Hierarchische Zeitreihen mit einem univariaten ARIMA_PLUS-Modell vorhersagen
In dieser Anleitung erfahren Sie, wie Sie ein univariates Zeitachsenmodell ARIMA_PLUS verwenden, um hierarchische Zeitachsen zu prognostizieren. Sie prognostiziert den zukünftigen Wert für eine bestimmte Spalte basierend auf den historischen Werten für diese Spalte und berechnet auch die zusammengefassten Werte für diese Spalte für eine oder mehrere Dimensionen.
Prognostizierte Werte werden für jeden Zeitpunkt und für jeden Wert in einer oder mehreren Spalten berechnet, die die relevanten Dimensionen angeben. Wenn Sie beispielsweise tägliche Verkehrsereignisse vorhersagen möchten und eine Dimensionsspalte mit Bundesstaatsdaten angeben, enthalten die prognostizierten Daten Werte für jeden Tag für Bundesstaat A, dann Werte für jeden Tag für Bundesstaat B usw. Wenn Sie beispielsweise tägliche Verkehrsereignisse vorhersagen möchten und Dimensionsspalten mit Daten zu Bundesstaat und Stadt angegeben haben, enthalten die prognostizierten Daten Werte für jeden Tag für Bundesstaat A und Stadt A, dann Werte für jeden Tag für Bundesstaat A und Stadt B usw. In hierarchischen Zeitreihenmodellen wird die hierarchische Abstimmung verwendet, um jede untergeordnete Zeitreihe mit der übergeordneten Zeitreihe zusammenzufassen und abzustimmen. Die Summe der prognostizierten Werte für alle Städte in Bundesstaat A muss beispielsweise dem prognostizierten Wert für Bundesstaat A entsprechen.
In dieser Anleitung erstellen Sie zwei Zeitachsenmodelle, die dieselben Daten nutzen. Ein Modell verwendet hierarchische Prognosen und ein Modell verwendet keine hierarchischen Prognosen. So können Sie die von den Modellen zurückgegebenen Ergebnisse vergleichen.
In dieser Anleitung werden Daten aus der öffentlichen Tabelle bigquery-public-data.iowa_liquor.sales.sales verwendet. Diese Tabelle enthält Informationen zu über einer Million Spirituosenprodukten in verschiedenen Geschäften anhand der öffentlichen Verkaufsdaten für Spirituosen in Iowa.
Bevor Sie diese Anleitung lesen, sollten Sie unbedingt Prognosen für mehrere Zeitachsen mit einem univariaten Modell erstellen lesen.
Erforderliche Berechtigungen
Sie benötigen die IAM-Berechtigung
bigquery.datasets.create, um das Dataset zu erstellen.Zum Erstellen des Modells benötigen Sie die folgenden Berechtigungen:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Zum Ausführen von Inferenzen benötigen Sie die folgenden Berechtigungen:
bigquery.models.getDatabigquery.jobs.create
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Einführung in IAM.
Ziele
In dieser Anleitung verwenden Sie Folgendes:
- Erstellen eines Modells für mehrere Zeitreihen und eines Modells für mehrere hierarchische Zeitreihen, um die Verkaufszahlen von Flaschen mit der
CREATE MODEL-Anweisung vorherzusagen. - Die prognostizierten Werte für den Flaschenverkauf werden mithilfe der
ML.FORECAST-Funktion aus den Modellen abgerufen.
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloudverwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu den Kosten von BigQuery finden Sie auf der Seite BigQuery-Preise.
Weitere Informationen zu den Kosten für BigQuery ML finden Sie unter BigQuery ML-Preise.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery ist in neuen Projekten automatisch aktiviert.
So aktivieren Sie BigQuery in einem vorhandenen Projekt:
Enable the BigQuery API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
Erstellen Sie ein Dataset mit dem Namen
bqml_tutorial, wobei der Datenspeicherort aufUSund die Beschreibung aufBigQuery ML tutorial datasetfestgelegt ist:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Anstelle des Flags
--datasetverwendet der Befehl die verkürzte Form-d. Wenn Sie-dund--datasetauslassen, wird standardmäßig ein Dataset erstellt.Prüfen Sie, ob das Dataset erstellt wurde:
bq lsÖffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'], HOLIDAY_REGION = 'US') AS SELECT store_number, zip_code, city, county, date, SUM(bottles_sold) AS total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31') AND county IN ('POLK', 'LINN', 'SCOTT') GROUP BY store_number, date, city, zip_code, county;
Die Abfrage dauert ungefähr 37 Sekunden. Anschließend wird das Modell
liquor_forecastim Bereich Explorer angezeigt. Da die Abfrage eineCREATE MODEL-Anweisung zum Erstellen eines Modells verwendet, gibt es keine Abfrageergebnisse.Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast`, STRUCT(20 AS horizon, 0.8 AS confidence_level)) ORDER BY store_number, county, city, zip_code, forecast_timestamp;
Die Antwort sollte in etwa so aussehen:
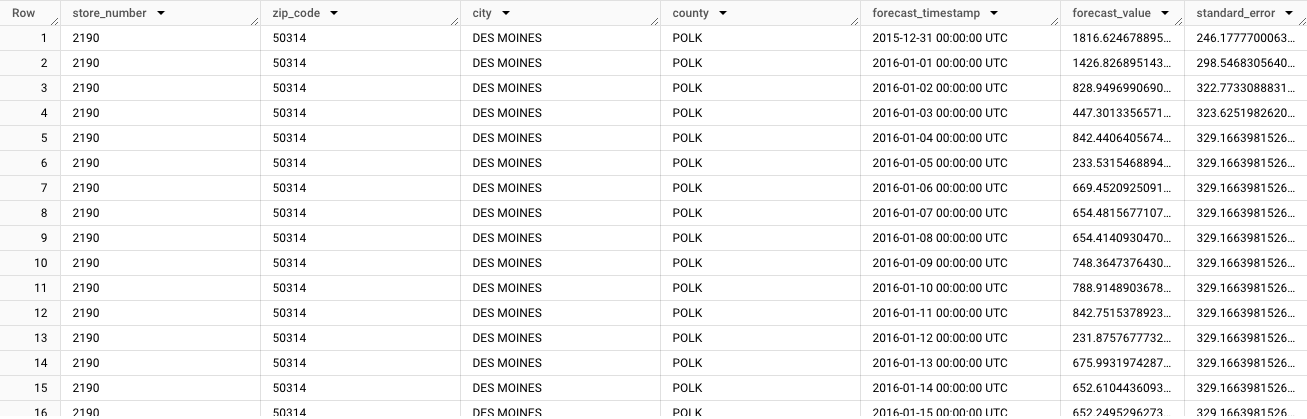
Die Ausgabe beginnt mit den prognostizierten Daten für die erste Zeitreihe:
store_number=2190,zip_code=50314,city=DES MOINES,county=POLK. Wenn Sie durch die Daten scrollen, sehen Sie die Prognosen für jede nachfolgende eindeutige Zeitreihe. Wenn Sie Prognosen generieren möchten, in denen Gesamtsummen für verschiedene Dimensionen aggregiert werden, z. B. Prognosen für ein bestimmtes Landkreis, müssen Sie eine hierarchische Prognose generieren.Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_hierarchical` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS', TIME_SERIES_TIMESTAMP_COL = 'date', TIME_SERIES_DATA_COL = 'total_bottles_sold', TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'], HIERARCHICAL_TIME_SERIES_COLS = ['zip_code', 'store_number'], HOLIDAY_REGION = 'US') AS SELECT store_number, zip_code, city, county, date, SUM(bottles_sold) AS total_bottles_sold FROM `bigquery-public-data.iowa_liquor_sales.sales` WHERE date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31') AND county IN ('POLK', 'LINN', 'SCOTT') GROUP BY store_number, date, city, zip_code, county;
Die Abfrage dauert ungefähr 45 Sekunden. Anschließend wird das Modell
bqml_tutorial.liquor_forecast_hierarchicalim Bereich Explorer angezeigt. Da die Abfrage eineCREATE MODEL-Anweisung zum Erstellen eines Modells verwendet, gibt es keine Abfrageergebnisse.Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast_hierarchical`, STRUCT(30 AS horizon, 0.8 AS confidence_level)) WHERE city = 'LECLAIRE' ORDER BY county, city, zip_code, store_number, forecast_timestamp;
Die Antwort sollte in etwa so aussehen:
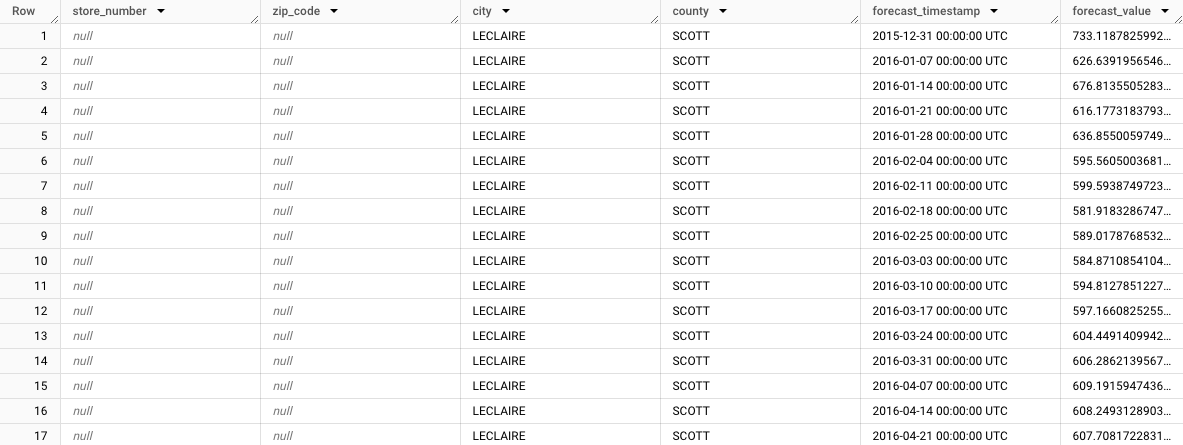
Die aggregierte Prognose wird für die Stadt LeClaire angezeigt:
store_number=NULL,zip_code=NULL,city=LECLAIRE,county=SCOTT. Sehen Sie sich die restlichen Zeilen an, um die Prognosen für die anderen Untergruppen zu sehen. Das folgende Bild zeigt beispielsweise die Prognosen, die für die Postleitzahlen52753,store_number=NULL,zip_code=52753,city=LECLAIREundcounty=SCOTTzusammengefasst wurden: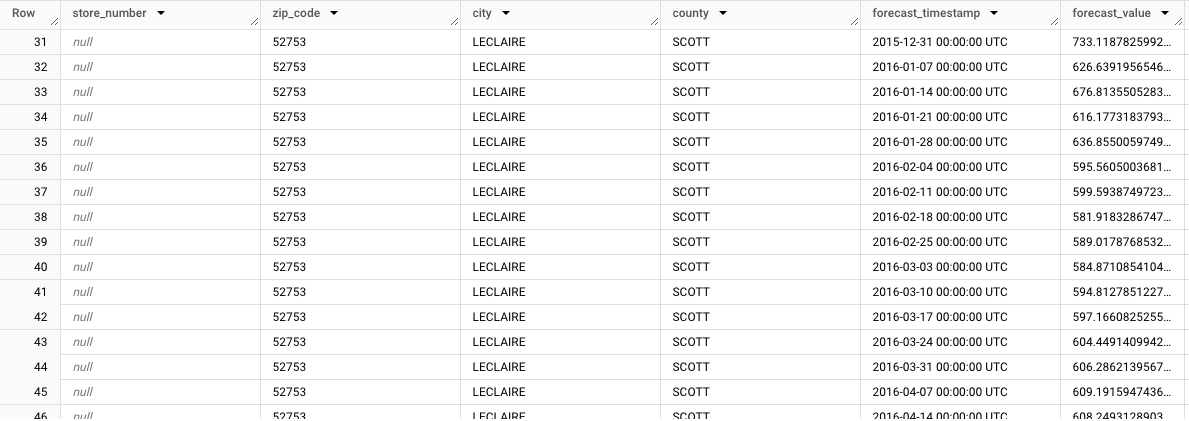
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Rufen Sie, falls erforderlich, die Seite „BigQuery“ in derGoogle Cloud Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie rechts im Fenster auf Delete dataset (Dataset löschen). Dadurch werden das Dataset, die Tabelle und alle Daten gelöscht.
Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Löschen.- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Informationen zum Prognostizieren einer einzelnen Zeitachse mit einem univariaten Modell
- Mehrere Zeitreihen mit einem univariaten Modell prognostizieren
- Informationen zum Skalieren eines univariaten Modells bei der Prognose mehrerer Zeitreihen über viele Zeilen hinweg
- Weitere Informationen zum Prognostizieren einer einzelnen Zeitachse mit einem multivariaten Modell
- Eine Übersicht über BigQuery ML finden Sie unter Einführung in KI und ML in BigQuery.
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells.
Konsole
bq
Wenn Sie ein neues Dataset erstellen möchten, verwenden Sie den Befehl bq mk mit dem Flag --location. Eine vollständige Liste der möglichen Parameter finden Sie in der bq mk --dataset-Befehlsreferenz.
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Zeitachsenmodell erstellen
Erstellen Sie ein Zeitachsenmodell mit den Daten zum Spirituosenverkauf in Iowa.
Mit der folgenden GoogleSQL-Abfrage wird ein Modell erstellt, das die tägliche Gesamtzahl der im Jahr 2015 in Polk, Linn und Scott-Landkreisen verkauften Flaschen prognostiziert.
In der folgenden Abfrage gibt die OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)-Anweisung an, dass Sie ein ARIMA-basiertes Zeitachsenmodell erstellen. Mit der TIME_SERIES_ID-Option der CREATE MODEL-Anweisung geben Sie eine oder mehrere Spalten in den Eingabedaten an, für die Sie Prognosen erstellen möchten. Die auto_arima_max_order-Option der CREATE MODEL-Anweisung steuert den Suchbereich für die Hyperparameter-Abstimmung im auto.ARIMA-Algorithmus. Die Option decompose_time_series der Anweisung CREATE MODELTRUE ist standardmäßig auf TRUE festgelegt. Wenn Sie das Modell im nächsten Schritt auswerten, werden also Informationen zu den Zeitreihendaten zurückgegeben.
Die OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)-Anweisung gibt an, dass Sie ein ARIMA-basiertes Zeitachsenmodell erstellen. Standardmäßig wird auto_arima=TRUE verwendet, sodass der auto.ARIMA-Algorithmus die Hyperparameter in ARIMA_PLUS-Modellen automatisch abstimmt. Der Algorithmus passt Dutzende von Kandidatenmodellen an und wählt das beste Modell aus, also das Modell mit dem niedrigsten Akaike-Informationskriterium (AIC).
Durch Festlegen der Option holiday_region auf US wird eine genauere Modellierung der Feiertagszeitpunkte in den USA ermöglicht, wenn in der Zeitachse Feiertagsmuster der USA vorhanden sind.
So erstellen Sie das Modell:
Modell zum Vorhersagen von Daten verwenden
Mit der Funktion ML.FORECAST können Sie zukünftige Zeitachsenwerte prognostizieren.
In der folgenden Abfrage gibt die STRUCT(20 AS horizon, 0.8 AS confidence_level)-Klausel an, dass die Abfrage 20 zukünftige Zeitpunkte prognostiziert und ein Vorhersageintervall mit einem Konfidenzniveau von 80% generiert.
So prognostizieren Sie Daten mit dem Modell:
Hierarchisches Zeitachsenmodell erstellen
Erstellen Sie eine hierarchische Zeitreihenvorhersage mit den Verkaufsdaten für Spirituosen in Iowa.
Mit der folgenden GoogleSQL-Abfrage wird ein Modell erstellt, das hierarchische Prognosen für die tägliche Gesamtzahl der im Jahr 2015 in Polk, Linn und Scott-Landkreisen verkauften Flaschen generiert.
In der folgenden Abfrage gibt die Option HIERARCHICAL_TIME_SERIES_COLS in der CREATE MODEL-Anweisung an, dass Sie eine hierarchische Prognose auf Grundlage einer Reihe von Spalten erstellen, die Sie angeben. Jede dieser Spalten wird für die Aggregation zusammengefasst. Im Beispiel von oben bedeutet das, dass der Wert der Spalte store_number zusammengefasst wird, um Prognosen für jeden county-, city- und zip_code-Wert zu erhalten. Getrennt voneinander werden auch zip_code- und store_number-Werte zusammengefasst, um Prognosen für jeden county- und city-Wert anzuzeigen.
Die Reihenfolge der Spalten ist wichtig, da sie die Struktur der Hierarchie bestimmt.
So erstellen Sie das Modell:
Hierarchisches Modell zum Vorhersagen von Daten verwenden
Rufen Sie hierarchische Prognosedaten aus dem Modell mit der Funktion ML.FORECAST ab.
So prognostizieren Sie Daten mit dem Modell:
Bereinigen
Damit Ihrem Google Cloud -Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, können Sie entweder das Projekt löschen, das die Ressourcen enthält, oder das Projekt beibehalten und die einzelnen Ressourcen löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Projekt löschen
So löschen Sie das Projekt: