Ce guide explique comment automatiser le déploiement de SAP HANA dans un cluster à haute disponibilité Red Hat Enterprise Linux (RHEL) ou SUSE Linux Enterprise Server (SLES) utilisant l'équilibreur de charge réseau passthrough interne pour gérer l'adresse IP virtuelle.
Ce guide utilise Cloud Deployment Manager pour déployer deux machines virtuelles (VM) Compute Engine, deux systèmes à évolutivité verticale SAP HANA, une adresse IP virtuelle avec implémentation d'un équilibreur de charge réseau passthrough interne et un cluster à haute disponibilité basé sur un système d'exploitation, le tout conformément aux bonnes pratiques de Google Cloud, de SAP et du fournisseur du système d'exploitation.
L'un des systèmes SAP HANA fonctionne en tant que système principal, actif, et l'autre en tant que système secondaire, de secours. Vous déployez les deux systèmes SAP HANA dans la même région, de préférence dans différentes zones.

Le cluster déployé inclut les fonctions et fonctionnalités suivantes :
- Le gestionnaire de ressources de cluster à haute disponibilité Pacemaker
- Un mécanisme de cloisonnement Google Cloud
- Une adresse IP virtuelle (VIP) avec mise en œuvre d'un équilibreur de charge interne TCP de niveau 4, y compris :
- Une réservation de l'adresse IP que vous choisissez comme adresse IP virtuelle
- Deux groupes d'instances Compute Engine
- Un équilibreur de charge interne TCP
- Une vérification de l'état Compute Engine
- Dans les clusters RHEL à haute disponibilité :
- Le modèle à haute disponibilité Red Hat
- Packages d'agent de ressources et de cloisonnement Red Hat
- Dans les clusters SLES à haute disponibilité :
- Le modèle à haute disponibilité SUSE
- Le package d'agents de ressources SUSE SAPHanaSR
- La réplication de système synchrone
- La précharge de mémoire
- Le redémarrage automatique de l'instance ayant échoué en tant que nouvelle instance secondaire
Pour déployer un système SAP HANA sans cluster Linux à haute disponibilité ni hôtes de secours, suivez le guide de déploiement de SAP HANA.
Ce guide est destiné aux utilisateurs avancés de SAP HANA qui connaissent bien les configurations Linux à haute disponibilité pour SAP HANA.
Prérequis
Avant de créer le cluster à haute disponibilité SAP HANA, assurez-vous que les conditions préalables suivantes sont remplies :
- Vous avez lu le guide de planification SAP HANA et le guide de planification de la haute disponibilité pour SAP HANA.
- Vous ou votre organisation disposez d'un compte Google Cloud et vous avez créé un projet pour le déploiement de SAP HANA. Pour en savoir plus sur la création de comptes et de projetsGoogle Cloud , consultez la section Configurer votre compte Google dans le guide de déploiement de SAP HANA.
- Si vous souhaitez que votre charge de travail SAP s'exécute conformément aux exigences liées à la résidence des données, au contrôle des accès, au personnel d'assistance ou à la réglementation, vous devez créer le dossier Assured Workloads requis. Pour en savoir plus, consultez la page Contrôles de conformité et de souveraineté pour SAP sur Google Cloud.
Le support d'installation de SAP HANA se trouve dans un bucket Cloud Storage disponible dans votre projet et votre région de déploiement. Pour savoir comment importer le support d'installation de SAP HANA dans un bucket Cloud Storage, consultez la section relative au téléchargement de SAP HANA dans le Guide de déploiement de SAP HANA.
Si OS Login est activé dans les métadonnées de votre projet, vous devrez le désactiver temporairement jusqu'à la fin du déploiement. Pour le déploiement, cette procédure configure les clés SSH dans les métadonnées d'instance. Lorsque OS Login est activé, les configurations de clé SSH basées sur les métadonnées sont désactivées et le déploiement échoue. Une fois le déploiement terminé, vous pouvez réactiver OS Login.
Pour en savoir plus, consultez les pages suivantes :
Si vous utilisez un DNS interne de VPC, la valeur de la variable
vmDnsSettingdans les métadonnées de votre projet doit êtreGlobalOnlyouZonalPreferredafin de permettre la résolution des noms de nœuds entre zones. La valeur par défaut devmDnsSettingestZonalOnly. Pour en savoir plus, consultez les pages suivantes :
Créer un réseau
Pour des raisons de sécurité, vous devez créer un réseau. Vous pourrez contrôler les accès en ajoutant des règles de pare-feu ou en utilisant une autre méthode.
Si votre projet dispose d'un réseau VPC par défaut, ne l'utilisez pas. À la place, créez votre propre réseau VPC afin que les seules règles de pare-feu appliquées soient celles que vous créez explicitement.
Lors du déploiement, les instances Compute Engine nécessitent généralement un accès à Internet pour télécharger l'agent Google Cloudpour SAP. Si vous utilisez l'une des images Linux certifiées SAP disponibles dans Google Cloud, l'instance de calcul nécessite également l'accès à Internet pour enregistrer la licence et accéder aux dépôts des fournisseurs d'OS. Une configuration comprenant une passerelle NAT et des tags réseau de VM permet aux instances de calcul cibles d'accéder à Internet même si elles ne possèdent pas d'adresses IP externes.
Pour configurer la mise en réseau, procédez comme suit :
Console
- Dans la console Google Cloud , accédez à la page Réseaux VPC.
- Cliquez sur Créer un réseau VPC.
- Saisissez un Nom pour le réseau.
Le nom doit respecter la convention d'attribution de noms. Les réseaux VPC utilisent la convention d'attribution de noms de Compute Engine.
- Dans le champ Mode de création du sous-réseau, sélectionnez Custom.
- Dans la section Nouveau sous-réseau, spécifiez les paramètres de configuration de sous-réseau suivants :
- Saisissez un nom pour le sous-réseau.
- Dans le champ Région, sélectionnez la région Compute Engine dans laquelle vous souhaitez créer le sous-réseau.
- Pour Type de pile IP, sélectionnez IPv4 (pile unique), puis saisissez une plage d'adresses IP au format CIDR, telle que
10.1.0.0/24.Il s'agit de la plage IPv4 principale du sous-réseau. Si vous envisagez d'ajouter plusieurs sous-réseaux, attribuez à chacun d'eux des plages d'adresses IP CIDR qui ne se chevauchent pas dans le réseau. Notez que chaque sous-réseau et ses plages d'adresses IP internes sont mappés sur une seule région.
- Cliquez sur OK.
- Pour ajouter d'autres sous-réseaux, cliquez sur Ajouter un sous-réseau et répétez les étapes ci-dessus. Vous pouvez ajouter d'autres sous-réseaux au réseau après sa création.
- Cliquez sur Créer.
gcloud
- Accédez à Cloud Shell.
- Pour créer un réseau en mode de sous-réseau personnalisé, exécutez la commande suivante :
gcloud compute networks create NETWORK_NAME --subnet-mode custom
Remplacez
NETWORK_NAMEpar le nom du nouveau réseau. Le nom doit respecter la convention d'attribution de noms. Les réseaux VPC utilisent la convention de dénomination de Compute Engine.Spécifiez
--subnet-mode custompour éviter d'utiliser le mode automatique par défaut, qui crée automatiquement un sous-réseau dans chaque région Compute Engine. Pour en savoir plus, consultez la section Mode de création du sous-réseau. - Créez un sous-réseau, et spécifiez la région et la plage d'adresses IP :
gcloud compute networks subnets create SUBNETWORK_NAME \ --network NETWORK_NAME --region REGION --range RANGERemplacez les éléments suivants :
SUBNETWORK_NAME: nom du nouveau sous-réseauNETWORK_NAME: nom du réseau que vous avez créé à l'étape précédenteREGION: région dans laquelle vous souhaitez créer le sous-réseauRANGE: plage d'adresses IP spécifiée au format CIDR (par exemple,10.1.0.0/24)Si vous envisagez d'ajouter plusieurs sous-réseaux, attribuez à chacun d'eux des plages d'adresses IP CIDR qui ne se chevauchent pas. Notez que chaque sous-réseau et ses plages d'adresses IP internes sont mappés sur une seule région.
- Si vous le souhaitez, répétez l'étape précédente et ajoutez des sous-réseaux.
Configurer une passerelle NAT
Si vous devez créer une ou plusieurs VM sans adresse IP publique, vous devez utiliser la traduction d'adresse réseau (NAT) pour permettre aux VM d'accéder à Internet. Utilisez Cloud NAT, un service Google Cloud géré distribué et défini par logiciel qui permet aux VM d'envoyer des paquets sortants vers Internet et de recevoir tous les paquets de réponses entrants établis correspondants. Vous pouvez également configurer une VM distincte en tant que passerelle NAT.
Pour créer une instance Cloud NAT pour votre projet, consultez la page Utiliser Cloud NAT.
Une fois que vous avez configuré Cloud NAT pour votre projet, vos instances de VM peuvent accéder en toute sécurité à Internet sans adresse IP publique.
Ajouter des règles de pare-feu
Par défaut, une règle de pare-feu implicite bloque les connexions entrantes provenant de l'extérieur de votre réseau VPC (Virtual Private Cloud, cloud privé virtuel). Pour autoriser les connexions entrantes, configurez une règle de pare-feu pour votre VM. Une fois qu'une connexion entrante est établie avec une VM, le trafic est autorisé dans les deux sens via cette connexion.
Les clusters à haute disponibilité pour SAP HANA nécessitent au moins deux règles de pare-feu, une permettant la vérification de l'état des nœuds du cluster et une autre permettant aux nœuds du cluster de communiquer entre eux.Si vous n'utilisez pas de réseau VPC partagé, vous devez créer la règle de pare-feu destinée à la communication entre les nœuds, et non aux vérifications de l'état. Le modèle Deployment Manager crée la règle de pare-feu destinée aux vérifications de l'état, que vous pouvez modifier une fois le déploiement terminé, si nécessaire.
Si vous utilisez un réseau VPC partagé, un administrateur réseau doit créer les deux règles de pare-feu dans le projet hôte.
Vous pouvez également créer une règle de pare-feu pour autoriser l'accès externe à des ports spécifiés ou pour limiter l'accès entre plusieurs VM d'un même réseau. Si le type de réseau VPC default est utilisé, d'autres règles par défaut s'appliquent également, telles que la règle default-allow-internal, qui permet la connectivité entre les VM d'un même réseau sur tous les ports.
En fonction de la stratégie informatique applicable à votre environnement, vous devrez peut-être isoler votre hôte de base de données, ou en restreindre la connectivité, en créant des règles de pare-feu.
Selon votre scénario, vous pouvez créer des règles de pare-feu afin d'autoriser l'accès pour ce qui suit :
- Ports SAP par défaut répertoriés dans le tableau listant les ports TCP/IP de tous les produits SAP.
- Connexions à partir de votre ordinateur ou de votre environnement de réseau d'entreprise à votre instance de VM Compute Engine. Si vous ne savez pas quelle adresse IP utiliser, contactez l'administrateur réseau de votre entreprise.
- Connexions SSH à votre instance de VM, y compris les connexions SSH-in-browser.
- Connexion à votre VM à l'aide d'un outil tiers sous Linux. Créez une règle autorisant l'accès de l'outil via votre pare-feu.
Pour créer une règle de pare-feu, procédez comme suit :
Console
Dans la console Google Cloud , accédez à la page Pare-feu du réseau VPC.
En haut de la page, cliquez sur Créer une règle de pare-feu.
- Dans le champ Réseau, sélectionnez le réseau sur lequel se trouve votre VM.
- Dans le champ Cibles, spécifiez les ressources Google Cloudauxquelles cette règle s'applique. Par exemple, spécifiez Toutes les instances du réseau. Pour limiter la règle à des instances spécifiques sur Google Cloud, saisissez des tags dans le champ Tags cibles spécifiés.
- Dans le champ Filtre source, sélectionnez l'une des options suivantes :
- Plages IP pour autoriser le trafic entrant provenant d'adresses IP spécifiques. Indiquez la plage d'adresses IP dans le champ Plages d'adresses IP sources.
- Sous-réseaux pour autoriser le trafic entrant depuis un sous-réseau particulier. Spécifiez le nom du sous-réseau dans le champ Sous-réseaux qui s'affiche. Utilisez cette option pour autoriser l'accès entre plusieurs VM dans une configuration à trois niveaux ou évolutive.
- Dans la section Protocoles et ports, sélectionnez Protocoles et ports spécifiés, puis saisissez
tcp:PORT_NUMBER.
Cliquez sur Créer pour créer la règle de pare-feu.
gcloud
Créez une règle de pare-feu à l'aide de la commande suivante :
$ gcloud compute firewall-rules create FIREWALL_NAME
--direction=INGRESS --priority=1000 \
--network=NETWORK_NAME --action=ALLOW --rules=PROTOCOL:PORT \
--source-ranges IP_RANGE --target-tags=NETWORK_TAGSCréer un cluster Linux à haute disponibilité avec SAP HANA installé
Les instructions suivantes utilisent Cloud Deployment Manager pour créer un cluster RHEL ou SLES avec deux systèmes SAP HANA : un système SAP HANA principal, à un seul hôte, sur une instance de VM, et un système SAP HANA de secours sur une autre instance de VM de la même région Compute Engine. Les systèmes SAP HANA utilisent la réplication de système synchrone, et le système de secours précharge les données répliquées.
Définissez des options de configuration pour le cluster à haute disponibilité SAP HANA dans un modèle de fichier de configuration Deployment Manager.
Les instructions suivantes utilisent Cloud Shell, mais sont généralement applicables à Google Cloud CLI.
Vérifiez que vos quotas actuels pour les ressources, telles que les disques persistants et les processeurs, sont suffisants pour les systèmes SAP HANA que vous allez installer. Si vos quotas sont insuffisants, le déploiement échoue. Pour connaître les exigences en matière de quotas de SAP HANA, consultez la section Remarques relatives aux tarifs et aux quotas applicables à SAP HANA.
Ouvrez Cloud Shell ou, si vous avez installé Google Cloud SDK sur votre poste de travail local, ouvrez un terminal.
Téléchargez dans votre répertoire de travail le modèle de fichier de configuration
template.yamlpour le cluster SAP HANA à haute disponibilité. Pour ce faire, saisissez la commande suivante dans Cloud Shell ou gcloud CLI :$wget https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/latest/dm-templates/sap_hana_ha_ilb/template.yamlRenommez éventuellement le fichier
template.yamlpour identifier la configuration qu'il définit.Ouvrez le fichier
template.yamldans l'éditeur de code Cloud Shell ou, si vous utilisez gcloud CLI, dans l'éditeur de texte de votre choix.Pour ce faire, cliquez sur l'icône en forme de crayon située dans l'angle supérieur droit de la fenêtre du terminal Cloud Shell.
Dans le fichier
template.yaml, mettez à jour les valeurs de propriété en remplaçant les crochets et leur contenu par les valeurs de votre installation. Ces propriétés sont décrites dans le tableau ci-dessous.Pour créer des instances de VM sans installer SAP HANA, supprimez ou commentez toutes les lignes commençant par
sap_hana_.Propriété Type de données Description typeChaîne Spécifie l'emplacement, le type et la version du modèle Deployment Manager à utiliser lors du déploiement.
Le fichier YAML comprend deux spécifications
type, dont l'une est laissée en commentaire. La spécificationtypequi est active par défaut spécifie la version du modèle en tant quelatest. La spécificationtypequi est laissée en commentaire spécifie une version de modèle spécifique avec un horodatage.Si tous vos déploiements doivent utiliser la même version de modèle, utilisez la spécification
typequi inclut l'horodatage.primaryInstanceNameChaîne Nom de l'instance de VM du système SAP HANA principal. Le nom ne doit contenir que des lettres minuscules, des chiffres ou des traits d'union. secondaryInstanceNameChaîne Nom de l'instance de VM du système SAP HANA secondaire. Le nom ne doit contenir que des lettres minuscules, des chiffres ou des traits d'union. primaryZoneChaîne Zone dans laquelle le système SAP HANA principal est déployé. Les zones principale et secondaire doivent se trouver dans la même région. secondaryZoneChaîne Zone dans laquelle le système SAP HANA secondaire sera déployé. Les zones principale et secondaire doivent se trouver dans la même région. instanceTypeChaîne Type de machine virtuelle Compute Engine nécessaire à l'exécution de SAP HANA. Si vous avez besoin d'un type de VM personnalisé, spécifiez un type de VM prédéfini doté d'un nombre de processeurs virtuels le plus proche possible de la quantité dont vous avez besoin tout en étant légèrement supérieur. Une fois le déploiement terminé, modifiez le nombre de processeurs virtuels et la quantité de mémoire. networkChaîne Nom du réseau dans lequel créer l'équilibreur de charge qui gère l'adresse IP virtuelle. Si vous utilisez un réseau VPC partagé, vous devez ajouter l'ID du projet hôte en guise de répertoire parent du nom du réseau. Par exemple :
host-project-id/network-name.subnetworkChaîne Nom du sous-réseau que vous utilisez pour votre cluster à haute disponibilité. Si vous utilisez un réseau VPC partagé, vous devez ajouter l'ID du projet hôte en guise de répertoire parent du nom du sous-réseau. Par exemple :
host-project-id/subnetwork-name.linuxImageChaîne Nom de la famille d'images ou de l'image du système d'exploitation Linux que vous utilisez avec SAP HANA. Pour spécifier une famille d'images, ajoutez le préfixe family/au nom de la famille. Par exemple,family/rhel-8-2-sap-haoufamily/sles-15-sp2-sap. Pour spécifier une image donnée, indiquez uniquement son nom. Pour obtenir la liste des familles d'images disponibles, consultez la page Images dans Cloud Console.linuxImageProjectChaîne Projet Google Cloudcontenant l'image que vous allez utiliser. Ce projet peut être votre propre projet ou un projet d'image Google Cloud . Pour RHEL, spécifiez rhel-sap-cloud. Pour SLES, spécifiezsuse-sap-cloud. Pour obtenir la liste des projets d'image Google Cloud, consultez la page Images dans la documentation Compute Engine.sap_hana_deployment_bucketChaîne Nom du bucket Cloud Storage de votre projet contenant les fichiers d'installation de SAP HANA que vous avez importés précédemment. sap_hana_sidChaîne ID du système SAP HANA. L'ID doit comporter trois caractères alphanumériques et commencer par une lettre. Les lettres doivent être saisies en majuscules. sap_hana_instance_numberEntier Numéro d'instance (0 à 99) du système SAP HANA. La valeur par défaut est 0. sap_hana_sidadm_passwordChaîne Un mot de passe temporaire à utiliser par l'administrateur du système d'exploitation lors du déploiement. Une fois le déploiement terminé, modifiez le mot de passe. Les mots de passe doivent comporter au moins huit caractères et inclure au moins une lettre majuscule, une lettre minuscule et un chiffre. sap_hana_system_passwordChaîne Un mot de passe temporaire pour le super-utilisateur de la base de données. Une fois le déploiement terminé, modifiez le mot de passe. Les mots de passe doivent comporter au moins huit caractères et inclure au moins une lettre majuscule, une lettre minuscule et un chiffre.. sap_vipChaîne Adresse IP utilisée en guise d'adresse IP virtuelle. L'adresse IP doit être comprise dans la plage d'adresses IP attribuées à votre sous-réseau. Le modèle Deployment Manager réserve cette adresse IP pour vous. Dans un cluster à haute disponibilité actif, cette adresse IP est toujours attribuée à l'instance SAP HANA active. primaryInstanceGroupNameChaîne Définit le nom du groupe d'instances non géré pour le nœud principal. Si vous omettez le paramètre, le nom par défaut est ig-primaryInstanceName.secondaryInstanceGroupNameChaîne Définit le nom du groupe d'instances non géré pour le nœud secondaire. Si vous omettez ce paramètre, le nom par défaut est ig-secondaryInstanceName.loadBalancerNameChaîne Définit le nom de l'équilibreur de charge interne TCP. nic_typeChaîne Facultatif, mais recommandé si disponible pour la machine cible et la version de l'OS. Spécifie l'interface réseau à utiliser avec l'instance de VM. Vous pouvez spécifier la valeur GVNICouVIRTIO_NET. Pour utiliser une carte d'interface réseau virtuelle Google (gVNIC), vous devez spécifier une image de l'OS compatible avec gVNIC comme valeur de la propriétélinuxImage. Pour obtenir la liste des images de l'OS, consultez la section Détails des systèmes d'exploitation.Si vous ne spécifiez pas de valeur pour cette propriété, l'interface réseau est automatiquement sélectionnée en fonction du type de machine que vous spécifiez pour la propriété
Cet argument est disponible dans les versionsinstanceType.202302060649du modèle Deployment Manager ou ultérieures.Les exemples suivants montrent un modèle de fichier de configuration terminé qui définit un cluster à haute disponibilité pour SAP HANA. Le cluster gère les adresses IP virtuelles à l'aide d'un équilibreur de charge réseau passthrough interne.
Deployment Manager déploie les ressources Google Clouddéfinies dans le fichier de configuration, puis les scripts prennent le relais pour configurer le système d'exploitation, installer SAP HANA, configurer la réplication et configurer le cluster Linux à haute disponibilité.
Cliquez sur
RHELouSLESpour afficher l'exemple spécifique à votre système d'exploitation.RHEL
resources: - name: sap_hana_ha type: https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/latest/dm-templates/sap_hana_ha_ilb/sap_hana_ha.py # # By default, this configuration file uses the latest release of the deployment # scripts for SAP on Google Cloud. To fix your deployments to a specific release # of the scripts, comment out the type property above and uncomment the type property below. # # type: https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/yyyymmddhhmm/dm-templates/sap_hana_ha_ilb/sap_hana_ha.py # properties: primaryInstanceName: example-ha-vm1 secondaryInstanceName: example-ha-vm2 primaryZone: us-central1-a secondaryZone: us-central1-c instanceType: n2-highmem-32 network: example-network subnetwork: example-subnet-us-central1 linuxImage: family/rhel-8-1-sap-ha linuxImageProject: rhel-sap-cloud # SAP HANA parameters sap_hana_deployment_bucket: my-hana-bucket sap_hana_sid: HA1 sap_hana_instance_number: 00 sap_hana_sidadm_password: TempPa55word sap_hana_system_password: TempPa55word # VIP parameters sap_vip: 10.0.0.100 primaryInstanceGroupName: ig-example-ha-vm1 secondaryInstanceGroupName: ig-example-ha-vm2 loadBalancerName: lb-ha1 # Additional optional properties networkTag: hana-ha-ntwk-tag serviceAccount: sap-deploy-example@example-project-123456.SLES
resources: - name: sap_hana_ha type: https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/latest/dm-templates/sap_hana_ha_ilb/sap_hana_ha.py # # By default, this configuration file uses the latest release of the deployment # scripts for SAP on Google Cloud. To fix your deployments to a specific release # of the scripts, comment out the type property above and uncomment the type property below. # # type: https://storage.googleapis.com/cloudsapdeploy/deploymentmanager/yyyymmddhhmm/dm-templates/sap_hana_ha_ilb/sap_hana_ha.py # properties: primaryInstanceName: example-ha-vm1 secondaryInstanceName: example-ha-vm2 primaryZone: us-central1-a secondaryZone: us-central1-c instanceType: n2-highmem-32 network: example-network subnetwork: example-subnet-us-central1 linuxImage: family/sles-15-sp1-sap linuxImageProject: suse-sap-cloud # SAP HANA parameters sap_hana_deployment_bucket: my-hana-bucket sap_hana_sid: HA1 sap_hana_instance_number: 00 sap_hana_sidadm_password: TempPa55word sap_hana_system_password: TempPa55word # VIP parameters sap_vip: 10.0.0.100 primaryInstanceGroupName: ig-example-ha-vm1 secondaryInstanceGroupName: ig-example-ha-vm2 loadBalancerName: lb-ha1 # Additional optional properties networkTag: hana-ha-ntwk-tag serviceAccount: sap-deploy-example@example-project-123456.Créez les instances :
$gcloud deployment-manager deployments create deployment-name --config template-name.yamlLa commande ci-dessus appelle Deployment Manager, qui configure l'infrastructure Google Cloud , puis contrôle manuellement un script qui installe et configure SAP HANA et le cluster à haute disponibilité.
Lorsque Deployment Manager exerce un contrôle, les messages d'état sont écrits dans Cloud Shell. Une fois les scripts appelés, les messages d'état sont écrits dans Logging et peuvent être consultés dans la console Google Cloud , comme décrit dans la section Vérifier les journaux.
La durée d'exécution peut varier, mais l'ensemble du processus prend généralement moins de 30 minutes.
Vérifier le déploiement de votre système à haute disponibilité HANA
La vérification d'un cluster à haute disponibilité SAP HANA implique plusieurs procédures différentes :
- Vérifier la journalisation
- Vérifier la configuration de la VM et l'installation de SAP HANA
- Vérifier la configuration du cluster
- Vérifier l'équilibreur de charge et l'état des groupes d'instances
- Vérifier le système SAP HANA à l'aide de SAP HANA Studio
- Effectuer un test de basculement
Vérifier les journaux
Dans la console Google Cloud , ouvrez Cloud Logging pour surveiller la progression de l'installation et rechercher les erreurs.
Filtrez les journaux :
Explorateur de journaux
Sur la page Explorateur de journaux, accédez au volet Requête.
Dans le menu déroulant Ressource, sélectionnez Global, puis cliquez sur Ajouter.
Si l'option Global n'apparaît pas, saisissez la requête suivante dans l'éditeur de requête :
resource.type="global" "Deployment"Cliquez sur Exécuter la requête.
Ancienne visionneuse de journaux
- Sur la page Ancienne visionneuse de journaux, dans le menu de sélection de base, sélectionnez Global comme ressource de journalisation.
Analysez les journaux filtrés :
- Si
"--- Finished"s'affiche, le traitement du déploiement est terminé, et vous pouvez passer à l'étape suivante. Si vous rencontrez une erreur de quota :
Sur la page Quotas de IAM & Admin, augmentez les quotas qui ne répondent pas aux exigences de SAP HANA décrites dans le guide de planification SAP HANA.
Sur la page Déploiements de Deployment Manager, supprimez le déploiement pour nettoyer les VM et les disques persistants de l'installation ayant échoué.
Réexécutez le déploiement.
- Si
Vérifier la configuration de la VM et l'installation de SAP HANA
Une fois le système SAP HANA déployé sans erreur, connectez-vous à chaque VM à l'aide du protocole SSH. Sur la page VM instances (Instances de VM) de Compute Engine, cliquez sur le bouton SSH de votre instance de VM ou utilisez la méthode SSH de votre choix.

Connectez-vous en tant qu'utilisateur racine.
sudo su -
À l'invite de commande, saisissez
df -h. Assurez-vous d'obtenir un résultat comprenant les répertoires/hana, par exemple/hana/data.RHEL
[root@example-ha-vm1 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 0 126G 0% /dev tmpfs 126G 54M 126G 1% /dev/shm tmpfs 126G 25M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda2 30G 5.4G 25G 18% / /dev/sda1 200M 6.9M 193M 4% /boot/efi /dev/mapper/vg_hana-shared 251G 52G 200G 21% /hana/shared /dev/mapper/vg_hana-sap 32G 477M 32G 2% /usr/sap /dev/mapper/vg_hana-data 426G 9.8G 417G 3% /hana/data /dev/mapper/vg_hana-log 125G 7.0G 118G 6% /hana/log /dev/mapper/vg_hanabackup-backup 512G 9.3G 503G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/899 tmpfs 26G 0 26G 0% /run/user/1003
SLES
example-ha-vm1:~ # df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 126G 8.0K 126G 1% /dev tmpfs 189G 54M 189G 1% /dev/shm tmpfs 126G 34M 126G 1% /run tmpfs 126G 0 126G 0% /sys/fs/cgroup /dev/sda3 30G 5.4G 25G 18% / /dev/sda2 20M 2.9M 18M 15% /boot/efi /dev/mapper/vg_hana-shared 251G 50G 202G 20% /hana/shared /dev/mapper/vg_hana-sap 32G 281M 32G 1% /usr/sap /dev/mapper/vg_hana-data 426G 8.0G 418G 2% /hana/data /dev/mapper/vg_hana-log 125G 4.3G 121G 4% /hana/log /dev/mapper/vg_hanabackup-backup 512G 6.4G 506G 2% /hanabackup tmpfs 26G 0 26G 0% /run/user/473 tmpfs 26G 0 26G 0% /run/user/900 tmpfs 26G 0 26G 0% /run/user/0 tmpfs 26G 0 26G 0% /run/user/1003
Vérifiez l'état du nouveau cluster en saisissant la commande d'état spécifique à votre système d'exploitation :
RHEL
pcs statusSLES
crm statusUn résultat semblable à l'exemple suivant devrait s'afficher, dans lequel les deux instances de VM sont démarrées, et où
example-ha-vm1correspond à l'instance principale active :RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.4-4b1f869f0f) - partition with quorum * Last updated: Wed Jul 7 23:05:11 2021 * Last change: Wed Jul 7 23:04:43 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ] Failed Resource Actions: * rsc_healthcheck_HA1_start_0 on example-ha-vm1 'error' (1): call=29, status='complete', exitreason='', last-rc-change='2021-07-07 21:07:35Z', queued=0ms, exec=2097ms * SAPHana_HA1_00_monitor_61000 on example-ha-vm1 'not running' (7): call=44, status='complete', exitreason='', last-rc-change='2021-07-07 21:09:49Z', queued=0ms, exec=0ms Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledSLES
example-ha-vm1:~ # crm status Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Wed Jul 7 22:57:59 2021 * Last change: Wed Jul 7 22:57:03 2021 by root via crm_attribute on example-ha-vm1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:external/gcpstonith): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:external/gcpstonith): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm1 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm1 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm1 ] * Slaves: [ example-ha-vm2 ]Connectez-vous en tant qu'administrateur SAP en remplaçant
SID_LCdans la commande suivante par la valeur SID que vous avez spécifiée dans le modèle de fichier de configuration. Utilisez des minuscules pour toutes les lettres.su - SID_LCadmAssurez-vous que les services SAP HANA, tels que
hdbnameserver,hdbindexserveret autres services, s'exécutent sur l'instance en saisissant la commande suivante :HDB infoSi vous utilisez RHEL pour SAP 9.0 ou une version ultérieure, assurez-vous que les packages
chkconfigetcompat-openssl11sont installés sur votre instance de VM.Pour en savoir plus, consultez la note SAP 3108316 – Red Hat Enterprise Linux 9.x : installation et configuration.
Vérifier la configuration du cluster
Vérifiez les paramètres du cluster. Vérifiez les paramètres affichés par le logiciel du cluster et les paramètres qui s'affichent dans le fichier de configuration du cluster. Comparez vos paramètres aux paramètres des exemples ci-dessous, qui ont été créés par les scripts d'automatisation utilisés dans ce guide.
Cliquez sur l'onglet correspondant à votre système d'exploitation.
RHEL
Affichez les configurations des ressources du cluster :
pcs config show
L'exemple suivant présente les configurations de ressources créées par les scripts d'automatisation sur RHEL 8.1 et versions ultérieures.
Si vous exécutez RHEL 7.7 ou une version antérieure, la définition de la ressource
Clone: SAPHana_HA1_00-clonen'inclut pasMeta Attrs: promotable=true.Cluster Name: hacluster Corosync Nodes: example-rha-vm1 example-rha-vm2 Pacemaker Nodes: example-rha-vm1 example-rha-vm2 Resources: Group: g-primary Resource: rsc_healthcheck_HA1 (class=service type=haproxy) Operations: monitor interval=10s timeout=20s (rsc_healthcheck_HA1-monitor-interval-10s) start interval=0s timeout=100 (rsc_healthcheck_HA1-start-interval-0s) stop interval=0s timeout=100 (rsc_healthcheck_HA1-stop-interval-0s) Resource: rsc_vip_HA1_00 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=32 ip=10.128.15.100 nic=eth0 Operations: monitor interval=3600s timeout=60s (rsc_vip_HA1_00-monitor-interval-3600s) start interval=0s timeout=20s (rsc_vip_HA1_00-start-interval-0s) stop interval=0s timeout=20s (rsc_vip_HA1_00-stop-interval-0s) Clone: SAPHanaTopology_HA1_00-clone Meta Attrs: clone-max=2 clone-node-max=1 interleave=true Resource: SAPHanaTopology_HA1_00 (class=ocf provider=heartbeat type=SAPHanaTopology) Attributes: InstanceNumber=00 SID=HA1 Operations: methods interval=0s timeout=5 (SAPHanaTopology_HA1_00-methods-interval-0s) monitor interval=10 timeout=600 (SAPHanaTopology_HA1_00-monitor-interval-10) reload interval=0s timeout=5 (SAPHanaTopology_HA1_00-reload-interval-0s) start interval=0s timeout=600 (SAPHanaTopology_HA1_00-start-interval-0s) stop interval=0s timeout=300 (SAPHanaTopology_HA1_00-stop-interval-0s) Clone: SAPHana_HA1_00-clone Meta Attrs: promotable=true Resource: SAPHana_HA1_00 (class=ocf provider=heartbeat type=SAPHana) Attributes: AUTOMATED_REGISTER=true DUPLICATE_PRIMARY_TIMEOUT=7200 InstanceNumber=00 PREFER_SITE_TAKEOVER=true SID=HA1 Meta Attrs: clone-max=2 clone-node-max=1 interleave=true notify=true Operations: demote interval=0s timeout=3600 (SAPHana_HA1_00-demote-interval-0s) methods interval=0s timeout=5 (SAPHana_HA1_00-methods-interval-0s) monitor interval=61 role=Slave timeout=700 (SAPHana_HA1_00-monitor-interval-61) monitor interval=59 role=Master timeout=700 (SAPHana_HA1_00-monitor-interval-59) promote interval=0s timeout=3600 (SAPHana_HA1_00-promote-interval-0s) reload interval=0s timeout=5 (SAPHana_HA1_00-reload-interval-0s) start interval=0s timeout=3600 (SAPHana_HA1_00-start-interval-0s) stop interval=0s timeout=3600 (SAPHana_HA1_00-stop-interval-0s) Stonith Devices: Resource: STONITH-example-rha-vm1 (class=stonith type=fence_gce) Attributes: pcmk_delay_max=30 pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm1 project=sap-certification-env zone=us-central1-a Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm1-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm1-start-interval-0) Resource: STONITH-example-rha-vm2 (class=stonith type=fence_gce) Attributes: pcmk_monitor_retries=4 pcmk_reboot_timeout=300 port=example-rha-vm2 project=sap-certification-env zone=us-central1-c Operations: monitor interval=300s timeout=120s (STONITH-example-rha-vm2-monitor-interval-300s) start interval=0 timeout=60s (STONITH-example-rha-vm2-start-interval-0) Fencing Levels: Location Constraints: Resource: STONITH-example-rha-vm1 Disabled on: example-rha-vm1 (score:-INFINITY) (id:location-STONITH-example-rha-vm1-example-rha-vm1--INFINITY) Resource: STONITH-example-rha-vm2 Disabled on: example-rha-vm2 (score:-INFINITY) (id:location-STONITH-example-rha-vm2-example-rha-vm2--INFINITY) Ordering Constraints: start SAPHanaTopology_HA1_00-clone then start SAPHana_HA1_00-clone (kind:Mandatory) (non-symmetrical) (id:order-SAPHanaTopology_HA1_00-clone-SAPHana_HA1_00-clone-mandatory) Colocation Constraints: g-primary with SAPHana_HA1_00-clone (score:4000) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-g-primary-SAPHana_HA1_00-clone-4000) Ticket Constraints: Alerts: No alerts defined Resources Defaults: migration-threshold=5000 resource-stickiness=1000 Operations Defaults: timeout=600s Cluster Properties: cluster-infrastructure: corosync cluster-name: hacluster dc-version: 2.0.2-3.el8_1.2-744a30d655 have-watchdog: false stonith-enabled: true stonith-timeout: 300s Quorum: Options:Affichez le fichier de configuration de votre cluster,
corosync.conf:cat /etc/corosync/corosync.conf
L'exemple suivant présente les paramètres définis par les scripts d'automatisation pour RHEL 8.1 et versions ultérieures.
Si vous utilisez RHEL 7.7 ou une version antérieure, la valeur de
transport:estudpuau lieu deknet:totem { version: 2 cluster_name: hacluster transport: knet join: 60 max_messages: 20 token: 20000 token_retransmits_before_loss_const: 10 crypto_cipher: aes256 crypto_hash: sha256 } nodelist { node { ring0_addr: example-rha-vm1 name: example-rha-vm1 nodeid: 1 } node { ring0_addr: example-rha-vm2 name: example-rha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum two_node: 1 } logging { to_logfile: yes logfile: /var/log/cluster/corosync.log to_syslog: yes timestamp: on }
SLES
Affichez les configurations des ressources du cluster :
crm config show
Les scripts d'automatisation utilisés par ce guide créent les configurations de ressources présentées dans l'exemple suivant :
node 1: example-ha-vm1 \ attributes hana_ha1_op_mode=logreplay lpa_ha1_lpt=1635380335 hana_ha1_srmode=syncmem hana_ha1_vhost=example-ha-vm1 hana_ha1_remoteHost=example-ha-vm2 hana_ha1_site=example-ha-vm1 node 2: example-ha-vm2 \ attributes lpa_ha1_lpt=30 hana_ha1_op_mode=logreplay hana_ha1_vhost=example-ha-vm2 hana_ha1_site=example-ha-vm2 hana_ha1_srmode=syncmem hana_ha1_remoteHost=example-ha-vm1 primitive STONITH-example-ha-vm1 stonith:external/gcpstonith \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params instance_name=example-ha-vm1 gcloud_path="/usr/bin/gcloud" logging=yes pcmk_reboot_timeout=300 pcmk_monitor_retries=4 pcmk_delay_max=30 primitive STONITH-example-ha-vm2 stonith:external/gcpstonith \ op monitor interval=300s timeout=120s \ op start interval=0 timeout=60s \ params instance_name=example-ha-vm2 gcloud_path="/usr/bin/gcloud" logging=yes pcmk_reboot_timeout=300 pcmk_monitor_retries=4 primitive rsc_SAPHanaTopology_HA1_HDB00 ocf:suse:SAPHanaTopology \ operations $id=rsc_sap2_HA1_HDB00-operations \ op monitor interval=10 timeout=600 \ op start interval=0 timeout=600 \ op stop interval=0 timeout=300 \ params SID=HA1 InstanceNumber=00 primitive rsc_SAPHana_HA1_HDB00 ocf:suse:SAPHana \ operations $id=rsc_sap_HA1_HDB00-operations \ op start interval=0 timeout=3600 \ op stop interval=0 timeout=3600 \ op promote interval=0 timeout=3600 \ op demote interval=0 timeout=3600 \ op monitor interval=60 role=Master timeout=700 \ op monitor interval=61 role=Slave timeout=700 \ params SID=HA1 InstanceNumber=00 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=true primitive rsc_vip_hc-primary anything \ params binfile="/usr/bin/socat" cmdline_options="-U TCP-LISTEN:60000,backlog=10,fork,reuseaddr /dev/null" \ op monitor timeout=20s interval=10s \ op_params depth=0 primitive rsc_vip_int-primary IPaddr2 \ params ip=10.128.15.101 cidr_netmask=32 nic=eth0 \ op monitor interval=3600s timeout=60s group g-primary rsc_vip_int-primary rsc_vip_hc-primary ms msl_SAPHana_HA1_HDB00 rsc_SAPHana_HA1_HDB00 \ meta notify=true clone-max=2 clone-node-max=1 target-role=Started interleave=true clone cln_SAPHanaTopology_HA1_HDB00 rsc_SAPHanaTopology_HA1_HDB00 \ meta clone-node-max=1 target-role=Started interleave=true location LOC_STONITH_example-ha-vm1 STONITH-example-ha-vm1 -inf: example-ha-vm1 location LOC_STONITH_example-ha-vm2 STONITH-example-ha-vm2 -inf: example-ha-vm2 colocation col_saphana_ip_HA1_HDB00 4000: g-primary:Started msl_SAPHana_HA1_HDB00:Master order ord_SAPHana_HA1_HDB00 Optional: cln_SAPHanaTopology_HA1_HDB00 msl_SAPHana_HA1_HDB00 property cib-bootstrap-options: \ have-watchdog=false \ dc-version="1.1.24+20210811.f5abda0ee-3.18.1-1.1.24+20210811.f5abda0ee" \ cluster-infrastructure=corosync \ cluster-name=hacluster \ maintenance-mode=false \ stonith-timeout=300s \ stonith-enabled=true rsc_defaults rsc-options: \ resource-stickiness=1000 \ migration-threshold=5000 op_defaults op-options: \ timeout=600Affichez le fichier de configuration de votre cluster,
corosync.conf:cat /etc/corosync/corosync.conf
Les scripts d'automatisation utilisés par ce guide spécifient les paramètres dans le fichier
corosync.conf, comme indiqué dans l'exemple suivant :totem { version: 2 secauth: off crypto_hash: sha1 crypto_cipher: aes256 cluster_name: hacluster clear_node_high_bit: yes token: 20000 token_retransmits_before_loss_const: 10 join: 60 max_messages: 20 transport: udpu interface { ringnumber: 0 bindnetaddr: 10.128.1.63 mcastport: 5405 ttl: 1 } } logging { fileline: off to_stderr: no to_logfile: no logfile: /var/log/cluster/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } nodelist { node { ring0_addr: example-ha-vm1 nodeid: 1 } node { ring0_addr: example-ha-vm2 nodeid: 2 } } quorum { provider: corosync_votequorum expected_votes: 2 two_node: 1 }
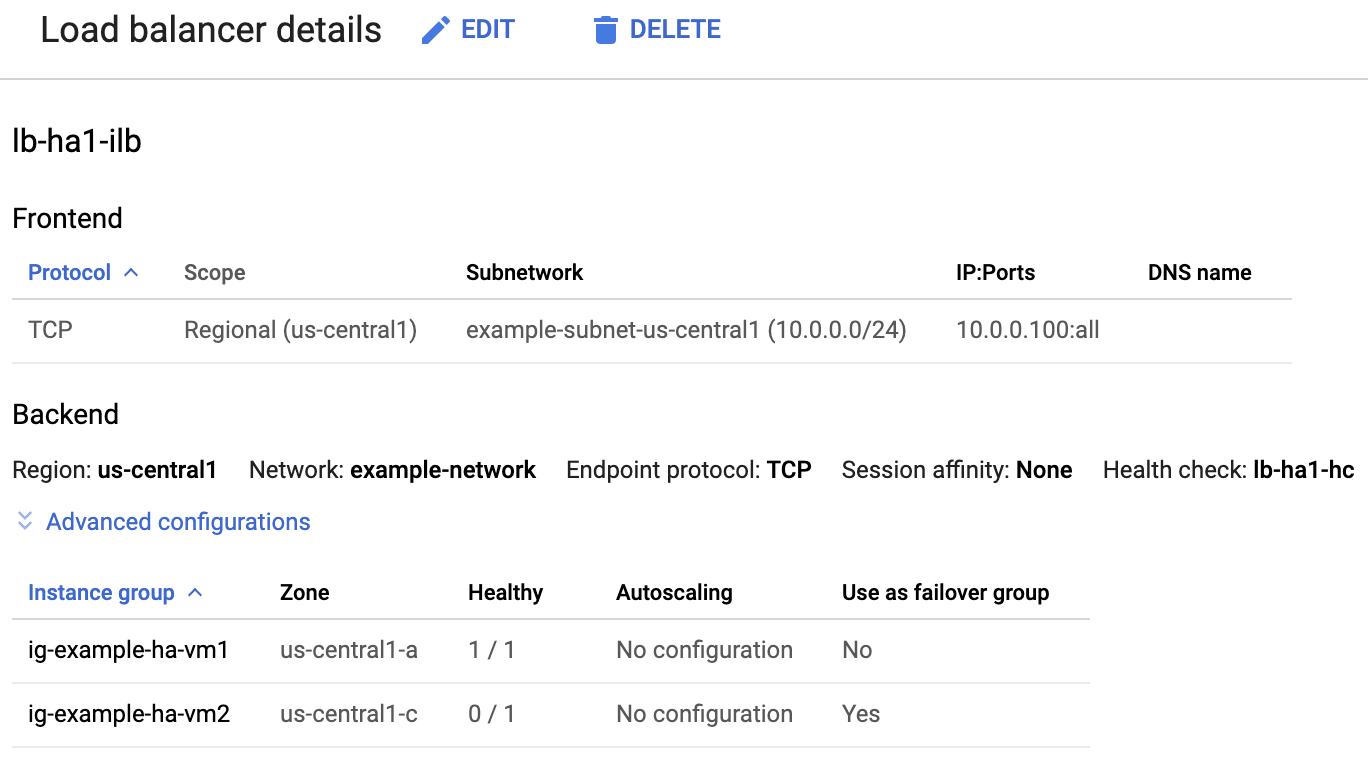
Vérifier l'équilibreur de charge et l'état des groupes d'instances
Pour vérifier que l'équilibreur de charge et la vérification de l'état ont été correctement configurés, vérifiez l'équilibreur de charge et les groupes d'instances dans la console Google Cloud .
Ouvrez la page Équilibrage de charge dans la console Google Cloud :
Dans la liste des équilibreurs de charge, vérifiez qu'un équilibreur de charge a été créé pour votre cluster à haute disponibilité.
Sur la page d'Informations sur l'équilibreur de charge, dans la colonne Opérationnel sous Groupe d'instances, dans la section Backend, confirmez que l'un des groupes d'instances indique "1/1" et l'autre "0/1". Après un failover, l'indicateur opérationnel "1/1" bascule sur le nouveau groupe d'instances actif.
Vérifier le système SAP HANA à l'aide de SAP HANA Studio
Vous pouvez utiliser SAP HANA Cockpit ou SAP HANA Studio pour surveiller et gérer vos systèmes SAP HANA dans un cluster à haute disponibilité.
Connectez-vous au système HANA à l'aide de SAP HANA Studio. Lors de la définition de la connexion, spécifiez les valeurs suivantes :
- Dans le volet "Specify System" (Spécifier le système), spécifiez l'adresse IP flottante comme nom d'hôte.
- Dans le volet "Connection Properties" (Propriétés de connexion), pour l'authentification de l'utilisateur de la base de données, spécifiez le nom de super-utilisateur de la base de données, ainsi que le mot de passe que vous avez spécifié pour la propriété sap_hana_system_password dans le fichier template.yaml.
Pour en savoir plus sur l'installation de SAP HANA Studio, consultez sur le site de SAP le Guide d'installation et de mise à jour de SAP HANA Studio.
Une fois SAP HANA Studio connecté à votre système à haute disponibilité HANA, affichez la vue d'ensemble du système en double-cliquant sur le nom du système dans le volet de navigation situé sur la gauche de la fenêtre.
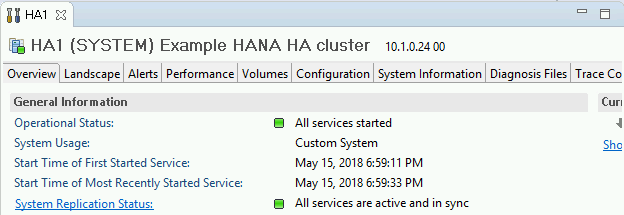
Dans l'onglet "Overview" (Aperçu), sous "General Information" (Informations générales), vérifiez les éléments suivants :
- L'élément "Operational Status" (État opérationnel) indique "All services started" (Tous les services sont démarrés).
- L'élément "System Replication Status" (État de la réplication du système) indique "All services are active and in sync" (Tous les services sont actifs et synchronisés).
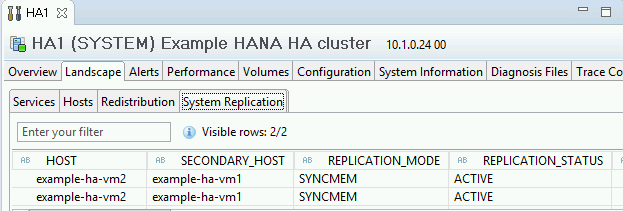
Confirmez le mode de réplication en cliquant sur le lien System Replication Status (État de la réplication du système) sous "General Information" (Informations générales). La réplication synchrone est indiquée par
SYNCMEMdans la colonne REPLICATION_MODE (Mode de réplication) de l'onglet "System Replication" (Réplication système).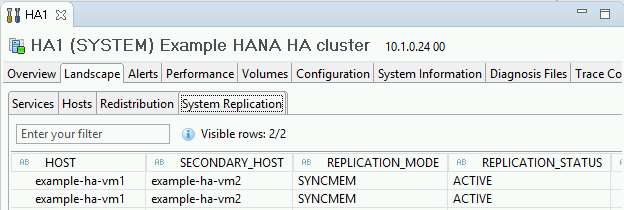
Si l'une des étapes de validation indique que l'installation a échoué, procédez comme suit :
- Corrigez les erreurs.
- Supprimez le déploiement de la page Déploiements.
- Recréez les instances, tel que décrit à la dernière étape de la section précédente.
Effectuer un test de basculement
Pour effectuer un test de basculement, procédez comme suit :
Connectez-vous à la VM principale à l'aide de SSH. Vous pouvez vous connecter à partir de la page Instances de VM de Compute Engine en cliquant sur le bouton "SSH" de chaque instance de VM. Vous avez également la possibilité d'utiliser la méthode SSH de votre choix.
À l'invite, saisissez la commande suivante :
sudo ip link set eth0 down
La commande
ip link set eth0 downdéclenche un basculement en coupant les communications avec l'hôte principal.Reconnectez-vous à l'un des hôtes à l'aide de SSH, puis connectez-vous en tant qu'utilisateur racine.
Confirmez que l'hôte principal est désormais actif sur la VM qui contenait l'hôte secondaire. Le redémarrage automatique est activé dans le cluster. Par conséquent, l'hôte arrêté redémarre et prend le rôle d'hôte secondaire.
RHEL
pcs statusSLES
crm statusLes exemples suivants montrent que les rôles de chaque hôte ont été inversés.
RHEL
[root@example-ha-vm1 ~]# pcs status Cluster name: hacluster Cluster Summary: * Stack: corosync * Current DC: example-ha-vm1 (version 2.0.3-5.el8_2.3-4b1f869f0f) - partition with quorum * Last updated: Fri Mar 19 21:22:07 2021 * Last change: Fri Mar 19 21:21:28 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:fence_gce): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:fence_gce): Started example-ha-vm1 * Resource Group: g-primary: * rsc_healthcheck_HA1 (service:haproxy): Started example-ha-vm2 * rsc_vip_HA1_00 (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * Clone Set: SAPHanaTopology_HA1_00-clone [SAPHanaTopology_HA1_00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: SAPHana_HA1_00-clone [SAPHana_HA1_00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]SLES
example-ha-vm2:~ # Cluster Summary: * Stack: corosync * Current DC: example-ha-vm2 (version 2.0.4+20200616.2deceaa3a-3.9.1-2.0.4+20200616.2deceaa3a) - partition with quorum * Last updated: Thu Jul 8 17:33:44 2021 * Last change: Thu Jul 8 17:33:07 2021 by root via crm_attribute on example-ha-vm2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ example-ha-vm1 example-ha-vm2 ] Full List of Resources: * STONITH-example-ha-vm1 (stonith:external/gcpstonith): Started example-ha-vm2 * STONITH-example-ha-vm2 (stonith:external/gcpstonith): Started example-ha-vm1 * Resource Group: g-primary: * rsc_vip_int-primary (ocf::heartbeat:IPaddr2): Started example-ha-vm2 * rsc_vip_hc-primary (ocf::heartbeat:anything): Started example-ha-vm2 * Clone Set: cln_SAPHanaTopology_HA1_HDB00 [rsc_SAPHanaTopology_HA1_HDB00]: * Started: [ example-ha-vm1 example-ha-vm2 ] * Clone Set: msl_SAPHana_HA1_HDB00 [rsc_SAPHana_HA1_HDB00] (promotable): * Masters: [ example-ha-vm2 ] * Slaves: [ example-ha-vm1 ]Sur la page d'informations sur l'équilibreur de charge de la console, confirmez que la nouvelle instance principale active affiche "1/1" dans la colonne Opérationnel. Rechargez la page si nécessaire.
Accéder à Cloud Load Balancing
Exemple :

Dans SAP HANA Studio, confirmez que vous êtes toujours connecté au système en double-cliquant sur l'entrée du système dans le volet de navigation afin d'actualiser les informations système.
Cliquez sur le lien System Replication Status (État de la réplication du système) pour confirmer que les hôtes principal et secondaire ont changé de VM et sont actifs.
Vérifier l'installation de l'agent Google Cloudpour SAP
Après avoir déployé une VM et installé le système SAP, vérifiez que l'agentGoogle Cloudpour SAP fonctionne correctement.
Vérifier que l'agent pour SAP de Google Cloudest en cours d'exécution
Pour vérifier que l'agent est en cours d'exécution, procédez comme suit :
Établissez une connexion SSH avec votre instance Compute Engine.
Exécutez la commande suivante :
systemctl status google-cloud-sap-agent
Si l'agent fonctionne correctement, la sortie contient
active (running). Exemple :google-cloud-sap-agent.service - Google Cloud Agent for SAP Loaded: loaded (/usr/lib/systemd/system/google-cloud-sap-agent.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2022-12-02 07:21:42 UTC; 4 days ago Main PID: 1337673 (google-cloud-sa) Tasks: 9 (limit: 100427) Memory: 22.4 M (max: 1.0G limit: 1.0G) CGroup: /system.slice/google-cloud-sap-agent.service └─1337673 /usr/bin/google-cloud-sap-agent
Si l'agent n'est pas en cours d'exécution, redémarrez-le.
Vérifier que l'agent hôte SAP reçoit les métriques
Pour vérifier que les métriques d'infrastructure sont collectées par l'agentGoogle Cloudpour SAP et envoyées correctement à l'agent hôte SAP, procédez comme suit:
- Dans votre système SAP, saisissez la transaction
ST06. Dans le volet de synthèse, vérifiez la disponibilité et le contenu des champs suivants pour vous assurer de la configuration de façon correcte et complète de l'infrastructure de surveillance SAP et Google :
- Fournisseur cloud :
Google Cloud Platform - Accès à la surveillance améliorée :
TRUE - Détails de la surveillance améliorée :
ACTIVE
- Fournisseur cloud :
Configurer la surveillance pour SAP HANA
Vous pouvez éventuellement surveiller vos instances SAP HANA à l'aide de l'agentGoogle Cloudpour SAP. À partir de la version 2.0, vous pouvez configurer l'agent de sorte qu'il collecte les métriques de surveillance SAP HANA et les envoie à Cloud Monitoring. Cloud Monitoring vous permet de créer des tableaux de bord pour visualiser ces métriques, de configurer des alertes en fonction de seuils de métriques, etc.
Pour surveiller un cluster à haute disponibilité à l'aide de l'agent Google Cloudpour SAP, veillez à suivre les instructions fournies sur la page Configuration de la haute disponibilité pour l'agent.Pour en savoir plus sur la collecte des métriques de surveillance SAP HANA à l'aide de l'agentGoogle Cloudpour SAP, consultez Collecte des métriques de surveillance SAP HANA.
Activer le redémarrage rapide de SAP HANA
Google Cloud Nous vous recommandons vivement d'activer le redémarrage rapide SAP HANA pour chaque instance de SAP HANA, en particulier pour les instances de grande capacité. Le redémarrage rapide de SAP HANA réduit le temps de redémarrage en cas d'arrêt de SAP HANA, mais le système d'exploitation reste en cours d'exécution.
Comme configuré par les scripts d'automatisation fournis par Google Cloud , les paramètres du système d'exploitation et du noyau sont déjà compatibles avec le redémarrage rapide de SAP HANA.
Vous devez définir le système de fichiers tmpfs et configurer SAP HANA.
Pour définir le système de fichiers tmpfs et configurer SAP HANA, vous pouvez suivre les étapes manuelles ou utiliser le script d'automatisation fourni parGoogle Cloud pour activer le redémarrage rapide de SAP HANA. Pour en savoir plus, consultez les pages suivantes :
- Étapes manuelles : Activer le redémarrage rapide de SAP HANA
- Étapes automatisées : Activer le redémarrage rapide de SAP HANA
Pour obtenir des instructions faisant autorité sur la fonction de redémarrage rapide SAP HANA, consultez la documentation sur les options de redémarrage rapide de SAP HANA.
Étapes manuelles
Configurer le système de fichiers tmpfs
Une fois les VM hôtes et les systèmes SAP HANA de base déployés, vous devez créer et installer des répertoires pour les nœuds NUMA du système de fichiers tmpfs.
Afficher la topologie NUMA de votre VM
Pour pouvoir mapper le système de fichiers tmpfs requis, vous devez connaître la quantité de nœuds NUMA dont dispose votre VM. Pour afficher les nœuds NUMA disponibles sur une VM Compute Engine, saisissez la commande suivante :
lscpu | grep NUMA
Par exemple, un type de VM m2-ultramem-208 comporte quatre nœuds NUMA, numérotés de 0 à 3, comme illustré dans l'exemple suivant :
NUMA node(s): 4 NUMA node0 CPU(s): 0-25,104-129 NUMA node1 CPU(s): 26-51,130-155 NUMA node2 CPU(s): 52-77,156-181 NUMA node3 CPU(s): 78-103,182-207
Créer les répertoires de nœuds NUMA
Créez un répertoire pour chaque nœud NUMA de votre VM et définissez les autorisations.
Par exemple, pour quatre nœuds NUMA numérotés de 0 à 3 :
mkdir -pv /hana/tmpfs{0..3}/SID
chown -R SID_LCadm:sapsys /hana/tmpfs*/SID
chmod 777 -R /hana/tmpfs*/SIDInstaller les répertoires de nœuds NUMA dans tmpfs
Montez les répertoires du système de fichiers tmpfs et spécifiez une préférence de nœud NUMA pour chacun avec mpol=prefer :
SID : spécifiez le SID en majuscules.
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0 /hana/tmpfs0/SID mount tmpfsSID1 -t tmpfs -o mpol=prefer:1 /hana/tmpfs1/SID mount tmpfsSID2 -t tmpfs -o mpol=prefer:2 /hana/tmpfs2/SID mount tmpfsSID3 -t tmpfs -o mpol=prefer:3 /hana/tmpfs3/SID
Mettre à jour /etc/fstab
Pour vous assurer que les points d'installation sont disponibles après un redémarrage du système d'exploitation, ajoutez des entrées dans la table du système de fichiers, /etc/fstab :
tmpfsSID0 /hana/tmpfs0/SID tmpfs rw,nofail,relatime,mpol=prefer:0 tmpfsSID1 /hana/tmpfs1/SID tmpfs rw,nofail,relatime,mpol=prefer:1 tmpfsSID1 /hana/tmpfs2/SID tmpfs rw,nofail,relatime,mpol=prefer:2 tmpfsSID1 /hana/tmpfs3/SID tmpfs rw,nofail,relatime,mpol=prefer:3
Facultatif : définir des limites à l'utilisation de la mémoire
Le système de fichiers tmpfs peut augmenter ou diminuer de manière dynamique.
Pour limiter la mémoire utilisée par le système de fichiers tmpfs, vous pouvez définir une limite de taille pour un volume de nœuds NUMA en utilisant l'option size.
Exemple :
mount tmpfsSID0 -t tmpfs -o mpol=prefer:0,size=250G /hana/tmpfs0/SID
Vous pouvez également limiter l'utilisation globale de la mémoire tmpfs pour tous les nœuds NUMA d'une instance SAP HANA donnée et d'un nœud de serveur donné en définissant le paramètre persistent_memory_global_allocation_limit dans la section [memorymanager] du fichier global.ini.
Configuration de SAP HANA pour le redémarrage rapide
Pour configurer SAP HANA pour le redémarrage rapide, mettez à jour le fichier global.ini et spécifiez les tables à stocker dans la mémoire persistante.
Mettre à jour la section [persistence] du fichier global.ini
Configurez la section [persistence] du fichier SAP HANA global.ini de manière à référencer les emplacements tmpfs. Séparez chaque emplacement tmpfs par un point-virgule :
[persistence] basepath_datavolumes = /hana/data basepath_logvolumes = /hana/log basepath_persistent_memory_volumes = /hana/tmpfs0/SID;/hana/tmpfs1/SID;/hana/tmpfs2/SID;/hana/tmpfs3/SID
L'exemple précédent spécifie quatre volumes de mémoire pour quatre nœuds NUMA, ce qui correspond à m2-ultramem-208. Si vous l'exécutez sur m2-ultramem-416, vous devez configurer huit volumes de mémoire (de 0 à 7).
Redémarrez SAP HANA après avoir modifié le fichier global.ini.
SAP HANA peut désormais utiliser l'emplacement tmpfs comme espace de mémoire persistant.
Spécifier les tables à stocker en mémoire persistante
Spécifiez des tables ou partitions de colonne spécifiques à stocker en mémoire persistante.
Par exemple, pour activer la mémoire persistante pour une table existante, exécutez la requête SQL :
ALTER TABLE exampletable persistent memory ON immediate CASCADE
Pour modifier la valeur par défaut des nouvelles tables, ajoutez le paramètre table_default dans le fichier indexserver.ini. Exemple :
[persistent_memory] table_default = ON
Pour en savoir plus sur le contrôle des colonnes et des tables ainsi que sur les vues de surveillance qui fournissent des informations détaillées, consultez la page Mémoire persistante SAP HANA.
Étapes automatisées
Le script d'automatisation fourni par Google Cloud pour activer le redémarrage rapide de SAP HANA apporte des modifications aux répertoires /hana/tmpfs*, au fichier /etc/fstab et à la configuration de SAP HANA. Google Cloud Lorsque vous exécuterez le script, vous devrez peut-être effectuer des étapes supplémentaires selon qu'il s'agit du déploiement initial de votre système SAP HANA ou que vous redimensionnez votre machine sur une autre taille NUMA.
Pour le déploiement initial de votre système SAP HANA ou le redimensionnement de la machine pour augmenter le nombre de nœuds NUMA, assurez-vous que SAP HANA est en cours d'exécution pendant l'exécution du script d'automatisation fourni par Google Cloudpour activer le redémarrage rapide de SAP HANA.
Lorsque vous redimensionnez votre machine pour réduire le nombre de nœuds NUMA, assurez-vous que SAP HANA est arrêté pendant l'exécution du script d'automatisation fourni par Google Cloud pour activer le redémarrage rapide de SAP HANA. Une fois le script exécuté, vous devez mettre à jour manuellement la configuration SAP HANA pour terminer la configuration du redémarrage rapide de SAP HANA. Pour en savoir plus, consultez la section Configuration de SAP HANA pour le redémarrage rapide.
Pour activer le redémarrage rapide de SAP HANA, procédez comme suit :
Établissez une connexion SSH avec votre VM hôte.
Passez en mode root :
sudo su -
Téléchargez le script
sap_lib_hdbfr.sh:wget https://storage.googleapis.com/cloudsapdeploy/terraform/latest/terraform/lib/sap_lib_hdbfr.sh
Rendez le fichier exécutable :
chmod +x sap_lib_hdbfr.sh
Vérifiez que le script ne comporte aucune erreur :
vi sap_lib_hdbfr.sh ./sap_lib_hdbfr.sh -help
Si la commande renvoie une erreur, contactez le Cloud Customer Care. Pour savoir comment contacter le service client, consultez la page Obtenir de l'aide pour SAP sur Google Cloud.
Exécutez le script après avoir remplacé l'ID système (SID) et le mot de passe SAP HANA de l'utilisateur système de la base de données SAP HANA. Pour fournir le mot de passe en toute sécurité, nous vous recommandons d'utiliser un secret dans Secret Manager.
Exécutez le script en utilisant le nom d'un secret dans Secret Manager. Ce secret doit exister dans le projet Google Cloud qui contient votre instance de VM hôte.
sudo ./sap_lib_hdbfr.sh -h 'SID' -s SECRET_NAME
Remplacez les éléments suivants :
SID: spécifiez le SID en majuscules. Par exemple,AHA.SECRET_NAME: spécifiez le nom du secret correspondant au mot de passe de l'utilisateur système de la base de données SAP HANA. Ce secret doit exister dans le projet Google Cloud qui contient votre instance de VM hôte.
Vous pouvez également exécuter le script en utilisant un mot de passe en texte brut. Une fois le redémarrage rapide de SAP HANA activé, veillez à modifier votre mot de passe. L'utilisation d'un mot de passe en texte brut n'est pas recommandée, car celui-ci serait enregistré dans l'historique de ligne de commande de votre VM.
sudo ./sap_lib_hdbfr.sh -h 'SID' -p 'PASSWORD'
Remplacez les éléments suivants :
SID: spécifiez le SID en majuscules. Par exemple,AHA.PASSWORD: spécifiez le mot de passe de l'utilisateur système de la base de données SAP HANA.
Dans le cas d'une exécution initiale réussie, vous devez obtenir une sortie semblable à celle-ci :
INFO - Script is running in standalone mode
ls: cannot access '/hana/tmpfs*': No such file or directory
INFO - Setting up HANA Fast Restart for system 'TST/00'.
INFO - Number of NUMA nodes is 2
INFO - Number of directories /hana/tmpfs* is 0
INFO - HANA version 2.57
INFO - No directories /hana/tmpfs* exist. Assuming initial setup.
INFO - Creating 2 directories /hana/tmpfs* and mounting them
INFO - Adding /hana/tmpfs* entries to /etc/fstab. Copy is in /etc/fstab.20220625_030839
INFO - Updating the HANA configuration.
INFO - Running command: select * from dummy
DUMMY
"X"
1 row selected (overall time 4124 usec; server time 130 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistence', 'basepath_persistent_memory_volumes') = '/hana/tmpfs0/TST;/hana/tmpfs1/TST;'
0 rows affected (overall time 3570 usec; server time 2239 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('global.ini', 'SYSTEM') SET ('persistent_memory', 'table_unload_action') = 'retain';
0 rows affected (overall time 4308 usec; server time 2441 usec)
INFO - Running command: ALTER SYSTEM ALTER CONFIGURATION ('indexserver.ini', 'SYSTEM') SET ('persistent_memory', 'table_default') = 'ON';
0 rows affected (overall time 3422 usec; server time 2152 usec)
Configurer l'agent de surveillance Google pour SAP HANA
Si vous le souhaitez, vous pouvez configurer l'agent de surveillance Google pour SAP HANA, qui collecte les métriques de SAP HANA et les envoie à Monitoring. Monitoring vous permet de créer des tableaux de bord pour visualiser vos métriques, de configurer des alertes personnalisées en fonction de seuils de métriques, etc.
Pour surveiller un cluster à haute disponibilité, installez l'agent de surveillance sur une instance de VM en dehors du cluster. Spécifiez l'adresse IP flottante du cluster en tant qu'adresse IP de l'instance hôte à surveiller.
Pour plus d'informations sur la configuration de l'agent de surveillance Google pour SAP HANA, consultez le Guide de l'utilisateur de l'agent de surveillance SAP HANA.
Se connecter à SAP HANA
Étant donné qu'aucune adresse IP externe n'est utilisée pour SAP HANA dans ces instructions, vous ne pouvez vous connecter aux instances SAP HANA que via l'instance bastion à l'aide de SSH ou via le serveur Windows à l'aide de SAP HANA Studio.
Pour vous connecter à SAP HANA via l'instance bastion, connectez-vous à l'hôte bastion, puis aux instances SAP HANA à l'aide du client SSH de votre choix.
Pour vous connecter à la base de données SAP HANA via SAP HANA Studio, utilisez un client Bureau à distance pour vous connecter à l'instance Windows Server. Une fois la connexion établie, installez SAP HANA Studio manuellement, puis accédez à votre base de données SAP HANA.
Configurer HANA actif/actif (lecture activée)
À partir de SAP HANA 2.0 SPS1, vous pouvez configurer HANA actif/actif (lecture activée) dans un cluster Pacemaker. Pour savoir comment procéder, consultez les articles suivants :
- Configurer HANA actif/actif (lecture activée) dans un cluster SUSE Pacemaker
- Configurer HANA actif/actif (lecture activée) dans un cluster Red Hat Pacemaker
Effectuer des tâches post-déploiement
Avant d'utiliser votre instance SAP HANA, nous vous recommandons de suivre la procédure post-déploiement ci-dessous. Pour en savoir plus, consultez le Guide d'installation et de mise à jour de SAP HANA.
Modifiez les mots de passe temporaires de l'administrateur système et du super-utilisateur du système SAP HANA.
Mettez à jour le logiciel SAP HANA avec les derniers correctifs.
Installez des composants supplémentaires tels que les bibliothèques Application Function Library (AFL) ou Smart Data Access (SDA).
Configurez et sauvegardez votre nouvelle base de données SAP HANA. Pour en savoir plus, consultez le Guide d'utilisation de SAP HANA.
Étape suivante
- Pour en savoir plus sur l'administration et la surveillance des VM, consultez le Guide d'utilisation de SAP HANA.