En este tutorial, usarás un modelo de regresión lineal en BigQuery ML para predecir el peso de un pingüino en función de su información demográfica. Una regresión lineal es un tipo de modelo de regresión que genera un valor continuo a partir de una combinación lineal de las características de entrada.
En este tutorial se usa el conjunto de datos
bigquery-public-data.ml_datasets.penguins.
Objetivos
En este tutorial, realizarás las siguientes tareas:
- Crea un modelo de regresión lineal.
- Evalúa el modelo.
- Hacer predicciones con el modelo.
Costes
En este tutorial se usan componentes facturables de Google Cloud, incluidos los siguientes:
- BigQuery
- BigQuery ML
Para obtener más información sobre los costes de BigQuery, consulta la página de precios de BigQuery.
Para obtener más información sobre los costes de BigQuery ML, consulta los precios de BigQuery ML.
Antes de empezar
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Permisos obligatorios
Para crear el modelo con BigQuery ML, necesita los siguientes permisos de gestión de identidades y accesos:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.models.updateMetadata
Para ejecutar la inferencia, necesitas los siguientes permisos:
bigquery.models.getDataen el modelobigquery.jobs.create
Crear conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de aprendizaje automático.
Consola
En la Google Cloud consola, ve a la página BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haga clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, introduce
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, a continuación, EE. UU. (varias regiones de Estados Unidos).
Deje el resto de los ajustes predeterminados como están y haga clic en Crear conjunto de datos.
bq
Para crear un conjunto de datos, usa el comando
bq mk
con la marca --location. Para ver una lista completa de los parámetros posibles, consulta la referencia del comando bq mk --dataset.
Crea un conjunto de datos llamado
bqml_tutorialcon la ubicación de los datos definida comoUSy la descripciónBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
En lugar de usar la marca
--dataset, el comando usa el acceso directo-d. Si omite-dy--dataset, el comando creará un conjunto de datos de forma predeterminada.Confirma que se ha creado el conjunto de datos:
bq ls
API
Llama al método datasets.insert con un recurso de conjunto de datos definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
Crear el modelo
Crea un modelo de regresión lineal con el conjunto de datos de muestra de Analytics para BigQuery.
SQL
Puedes crear un modelo de regresión lineal usando la sentencia CREATE MODEL y especificando LINEAR_REG para el tipo de modelo. La creación del modelo incluye el entrenamiento del modelo.
A continuación, se indican algunos aspectos útiles sobre la instrucción CREATE MODEL:
- La opción
input_label_colsespecifica qué columna de la instrucciónSELECTse debe usar como columna de etiquetas. En este caso, la columna de etiquetas esbody_mass_g. En el caso de los modelos de regresión lineal, la columna de etiquetas debe tener valores reales, es decir, los valores de la columna deben ser números reales. La instrucción
SELECTde esta consulta usa las siguientes columnas de la tablabigquery-public-data.ml_datasets.penguinspara predecir el peso de un pingüino:species: la especie de pingüino.island: la isla en la que reside el pingüino.culmen_length_mm: longitud del culmen del pingüino en milímetros.culmen_depth_mm: la profundidad del culmen del pingüino en milímetros.flipper_length_mm: longitud de las aletas del pingüino en milímetros.sex: el sexo del pingüino.
La cláusula
WHEREde la instrucciónSELECTde esta consulta,WHERE body_mass_g IS NOT NULL, excluye las filas en las que la columnabody_mass_gesNULL.
Ejecuta la consulta que crea tu modelo de regresión lineal:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, ejecuta la siguiente consulta:
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS (model_type='linear_reg', input_label_cols=['body_mass_g']) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
El modelo
penguins_modeltarda unos 30 segundos en crearse. Para ver el modelo, ve al panel Explorador, despliega el conjunto de datosbqml_tutorialy, a continuación, la carpeta Modelos.
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
El modelo tarda unos 30 segundos en crearse. Para ver el modelo, vaya al panel Explorador, despliegue el conjunto de datos bqml_tutorial y, a continuación, la carpeta Modelos.
Obtener estadísticas de formación
Para ver los resultados del entrenamiento del modelo, puedes usar la función ML.TRAINING_INFO o consultar las estadísticas en la consola Google Cloud . En este tutorial, usarás la Google Cloud consola.
Un algoritmo de aprendizaje automático crea un modelo examinando muchos ejemplos e intentando encontrar un modelo que minimice las pérdidas. Este proceso se denomina minimización del riesgo empírico.
La pérdida es la penalización por una predicción incorrecta. Es un número que indica lo incorrecta que ha sido la predicción del modelo en un ejemplo concreto. Si las predicciones del modelo son perfectas, la pérdida será igual a 0; si no, será superior. El objetivo de entrenar un modelo es encontrar un conjunto de pesos y sesgos que tengan una pérdida baja, de media, en todos los ejemplos.
Consulta las estadísticas de entrenamiento del modelo que se generaron al ejecutar la consulta CREATE MODEL:
En el panel Explorador, despliega el conjunto de datos
bqml_tutorialy, a continuación, la carpeta Modelos. Haz clic en penguins_model para abrir el panel de información del modelo.Haga clic en la pestaña Entrenamiento y, a continuación, en Tabla. Los resultados deberían ser similares a los siguientes:
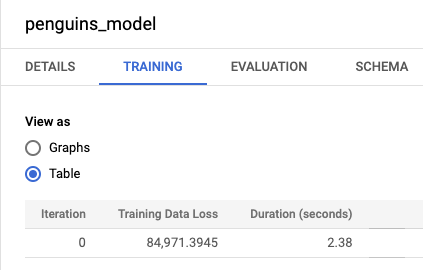
La columna Pérdida de datos de entrenamiento representa la métrica de pérdida calculada después de que el modelo se haya entrenado con el conjunto de datos de entrenamiento. Como has realizado una regresión lineal, esta columna muestra el valor del error cuadrático medio. Para este entrenamiento se usa automáticamente una estrategia de optimización de normal_equation, por lo que solo se necesita una iteración para converger al modelo final. Para obtener más información sobre cómo definir la estrategia de optimización del modelo, consulte
optimize_strategy.
Evaluar el modelo
Después de crear el modelo, evalúa su rendimiento con la función ML.EVALUATE o la función score de DataFrames de BigQuery para comparar los valores predichos generados por el modelo con los datos reales.
SQL
Como entrada, la función ML.EVALUATE toma el modelo entrenado y un conjunto de datos que coincida con el esquema de los datos que has usado para entrenar el modelo. En un entorno de producción, debe evaluar el modelo con datos distintos de los que ha usado para entrenarlo.
Si ejecutas ML.EVALUATE sin proporcionar datos de entrada, la función recupera las métricas de evaluación calculadas durante el entrenamiento. Estas métricas se calculan
usando el conjunto de datos de evaluación reservado automáticamente:
SELECT
*
FROM
ML.EVALUATE(MODEL bqml_tutorial.penguins_model);
Ejecuta la consulta ML.EVALUATE:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, ejecuta la siguiente consulta:
SELECT * FROM ML.EVALUATE(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL));
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
Los resultados deberían ser similares a los siguientes:
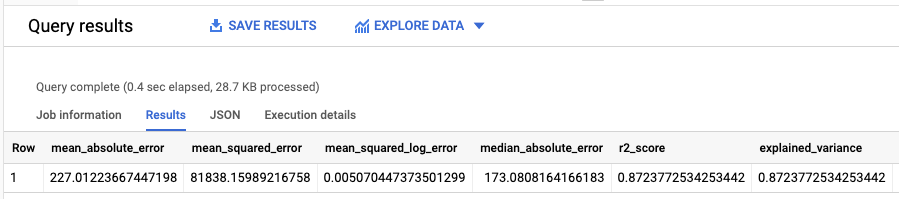
Como has realizado una regresión lineal, los resultados incluyen las siguientes columnas:
mean_absolute_errormean_squared_errormean_squared_log_errormedian_absolute_errorr2_scoreexplained_variance
Una métrica importante en los resultados de la evaluación es la puntuación R2.
La puntuación R2 es una medida estadística que determina si las predicciones de regresión lineal se aproximan a los datos reales. Un valor de 0 indica que el modelo no explica ninguna de las variabilidades de los datos de respuesta en torno a la media. Un valor de 1 indica que el modelo explica toda la variabilidad de los datos de respuesta en torno a la media.
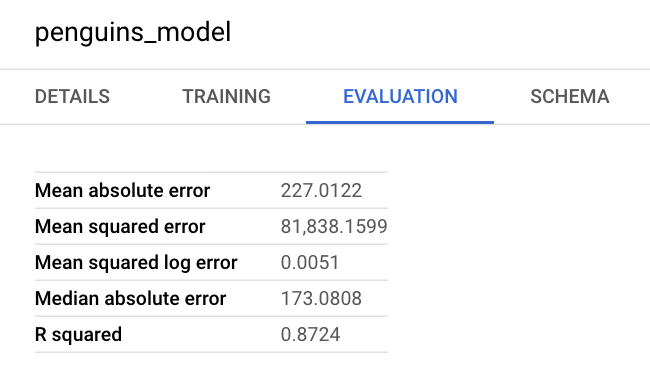
También puedes consultar el panel de información del modelo en la Google Cloud consola para ver las métricas de evaluación:
Usar el modelo para predecir resultados
Ahora que has evaluado tu modelo, el siguiente paso es usarlo para predecir un resultado. Puedes ejecutar la función ML.PREDICT o la función BigQuery DataFrames predict en el modelo para predecir la masa corporal en gramos de todos los pingüinos que residen en las islas Biscoe.
SQL
Como entrada, la función ML.PREDICT toma el modelo entrenado y un conjunto de datos que coincide con el esquema de los datos que usaste para entrenar el modelo, excepto la columna de etiquetas.
Ejecuta la consulta ML.PREDICT:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, ejecuta la siguiente consulta:
SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'));
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
Los resultados deberían ser similares a los siguientes:

Explicar los resultados de la predicción
SQL
Para saber por qué el modelo genera estos resultados de predicción, puedes usar la función ML.EXPLAIN_PREDICT.
ML.EXPLAIN_PREDICT es una versión ampliada de la función ML.PREDICT.
ML.EXPLAIN_PREDICT no solo genera resultados de predicción, sino que también genera columnas adicionales para explicar los resultados de predicción. En la práctica, puedes ejecutar
ML.EXPLAIN_PREDICT en lugar de ML.PREDICT. Para obtener más información, consulta la información general sobre la IA explicable de BigQuery ML.
Ejecuta la consulta ML.EXPLAIN_PREDICT:
- En la Google Cloud consola, ve a la página BigQuery.
- En el editor de consultas, ejecuta la siguiente consulta:
SELECT * FROM ML.EXPLAIN_PREDICT(MODEL `bqml_tutorial.penguins_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE island = 'Biscoe'), STRUCT(3 as top_k_features));
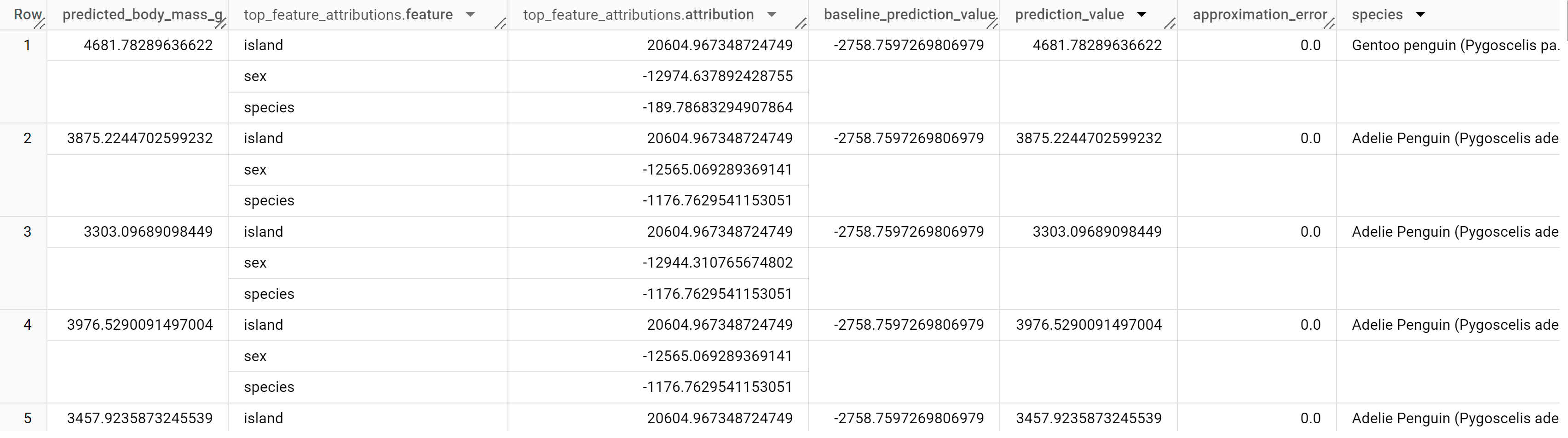
Los resultados deberían ser similares a los siguientes:
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
En los modelos de regresión lineal, los valores de Shapley se usan para generar valores de atribución de características para cada característica del modelo. El resultado incluye las tres atribuciones de características principales por fila de la tabla penguins porque top_k_features se ha definido como 3. Estas atribuciones se ordenan por el valor absoluto de la atribución en orden descendente. En todos los ejemplos, la característica sex es la que más ha contribuido a la predicción general.
Explica el modelo de forma global
SQL
Para saber qué características son las más importantes para determinar el peso de los pingüinos, puedes usar la función ML.GLOBAL_EXPLAIN.
Para usar ML.GLOBAL_EXPLAIN, debes volver a entrenar el modelo con la opción ENABLE_GLOBAL_EXPLAIN definida como TRUE.
Vuelve a entrenar el modelo y obtén explicaciones globales:
- En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, ejecuta la siguiente consulta para volver a entrenar el modelo:
#standardSQL CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model` OPTIONS ( model_type = 'linear_reg', input_label_cols = ['body_mass_g'], enable_global_explain = TRUE) AS SELECT * FROM `bigquery-public-data.ml_datasets.penguins` WHERE body_mass_g IS NOT NULL;
En el editor de consultas, ejecuta la siguiente consulta para obtener explicaciones globales:
SELECT * FROM ML.GLOBAL_EXPLAIN(MODEL `bqml_tutorial.penguins_model`)
Los resultados deberían ser similares a los siguientes:
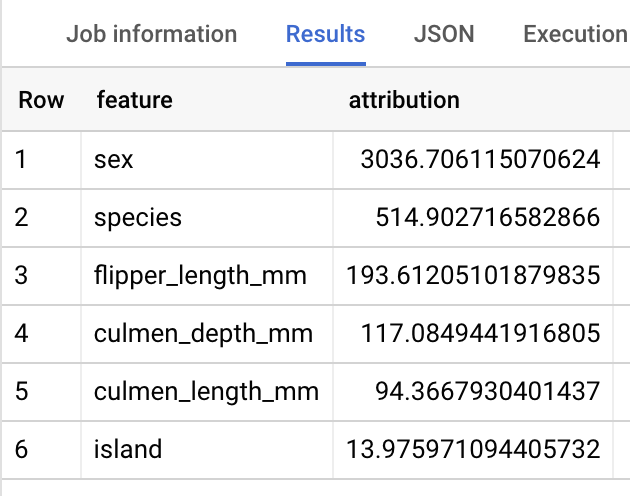
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
Limpieza
Para evitar que los recursos utilizados en este tutorial se cobren en tu cuenta de Google Cloud, elimina el proyecto que contiene los recursos o conserva el proyecto y elimina los recursos.
- Puedes eliminar el proyecto que has creado.
- También puedes conservar el proyecto y eliminar el conjunto de datos.
Eliminar un conjunto de datos
Si eliminas un proyecto, se eliminarán todos los conjuntos de datos y todas las tablas que contenga. Si prefieres reutilizar el proyecto, puedes eliminar el conjunto de datos que has creado en este tutorial:
Si es necesario, abre la página de BigQuery en laGoogle Cloud consola.
En el panel de navegación, haz clic en el conjunto de datos bqml_tutorial que has creado.
Haz clic en Eliminar conjunto de datos, en la parte derecha de la ventana. Esta acción elimina el conjunto de datos, la tabla y todos los datos.
En el cuadro de diálogo Eliminar conjunto de datos, confirma el comando de eliminación escribiendo el nombre del conjunto de datos (
bqml_tutorial) y, a continuación, haz clic en Eliminar.
Eliminar un proyecto
Para ello, sigue las instrucciones que aparecen a continuación:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Siguientes pasos
- Para obtener una descripción general de BigQuery ML, consulta la introducción a BigQuery ML.
- Para obtener información sobre cómo crear modelos, consulta la página de sintaxis de
CREATE MODEL.