執行查詢
本文將說明如何在 BigQuery 中執行查詢,並透過試算瞭解查詢執行前會處理多少資料。
查詢作業的類型
您可以使用下列其中一種查詢工作類型查詢 BigQuery 資料:
互動式查詢作業。根據預設,BigQuery 會以互動式查詢工作執行查詢,這類工作會盡快開始執行。
批次查詢工作。批次查詢的優先順序低於互動式查詢。如果專案或預訂項目已用盡所有可用的運算資源,批次查詢就更有可能排入佇列,並留在佇列中。批次查詢開始執行後,運作方式與互動式查詢相同。詳情請參閱「查詢佇列」。
持續查詢工作。 這些工作會持續執行查詢,讓您即時分析 BigQuery 中的輸入資料,然後將結果寫入 BigQuery 資料表,或將結果匯出至 Bigtable 或 Pub/Sub。您可以使用這項功能執行時間敏感型工作,例如建立洞察資料並立即採取行動、套用即時機器學習 (ML) 推論,以及建構事件驅動的資料管道。
您可以使用下列方法執行查詢工作:
- 在Google Cloud 控制台中編寫及執行查詢。
- 在 bq 指令列工具中執行
bq query指令。 - 透過程式呼叫 BigQuery REST API 中的
jobs.query或jobs.insert方法。 - 使用 BigQuery 用戶端程式庫。
BigQuery 會將查詢結果儲存至臨時資料表 (預設) 或永久資料表。 將永久資料表指定為結果的目標資料表時,您可以選擇附加或覆寫現有資料表,也可以建立名稱不重複的新資料表。
必要的角色
如要取得執行查詢作業所需的權限,請要求管理員授予下列 IAM 角色:
-
專案的 BigQuery 工作使用者 (
roles/bigquery.jobUser)。 -
BigQuery 資料檢視者 (
roles/bigquery.dataViewer) 查詢參照的所有資料表和檢視畫面。如要查詢檢視區塊,您也必須具備所有基礎資料表和檢視區塊的這項角色。如果您使用授權檢視畫面或授權資料集,就不需要存取基礎來源資料。
如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和機構的存取權」。
這些預先定義角色具備執行查詢工作所需的權限。如要查看確切的必要權限,請展開「必要權限」部分:
所需權限
如要執行查詢工作,必須具備下列權限:
疑難排解
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
如果主體沒有在專案中建立查詢工作的權限,就會發生這個錯誤。
解決方法:管理員必須授予您查詢專案的 bigquery.jobs.create 權限。除了存取所查詢資料所需的權限外,您還必須具備這項權限。
如要進一步瞭解 BigQuery 權限,請參閱「使用身分與存取權管理功能控管存取權」一文。
執行互動式查詢
如要執行互動式查詢,請選取下列其中一個選項:
主控台
前往「BigQuery」頁面
按一下「SQL 查詢」。
在查詢編輯器中輸入有效的 GoogleSQL 查詢。
舉例來說,您可以查詢 BigQuery 公開資料集
usa_names,找出 1910 年到 2013 年之間美國最常見的姓名:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;或者,您也可以使用「參考」面板建構新查詢。
選用步驟:如要在輸入查詢時自動顯示程式碼建議,請按一下「更多」,然後選取「SQL 自動完成」。如果不需要自動完成建議,請取消選取「SQL 自動完成」。這也會關閉專案名稱自動填入建議。
選用:如要選取其他查詢設定,請按一下「更多」,然後按一下「查詢設定」。
按一下「執行」。
如未指定目的地資料表,查詢工作會將輸出寫入臨時 (快取) 資料表。
現在可以在「查詢結果」窗格的「結果」分頁中,探索查詢結果。
選用步驟:如要按照資料欄排序查詢結果,請點選資料名稱欄旁的 「Open sort menu」(開啟排序選單),然後選取排列順序。如果排序作業的預估處理位元組數大於 0,選單頂端就會顯示位元組數。
選用步驟:如要查看查詢結果的視覺化資料,請前往「Visualization」(視覺化) 分頁標籤。您可以放大或縮小圖表、將圖表下載為 PNG 檔案,或切換圖例的顯示狀態。
在「視覺化設定」窗格中,您可以變更視覺化類型,並設定視覺化的指標和維度。這個窗格中的欄位會預先填入從查詢目的地資料表結構定義推斷的初始設定。在同一個查詢編輯器中,後續執行查詢時會保留設定。
如果是「折線圖」、「長條圖」或「散布圖」,支援的維度為
INT64、FLOAT64、NUMERIC、BIGNUMERIC、TIMESTAMP、DATE、DATETIME、TIME和STRING資料類型,支援的指標則為INT64、FLOAT64、NUMERIC和BIGNUMERIC資料類型。如果查詢結果包含
GEOGRAPHY類型,則預設的視覺化類型為「地圖」,可讓您在互動式地圖上查看結果。選用步驟:在「JSON」分頁中,您可以 JSON 格式查看查詢結果,其中鍵是資料欄名稱,值則是該資料欄的結果。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
使用
bq query指令。在下列範例中,--use_legacy_sql=false旗標可讓您使用 GoogleSQL 語法。bq query \ --use_legacy_sql=false \ 'QUERY'
請將 QUERY 替換成有效的 GoogleSQL 查詢。舉例來說,您可以查詢 BigQuery 公開資料集
usa_names,找出 1910 年到 2013 年之間美國最常見的姓名:bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'查詢工作會將輸出寫入暫時性 (快取) 資料表。
您可以選擇指定查詢結果的目的地資料表和位置。如要將結果寫入現有資料表,請加入適當的標記來附加 (
--append_table=true) 或覆寫 (--replace=true) 資料表。bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
更改下列內容:
LOCATION:目的地資料表的區域或多區域,例如
US在本例中,
usa_names資料集儲存在美國多地區位置。如果您為這項查詢指定目的地資料表,則包含目的地資料表的資料集也必須位於美國多地區。您無法查詢位於某個位置的資料集,然後將結果寫入位於另一個位置的資料表。您可以使用 .bigqueryrc 檔案設定位置的預設值。
TABLE:目標資料表的名稱,例如
myDataset.myTable如果目的地資料表是新資料表,BigQuery 會在您執行查詢時建立該資料表。不過,您必須指定現有資料集。
如果資料表不在目前的專案中,請使用
PROJECT_ID:DATASET.TABLE格式新增Google Cloud 專案 ID,例如myProject:myDataset.myTable。如未指定--destination_table,系統會產生將輸出寫入臨時資料表的查詢工作。
API
如要使用 API 執行查詢,請插入新工作並填入 query 工作設定屬性。(選用) 請前往工作資源的 jobReference 區段,並在 location 屬性中指定您的位置。
呼叫 getQueryResults 來輪詢結果。持續輪詢,直到 jobComplete 等於 true 為止。檢查 errors 清單中的錯誤與警告。
C#
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 C# 設定說明進行操作。詳情請參閱 BigQuery C# API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Go
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Go 設定說明進行操作。詳情請參閱 BigQuery Go API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
如要透過 Proxy 執行查詢,請參閱設定 Proxy。
Node.js
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Node.js 設定說明進行操作。詳情請參閱 BigQuery Node.js API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
PHP
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 PHP 設定說明進行操作。詳情請參閱 BigQuery PHP API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Ruby
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Ruby 設定說明進行操作。詳情請參閱 BigQuery Ruby API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
執行批次查詢
如要執行批次查詢,請選取下列任一選項:
主控台
前往「BigQuery」頁面
按一下「SQL 查詢」。
在查詢編輯器中輸入有效的 GoogleSQL 查詢。
舉例來說,您可以查詢 BigQuery 公開資料集
usa_names,找出 1910 年到 2013 年之間美國最常見的姓名:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;按一下「更多」,然後按一下「查詢設定」。
在「資源管理」部分,選取「批次」。
選用:調整查詢設定。
按一下 [儲存]。
按一下「執行」。
如未指定目的地資料表,查詢工作會將輸出寫入臨時 (快取) 資料表。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
使用
bq query指令並指定--batch旗標。在下列範例中,--use_legacy_sql=false旗標可讓您使用 GoogleSQL 語法。bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
請將 QUERY 替換成有效的 GoogleSQL 查詢。舉例來說,您可以查詢 BigQuery 公開資料集
usa_names,找出 1910 年到 2013 年之間美國最常見的姓名:bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'查詢工作會將輸出寫入暫時性 (快取) 資料表。
您可以選擇指定查詢結果的目的地資料表和位置。如要將結果寫入現有資料表,請加入適當的標記來附加 (
--append_table=true) 或覆寫 (--replace=true) 資料表。bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
更改下列內容:
LOCATION:目的地資料表的區域或多區域,例如
US在本例中,
usa_names資料集儲存在美國多地區位置。如果您為這項查詢指定目的地資料表,則包含目的地資料表的資料集也必須位於美國多地區。您無法查詢位於某個位置的資料集,然後將結果寫入位於另一個位置的資料表。您可以使用 .bigqueryrc 檔案設定位置的預設值。
TABLE:目標資料表的名稱,例如
myDataset.myTable如果目的地資料表是新資料表,BigQuery 會在您執行查詢時建立該資料表。不過,您必須指定現有資料集。
如果資料表不在目前的專案中,請使用
PROJECT_ID:DATASET.TABLE格式新增Google Cloud 專案 ID,例如myProject:myDataset.myTable。如未指定--destination_table,系統會產生將輸出寫入臨時資料表的查詢工作。
API
如要使用 API 執行查詢,請插入新工作並填入 query 工作設定屬性。(選用) 請前往工作資源的 jobReference 區段,並在 location 屬性中指定您的位置。
填入查詢工作屬性時,請加入 configuration.query.priority 屬性,並將值設為 BATCH。
呼叫 getQueryResults 來輪詢結果。持續輪詢,直到 jobComplete 等於 true 為止。檢查 errors 清單中的錯誤與警告。
Go
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Go 設定說明進行操作。詳情請參閱 BigQuery Go API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Java
如要執行批次查詢,請將查詢優先順序設定為 QueryJobConfiguration.Priority.BATCH (當建立 QueryJobConfiguration 時)。
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Node.js
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Node.js 設定說明進行操作。詳情請參閱 BigQuery Node.js API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
執行持續查詢
執行持續查詢工作需要額外設定。詳情請參閱「建立連續查詢」。
使用「參考資料」面板
在查詢編輯器中,「參考資料」面板會動態顯示資料表、快照、檢視表和具體化檢視表的情境感知資訊。您可以在面板中預覽這些資源的結構定義詳細資料,或在新分頁中開啟。您也可以使用「Reference」(參考) 面板插入查詢程式碼片段或欄位名稱,建構新查詢或編輯現有查詢。
如要使用「Reference」(參考) 面板建構新查詢,請按照下列步驟操作:
前往 Google Cloud 控制台的「BigQuery」頁面。
按一下「SQL 查詢」。
按一下「quick_reference_all」quick_reference_all參考資料。
按一下最近或已加星號的資料表或檢視畫面。您也可以使用搜尋列尋找表格和檢視區塊。
按一下「查看動作」,然後點選「插入查詢程式碼片段」。
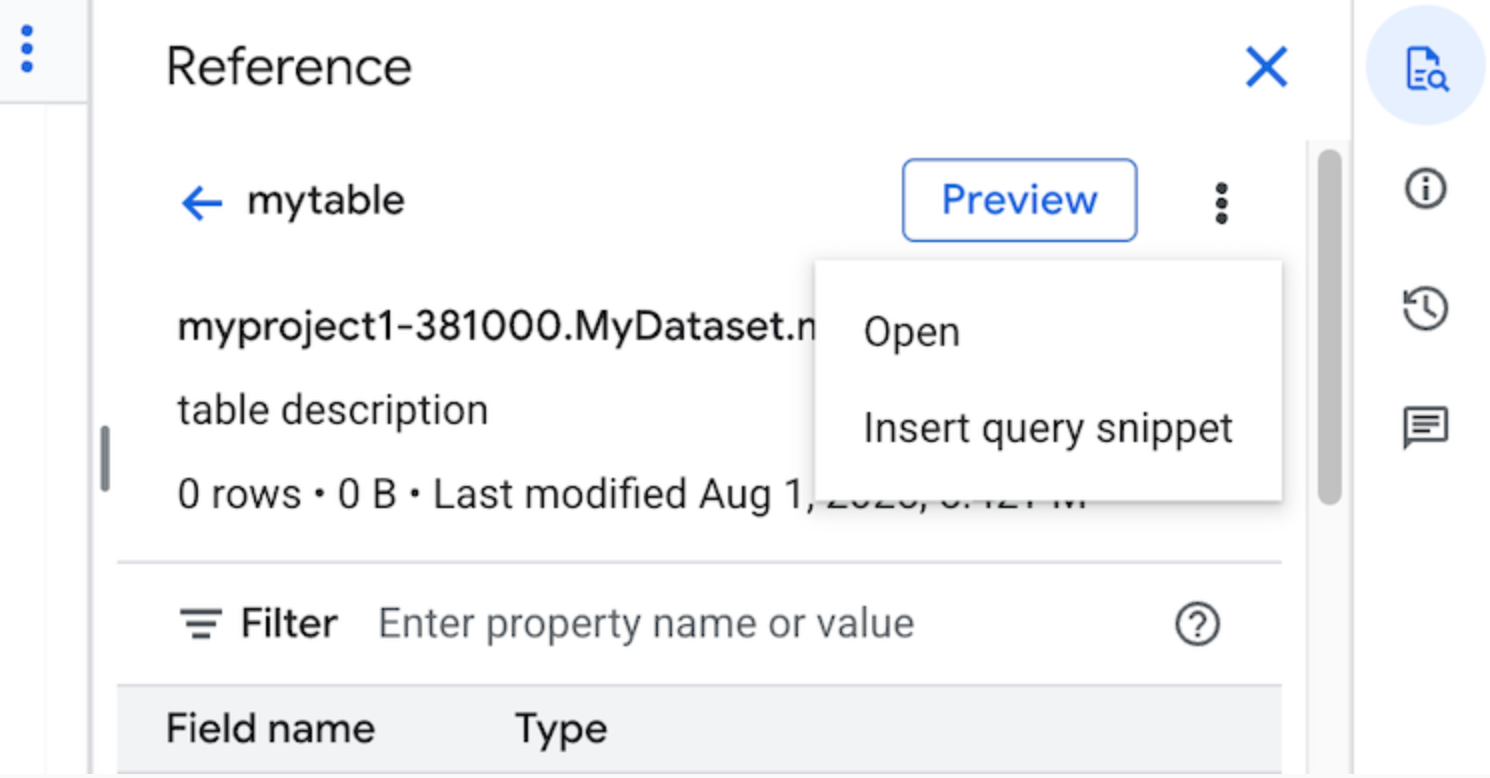
選用:您可以預覽資料表的結構定義詳細資料,或在新分頁中查看/開啟這些資料。
現在您可以手動編輯查詢,或直接在查詢中插入欄位名稱。如要插入欄位名稱,請在查詢編輯器中指向並按一下要插入欄位名稱的位置,然後按一下「參照」面板中的欄位名稱。
查詢設定
執行查詢時,您可以指定下列設定:
查詢結果的目的地資料表。
這項工作的優先順序。
是否要使用快取查詢結果。
工作逾時時間 (以毫秒為單位)。
是否使用工作階段模式。
要使用的加密類型。
查詢的計費位元組數上限。
要使用的 SQL 方言。
執行查詢的位置。查詢必須在與查詢中參照的任何資料表相同的位置執行。
在「預覽」中執行查詢的預留。
「選擇性建立工作」模式
對於執行時間較短的查詢 (例如來自資訊主頁或資料探索工作負載的查詢),選用工作建立模式可縮短整體延遲時間。這個模式會執行查詢,並針對 SELECT 陳述式傳回內嵌結果,不需要使用 jobs.getQueryResults 擷取結果。使用選用工作建立模式的查詢在執行時不會建立工作,除非 BigQuery 判斷必須建立工作才能完成查詢。
如要啟用「選擇性建立工作」模式,請在 jobs.query 要求主體中,將 QueryRequest 執行個體的 jobCreationMode 欄位設為 JOB_CREATION_OPTIONAL。
如果這個欄位的值設為 JOB_CREATION_OPTIONAL,BigQuery 會判斷查詢是否可以使用選用的工作建立模式。如果是,BigQuery 會執行查詢,並在回應的 rows 欄位中傳回所有結果。由於系統不會為這項查詢建立工作,因此 BigQuery 不會在回應主體中傳回 jobReference。而是會傳回 queryId 欄位,您可以使用該欄位,透過 INFORMATION_SCHEMA.JOBS
檢視畫面取得查詢洞察資料。由於未建立任何工作,因此沒有可傳遞至 jobs.get 和 jobs.getQueryResults API 的 jobReference,無法查詢這些查詢。
如果 BigQuery 判斷需要工作才能完成查詢,就會傳回 jobReference。您可以檢查 INFORMATION_SCHEMA.JOBS 檢視區塊中的 job_creation_reason 欄位,判斷系統為查詢建立工作的原因。在這種情況下,查詢完成時,您應使用 jobs.getQueryResults 擷取結果。
使用 JOB_CREATION_OPTIONAL 值時,回應中可能不會出現 jobReference 欄位。存取欄位前,請先檢查該欄位是否存在。
為多重陳述式查詢 (指令碼) 指定 JOB_CREATION_OPTIONAL 時,BigQuery 可能會最佳化執行程序。在最佳化過程中,BigQuery 可能會判斷建立的工作資源數量少於個別陳述式數量,即可完成指令碼,甚至可能完全不建立任何工作,就執行整個指令碼。這項最佳化作業取決於 BigQuery 對指令碼的評估結果,因此不一定適用於所有情況。系統會全自動執行最佳化作業。使用者無須進行任何控制或操作。
如要使用選用工作建立模式執行查詢,請選取下列其中一個選項:
主控台
前往「BigQuery」頁面
按一下「SQL 查詢」。
在查詢編輯器中輸入有效的 GoogleSQL 查詢。
舉例來說,您可以查詢 BigQuery 公開資料集
usa_names,找出 1910 年到 2013 年之間美國最常見的姓名:SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;按一下「更多」,然後選擇「選擇性建立工作」查詢模式。如要確認這項選擇,請按一下「確認」。
按一下「執行」。
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
使用
bq query指令並指定--job_creation_mode=JOB_CREATION_OPTIONAL旗標。在下列範例中,--use_legacy_sql=false旗標可讓您使用 GoogleSQL 語法。bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
請將 QUERY 改成有效的 GoogleSQL 查詢,並將 LOCATION 改成資料集所在的有效區域。舉例來說,您可以查詢 BigQuery 公開資料集
usa_names,找出 1910 年到 2013 年之間美國最常見的姓名:bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'查詢作業會在回應中內嵌傳回輸出內容。
API
如要使用 API 在選用工作建立模式中執行查詢,請同步執行查詢,並填入 QueryRequest 屬性。加入 jobCreationMode 屬性,並將值設為 JOB_CREATION_OPTIONAL。
查看回覆。如果 jobComplete 等於 true 且 jobReference 為空,請從 rows 欄位讀取結果。您也可以從回覆中取得 queryId。
如果存在 jobReference,您可以查看 jobCreationReason,瞭解 BigQuery 建立工作的原因。呼叫 getQueryResults 來輪詢結果。持續輪詢,直到 jobComplete 等於 true 為止。檢查 errors 清單中的錯誤與警告。
Java
適用版本:2.51.0 以上
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
如要透過 Proxy 執行查詢,請參閱設定 Proxy。
Python
適用版本:3.34.0 以上
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
節點
適用版本:8.1.0 以上
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Node.js 設定說明進行操作。詳情請參閱 BigQuery Node.js API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Go
適用版本:1.69.0 以上
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Go 設定說明進行操作。詳情請參閱 BigQuery Go API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
JDBC 驅動程式
適用版本:JDBC 1.6.1 以上版本
必須在連線字串中設定 JobCreationMode=2。
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
ODBC 驅動程式
適用版本:ODBC v3.0.7.1016 以上版本
必須在 .ini 檔案中設定 JobCreationMode=2。
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
配額
如要瞭解互動式和批次查詢的配額,請參閱查詢工作。
監控查詢
您可以使用作業探索器,或查詢 INFORMATION_SCHEMA.JOBS_BY_PROJECT 檢視區塊,取得查詢執行期間的相關資訊。
模擬測試
BigQuery 中的試算會提供下列資訊:
模擬測試不會使用查詢運算單元,執行模擬測試也不會產生費用。 您可以使用模擬測試傳回的估算值,在 Pricing Calculator 中計算查詢費用。
執行模擬測試
如要執行模擬測試,請按照下列步驟操作:
主控台
前往 BigQuery 頁面。
在查詢編輯器中輸入查詢。
如果查詢有效,系統就會自動顯示勾號和查詢處理的資料量。如果查詢無效,則會顯示驚嘆號和錯誤訊息。
bq
使用 --dry_run 旗標輸入如下的查詢。
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
如果查詢有效,這項指令會產生下列回應:
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
如要使用 API 執行模擬測試,請在 JobConfiguration 型別中,將 dryRun 設定為 true,然後提交查詢工作。
Go
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Go 設定說明進行操作。詳情請參閱 BigQuery Go API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Java
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Java 設定說明進行操作。詳情請參閱 BigQuery Java API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Node.js
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Node.js 設定說明進行操作。詳情請參閱 BigQuery Node.js API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
PHP
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 PHP 設定說明進行操作。詳情請參閱 BigQuery PHP API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。
Python
將 QueryJobConfig.dry_run 屬性設為 True。如果有提供模擬測試的查詢設定,則 Client.query() 一律會傳回已完成的 QueryJob。
在試行這個範例之前,請先按照 BigQuery 快速入門導覽課程:使用用戶端程式庫中的 Python 設定說明進行操作。詳情請參閱 BigQuery Python API 參考說明文件。
如要向 BigQuery 進行驗證,請設定應用程式預設憑證。 詳情請參閱「設定用戶端程式庫的驗證機制」。