本說明文件將說明如何使用 SAP Landscape Transformation (LT) Replication Server 和 SAP Data Services (DS) 設定解決方案,將資料從 SAP 應用程式 (例如 SAP S/4HANA 或 SAP Business Suite) 複製到 BigQuery。
您可以使用資料複製功能,近乎即時備份 SAP 資料,或在 BigQuery 中將 SAP 系統的資料與其他系統的消費者資料合併,藉由機器學習取得洞察資料,並進行 PB 等級的資料分析。
本操作說明適用於 SAP 系統管理員,他們必須具備 SAP Basis、SAP LT Replication Server、SAP DS 和 Google Cloud的基礎設定經驗。
架構

SAP LT Replication Server 可做為 SAP NetWeaver 作業資料佈建架構 (ODP) 的資料提供者。SAP LT Replication Server 會接收已連線 SAP 系統的資料,並將資料儲存在 SAP LT Replication Server 系統的 Operational Delta Queue (ODQ) 中 ODP 架構中。因此,SAP LT Replication Server 本身也能做為 SAP LT Replication Server 設定的目標。ODP 架構會將資料提供為與來源系統資料表相對應的 ODP 物件。
ODP 架構支援各種目標 SAP 應用程式 (稱為「訂閱者」) 的擷取和複製情境。訂閱端會從差異佇列擷取資料,以便進一步處理。
訂閱者透過 ODP context 要求資料來源的資料後,系統就會複製資料。多個訂閱者可以使用相同的 ODQ 做為來源。
SAP LT Replication Server 會運用 SAP Data Services 4.2 SP1 以上版本的變更資料擷取 (CDC) 支援功能,包括所有來源資料表的即時資料佈建和差異功能。
下圖說明系統中的資料流程:
- SAP 應用程式會更新來源系統中的資料。
- SAP SAP LT Replication Server 會複製資料變更,並將資料儲存在作業差異佇列中。
- SAP DS 是作業差異佇列的訂閱者,會定期輪詢佇列中的資料變更。
- SAP DS 會從差異佇列擷取資料,將資料轉換為與 BigQuery 格式相容的格式,並啟動負載工作,將資料移至 BigQuery。
- 您可以在 BigQuery 中使用這些資料進行分析。
在這種情況下,SAP 來源系統、SAP LT Replication Server 和 SAP Data Services 可以是執行在 Google Cloud上,也可以是執行在 Google Cloud外。如需 SAP 的更多資訊,請參閱「使用 SAP Landscape Transformation Replication Server 即時提供營運資料」。

核心解決方案元件
如要使用 SAP Landscape Transformation Replication Server 和 SAP Data Services,將資料從 SAP 應用程式複製到 BigQuery,必須具備下列元件:
| 元件 | 必要版本 | 附註 |
|---|---|---|
| SAP 應用程式伺服器堆疊 | 任何以 ABAP 為基礎的 SAP 系統,從 R/3 4.6C 開始 SAP_Basis (最低需求):
|
在本指南中,應用程式伺服器和資料庫伺服器統稱為「來源系統」,即使這兩者在不同機器上執行也一樣。 定義具有適當授權的 RFC 使用者 選用:定義記錄資料表的專屬資料表空間 |
| 資料庫 (DB) 系統 | 任何 SAP 產品供應情形對照表 (PAM) 中列為支援的資料庫版本,但須遵守 PAM 中列出的 SAP NetWeaver 堆疊限制。請參閱 service.sap.com/pam。 | |
| 作業系統 (OS) | 任何 SAP PAM 中列為支援的 OS 版本,須遵守 PAM 中列出的 SAP NetWeaver 堆疊限制。請參閱 service.sap.com/pam。 | |
| SAP 資料移轉伺服器 (DMIS) | DMIS:
|
|
| SAP Landscape Transformation Replication Server | SAP LT Replication Server 2.0 以上版本 | 需要與來源系統建立 RFC 連線。 SAP LT Replication Server 系統的大小,取決於 ODQ 中儲存的資料量和預定的保留期限。 |
| SAP Data Services | SAP Data Services 4.2 SP1 以上版本 | |
| BigQuery | 不適用 |
費用
BigQuery 是可計費的 Google Cloud 元件。
使用 Pricing Calculator 可根據您的預測使用量來產生預估費用。
事前準備
這些操作說明假設 SAP 應用程式伺服器、資料庫伺服器、SAP LT 複製伺服器和 SAP Data Services 已安裝並設定為正常運作。
您必須先建立 Google Cloud專案,才能使用 BigQuery。
在 Google Cloud中設定 Google Cloud 專案
您必須啟用 BigQuery API,如果還沒有建立Google Cloud 專案,也必須建立專案。
建立 Google Cloud 專案
前往 Google Cloud 控制台註冊,並完成設定精靈的步驟。
按一下左上角「 Google Cloud 」標誌旁的下拉式選單,然後選取「Create Project」。
為專案命名,然後點選「建立」。
專案建立完成後 (右上方會顯示通知),請重新整理頁面。
啟用 API
啟用 BigQuery API:
啟用 Google Cloud API 的私人存取權
對於在 Google Cloud外執行的 SAP 工作負載,您必須在建立與 Google Cloud的網路連線後,啟用對 Google Cloud API 的私人存取權。
詳情請參閱「各項服務的私人 Google 存取權選項」。
建立服務帳戶
服務帳戶 (特別是其金鑰檔案) 會用於驗證 SAP DS 與 BigQuery 之間的連線。您稍後會在建立目標資料儲存庫時使用此金鑰檔案。
前往 Google Cloud 控制台的「Service accounts」(服務帳戶) 頁面。
選取 Google Cloud 專案。
按一下「Create Service Account」(建立服務帳戶)。
輸入服務帳戶名稱。
按一下「建立並繼續」。
在「請選擇角色」清單中,選擇「BigQuery」>「BigQuery 資料編輯者」。
按一下 [Add another role] (新增其他角色)。
在「請選擇角色」清單中,選擇「BigQuery」>「BigQuery 工作使用者」。
按一下「繼續」。
視情況授予其他使用者服務帳戶的存取權。
按一下 [完成]。
在 Google Cloud 控制台的「Service accounts」頁面中,按一下您剛建立的服務帳戶電子郵件地址。
在服務帳戶名稱下方,按一下「金鑰」分頁標籤。
點選「Add Key」下拉式選單,然後選取「Create new key」。
請務必指定 JSON 金鑰類型。
按一下 [建立]。
將自動下載的金鑰檔案儲存到安全的位置。
設定 SAP 應用程式和 BigQuery 之間的複製作業
設定這個解決方案包含下列高階步驟:
- 設定 SAP LT Replication Server
- 設定 SAP Data Services
- 建立 SAP Data Services 和 BigQuery 之間的資料流
SAP Landscape Transformation Replication Server 設定
以下步驟會將 SAP LT Replication Server 設為作業資料佈建架構中的供應者,並建立作業差異佇列。在這種設定中,SAP LT Replication Server 會使用觸發事件為基礎的複製作業,將來源 SAP 系統中的資料複製到微調佇列中的資料表中。SAP Data Services 會在 ODP 架構中擔任訂閱者,從差異佇列中擷取資料、轉換資料,然後載入至 BigQuery。
設定作業差異資料佇列 (ODQ)
- 在 SAP LT Replication Server 中,使用交易
SM59為資料來源的 SAP 應用程式系統建立 RFC 目的地。 - 在 SAP LT Replication Server 中,使用交易
LTRC建立設定。在設定中定義 SAP LT 複寫伺服器的來源和目標。使用 ODP 進行資料轉移的目標是 SAP LT Replication Server 本身。- 如要指定來源,請輸入要用來做為資料來源的 SAP 應用程式系統 RFC 目的地。
- 如何指定目標:
- 輸入「NONE」做為 RFC 連線。
- 請選擇「ODQ 複製情境」做為 RFC 溝通內容。在這個情境中,請指定使用內含作業資料差異的作業資料佈建基礎架構來傳輸資料。
- 指派佇列別名。
佇列別名會用於 SAP Data Services,用於資料來源 ODP 內容設定。
SAP Data Services 設定
建立資料服務專案
- 開啟 SAP Data Services Designer 應用程式。
- 依序前往「File」>「New」>「Project」。
- 在「專案名稱」欄位中指定名稱。
- 在「資料服務存放區」中,選取資料服務存放區。
- 按一下「完成」。您的專案會顯示在左側的「Project Explorer」中。
SAP Data Services 會連線至來源系統收集中繼資料,然後連線至 SAP Replication Server 代理程式,擷取設定並變更資料。
建立來源資料儲存庫
下列步驟會建立與 SAP LT Replication Server 的連線,並將資料表新增至 Designer 物件程式庫中適用的資料儲存庫節點。
如要搭配使用 SAP LT Replication Server 和 SAP Data Services,您必須將資料儲存庫連結至 ODP 基礎架構,並將 SAP DataServices 連結至 ODP 中的正確作業差異佇列。
- 開啟 SAP Data Services Designer 應用程式。
- 在「Project Explorer」中,按一下 SAP Data Services 專案名稱的滑鼠右鍵。
- 依序選取「New」>「Datastore」。
- 填入「Datastore Name」。例如 DS_SLT。
- 在「Datastore type」欄位中,選取「SAP Applications」。
- 在「Application server name」欄位中,提供 SAP LT Replication Server 的執行個體名稱。
- 指定 SAP LT Replication Server 存取憑證。
- 按一下 [Advanced] (進階) 分頁標籤。
- 在 ODP 內容中輸入 SLT~ALIAS,其中別名是您在 設定作業 Delta 佇列 (ODQ) 中指定的佇列別名。
- 按一下 [確定]。
新的資料儲存庫會顯示在 Designer 中本機物件程式庫的「Datastore」Datastore分頁中。
建立目標資料儲存庫
這些步驟會建立 BigQuery 資料儲存庫,使用您先前在「建立服務帳戶」一節中建立的服務帳戶。服務帳戶可讓 SAP Data Services 安全存取 BigQuery。
詳情請參閱 SAP Data Services 說明文件中的「取得 Google 服務帳戶電子郵件」和「取得 Google 服務帳戶私密金鑰檔案」。
- 開啟 SAP Data Services Designer 應用程式。
- 在「Project Explorer」中,按一下 SAP Data Services 專案名稱的滑鼠右鍵。
- 依序選取「New」>「Datastore」。
- 填寫「名稱」欄位。例如 BQ_DS。
- 點選「下一步」。
- 在「Datastore type」(資料儲存庫類型) 欄位中,選取「Google BigQuery」。
- 系統會顯示「Web Service URL」選項。軟體會自動使用預設的 BigQuery 網路服務網址填入這個選項。
- 選取 [進階]。
- 根據 SAP Data Services 說明文件中 BigQuery 的Datastore 選項說明,填寫「進階」選項。
- 按一下 [確定]。
新的資料儲存庫會顯示在 Designer 本機物件程式庫的「Datastore」Datastore分頁中。
匯入來源 ODP 物件以進行複製
這些步驟會從來源資料儲存庫匯入 ODP 物件,以便進行初始和差異式載入作業,並在 SAP Data Services 中提供這些物件。
- 開啟 SAP Data Services Designer 應用程式。
- 在「Project Explorer」中展開複製負載的來源資料儲存庫。
- 選取右側面板上方的「外部中繼資料」選項。畫面上會顯示含有可用表格和 ODP 物件的節點清單。
- 按一下 ODP 物件節點,擷取可用 ODP 物件的清單。清單可能需要很長的時間才能顯示。
- 按一下「搜尋」按鈕。
- 在對話方塊中,選取「Look in」選單中的「External data」,然後選取「Object type」選單中的「ODP object」。
- 在「搜尋」對話方塊中,選取搜尋條件,篩選來源 ODP 物件清單。
- 從清單中選取要匯入的 ODP 物件。
- 按一下滑鼠右鍵,然後選取「匯入」選項。
- 填入「消費者姓名」。
- 填入「專案名稱」。
- 在擷取模式中選取「變更資料擷取 (CDC)」選項。
- 按一下 [匯入]。這會開始將 ODP 物件匯入資料服務。ODP 物件現已可在 DS_SLT 節點的物件程式庫中使用。
詳情請參閱 SAP Data Services 說明文件中的「匯入 ODP 來源中繼資料」。
建立結構定義檔案
這些步驟會在 SAP Data Services 中建立資料流,以產生反映來源資料表結構的結構定義檔。稍後您會使用結構定義檔案建立 BigQuery 資料表。
結構定義可確保 BigQuery 載入器資料流成功填入新的 BigQuery 資料表。
建立資料流程
- 開啟 SAP Data Services Designer 應用程式。
- 在「Project Explorer」中,按一下 SAP Data Services 專案名稱的滑鼠右鍵。
- 依序選取「Project」>「New」>「Data flow」。
- 填寫「名稱」欄位。例如 DF_BQ。
- 按一下「完成」。
重新整理物件程式庫
- 在 Project Explorer 中,以滑鼠右鍵按一下初始載入的來源資料儲存庫,然後選取「Refresh Object Library」選項。這會更新資料流程中可用的資料來源資料庫表格清單。
建立資料流程
- 將來源資料表拖曳至資料流程工作區,然後在系統提示時選擇「Import as Source」,即可建立資料流程。
- 在物件程式庫的「Transforms」分頁中,將「XML_Map」轉換從「Platform」節點 i 拖曳至資料流,並在系統提示時選擇「Batch Load」選項。
- 將工作區中的所有來源資料表連結至 XML 對應轉換作業。
- 開啟 XML 對應轉換,然後根據您在 BigQuery 資料表中納入的資料,完成輸入和輸出結構定義部分。
- 在「Schema Out」欄中,按一下「XML_Map」節點的滑鼠右鍵,然後從下拉式選單中選取「Generate Google BigQuery Schema」。
- 輸入結構定義的名稱和位置。
- 按一下 [儲存]。
- 在「Project Explorer」中,按一下資料流程的滑鼠右鍵,然後選取「Remove」。
SAP Data Services 會產生副檔名為 .json 的結構定義檔。
建立 BigQuery 資料表
您需要在Google Cloud 的 BigQuery 資料集中建立資料表,才能進行初始載入和差異載入。您會使用在 SAP Data Services 中建立的結構定義來建立資料表。
初始載入的資料表會用於初始複製整個來源資料集。差異載入表格會用於複製初始載入後,來源資料集中發生的變更。這些資料表是根據您在上一個步驟中產生的結構定義建立。差異載入作業的資料表包含額外的時間戳記欄位,可識別每個差異載入作業的時間。
建立 BigQuery 資料表以進行初始載入
這些步驟會在 BigQuery 資料集中建立初始載入的資料表。
- 在 Google Cloud 控制台中存取 Google Cloud 專案。
- 選取「BigQuery」。
- 按一下適用的資料集。
- 按一下「建立資料表」。
- 輸入資料表名稱。例如 BQ_INIT_LOAD。
- 在「結構定義」下方,切換設定以啟用「以文字形式編輯」模式。
- 在 建立結構定義檔案中,複製並貼上所建立的結構定義檔案內容,即可在 BigQuery 中設定新資料表的結構定義。
- 點選「建立資料表」。
建立差異載入作業的 BigQuery 資料表
這些步驟會為 BigQuery 資料集的差異載入作業建立資料表。
- 在 Google Cloud 控制台中存取 Google Cloud 專案。
- 選取「BigQuery」。
- 按一下適用的資料集。
- 按一下「建立資料表」。
- 輸入資料表名稱。例如 BQ_DELTA_LOAD。
- 在「結構定義」下方,切換設定以啟用「以文字形式編輯」模式。
- 在 建立結構定義檔案中,複製並貼上所建立的結構定義檔案內容,即可在 BigQuery 中設定新資料表的結構定義。
在結構定義檔案的 JSON 清單中,在 DI_SEQUENCE_NUMBER 欄位的欄位定義前方,新增下列 DL_TIMESTAMP 欄位定義。這個欄位會儲存每個差異載入執行作業的時間戳記):
{ "name": "DL_TIMESTAMP", "type": "TIMESTAMP", "mode": "REQUIRED", "description": "Delta load timestamp" },點選「建立資料表」。
設定 SAP Data Services 和 BigQuery 之間的資料流
如要設定資料流,您必須將 BigQuery 資料表匯入 SAP Data Services 做為外部中繼資料,並建立複製工作和 BigQuery 載入器資料流。
匯入 BigQuery 資料表
這些步驟會匯入您在前一個步驟中建立的 BigQuery 資料表,並在 SAP Data Services 中提供這些資料表。
- 在 SAP Data Services Designer 物件程式庫中,開啟先前建立的 BigQuery 資料儲存庫。
- 在右側面板的頂端,選取「外部結構定義資料」。系統會顯示您建立的 BigQuery 資料表。
- 在適用的 BigQuery 資料表名稱上按一下滑鼠右鍵,然後選取「Import」。
- 系統開始將所選資料表匯入 SAP Data Services。該資料表現在已在目標資料儲存庫節點下的物件程式庫中提供。
建立複製工作和 BigQuery 載入器資料流
這些步驟會在 SAP Data Services 中建立複製工作和資料流,用於將資料從 SAP LT Replication Server 載入至 BigQuery 資料表。
資料流程包含兩個部分。第一個會執行從來源 ODP 物件到 BigQuery 資料表的初始資料載入作業,第二個則會啟用後續的差異載入作業。
建立全域變數
為了讓複製工作能夠判斷要執行初始載入作業還是差異載入作業,您需要建立全域變數,以便在資料流程邏輯中追蹤載入類型。
- 在 SAP Data Services Designer 應用程式選單中,依序前往「工具」 >「變數」。
- 在「全域變數」上按一下滑鼠右鍵,然後選取「插入」。
- 在變數「Name」 上按一下滑鼠右鍵,然後選取「Properties」。
- 在變數「Name」中輸入 $INITLOAD。
- 在「資料類型」中,選取「Int」。
- 在「Value」欄位中輸入 0。
- 按一下 [確定]。
建立複製作業
- 在「Project Explorer」中,按一下專案名稱的滑鼠右鍵。
- 依序選取「New」 >「Batch Job」
- 填入「名稱」欄位。例如 JOB_SRS_DS_BQ_REPLICATION。
- 按一下「完成」。
建立初始載入的資料流邏輯
建立條件
- 在「工作名稱」上按一下滑鼠右鍵,然後依序選取「新增」 >「條件式」。
- 在條件式規則圖示上按一下滑鼠右鍵,然後選取「重新命名」。
將名稱變更為「InitialOrDelta」InitialOrDelta。

按兩下條件式規則圖示,開啟條件式規則編輯器。
在「If 陳述式」欄位中輸入 $INITLOAD = 1,即可設定執行初始載入作業的條件。
在「Then」窗格中按一下滑鼠右鍵,然後依序選取「Add New」 >「Script」。
在「Script」圖示上按一下滑鼠右鍵,然後選取「Rename」。
變更名稱。舉例來說,這些操作說明會使用 InitialLoadCDCMarker。
按兩下「Script」圖示,即可開啟「Function」編輯器。
輸入
print('Beginning Initial Load');人數輸入
begin_initial_load();人數
按一下應用程式工具列中的「返回」圖示,退出函式編輯器。
建立初始載入的資料流
- 在「Then」窗格中按一下滑鼠右鍵,然後依序選取「Add New」 >「Data Flow」。
- 重新命名資料流程。例如 DF_SRS_DS_InitialLoad。
- 按一下 InitialLoadCDCMarker 的連線輸出圖示,然後將連線線拖曳至 DF_SRS_DS_InitialLoad 的輸入圖示,即可將 InitialLoadCDCMarker 連結至 DF_SRS_DS_InitialLoad。
- 按兩下 DF_SRS_DS_InitialLoad 資料流。
匯入資料流並連結至來源資料儲存庫物件
- 從資料儲存庫中,將來源 ODP 物件拖曳至資料流程工作區。在這些操作說明中,資料儲存庫的名稱為 DS_SLT。您的資料儲存庫名稱可能不同。
- 將「查詢轉換」從物件程式庫的「轉換」分頁中的「平台」節點拖曳至資料流。
在 ODP 物件上按兩下滑鼠,然後在「Source」分頁中,將「Initial Load」選項設為「Yes」。

將工作區中的所有來源 ODP 物件連結至查詢轉換。
按兩下「查詢轉換」。
選取左側「Schema In」下方的所有資料表欄位,然後將它們拖曳至右側的「Schema Out」。
如要為日期時間欄位新增轉換函式,請按照下列步驟操作:
- 在右側的「Schema Out」清單中選取日期時間欄位。
- 選取結構定義清單下方的「對應」分頁標籤。
將欄位名稱替換為下列函式:
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')其中 FIELDNAME 是您選取的欄位名稱。
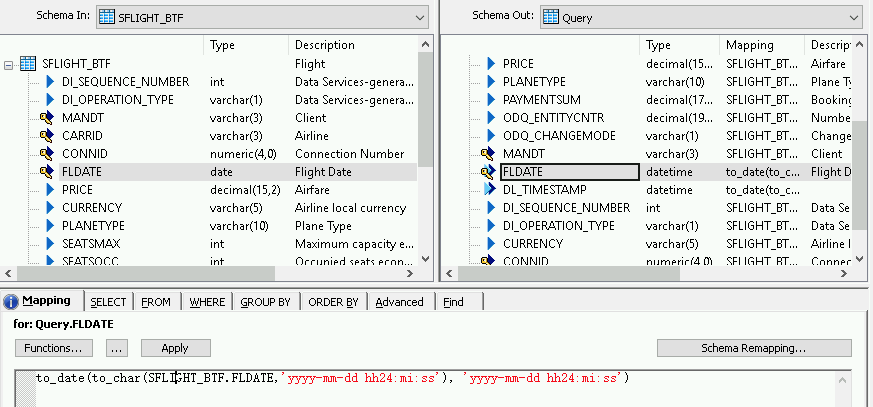
按一下應用程式工具列中的「返回」圖示,即可返回資料流程。
匯入資料流並與目標資料儲存庫物件連結
- 從物件程式庫中的資料儲存庫,將匯入的 BigQuery 資料表拖曳至初始載入資料流。這些操作說明中的資料儲存庫名稱為 BQ_DS。您的資料儲存庫名稱可能不同。
- 從物件程式庫的「Transforms」分頁標籤中的「Platform」節點,將「XML_Map」轉換作業拖曳至資料流。
- 在對話方塊中選取「批次模式」。
- 將「查詢」轉換連結至「XML_Map」轉換。
將 XML_Map 轉換連結至匯入的 BigQuery 資料表。
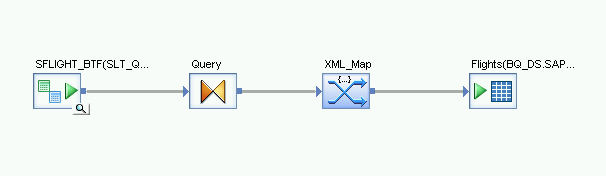
開啟 XML_Map 轉換,並根據您在 BigQuery 資料表中納入的資料,完成輸入和輸出結構定義部分。
在工作區中雙擊 BigQuery 資料表,然後按照下表所示完成「Target」分頁中的選項:
| 選項 | 說明 |
|---|---|
| Make Port | 指定預設值「否」。 指定「是」會將來源或目標檔案設為嵌入式資料流程埠。 |
| 眾數 | 針對初始載入作業指定「Truncate」,這樣 BigQuery 表格中的任何現有記錄都會替換為 SAP Data Services 載入的資料。預設為「Truncate」。 |
| 載入器數量 | 指定正整數,設定用於處理的載入器 (執行緒) 數量。預設值為 4。
每個載入器會在 BigQuery 中啟動一個可暫停的載入工作。您可以指定任意數量的載入器。 如要瞭解如何判斷適當的載入器數量,請參閱 SAP 說明文件,包括: |
| 每個載入器的失敗記錄數量上限 | 指定 0 或正整數,設定每個載入工作在 BigQuery 停止載入記錄前,可失敗的記錄數量上限。預設值為零 (0)。 |
- 按一下頂端工具列中的「驗證」圖示。
- 按一下應用程式工具列中的「返回」圖示,即可返回「條件」編輯器。
建立差異載入作業的資料流
您需要建立資料流,以便複製初始載入後累積的變更資料擷取記錄。
建立條件差異流程:
- 按兩下「InitialOrDelta」InitialOrDelta條件式。
- 在「Else」部分按一下滑鼠右鍵,然後依序選取「Add New」 >「Script」。
- 重新命名指令碼。例如 MarkBeginCDCLoad。
- 按兩下「指令碼」圖示,開啟「函式」編輯器。
輸入 print('Beginning Delta Load');

按一下應用程式工具列中的「返回」圖示,即可返回「條件編輯器」。
建立差異載入作業的資料流
- 在「條件式編輯器」中,按一下滑鼠右鍵,然後依序選取「Add New」 >「Data Flow」。
- 重新命名資料流程。例如 DF_SRS_DS_DeltaLoad。
- 如下圖所示,將 MarkBeginCDCLoad 連結至 DF_SRS_DS_DeltaLoad。
按兩下 DF_SRS_DS_DeltaLoad 資料流。
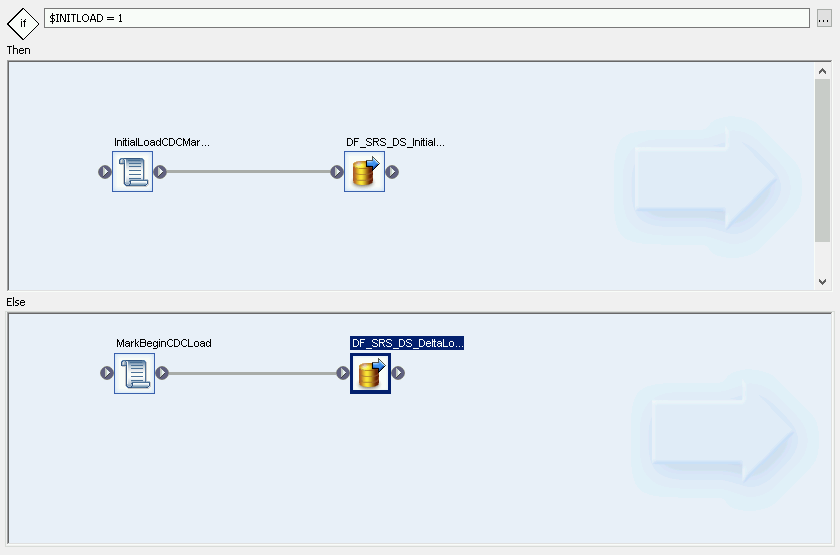
匯入資料流並連結至來源資料儲存庫物件
- 將來源 ODP 物件從資料儲存庫拖曳至資料流程工作區。這些操作說明中的資料儲存庫使用 DS_SLT 這個名稱。您的資料儲存庫名稱可能不同。
- 從物件程式庫的「轉換」分頁中的「平台」節點,將「查詢」轉換作業拖曳至資料流。
- 請按兩下 ODP 物件,然後在「Source」分頁中,將「Initial Load」選項設為「No」。
- 將工作區中的所有來源 ODP 物件連結至「查詢」轉換。
- 按兩下「查詢」轉換。
- 選取左側「Schema In」清單中的所有表格欄位,然後拖曳至右側的「Schema Out」清單
啟用差異載入作業的時間戳記
下列步驟可讓 SAP Data Services 自動記錄每個差異載入執行作業的時間戳記,並儲存在差異載入表格的欄位中。
- 在右側的「Schema Out」窗格中,按一下「Query」節點的滑鼠右鍵。
- 選取「新增輸出資料欄」。
- 在「名稱」中輸入 DL_TIMESTAMP。
- 在「資料類型」中選取「日期時間」。
- 按一下 [確定]。
- 按一下新建立的 DL_TIMESTAMP 欄位。
- 前往下方的「對應」分頁
輸入以下函式:
- to_date(to_char(sysdate(),'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')

匯入資料流並連結至目標資料儲存庫物件
- 從物件程式庫中的資料儲存庫,將匯入的 BigQuery 資料表拖曳至 XML_Map 轉換後的資料流工作區,用於差異載入。這些操作說明會使用範例資料儲存庫名稱 BQ_DS。您的資料儲存庫名稱可能不同。
- 從物件程式庫的「Transforms」分頁標籤中的「Platform」節點,將「XML_Map」轉換作業拖曳至資料流。
- 將「查詢」轉換連結至「XML_Map」轉換。
將 XML_Map 轉換連結至匯入的 BigQuery 資料表。
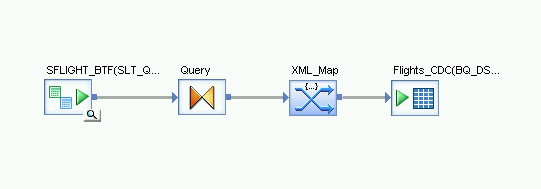
開啟 XML_Map 轉換,並根據您在 BigQuery 資料表中納入的資料,完成輸入和輸出結構定義部分。
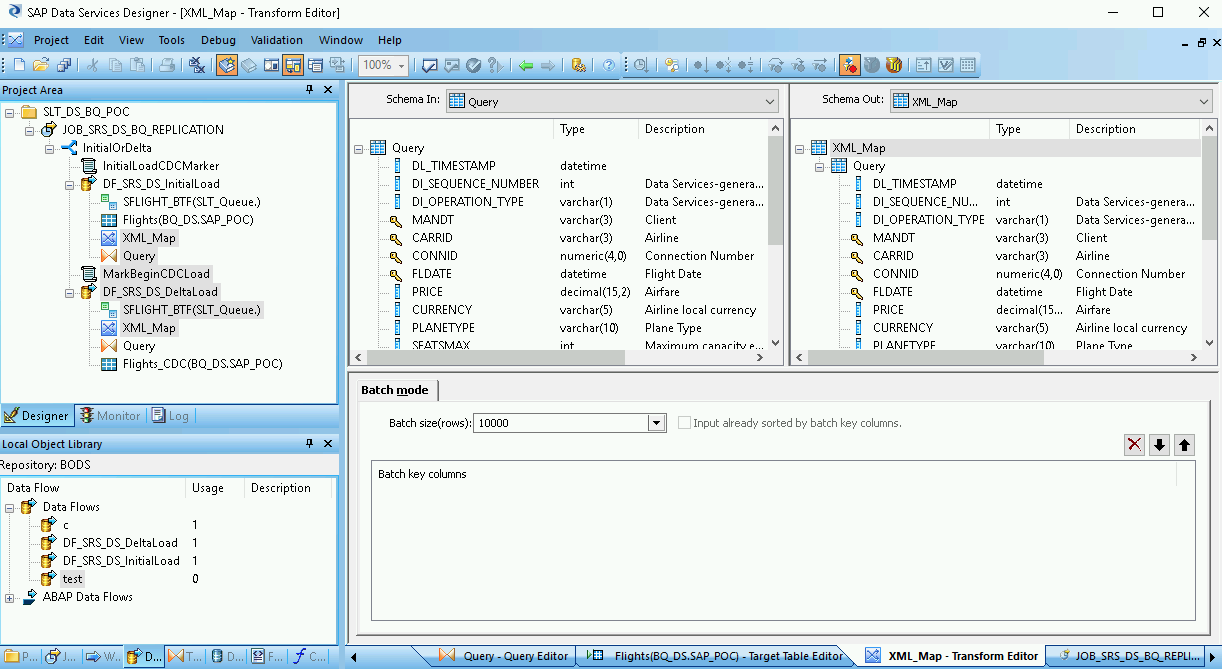
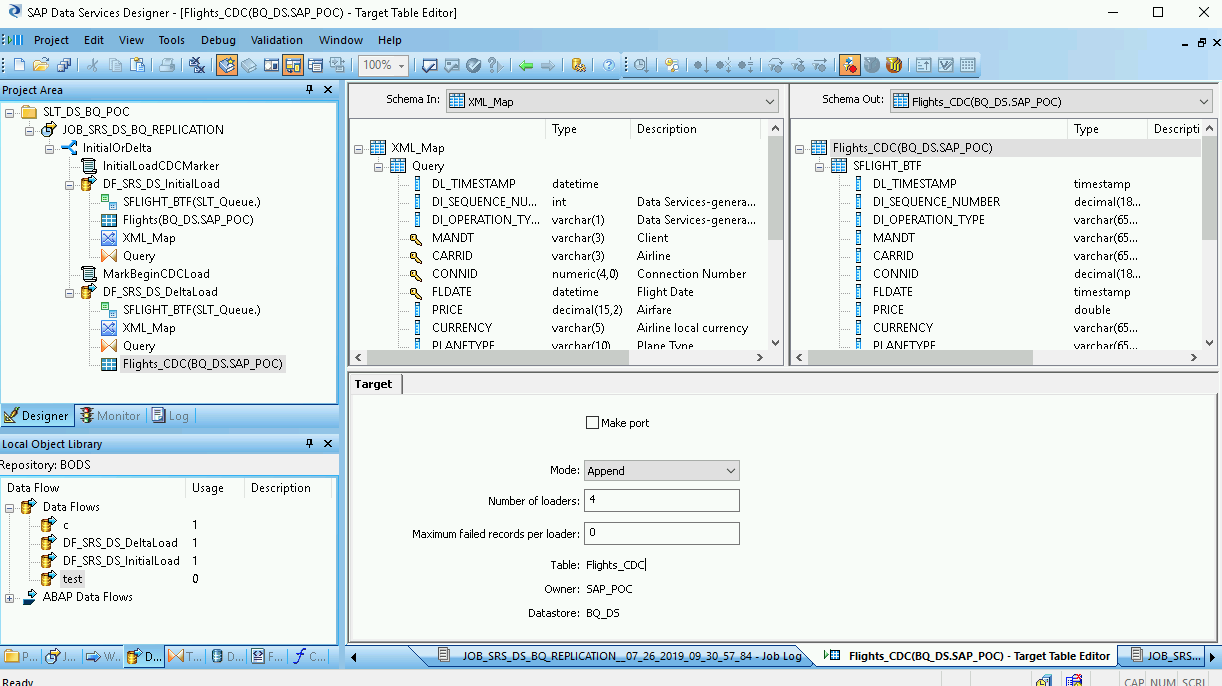
在工作區中雙擊 BigQuery 資料表來開啟資料表,然後根據下列說明完成「Target」分頁中的選項:
| 選項 | 說明 |
|---|---|
| Make Port | 指定預設值「否」。 如果指定「是」,來源或目標檔案就會成為嵌入式資料流程埠。 |
| 眾數 | 針對差異載入作業指定「附加」,這樣當從 SAP Data Services 載入新記錄時,就會保留 BigQuery 資料表中的現有記錄。 |
| 載入器數量 | 指定正整數,設定用於處理的載入器 (執行緒) 數量。 每個載入器會在 BigQuery 中啟動一個可暫停的載入工作。您可以指定任意數量的載入器。一般來說,增量載入作業所需的載入器比初始載入作業少。 如要瞭解如何決定適當的載入器數量,請參閱 SAP 說明文件,包括: |
| 每個載入器的失敗記錄上限 | 指定 0 或正整數,設定每個載入工作在 BigQuery 停止載入記錄前,可失敗的記錄數量上限。預設值為零 (0)。 |
- 按一下頂端工具列中的「驗證」圖示。
- 按一下應用程式工具列中的「返回」圖示,返回「Conditional」編輯器。
將資料載入 BigQuery
初始載入和差異載入的步驟類似。針對每個工作,您可以啟動複製工作,並在 SAP Data Services 中執行資料流程,將資料從 SAP LT Replication Server 載入至 BigQuery。這兩種載入程序之間的重要差異在於 $INITLOAD 全域變數的值。對於初始載入,$INITLOAD 必須設為 1。對於 Delta 載入作業,$INITLOAD 必須為 0。
執行初始載入
執行初始載入作業時,來源資料集中的所有資料都會複製到與初始載入資料流程連結的目標 BigQuery 表格。目標資料表中的所有資料都會遭到覆寫。
- 在 SAP Data Services Designer 中,開啟「Project Explorer」。
- 在複寫工作名稱上按一下滑鼠右鍵,然後選取「執行」。畫面上會顯示對話方塊。
- 在對話方塊中,前往「Global Variable」分頁,然後將
$INITLOAD的值變更為 1,以便先執行初始載入作業。 - 按一下 [確定]。載入程序開始,並在 SAP Data Services 記錄檔中顯示偵錯訊息。系統會將資料載入您在 BigQuery 中建立的初始載入資料表。這些操作說明中的初始載入資料表名稱為 BQ_INIT_LOAD。您的資料表名稱可能不同。
- 如要查看是否已完成載入作業,請前往 Google Cloud 控制台,然後開啟包含資料表的 BigQuery 資料集。如果資料仍在載入中,資料表名稱旁會顯示「Loading」。
載入完成後,資料即可在 BigQuery 中處理。
從這時起,來源資料表中的所有變更都會記錄在 SAP LT 複製伺服器的差異佇列中。如要將資料從差異佇列載入至 BigQuery,請執行差異載入工作。
執行差異載入
執行差異載入作業時,系統只會將來源資料集中自上次載入作業以來發生的變更複製到與差異載入資料流程連結的目標 BigQuery 資料表。
- 在工作名稱上按一下滑鼠右鍵,然後選取「執行」。
- 按一下 [確定]。載入程序開始,SAP Data Services 記錄檔中開始顯示偵錯訊息。資料會載入您在 BigQuery 中為差異載入作業建立的資料表。在這些操作說明中,差異載入資料表的名稱為 BQ_DELTA_LOAD。您的資料表名稱可能不同。
- 如要查看是否已完成載入作業,請前往 Google Cloud 控制台,然後開啟包含資料表的 BigQuery 資料集。如果資料仍在載入中,資料表名稱旁會顯示「Loading」。
- 載入完成後,資料即可在 BigQuery 中處理。
為追蹤來源資料的變更,SAP LT Replication Server 會在 DI_SEQUENCE_NUMBER 欄中記錄變更資料作業的順序,並在 DI_OPERATION_TYPE 欄中記錄變更資料作業的類型 (D=刪除、U=更新、I=插入)。SAP LT Replication Server 會將資料儲存在差異佇列資料表的資料欄中,並從中複製至 BigQuery。
排定差異載入作業
您可以使用 SAP Data Services 管理控制台,安排以定期間隔執行差異載入工作。
- 開啟 SAP Data Services Management Console 應用程式。
- 按一下「管理員」。
- 展開左側選單樹狀結構中的「Batch」節點。
- 按一下 SAP Data Services 存放區的名稱。
- 按一下「大量工作設定」分頁標籤。
- 按一下「新增時間表」。
- 填入「排程名稱」。
- 勾選「已啟用」。
- 在「Select scheduled time for executing the jobs」(選取執行工作排程時間) 部分,指定差異負載執行的頻率。
- 重要事項: Google Cloud 會限制您每天可以執行的 BigQuery 載入工作數量。請確認您的排程未超過上限,且無法提高。如要進一步瞭解 BigQuery 載入工作限制,請參閱 BigQuery 說明文件中的「配額與限制」。
- 展開「全域變數」,然後確認 $INITLOAD 是否設為 0。
- 按一下「套用」。

後續步驟
在 BigQuery 中查詢及分析複製的資料。
如要進一步瞭解查詢,請參閱:
- 請參閱 BigQuery 說明文件中的查詢 BigQuery 資料總覽。
如要瞭解如何在 BigQuery 中大規模合併初始和差異載入資料,請參閱:
- 在 BigQuery 中執行大規模變異解決方案,請參閱 Google Cloud 部落格文章。
- BigQuery 說明文件中的資料操縱語言。
探索 Google Cloud 的參考架構、圖表和最佳做法。歡迎瀏覽我們的雲端架構中心。