Ce guide présente le fonctionnement de SAP NetWeaver sur Google Cloud et fournit des informations détaillées sur la migration de votre système SAP NetWeaver existant ou sur la mise en œuvre d'un nouveau système. Google Cloud est certifié pour l'exécution des serveurs d'applications SAP NetWeaver ABAP et Java, et des produits SAP basés sur ces piles de serveurs d'applications.
Ce guide ne couvre pas les spécificités du déploiement du système SAP NetWeaver. Pour découvrir comment planifier votre déploiement de SAP NetWeaver, consultez le Guide de référence de SAP NetWeaver (en anglais).
Principes de base de Google Cloud
Google Cloud comprend de nombreux services et produits basés sur le cloud. Lorsque vous exécutez des produits SAP sur Google Cloud, vous utilisez principalement les services IaaS proposés par Compute Engine et Cloud Storage, ainsi que certaines fonctionnalités communes au niveau de la plate-forme, telles que les outils.
Consultez la page Présentation de Google Cloud Platform pour découvrir les principaux concepts et la terminologie. Ce guide reprend certaines informations de la présentation pour plus de facilité et de cohérence.
Pour une présentation des considérations que les entreprises doivent prendre en compte lors de l'exécution sur Google Cloud, consultez le framework d'architecture Google Cloud.
Interagir avec Google Cloud
Google Cloud propose trois méthodes principales pour interagir avec la plate-forme et vos ressources dans le cloud :
- Google Cloud Console, qui est une interface utilisateur Web.
- L'outil de ligne de commande
gcloud, qui fournit un sur-ensemble des fonctionnalités offertes par la console Google Cloud. - Les bibliothèques clientes, qui fournissent des API pour accéder aux services et gérer les ressources. Ces bibliothèques sont utiles pour créer vos propres outils.
Tarifs et quotas
Vous pouvez utiliser le simulateur de coût pour estimer vos coûts d'utilisation. Pour en savoir plus sur la tarification, consultez les pages Tarifs de Compute Engine, Tarifs de Cloud Storage, et Tarifs de Google Cloud Observability.
Les ressources Google Cloud sont soumises à des quotas. Si vous envisagez d'utiliser des machines à haute capacité de processeur ou de mémoire, vous devrez peut-être demander un quota supplémentaire. Pour plus d'informations, consultez la section sur les quotas des ressources de Compute Engine.
Contrôles de conformité et de souveraineté
Si vous souhaitez que votre charge de travail SAP s'exécute conformément aux exigences liées à la résidence des données, au contrôle des accès, au personnel d'assistance ou à la réglementation, vous devez planifier l'utilisation d'Assured Workloads. Ce service vous aide à exécuter des charges de travail sécurisées et conformes sur Google Cloud, sans compromettre la qualité de votre expérience cloud. Pour en savoir plus, consultez la page Contrôles de conformité et de souveraineté pour SAP sur Google Cloud.
Présentation de SAP NetWeaver sur Google Cloud
À bien des égards, l'exécution de SAP NetWeaver sur Google Cloud est semblable à l'exécution dans votre propre centre de données. Vous devez là encore tenir compte des considérations relatives aux ressources informatiques, au stockage et au réseau. Vous devez également réfléchir à la manière dont vous gérerez les sauvegardes et la récupération après sinistre de votre base de données.
Voici quelques-unes des différences que vous devez connaître :
- Vous interagissez avec les différents composants d'infrastructure via des services, qui sont des versions abstraites ou virtuelles du matériel que vous utiliseriez sur site. Par exemple, certains des services d'infrastructure virtualisés que vous utilisez à la place du matériel sur Google Cloud incluent des disques persistants et des machines virtuelles (VM) Compute Engine, des réseaux et des pare-feu de cloud privé virtuel, et des buckets Cloud Storage pour le stockage de masse.
- Les services Google Cloud offrent des fonctionnalités spécifiques et présentent certaines limites.
- Les services Google Cloud interagissent entre eux de manière particulière.
- SAP NetWeaver et les services Google Cloud interagissent entre eux de manière particulière.
Le diagramme suivant offre une vue d'ensemble de SAP NetWeaver exécuté sur Google Cloud :

Voici quelques points importants à noter dans le diagramme :
- Le système utilise un certain nombre de disques persistants et de VM Compute Engine. Ces composants hébergent le logiciel, y compris le système de base de données principal.
- Le système SAP NetWeaver se compose de ses composants d'application habituels et d'un composant d'agent hôte.
- Le composant d'agent hôte SAP/SAPOSCOL collecte les métadonnées de surveillance de l'agent Google Cloud pour SAP. L'agent Google Cloud pour SAP regroupe les métriques de Cloud Monitoring, la solution de surveillance Google Cloud.
- Toutes les communications entre les composants Google Cloud et les composants externes passent par une couche réseau. Cette couche fournit des fonctionnalités de sécurité telles que des pare-feu, des routes et des passerelles Internet, des VPN, etc.
Architecture à deux niveaux
Le schéma suivant montre des détails propres à une architecture à deux niveaux exécutée sur une VM Compute Engine.

Dans cette architecture, tous les composants sont exécutés sur une seule VM. La VM dispose de cinq disques persistants Compute Engine associés, et chacun d'entre eux a un rôle spécifique. Par exemple :
- Disque racine : contient le système d'exploitation de la VM.
- Disque d'échange : contient le fichier de pagination du système d'exploitation.
- SAP NetWeaver : contient l'installation NetWeaver et les fichiers de profil.
- Volume de données : contient les fichiers de base de données.
- Volume de journaux : contient les journaux du système de base de données utilisés pour assurer la cohérence des données et gérer les opérations de sauvegarde et de restauration des données.
Selon le serveur de base de données que vous utilisez, les volumes de données dont vous avez besoin peuvent être différents de ceux indiqués dans la figure précédente.
Jusqu'à une certaine limite, les performances des disques persistants SSD ou avec équilibrage s'améliorent à mesure que la taille du disque et le nombre de processeurs virtuels augmentent. Si vous utilisez l'un de ces types de disques persistants, créez un volume de disque persistant plus important et partitionnez logiquement le disque dans le système d'exploitation invité pour créer plusieurs systèmes de fichiers. Par exemple, si vous utilisez SAP HANA, vous pouvez mapper les volumes /hana/data, /hana/log et /hana/shared à un seul disque persistant. L'utilisation d'un disque persistant plus grand facilite également le redimensionnement dans la VM et simplifie le processus de gestion.
En fonction de votre application, l'association de plusieurs volumes de disque persistant à votre VM peut avoir des avantages opérationnels. Cela peut par exemple simplifier l'utilisation d'instantanés de disque persistant pour des volumes spécifiques.
La répartition sur plusieurs volumes de disques persistants n'offre pas d'avantage significatif en termes de performances pour SAP sur Google Cloud.
Pour en savoir plus, consultez cette page :
- Performances des disques persistants (documentation de Compute Engine).
- Stockage sur disque persistant (sur la présente page).
Le serveur de base de données aura aussi probablement besoin de disques persistants offrant des performances supérieures aux performances dont SAP NetWeaver a besoin.
Par exemple, pour un déploiement SAP HANA :
- Le disque "Volume de données" contient les fichiers de données.
- Le disque "Journaux" contient les fichiers journaux HANA.
- Les fichiers binaires et les fichiers partagés HANA peuvent être hébergés sur le disque "NetWeaver".
- Vous avez besoin de volume supplémentaire pour stocker les sauvegardes de la base de données.
Obtenez davantage d'informations sur SAP HANA sur Google Cloud en consultant les pages suivantes :
Pour obtenir la liste des lecteurs de disques requis pour SAP ASE, consultez le Guide de planification SAP ASE.
Pour obtenir la liste des lecteurs de disques requis pour SAP MaxDB, consultez le Guide de planification SAP MaxDB.
Dans le cas du déploiement d'IBM Db2 pour Linux, UNIX et Windows (IBM Db2), le nombre de lecteurs de disques requis est supérieur à celui indiqué dans la figure précédente. Pour obtenir la liste des lecteurs de disques requis, consultez le Guide de planification IBM Db2 pour SAP.
Pour plus d'informations sur Microsoft SQL Server sur Google Cloud, consultez la page Windows sur Compute Engine.
Dans les prochaines sections, vous découvrirez ces composants plus en détail et obtiendrez des recommandations à leur sujet.
Architecture à trois niveaux
Le schéma suivant montre quelques informations propres à une architecture à trois niveaux exécutée sur Compute Engine.

Dans cette architecture, le système SAP NetWeaver répartit le travail entre plusieurs serveurs d'applications NetWeaver hébergés sur plusieurs VM. Tous les nœuds des serveurs d'application de NetWeaver partagent la même base de données, qui est hébergée sur une VM distincte. Tous les nœuds des serveurs d'application de NetWeaver ont accès à un système de fichiers partagé sur lequel ils sont installés et qui héberge les profils SAP NetWeaver. Ce système de fichiers partagé se situe sur un disque persistant associé à la VM 1, aux côtés des services centraux SAP.
Machines certifiées
Google Cloud fournit la plupart des ressources informatiques sous forme de VM, également appelées instances de VM, via Compute Engine. Google Cloud fournit des machines "bare-metal" au moyen de la solution Bare Metal.
Tous les types de machines sont capables :
- d'exécuter des systèmes d'exploitation ;
- d'héberger des services centraux SAP ;
- d'héberger les serveurs d'application SAP ;
- d'héberger des serveurs de bases de données.
Lorsque vous planifiez une mise en œuvre de SAP, vous devez tenir compte des points suivants :
- Le nombre de machines dont votre architecture de mise en œuvre a besoin. Il peut s'agir d'une seule VM pour un système de développement, d'entraînement ou de petite production, ou d'un grand nombre de VM pour un système de production permettant un scaling horizontal.
- Les types de machines particuliers, qui détermineront la puissance de traitement (types de processeurs, nombre de cœurs, etc.) et la mémoire volatile disponible.
- L'augmentation du nombre de processeurs virtuels dans une instance de VM augmente la bande passante réseau pour les communications sortantes de la VM (le débit de sortie) jusqu'à une limite pouvant varier en fonction du type de machine. Reportez-vous à la section Quotas de ressources VPC par instance pour plus d'informations.
- Les types d'image, qui détermineront le système d'exploitation, et le type de base de données si vous choisissez d'utiliser SQL Server.
- L'emplacement des VM. Les ressources Compute Engine sont exécutées dans des centres de données Google Cloud à travers le monde. Ces centres de données sont organisés par région et par zone. Pour en savoir plus, consultez la section Planifier les régions et les zones.
- La quantité de stockage sur disque persistant et le nombre de disques persistants. Pour la plupart des types de machines, vous pouvez associer jusqu'à 257 To de stockage sur disque persistant. Bien que vous puissiez associer jusqu'à 128 disques persistants à la plupart des types de machines, l'utilisation d'un nombre réduit de disques persistants réduit la charge de gestion.
Si vous prévoyez un trafic réseau important, comme c'est souvent le cas dans les architectures à trois niveaux qui placent la base de données sur une VM distincte, sélectionnez une instance de VM disposant d'un nombre suffisant de processeurs virtuels afin de fournir le débit dont vous avez besoin.
Pour plus d'informations sur les types de machines Google Cloud et SAPS, consultez la note SAP 2456432 - Applications SAP sur Google Cloud : Produits et types de machines Google Cloud acceptés.
Les sections ci-dessous contiennent des détails supplémentaires.
Types de machine
Google Cloud propose des machines certifiées SAP dans les familles de types de machines suivantes :
- Types de machines optimisés pour le calcul : C2 ou C2D
- Types de machines à usage général : N1, N2, N2D, T2D, C3, C3D ou C4
- Types de machines à mémoire optimisée : M1, M2, M3 ou X4
- Types de machines de solution Bare Metal à mémoire optimisée O2
- Configurations personnalisées des types de machines : N1, N2 ou N2D
Pour plus d'informations sur les différentes familles de types de machines Compute Engine certifiés pour les applications SAP, consultez la section Types de machines certifiés.
Les certifications de machine suivantes s'appliquent à SAP NetWeaver. Pour les certifications de machine spécifiques à SAP HANA, reportez-vous à la section Types de machines certifiés pour SAP HANA.
Avant de sélectionner un type de machine à utiliser, vérifiez qu'il est disponible dans la région et les zones dont vous avez besoin.
Pour plus d'informations sur chaque type de machine Compute Engine, y compris sa disponibilité régionale et zonale, consultez les types de machines.
Pour connaître la disponibilité des types de machines Bare Metal, consultez la section Disponibilité régionale des machines Bare Metal certifiées par SAP.
| Type de machine | Processeurs virtuels | Mémoire (Go) | Configuration minimale de la plate-forme du processeur |
|---|---|---|---|
| Types de machines standards C2 | |||
|
4 | 16 | Intel Cascade Lake |
|
8 | 32 | Intel Cascade Lake |
|
16 | 64 | Intel Cascade Lake |
|
30 | 120 | Intel Cascade Lake |
|
60 | 240 | Intel Cascade Lake |
| Types de machines à haute capacité de mémoire C2D | |||
c2d-highmem-2 |
2 | 16 | AMD EPYC Milan |
c2d-highmem-4 |
4 | 32 | AMD EPYC Milan |
c2d-highmem-8 |
8 | 64 | AMD EPYC Milan |
c2d-highmem-16 |
16 | 128 | AMD EPYC Milan |
c2d-highmem-32 |
32 | 256 | AMD EPYC Milan |
c2d-highmem-56 |
56 | 448 | AMD EPYC Milan |
c2d-highmem-112 |
112 | 896 | AMD EPYC Milan |
| Types de machines standards C2D | |||
|
2 | 8 | AMD EPYC Milan |
|
4 | 16 | AMD EPYC Milan |
|
8 | 32 | AMD EPYC Milan |
|
16 | 64 | AMD EPYC Milan |
|
32 | 128 | AMD EPYC Milan |
c2d-standard-56 |
56 | 224 | AMD EPYC Milan |
c2d-standard-112 |
112 | 448 | AMD EPYC Milan |
| Types de machines personnalisés | |||
| Type de machine personnalisé basé sur N1Remarque | 1 ou n'importe quel nombre pair jusqu'à 96 | 3,75 Go ou plus par processeur virtuel pour une utilisation de mémoire standard, ou 6,5 Go ou plus par processeur virtuel pour une utilisation de mémoire élevée. | Intel Skylake Intel Broadwell |
| Type de machine personnalisé basé sur N2Remarque | N'importe quel nombre pair jusqu'à 32. Après 32, le nombre de processeurs virtuels doit être divisible par 4, jusqu'à 80 processeurs virtuels. Par exemple, 32, 36 et 40 processeurs virtuels sont tous valides, mais 38 ne l'est pas. | 4 Go ou plus par processeur virtuel pour une utilisation de mémoire standard, ou 8 Go ou plus par processeur virtuel pour une utilisation de mémoire élevée. | Intel Cascade Lake |
| Type de machine personnalisé basé sur N2DRemarque | 2 ou un nombre pair de processeurs virtuels divisible par 4, dans la limite de 32 processeurs pris en charge par SAP. | 4 Go par processeur virtuel pour une utilisation de mémoire standard ou 8 Go par processeur virtuel pour une utilisation de mémoire élevée. | AMD EPYC Rome |
| Types de machines à mémoire optimisée M1 | |||
m1-megamem-96 |
96 | 1433 | Intel Skylake |
|
40 | 961 | Intel Broadwell |
|
80 | 1 922 | Intel Broadwell |
|
160 | 3 844 | Intel Broadwell |
| Types de machines à mémoire optimisée M2 | |||
|
208 | 5 888 | Intel Cascade Lake |
|
416 | 11 776 | Intel Cascade Lake |
|
416 | 5 888 | Intel Cascade Lake |
|
416 | 8,832 | Intel Cascade Lake |
| Types de machines à mémoire optimisée M3 | |||
m3-ultramem-32 |
32 | 976 | Intel Ice Lake |
m3-ultramem-64 |
64 | 1 952 | Intel Ice Lake |
m3-ultramem-128 |
128 | 3 904 | Intel Ice Lake |
m3-megamem-64 |
64 | 976 | Intel Ice Lake |
m3-megamem-128 |
128 | 1 952 | Intel Ice Lake |
| Types de machines Bare Metal à mémoire optimisée X4 | |||
x4-megamem-960-metal |
960 | 16 384 | Intel Sapphire Rapids |
x4-megamem-1440-metal |
1 440 | 24,576 | Intel Sapphire Rapids |
x4-megamem-1920-metal |
1 920 | 32 768 | Intel Sapphire Rapids |
| Types de machines à haute capacité de mémoire N1 | |||
|
2 | 13 | Intel Skylake Intel Broadwell |
|
4 | 26 | Intel Skylake Intel Broadwell |
|
8 | 52 | Intel Skylake Intel Broadwell |
|
16 | 104 | Intel Skylake Intel Broadwell |
|
32 | 208 | Intel Skylake Intel Broadwell |
|
64 | 416 | Intel Skylake Intel Broadwell |
|
96 | 624 | Intel Skylake |
| Types de machines standards N1 | |||
|
8 | 30 | Intel Skylake Intel Broadwell |
|
16 | 60 | Intel Skylake Intel Broadwell |
|
32 | 120 | Intel Skylake Intel Broadwell |
|
64 | 240 | Intel Skylake Intel Broadwell |
|
96 | 360 | Intel Skylake |
| Types de machines à haute capacité de mémoire N2 | |||
n2-highmem-2 |
2 | 16 | Intel Ice Lake Intel Cascade Lake |
n2-highmem-4 |
4 | 32 | Intel Ice Lake Intel Cascade Lake |
n2-highmem-8 |
8 | 64 | Intel Ice Lake Intel Cascade Lake |
n2-highmem-16 |
16 | 128 | Intel Ice Lake Intel Cascade Lake |
n2-highmem-32 |
32 | 256 | Intel Ice Lake Intel Cascade Lake |
n2-highmem-48 |
48 | 384 | Intel Ice Lake Intel Cascade Lake |
n2-highmem-64 |
64 | 512 | Intel Ice Lake Intel Cascade Lake |
n2-highmem-80 |
80 | 640 | Intel Ice Lake Intel Cascade Lake |
n2-highmem-96 |
96 | 768 | Intel Ice Lake |
n2-highmem-128 |
128 | 838 | Intel Ice Lake |
| Types de machines standards N2 | |||
n2-standard-2 |
2 | 8 | Intel Ice Lake Intel Cascade Lake |
n2-standard-4 |
4 | 16 | Intel Ice Lake Intel Cascade Lake |
n2-standard-8 |
8 | 32 | Intel Ice Lake Intel Cascade Lake |
n2-standard-16 |
16 | 64 | Intel Ice Lake Intel Cascade Lake |
n2-standard-32 |
32 | 128 | Intel Ice Lake Intel Cascade Lake |
n2-standard-48 |
48 | 192 | Intel Ice Lake Intel Cascade Lake |
n2-standard-64 |
64 | 256 | Intel Ice Lake Intel Cascade Lake |
n2-standard-80 |
80 | 320 | Intel Ice Lake Intel Cascade Lake |
n2-standard-96 |
96 | 384 | Intel Ice Lake |
n2-standard-128 |
128 | 512 | Intel Ice Lake |
| Types de machines à haute capacité de mémoire N2D | |||
|
2 | 16 | AMD EPYC Rome AMD EPYC Milan |
|
4 | 32 | AMD EPYC Rome AMD EPYC Milan |
|
8 | 64 | AMD EPYC Rome AMD EPYC Milan |
|
16 | 128 | AMD EPYC Rome AMD EPYC Milan |
|
32 | 256 | AMD EPYC Rome AMD EPYC Milan |
n2d-highmem-48 |
48 | 384 | AMD EPYC Rome AMD EPYC Milan |
n2d-highmem-64 |
64 | 512 | AMD EPYC Rome AMD EPYC Milan |
n2d-highmem-80 |
80 | 640 | AMD EPYC Rome AMD EPYC Milan |
n2d-highmem-96 |
96 | 768 | AMD EPYC Rome AMD EPYC Milan |
| Types de machines standards N2D | |||
|
2 | 8 | AMD EPYC Rome AMD EPYC Milan |
|
4 | 16 | AMD EPYC Rome AMD EPYC Milan |
|
8 | 32 | AMD EPYC Rome AMD EPYC Milan |
|
16 | 64 | AMD EPYC Rome AMD EPYC Milan |
|
32 | 128 | AMD EPYC Rome AMD EPYC Milan |
n2d-standard-48 |
48 | 192 | AMD EPYC Rome AMD EPYC Milan |
n2d-standard-64 |
64 | 256 | AMD EPYC Rome AMD EPYC Milan |
n2d-standard-80 |
80 | 320 | AMD EPYC Rome AMD EPYC Milan |
n2d-standard-96 |
96 | 384 | AMD EPYC Rome AMD EPYC Milan |
n2d-standard-128 |
128 | 512 | AMD EPYC Rome AMD EPYC Milan |
n2d-standard-224 |
224 | 896 | AMD EPYC Rome AMD EPYC Milan |
| Types de machines standards T2D | |||
|
2 | 8 | AMD EPYC Milan |
|
4 | 16 | AMD EPYC Milan |
|
8 | 32 | AMD EPYC Milan |
|
16 | 64 | AMD EPYC Milan |
t2d-standard-32 |
32 | 128 | AMD EPYC Milan |
t2d-standard-48 |
48 | 192 | AMD EPYC Milan |
t2d-standard-60 |
60 | 240 | AMD EPYC Milan |
| Types de machines à haute capacité de mémoire C4 | |||
c4-highmem-2 |
2 | 15 | Intel Emerald Rapids |
c4-highmem-4 |
4 | 31 | Intel Emerald Rapids |
c4-highmem-8 |
8 | 62 | Intel Emerald Rapids |
c4-highmem-16 |
16 | 124 | Intel Emerald Rapids |
c4-highmem-32 |
32 | 248 | Intel Emerald Rapids |
c4-highmem-48 |
48 | 372 | Intel Emerald Rapids |
c4-highmem-96 |
96 | 744 | Intel Emerald Rapids |
c4-highmem-192 |
192 | 1,488 | Intel Emerald Rapids |
| Types de machines standards C4 | |||
c4-standard-2 |
2 | 7 | Intel Emerald Rapids |
c4-standard-4 |
4 | 15 | Intel Emerald Rapids |
c4-standard-8 |
8 | 30 | Intel Emerald Rapids |
c4-standard-16 |
16 | 60 | Intel Emerald Rapids |
c4-standard-32 |
32 | 120 | Intel Emerald Rapids |
c4-standard-48 |
48 | 180 | Intel Emerald Rapids |
c4-standard-96 |
96 | 360 | Intel Emerald Rapids |
c4-standard-192 |
192 | 720 | Intel Emerald Rapids |
| Types de machines à haute capacité de mémoire C3 | |||
c3-highmem-4 |
4 | 32 | Intel Sapphire Rapids |
c3-highmem-8 |
8 | 64 | Intel Sapphire Rapids |
c3-highmem-22 |
22 | 176 | Intel Sapphire Rapids |
c3-highmem-44 |
44 | 352 | Intel Sapphire Rapids |
c3-highmem-88 |
88 | 704 | Intel Sapphire Rapids |
c3-highmem-176 |
176 | 1408 | Intel Sapphire Rapids |
| Types de machines standards C3 | |||
c3-standard-4 |
4 | 16 | Intel Sapphire Rapids |
c3-standard-8 |
8 | 32 | Intel Sapphire Rapids |
c3-standard-22 |
22 | 88 | Intel Sapphire Rapids |
c3-standard-44 |
44 | 176 | Intel Sapphire Rapids |
c3-standard-88 |
88 | 352 | Intel Sapphire Rapids |
c3-standard-176 |
176 | 704 | Intel Sapphire Rapids |
| Types de machines Bare Metal standards C3 | |||
c3-standard-192-metal |
192 | 768 | Intel Sapphire Rapids |
| Types de machines Bare Metal à haute capacité de mémoire C3 | |||
c3-highmem-192-metal |
192 | 1 536 | Intel Sapphire Rapids |
| Types de machines à haute capacité de mémoire C3D | |||
c3d-highmem-4 |
4 | 32 | Non applicable (N/A) |
c3d-highmem-8 |
8 | 64 | N/A |
c3d-highmem-16 |
16 | 128 | N/A |
c3d-highmem-30 |
30 | 240 | N/A |
c3d-highmem-60 |
60 | 480 | N/A |
c3d-highmem-90 |
90 | 720 | N/A |
c3d-highmem-180 |
180 | 1440 | N/A |
| Types de machines standards C3 | |||
|
4 | 16 | N/A |
|
8 | 32 | N/A |
|
16 | 64 | N/A |
|
30 | 120 | N/A |
c3d-standard-60 |
60 | 240 | N/A |
c3d-standard-90 |
90 | 360 | N/A |
c3d-standard-180 |
180 | 720 | N/A |
| Types de machines Bare Metal O2 | |||
o2-standard-16-metal |
16 | 192 Gio | Intel Cascade Lake |
o2-standard-32-metal |
32 | 384 Gio | Intel Xeon Gold |
o2-standard-48-metal |
48 | 768 Gio | Intel Xeon Gold |
o2-standard-112-metal |
112 | 1 532 Gio | Intel Xeon Platinum |
o2-highmem-224-metal |
224 | 3 Tio | Intel Xeon Platinum |
Disponibilité régionale des machines Bare Metal certifiées par SAP
Les machines Bare Metal qui sont certifiées pour les applications SAP ne sont disponibles que dans les extensions de région de la solution Bare Metal, qui ne sont pas disponibles pour toutes les régions Google Cloud. Pour obtenir la liste complète des régions disposant d'une extension de région de la solution Bare Metal, consultez la page Disponibilité régionale de la solution Bare Metal.
Pour connaître la disponibilité des machines Bare Metal certifiées pour SAP HANA, reportez-vous à la section Disponibilité régionale des machines Bare Metal pour SAP HANA.
Images
Lorsque vous créez une VM Compute Engine, vous utilisez une image contenant les composants de base requis. Par exemple, une image peut contenir un système d'exploitation Microsoft Windows Server avec une installation SQL Server.
Lorsque vous commandez une machine Bare Metal, vous devez également spécifier le système d'exploitation dont vous avez besoin. La machine est disponible avec le système d'exploitation déjà installé.
Pour les VM, il existe plusieurs façons de spécifier une image. Vous pouvez :
- Utiliser le fichier de configuration Terraform (recommandé) ou le modèle Cloud Deployment Manager, fourni par Google Cloud et conçu pour faciliter la configuration de SAP NetWeaver. Pour en savoir plus sur l'utilisation de Terraform ou Cloud Deployment Manager, consultez le guide de déploiement de SAP NetWeaver sur Google Cloud correspondant à votre système d'exploitation.
- Utilisez une image publique : Google propose une variété d'images publiques. Vous devez choisir une image contenant des composants compatibles avec SAP NetWeaver.
- Créez votre propre image personnalisée : vous pouvez créer votre propre système de base de A à Z et créer une image personnalisée que vous pourrez réutiliser. Vous pouvez également créer une image en important un disque de démarrage existant dans Compute Engine.
Images publiques compatibles
Compute Engine fournit des images publiques pour les versions de système d'exploitation compatibles dans des familles d'images.
Pour afficher les versions disponibles dans chaque famille d'images, consultez les détails du système d'exploitation :
- Red Hat Enterprise Linux (RHEL)
- SUSE Linux Enterprise Server (SLES)
- Windows Server
- SQL Server Enterprise
Pour en savoir plus sur l'état de compatibilité des versions de système d'exploitation certifiées pour SAP, consultez la page Compatibilité des systèmes d'exploitation pour SAP NetWeaver sur Google Cloud.
Planifier la gestion des images
Une fois votre système configuré, vous pouvez créer des images personnalisées. En créant des images personnalisées lorsque vous modifiez l'état de votre disque persistant racine, vous pourrez facilement restaurer le nouvel état si nécessaire. Il est important de planifier la gestion des images personnalisées que vous créez. Pour plus d'informations, consultez les bonnes pratiques pour la gestion des images.
Planifier les régions et les zones
Lorsque vous déployez une VM, vous devez choisir une région et une zone. Une région est un emplacement géographique spécifique où vous pouvez exécuter vos ressources et correspond à un ou plusieurs emplacements de centre de données relativement proches les uns des autres. Chaque région possède une ou plusieurs zones avec une connectivité, une alimentation et un refroidissement redondants.
Les ressources globales, telles que les images de disque préconfigurées et les instantanés de disque, sont accessibles dans toutes les régions et les zones. Les ressources régionales, telles que les adresses IP externes statiques régionales, ne sont accessibles qu'aux ressources situées dans la même région. Les ressources zonales, telles que les VM et les disques, ne sont accessibles qu'aux ressources situées dans la même zone. Pour en savoir plus, consultez la page Ressources globales, régionales et zonales.

Lorsque vous choisissez une région et une zone pour vos VM, tenez compte des points suivants :
- L'emplacement de vos utilisateurs et de vos ressources internes, telles que votre centre de données ou votre réseau d'entreprise. Pour réduire la latence, sélectionnez un emplacement situé à proximité de vos utilisateurs et de vos ressources.
- Les plates-formes de processeur disponibles pour cette région et cette zone. Par exemple, les processeurs Intel Broadwell, Haswell, Skylake et Ice Lake sont compatibles avec les charges de travail SAP NetWeaver sur Google Cloud.
- Pour plus d'informations, accédez à la note SAP 2456432 - SAP Applications on Google Cloud: Supported Products and Google Cloud machine types.
- Pour en savoir plus sur les régions dans lesquelles les processeurs Haswell, Broadwell, Skylake et Ice Lake peuvent être utilisés avec Compute Engine, consultez la section Régions et zones disponibles.
- Assurez-vous que votre serveur d'applications SAP et votre base de données se trouvent dans la même région.
Déployer des VM
Vous pouvez utiliser les méthodes standards de Google Cloud pour déployer vos VM sur Compute Engine : la console Google Cloud, Google Cloud CLI, Deployment Manager et l'API REST. Les pages suivantes fournissent des informations qui sont généralement utiles sur le déploiement des VM :
Pour obtenir des informations et des instructions détaillées sur le déploiement d'un système SAP NetWeaver sur des VM Compute Engine, consultez les pages suivantes :
- Présentation du déploiement Linux pour SAP NetWeaver
- Présentation du déploiement Windows pour SAP NetWeaver
Automatisation pour les déploiements SAP NetWeaver
Google Cloud fournit des fichiers de configuration Terraform et des modèles Deployment Manager que vous pouvez utiliser pour automatiser le déploiement de l'infrastructure Google Cloud pour SAP NetWeaver avec un système d'exploitation Linux ou Windows.
Les modèles fournis instancient les ressources suivantes pour SAP NetWeaver :
- Une instance du type de machine de votre choix.
- Votre choix parmi les systèmes d'exploitation suivants :
- Red Hat Enterprise Linux (RHEL)
- SUSE Linux Enterprise Server (SLES)
- Windows Server
- Des disques persistants standards Compute Engine
- Le système de fichiers XFS (pour Linux)
Pour obtenir des instructions sur le déploiement automatisé, consultez les pages suivantes :
- Terraform : Déploiement automatisé de VM pour SAP NetWeaver sous Linux
- Deployment Manager : Déploiement automatisé de VM pour SAP NetWeaver sous Linux
- Deployment Manager : Déploiement automatisé de VM pour SAP NetWeaver sur Windows Server
VM personnalisées et déploiements automatisés
Les fichiers de configuration Terraform et les modèles Deployment Manager ne sont pas compatibles avec la spécification des VM personnalisées Compute Engine.
Si vous avez besoin d'un type de VM personnalisé, déployez d'abord un petit type de VM prédéfini et, une fois le déploiement terminé, personnalisez la VM.
Pour plus d'informations sur la modification de VM, consultez Modifier des configurations de VM pour les systèmes SAP.
Accéder aux VM
Le créateur d'une VM dispose de privilèges racine complets.
- Sur une VM Linux, le créateur dispose de la capacité SSH et peut utiliser la console Google Cloud pour accorder la capacité SSH à d'autres utilisateurs.
- Sur une VM Windows, le créateur peut utiliser la console Google Cloud pour générer un nom d'utilisateur et un mot de passe. Par la suite, toute personne connaissant le nom d'utilisateur et le mot de passe peut se connecter à la VM via RDP.
Lorsqu'un utilisateur disposant de droits d'administrateur se connecte à une instance via SSH ou RDP, il peut ajouter d'autres utilisateurs système via les commandes Linux standard ou via la gestion des comptes utilisateur Windows. Les pages suivantes fournissent des informations utiles sur la connexion aux VM Compute Engine :
Si vous utilisez des instances Linux, vous devez planifier la manière dont vous utiliserez les clés SSH. En général, Compute Engine gère les clés SSH pour vous. Vous pouvez décider de gérer vos propres clés SSH, mais vous devez comprendre les risques qui y sont associés. Pour plus de détails, consultez la page sur les clés SSH.
Pour obtenir des informations et des instructions sur la connexion aux VM Compute Engine dans votre déploiement SAP NetWeaver, consultez le Guide de déploiement de SAP NetWeaver correspondant à votre système d'exploitation :
Bases de données
Vous pouvez utiliser les systèmes de gestion de base de données suivants avec SAP NetWeaver sur Google Cloud :
- SAP HANA sous Linux
- SAP ASE sous Linux ou Windows
- SAP MaxDB sous Linux ou Windows
- IBM Db2 sous Linux ou Windows
- Microsoft SQL Server Enterprise sous Windows
- Serveurs Oracle sur solution Bare Metal avec systèmes d'exploitation compatibles avec la solution Bare Metal pour Oracle. Pour plus d'informations, consultez la page Systèmes d'exploitation.
SAP HANA
SAP HANA est certifié pour fonctionner dans Google Cloud sur les systèmes d'exploitation Linux suivants :
- Red Hat Enterprise Linux (RHEL) pour les solutions SAP
- SUSE Linux Enterprise Server (SLES)
- SUSE Linux Enterprise Server (SLES) pour les applications SAP
Pour plus d'informations sur les types de VM et les systèmes d'exploitation compatibles, consultez la page Guide de planification SAP HANA.
Pour plus d'informations sur SAP HANA, consultez le guide d'utilisation de SAP HANA et la documentation SAP.
Pour obtenir des conseils de dimensionnement et des recommandations pour SAP HANA, consultez la page Dimensionnement de SAP (en anglais).
SAP ASE
SAP ASE sur Google Cloud est compatible avec les systèmes d'exploitation suivants :
Pour plus d'informations sur les types de machines et les systèmes d'exploitation compatibles, consultez le Guide de planification SAP ASE.
Pour déployer SAP ASE sur Google Cloud, consultez le guide de déploiement d'ASE correspondant à votre système d'exploitation :
- Pour Linux, consultez les articles suivants :
- Pour Windows, consultez l'article Deployment Manager : Déploiement automatisé de VM pour SAP ASE sous Windows.
Pour plus d'informations sur SAP ASE, consultez la documentation SAP.
SAP MaxDB
SAP MaxDB sur Google Cloud est compatible avec les systèmes d'exploitation suivants :
Pour plus d'informations sur les types de machines et les systèmes d'exploitation compatibles, consultez le Guide de planification SAP MaxDB. Pour déployer SAP MaxDB sur Google Cloud, consultez le guide de déploiement de SAP MaxDB correspondant à votre système d'exploitation :
Pour plus d'informations sur SAP MaxDB, consultez la bibliothèque SAP MaxDB.
IBM Db2 pour Linux, UNIX et Windows
IBM Db2 est compatible avec SLES, RHEL et Windows Server.
Pour plus d'informations sur les types de machines et les systèmes d'exploitation compatibles, consultez le guide de planification IBM Db2 pour SAP.
Pour déployer IBM Db2 sur Google Cloud, consultez les pages suivantes :
- Déploiement automatisé de VM pour IBM Db2 sous Linux
- Déploiement manuel de VM pour IBM Db2 sous Linux et Windows
Pour plus d'informations sur IBM Db2, consultez la page SAP on IBM Db2 for Linux, UNIX and Windows.
Microsoft SQL Server
Vous pouvez installer SQL Server de différentes manières :
- Vous pouvez utiliser une image publique fournie par Google avec SQL Server Enterprise. L'image SQL Server dans Windows Server est une image payante, ce qui signifie que le coût de l'image est combiné au coût du type de machine.
- Vous pouvez télécharger le DVD de SQL Server à partir de SAP et utiliser le script spécifique à SAP
SQL4SAP.batqui installe SQL Server avec les paramètres appropriés. - Vous pouvez télécharger le DVD de SQL Server à partir de SAP ou Microsoft et utiliser la version standard du fichier Microsoft
setup.exepour installer SQL Server afin de personnaliser votre configuration.
Si vous utilisez SQL Server comme base de données, vous devez vous assurer que SQL Server est configuré pour utiliser le classement SAP, SQL_Latin1_General_CP850_BIN2, afin d'assurer la compatibilité avec les systèmes SAP.
Vous pouvez confirmer le classement de votre serveur SQL dans les propriétés de votre serveur :
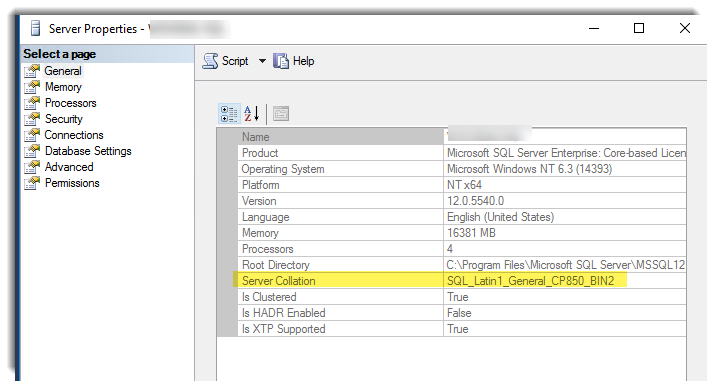
Si vous avez déjà configuré votre serveur SQL, vous pouvez modifier le classement, mais vous devrez ensuite recréer les bases de données. Pour plus d'informations sur la spécification ou la modification du classement, consultez le Guide de déploiement de SAP NetWeaver sous Windows.
Oracle
SAP sur Oracle n'est compatible qu'avec les serveurs de solution Bare Metal, qui s'exécutent dans une extension régionale colocalisée et connectée à certaines régions Google Cloud.
Pour en savoir plus, consultez les pages suivantes :
Sauvegarde et récupération de base de données
Vous devez mettre en place une marche à suivre pour remettre votre système en état de fonctionnement si le pire se produisait. Pour obtenir des conseils généraux sur la façon de planifier la reprise après sinistre à l'aide de Google Cloud, consultez les articles suivants :
Pour plus d'informations sur la sauvegarde et la récupération SAP HANA, consultez le guide des opérations de SAP HANA sur Google Cloud.
Pour plus d'informations sur la sauvegarde et la récupération de SAP ASE, consultez la page Performance and Tuning Series: Physical Database Tuning pour SAP ASE.
Pour plus d'informations sur la sauvegarde et la récupération de SAP MaxDB, consultez la page SAP MaxDB Database Administration.
Pour plus d'informations sur la sauvegarde et la restauration d'IBM Db2, consultez la page Backup and Recovery.
Au lieu d'options de reprise après sinistre natives, pour la reprise après sinistre active-passive interrégionale, vous pouvez utiliser la réplication asynchrone des disques persistants. La réplication asynchrone des disques persistants fournit une réplication asynchrone des données entre deux régions Google Cloud.
Stockage
Par défaut, chaque VM Compute Engine possède un petit disque persistant racine contenant le système d'exploitation. Vous pouvez ajouter des disques supplémentaires à vos VM afin d'y stocker les différents composants de votre système.
Stockage sur disque persistant
Pour le stockage de blocs persistants, vous pouvez associer des volumes Persistent Disk et Hyperdisk à vos VM Compute Engine.
Compute Engine propose différents types de volumes Persistent Disk et Hyperdisk. Chaque type présente des caractéristiques de performances différentes. Google Cloud gère le matériel sous-jacent de ces disques pour garantir la redondance des données et optimiser les performances.
Avec SAP NetWeaver, vous pouvez utiliser l'un des types de volumes Persistent Disk ou Hyperdisk suivants :
- Types de volumes Persistent Disk : Standard (
pd-standard), Balanced (pd-balanced), Performance ou SSD (pd-ssd) et Extreme (pd-extreme)- Les disques Persistent Disk Standard s'appuient sur des disques durs standards (HDD). Ce type de disque est efficace et économique pour la gestion des opérations de lecture/écriture séquentielles, mais n'est pas optimisé pour gérer des taux élevés d'opérations d'entrée/sortie par seconde (IOPS) aléatoires.
- Les volumes Persistent Disk Balanced, Performance ou SSD (
pd-ssd) et Extreme s'appuient sur des disques durs SSD. Ces types de disques offrent un stockage de blocs économique et fiable. - Le volume Persistent Disk SSD ou Performance offre des performances supérieures au volume Persistent Disk Balanced.
- Les volume Persistent Disk Balanced et Performance (SSD) sont compatibles avec la réplication asynchrone des disques persistants. Vous pouvez utiliser cette fonctionnalité pour la reprise après sinistre active/passive interrégionale. Pour en savoir plus, consultez la section Réplication asynchrone des disques persistants.
- Bien que vous puissiez utiliser un volume Persistent Disk Extreme (
pd-extreme) avec vos applications SAP, nous vous recommandons plutôt d'utiliser des volumes Hyperdisk, qui offrent de meilleures performances. Pour en savoir plus sur les types de machines compatibles avec l'utilisation de volumes Persistent Disk Extreme, consultez la section Compatibilité avec les types de machine.
- Types de volume Hyperdisk : Hyperdisk Balanced (
hyperdisk-balanced) et Hyperdisk Extreme (hyperdisk-extreme)- Les volumes Hyperdisk Extreme offrent des options d'IOPS et de débit maximum plus élevées que les volumes Persistent Disk.
- Pour les volumes Hyperdisk Extreme, vous sélectionnez les performances dont vous avez besoin en provisionnant les IOPS, qui déterminent également votre débit. Pour en savoir plus, consultez la section Débit.
- Pour les volumes Hyperdisk Balanced, vous sélectionnez les performances dont vous avez besoin en provisionnant les IOPS et le débit. Pour en savoir plus, consultez la section À propos du provisionnement des IOPS et du débit pour Hyperdisk.
- Pour en savoir plus sur les types de machines compatibles avec Hyperdisk, consultez la section Compatibilité avec les types de machines.
Le type de VM que vous utilisez et le nombre de processeurs virtuels qu'elle contient peuvent également affecter ou limiter les performances des disques persistants.
La figure suivante illustre les performances approximatives des volumes Persistent Disk Balanced dans un exemple de configuration SAP NetWeaver sur Google Cloud. Les nombres réels que vous pouvez voir dans une configuration similaire sont susceptibles de différer pour diverses raisons, y compris les améliorations effectuées par Compute Engine au fil du temps.
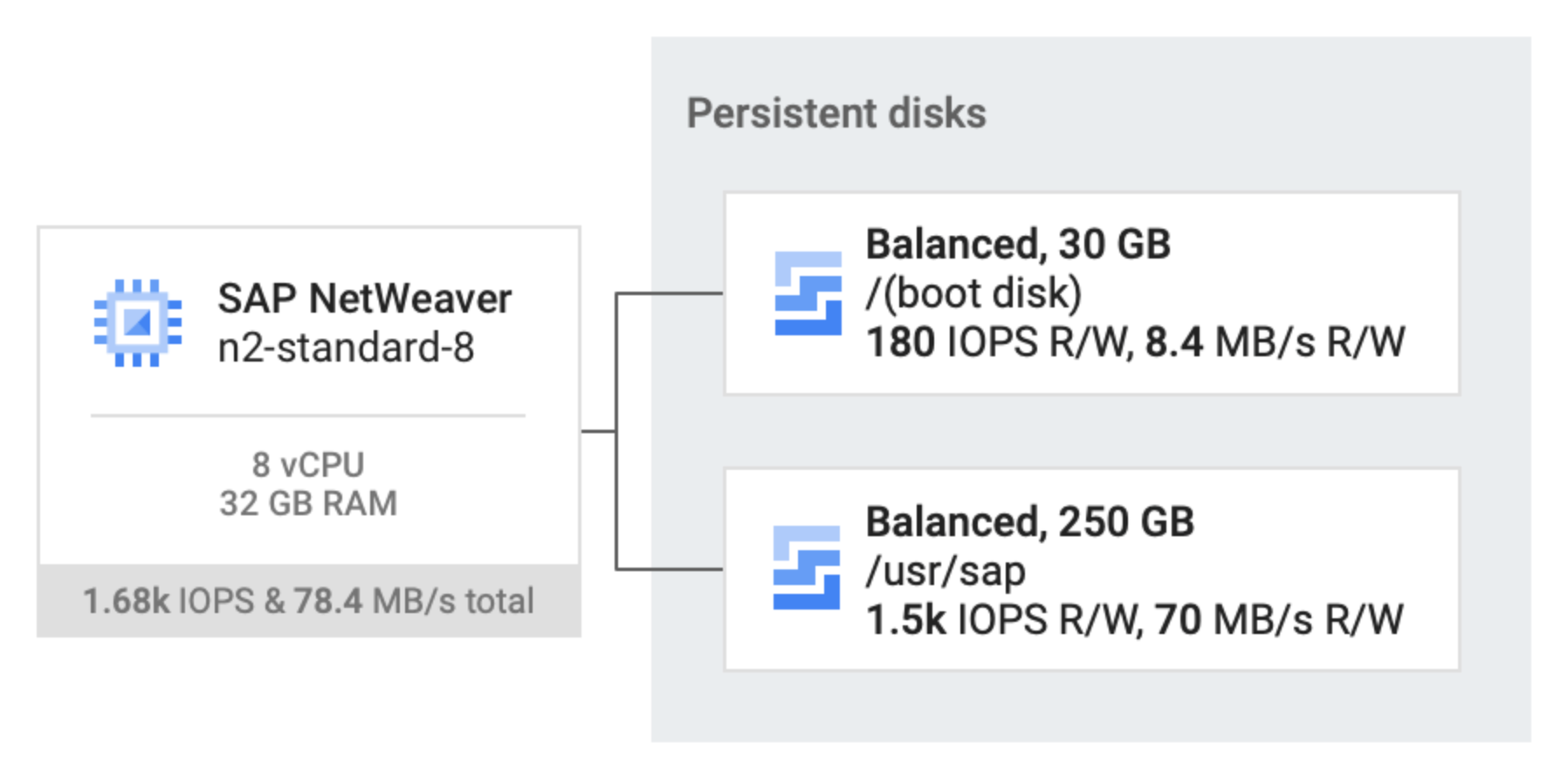
Comme indiqué dans la figure précédente, lorsque les volumes Persistent Disk sont du même type, par exemple SSD ou Balanced, les performances fournies à la VM sont cumulatives. Par conséquent, vous pouvez estimer les performances globales en additionnant les valeurs de performances de chaque volume Persistent Disk.
Par exemple, si vous associez deux volumes Persistent Disk Balanced, comme illustré dans la figure, l'un fournissant 180 IOPS en lecture/écriture et un débit de 8,4 Mo par seconde, et l'autre fournissant 1 500 IOPS en lecture/écriture et un débit de 70 Mo par seconde, les deux volumes Persistent Disk Balanced fournissent ensemble 1 680 IOPS en lecture/écriture et 78,4 Mo par seconde de débit. Pour plus d'informations, consultez les sections "Plusieurs disques associés à une seule instance de VM" et "Lectures et écritures simultanées" dans Facteurs ayant une incidence sur les performances du disque.
Les volumes Persistent Disk et Hyperdisk sont hébergés indépendamment de vos VM. Vous pouvez donc dissocier ou déplacer les volumes pour conserver vos données, même après la suppression de vos VM.
Sur la page Instances de VM de la console Google Cloud, vous pouvez voir les disques associés à vos instances de VM sous Disques supplémentaires, sur la page Informations sur l'instance de VM correspondant à chaque instance de VM.
Pour plus d'informations sur les différents types de stockage de blocs proposés par Compute Engine, leurs caractéristiques de performances et leur utilisation, consultez la documentation de Compute Engine :
- Options de stockage
- Performances des options de stockage de blocs
- À propos de Google Cloud Hyperdisk
- Autres facteurs ayant une incidence sur les performances
- Ajouter ou redimensionner des disques persistants zonaux
- Créer des instantanés de disque persistants
Disques persistants déployés par les modèles de déploiement
Si vous déployez la VM hôte à l'aide des fichiers de configuration Terraform ou des modèles Cloud Deployment Manager fournis par SAP NetWeaver, les scripts d'automatisation du déploiement associent deux ou trois disques persistants standards pour les volumes ou lecteurs requis, selon que vous utilisez Windows Server ou Linux.
Solutions de partage de fichiers
Plusieurs solutions de partage de fichiers sont disponibles sur Google Cloud, parmi lesquelles :
- Filestore
- NetApp Cloud Volumes ONTAP
- Service NetApp Cloud Volumes pour Google Cloud
Pour déterminer quelle solution convient le mieux à votre scénario de déploiement, consultez la page Solutions de partage de fichiers pour SAP sur Google Cloud.
Disque SSD local (non persistant)
Google Cloud propose des disques SSD locaux. Bien que les disques SSD locaux puissent offrir certains avantages par rapport aux disques persistants, ne les utilisez pas dans le cadre d’un système SAP NetWeaver. Les instances de VM avec des disques SSD locaux associés ne peuvent pas être arrêtées, puis redémarrées.
Utiliser Cloud Storage pour stocker des objets
Cloud Storage est un magasin d'objets pour des fichiers de n'importe quel type et n'importe quel format. Il propose un espace de stockage quasiment illimité, ce qui signifie que vous n'avez pas à vous soucier de son provisionnement ni de l'ajout de capacité. Un objet Cloud Storage contient des données de fichier et les métadonnées qui y sont associées, et sa taille peut atteindre 5 téraoctets. Un bucket Cloud Storage peut stocker un nombre illimité d'objets.
Il est courant de stocker des fichiers dans Cloud Storage pour tout type d'usage. Par exemple, Cloud Storage constitue un excellent emplacement de stockage pour les fichiers de sauvegarde SAP HANA. Pour planifier la sauvegarde de vos bases de données, consultez les ressources disponibles à la section Sauvegarde et restauration de bases de données. Vous pouvez également utiliser Cloud Storage dans le cadre d'un processus de migration.
Choisissez votre option Cloud Storage en fonction de la fréquence à laquelle vous devez accéder aux données. Pour un accès fréquent plusieurs fois par mois, sélectionnez la classe de stockage Standard. Si seul un accès peu fréquent est requis, sélectionnez le stockage Nearline ou Coldline. Pour les données d'archivage auxquelles vous ne pensez pas avoir besoin d'accéder, sélectionnez le stockage Archive.
Lorsque vous planifiez vos options de stockage, commencez par le niveau le plus utilisé, puis affectez vos données de sauvegarde aux niveaux d'accès peu fréquents, car les sauvegardes les plus anciennes sont rarement utilisées. En effet, il est très peu probable que vous ayez besoin d'une sauvegarde vieille de 3 ans. Vous pouvez donc affecter vos données de sauvegarde au niveau Archive par souci d'optimisation des coûts.
Pour une comparaison plus détaillée, consultez la page Classes de stockage. Pour en savoir plus sur les différentes options de stockage disponibles, consultez la page Produits Cloud Storage.
Identification de l'utilisateur et accès aux ressources
Lorsque vous planifiez la sécurité d'un déploiement SAP sur Google Cloud, vous devez identifier les éléments suivants :
- Les comptes utilisateur et les applications qui ont besoin d'accéder aux ressources Google Cloud de votre projet Google Cloud.
- Les ressources Google Cloud spécifiques à votre projet auxquelles chaque utilisateur doit accéder.
Vous devez ajouter chaque utilisateur à votre projet en ajoutant son ID de compte Google au projet en tant que compte principal. Pour un programme d'application qui utilise les ressources Google Cloud, vous devez créer un compte de service. Il fournit une identité d'utilisateur pour le programme au sein de votre projet.
Les VM Compute Engine possèdent leur propre compte de service. Tous les programmes qui s'exécutent sur une VM peuvent utiliser le compte de service de la VM, à condition que le compte de service de la VM dispose des autorisations liées aux ressources dont le programme a besoin.
Après avoir identifié les ressources Google Cloud dont chaque utilisateur a besoin, accordez à chaque utilisateur l'autorisation d'utiliser chaque ressource en attribuant des rôles spécifiques à l'utilisateur. Examinez les rôles prédéfinis fournis par IAM pour chaque ressource et attribuez des rôles à chaque utilisateur afin de lui accorder les autorisations minimales nécessaires pour exécuter ses tâches ou ses fonctions.
Si vous avez besoin d'exercer un contrôle plus précis et plus restrictif sur les autorisations que celui fourni par les rôles IAM prédéfinis, créez des rôles personnalisés.
Pour en savoir plus sur les rôles IAM dont les programmes SAP ont besoin sur Google Cloud, consultez la page Gestion de l'authentification et des accès pour les programmes SAP sur Google Cloud.
Pour en savoir plus sur la gestion de l'authentification et des accès pour SAP sur Google Cloud, consultez la présentation de la gestion de l'authentification et des accès pour SAP sur Google Cloud.
Mise en réseau et sécurité réseau
Tenez compte des informations fournies dans les sections suivantes lorsque vous planifiez la mise en réseau et la sécurité réseau.
Modèle de privilège minimum
L'une de vos premières lignes de défense consiste à limiter le nombre de personnes pouvant accéder à votre réseau et à vos VM à l'aide de pare-feu.
Par défaut, tout le trafic vers les VM, même celui provenant d'autres VM, est bloqué par le pare-feu, sauf si vous créez des règles pour autoriser l'accès. Ceci à l'exception du réseau default qui est créé automatiquement avec chaque projet et qui possède des règles de pare-feu par défaut.
En créant des règles de pare-feu, vous pouvez limiter tout le trafic sur un ensemble de ports donné à des adresses IP source spécifiques. Suivez le modèle de privilège minimum pour limiter l'accès aux adresses IP, protocoles et ports spécifiques qui nécessitent un accès. Par exemple, vous devez toujours configurer un hôte bastion et autoriser les connexions SSH dans votre système SAP NetWeaver uniquement à partir de cet hôte.
Réseaux personnalisés et règles de pare-feu
Vous pouvez utiliser un réseau pour définir une adresse IP de passerelle et la plage de réseau des VM connectées à ce réseau. Tous les réseaux Compute Engine utilisent le protocole IPv4. Chaque projet Google Cloud dispose d'un réseau par défaut avec des configurations prédéfinies et des règles de pare-feu, mais vous devez ajouter un sous-réseau personnalisé et ajouter des règles de pare-feu selon le modèle de privilège minimum. Par défaut, un réseau nouvellement créé n’a pas de règles de pare-feu et donc pas d’accès au réseau.
Vous pouvez ajouter plusieurs sous-réseaux si vous souhaitez isoler certaines parties de votre réseau, et selon vos besoins. Pour plus d'informations, consultez la section sur les sous-réseaux.
Les règles de pare-feu s'appliquent à l'ensemble du réseau et à toutes les VM du réseau. Vous pouvez ajouter une règle de pare-feu qui autorise le trafic entre les VM du même réseau et pour tous les sous-réseaux. Vous pouvez également configurer des pare-feu à appliquer à des VM cibles spécifiques à l'aide du mécanisme de marquage.
SAP nécessite l'accès à certains ports. Par conséquent, vous devrez ajouter des règles de pare-feu pour permettre l'accès aux ports indiqués par SAP.
Routes
Les routes sont des ressources globales associées à un seul réseau. Les routes créées par l'utilisateur s'appliquent à toutes les VM d'un réseau. Cela signifie que vous pouvez ajouter une route qui transfère le trafic d'une VM à une autre au sein du même réseau et entre sous-réseaux sans requérir d'adresses IP externes.
Pour un accès externe aux ressources Internet, lancez une VM sans adresse IP externe et configurez une autre VM en tant que passerelle NAT. Cette configuration nécessite que vous ajoutiez votre passerelle NAT en tant que route pour votre instance SAP.
Utiliser des hôtes bastion et des passerelles NAT
Si votre stratégie de sécurité requiert des VM véritablement internes, vous devez configurer manuellement un proxy NAT sur votre réseau et une route correspondante afin que les VM puissent accéder à Internet. Il est important de noter que vous ne pouvez pas vous connecter directement à une instance de VM entièrement interne à l'aide de SSH. Pour ce faire, vous devez configurer une instance bastion dotée d'une adresse IP externe et vous en servir comme tunnel. Lorsque les VM n'ont pas d'adresses IP externes, elles ne peuvent être accessibles que par d'autres VM du réseau ou par le biais d'une passerelle VPN gérée. Vous pouvez provisionner des VM pour votre réseau pour qu’elles agissent en tant que relais de confiance pour les connexions entrantes, appelées hôtes bastions, ou pour les sorties réseau, appelées passerelles NAT. Pour une connectivité plus transparente sans configurer de telles connexions, vous pouvez utiliser une ressource de passerelle VPN gérée.
Utiliser des hôtes bastion pour les connexions entrantes
Les hôtes bastion constituent un point d'entrée externe dans un réseau contenant des VM de réseau privé. Cet hôte peut fournir un seul point de renforcement ou d'audit et peut être démarré et arrêté pour activer ou désactiver la communication SSH entrante à partir d'Internet.
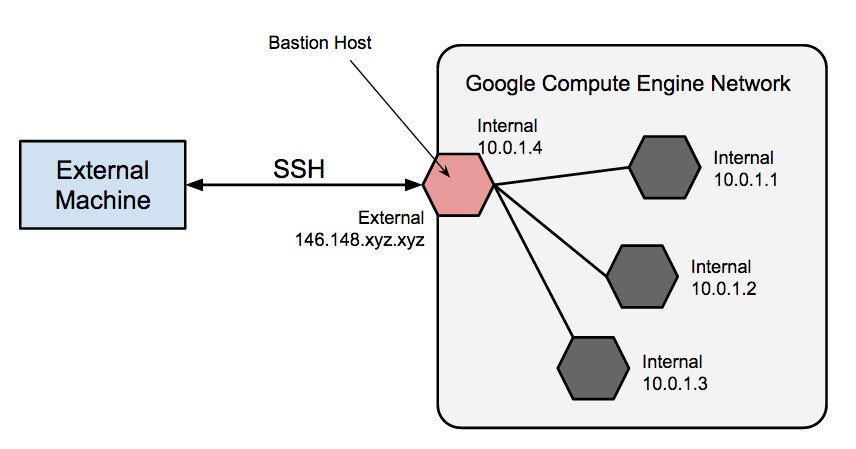
Vous pouvez obtenir un accès SSH aux VM n'ayant pas d'adresse IP externe en vous connectant d'abord à un hôte bastion. Le renforcement complet d'un hôte bastion n'entre pas dans le cadre de cet article, mais vous pouvez effectuer les premières étapes suivantes :
- Limiter la plage CIDR d'adresses IP sources pouvant communiquer avec le bastion
- Configurer des règles de pare-feu qui autorisent uniquement le trafic SSH provenant de l'hôte bastion vers des VM privées
Par défaut, SSH sur les VM est configuré pour utiliser des clés privées pour l'authentification. Lorsque vous utilisez un hôte bastion, vous devez d'abord vous connecter à l'hôte bastion, puis à votre VM privée cible. En raison de cette connexion en deux étapes, nous vous recommandons d'utiliser le transfert d'agent SSH pour atteindre la VM cible au lieu de stocker la clé privée de la VM cible sur l'hôte bastion. Vous devez procéder ainsi même si vous utilisez la même paire de clés pour les VM cibles et le bastion, car le bastion a un accès direct uniquement à la moitié publique de la paire de clés.
Utiliser des passerelles NAT pour le trafic sortant
Lorsqu'une VM ne possède pas d'adresse IP externe attribuée, elle ne peut pas établir de connexions directes avec des services externes, y compris d'autres services Google Cloud. Pour permettre à ces VM d'accéder aux services sur Internet, vous pouvez mettre en place et configurer une passerelle NAT. La passerelle NAT est une VM pouvant acheminer le trafic pour le compte de toute autre VM du réseau. Utilisez une passerelle NAT par réseau. Une passerelle NAT à VM unique n'est pas hautement disponible et n'est pas en mesure d'accepter un débit élevé pour plusieurs VM. Pour obtenir des instructions sur la configuration d'une VM en tant que passerelle NAT, consultez le guide de déploiement NetWeaver correspondant à votre système d'exploitation :
Cloud VPN
Vous pouvez connecter de manière sécurisée votre réseau existant à Google Cloud via une connexion VPN avec IPsec en utilisant Cloud VPN. Le trafic circulant entre les deux réseaux est chiffré par une passerelle VPN, puis déchiffré par l'autre passerelle VPN. Ce procédé protège les données lors des transferts via Internet. Vous pouvez contrôler de manière dynamique quelles sont les VM qui peuvent envoyer du trafic via le VPN à l'aide de tags d'instance sur les routes. Les tunnels Cloud VPN sont facturés à un tarif mensuel fixe, majoré des frais de sortie standards. Notez que vous devez quand même payer les frais de sortie standards lorsque vous connectez deux réseaux d'un même projet. Pour en savoir plus, consultez les pages suivantes :
Sécuriser un bucket Cloud Storage
Si vous utilisez Cloud Storage pour héberger les sauvegardes de vos données et journaux, assurez-vous d'utiliser TLS (HTTPS) lors de l'envoi de données à Cloud Storage à partir de vos VM afin de protéger les données en transit. Cloud Storage chiffre automatiquement les données au repos. Vous pouvez spécifier vos propres clés de chiffrement si vous disposez de votre propre système de gestion de clés.
Envoi d'e-mails
Pour protéger vos systèmes et Google contre les utilisations abusives, Google Cloud impose des limites concernant l'envoi d'e-mails depuis Compute Engine. Pour plus d'informations, consultez la page Envoyer des e-mails depuis une instance.
Documents de sécurité associés
Reportez-vous aux ressources de sécurité supplémentaires ci-dessous pour votre environnement SAP sur Google Cloud :
- Se connecter en toute sécurité aux instances de VM
- Centre de sécurité
- Conformité dans Google Cloud
- Livre blanc sur la sécurité dans Google Cloud
- Conception de la sécurité dans l'infrastructure de Google
Surveillance
Pour l'assistance et la surveillance, Google Cloud fournit l'agent pour SAP pour les charges de travail SAP exécutées sur des instances de VM Compute Engine et des serveurs de solution Bare Metal.
Conformément à la demande de SAP, vous devez installer l'agent Google Cloud pour SAP sur toutes les instances de VM Compute Engine et tous les serveurs de solution Bare Metal qui exécutent un système SAP afin de bénéficier de l'assistance de SAP et de permettre à SAP de respecter ses contrats de niveau de service. Pour en savoir plus sur les conditions préalables à l'assistance, consultez la Note SAP 2456406 - SAP on Google Cloud Platform: Support Prerequisites (SAP sur Google Cloud Platform : prérequis pour l'assistance).
La version 3.5 (la plus récente) de l'agent Google Cloud pour SAP est le successeur de l'agent de surveillance de Google Cloud pour SAP NetWeaver version 2, de l'agent de surveillance pour SAP HANA version 2 et de l'agent Backint Cloud Storage pour SAP HANA. Par conséquent, en plus de la collecte de métriques, la version 3.5 (la plus récente) de l'agent Google Cloud pour SAP inclut la fonctionnalité facultative suivante : Sauvegarde et récupération basées sur Backint pour SAP HANA. Vous pouvez activer ces fonctionnalités pour activer des produits et des services, tels que la gestion des charges de travail, pour vos charges de travail SAP.Installez l'agent Google Cloud pour SAP sur l'hôte conjointement au système SAP. Pour savoir comment installer et configurer l'agent, valider votre installation et vérifier que l'agent s'exécute comme prévu, consultez Installer l'agent sur une instance de VM Compute Engine.
Si vous utilisez les images "pour SAP" suivantes des OS RHEL ou SLES, fournies par Google Cloud, l'agent Google Cloud pour SAP sera empaqueté avec les images d'OS :
- RHEL : toutes les images "for SAP"
- SLES : SLES 15 SP4 pour SAP et versions ultérieures
Mettre à l'échelle des serveurs d'applications SAP NetWeaver
SAP est compatible avec une architecture à évolutivité horizontale utilisant plusieurs serveurs d'applications pour gérer les charges de travail plus importantes.
Si vous utilisez Windows Server comme système d'exploitation, vous pouvez utiliser Active Directory exécuté sur une VM en tant que contrôleur de domaine. Pour plus d'informations, consultez la page Configurer Active Directory sur Google Compute Engine. Vous pouvez également connecter des VM Compute Engine à votre contrôleur de domaine Active Directory sur site à l'aide d'un VPN.
Dans une configuration à évolutivité horizontale, les nœuds doivent accéder à un système de fichiers partagé. Sous Windows Server, spécifiez l'endroit où est installé le système de fichiers partagé lors de l'installation à l'aide du programme d'installation SAP. Pour Linux, utilisez le système de fichiers NFS en tant que partage de fichiers sur le disque de fichiers binaires/profils NetWeaver du système central (/sapmnt/[SID], où [SID] est l'ID système). Pour plus d'informations, consultez la documentation SAP.
Pour en savoir plus sur les solutions de partage de fichiers disponibles sur Google Cloud pour SAP NetWeaver, consultez la page Solutions de partage de fichiers.
Migrer un système SAP NetWeaver existant
En migrant un environnement SAP NetWeaver existant, vous pouvez tirer le maximum de votre investissement dans votre configuration existante, dans le cloud. Or, lorsqu'il s'agit d'un système de taille significative, vous devez avoir recours à une planification minutieuse et procéder à la migration étape par étape afin d'éviter toute perte de cohérence entre les composants du système.
Pour ce qui est des migrations, suivez les procédures de migration SAP standards. SAP recommande de suivre ses bonnes pratiques pour la copie des composants de votre système source vers un système cible nouvellement créé. Lorsque les systèmes source et cible utilisent les mêmes systèmes d'exploitation et de base de données, utilisez la copie de système homogène. Lorsque les systèmes source et cible utilisent des systèmes d'exploitation ou de base de données différents, utilisez la copie de système hétérogène.
Licences
Cette section fournit des informations sur les exigences en matière de licences.
Licences SAP
Pour exécuter SAP sur Google Cloud, vous devez apporter votre propre licence (BYOL).
Consultez les notes SAP suivantes :
- 2446441 - Linux on Google Cloud Platform (IaaS): Adaption of your SAP License
- 2456953 - Windows on Google Cloud Platform (IaaS): Adaption of your SAP License
Pour en savoir plus sur la gestion de vos licences SAP NetWeaver, consultez la procédure de gestion des licences SAP.
Microsoft Windows Server et SQL Server
Dans Compute Engine, il existe deux méthodes d'octroi de licence pour les logiciels Microsoft :
Avec les licences pay-as-you-go (facturation à l'usage), le coût horaire de votre VM Compute Engine inclut les licences. Google gère la logistique des licences avec Microsoft. Vos coûts horaires sont plus élevés, mais vous avez toute la flexibilité nécessaire pour augmenter et diminuer les coûts selon vos besoins. Il s'agit du modèle de licence utilisé pour les images publiques Google Cloud qui incluent Windows Server, avec ou sans SQL Server.
Avec BYOL, les coûts de votre VM Compute Engine sont réduits car la licence n’est pas incluse. Vous devez migrer une licence existante ou acheter votre propre licence, ce qui signifie payer à l'avance, et vous avez moins de flexibilité. Cependant, avec des besoins d'utilisation très stables, ou avec des licences gratuites ou à prix réduit via des contrats de licence Microsoft, cette approche pourrait être moins coûteuse.
Les conditions de Microsoft concernant la migration des licences sont différentes pour Windows Server et SQL Server. Pour plus d'informations sur BYOL avec Google Cloud, consultez la page Utiliser les licences d'application Microsoft existantes.
Pour plus d'informations sur les limitations relatives aux licences SAP pour SQL Server, consultez la note SAP 2139358.
Linux
Dans Compute Engine, il existe deux méthodes d'octroi de licence pour SLES et RHEL :
Avec les licences pay-as-you-go (facturation à l'usage), le coût horaire de votre VM Compute Engine inclut les licences. Google gère la logistique des licences. Vos coûts horaires sont plus élevés, mais vous avez toute la flexibilité nécessaire pour augmenter et diminuer les coûts selon vos besoins. Il s'agit du modèle de licence utilisé pour les images publiques Google Cloud qui incluent SLES ou RHEL.
Avec BYOL, les coûts de votre VM Compute Engine sont réduits car la licence n’est pas incluse. Vous devez migrer une licence existante ou acheter votre propre licence, ce qui signifie payer à l'avance, et vous avez moins de flexibilité.
Assistance
Pour les problèmes liés à l'infrastructure ou aux services Google Cloud, contactez l'assistance Customer Care. Ses coordonnées sont disponibles sur la page de présentation de l'assistance dans la console Google Cloud. Si l'assistance Customer Care détecte un problème dans vos systèmes SAP, vous serez redirigé vers l'assistance SAP.
Pour les problèmes liés au produit SAP, entrez votre demande d'assistance avec l'outil de l'assistance SAP.
SAP évalue la demande d'assistance puis, s'il semble s'agir d'un problème d'infrastructure Google Cloud, la transfère au composant Google Cloud approprié dans son système : BC-OP-LNX-GOOGLE ou BC-OP-NT-GOOGLE.
Exigences liées à l'assistance
Pour bénéficier d'une assistance pour les systèmes SAP ainsi que pour l'infrastructure et les services Google Cloud que ces systèmes utilisent, vous devez satisfaire aux exigences minimales de la formule d'assistance.
Pour en savoir plus sur les exigences minimales concernant l'assistance pour SAP sur Google Cloud, consultez les ressources suivantes :
- Obtenir de l'aide concernant SAP sur Google Cloud
- Note SAP 2456406 – SAP sur Google Cloud Platform : prérequis pour l'assistance (un compte utilisateur SAP est requis)
Étapes suivantes
Pour effectuer les tâches nécessaires au déploiement, consultez le Guide de déploiement de NetWeaver correspondant à votre système d'exploitation :
Pour obtenir une présentation des systèmes SAP NetWeaver haute disponibilité sur Google Cloud, consultez le guide de planification de la haute disponibilité pour SAP NetWeaver sur Google Cloud.
Pour obtenir une présentation des options de reprise après sinistre des systèmes SAP NetWeaver sur Google Cloud, consultez la page Guide de planification de la reprise après sinistre pour SAP NetWeaver sur Google Cloud.
Pour plus d'informations sur l'administration des VM et la surveillance, consultez le guide des opérations SAP NetWeaver sur Google Cloud.