安排查詢
本頁面說明如何在 BigQuery 中排定週期性的查詢。
您可以為查詢進行排程,讓查詢週期性執行。排程查詢必須以 GoogleSQL 編寫,以納入資料定義語言 (DDL) 和資料操縱語言 (DML) 陳述式。您可以將查詢字串和目的地資料表參數化,依日期和時間整理查詢結果。
建立或更新查詢的排程時,系統會將查詢的排程時間從當地時間轉換為世界標準時間。世界標準時間不受日光節約時間影響。
事前準備
- 排程查詢會使用 BigQuery 資料移轉服務的功能。請確認您已完成「啟用 BigQuery 資料移轉服務」一文中的所有必要動作。
- 授予 Identity and Access Management (IAM) 角色,讓使用者擁有執行本文中各項工作所需的權限。
- 如果您打算指定客戶管理的加密金鑰 (CMEK),請確保服務帳戶具有加密和解密權限,且您擁有使用 CMEK 時所需的 Cloud KMS 金鑰資源 ID。如要瞭解 CMEK 如何與 BigQuery 資料移轉服務搭配運作,請參閱指定排定查詢的加密金鑰。
所需權限
如要排定查詢時間,您需要下列 IAM 權限:
如要建立轉移作業,您必須具備
bigquery.transfers.update和bigquery.datasets.get權限,或是bigquery.jobs.create、bigquery.transfers.get和bigquery.datasets.get權限。如要執行排程查詢,必須具備下列條件:
- 目標資料集的
bigquery.datasets.get權限 bigquery.jobs.create
- 目標資料集的
如要修改或刪除已排定的查詢,您必須具備 bigquery.transfers.update 和 bigquery.transfers.get 權限,或是 bigquery.jobs.create 權限和已排定查詢的擁有權。
預先定義的 BigQuery 管理員 (roles/bigquery.admin) IAM 角色包含排定或修改查詢所需的權限。
如要進一步瞭解 BigQuery 中的 IAM 角色,請參閱預先定義的角色與權限一文。
如要建立或更新由服務帳戶執行的排程查詢,您必須有該服務帳戶的存取權。如要進一步瞭解如何授予使用者服務帳戶角色,請參閱服務帳戶使用者角色。如要在Google Cloud 控制台的排定查詢使用者介面中選取服務帳戶,您必須具備下列 IAM 權限:
iam.serviceAccounts.list列出服務帳戶。iam.serviceAccountUser,將服務帳戶指派給排程查詢。
設定選項
以下各節說明設定選項。
查詢字串
查詢字串必須有效,且必須以 GoogleSQL 編寫。排程查詢每次執行時,都會收到下列查詢參數。
如要在為查詢進行排程之前,手動以 @run_time 和 @run_date 參數測試查詢字串,請使用 bq 指令列工具。
可用的參數
| 參數 | GoogleSQL 類型 | 值 |
|---|---|---|
@run_time |
TIMESTAMP |
以世界標準時間表示。對於具有定期執行排程的查詢,run_time 用以表示預定的執行時間。舉例來說,如果排程查詢的時程設定為「every 24 hours」(每 24 小時),則連續兩次查詢之間的 run_time 差異就是 24 小時整 (雖然實際執行時間可能會略有不同)。 |
@run_date |
DATE |
代表邏輯日曆日期。 |
範例
在以下範例中,系統會查詢名為 hacker_news.stories 的公開資料集,而 @run_time 參數是該查詢字串的一部分。
SELECT @run_time AS time, title, author, text FROM `bigquery-public-data.hacker_news.stories` LIMIT 1000
目標資料表
設定排程查詢時,如果查詢結果的目的地資料表不存在,BigQuery 會嘗試建立目的地資料表。
如使用 DDL 或 DML 查詢,請在 Google Cloud 控制台中選擇「Processing location」(處理位置) 或地區。DDL 或 DML 查詢需有處理位置,才能建立目的地資料表。
如果目的地資料表存在,且您使用 WRITE_APPEND
寫入偏好設定,BigQuery 會將資料附加至目的地資料表,並嘗試對應結構定義。BigQuery 會自動允許新增及重新排序欄位,並容許缺少選填欄位。如果資料表結構定義在執行期間的變更幅度過大,導致 BigQuery 無法自動處理變更,排定時程的查詢就會失敗。
查詢可參照來自不同專案和不同資料集的資料表。設定排程查詢時,資料表名稱不需要包含目的地資料集。目的地資料集會另外指定。
排程查詢的目的地資料集和資料表必須與排程查詢位於同一個專案。
寫入偏好設定
您選取的寫入偏好設定,會決定查詢結果寫入現有目的地資料表的方式。
WRITE_TRUNCATE:如果資料表存在,BigQuery 會覆寫資料表資料。WRITE_APPEND:如果資料表存在,BigQuery 會將資料附加至資料表。
如果使用 DDL 或 DML 查詢,就無法使用寫入偏好設定選項。
唯有 BigQuery 成功完成查詢,才能建立、截斷或附加目的地資料表。建立、截斷或附加的動作是在工作完成時,以一次完整更新的形式進行。
分群
如果資料表是使用 DDL 陳述式 CREATE TABLE AS SELECT 建立,排程查詢只能在新資料表上建立叢集。請參閱「使用資料定義語言陳述式」頁面中的「從查詢結果建立叢集資料表」一節。
分區選項
排程查詢可建立分區或非分區的目的地資料表。分區功能適用於 Google Cloud 主控台、bq 指令列工具和 API 設定方法。如要使用具有分區功能的 DDL 或 DML 查詢,請將「目標資料表分區欄位」留白。
您可以在 BigQuery 中使用下列類型的資料表分區:
- 整數範圍分區:根據特定
INTEGER資料欄中的值範圍分區的資料表。 - 依時間單位資料欄分區:依據
TIMESTAMP、DATE或DATETIME資料欄分區的資料表。 - 擷取時間分區:根據擷取時間分區的資料表。BigQuery 會根據資料擷取時間,自動將資料列指派給分區。
如要在Google Cloud 控制台使用排程查詢建立分區資料表,請使用下列選項:
如要使用整數範圍分區,請將「目的地資料表分區欄位」留空。
如要使用時間單位資料欄分區,請在設定排定的查詢時,於「目的地資料表分區欄位」中指定資料欄名稱。
如要使用擷取時間分區,請將「目的地資料表分區欄位」留空,並在目的地資料表的名稱中指定日期分區。例如:
mytable${run_date}。詳情請參閱「參數範本語法」。
可用的參數
設定排定的查詢時,可使用執行階段參數,指定要以何種方式對目的地資料表進行分區。
| 參數 | 範本類型 | 值 |
|---|---|---|
run_time |
格式化的時間戳記 | 採用世界標準時間,依排程而定。對於具有定期執行排程的查詢,run_time 用以表示預定的執行時間。舉例來說,如果排程查詢的時程設定為「every 24 hours」(每 24 小時),則連續兩次查詢之間的 run_time 差異就是 24 小時整 (雖然實際執行時間可能會略有不同)。請參閱 TransferRun.runTime 的說明。 |
run_date |
日期字串 | run_time 參數的日期,採用以下格式:%Y-%m-%d;例如 2018-01-01。這個格式與擷取時間分區資料表相容。 |
範本系統
可使用範本語法讓排定的查詢支援目的地資料表名稱中的執行階段參數。
參數範本語法
範本語法支援基本字串範本和時區設定。參數會以下列格式參照:
{run_date}{run_time[+\-offset]|"time_format"}
| 參數 | Purpose |
|---|---|
run_date |
這個參數會由格式為 YYYYMMDD 的日期取代。 |
run_time |
這個參數支援下列屬性:
|
- run_time、offset 和 time_format 之間不得有空格字元。
- 如果字串要包含大括號,可以按以下方式加以逸出:
'\{' and '\}'。 - 如果 time_format 要包含引號或分隔號,例如
"YYYY|MM|DD",可以在格式字串按以下方式加以逸出:'\"'或'\|'。
參數範本範例
以下範例說明如何以不同的時間格式指定目的地資料表名稱,以及如何設定執行時間時區。| run_time (UTC) | 範本參數 | 輸出目的地資料表名稱 |
|---|---|---|
| 2018-02-15 00:00:00 | mytable |
mytable |
| 2018-02-15 00:00:00 | mytable_{run_time|"%Y%m%d"} |
mytable_20180215 |
| 2018-02-15 00:00:00 | mytable_{run_time+25h|"%Y%m%d"} |
mytable_20180216 |
| 2018-02-15 00:00:00 | mytable_{run_time-1h|"%Y%m%d"} |
mytable_20180214 |
| 2018-02-15 00:00:00 | mytable_{run_time+1.5h|"%Y%m%d%H"}或 mytable_{run_time+90m|"%Y%m%d%H"} |
mytable_2018021501 |
| 2018-02-15 00:00:00 | {run_time+97s|"%Y%m%d"}_mytable_{run_time+97s|"%H%M%S"} |
20180215_mytable_000137 |
使用服務帳戶
您可以將排程查詢設定為以服務帳戶身分進行驗證。服務帳戶是與 Google Cloud 專案相關聯的特殊帳戶。服務帳戶可以執行工作 (例如排程查詢或批次處理管道),使用的憑證是自己的服務憑證,而非使用者憑證。
如要進一步瞭解如何透過服務帳戶進行驗證,請參閱驗證功能簡介一文。
您可以設定排程查詢,透過服務帳戶進行驗證。如果使用聯合身分登入,您必須擁有服務帳戶才能建立移轉作業。如果以 Google 帳戶登入,則不一定要透過服務帳戶建立移轉作業。
您可以使用 bq 指令列工具或 Google Cloud 控制台,透過服務帳戶的憑證來更新現有排程查詢。詳情請參閱「更新排程查詢憑證」。
使用排定的查詢指定加密金鑰
您可以指定客戶自行管理的加密金鑰 (CMEK),為轉移作業加密資料。您可以使用 CMEK 支援從已排定的查詢進行轉移。指定移轉作業的 CMEK 時,BigQuery 資料移轉服務會將 CMEK 套用至所有已擷取資料的中間磁碟快取,確保整個資料移轉工作流程符合 CMEK 規定。
如果轉移作業最初並非使用 CMEK 建立,您就無法更新現有轉移作業來新增 CMEK。舉例來說,您無法將原本預設加密的目的地資料表,變更為使用 CMEK 加密。反之,您也無法將 CMEK 加密的目的地資料表變更為其他類型的加密。
如果移轉設定最初是使用 CMEK 加密建立,您可以更新移轉的 CMEK。更新移轉作業設定的 CMEK 時,BigQuery 資料移轉服務會在下次執行移轉作業時,將 CMEK 傳播至目的地資料表。屆時,BigQuery 資料移轉服務會在移轉作業執行期間,以新的 CMEK 取代任何過時的 CMEK。詳情請參閱「更新轉移作業」。
您也可以使用專案預設鍵。 使用移轉作業指定專案預設金鑰時,BigQuery 資料移轉服務會將專案預設金鑰做為任何新移轉作業設定的預設金鑰。
設定排程查詢
如要瞭解排程語法,請參閱「排程格式」。如要瞭解時間表語法詳情,請參閱資源:TransferConfig。
主控台
在 Google Cloud 控制台中開啟 BigQuery 頁面。
執行您有興趣的查詢。如您對查詢結果感到滿意,請按一下「排定」。
排程查詢的選項會在「New scheduled query」(新增排程查詢) 窗格中開啟。

請在「New scheduled query」(新增排程查詢) 窗格中進行以下操作:
- 針對「Name for the scheduled query」(已排定查詢的名稱),請輸入名稱,例如
My scheduled query。排定的查詢名稱可以是任何值,方便您日後在必要時進行修改。 選用:根據預設,查詢會排定為每日執行。如要變更預設時間表,請從「重複」下拉式選單中選取所需選項:
- 針對「Name for the scheduled query」(已排定查詢的名稱),請輸入名稱,例如
如果是 GoogleSQL
SELECT查詢,請選取「為查詢結果設定目的地資料表」選項,然後提供目的地資料集的下列資訊。- 在「Dataset name」(資料集名稱) 部分選擇適當的目的地資料集。
- 在「Table name」(資料表名稱) 部分,輸入目的地資料表的名稱。
針對「Destination table write preference」(目標資料表寫入偏好設定),請選擇「Append to table」(附加到資料表中) 將資料附加至資料表,或是選擇「Overwrite table」(覆寫資料表) 覆寫目標資料表。

選擇「位置類型」。
如果已啟用查詢結果的目的地資料表,可以選取「自動選取位置」,自動選取目的地資料表所在位置。
否則,請選擇要查詢的資料所在位置。
進階選項:
選用步驟:CMEK 如使用客戶管理的加密金鑰,您可以在「Advanced options」(進階選項) 下方選取「Customer-managed key」(客戶管理的金鑰)。畫面隨即會列出可用的 CMEK 供您選擇。如要瞭解客戶管理的加密金鑰 (CMEK) 如何與 BigQuery 資料移轉服務搭配運作,請參閱指定排定查詢的加密金鑰。
以服務帳戶身分進行驗證 如果您的 Google Cloud 專案有一或多個相關聯的服務帳戶,您可以將服務帳戶與排程查詢建立關聯,而不使用使用者憑證。按一下「排定查詢憑證」下方的選單,即可查看可用的服務帳戶清單。如果您以聯合身分登入,則必須使用服務帳戶。

其他設定:
選用:勾選「Send email notifications」(傳送電子郵件通知),讓系統在移轉執行失敗時,寄送電子郵件通知。
選擇性:針對「Pub/Sub topic」(Pub/Sub 主題),請輸入您的 Pub/Sub 主題名稱,例如:
projects/myproject/topics/mytopic。
按一下 [儲存]。

bq
選項 1:使用 bq query 指令。
如要建立排程查詢,請將 destination_table (或 target_dataset)、--schedule 和 --display_name 選項加到 bq query 指令。
bq query \ --display_name=name \ --destination_table=table \ --schedule=interval
更改下列內容:
name. 排定查詢的顯示名稱。 顯示名稱可以是任何值,方便您日後在必要時修改查詢。table。查詢結果的目的地資料表。- 與 DDL 和 DML 查詢搭配使用時,
--target_dataset是命名查詢結果目標資料集的另一種方式。 --destination_table或--target_dataset請擇一使用,不能兩者同時使用。
- 與 DDL 和 DML 查詢搭配使用時,
interval。與bq query搭配使用時,可將查詢設為具有週期性排程的查詢。您必須排定查詢的執行頻率。如要瞭解有效時間表 (包括自訂間隔),請參閱「資源:TransferConfig」下方的schedule欄位。 示例:--schedule='every 24 hours'--schedule='every 3 hours'--schedule='every monday 09:00'--schedule='1st sunday of sep,oct,nov 00:00'
選用標記:
--project_id是您的專案 ID。如果未指定--project_id,系統會使用預設專案。--replace會在每次執行排程查詢後,以查詢結果覆寫目的地資料表。系統會清除所有現有資料。如果是未分區的資料表,結構定義也會一併清除。--append_table會將結果附加到目的地資料表。如為 DDL 和 DML 查詢,您亦可加上
--location旗標,指定特定的處理地區。如未指定--location,則會使用最近的 Google Cloud 位置。
舉例來說,下列指令會使用查詢 SELECT 1 from mydataset.test 建立名為 My Scheduled Query 的排程查詢。目的地資料表為資料集 mydataset 中的 mytable。排程查詢會在預設的專案內建立:
bq query \
--use_legacy_sql=false \
--destination_table=mydataset.mytable \
--display_name='My Scheduled Query' \
--schedule='every 24 hours' \
--replace=true \
'SELECT
1
FROM
mydataset.test'
選項 2:使用 bq mk 指令。
排程查詢是一種移轉作業。如要為查詢進行排程,可使用 bq 指令列工具建立移轉作業設定。
查詢必須使用 StandardSQL 方言才能進行排程。
輸入 bq mk 指令並加上下列必要旗標:
--transfer_config--data_source--target_dataset(DDL 和 DML 查詢為選用)--display_name--params
選用標記:
--project_id是您的專案 ID。如果未指定--project_id,系統會使用預設專案。--schedule是您希望查詢執行的頻率。如未指定--schedule,預設設定為依建立時間計算「every 24 hours」(每 24 小時)。如為 DDL 和 DML 查詢,您亦可加上
--location旗標,指定特定的處理地區。如未指定--location,則會使用最近的 Google Cloud 位置。--service_account_name是用於透過服務帳戶 (而非個別使用者帳戶) 來驗證排程查詢。--destination_kms_key:如果您使用客戶代管加密金鑰 (CMEK) 進行這項轉移作業,請指定金鑰的金鑰資源 ID。如要瞭解 CMEK 如何與 BigQuery 資料移轉服務搭配運作,請參閱指定排定查詢的加密金鑰。
bq mk \ --transfer_config \ --target_dataset=dataset \ --display_name=name \ --params='parameters' \ --data_source=data_source
更改下列內容:
dataset。移轉設定的目標資料集。- 此參數對 DDL 和 DML 查詢而言為選用,是其他所有查詢的必要參數。
name. 移轉設定的顯示名稱。顯示名稱可以是任何值,方便您日後在必要時修改查詢。parameters。含有已建立移轉設定的 JSON 格式參數。例如:--params='{"param":"param_value"}'。- 針對排程查詢,您必須提供
query參數。 destination_table_name_template參數是目的地資料表的名稱。- 此參數對 DDL 和 DML 查詢而言為選用,是其他所有查詢的必要參數。
- 針對
write_disposition參數,您可以選擇WRITE_TRUNCATE來截斷 (覆寫) 目的地資料表,或選擇WRITE_APPEND將查詢結果附加到目的地資料表。- 此參數對 DDL 和 DML 查詢而言為選用,是其他所有查詢的必要參數。
- 針對排程查詢,您必須提供
data_source。資料來源:scheduled_query。- 選用:
--service_account_name標記是用來透過服務帳戶 (而非個別使用者帳戶) 進行驗證。 - 選用:
--destination_kms_key指定 Cloud KMS 金鑰的金鑰資源 ID,例如projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name。
舉例來說,下列指令會使用查詢 SELECT 1
from mydataset.test 建立名為 My Scheduled Query 的排程查詢移轉作業設定。目的地資料表 mytable 每次寫入時皆會截斷,而目標資料集為 mydataset。排程查詢會在預設的專案內建立,並以服務帳戶身分進行驗證:
bq mk \
--transfer_config \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}' \
--data_source=scheduled_query \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com
首次執行指令時,您會收到類似以下的訊息:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
請按照訊息中的操作說明進行,在指令列中貼上驗證碼。
API
請使用 projects.locations.transferConfigs.create 方法,並提供 TransferConfig 資源的執行個體。
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
使用服務帳戶設定排程查詢
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
查看排程查詢狀態
主控台
如要查看排定查詢的狀態,請在導覽選單中按一下「排程」,然後篩選「排定查詢」。按一下排程查詢,即可查看詳細資料。
bq
排程查詢是一種移轉作業。如要顯示排程查詢的詳細資料,您可以先使用 bq 指令列工具列出移轉作業設定。
輸入 bq ls 指令並加上移轉旗標 --transfer_config。還需加上以下旗標:
--transfer_location
例如:
bq ls \
--transfer_config \
--transfer_location=us
如要顯示單一排程查詢的詳細資料,請輸入 bq show 指令,並提供該排程查詢或移轉作業設定的 transfer_path。
例如:
bq show \
--transfer_config \
projects/862514376110/locations/us/transferConfigs/5dd12f26-0000-262f-bc38-089e0820fe38
API
請使用 projects.locations.transferConfigs.list 方法,並提供 TransferConfig 資源的執行個體。
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
更新排程查詢
主控台
如要更新排定的查詢,請按照下列步驟操作:
- 在導覽選單中,按一下「排程查詢」或「排程」。
- 在排定查詢清單中,按一下要變更的查詢名稱。
- 在開啟的「已排定的查詢詳細資料」頁面中,按一下「編輯」。

- 選用:在查詢編輯窗格中變更查詢文字。
- 按一下「排程查詢」,然後選取「更新排程查詢」。
- 選用:變更查詢的其他排程選項。
- 按一下「Update」。
bq
排程查詢是一種移轉作業。如要更新排程查詢,可使用 bq 指令列工具建立移轉作業設定。
輸入 bq update 指令,並加上必要的 --transfer_config 旗標。
選用標記:
--project_id是您的專案 ID。如果未指定--project_id,系統會使用預設專案。--schedule是您希望查詢執行的頻率。如未指定--schedule,預設設定為依建立時間計算「every 24 hours」(每 24 小時)。--service_account_name必須配合--update_credentials才會生效。詳情請參閱「更新排程查詢憑證」。與 DDL 和 DML 查詢搭配使用時,
--target_dataset(DDL 和 DML 查詢為選用) 是命名查詢結果目標資料集的另一種方式。--display_name是排定查詢的名稱。--params:已建立移轉設定的 JSON 格式參數。例如:--params='{"param":"param_value"}'。--destination_kms_key指定 Cloud KMS 金鑰的金鑰資源 ID,前提是您要使用客戶管理加密金鑰 (CMEK) 進行這項轉移作業。如要瞭解客戶管理的加密金鑰 (CMEK) 如何與 BigQuery 資料移轉服務搭配運作,請參閱「指定排定查詢的加密金鑰」。
bq update \ --target_dataset=dataset \ --display_name=name \ --params='parameters' --transfer_config \ RESOURCE_NAME
更改下列內容:
dataset。移轉設定的目標資料集。此參數對 DDL 和 DML 查詢而言為選用,但為其他所有查詢的必要參數。name. 移轉設定的顯示名稱。顯示名稱可以是任何值,方便您日後在必要時修改查詢。parameters。含有已建立移轉設定的 JSON 格式參數。例如:--params='{"param":"param_value"}'。- 針對排程查詢,您必須提供
query參數。 destination_table_name_template參數是目的地資料表的名稱。此參數對 DDL 和 DML 查詢而言為選用,但為其他所有查詢的必要參數。- 針對
write_disposition參數,您可以選擇WRITE_TRUNCATE來截斷 (覆寫) 目的地資料表,或選擇WRITE_APPEND將查詢結果附加到目的地資料表。此參數對 DDL 和 DML 查詢而言為選用,但為其他所有查詢的必要參數。
- 針對排程查詢,您必須提供
- 選用:
--destination_kms_key指定 Cloud KMS 金鑰的金鑰資源 ID,例如projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name。 RESOURCE_NAME:移轉的資源名稱 (也稱為移轉設定)。如果您不知道移轉的資源名稱,請使用bq ls --transfer_config --transfer_location=location找出資源名稱。
舉例來說,下列指令會使用查詢 SELECT 1
from mydataset.test,更新名為 My Scheduled Query 的排程查詢移轉作業設定。目的地資料表 mytable 每次寫入時皆會截斷,而目標資料集為 mydataset:
bq update \
--target_dataset=mydataset \
--display_name='My Scheduled Query' \
--params='{"query":"SELECT 1 from mydataset.test","destination_table_name_template":"mytable","write_disposition":"WRITE_TRUNCATE"}'
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
API
請使用 projects.transferConfigs.patch 方法,並使用 transferConfig.name 參數提供轉移作業的資源名稱。如果您不知道移轉的資源名稱,請使用 bq ls --transfer_config --transfer_location=location 指令列出所有移轉,或呼叫 projects.locations.transferConfigs.list 方法,並使用 parent 參數提供專案 ID。
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
更新設有擁有權限制的排程查詢
如果嘗試更新不屬於自己的排程查詢,更新可能會失敗,並顯示以下錯誤訊息:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
排程查詢的擁有者是與排程查詢相關聯的使用者,或是可存取與排程查詢相關聯服務帳戶的使用者。您可以在排定查詢的設定詳細資料中查看相關聯的使用者。如要瞭解如何更新排程查詢,以便取得擁有權,請參閱「更新排程查詢憑證」。如要授予使用者服務帳戶存取權,您必須具備服務帳戶使用者角色。
排定查詢的擁有者受限參數如下:
- 查詢文字
- 目的地資料集
- 目的地資料表名稱範本
更新排定查詢的憑證
如果您是為既有的查詢進行排程,可能需要在查詢中更新使用者憑證。系統會自動為新的排定查詢更新憑證。
其他可能需要更新憑證的情況包括:
- 您想在排定的查詢中查詢 Google 雲端硬碟資料。
嘗試排定查詢時,您會收到 INVALID_USER 錯誤:
Error code 5 : Authentication failure: User Id not found. Error code: INVALID_USERID嘗試更新查詢時,您會收到下列受限參數錯誤:
Cannot modify restricted parameters without taking ownership of the transfer configuration.
主控台
如要重新整理排程查詢上的現有憑證,請進行以下操作:
找出並查看排程查詢的狀態。
按一下 [MORE] (更多) 按鈕,然後選取 [Update credentials] (更新憑證)。

變更需要 10 至 20 分鐘才會生效。你可能需要清除瀏覽器的快取。
bq
排程查詢是一種移轉作業。如要更新排程查詢的憑證,您可以使用 bq 指令列工具更新移轉作業設定。
輸入 bq update 指令並加上移轉旗標 --transfer_config。還需加上以下旗標:
--update_credentials
選用旗標:
--service_account_name是用於透過服務帳戶 (而非個別使用者帳戶) 來驗證排程查詢。
舉例來說,下列指令會更新排程查詢的移轉作業設定,並以服務帳戶身分進行驗證:
bq update \
--update_credentials \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com \
--transfer_config \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
設定過去日期的手動執行作業
除了排定查詢於日後執行,您也可以手動觸發立即執行作業。如果您的查詢使用 run_date 參數,且在先前執行期間發生問題,則可能需要觸發立即執行作業。
舉例來說,每天 09:00 您會在來源資料表中查詢符合目前日期的資料列。然而您發現系統在過去三天內,並未將這項資料加進來源資料表。在這種情況下,您可以將查詢設定為在指定日期範圍的歷史資料中執行。您的查詢在執行時,使用的 run_date 和 run_time 參數組合會對應到您排程查詢中所設的日期。
設定排程查詢後,可按照以下步驟使用過去的日期範圍來執行查詢:
主控台
按一下「排程」儲存排程查詢後,您可以按一下「已排定的查詢」按鈕,查看排程查詢清單。按一下任何顯示名稱可查看該查詢的排程詳細資料。在頁面右上方,按一下 [Schedule Backfill] (排程補充作業),即可指定過去的日期範圍。
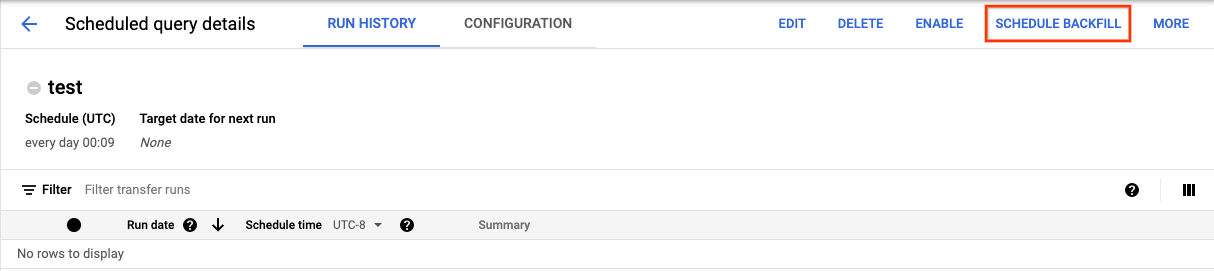
所選的執行時間皆於您所選的範圍之內,這個範圍包含初次執行日期,並排除最後一次的日期。

範例 1
排程查詢設定在太平洋時間的 every day 09:00 執行,而您缺少 1 月 1 日、1 月 2 日和 1 月 3 日的資料。請選擇下列過去的日期範圍:
Start Time = 1/1/19
End Time = 1/4/19
您的查詢會使用對應至下列時間的 run_date 和 run_time 參數執行:
- 1/1/19 09:00 太平洋時間
- 1/2/19 09:00 太平洋時間
- 1/3/19 09:00 太平洋時間
示例 2
排程查詢設定在太平洋時間的 every day 23:00 執行,而您缺少 1 月 1 日、1 月 2 日和 1 月 3 日的資料。請選擇下列過去的日期範圍 (由於太平洋時間的 23:00 與世界標準時間的日期不同,因此要選擇較晚的日期):
Start Time = 1/2/19
End Time = 1/5/19
您的查詢會使用對應至下列時間的 run_date 和 run_time 參數執行:
- 1/2/19 06:00 世界標準時間,或 1/1/2019 23:00 太平洋時間
- 1/3/19 06:00 世界標準時間,或 1/2/2019 23:00 太平洋時間
- 1/4/19 06:00 世界標準時間,或 1/3/2019 23:00 太平洋時間
設定手動執行作業後,請重新整理頁面,這些執行作業便會顯示在執行作業清單中。
bq
如要針對過去的日期範圍手動執行查詢:
輸入 bq mk 指令並加上移轉執行作業旗標 --transfer_run。還需加上以下旗標:
--start_time--end_time
bq mk \ --transfer_run \ --start_time='start_time' \ --end_time='end_time' \ resource_name
更改下列內容:
start_time和end_time。 以 Z 結尾或包含有效時區設定的時間戳記。範例:- 2017-08-19T12:11:35.00Z
- 2017-05-25T00:00:00+00:00
resource_name。排程查詢 (或移轉作業) 的資源名稱。資源名稱也稱為移轉設定。
例如,下列指令會為排程查詢資源 (又稱為移轉作業設定) 排定補充作業:projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7。
bq mk \
--transfer_run \
--start_time 2017-05-25T00:00:00Z \
--end_time 2017-05-25T00:00:00Z \
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7
詳情請參閱 bq mk --transfer_run。
API
使用 projects.locations.transferConfigs.scheduleRun 方法並提供 TransferConfig 資源的路徑。
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
為排程查詢設定快訊
您可以根據資料列計數指標,為排程查詢設定警告政策。詳情請參閱「使用排定查詢設定快訊」。
刪除預定查詢
主控台
如要透過 Google Cloud 控制台的「Scheduled queries」(已排定的查詢) 頁面刪除排程查詢,請按照下列步驟操作:
- 在導覽選單中,按一下「已排程的查詢」。
- 在排定查詢清單中,按一下要刪除的排定查詢名稱。
在「Scheduled query details」(已排定查詢詳細資料) 頁面,按一下「Delete」(刪除)。

或者,您也可以在 Google Cloud 控制台的「Scheduling」(排程) 頁面中刪除排程查詢:
- 在導覽選單中,按一下「排程」。
- 在排程查詢清單中,按一下要刪除的排程查詢的「動作」選單 。
選取 [刪除]。

Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
停用或啟用已排定的查詢
如要暫停所選查詢的排定執行作業,但不想刪除排程,可以停用排程。
如要停用所選查詢的排程,請按照下列步驟操作:
- 在 Google Cloud 控制台的導覽選單中,按一下「Scheduling」(排程)。
- 在排程查詢清單中,按一下要停用的排程查詢的「動作」選單。
選取 [Disable] (停用)。

如要啟用已停用的預定查詢,請點選要啟用的預定查詢的「動作」選單,然後選取「啟用」。
配額
排定查詢一律會以批次查詢工作的形式執行,且與手動查詢一樣,都應遵循相同 BigQuery 配額與限制。
雖然排程查詢會使用 BigQuery 資料移轉服務的功能,但這類查詢並非移轉作業,也不受載入工作配額的限制。
用來執行查詢的身分會決定套用哪些配額。這取決於排定查詢的設定:
建立者的憑證 (預設):如果您未指定服務帳戶,系統會使用建立者的憑證執行排定的查詢。查詢作業的費用會計入建立者的專案,並受該使用者和專案配額限制。
服務帳戶憑證:如果將排定的查詢設定為使用服務帳戶,系統會使用該帳戶的憑證執行查詢。在這種情況下,系統仍會向包含排程查詢的專案收取工作費用,但執行作業時會受到指定服務帳戶配額的限制。
定價
排程查詢的定價與手動 BigQuery 查詢相同。
支援的地區
下列地區支援排程查詢。
區域
下表列出 BigQuery 適用的美洲地區。| 地區說明 | 區域名稱 | 詳細資料 |
|---|---|---|
| 俄亥俄州哥倫布 | us-east5 |
|
| 達拉斯 | us-south1 |
|
| 愛荷華州 | us-central1 |
|
| 拉斯維加斯 | us-west4 |
|
| 洛杉磯 | us-west2 |
|
| 墨西哥 | northamerica-south1 |
|
| 蒙特婁 | northamerica-northeast1 |
|
| 北維吉尼亞州 | us-east4 |
|
| 奧勒岡州 | us-west1 |
|
| 鹽湖城 | us-west3 |
|
| 聖保羅 | southamerica-east1 |
|
| 聖地亞哥 | southamerica-west1 |
|
| 南卡羅來納州 | us-east1 |
|
| 多倫多 | northamerica-northeast2 |
|
| 地區說明 | 區域名稱 | 詳細資料 |
|---|---|---|
| 德里 | asia-south2 |
|
| 香港 | asia-east2 |
|
| 雅加達 | asia-southeast2 |
|
| 墨爾本 | australia-southeast2 |
|
| 孟買 | asia-south1 |
|
| 大阪 | asia-northeast2 |
|
| 首爾 | asia-northeast3 |
|
| 新加坡 | asia-southeast1 |
|
| 雪梨 | australia-southeast1 |
|
| 台灣 | asia-east1 |
|
| 東京 | asia-northeast1 |
| 地區說明 | 區域名稱 | 詳細資料 |
|---|---|---|
| 比利時 | europe-west1 |
|
| 柏林 | europe-west10 |
|
| 芬蘭 | europe-north1 |
|
| 法蘭克福 | europe-west3 |
|
| 倫敦 | europe-west2 |
|
| 馬德里 | europe-southwest1 |
|
| 米蘭 | europe-west8 |
|
| 荷蘭 | europe-west4 |
|
| 巴黎 | europe-west9 |
|
| 斯德哥爾摩 | europe-north2 |
|
| 杜林 | europe-west12 |
|
| 華沙 | europe-central2 |
|
| 蘇黎世 | europe-west6 |
|
| 地區說明 | 區域名稱 | 詳細資料 |
|---|---|---|
| 達曼 | me-central2 |
|
| 杜哈 | me-central1 |
|
| 特拉維夫市 | me-west1 |
| 地區說明 | 區域名稱 | 詳細資料 |
|---|---|---|
| 約翰尼斯堡 | africa-south1 |
多區域
下表列出 BigQuery 適用的多區域。| 多地區說明 | 多區域名稱 |
|---|---|
| 歐盟1成員國境內的資料中心 | EU |
| 美國資料中心2 | US |
1 位於 EU 多地區的資料只會儲存在下列任一位置:europe-west1 (比利時) 或 europe-west4 (荷蘭)。
BigQuery 會自動決定資料的儲存和處理位置。
2 位於 US 多地區的資料只會儲存在下列其中一個位置:us-central1 (愛荷華州)、us-west1 (奧勒岡州) 或 us-central2 (奧克拉荷馬州)。BigQuery 會自動決定資料的儲存和處理位置。
後續步驟
- 如需使用服務帳戶並包含
@run_date和@run_time參數的排程查詢範例,請參閱使用排程查詢建立資料表快照。