本指南依循 Terraform:SAP HANA 擴大部署指南,說明如何操作部署在 Google Cloud 上的 SAP HANA 系統。請注意,本指南的目的並非取代任何標準 SAP 說明文件。
在 Google Cloud上管理 SAP HANA 系統
本節說明如何執行運作 SAP HANA 系統時通常需要的管理工作,包括啟動、停止和複製系統的相關資訊。
啟動及停止執行個體
您可以隨時停用一或多個 SAP HANA 主機,阻止執行個體關閉該執行個體。如果關閉程序未在關閉期間內完成,系統將強制停止執行個體,為避免資料遺失或檔案系統損毀,建議您採取下列一項或多項做法:
請先停止在執行個體上執行的 SAP HANA,再停止執行個體。
如要延長執行個體的關機時間,請在執行個體中啟用正常關機功能。
如要瞭解如何停止或重新啟動執行個體,請參閱「停止或重新啟動 Compute Engine 執行個體」。
修改 VM
在 VM 部署完成後,您可以變更 VM 的各種屬性,包括 VM 類型。某些變更可能需要您從備份還原 SAP 系統,而其他變更則只需要重新啟動 VM。
詳情請參閱「修改 SAP 系統的 VM 設定」。
建立 SAP HANA 快照
如要產生永久磁碟的時間點備份,您可以建立快照。Compute Engine 會將每個快照的多個副本備份儲存在不同位置,同時也會自動使用檢查碼機制確保資料完整性。
如要建立快照,請按照 Compute Engine 建立快照一節中的說明操作。在建立一致的快照前,請特別留意相關的準備步驟,例如清除磁碟緩衝區,以確保快照一致。
快照功能在下列用途中相當實用:
| 用途 | 詳細資料 |
|---|---|
| 提供簡易、軟體獨立且具成本效益的資料備份解決方案。 | 使用快照備份資料、記錄、備份和共用磁碟。請安排每天備份這些磁碟,以便針對整個資料集進行時間點備份。擷取第一個快照後,後續的快照只會儲存累進式區塊變更。這有助於節省成本。 |
| 遷移至其他儲存類型。 | Compute Engine 提供不同類型的永久磁碟,包括以標準 (磁性) 儲存空間備份的類型,以及以固態硬碟儲存空間 (以 SSD 為基礎的永久磁碟) 備份的類型。每個類型都有不同的成本和效能特性。舉例來說,請為備份磁碟區使用標準類型,並為 /hana/log 和 /hana/data 磁碟區使用 SSD 類型,因為這兩者需要更高的效能。如要遷移儲存空間類型,請使用磁碟區快照,然後使用快照建立新的磁碟區,並選取不同的儲存空間類型。 |
| 將 SAP HANA 遷移至其他區域或區域。 | 您可以使用快照,將 SAP HANA 系統從同一個區域的一個區域移動到另一個區域,甚至是其他區域。快照可在Google Cloud 中全域使用,用於在其他區域或區塊建立磁碟。如要遷移至其他區域或區域,請建立磁碟 (包括根磁碟) 的快照,然後在所需區域或區域中建立虛擬機器,並使用這些快照建立的磁碟。 |
變更磁碟設定
您可以每 4 小時變更一次已配置的 IOPS 或處理量,或增加 Hyperdisk 磁碟區的大小。如果您在 4 小時過期前再次嘗試修改磁碟,系統會傳送 Cannot update provisioned throughput due to being rate limited 等速率限制錯誤訊息。如要解決這些錯誤,請在上次修改後等待 4 小時,再嘗試再次修改磁碟。
只有在緊急情況下,無法等待 4 小時調整 Hyperdisk 磁碟區的磁碟大小、已配置的 IOPS 或總處理量時,才使用這項程序。
如要變更磁碟設定,請執行下列步驟:
執行下列任一指令即可停止 SAP HANA 執行個體:
HDB stopsapcontrol -nr INSTANCE_NUMBER -function StopSystem HDB
將
INSTANCE_NUMBER替換為 SAP HANA 系統的執行個體編號。詳情請參閱「啟動及停止 SAP HANA 系統」。
建立現有磁碟的快照或映像檔:
以快照為基礎的備份
gcloud compute snapshots create SNAPSHOT_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATION更改下列內容:
SNAPSHOT_NAME:要建立的快照名稱。PROJECT_NAME: Google Cloud 專案名稱。SOURCE_DISK_NAME:用於建立快照的來源磁碟。ZONE:要操作的來源磁碟區。LOCATION:Cloud Storage 位置 (地區或多地區),用於儲存快照內容。詳情請參閱「建立及管理磁碟快照」。
以圖片為基礎的備份
gcloud compute images create IMAGE_NAME \ --project=PROJECT_NAME \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=ZONE \ --storage-location=LOCATION更改下列內容:
IMAGE_NAME:您要建立的磁碟映像檔名稱。PROJECT_NAME: Google Cloud 專案名稱。SOURCE_DISK_NAME:用來建立映像檔的來源磁碟。ZONE:要操作的來源磁碟區。LOCATION:Cloud Storage 位置 (地區或多地區),用於儲存圖片內容。詳情請參閱「建立自訂圖片」。
使用快照或映像檔建立新磁碟。
針對 Hyperdisk 磁碟區,請務必指定磁碟大小、IOPS 和總處理量,以符合工作負載需求。如要進一步瞭解如何為 Hyperdisk 佈建 IOPS 和處理量,請參閱「關於 Hyperdisk 的佈建效能」。
從快照
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --source-snapshot=SOURCE_SNAPSHOT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUT更改下列內容:
NEW_DISK_NAME:要建立的磁碟名稱。PROJECT_NAME: Google Cloud 專案名稱。DISK_TYPE:要建立的磁碟類型。DISK_SIZE:磁碟大小。ZONE:要建立的磁碟可用區。SOURCE_SNAPSHOT:用於建立磁碟的來源快照。IOPS:要建立的磁碟已佈建的 IOPS。THROUGHPUT:要建立的磁碟所提供的吞吐量。
從圖片
gcloud compute disks create NEW_DISK_NAME \ --project=PROJECT_NAME \ --type=DISK_TYPE \ --size=DISK_SIZE \ --zone=ZONE \ --image=SOURCE_IMAGE_NAME \ --image-project=IMAGE_PROJECT_NAME \ --provisioned-iops=IOPS \ --provisioned-throughput=THROUGHPUT更改下列內容:
NEW_DISK_NAME:要建立的磁碟名稱。PROJECT_NAME: Google Cloud 專案名稱。DISK_TYPE:要建立的磁碟類型。DISK_SIZE:磁碟大小。ZONE:要建立的磁碟可用區。SOURE_IMAGE_NAME:要套用至建立中的磁碟的來源映像檔。IMAGE_PROJECT_NAME:會對所有圖片和圖片系列參照進行解析的 Google Cloud 專案。IOPS:要建立的磁碟已佈建的 IOPS。THROUGHPUT:要建立的磁碟已配置的吞吐量。
詳情請參閱
gcloud compute disks create。從 SAP HANA 系統中卸除現有磁碟:
gcloud compute instances detach-disk INSTANCE_NAME \ --disk OLD_DISK_NAME \ --zone ZONE \ --project PROJECT_NAME更改下列內容:
INSTANCE_NAME:要運作的執行個體名稱。OLD_DISK_NAME:要以資源名稱卸離的磁碟。ZONE:要運作的執行個體區域。PROJECT_NAME: Google Cloud 專案名稱。
將新磁碟連結至 SAP HANA 系統:
gcloud compute instances attach-disk INSTANCE_NAME \ --disk NEW_DISK_NAME \ --zone ZONE \ --project PROJECT_NAME更改下列內容:
INSTANCE_NAME:要運作的執行個體名稱。NEW_DISK_NAME:要連結至執行個體的磁碟名稱。ZONE:要運作的執行個體區域。PROJECT_NAME: Google Cloud 專案名稱。
驗證掛接點是否正確連結:
lsblk畫面會顯示類似以下的輸出:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT ... sdd 8:48 0 1T 0 disk └─vg_hana_shared-shared 254:0 0 1024G 0 lvm /hana/shared sde 8:64 0 32G 0 disk └─vg_hana_usrsap-usrsap 254:3 0 32G 0 lvm /usr/sap sdf 8:80 0 13.8T 0 disk └─vg_hana_data-data 254:1 0 13.8T 0 lvm /hana/data sdg 8:96 0 512G 0 disk └─vg_hana_log-log 254:2 0 512G 0 lvm /hana/log執行下列其中一項指令,即可啟動 SAP HANA 執行個體:
HDB startsapcontrol -nr INSTANCE_NUMBER -function StartSystem HDB
將
INSTANCE_NUMBER替換為 SAP HANA 系統的執行個體編號。詳情請參閱「啟動及停止 SAP HANA 系統」。
驗證新 Hyperdisk 磁碟區的磁碟大小、IOPS 和總處理量:
gcloud compute disks describe DISK_NAME \ --zone ZONE \ --project PROJECT_NAME更改下列內容:
DISK_NAME:要說明的磁碟名稱。ZONE:要說明的磁碟區域。PROJECT_NAME: Google Cloud 專案名稱。
複製 SAP HANA 系統
您可以為 Google Cloud 上現有的 SAP HANA 系統建立快照,以便建立系統的確切複本。
如要複製單一主機 SAP HANA 系統,請按照下列步驟操作:
建立資料和備份磁碟的快照。
使用快照建立新磁碟。
前往 Google Cloud 控制台的「VM Instances」(VM 執行個體) 頁面。
按一下要複製的執行個體,開啟執行個體詳細資料頁面,然後點選「複製」。
附加從快照建立的磁碟。
如要複製多主機 SAP HANA 系統,請按照下列步驟操作:
佈建新的 SAP HANA 系統,並採用與要複製的 SAP HANA 系統相同的設定。
備份原始系統的資料。
將原始系統的備份還原至新系統。
安裝及更新 gcloud CLI
為 SAP HANA 部署 VM 並安裝作業系統後,您需要使用最新版的 Google Cloud CLI 來執行各種作業,例如在 Cloud Storage 之間傳輸檔案、與網路服務互動等等。
如果您按照 SAP HANA 部署指南中的指示操作,系統會自動為您安裝 gcloud CLI。
不過,如果您將自有作業系統導入 Google Cloud 做為自訂映像檔,或是使用Google Cloud提供的舊版公開映像檔,可能就需要自行安裝或更新 gcloud CLI。
如要檢查是否已安裝 gcloud CLI,以及是否有可用的更新,請開啟終端機或命令提示,然後輸入:
gcloud version
如果系統無法辨識指令,表示您尚未安裝 gcloud CLI。
如要安裝 gcloud CLI,請按照「安裝 gcloud CLI」中的操作說明進行。
如要取代整合 SLES 的 gcloud CLI 140 以下版本,請按照下列步驟操作:
使用
ssh登入 VM。切換至超級使用者:
sudo su輸入下列指令:
bash <(curl -s https://dl.google.com/dl/cloudsdk/channels/rapid/install_google_cloud_sdk.bash) --disable-prompts --install-dir=/usr/local update-alternatives --install /usr/bin/gsutil gsutil /usr/local/google-cloud-sdk/bin/gsutil 1 --force update-alternatives --install /usr/bin/gcloud gcloud /usr/local/google-cloud-sdk/bin/gcloud 1 --force gcloud --quiet compute instances list
啟用 SAP HANA 快速重新啟動功能
Google Cloud 強烈建議您為每個 SAP HANA 執行個體啟用 SAP HANA 快速重新啟動功能,尤其是較大的執行個體。如果 SAP HANA 終止,但作業系統仍在執行,SAP HANA 快速重新啟動功能可縮短重新啟動時間。
根據 Google Cloud 提供的自動化指令碼設定,作業系統和核心設定已支援 SAP HANA 快速重新啟動。您需要定義 tmpfs 檔案系統,並設定 SAP HANA。
如要定義 tmpfs 檔案系統並設定 SAP HANA,您可以按照手動步驟操作,也可以使用Google Cloud 提供的自動化指令碼啟用 SAP HANA 快速重新啟動功能。詳情請參閱:
如需 SAP HANA 快速重新啟動功能的完整操作說明,請參閱 SAP HANA 快速重新啟動選項說明文件。
手動步驟
設定 tmpfs 檔案系統
主機 VM 和基礎 SAP HANA 系統成功部署後,您需要在 tmpfs 檔案系統中為 NUMA 節點建立及掛載目錄。
顯示 VM 的 NUMA 拓撲
您必須先瞭解 VM 有多少個 NUMA 節點,才能對應必要的 tmpfs 檔案系統。如要顯示 Compute Engine VM 上的可用 NUMA 節點,請輸入下列指令:
lscpu | grep NUMA
舉例來說,m2-ultramem-208 VM 類型有四個 NUMA 節點,編號為 0 到 3,如以下範例所示:
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
建立 NUMA 節點目錄
為 VM 中的每個 NUMA 節點建立目錄,並設定權限。
舉例來說,如果有四個 NUMA 節點,編號為 0 到 3:
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SID將 NUMA 節點目錄掛接至 tmpfs
掛接 tmpfs 檔案系統目錄,並使用 mpol=prefer 為每個目錄指定 NUMA 節點偏好設定:
SID 請使用大寫英文字母指定 SID。
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
更新「/etc/fstab」
為確保掛接點在作業系統重新啟動後可供使用,請在檔案系統表格 /etc/fstab 中新增項目:
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
選用:設定記憶體用量限制
tmpfs 檔案系統可動態擴充及縮減。
如要限制 tmpfs 檔案系統使用的記憶體,您可以使用 size 選項為 NUMA 節點磁碟機容納的大小設定限制。例如:
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
您也可以在 global.ini 檔案的 [memorymanager] 區段中設定 persistent_memory_global_allocation_limit 參數,為特定 SAP HANA 例項和特定伺服器節點的所有 NUMA 節點限制整體 tmpfs 記憶體用量。
快速重新啟動的 SAP HANA 設定
如要設定 SAP HANA 以便快速重新啟動,請更新 global.ini 檔案,並指定要儲存在永久性記憶體中的資料表。
更新 global.ini 檔案中的 [persistence] 區段
設定 SAP HANA global.ini 檔案中的 [persistence] 區段,以參照 tmpfs 位置。請使用半形分號分隔每個 tmpfs 位置:
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
上述範例為四個 NUMA 節點指定四個記憶體磁碟區,對應至 m2-ultramem-208。如果您在 m2-ultramem-416 上執行,則需要設定八個記憶體磁區 (0..7)。
修改 global.ini 檔案後,請重新啟動 SAP HANA。
SAP HANA 現在可以使用 tmpfs 位置做為永久記憶體空間。
指定要儲存在永久性記憶體中的資料表
指定要儲存在永久性記憶體中的特定資料欄資料表或分區。
舉例來說,如要為現有資料表開啟持久性記憶體,請執行 SQL 查詢:
ALTER TABLE exampletable persistent memory ON immediate CASCADE
如要變更新資料表的預設值,請在 indexserver.ini 檔案中新增 table_default 參數。例如:
[persistent_memory] table_default = ON
如要進一步瞭解如何控制資料欄、資料表,以及哪些監控檢視畫面可提供詳細資訊,請參閱「SAP HANA 永久記憶體」。
自動化步驟
Google Cloud 提供的自動化指令碼可啟用 SAP HANA 快速重新啟動功能,並修改目錄 /hana/tmpfs*、檔案 /etc/fstab 和 SAP HANA 設定。執行指令碼時,您可能需要執行額外步驟,具體取決於這是 SAP HANA 系統的初始部署作業,還是將機器大小調整為不同的 NUMA 大小。
如要初始部署 SAP HANA 系統,或調整機器大小以增加 NUMA 節點數量,請務必在執行 Google Cloud提供的自動化指令碼時,讓 SAP HANA 執行,以便啟用 SAP HANA 快速重新啟動功能。
當您調整機器大小以減少 NUMA 節點數時,請務必在執行 Google Cloud 提供的自動化指令碼時,停止 SAP HANA,以便啟用 SAP HANA 快速重新啟動功能。執行指令碼後,您必須手動更新 SAP HANA 設定,才能完成 SAP HANA 快速重新啟動設定。詳情請參閱「SAP HANA 快速重新啟動設定」。
如要啟用 SAP HANA 快速重新啟動功能,請按照下列步驟操作:
與主機 VM 建立 SSH 連線。
切換至根目錄:
sudo su -
下載
sap_lib_hdbfr.sh指令碼:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
將檔案設為可執行檔:
chmod +x sap_lib_hdbfr.sh
確認指令碼沒有錯誤:
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
如果指令傳回錯誤,請與 Cloud Customer Care 團隊聯絡。如要進一步瞭解如何與客戶服務團隊聯絡,請參閱「取得 SAP 支援 Google Cloud」一文。
請先為 SAP HANA 資料庫的系統使用者,替換 SAP HANA 系統 ID (SID) 和密碼,再執行指令碼。為確保密碼安全,建議您在 Secret Manager 中使用密鑰。
使用 Secret Manager 中的密鑰名稱執行指令碼。這個機密金鑰必須存在於包含主機 VM 執行個體的 Google Cloud 專案中。
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
更改下列內容:
SID:請使用大寫字母指定 SID。例如:AHA。SECRET_NAME:指定與 SAP HANA 資料庫系統使用者密碼相對應的機密金鑰名稱。這個祕密值必須存在於 Google Cloud 專案中,且該專案包含主機 VM 執行個體。
或者,您也可以使用純文字密碼執行指令碼。啟用 SAP HANA 快速重新啟動功能後,請務必變更密碼。我們不建議使用純文字密碼,因為密碼會記錄在 VM 的指令列記錄中。
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
更改下列內容:
SID:請使用大寫字母指定 SID。例如:AHA。PASSWORD:指定 SAP HANA 資料庫系統使用者的密碼。
如果初次執行成功,您應該會看到類似以下的輸出內容:
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
使用 SAProuter 設定 SAP 支援管道
如果您需要讓 SAP 支援工程師存取Google Cloud上的 SAP HANA 系統,可以使用 SAProuter 執行這項操作。步驟如下:
啟動要安裝 SAProuter 軟體的 Compute Engine VM 執行個體,並指派外部 IP 位址,讓執行個體能夠存取網際網路。
建立新的靜態外部 IP 位址,然後將這個 IP 位址指派給執行個體。
在網路中建立並設定特定 SAProuter 防火牆規則。在這個規則中,只允許 SAProuter 例項對 SAP 支援網路的必要傳入和傳出存取權。
將傳入和傳出存取權限制在 SAP 提供的特定 IP 位址,以及 TCP 通訊埠
3299。在防火牆規則中新增目標標記,然後輸入執行個體名稱。這可確保防火牆規則只套用至新執行個體。如要進一步瞭解如何建立及設定防火牆規則,請參閱防火牆規則說明文件。按照 SAP 注意事項 1628296安裝 SAProuter 軟體,並建立
saprouttab檔案,讓 SAP 可以存取 Google Cloud上的 SAP HANA 系統。設定與 SAP 的連線。如要使用網際網路連線,請使用安全網路通訊。詳情請參閱 SAP 遠端支援服務 – 說明。
設定網路
您會使用 VM 和Google Cloud 虛擬網路來佈建 SAP HANA 系統。 Google Cloud 採用最先進的軟體定義網路和分散式系統技術,託管您的服務並將這些服務傳送到世界各地。
針對 SAP HANA,請建立非預設子網路網路,並為網路中的每個子網路指派不重疊的 CIDR IP 位址範圍。請注意,每個子網路及其內部 IP 位址範圍都會對應至單一地區。
子網路會橫跨建立所在區域的所有可用區。不過,建立 VM 執行個體時,您必須為 VM 指定可用區和子網路。舉例來說,您可以根據需求,在 subnetwork1 和 region1 的 zone1 中建立一組例項,並在 subnetwork2 和 region1 的 zone2 中建立另一組例項。
新網路不具有防火牆規則,因此也沒有網路存取權。您應建立防火牆規則,根據最低權限模型開放 SAP HANA 執行個體的存取權。防火牆規則會套用至整個網路,也可以使用標記機制將其套用至特定目標執行個體。
路徑是與單一網路連結的全域資源,而非區域資源。使用者建立的路徑會套用到網路中的所有執行個體。這表示您可以新增路徑,在同一個網路中 (甚至跨越子網路) 將流量從一個執行個體轉送至另一個執行個體,而不需要外部 IP 位址。
針對 SAP HANA 執行個體,請啟動不具外部 IP 位址的執行個體,然後將另一個 VM 設為 NAT 閘道,以便外部存取。使用此設定方法時,您必須另外將 NAT 閘道新增為 SAP HANA 執行個體的路徑。部署指南會說明這項程序。
安全性
以下各節將討論安全性作業。
最低權限模式
您的第一道防線是使用防火牆限制誰能連至執行個體。建立防火牆規則後,即可將網路或特定通訊埠上目標機器的所有流量限制在特定來源 IP 位址。您應依照最低權限模式將存取權限制在需要存取的特定 IP 位址、通訊協議和通訊埠。例如,您應該設定防禦主機,並且只允許 SSH 經由該主機進入您的 SAP HANA 系統。
設定變更
您應使用建議的安全性設定,設定 SAP HANA 系統和作業系統。舉例來說,請確認只有相關網路連接埠列出,以便允許存取,並強化執行 SAP HANA 的作業系統等等。
請參閱下列 SAP 注意事項 (需使用 SAP 使用者帳戶):
停用不必要的 SAP HANA 服務
如果您不需要 SAP HANA 擴充應用程式服務 (SAP HANA XS),請停用該服務。請參閱 SAP 注意事項 1697613:從拓樸中移除 SAP HANA XS 傳統引擎服務。
服務停用後,請移除為服務開啟的所有 TCP 連接埠。在 Google Cloud中,這表示您需要編輯網路的防火牆規則,將這些通訊埠從存取清單中移除。
稽核記錄
Cloud 稽核記錄包含管理員活動和資料存取兩種記錄串流,兩者皆由 Google Cloud自動產生。這些資訊可協助您回答Google Cloud 專案中「從事活動的人員、內容、地點及時間為何?」的問題。
管理員活動記錄包含 API 呼叫或管理動作的記錄項目,而這些呼叫或動作會修改服務或專案的設定或中繼資料。這個記錄一律為啟用,且所有專案成員都可以看到該記錄。
資料存取記錄包含的 API 呼叫記錄項目可以建立、修改或讀取使用者提供的服務代管資料,例如儲存在資料庫服務中的資料。系統會在專案中預設啟用這類記錄,您可以透過 Cloud Logging 或活動動態消息存取這些記錄。
保護 Cloud Storage 值區安全
如要使用 Cloud Storage 來託管資料和記錄檔的備份,請務必在將資料從執行個體傳送到 Cloud Storage 時使用傳輸層安全標準 (TLS) (HTTPS),以保護傳輸資料的安全。Cloud Storage 會自動加密靜態資料。如果您有自己的金鑰管理系統,就可以自行指定加密金鑰。
相關安全文件
請參閱下列 Google Cloud上適用於 SAP HANA 環境的其他安全資源:
Google Cloud上 SAP HANA 的高可用性
Google Cloud 提供多種選項,確保 SAP HANA 系統的高可用性,包括 Compute Engine 即時遷移和自動重新啟動功能。這些功能加上 Compute Engine VM 的每月正常運作時間百分比高,可能就不需要支付費用及維護待命系統。
不過,如果需要,您可以部署多主機向外擴充系統,其中包含 SAP HANA 主機自動容錯移轉的待命主機,或者您也可以在高可用性 Linux 叢集中,部署具有待命 SAP HANA 例項的擴充系統。
如要進一步瞭解Google Cloud上的 SAP HANA 高可用性選項,請參閱 SAP HANA 高可用性規劃指南。
啟用 SAP HANA HA/DR 供應器掛鉤
災難復原
SAP HANA 系統提供多項高可用性功能,確保 SAP HANA 資料庫可承受軟體或基礎架構層級的故障。其中包括 SAP HANA 系統複製和 SAP HANA 備份, Google Cloud 兩者皆支援。
如要進一步瞭解 SAP HANA 備份,請參閱「備份與復原」。
如要進一步瞭解系統複製功能,請參閱 SAP HANA 災難復原規劃指南。
備份與還原
備份對於保護記錄系統 (資料庫) 至關重要。由於 SAP HANA 是記憶體內資料庫,因此定期建立備份並實施適當的備份策略,有助於在基礎架構發生非預期停機或故障,導致資料毀損或遺失時,復原 SAP HANA 資料庫。SAP HANA 系統提供內建備份和復原功能,可協助您完成這項工作。您可以使用 Google CloudCloud Storage 等服務,做為 SAP HANA 備份的備份目的地。
您也可以啟用 Google Cloud的 SAP 代理程式 Backint 功能,直接使用 Cloud Storage 進行備份和復原作業。
如要瞭解在 Compute Engine 裸機執行個體 (例如 X4) 上執行的 SAP HANA 系統的備份與復原建議,請參閱「在裸機執行個體上備份及復原 SAP HANA」。
本文件假設您熟悉 SAP HANA 備份和復原作業,以及下列 SAP 服務注意事項:
- 1642148:常見問題:SAP HANA 資料庫備份與復原
- 1821207:判斷必要的復原檔案
- 1869119:使用
hdbbackupcheck檢查備份 - 1873247:使用
hdbbackupdiag --check檢查可復原性 - 1651055:在 Linux 中排定 SAP HANA 資料庫備份作業
使用 Compute Engine 永久磁碟磁碟區和 Cloud Storage 進行備份
如果您按照 Google Cloud 提供的 Terraform 部署操作說明部署 SAP HANA 系統,則您會擁有 SAP HANA 安裝作業,其中 /hanabackup 目錄會代管在 Balanced 永久磁碟磁碟區中。
如要將線上資料庫備份建立到 /hanabackup 目錄,您可以使用標準 SAP 工具,例如 SAP HANA Studio、SAP HANA Cockpit、SAP ABAP 交易 DB13 或 SAP HANA SQL 陳述式。最後,您可以將完成的備份上傳至 Cloud Storage 值區,以便在需要復原 SAP HANA 系統時下載備份。
使用 Compute Engine 建立備份和磁碟快照
您可以使用 Compute Engine 備份 SAP HANA,也可以使用標準磁碟快照備份主機 SAP HANA 資料和記錄檔磁碟區的整個磁碟。
如果您按照部署指南中的指示操作,則 SAP HANA 安裝作業會建立 /hanabackup 目錄,用於線上資料庫備份。您可以使用相同的目錄儲存 /hanabackup 磁碟區的快照,並維護 SAP HANA 資料和記錄磁碟區的特定時間點備份。
標準磁碟快照的優點是採取增量快照,每個後續備份只會儲存累進式區塊變更,而不會建立全新的備份。Compute Engine 會將每個快照的多個副本備份到不同位置,同時也會自動使用檢查碼機制確保資料完整性。
以下是漸進式備份的插圖:

將 Cloud Storage 做為備份目的地
Cloud Storage 可提供高耐用性和資料可用性,是 SAP HANA 備份目的地的絕佳選擇。
Cloud Storage 是任何類型或格式的檔案的物件儲存空間。其儲存空間幾乎沒有限制,而且不必擔心是否需要佈建或新增更多容量。Cloud Storage 中的物件包含檔案資料及其相關中繼資料,且大小上限為 5 TB。Cloud Storage 值區可儲存任意數量的物件。
使用 Cloud Storage 時,資料會儲存在多個位置,因此可確保資料高度耐用且可用。當您上傳資料到 Cloud Storage 或複製資料到其中時,Cloud Storage 只會在達成物件備援功能時,才會將該動作回報為成功。
下表列出 Cloud Storage 提供的儲存空間選項:
| 資料讀取/寫入頻率 | 建議的 Cloud Storage 選項 |
|---|---|
| 頻繁讀取或寫入 | 請為正在使用的資料庫選擇標準儲存空間級別,因為這些資料庫可能會經常存取 Cloud Storage 來寫入及讀取備份檔案。 |
| 讀取或寫入次數不多 | 請為不常存取的資料選擇 Nearline 或 Coldline 儲存空間,例如需要依照貴機構的保留政策維護的已封存備份。如果您預計每月最多存取一次備份資料,Nearline 是理想的選擇;如果資料的存取機率非常低 (例如一年最多存取一次),則建議使用 Coldline。 |
| 封存資料 | 請為長期封存資料選擇封存儲存空間。如果您需要保留資料副本一段較長的時間,但一年內不會存取,Archive 就是不錯的選擇。舉例來說,如果您需要長期保留備份資料以符合法規要求,請使用封存儲存空間。建議您將磁帶備份解決方案換成 Archive。 |
規劃這些儲存選項的用途時,請從經常存取的層級開始,並將老舊備份資料放到不常存取的層級。備份檔案通常會隨著時間流逝而變得鮮少使用。需要 3 年前的備份的機率非常低,您可以將這個備份封存到 Archive 層級以節省成本。如要瞭解 Cloud Storage 費用,請參閱 Cloud Storage 定價。
Cloud Storage 與磁帶備份的比較
傳統的內部備份目的地是磁帶。Cloud Storage 比磁帶有許多優點,包括可自動將來源系統的備份儲存在「異地」位置,因為 Cloud Storage 中的資料會跨多個設施複製。這也表示儲存在 Cloud Storage 中的備份可用性極高。
另一個主要差異在於,當您需要使用備份資料時,還原備份資料的速度。如果您需要從備份建立新的 SAP HANA 系統,或從備份還原現有系統,Cloud Storage 可讓您更快存取資料,協助您更快建構系統。
Google Cloud的 Agent for SAP 的 Backint 功能
您可以使用 Google Cloud適用於 SAP 的代理程式,運用經 SAP 認證的 Backint 功能,直接使用 Cloud Storage 備份及復原內部部署和雲端安裝作業。
如要進一步瞭解這項功能,請參閱「以 Backint 為基礎的 SAP HANA 備份與復原」。
使用 Backint 備份及復原 SAP HANA
下列各節將說明如何使用 Google Cloud的 SAP 代理程式,透過 Backint 功能備份及復原 SAP HANA。
觸發資料和差異備份
如要使用 Google Cloud的 SAP 代理程式 Backint 功能,觸發 SAP HANA 資料磁碟區的備份作業,並將備份資料傳送至 Cloud Storage,您可以使用 SAP HANA Studio、SAP HANA Cockpit、SAP HANA SQL 或 DBA Cockpit。
以下是用於觸發資料備份的 SAP HANA SQL 陳述式:
如要為系統資料庫建立完整備份,請按照下列步驟操作:
BACKUP DATA USING BACKINT ('BACKUP_NAME');將
BACKUP_NAME替換為您要為備份設定的名稱。如要為租用戶資料庫建立完整備份,請按照下列步驟操作:
BACKUP DATA FOR TENANT_SID USING BACKINT ('BACKUP_NAME');將
TENANT_SID替換為租用戶資料庫的 SID。如要建立差異備份和增量備份,請按照下列步驟操作:
BACKUP DATA BACKUP_TYPE USING BACKINT ('BACKUP_NAME'); BACKUP DATA BACKUP_TYPE FOR TENANT_SID USING BACKINT ('BACKUP_NAME');視您要建立的備份類型而定,將
BACKUP_TYPE替換為DIFFERENTIAL或INCREMENTAL。
您可以使用多種方式觸發資料備份。如要瞭解這些選項,請參閱 SAP HANA SQL 參考指南的 BACKUP DATA 陳述式 (備份和復原)。
如要進一步瞭解資料和差異備份,請參閱 SAP 文件「資料備份」和「差異備份」。
觸發記錄檔備份
如要使用 Google Cloud的 SAP 代理程式 Backint 功能,觸發 SAP HANA 記錄檔磁碟區的備份作業,並將備份檔案傳送至 Cloud Storage,請完成下列步驟:
- 建立完整的資料庫備份。如需操作說明,請參閱 SAP HANA 版本的 SAP 說明文件。
- 在 SAP HANA
global.ini檔案中,將參數catalog_backup_using_backint設為yes。
請確認 SAP HANA 系統的記錄模式為 normal,這是預設值。如果記錄模式設為 overwrite,SAP HANA 資料庫就會停用記錄備份功能。
如要進一步瞭解記錄備份,請參閱 SAP 文件「記錄備份」。
查詢備份目錄
SAP HANA 備份目錄是備份與復原作業的重要環節。其中包含為 SAP HANA 資料庫建立的備份資訊。
如要查詢備份目錄,取得租用戶資料庫備份的相關資訊,請完成下列步驟:
- 將租用戶資料庫離線。
在系統資料庫中執行下列 SQL 陳述式:
BACKUP COMPLETE LIST DATA FOR TENANT_SID;
或者,如要查詢特定時間點,請執行下列 SQL 陳述式:
BACKUP LIST DATA FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD';
這項陳述式會在以下目錄中建立
strategyOutput.xml檔案:/usr/sap/SID/HDBINSTANCE_NUMBER/HOST_NAME/trace/DB_TENANT_SID。
如需 BACKUP LIST DATA 陳述式的相關資訊,請參閱 SAP HANA SQL 參考指南中的 BACKUP DATA 陳述式 (備份與復原)。如要瞭解備份目錄,請參閱 SAP 文件「備份目錄」。
復原資料庫
使用多串流資料備份執行復原作業時,SAP HANA 會使用與建立備份時相同的管道數量。詳情請參閱 SAP 文件「先決條件:使用多串流備份復原」。
如要還原使用 Google Cloud的 SAP 代理程式 Backint 功能建立的 SAP HANA 資料庫備份,SAP HANA 提供 RECOVER DATA 和 RECOVER DATABASE SQL 陳述式。
這兩個 SQL 陳述式會從您在 PARAMETERS.json 檔案中為 bucket 參數指定的 Cloud Storage 值區還原備份,除非您已為 recover_bucket 參數指定值區。
以下是使用Google Cloud適用於 SAP 的代理程式 Backint 功能建立的備份,來復原 SAP HANA 資料庫的 SQL 陳述式範例:
如要透過指定備份檔案名稱來復原租用戶資料庫,請按照下列步驟操作:
RECOVER DATA FOR TENANT_SID USING BACKINT('BACKUP_NAME') CLEAR LOG;如要透過指定備份 ID 還原租用戶資料庫,請按照下列步驟操作:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID CLEAR LOG;
將
BACKUP_ID替換為必要備份的 ID。如需使用儲存在 Cloud Storage 值區中的 SAP HANA 備份目錄備份,請在需要時指定備份 ID,藉此復原租用戶資料庫:
RECOVER DATA FOR TENANT_SID USING BACKUP_ID BACKUP_ID USING CATALOG BACKINT CLEAR LOG;
如要將租用戶資料庫復原至特定時間點或特定記錄位置:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CHECK ACCESS USING BACKINT;
如要使用外部資料庫的備份還原租用戶資料庫,請按照下列步驟操作:
RECOVER DATABASE FOR TENANT_SID UNTIL TIMESTAMP 'YYYY-MM-DD HH:MM:SS' CLEAR LOG USING SOURCE 'SOURCE_TENANT_SID@SOURCE_SID' USING CATALOG BACKINT CHECK ACCESS USING BACKINT
更改下列內容:
SOURCE_TENANT_SID:來源租用戶資料庫的 SIDSOURCE_SID:來源租用戶資料庫所在的 SAP 系統 SID
如果您需要在 Cloud Storage 值區儲存的備份中找不到 SAP HANA 備份目錄,而需要復原 SAP HANA 資料庫,請按照 SAP 附註 3227931 - Recover a HANA DB From Backint Without a HANA Backup Catalog 中的指示操作。
管理備份的身分和存取權
使用 Cloud Storage 或 Compute Engine 備份 SAP HANA 資料時,這些備份的存取權會由身分與存取權管理 (IAM) 控管。這項功能可讓管理員授權哪些使用者可以對特定資源執行操作。IAM 可提供集中控管和瀏覽權限,方便您管理所有Google Cloud 資源,包括備份。
IAM 也會自動向管理員顯示授予、撤銷及指派權限的完整稽核追蹤記錄。這可讓您設定政策,監控備份中資料的存取權,讓您能透過資料完成完整的存取權控管週期。IAM 可讓您統一查看整個機構的安全政策,並透過內建的稽核功能簡化法規遵循程序。
如要授予實體存取 Cloud Storage 中的備份,請按照下列步驟操作:
在 Google Cloud 控制台中,前往「IAM & Admin」頁面:
指定要授予存取權的使用者,然後指派「儲存空間」>「Storage 物件建立者」角色:

如何為 SAP HANA 建立以檔案系統為基礎的備份
使用部署指南在 Google Cloud 上部署的 SAP HANA 系統,會設定一組永久磁碟或 Hyperdisk 磁碟區,用於做為 NFS 掛載的備份目的地。SAP HANA 備份會先儲存在這些本機磁碟上,之後您需要將備份複製到 Cloud Storage 進行長期儲存。您可以手動將備份複製到 Cloud Storage,也可以在 crontab 中排定將備份複製到 Cloud Storage。
如果您使用 Google Cloud的 SAP 代理程式 Backint 功能,則可以直接備份至 Cloud Storage 值區並從中復原,因此不需要使用永久磁碟儲存備份內容。
如要啟動或排程 SAP HANA 資料備份,您可以使用 SAP HANA Studio、SQL 指令或 DBA Cockpit。除非停用,否則系統會自動寫入記錄備份。以下螢幕截圖為範例:
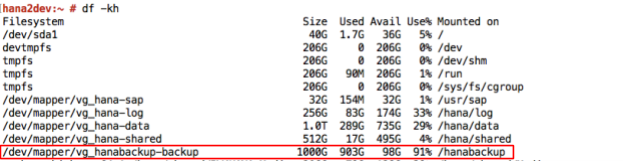
設定 SAP HANA global.ini
如果您按照部署指南的操作說明進行設定,SAP HANA global.ini 設定檔會自訂,資料庫備份會儲存在 /hanabackup/data/,自動記錄檔案則會儲存在 /hanabackup/log/。以下是 global.ini 的範例外觀:
[persistence]
basepath_datavolumes = /hana/data
basepath_logvolumes = /hana/log
basepath_databackup = /hanabackup/data
basepath_logbackup = /hanabackup/log
[system_information]
usage = production
如要為Google Cloud的 SAP 代理程式自訂 Backint 功能的 global.ini 設定檔,請參閱「為 Backint 功能設定 SAP HANA」。
向外擴充部署作業的注意事項
在橫向擴展導入作業中,採用即時遷移和自動重新啟動功能的高可用性解決方案的運作方式與單主機設定相同。主要差異在於 /hana/shared 磁碟區會透過 NFS 掛接至所有工作站主機,並在 HANA 主機中進行主控。在主要主機即時遷移或自動重新啟動時,NFS 磁碟區會有短暫的無法存取時間。重新啟動主要主機後,所有主機的 NFS 磁碟區會開始運作,並自動繼續進行一般作業。
在備份和復原作業期間,所有主機都必須提供 SAP HANA 備份磁碟區 /hanabackup。如果發生錯誤,您必須確認 /hanabackup 已掛載至所有主機,並重新掛載未掛載的所有主機。當您選擇將備份組複製到其他磁區或 Cloud Storage 時,請在主主機上執行複製作業,以便提升 I/O 效能並減少網路用量。為簡化備份和復原程序,您可以使用 Cloud Storage Fuse 在每個主機上掛接 Cloud Storage 值區。
資料分布越均勻,擴展效能就越好。資料分佈得越好,查詢效能就越高。這需要您充分瞭解資料、瞭解資料的使用方式,並據此設計表格分佈和分區。詳情請參閱 SAP 附註 2081591 - 常見問題:SAP HANA 資料表分發。
Gcloud Python
Gcloud Python 是慣用的 Python 用戶端,可用來存取Google Cloud 服務。本指南會使用 Gcloud Python 執行 SAP HANA 資料庫備份的 Cloud Storage 備份和還原作業。
如果您按照部署指南的說明操作,Compute Engine 執行個體中就會提供 Gcloud Python 程式庫。
這些程式庫是開放原始碼,可讓您操作 Cloud Storage 值區,以便儲存及擷取備份資料。
您可以執行下列指令,列出 Cloud Storage 值區中的物件。您可以使用這項指令列出可用的備份:
python 2>/dev/null - <<EOF
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("<bucket_name>")
blobs = bucket.list_blobs()
for fileblob in blobs:
print(fileblob.name)
EOF
如需 Gcloud Python 的完整詳細資料,請參閱 storage 用戶端程式庫參考說明文件。
備份與還原範例
以下各節將說明使用 SAP HANA Studio 執行一般備份和還原作業時,可能會遵循的程序。
建立備份範例
在 SAP HANA 備份編輯器中,選取「開啟備份精靈」。
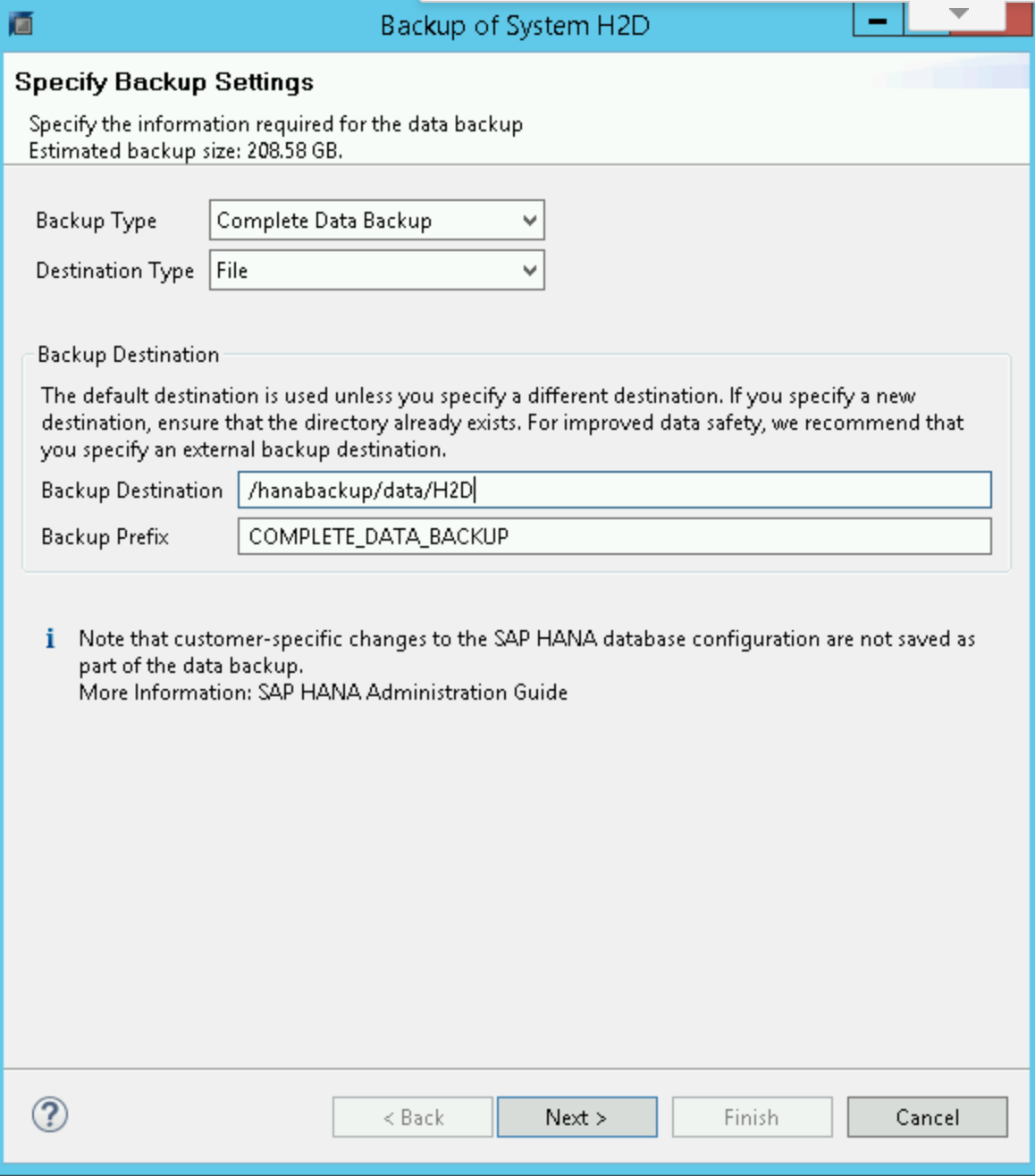
- 選取「檔案」做為目的地類型。這會將資料庫備份至指定檔案系統中的檔案。
- 指定備份目的地
/hanabackup/data/SID和備份前置字串。將SID替換為 SAP 系統的系統 ID。 - 點按「Next」。
在確認表單中按一下「完成」,即可開始備份。
備份開始時,狀態視窗會顯示備份進度。等待備份完成。
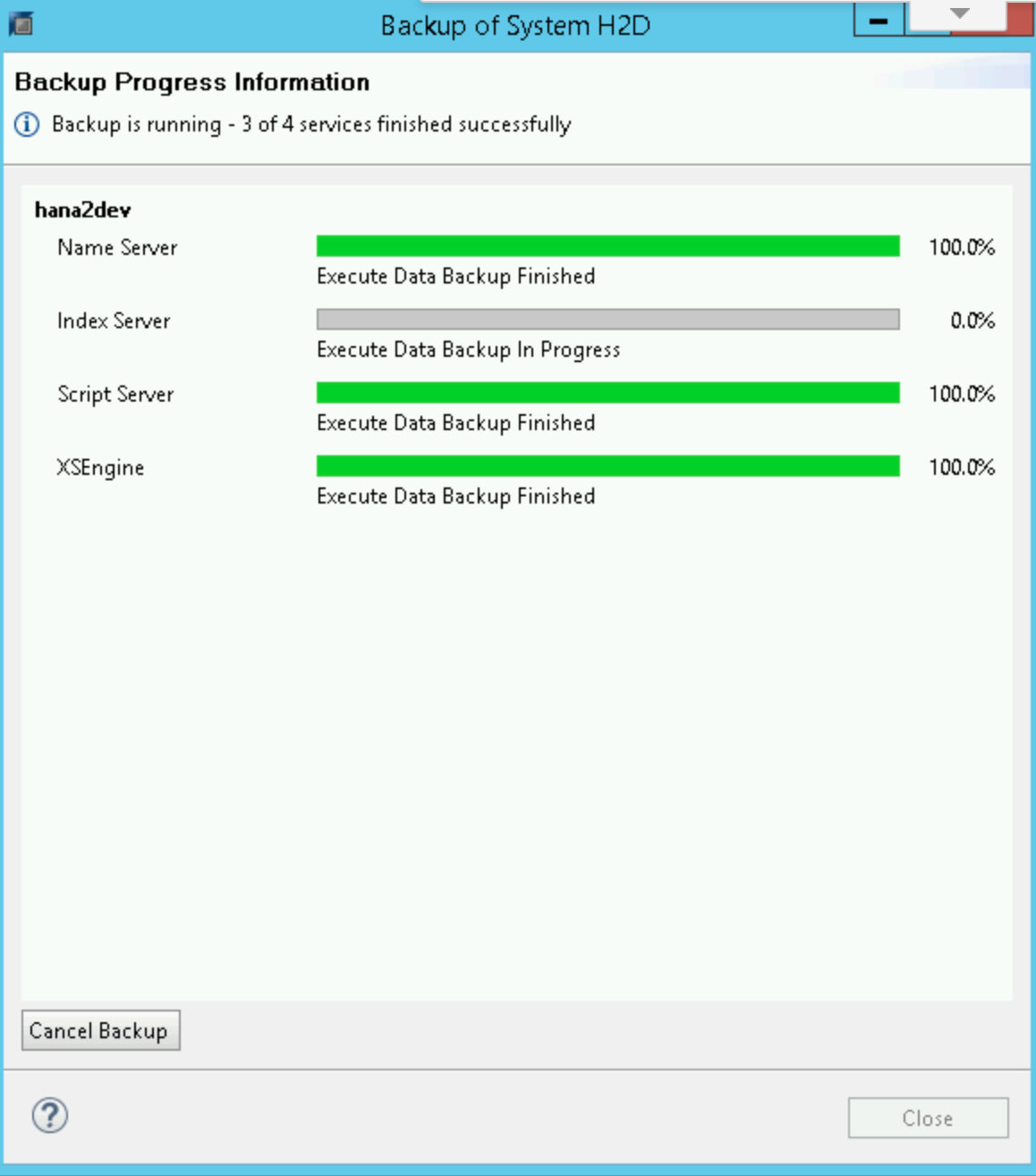
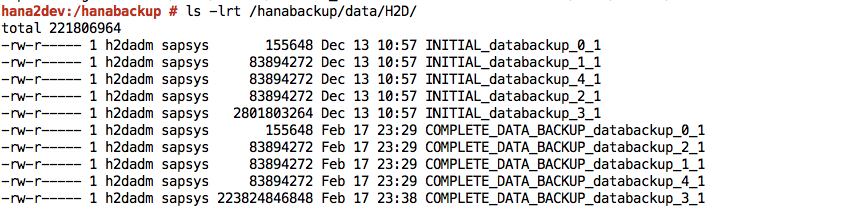
備份完成後,備份摘要會顯示
Finished訊息。登入 SAP HANA 系統,並確認備份檔案是否位於檔案系統中預期的位置。例如:

將備份檔案從
/hanabackup檔案系統推送或同步至 Cloud Storage。以下 Python 範例指令碼會將資料從/hanabackup/data和/hanabackup/log推送至用於備份的值區,格式為NODE_NAME/DATA或LOG/YYYY/MM/DD/HH/BACKUP_FILE_NAME。這樣一來,您就能根據備份資料複製的時間來識別備份檔案。在作業系統的 bash 提示符中執行這個gcloud Python指令碼:python 2>/dev/null - <<EOF import os import socket from datetime import datetime from google.cloud import storage storage_client = storage.Client() today = datetime.today() current_hour = today.strftime('%Y/%m/%d/%H') hostname = socket.gethostname() bucket = storage_client.get_bucket("hanabackup") for subdir, dirs, files in os.walk('/hanabackup/data/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/data/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) for subdir, dirs, files in os.walk('/hanabackup/log/H2D/'): for file in files: backupfilename = os.path.join(subdir, file) if 'COMPLETE_DATA_BACKUP' in backupfilename: only_filename = backupfilename.split('/')[-1] backup_file = hostname + '/log/' + current_hour + '/' + only_filename blob = bucket.blob(backup_file) blob.upload_from_filename(filename=backupfilename) EOF請使用 Gcloud Python 程式庫或 Google Cloud 主控台來列出備份資料。
備份還原範例
如果備份檔案不在
/hanabackup目錄中,但在 Cloud Storage 中,請透過在作業系統 bash 提示符中執行下列指令碼,從 Cloud Storage 下載檔案:python - <<EOF from google.cloud import storage storage_client = storage.Client() bucket = storage_client.get_bucket("hanabackup") blobs = bucket.list_blobs() for fileblob in blobs: blob = bucket.blob(fileblob.name) fname = str(fileblob.name).split('/')[-1] blob.chunk_size=1<<30 if 'log' in fname: blob.download_to_filename('/hanabackup/log/H2D/' + fname) else: blob.download_to_filename('/hanabackup/data/H2D/' + fname) EOF如要復原 SAP HANA 資料庫,請依序點選「Backup and Recovery」 >「Recover System」:

點按「Next」。
指定本機檔案系統中的備份位置,然後按一下「新增」。
點按「Next」。
選取「不使用備份目錄復原」:

點按「Next」。
選取「檔案」做為目的地類型,然後指定備份檔案的位置和正確的備份前置字串。如果您按照備份建立範例程序操作,請注意
COMPLETE_DATA_BACKUP已設為前置字串。點選「下一步」兩次。
按一下「完成」即可開始復原程序。
復原作業完成後,請恢復正常運作,並從
/hanabackup/data/SID/*目錄中移除備份檔案。
後續步驟
以下標準 SAP 文件可能對您有所幫助:
您可能也會覺得下列 Google Cloud 文件很實用: