I valori previsti vengono calcolati una volta per ogni punto temporale nei dati di input.
Questo tutorial utilizza i dati del
set di dati pubblico bigquery-public-data.epa_historical_air_quality. Questo
set di dati contiene informazioni giornaliere sul particolato (PM2,5),
sulla temperatura e sulla velocità del vento raccolte in più città degli Stati Uniti.
Crea un set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML.
Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
Nella pagina Crea set di dati:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Multi-regione e poi Stati Uniti (più regioni negli Stati Uniti).
Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
bq
Per creare un nuovo set di dati, utilizza il
comando bq mk
con il flag --location. Per un elenco completo dei possibili parametri, consulta la
documentazione di riferimento del
comando bq mk --dataset.
Crea un set di dati denominato
bqml_tutorialcon la località dei dati impostata suUSe una descrizione diBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anziché utilizzare il flag
--dataset, il comando utilizza la scorciatoia-d. Se ometti-de--dataset, il comando crea per impostazione predefinita un dataset.Verifica che il set di dati sia stato creato:
bq ls
API
Chiama il metodo datasets.insert con una risorsa dataset definita.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery che utilizza BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per maggiori informazioni, vedi Configurare ADC per un ambiente di sviluppo locale.
Crea una tabella di dati di input
Crea una tabella di dati che puoi utilizzare per addestrare e valutare il modello. Questa
tabella combina le colonne di diverse tabelle del
set di dati bigquery-public-data.epa_historical_air_quality per fornire
dati meteo giornalieri. Crea anche le seguenti colonne da utilizzare come
variabili di input per il modello:
date: la data dell'osservazionepm25il valore medio di PM2,5 per ogni giornowind_speed: la velocità media del vento per ogni giornotemperature: la temperatura più alta per ogni giorno
Nella seguente query GoogleSQL, la clausola
FROM bigquery-public-data.epa_historical_air_quality.*_daily_summaryindica che stai eseguendo query sulle tabelle *_daily_summary nel set di dati
epa_historical_air_quality. Queste tabelle sono
tabelle partizionate.
Per creare la tabella dei dati di input:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE TABLE `bqml_tutorial.seattle_air_quality_daily` AS WITH pm25_daily AS ( SELECT avg(arithmetic_mean) AS pm25, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass' GROUP BY date_local ), wind_speed_daily AS ( SELECT avg(arithmetic_mean) AS wind_speed, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.wind_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant' GROUP BY date_local ), temperature_daily AS ( SELECT avg(first_max_value) AS temperature, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.temperature_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature' GROUP BY date_local ) SELECT pm25_daily.date AS date, pm25, wind_speed, temperature FROM pm25_daily JOIN wind_speed_daily USING (date) JOIN temperature_daily USING (date);
Visualizzare i dati di input
Prima di creare il modello, puoi visualizzare facoltativamente i dati delle serie temporali di input per farti un'idea della distribuzione. Puoi farlo utilizzando Looker Studio.
Segui questi passaggi per visualizzare i dati delle serie temporali:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`;
Al termine della query, fai clic su Esplora i dati > Esplora con Looker Studio. Looker Studio si apre in una nuova scheda. Completa i seguenti passaggi nella nuova scheda.
In Looker Studio, fai clic su Inserisci > Grafico delle serie temporali.
Nel riquadro Grafico, scegli la scheda Configurazione.
Nella sezione Metrica, aggiungi i campi pm25, temperature e wind_speed e rimuovi la metrica predefinita Conteggio record. Il grafico risultante è simile al seguente:
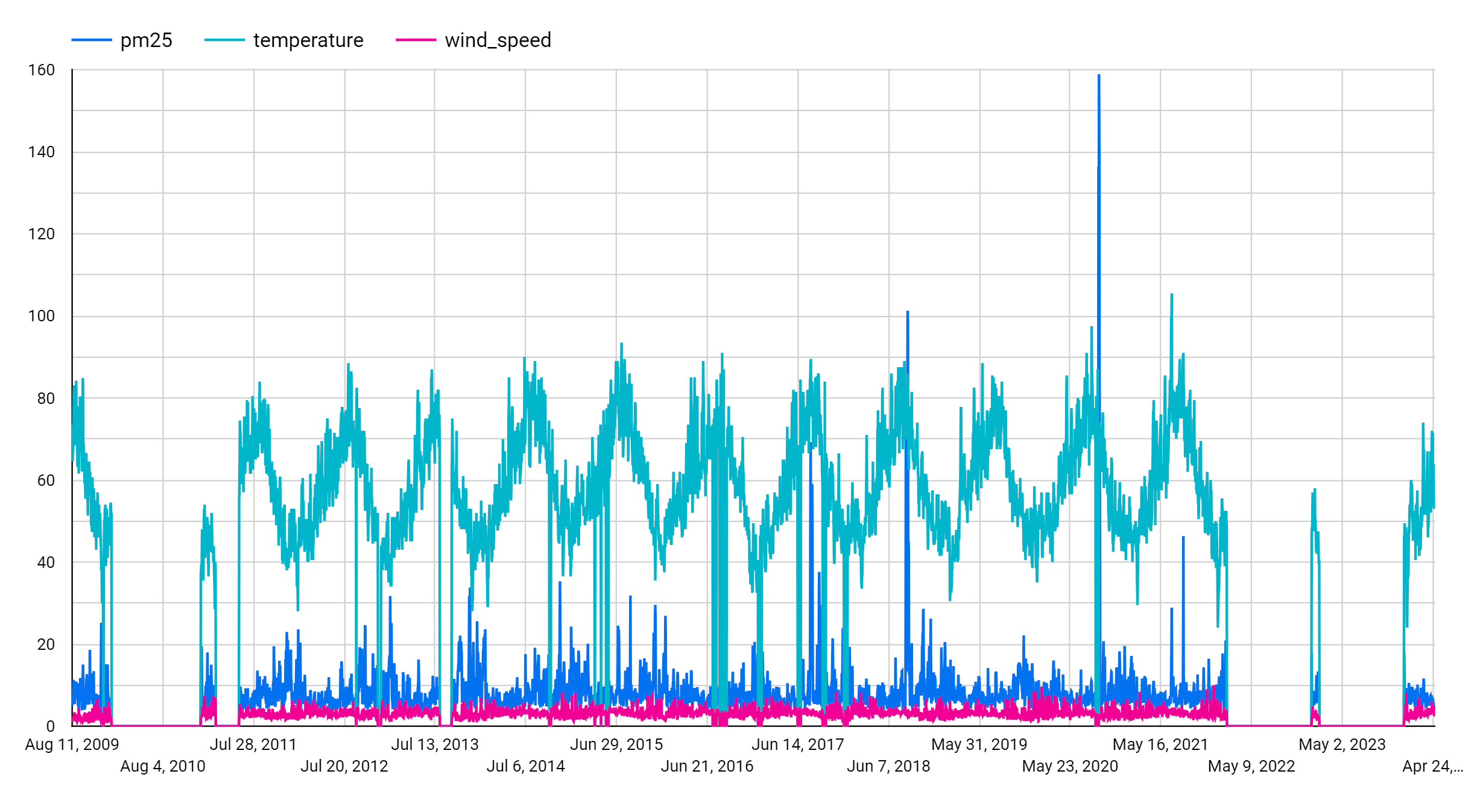
Dal grafico puoi notare che la serie temporale di input presenta un pattern stagionale settimanale.
Crea il modello di serie temporali
Crea un modello di serie temporale per prevedere i valori di particolato, come rappresentato
dalla colonna pm25, utilizzando i valori delle colonne pm25, wind_speed e temperature
come variabili di input. Addestra il modello sui dati sulla qualità dell'aria della tabella
bqml_tutorial.seattle_air_quality_daily, selezionando i dati raccolti
tra il 1° gennaio 2012 e il 31 dicembre 2020.
Nella seguente query, la clausola OPTIONS(model_type='ARIMA_PLUS_XREG',
time_series_timestamp_col='date', ...) indica che stai creando
un modello ARIMA con regressori esterni. L'opzione auto_arima dell'istruzione CREATE MODEL è impostata su TRUE per impostazione predefinita, quindi l'algoritmo auto.ARIMA ottimizza automaticamente gli iperparametri nel modello. L'algoritmo
adatta decine di modelli candidati e sceglie il migliore, ovvero quello
con il criterio di informazione di Akaike (AIC) più basso.
L'opzione data_frequency delle istruzioni CREATE MODEL è impostata su AUTO_FREQUENCY per impostazione predefinita, pertanto il processo di addestramento deduce automaticamente la frequenza dei dati della serie temporale di input.
Per creare il modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
CREATE OR REPLACE MODEL `bqml_tutorial.seattle_pm25_xreg_model` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS_XREG', time_series_timestamp_col = 'date', # Identifies the column that contains time points time_series_data_col = 'pm25') # Identifies the column to forecast AS SELECT date, # The column that contains time points pm25, # The column to forecast temperature, # Temperature input to use in forecasting wind_speed # Wind speed input to use in forecasting FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31');
Il completamento della query richiede circa 20 secondi, dopodiché puoi accedere al modello
seattle_pm25_xreg_model. Poiché la query utilizza un'istruzioneCREATE MODELper creare un modello, non vengono visualizzati i risultati della query.
Valutare i modelli candidati
Valuta i modelli di serie temporali utilizzando la funzione ML.ARIMA_EVALUATE. La funzione ML.ARIMA_EVALUATE mostra le metriche di valutazione di tutti i modelli candidati valutati durante il processo di tuning automatico degli iperparametri.
Per valutare il modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
I risultati dovrebbero essere simili ai seguenti:

Le colonne di output
non_seasonal_p,non_seasonal_d,non_seasonal_qehas_driftdefiniscono un modello ARIMA nella pipeline di addestramento. Le colonne di outputlog_likelihood,AICevariancesono pertinenti per la procedura di adattamento del modello ARIMA.L'algoritmo
auto.ARIMAutilizza il test KPSS per determinare il valore migliore pernon_seasonal_d, che in questo caso è1. Quandonon_seasonal_dè1, l'algoritmoauto.ARIMAaddestra 42 diversi modelli ARIMA candidati in parallelo. In questo esempio, tutti i 42 modelli candidati sono validi, quindi l'output contiene 42 righe, una per ogni modello ARIMA candidato; nei casi in cui alcuni modelli non sono validi, vengono esclusi dall'output. Questi modelli candidati vengono restituiti in ordine crescente in base all'AIC. Il modello nella prima riga ha l'AIC più basso ed è considerato il migliore. Il modello migliore viene salvato come modello finale e viene utilizzato quando chiami funzioni comeML.FORECASTsul modello.La colonna
seasonal_periodscontiene informazioni sul pattern stagionale identificato nei dati delle serie temporali. Non ha nulla a che fare con la modellazione ARIMA, pertanto ha lo stesso valore in tutte le righe di output. Mostra un pattern settimanale, che corrisponde ai risultati visualizzati se hai scelto di visualizzare i dati di input.Le colonne
has_holiday_effect,has_spikes_and_dipsehas_step_changesforniscono informazioni sui dati delle serie temporali di input e non sono correlate alla modellazione ARIMA. Queste colonne vengono restituite perché il valore dell'opzionedecompose_time_seriesnell'istruzioneCREATE MODELèTRUE. Queste colonne hanno anche gli stessi valori in tutte le righe di output.La colonna
error_messagemostra gli eventuali errori riscontrati durante il processo di adattamentoauto.ARIMA. Uno dei possibili motivi degli errori è che le colonnenon_seasonal_p,non_seasonal_d,non_seasonal_qehas_driftselezionate non sono in grado di stabilizzare la serie temporale. Per recuperare il messaggio di errore di tutti i modelli candidati, imposta l'opzioneshow_all_candidate_modelssuTRUEquando crei il modello.Per ulteriori informazioni sulle colonne di output, consulta la funzione
ML.ARIMA_EVALUATE.
Ispezionare i coefficienti del modello
Esamina i coefficienti del modello di serie temporale utilizzando la funzione
ML.ARIMA_COEFFICIENTS.
Per recuperare i coefficienti del modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
I risultati dovrebbero essere simili ai seguenti:
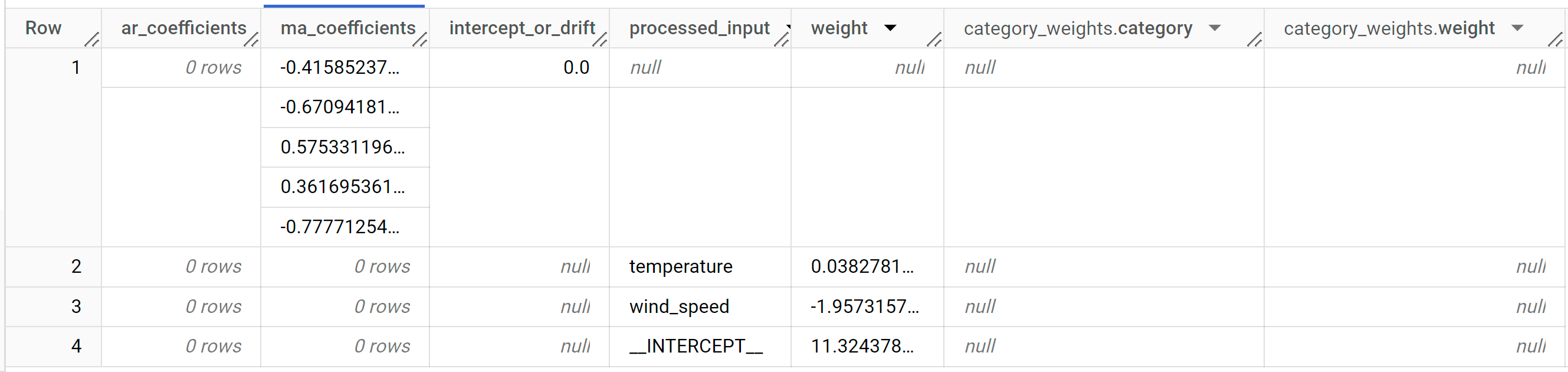
La colonna di output
ar_coefficientsmostra i coefficienti del modello della parte autoregressiva (AR) del modello ARIMA. Analogamente, la colonna di outputma_coefficientsmostra i coefficienti del modello della parte di media mobile (MA) del modello ARIMA. Entrambe queste colonne contengono valori di array, le cui lunghezze sono uguali anon_seasonal_penon_seasonal_q, rispettivamente. Nell'output della funzioneML.ARIMA_EVALUATEhai visto che il modello migliore ha un valorenon_seasonal_ppari a0e un valorenon_seasonal_qpari a5. Pertanto, nell'outputML.ARIMA_COEFFICIENTS, il valorear_coefficientsè un array vuoto e il valorema_coefficientsè un array di 5 elementi. Il valoreintercept_or_driftè il termine costante nel modello ARIMA.Le colonne di output
processed_input,weightecategory_weightsmostrano i pesi per ogni funzionalità e l'intercetta nel modello di regressione lineare. Se la caratteristica è numerica, il peso si trova nella colonnaweight. Se la caratteristica è categorica, il valorecategory_weightsè un array di valori struct, dove ogni valore struct contiene il nome e il peso di una determinata categoria.Per ulteriori informazioni sulle colonne di output, consulta la funzione
ML.ARIMA_COEFFICIENTS.
Utilizzare il modello per prevedere i dati
Prevedi i valori futuri delle serie temporali utilizzando la funzione ML.FORECAST.
Nella seguente query GoogleSQL, la clausola
STRUCT(30 AS horizon, 0.8 AS confidence_level) indica che la
query prevede 30 punti temporali futuri e genera un intervallo di previsione
con un livello di confidenza dell'80%.
Per prevedere i dati con il modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
I risultati dovrebbero essere simili ai seguenti:
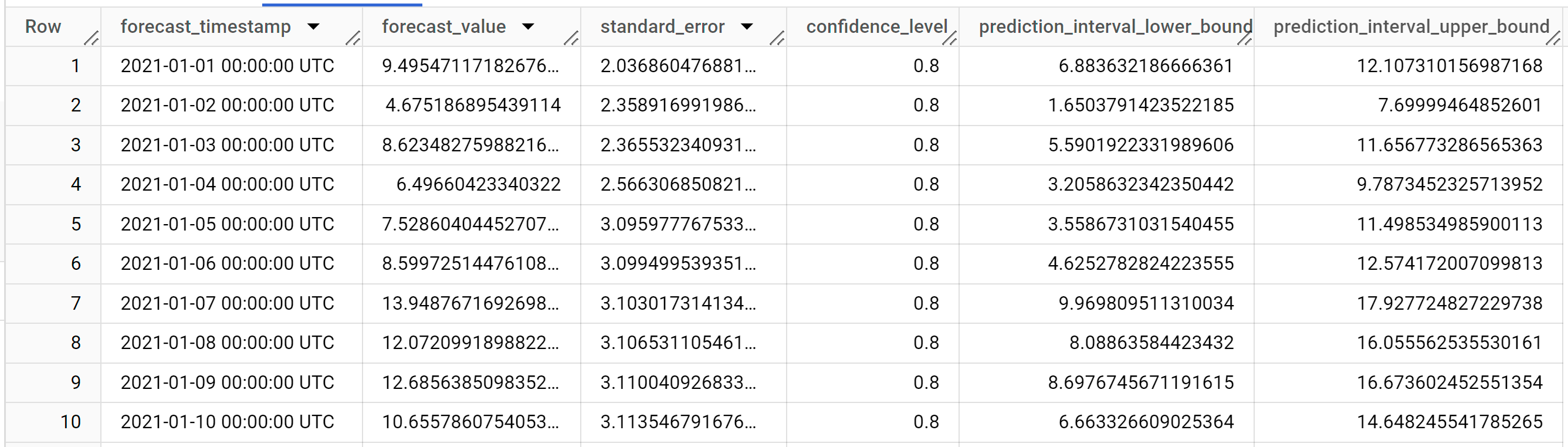
Le righe di output sono in ordine cronologico in base al valore della colonna
forecast_timestamp. Nella previsione delle serie temporali, l'intervallo di previsione, rappresentato dai valori delle colonneprediction_interval_lower_boundeprediction_interval_upper_bound, è importante quanto il valore della colonnaforecast_value. Il valoreforecast_valueè il punto medio dell'intervallo di previsione. L'intervallo di previsione dipende dai valori delle colonnestandard_erroreconfidence_level.Per ulteriori informazioni sulle colonne di output, consulta la funzione
ML.FORECAST.
Valutare l'accuratezza delle previsioni
Valuta l'accuratezza della previsione del modello utilizzando la funzione ML.EVALUATE.
Nella seguente query GoogleSQL, la seconda istruzione SELECT
fornisce i dati con le funzionalità future, che vengono utilizzati
per prevedere i valori futuri da confrontare con i dati effettivi.
Per valutare l'accuratezza del modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, ( SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon));
I risultati dovrebbero essere simili ai seguenti:

Per ulteriori informazioni sulle colonne di output, consulta la funzione
ML.EVALUATE.
Spiegare i risultati delle previsioni
Puoi ottenere metriche di interpretabilità oltre ai dati di previsione utilizzando la
funzione ML.EXPLAIN_FORECAST. La funzione ML.EXPLAIN_FORECAST prevede
i valori futuri delle serie temporali e restituisce anche tutti i componenti separati delle
serie temporali.
Analogamente alla funzione ML.FORECAST, la clausola STRUCT(30 AS horizon, 0.8 AS confidence_level) utilizzata nella funzione ML.EXPLAIN_FORECAST indica che la query prevede 30 punti temporali futuri e genera un intervallo di previsione con un livello di confidenza dell'80%.
Per spiegare i risultati del modello:
Nella console Google Cloud , vai alla pagina BigQuery.
Nell'editor di query, incolla la seguente query e fai clic su Esegui:
SELECT * FROM ML.EXPLAIN_FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
I risultati dovrebbero essere simili ai seguenti:
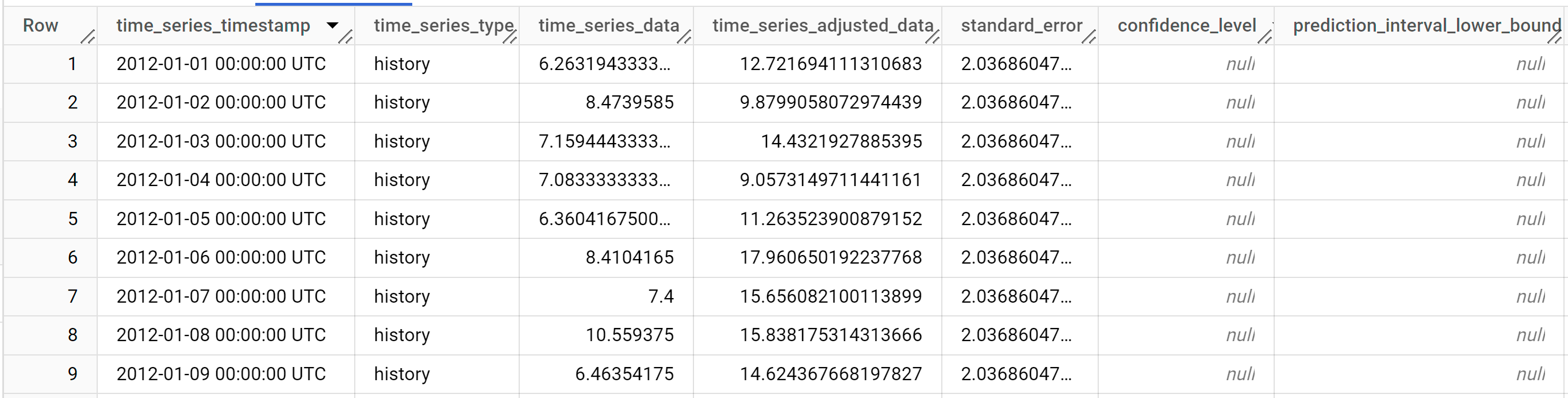
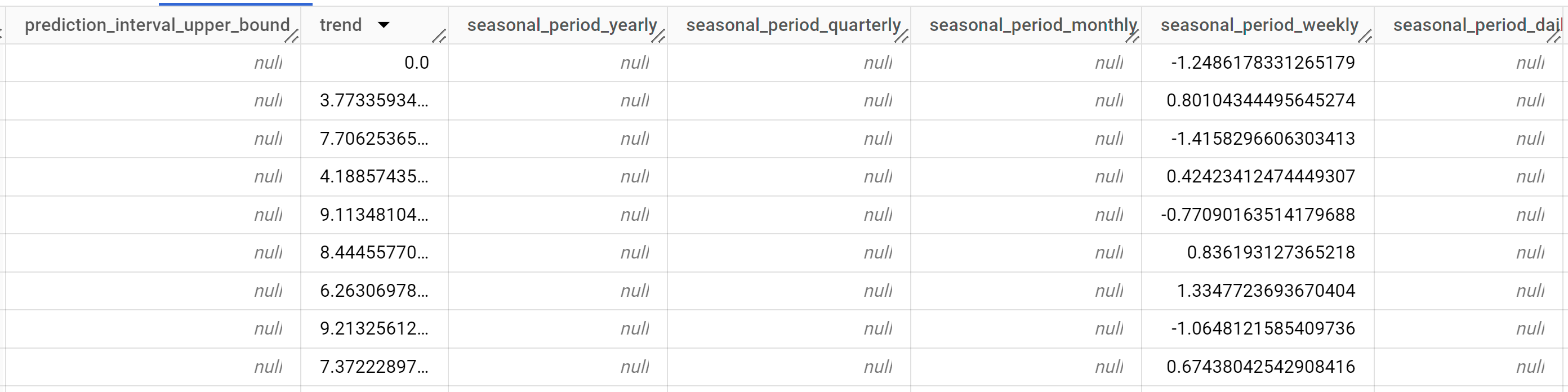
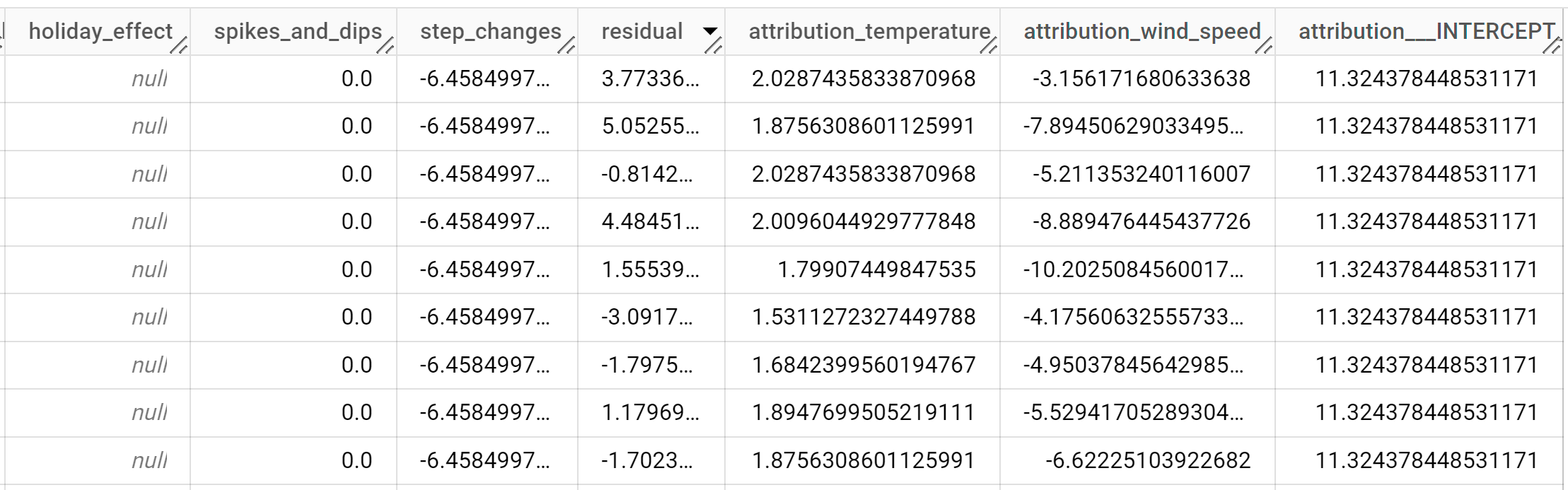
Le righe di output sono ordinate cronologicamente in base al valore della colonna
time_series_timestamp.Per ulteriori informazioni sulle colonne di output, consulta la funzione
ML.EXPLAIN_FORECAST.