Neste tutorial, você vai aprender a usar um modelo k-means no BigQuery ML para identificar clusters em um conjunto de dados.
O algoritmo k-means, que agrupa seus dados em clusters, é uma forma de machine learning não supervisionado. Ao contrário do machine learning supervisionado, que tem a ver com análise preditiva, o machine learning não supervisionado tem a ver com análise descritiva. O aprendizado de máquina não supervisionado pode ajudar você a entender seus dados para tomar decisões com base neles.
As consultas neste tutorial usam funções geográficas disponíveis na análise geoespacial. Para mais informações, consulte Introdução à análise geoespacial.
Este tutorial usa o conjunto de dados público London Bicycle Hires. Os dados incluem carimbos de data/hora iniciais e finais, nomes das estações e duração dos passeios.
Objetivos
Este tutorial vai orientar você nas tarefas a seguir:- Examine os dados usados para treinar o modelo.
- Criar um modelo de agrupamento k-means.
- Interprete os clusters de dados produzidos usando a visualização deles do BigQuery ML.
- Execute a função
ML.PREDICTno modelo k-means para prever o cluster provável de um conjunto de estações de aluguel de bicicletas.
Custos
Neste tutorial, usamos componentes faturáveis do Google Cloud, incluindo:
- BigQuery
- BigQuery ML
Para mais informações sobre os custos do BigQuery, consulte a página de preços do BigQuery.
Para mais sobre os custos do BigQuery ML, consulte Preços do BigQuery ML.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- O BigQuery é ativado automaticamente em novos projetos.
Para ativar o BigQuery em um projeto preexistente, acesse
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Para criar o conjunto de dados, é preciso ter a permissão de IAM
bigquery.datasets.create.Para criar o modelo, você precisa das seguintes permissões:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Para executar a inferência, você precisa das seguintes permissões:
bigquery.models.getDatabigquery.jobs.create
Permissões exigidas
Para mais informações sobre os papéis e as permissões do IAM no BigQuery, consulte Introdução ao IAM.
crie um conjunto de dados
Crie um conjunto de dados do BigQuery para armazenar o modelo de k-means:
No Google Cloud console, acesse a página BigQuery.
No painel Explorer, clique no nome do seu projeto.
Clique em Conferir ações > Criar conjunto de dados.
Na página Criar conjunto de dados, faça o seguinte:
Para o código do conjunto de dados, insira
bqml_tutorial.Em Tipo de local, selecione Multirregional e selecione UE (várias regiões na União Europeia).
O conjunto de dados público de Locações de Bicicletas de Londres é armazenado na multirregião
EU. O conjunto de dados precisa estar no mesmo local.Mantenha as configurações padrão restantes e clique em Criar conjunto de dados.

Analisar os dados de treinamento
Examine os dados que você vai usar para treinar o modelo k-means. Neste tutorial, as estações de bicicletas são agrupadas com base nos seguintes atributos:
- Duração das locações
- Número de viagens por dia
- Distância do centro da cidade
SQL
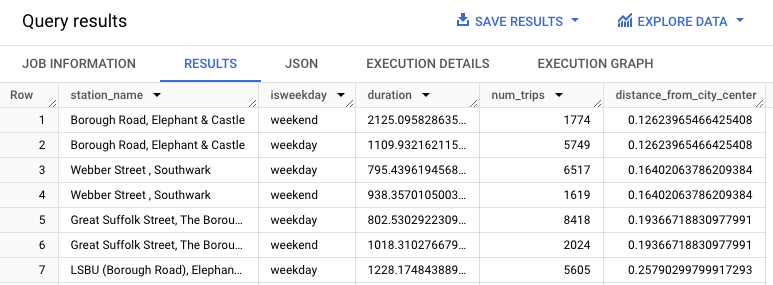
Essa consulta extrai dados sobre locações de bicicletas, incluindo as colunas start_station_name e duration, e associa esses dados às informações da estação. Isso inclui a criação de uma coluna calculada que contém a distância da estação do centro da cidade. Em seguida, ela calcula os atributos da estação em uma coluna stationstats, incluindo a duração média dos passeios e o número de viagens, e a coluna distance_from_city_center calculada.
Siga estas etapas para examinar os dados de treinamento:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, cole a consulta a seguir e clique em Executar:
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASC;
A resposta deve ficar assim:
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Criar um modelo k-means
Crie um modelo k-means usando os dados de treinamento de locações de bicicletas de Londres.
SQL
Na consulta a seguir, a instrução CREATE MODEL especifica o número de clusters a serem usados: quatro. Na instrução SELECT, a cláusula EXCEPT exclui a coluna station_name porque ela não contém um recurso. A consulta cria uma linha única por station_name, e somente os recursos são mencionados na instrução SELECT.
Siga estas etapas para criar um modelo k-means:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, cole a consulta a seguir e clique em Executar:
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS ( model_type = 'kmeans', num_clusters = 4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (station_name, isweekday) FROM stationstats;
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Interpretar os clusters de dados
As informações na guia Avaliação dos modelos podem ajudar você a interpretar os clusters produzidos pelo modelo.
Siga estas etapas para conferir as informações de avaliação do modelo:
No console do Google Cloud , acesse a página BigQuery.
No painel Explorer, expanda o projeto, o conjunto de dados
bqml_tutoriale a pasta Modelos.Selecione o modelo
london_station_clusters.Selecione a guia Avaliação. Essa guia mostra visualizações dos clusters identificados pelo modelo k-means. Na seção Recursos numéricos, os gráficos de barras mostram os valores de atributos numéricos mais importantes para cada centroide. Cada centroide representa um determinado cluster de dados. É possível selecionar quais recursos visualizar no menu suspenso.
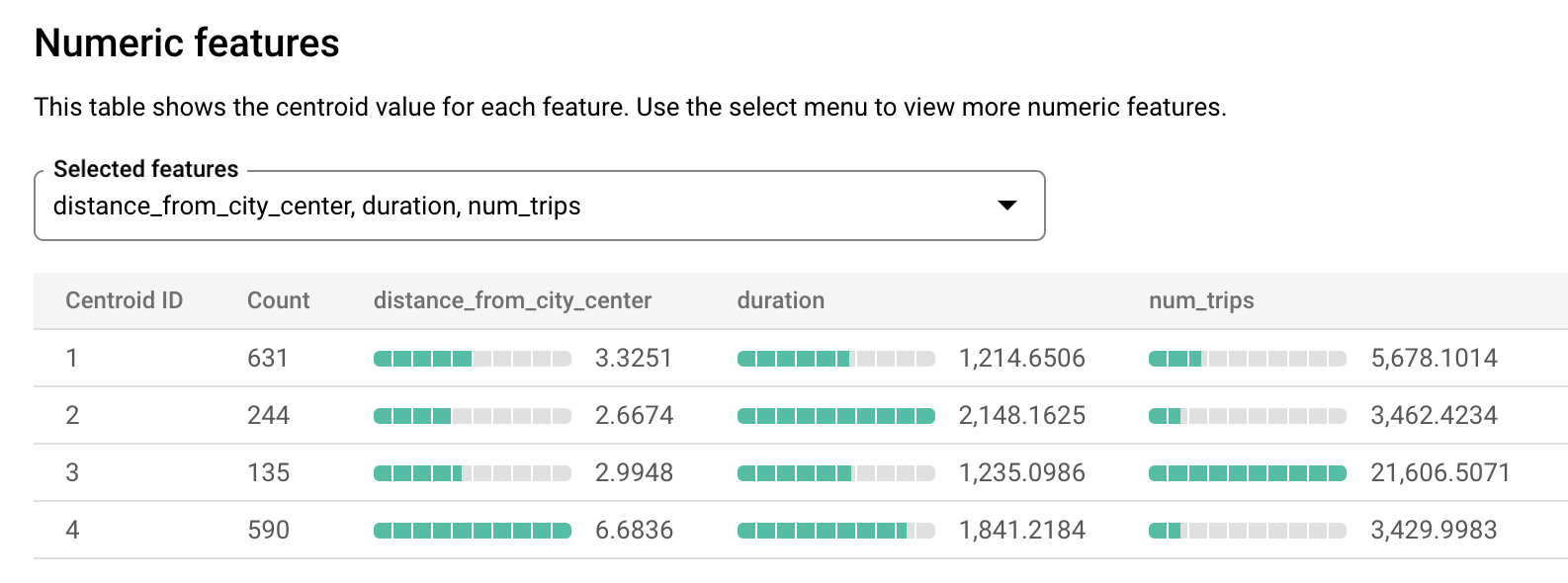
Esse modelo cria os seguintes centroides:
- O Centroide 1 mostra uma estação menos movimentada, com aluguéis de menor duração.
- O Centroide 2 mostra a segunda estação da cidade, que é menos movimentada e usada para aluguéis por mais tempo.
- O centroide 3 mostra uma estação de cidade movimentada perto do centro da cidade.
- O Centroide 4 mostra uma estação suburbana com viagens mais longas.
Se você tivesse uma empresa de aluguel de bicicletas, poderia usar essas informações para tomar decisões de negócios. Exemplo:
Vamos supor que você precise experimentar um novo tipo de trava. Qual cluster de estações precisa ser escolhido como tema desse experimento? As estações no centroide 1, no centroide 2 ou no centroide 4 parecem ser escolhas lógicas, porque não são as estações mais movimentadas.
Vamos supor que você queira abastecer algumas estações com bicicletas de corrida. Quais estações deve escolher? Centroide 4 é o grupo de estações que estão longe do centro da cidade, cujas viagens são as mais longas. Elas são as candidatas mais prováveis a bicicletas de corrida.
Usar a função ML.PREDICT para prever o cluster de uma estação
Identifique o cluster a que uma estação específica pertence usando a função SQL ML.PREDICT ou a função predict do BigQuery DataFrames.
SQL
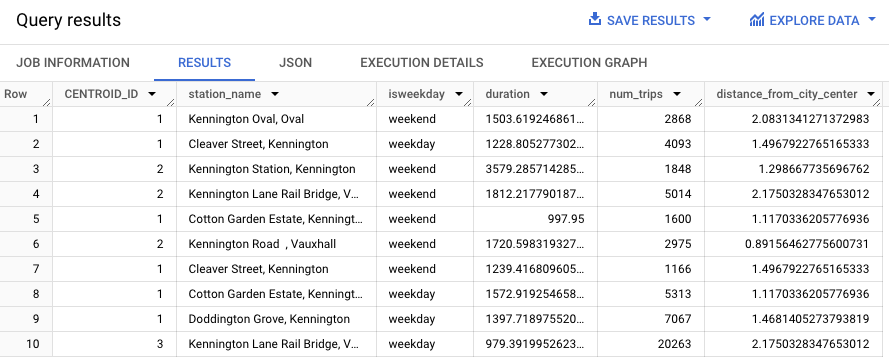
A consulta a seguir usa a função REGEXP_CONTAINS para encontrar todas as entradas na coluna station_name que contêm a string Kennington. A função ML.PREDICT usa esses valores para prever quais clusters podem conter essas estações.
Siga estas etapas para prever o cluster de todas as estações que têm a string Kennington no nome:
No console do Google Cloud , acesse a página BigQuery.
No Editor de consultas, cole a consulta a seguir e clique em Executar:
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington') ));
Os resultados serão semelhantes a este:
BigQuery DataFrames
Antes de testar esta amostra, siga as instruções de configuração dos BigQuery DataFrames no Guia de início rápido do BigQuery: como usar os BigQuery DataFrames. Para mais informações, consulte a documentação de referência do BigQuery DataFrames.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, consulte Configurar o ADC para um ambiente de desenvolvimento local.
Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
- exclua o projeto que você criou; ou
- Mantenha o projeto e exclua o conjunto de dados.
Excluir o conjunto de dados
A exclusão do seu projeto removerá todos os conjuntos de dados e tabelas no projeto. Caso prefira reutilizá-lo, exclua o conjunto de dados criado neste tutorial:
Se necessário, abra a página do BigQuery no console doGoogle Cloud .
Na navegação, clique no conjunto de dados bqml_tutorial criado.
Clique em Excluir conjunto de dados no lado direito da janela. Essa ação exclui o conjunto de dados e o modelo.
Na caixa de diálogo Excluir conjunto de dados, confirme o comando de exclusão digitando o nome do seu conjunto de dados (
bqml_tutorial). Em seguida, clique em Excluir.
Excluir o projeto
Para excluir o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
A seguir
- Para uma visão geral sobre ML do BigQuery, consulte Introdução ao ML do BigQuery.
- Para mais informações sobre como criar modelos, consulte a página de sintaxe
CREATE MODEL.