Snowflake から BigQuery への移行: 概要
このドキュメントでは、Snowflake から BigQuery にデータを移行する方法について説明します。
他のデータ ウェアハウスから BigQuery への移行の一般的なフレームワークについては、概要: データ ウェアハウスを BigQuery に移行するをご覧ください。
Snowflake から BigQuery への移行の概要
Snowflake の移行では、既存のオペレーションへの影響が最小限になる移行アーキテクチャを設定することをおすすめします。次の例は、既存のツールとプロセスを再利用しながら、他のワークロードを BigQuery にオフロードできるアーキテクチャを示しています。
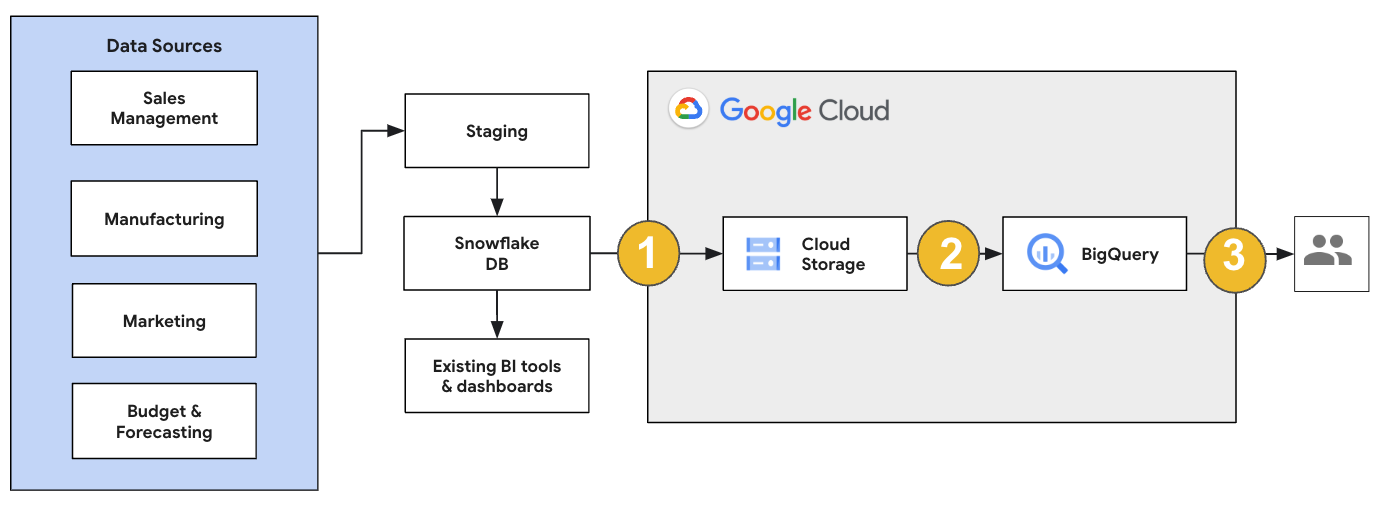
以前のバージョンに対してレポートとダッシュボードを検証することもできます。詳細については、データ ウェアハウスの BigQuery への移行: 確認と検証をご覧ください。
個々のワークロードを移行する
Snowflake の移行を計画する際は、次のワークロードを次の順序で個別に移行することをおすすめします。
スキーマを移行する
まず、必要なスキーマを Snowflake 環境から BigQuery に複製します。スキーマを移行するには、BigQuery Migration Service を使用することをおすすめします。BigQuery Migration Service は、スタースキーマやスノーフレーク スキーマなど、幅広いデータモデル デザイン パターンをサポートしているため、新しいスキーマに合わせてアップストリーム データ パイプラインを更新する必要がありません。BigQuery Migration Service には、スキーマの抽出と変換機能など、スキーマの自動移行機能も用意されており、移行プロセスを効率化できます。
SQL クエリを移行する
SQL クエリを移行するために、BigQuery Migration Service には、Snowflake SQL クエリを GoogleSQL SQL に自動的に変換するさまざまな SQL 変換機能が用意されています。たとえば、クエリを一括で変換するバッチ SQL トランスレータ、個々のクエリを変換するインタラクティブ SQL トランスレータ、SQL 変換 API などがあります。これらの変換サービスには、SQL クエリの移行プロセスをさらに簡素化する Gemini 拡張機能も含まれています。
SQL クエリを変換する際は、変換後のクエリを慎重に確認して、データ型とテーブル構造が正しく処理されていることを確認してください。そのため、さまざまなシナリオとデータを含む幅広いテストケースを作成することをおすすめします。次に、これらのテストケースを BigQuery で実行して、結果を元の Snowflake の結果と比較します。違いがある場合は、変換されたクエリを分析して修正します。
データを移行する
BigQuery にデータを転送するようにデータ移行パイプラインを設定する方法はいくつかあります。通常、これらのパイプラインは同じパターンに従います。
移行元からデータを抽出する: 移行元から抽出したファイルをオンプレミス環境のステージング ストレージにコピーします。詳細は、データ ウェアハウスの BigQuery への移行: ソースデータの抽出をご覧ください。
ステージング用の Cloud Storage バケットにデータを転送する: 送信元からデータの抽出が完了したら、Cloud Storage の一時バケットに転送します。転送するデータの量と利用可能なネットワーク帯域幅に応じて、いくつかの選択肢があります。
BigQuery データセットと外部データソースまたは Cloud Storage バケットの場所が同じリージョンであることを確認する必要があります。
Cloud Storage バケットから BigQuery へのデータの読み込み: データは Cloud Storage バケットに配置されます。BigQuery にデータをアップロードする方法はいくつかあります。これらのオプションは、データ変換が必要な量によって異なります。また、ELT の手法を使用して、BigQuery 内でデータを変換することもできます。
JSON ファイル、Avro ファイル、CSV ファイルからデータを一括でインポートすると、BigQuery がスキーマを自動的に検出するため、事前に定義する必要はありません。EDW ワークロードのスキーマ移行プロセスの詳細については、スキーマとデータの移行プロセスをご覧ください。
Snowflake のデータ移行をサポートするツールのリストについては、移行ツールをご覧ください。
Snowflake データ移行パイプラインの設定のエンドツーエンドの例については、Snowflake 移行パイプラインの例をご覧ください。
スキーマとクエリを最適化する
スキーマ移行後は、パフォーマンスをテストし、その結果に基づいて最適化を行うことができます。たとえば、パーティショニングを導入して、データの管理とクエリを効率的に行うことができます。テーブル パーティショニングでは、取り込み時間、タイムスタンプ、整数の範囲でパーティショニングすることで、クエリのパフォーマンスとコストを制御できます。詳細については、パーティション分割テーブルの概要をご覧ください。
クラスタ化テーブルは、別のスキーマ最適化です。テーブルをクラスタリングして、テーブルのスキーマの内容に基づいてテーブルデータを整理し、フィルタ句を使用するクエリやデータを集計するクエリのパフォーマンスを向上させることができます。詳細については、クラスタ化テーブルの概要をご覧ください。
サポートされるデータ型、プロパティ、ファイル形式
Snowflake と BigQuery ではほとんど同じデータ型をサポートしていますが、名前が異なる場合があります。Snowflake と BigQuery でサポートされているデータ型の一覧については、データ型をご覧ください。また、インタラクティブ SQL トランスレータ、SQL Translation API、バッチ SQL トランスレータなどの SQL 変換ツールを使用して、さまざまな SQL 言語を GoogleSQL に変換することもできます。
BigQuery でサポートされているデータ型の詳細については、GoogleSQL のデータ型をご覧ください。
Snowflake では次のファイル形式でデータをエクスポートできます。次の形式は BigQuery に直接読み込むことができます。
- Cloud Storage からの CSV データの読み込み
- Cloud Storage からの Parquet データの読み込み
- Cloud Storage からの JSON データの読み込み
- Apache Iceberg からデータをクエリする
移行ツール
次のリストは、Snowflake から BigQuery にデータを移行するために使用できるツールを示しています。これらのツールを Snowflake 移行パイプラインで一緒に使用する方法の例については、Snowflake 移行パイプラインの例をご覧ください。
COPY INTO <location>コマンド: Snowflake では、このコマンドを使用して、Snowflake テーブルから指定の Cloud Storage バケットに直接データを抽出します。エンドツーエンドの例については、GitHub の Snowflake から BigQuery(snowflake2bq)をご覧ください。- Apache Sqoop: Snowflake から HDFS または Cloud Storage にデータを抽出するには、Sqoop と Snowflake の JDBC ドライバを使用して Hadoop ジョブを送信します。Sqoop は Dataproc 環境で動作します。
- Snowflake JDBC: このドライバは、JDBC をサポートするほとんどのクライアント ツールやアプリケーションで使用されています。
Snowflake から BigQuery にデータを移行するには、次の汎用ツールを使用できます。
- BigQuery Data Transfer Service for Snowflake コネクタ プレビュー: Cloud Storage データの BigQuery への自動バッチ転送を実行します。
- Google Cloud CLI: このコマンドライン ツールを使用して、ダウンロードした Snowflake ファイルを Cloud Storage にコピーします。
- bq コマンドライン ツール: このコマンドライン ツールでは BigQuery を操作します。一般的なユースケースとしては、BigQuery テーブル スキーマの作成、Cloud Storage データのテーブルへの読み込み、クエリの実行などがあります。
- Cloud Storage クライアント ライブラリ: Cloud Storage クライアント ライブラリを使用するカスタムツールを使用して、ダウンロードした Snowflake ファイルを Cloud Storage にコピーします。
- BigQuery クライアント ライブラリ: BigQuery クライアント ライブラリの上に構築されたカスタムツールを使用して、BigQuery を操作します。
- BigQuery クエリ スケジューラ: この BigQuery の組み込み機能を使用して、SQL クエリのスケジュールを設定します。
- Cloud Composer: このフルマネージドの Apache Airflow 環境を使用して、BigQuery の読み込みジョブと変換をオーケストレートします。
BigQuery へのデータの読み込みの詳細については、BigQuery へのデータの読み込みをご覧ください。
Snowflake 移行パイプラインの例
以降のセクションでは、ELT、ETL、パートナー ツールという 3 つの異なるプロセスを使用して、Snowflake から BigQuery にデータを移行する例を示します。
抽出、読み込み、変換
抽出、読み込み、変換(ELT)プロセスは、次の 2 つの方法で設定できます。
- パイプラインを使用して Snowflake からデータを抽出し、BigQuery にデータを読み込む
- 他の Google Cloud プロダクトを使用して Snowflake からデータを抽出する
パイプラインを使用して Snowflake からデータを抽出する
Snowflake からデータを抽出し、Cloud Storage に直接読み込むには、snowflake2bq ツールを使用します。
その後、次のいずれかのツールを使用して、Cloud Storage から BigQuery にデータを読み込むことができます。
- BigQuery Data Transfer Service for Cloud Storage コネクタ
- bq コマンドライン ツールを使用する
LOADコマンド - BigQuery API クライアント ライブラリ
Snowflake からデータを抽出するその他のツール
次のツールを使用して、Snowflake からデータを抽出することもできます。
- Dataflow
- Cloud Data Fusion
- Dataproc
- Apache Spark BigQuery コネクタ
- Apache Spark 用の Snowflake コネクタ
- Hadoop BigQuery コネクタ
- Snowflake と Sqoop の JDBC ドライバ。Snowflake から Cloud Storage にデータを抽出します。
BigQuery にデータを読み込むその他のツール
次のツールを使用して、BigQuery にデータを読み込むこともできます。
- Dataflow
- Cloud Data Fusion
- Dataproc
- Dataprep by Trifacta
抽出、変換、読み込み
BigQuery にデータを読み込む前にデータを変換する場合は、次のツールを検討してください。
- Dataflow
- JDBC to BigQuery テンプレート コードのクローンを作成し、このテンプレートを変更して Apache Beam 変換を追加します。
- Cloud Data Fusion
- 再利用可能なパイプラインを作成し、CDAP プラグインを使用してデータを変換します。
- Dataproc
- サポートされている Spark 言語(Scala、Java、Python、R)のいずれかで Spark SQL またはカスタムコードを使用してデータを変換します。
移行用のパートナー ツール
EDW 移行空間を専門とする複数のベンダーがあります。主要なパートナーと、パートナーが提供するソリューションの一覧については、BigQuery パートナーをご覧ください。
Snowflake エクスポートのチュートリアル
以下のチュートリアルでは、Snowflake の COPY INTO <location> コマンドを使用して Snowflake から BigQuery へサンプルデータをエクスポートする方法について説明します。コードサンプルを含む詳細な手順については、Google Cloud プロフェッショナル サービスの Snowflake から BigQuery への移行ツールをご覧ください。
エクスポートの準備を行う
次の手順で、Snowflake データを Cloud Storage または Amazon Simple Storage Service(Amazon S3)バケットに抽出して、エクスポートの準備をすることができます。
Cloud Storage
このチュートリアルでは、PARQUET 形式でファイルを準備します。
Snowflake SQL ステートメントを使用して、名前付きファイル形式の仕様を作成します。
create or replace file format NAMED_FILE_FORMAT type = 'PARQUET'
NAMED_FILE_FORMATは、ファイル形式の名前に置き換えます。例:my_parquet_unload_formatCREATE STORAGE INTEGRATIONコマンドで統合を作成します。create storage integration INTEGRATION_NAME type = external_stage storage_provider = gcs enabled = true storage_allowed_locations = ('BUCKET_NAME')
次のように置き換えます。
INTEGRATION_NAME: ストレージ統合の名前。例:gcs_intBUCKET_NAME: Cloud Storage バケットのパス。例:gcs://mybucket/extract/
DESCRIBE INTEGRATIONコマンドを使用して、Snowflake の Cloud Storage サービス アカウントを取得します。desc storage integration INTEGRATION_NAME;
出力は次のようになります。
+-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+ | property | property_type | property_value | property_default | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | gcs://mybucket1/path1/,gcs://mybucket2/path2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | gcs://mybucket1/path1/sensitivedata/,gcs://mybucket2/path2/sensitivedata/ | [] | | STORAGE_GCP_SERVICE_ACCOUNT | String | service-account-id@iam.gserviceaccount.com | | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+
STORAGE_GCP_SERVICE_ACCOUNTとしてリストされているサービス アカウントに、ストレージ統合コマンドで指定されたバケットに対する読み取り / 書き込みアクセス権を付与します。この例では、service-account-id@サービス アカウントに<var>UNLOAD_BUCKET</var>バケットに対する読み取り / 書き込みアクセス権を付与します。以前に作成した統合を参照する外部 Cloud Storage ステージを作成します。
create or replace stage STAGE_NAME url='UNLOAD_BUCKET' storage_integration = INTEGRATION_NAME file_format = NAMED_FILE_FORMAT;
次のように置き換えます。
STAGE_NAME: Cloud Storage ステージ オブジェクトの名前。例:my_ext_unload_stage
Amazon S3
次の例は、Snowflake テーブルから Amazon S3 バケットにデータを移行する方法を示しています。
Snowflake で、ストレージ統合オブジェクトを構成して、外部の Cloud Storage ステージで参照される Amazon S3 バケットに Snowflake が書き込めるようにします。
この手順には、Amazon S3 バケットへのアクセス権限の構成、アマゾン ウェブ サービス(AWS)IAM ロールの作成、
CREATE STORAGE INTEGRATIONコマンドによる Snowflake でのストレージ統合の作成が含まれます。create storage integration INTEGRATION_NAME type = external_stage storage_provider = s3 enabled = true storage_aws_role_arn = 'arn:aws:iam::001234567890:role/myrole' storage_allowed_locations = ('BUCKET_NAME')
次のように置き換えます。
INTEGRATION_NAME: ストレージ統合の名前。例:s3_intBUCKET_NAME: ファイルを読み込む Amazon S3 バケットのパス。例:s3://unload/files/
DESCRIBE INTEGRATIONコマンドを使用して、AWS IAM ユーザーを取得します。desc integration INTEGRATION_NAME;
出力は次のようになります。
+---------------------------+---------------+================================================================================+------------------+ | property | property_type | property_value | property_default | +---------------------------+---------------+================================================================================+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | s3://mybucket1/mypath1/,s3://mybucket2/mypath2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | s3://mybucket1/mypath1/sensitivedata/,s3://mybucket2/mypath2/sensitivedata/ | [] | | STORAGE_AWS_IAM_USER_ARN | String | arn:aws:iam::123456789001:user/abc1-b-self1234 | | | STORAGE_AWS_ROLE_ARN | String | arn:aws:iam::001234567890:role/myrole | | | STORAGE_AWS_EXTERNAL_ID | String | MYACCOUNT_SFCRole=
| | +---------------------------+---------------+================================================================================+------------------+ スキーマに対する
CREATE STAGE権限と、ストレージ統合に対するUSAGE権限を含むロールを作成します。CREATE role ROLE_NAME; GRANT CREATE STAGE ON SCHEMA public TO ROLE ROLE_NAME; GRANT USAGE ON INTEGRATION s3_int TO ROLE ROLE_NAME;
ROLE_NAMEは、ロールの名前に置き換えます。例:myroleAWS IAM ユーザーに Amazon S3 バケットにアクセスするための権限を付与し、
CREATE STAGEコマンドを使用して外部ステージを作成します。USE SCHEMA mydb.public; create or replace stage STAGE_NAME url='BUCKET_NAME' storage_integration = INTEGRATION_NAMEt file_format = NAMED_FILE_FORMAT;
次のように置き換えます。
STAGE_NAME: Cloud Storage ステージ オブジェクトの名前。例:my_ext_unload_stage
Snowflake データをエクスポートする
データを準備したら、 Google Cloudにデータを移動できます。COPY INTO コマンドを使用して、外部ステージ オブジェクト STAGE_NAME を指定し、Snowflake データベース テーブルから Cloud Storage または Amazon S3 バケットにデータをコピーします。
copy into @STAGE_NAME/d1 from TABLE_NAME;
TABLE_NAME は、Snowflake データベース テーブルの名前に置き換えます。
このコマンドの結果、テーブルデータは Cloud Storage または Amazon S3 バケットにリンクされているステージ オブジェクトにコピーされます。ファイルには d1 という接頭辞が付きます。
その他のエクスポート方法
データのエクスポートに Azure Blob Storage を使用するには、Microsoft Azure へのアンロードの説明に従います。次に、Storage Transfer Service を使用して、エクスポートされたファイルを Cloud Storage に転送します。
料金
Snowflake の移行を計画する際は、BigQuery でのデータの転送、データの保存、サービスの利用にかかる費用を考慮してください。詳細については、料金をご覧ください。
Snowflake または AWS からデータを移動すると、下り(外向き)費用が発生する可能性があります。リージョン間でデータを転送する場合や、異なるクラウド プロバイダ間でデータを転送する場合にも、追加費用が発生する可能性があります。
次のステップ
- 移行後のパフォーマンスと最適化。