Estensioni parser
Questo documento spiega come creare estensioni del parser per estrarre i campi dai dati di log non elaborati e mapparli ai campi UDM (Unified Data Model) di destinazione all'interno della piattaforma Google Security Operations.
Il documento descrive la procedura di creazione dell'estensione parser:
- Crea estensioni del parser.
- Prerequisiti e limitazioni.
- Identifica i campi di origine nei dati dei log non elaborati.
- Seleziona i campi UDM di destinazione appropriati.
Scegli l'approccio di definizione dell'estensione parser appropriato:
La definizione di un'estensione del parser include la progettazione della logica di analisi per filtrare i dati dei log non elaborati, trasformarli e mapparli nei campi UDM di destinazione. Google SecOps offre due approcci per creare estensioni del parser:
- Crea estensioni del parser utilizzando l'approccio no-code (campi dati mappa).
- Crea estensioni del parser utilizzando l'approccio dello snippet di codice.
Esempi illustrativi di creazione di estensioni del parser per vari formati di log e scenari. Ad esempio, esempi senza codice che utilizzano JSON e snippet di codice per logica complessa o formati non JSON (CSV, XML, Syslog).
Creare estensioni parser
Le estensioni del parser forniscono un modo flessibile per estendere le funzionalità dei parser predefiniti (e personalizzati) esistenti. Le estensioni del parser forniscono un modo flessibile per estendere le funzionalità dei parser predefiniti (o personalizzati) esistenti senza sostituirli. Le estensioni ti consentono di personalizzare la pipeline del parser aggiungendo nuove logiche di analisi, estraendo e trasformando i campi e aggiornando o rimuovendo le mappature dei campi UDM.
Un'estensione del parser non è la stessa cosa di un parser personalizzato. Puoi creare un parser personalizzato per il tipo di log che non ha un parser predefinito o per disattivare gli aggiornamenti del parser.
Processo di estrazione e normalizzazione del parser
Google SecOps riceve i dati dei log originali come log non elaborati. I parser predefiniti (e personalizzati) estraggono e normalizzano i campi di log principali in campi UDM strutturati nei record UDM. che rappresenta solo un sottoinsieme dei dati di log non elaborati originali. Puoi definire estensioni del parser per estrarre valori di log non gestiti dai parser predefiniti. Una volta attivate, le estensioni dell'analizzatore sintattico diventano parte del processo di estrazione e normalizzazione dei dati di Google SecOps.
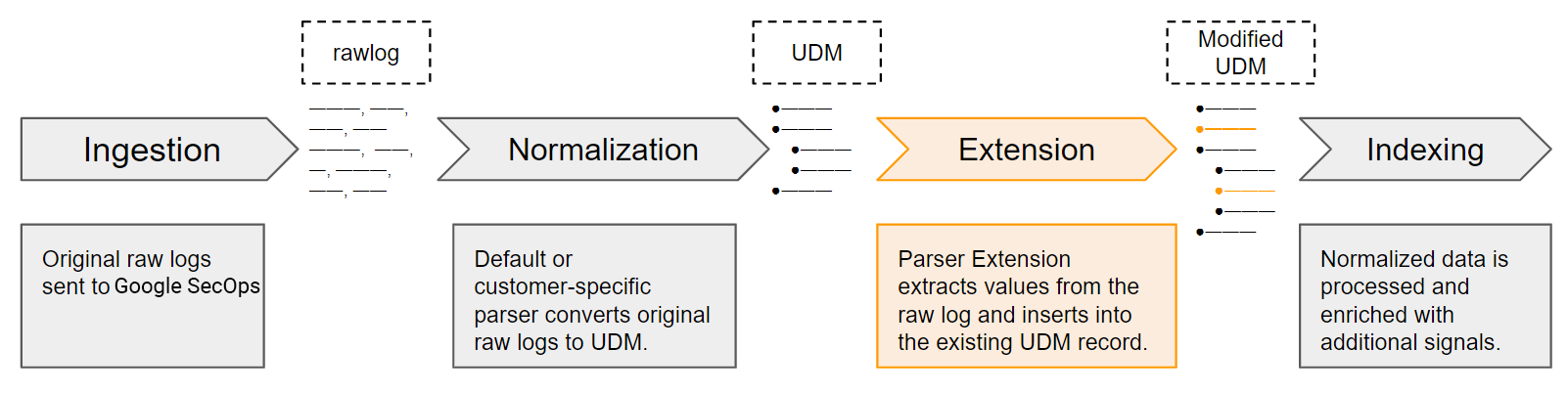
Definisci nuove estensioni del parser
I parser predefiniti contengono set predefiniti di istruzioni di mappatura che specificano come estrarre, trasformare e normalizzare i valori di sicurezza principali. Puoi creare nuove estensioni del parser definendo le istruzioni di mappatura utilizzando l'approccio no-code (Mappa i campi di dati) o l'approccio con snippet di codice:
Approccio no-code
L'approccio no-code è più adatto per estrazioni semplici dai log non elaborati in formato JSON, XML o CSV nativo. Consente di specificare i campi di origine dei log non elaborati e mappare i campi UDM di destinazione corrispondenti.
Ad esempio, per estrarre dati di log JSON con un massimo di 10 campi, utilizzando semplici confronti di uguaglianza.
Approccio basato sullo snippet di codice
L'approccio basato sugli snippet di codice consente di definire le istruzioni per estrarre e trasformare i valori dal log non elaborato e assegnarli ai campi UDM. Gli snippet di codice utilizzano la stessa sintassi simile a Logstash dell'analizzatore predefinito (o personalizzato).
Questo approccio è applicabile a tutti i formati di log supportati. È ideale per questi scenari:
- Estrazioni di dati complesse o logica complessa.
- Dati non strutturati che richiedono analizzatori basati su Grok.
- Formati non JSON come CSV e XML.
Gli snippet di codice utilizzano funzioni per estrarre dati specifici dai dati di log non elaborati. Ad esempio, Grok, JSON, KV e XML.
Nella maggior parte dei casi è consigliabile utilizzare l'approccio di mappatura dei dati utilizzato nel parser predefinito (o personalizzato).
Unire i valori appena estratti nei campi UDM
Una volta attivate, le estensioni del parser uniscono i valori appena estratti nei campi UDM designati nel record UDM corrispondente in base a principi di unione predefiniti. Ad esempio:
Sovrascrivi valori esistenti: i valori estratti sovrascrivono i valori esistenti nei campi UDM di destinazione.
L'unica eccezione sono i campi ripetuti, in cui puoi configurare l'estensione del parser per aggiungere nuovi valori durante la scrittura dei dati in un campo ripetuto nel record UDM.
Precedenza dell'estensione del parser: le istruzioni di mappatura dei dati in un'estensione del parser hanno la precedenza su quelle nel parser predefinito (o personalizzato) per quel tipo di log. Se si verifica un conflitto nelle istruzioni di mappatura, l'estensione del parser sovrascriverà il valore impostato per impostazione predefinita.
Ad esempio, se il parser predefinito mappa un campo log non elaborato al campo UDM
event.metadata.descriptione l'estensione del parser mappa un campo log non elaborato diverso allo stesso campo UDM, l'estensione del parser sovrascrive il valore impostato dal parser predefinito.
Limitazioni
- Un'estensione del parser per tipo di log: puoi creare una sola estensione del parser per tipo di log.
- Un solo approccio alle istruzioni di mappatura dei dati: puoi creare un'estensione del parser utilizzando l'approccio no-code o quello degli snippet di codice, ma non entrambi contemporaneamente.
- Esempi di log per la convalida: sono necessari esempi di log degli ultimi 30 giorni per convalidare un'estensione del parser UDM. Per i dettagli, vedi Assicurati che esista un parser attivo per il tipo di log.
- Errori del parser di base: gli errori del parser di base non sono identificabili o correggibili all'interno delle estensioni del parser.
- Campi ripetuti negli snippet di codice: fai attenzione quando sostituisci interi oggetti ripetuti negli snippet di codice per evitare la perdita di dati involontaria. Per maggiori dettagli, vedi Ulteriori informazioni sul selettore dei campi ripetuti.
- Eventi disambiguati: le estensioni del parser non possono gestire i log con più eventi unici in un singolo record, ad esempio l'array di Google Drive.
XML e no-code: la modalità no-code non è supportata per XML. Utilizza invece il metodo dello snippet di codice.
Nessun dato retroattivo: non puoi analizzare i dati dei log non elaborati in modo retroattivo.
Parole chiave riservate con l'approccio senza codice: se i log contengono una delle seguenti parole chiave riservate, utilizza l'approccio con snippet di codice anziché quello senza codice:
collectionTimestampcreateTimestampenableCbnForLoopeventfilenamemessagenamespaceoutputonErrorCounttimestamptimezone
Rimuovi le mappature esistenti: puoi rimuovere le mappature dei campi UDM esistenti utilizzando solo l'approccio dello snippet di codice.
Rimuovi mappature per campi IP ripetuti: non puoi rimuovere le mappature dei campi UDM per i campi IP ripetuti.
Concetti relativi al parser
I seguenti documenti spiegano concetti importanti relativi al parser:
- Panoramica del modello di dati unificato
- Panoramica dell'analisi dei log
- Riferimento alla sintassi del parser
Prerequisiti
Prerequisiti per la creazione dell'estensione del parser:
- Deve esistere un parser predefinito (o personalizzato) attivo per il tipo di log.
- Google SecOps deve essere in grado di importare e normalizzare i log non elaborati utilizzando un parser predefinito (o personalizzato).
- Assicurati che il parser attivo predefinito (o personalizzato) per il tipo di log di destinazione abbia inserito i dati di log non elaborati negli ultimi 30 giorni. Questi dati devono contenere un campione dei campi che intendi estrarre o utilizzare per filtrare i record di log. Verrà utilizzato per convalidare le nuove istruzioni di mappatura dei dati.
Inizia
Prima di creare un'estensione del parser, segui questi passaggi:
-
Assicurati che esista un parser attivo per il tipo di log. Se non ha ancora un parser, creane uno personalizzato.
Identifica i campi da estrarre dai log non elaborati:
Identifica i campi da estrarre dai log non elaborati.
Seleziona i campi UDM appropriati:
Seleziona i campi UDM corrispondenti appropriati per mappare i campi dei log non elaborati estratti.
Scegli un approccio di definizione dell'estensione parser:
Scegli uno dei due approcci di estensione (approcci di mappatura dei dati) per creare l'estensione del parser.
Verifica i prerequisiti
Assicurati che esista un parser attivo per il tipo di log che intendi estendere, come descritto nelle sezioni seguenti:
Assicurati che esista un parser attivo per il tipo di log
Assicurati che esista un parser predefinito (o personalizzato) attivo per il tipo di log che intendi estendere.
Cerca il tipo di log in questi elenchi:
Tipi di log supportati con un parser predefinito.
- Se esiste un parser predefinito per il tipo di log, assicurati che il parser sia attivo.
- Se non è presente alcun parser predefinito per il tipo di log, assicurati che sia presente un parser personalizzato per il tipo di log.
Tipi di log supportati senza un analizzatore predefinito.
- Se non è presente alcun parser predefinito per il tipo di log, assicurati che sia presente un parser personalizzato per il tipo di log.
Assicurati che esista un parser personalizzato per il tipo di log
Per assicurarti che esista un parser personalizzato per un tipo di log:
- Nella barra di navigazione, seleziona Impostazioni SIEM > Parser.
Cerca nella tabella Parser il tipo di log che vuoi estendere.
- Se questo tipo di log non ha ancora un parser predefinito o personalizzato, fai clic su CREA PARSER e segui i passaggi descritti in Creare un parser personalizzato in base alle istruzioni di mappatura.
- Se questo tipo di log ha già un parser personalizzato, assicurati che il parser sia attivo.
Assicurati che il parser sia attivo per il tipo di log
Per verificare se un parser è attivo per un tipo di log:
- Nella barra di navigazione, seleziona Impostazioni SIEM > Parser.
Cerca nella tabella Parser il tipo di log che vuoi estendere.
Se il parser per il tipo di log non è attivo, attivalo:
- Per i parser predefiniti, vedi Gestire gli aggiornamenti dei parser predefiniti.
- Per i parser personalizzati, vedi Gestire gli aggiornamenti dei parser personalizzati.
Identifica i campi da estrarre dai log non elaborati
Analizza il log non elaborato da cui vuoi estrarre i dati per identificare i campi non estratti dal parser predefinito (o personalizzato). Presta attenzione al modo in cui il parser predefinito (o personalizzato) estrae i campi dei log non elaborati e li mappa ai campi UDM corrispondenti.
Per identificare i campi specifici da estrarre dai log non elaborati, puoi utilizzare gli strumenti di ricerca per identificare i campi:
Per accedere allo strumento di ricerca, vai a Indagine > Ricerca SIEM. Digita raw= prima della query di ricerca. Per maggiori dettagli, vedi Eseguire una ricerca nei log non elaborati.
Per accedere allo strumento di ricerca legacy, fai clic su Vai alla ricerca legacy nella parte superiore della pagina Ricerca SIEM. Per maggiori dettagli, vedi Cercare nei log non elaborati utilizzando la scansione dei log non elaborati.
Per informazioni dettagliate sulla ricerca nei log non elaborati, vedi:
Seleziona i campi UDM appropriati
Ora che hai identificato i campi di destinazione specifici da estrarre, puoi corrispondere ai campi UDM di destinazione corrispondenti. Stabilisci una mappatura chiara tra i campi dell'origine log non elaborati e i campi UDM di destinazione. Puoi mappare i dati a qualsiasi campo UDM che supporti i tipi di dati standard o i campi ripetuti.
Scegliere il campo UDM corretto
Le seguenti risorse possono aiutarti a semplificare la procedura:
- Acquisisci familiarità con i concetti principali di UDM
- Comprendere la mappatura dei dati utilizzata dal parser esistente
- Utilizza lo strumento di ricerca UDM per trovare potenziali campi UDM che corrispondono ai campi di origine.
- La guida Campi UDM importanti per la mappatura dei dati del parser include un riepilogo e una spiegazione dei campi più utilizzati dello schema UDM.
- L'elenco dei campi Unified Data Model contiene un elenco di tutti i campi UDM e le relative descrizioni. I campi ripetuti sono identificati dall'etichetta "ripetuto" negli elenchi.
- Considerazioni importanti relative a UDM per evitare errori
Acquisisci familiarità con i concetti principali di UDM
Oggetti logici: evento ed entità
Lo schema UDM descrive tutti gli attributi disponibili che archiviano i dati. Ogni record UDM descrive un evento o un'entità. I dati vengono archiviati in campi diversi a seconda che il record descriva un evento o un'entità.
- Un oggetto Evento UDM memorizza i dati relativi all'azione eseguita nell'ambiente. Il log eventi originale descrive l'azione così come è stata registrata dal dispositivo, ad esempio firewall o proxy web.
- Gli oggetti Entità UDM archiviano i dati sui partecipanti o sulle entità coinvolte nell'evento UDM, ad esempio risorse, utenti o risorse nel tuo ambiente.
Sostantivi UDM: Un sostantivo rappresenta un partecipante o un'entità in un evento UDM. Un sostantivo potrebbe essere, ad esempio, il dispositivo o l'utente che esegue l'attività descritta nell'evento. Un sostantivo potrebbe anche essere il dispositivo o l'utente che è il target dell'attività descritta nell'evento.
UDM Noun Descrizione principalL'entità responsabile dell'avvio dell'azione descritta nell'evento. targetL'entità che è il destinatario o l'oggetto dell'azione. In una connessione firewall, la macchina che riceve la connessione è la destinazione. srcUn'entità di origine su cui agisce l'entità. Ad esempio, se un utente copia un file da un computer a un altro, il file e il computer di origine vengono rappresentati come origine. intermediaryQualsiasi entità che funge da intermediario nell'evento, ad esempio un server proxy. Possono influenzare l'azione, ad esempio bloccando o modificando una richiesta. observerUn'entità che monitora e genera report sull'evento, ma non interagisce direttamente con il traffico. Alcuni esempi includono sistemi di rilevamento delle intrusioni di rete o sistemi di gestione delle informazioni e degli eventi di sicurezza. aboutQualsiasi altra entità coinvolta nell'evento che non rientra nelle categorie precedenti. Ad esempio, gli allegati email o le DLL caricate durante l'avvio di un processo. In pratica, gli oggetti Noun principale e target sono quelli utilizzati più di frequente. È inoltre importante notare che le descrizioni precedenti costituiscono l'utilizzo consigliato dei Nomi. L'utilizzo effettivo può variare in base all'implementazione di un parser di base predefinito o personalizzato.
Comprendere la mappatura dei dati utilizzata dal parser esistente
Ti consigliamo di comprendere la mappatura dei dati esistente utilizzata dal parser predefinito (o personalizzato) tra i campi di origine dei log non elaborati e i campi UDM di destinazione.
Per visualizzare la mappatura dei dati tra i campi di origine dei log non elaborati e i campi UDM di destinazione utilizzati nel parser predefinito (o personalizzato) esistente:
- Nella barra di navigazione, seleziona Impostazioni SIEM > Parser.
- Cerca nella tabella Parser il tipo di log che vuoi estendere.
Vai alla riga in questione, quindi fai clic su Menu > Visualizza.
La scheda Codice parser mostra la mappatura dei dati tra i campi di origine dei log non elaborati e i campi UDM di destinazione utilizzati nel parser predefinito (o personalizzato) esistente.
Utilizzare lo strumento di ricerca UDM
Utilizza lo strumento di ricerca UDM per identificare i campi UDM che corrispondono ai campi dell'origine log non elaborata.
Google SecOps fornisce lo strumento di ricerca UDM per aiutarti a trovare rapidamente i campi UDM di destinazione. Per accedere allo strumento di ricerca UDM, vai a Indagine > Ricerca SIEM.
Per informazioni dettagliate su come utilizzare lo strumento di ricerca UDM, consulta questi argomenti:
- Trovare un campo UDM
- Inserisci una ricerca UDM
- Impostare un filtro temporale sulla ricerca
- Esempi di ricerche UDM
- Generare query di ricerca UDM con Gemini
Esempio di strumento di ricerca UDM
Ad esempio, se hai un campo di origine nel log non elaborato denominato "packets", utilizza lo strumento di ricerca UDM per trovare potenziali campi UDM di destinazione con "packets" nel nome:
Vai a Indagine > Ricerca SIEM.
Nella pagina SIEM Search, inserisci "packets" nel campo Cerca campi UDM per valore, poi fai clic su UDM Lookup.
Si apre la finestra di dialogo Ricerca UDM. Lo strumento di ricerca trova corrispondenze per i campi UDM in base al nome del campo o al valore del campo:
- Ricerca per nome campo: corrisponde alla stringa di testo che inserisci nei nomi dei campi che contengono quel testo.
- Ricerca per valore del campo: corrisponde al valore inserito nei campi che contengono quel valore nei dati di log archiviati.
Nella finestra di dialogo Ricerca UDM, seleziona Campi UDM.
La funzione di ricerca mostrerà un elenco di potenziali campi UDM contenenti il testo "pacchetti" nei nomi dei campi UDM.
Fai clic su ogni riga una alla volta per visualizzare la descrizione di ogni campo UDM.
Considerazioni importanti su UDM per evitare errori
- Campi dall'aspetto simile: la struttura gerarchica di UDM può portare a campi con nomi simili. Per informazioni, consulta gli analizzatori sintattici predefiniti. Per maggiori dettagli, vedi Comprendere la mappatura dei dati utilizzata dal parser esistente.
- Mappatura arbitraria dei campi: utilizza l'oggetto
additionalper i dati che non vengono mappati direttamente a un campo UDM. Per maggiori dettagli, vedi Mappatura di campi arbitrari in UDM. - Campi ripetuti: fai attenzione quando utilizzi i campi ripetuti negli snippet di codice. La sostituzione di un intero oggetto potrebbe sovrascrivere i dati originali. L'utilizzo dell'approccio no-code offre un maggiore controllo sui campi ripetuti. Per maggiori dettagli, vedi Ulteriori informazioni sul selettore dei campi ripetuti.
- Campi UDM obbligatori per i tipi di eventi UDM: quando assegni un campo UDM
metadata.event_typea un record UDM, ognievent_typerichiede un diverso insieme di campi correlati da includere nel record UDM. Per maggiori dettagli, vedi Ulteriori informazioni sull'assegnazione dei campimetadata.event_typedi UDM. - Problemi del parser di base: le estensioni del parser non possono correggere gli errori del parser di base. Il parser di base è il parser predefinito (o personalizzato) che ha creato il record UDM. Valuta opzioni come il miglioramento dell'estensione del parser, la modifica del parser di base o il pre-filtraggio dei log.
Mappatura arbitraria dei campi in UDM
Quando non riesci a trovare un campo UDM standard adatto per archiviare i dati, utilizza l'oggetto
additional per archiviare i dati come coppia chiave-valore personalizzata. In questo modo puoi
memorizzare informazioni preziose nel record UDM, anche se non ha un campo UDM corrispondente.
Scegli un approccio di definizione dell'estensione parser
Prima di scegliere un approccio per la definizione dell'estensione del parser, devi aver esaminato queste sezioni:
I passaggi successivi consistono nell'aprire la pagina Estensioni del parser e selezionare l'approccio di estensione da utilizzare per definire l'estensione del parser:
Aprire la pagina delle estensioni del parser
La pagina Estensioni parser ti consente di definire la nuova estensione parser.
Puoi aprire la pagina Estensioni parser nei seguenti modi, dal menu Impostazioni, da una ricerca nei log grezzi o da una ricerca nei log grezzi legacy:
Aprire dal menu Impostazioni
Per aprire la pagina Estensioni del parser dal menu Impostazioni:
Nella barra di navigazione, seleziona Impostazioni SIEM > Parser.
La tabella Parser mostra un elenco di parser predefiniti per tipo di log.
Trova il tipo di log che vuoi estendere, fai clic sul menu > Crea estensione.
Si apre la pagina Estensioni dell'analizzatore sintattico.
Aprire da una ricerca nei log non elaborati
Per aprire la pagina Estensioni del parser da una Ricerca log non elaborati:
- Vai a Indagine > Ricerca SIEM.
- Nel campo di ricerca, aggiungi il prefisso
raw =all'argomento di ricerca e racchiudi il termine di ricerca tra virgolette. Ad esempio,raw = "example.com". - Fai clic su Esegui ricerca. I risultati vengono visualizzati nel riquadro Log grezzi.
- Fai clic su un log (riga) nel riquadro Log grezzi. Viene visualizzato il riquadro Visualizzazione eventi.
- Fai clic sulla scheda Log grezzo nel riquadro Visualizzazione eventi. Viene visualizzato il log non elaborato.
Fai clic su Gestisci parser > Crea estensione > Avanti.
Si apre la pagina Estensioni dell'analizzatore sintattico.
Aprire da una ricerca nei log non elaborati precedente
Per aprire la pagina Estensioni parser da una ricerca di log non elaborati legacy:
- Utilizza la ricerca nei log non elaborati per cercare record simili a quelli che verranno analizzati.
- Seleziona un evento dal riquadro Eventi > Sequenza temporale.
- Espandi il riquadro Dati evento.
Fai clic su Gestisci parser > Crea estensione > Avanti.
Si apre la pagina Estensioni dell'analizzatore sintattico.
Pagina delle estensioni parser
La pagina mostra i riquadri Log grezzo e Definizione dell'estensione:
Riquadro Log non elaborato:
Vengono visualizzati dati di log non elaborati di esempio per il tipo di log selezionato. Se hai aperto la pagina dalla Ricerca log grezzi, i dati di esempio sono il risultato della ricerca. Puoi formattare il campione utilizzando il menu Visualizza come (RAW, JSON, CSV, XML e così via) e la casella di controllo A capo.
Verifica che il campione di dati di log non elaborati visualizzato sia rappresentativo dei log che l'estensione del parser elaborerà.
Fai clic su Visualizza anteprima output UDM per visualizzare l'output UDM per i dati di log non elaborati di esempio.
Riquadro Definizione estensione:
In questo modo puoi definire un'estensione del parser utilizzando uno dei due approcci per le istruzioni di mappatura: Mappa campi di dati (senza codice) o Scrivi snippet di codice. Non puoi utilizzare entrambi gli approcci nella stessa estensione del parser.
A seconda dell'approccio scelto, puoi specificare i campi dei dati di log di origine da estrarre dai log non elaborati in entrata e mapparli ai campi UDM corrispondenti oppure puoi scrivere un frammento di codice per eseguire queste attività e altro ancora.
Seleziona l'approccio di estensione
Nella pagina Estensioni parser, nel riquadro Definizione estensione, nel campo Metodo di estensione, seleziona uno dei seguenti approcci per creare l'estensione parser:
Approccio mappa i campi di dati (senza codice):
Questo approccio ti consente di specificare i campi nel log non elaborato e di mapparli ai campi UDM di destinazione.
Questo approccio funziona con i seguenti formati di log grezzi:
- JSON nativo, XML nativo o CSV.
- Intestazione Syslog più JSON nativo, XML nativo o CSV. Puoi creare istruzioni di mapping dei tipi di campi di dati per i log non elaborati in questi formati:
JSON,XML,CSV,SYSLOG + JSON,SYSLOG + XMLeSYSLOG + CSV.
Consulta i passaggi successivi, Istruzioni per la creazione di campi di dati della mappa no-code.
Approccio Scrivi snippet di codice:
Questo approccio ti consente di utilizzare una sintassi simile a Logstash per specificare le istruzioni per estrarre e trasformare i valori dal log non elaborato e assegnarli ai campi UDM nel record UDM.
Gli snippet di codice utilizzano la stessa sintassi e le stesse sezioni dei parser predefiniti (o personalizzati). Per ulteriori informazioni, consulta Sintassi del parser.
Questo approccio funziona con tutti i formati di dati supportati per quel tipo di log.
Consulta i passaggi successivi, Istruzioni per la creazione di snippet di codice.
Crea istruzioni no-code (mappa i campi di dati)
L'approccio no-code (chiamato anche metodo Mappa campi di dati) ti consente di specificare i percorsi dei campi dei log non elaborati e di mapparli ai campi UDM di destinazione corrispondenti.
Prima di creare un'estensione del parser utilizzando l'approccio no-code, devi aver esaminato le seguenti sezioni:
- Creare estensioni del parser
- Inizia
- Seleziona l'approccio di estensione e scegli l'opzione Mappa i campi di dati.
I passaggi successivi per definire l'estensione del parser sono:
- Impostare il selettore Campi ripetuti
- Definisci un'istruzione di mappatura dei dati per ogni campo
- Inviare e attivare l'estensione parser
Imposta il selettore Campi ripetuti
Nel riquadro Definizione dell'estensione, nel campo Campi ripetuti, imposta
il modo in cui l'estensione del parser deve salvare un valore nei campi ripetuti (campi che
supportano un array di valori, ad esempio principal.ip):
- Aggiungi valori: il valore appena estratto viene aggiunto all'insieme di valori esistenti memorizzati nel campo dell'array UDM.
- Sostituisci valori: il valore appena estratto sostituisce l'insieme di valori esistente nel campo dell'array UDM, precedentemente memorizzato dal parser predefinito.
Le impostazioni nel selettore Campi ripetuti non influiscono sui campi non ripetuti.
Per maggiori dettagli, vedi Ulteriori informazioni sul selettore Campi ripetuti.
Definisci un'istruzione di mappatura dei dati per ogni campo
Definisci un'istruzione di mappatura dei dati per ogni campo che vuoi estrarre dal log non elaborato. L'istruzione deve specificare il percorso del campo di origine nel log non elaborato e mapparlo al campo UDM di destinazione.
Se l'esempio di log non elaborato visualizzato nel riquadro Log non elaborato contiene un'intestazione Syslog, vengono visualizzati i campi Syslog e Destinazione. Alcuni formati di log non contengono un'intestazione Syslog, ad esempio JSON nativo, XML nativo o CSV.
Google SecOps avrà bisogno dei campi Syslog e Target per pre-elaborare l'intestazione Syslog ed estrarre la parte strutturata del log.
Definisci questi campi:
Syslog: si tratta di un pattern definito dall'utente che preelabora e separa un'intestazione Syslog dalla parte strutturata di un log non elaborato.
Specifica il pattern di estrazione, utilizzando Grok e le espressioni regolari, che identifica l'intestazione Syslog e il messaggio di log non elaborato. Per maggiori dettagli, vedi Definire i campi dell'estrattore Syslog.
Destinazione: nome della variabile nel campo Syslog che memorizza la parte strutturata del log.
Specifica il nome della variabile nel pattern di estrazione che memorizza la parte strutturata del log.
Questo è un esempio di pattern di estrazione e di nome variabile per i campi Syslog e Destinazione, rispettivamente.

Dopo aver inserito i valori nei campi Syslog e Destinazione, fai clic sul pulsante Convalida.
La procedura di convalida verifica la presenza di errori di sintassi e di analisi, quindi restituisce uno dei seguenti risultati:
- Operazione riuscita: vengono visualizzati i campi di mappatura dei dati. Definisci il resto dell'estensione del parser.
- Errore: viene visualizzato un messaggio di errore. Correggi la condizione di errore prima di continuare.
(Facoltativo) Definisci un'istruzione di precondizione.
Un'istruzione di precondizione identifica un sottoinsieme dei log non elaborati che l'estensione del parser elabora abbinando un valore statico a un campo nel log non elaborato. Se un log non elaborato in entrata soddisfa i criteri di precondizione, l'estensione del parser applica l'istruzione di mappatura. Se i valori non corrispondono, l'estensione del parser non applica l'istruzione di mappatura.
Completa i seguenti campi:
- Campo precondizione: identificatore del campo nel log non elaborato contenente il valore da confrontare. Inserisci il percorso completo del campo se il formato dei dati dei log è JSON o XML oppure la posizione della colonna se il formato dei dati è CSV.
- Operatore di precondizione: seleziona
EQUALSoNOT EQUALS. - Valore precondizione: il valore statico che verrà confrontato con il Campo precondizione nel log non elaborato.
Per un altro esempio di istruzione di precondizione, consulta No-code - Extract fields with precondition value.
Mappa il campo dei dati di log non elaborati al campo UDM di destinazione:
Campo dati non elaborati: inserisci il percorso completo del campo se il formato dei dati di log è JSON (ad esempio:
jsonPayload.connection.dest_ip) o XML (ad esempio:/Event/Reason-Code) oppure la posizione della colonna se il formato dei dati è CSV (nota: le posizioni dell'indice iniziano da 1).Campo di destinazione: inserisci il nome del campo UDM completo in cui verrà archiviato il valore, ad esempio
udm.metadata.collected_timestamp.seconds.
Per continuare ad aggiungere altri campi, fai clic su Aggiungi e inserisci tutti i dettagli delle istruzioni di mappatura per il campo successivo.
Per un altro esempio di mappatura dei campi, vedi No-code - Extract fields.
Invia e attiva l'estensione parser
Dopo aver definito le istruzioni di mappatura dei dati per tutti i campi che intendi estrarre dal log non elaborato, invia e attiva l'estensione del parser.
Fai clic su Invia per salvare e convalidare l'istruzione di mappatura.
Google SecOps convalida le istruzioni di mappatura:
- Se la procedura di convalida ha esito positivo, lo stato cambia in Live e le istruzioni di mappatura iniziano a elaborare i dati dei log in entrata.
Se la procedura di convalida non va a buon fine, lo stato viene modificato in Non riuscita e viene visualizzato un errore nel campo Log grezzo.
Ecco un esempio di errore di convalida:
ERROR: generic::unknown: pipeline.ParseLogEntry failed: LOG_PARSING_CBN_ERROR: "generic::invalid_argument: pipeline failed: filter mutate (7) failed: copy failure: copy source field \"jsonPayload.dest_instance.region\" must not be empty (try using replace to provide the value before calling copy) "LOG: {"insertId":"14suym9fw9f63r","jsonPayload":{"bytes_sent":"492", "connection":{"dest_ip":"10.12.12.33","dest_port":32768,"protocol":6, "src_ip":"10.142.0.238","src_port":22},"end_time":"2023-02-13T22:38:30.490546349Z", "packets_sent":"15","reporter":"SRC","src_instance":{"project_id":"example-labs", "region":"us-east1","vm_name":"example-us-east1","zone":"us-east1-b"}, "src_vpc":{"project_id":"example-labs","subnetwork_name":"default", "vpc_name":"default"},"start_time":"2023-02-13T22:38:29.024032655Z"}, "logName":"projects/example-labs/logs/compute.googleapis.com%2Fvpc_flows", "receiveTimestamp":"2023-02-13T22:38:37.443315735Z","resource":{"labels": {"location":"us-east1-b","project_id":"example-labs", "subnetwork_id":"00000000000000000000","subnetwork_name":"default"}, "type":"gce_subnetwork"},"timestamp":"2023-02-13T22:38:37.443315735Z"}Stati del ciclo di vita di un'estensione del parser
Le estensioni parser hanno i seguenti stati del ciclo di vita:
DRAFT: Estensione del parser appena creata e non ancora inviata.VALIDATING: Google SecOps sta convalidando le istruzioni di mapping rispetto ai log non elaborati esistenti per garantire che i campi vengano analizzati senza errori.LIVE: l'estensione del parser ha superato la convalida ed è ora in produzione. Estrae e trasforma i dati dai log non elaborati in entrata in record UDM.FAILED: La convalida dell'estensione del parser non è riuscita.
Scopri di più sul selettore Campi ripetuti
Alcuni campi UDM memorizzano un array di valori, ad esempio il campo principal.ip. Il selettore Campi ripetuti consente di controllare il modo in cui l'estensione del parser memorizzerà i nuovi dati estratti in un campo ripetuto:
Aggiungi valori:
L'estensione del parser aggiungerà il valore appena estratto all'array di valori esistenti nel campo UDM.
Sostituisci valori:
L'estensione del parser sostituirà l'array di valori esistenti nel campo UDM con il valore appena estratto.
Un'estensione del parser può mappare i dati a un campo ripetuto solo quando il campo ripetuto si trova al livello più basso della gerarchia. Ad esempio:
- Il mapping dei valori a
udm.principal.ipè supportato perché il campo ripetutoipsi trova al livello più basso della gerarchia eprincipalnon è un campo ripetuto. - La mappatura dei valori su
udm.intermediary.hostnamenon è supportata perchéintermediaryè un campo ripetuto e non si trova al livello più basso della gerarchia.
La tabella seguente fornisce esempi di come la configurazione del selettore Campi ripetuti influisce sul record UDM generato.
| Selezione Campi ripetuti | Log di esempio | Configurazione dell'estensione del parser | Risultato generato |
|---|---|---|---|
| Aggiungi valori | {"protoPayload":{"@type":"type.AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"1.1.1.1, 2.2.2.2"}}} |
Campo precondizione: protoPayload.requestMetadata.callerIp
Valore precondizione: " "
Operatore precondizione: NOT_EQUALS
Campo dati non elaborati: protoPayload.requestMetadata.callerIp
Campo di destinazione: event.idm.read_only_udm.principal.ip
|
metadata:{event_timestamp:{}.....}principal:{Ip:"1.1.1.1, 2.2.2.2"}
}
} |
| Aggiungi valori | {"protoPayload":{"@type":"type.AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"2.2.2.2, 3.3.3.3", "name":"Akamai Ltd"}}} |
Precondizione 1:
Campo precondizione: protoPayload.requestMetadata.callerIp
Valore precondizione: " "
Operatore precondizione: NOT_EQUALS
Campo dati non elaborati: protoPayload.requestMetadata.callerIp
Campo di destinazione: event.idm.read_only_udm.principal.ip
Condizione preliminare 2:
|
Eventi generati dal parser predefinito prima dell'applicazione dell'estensione.
metadata:{event_timestamp:{} ... principal:{ip:"1.1.1.1"}}}
Output dopo l'applicazione dell'estensione.
|
| Sostituisci valori | {"protoPayload":{"@type":"type..AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"2.2.2.2"}}} |
Campo precondizione: protoPayload.authenticationInfo.principalEmail
Valore precondizione: " "
Operatore precondizione: NOT_EQUALS
Campo dati non elaborati: protoPayload.authenticationInfo.principalEmail
Campo di destinazione: event.idm.read_only_udm.principal.ip
|
Eventi UDM generati dall'analizzatore predefinito prima dell'applicazione dell'estensione.timestamp:{} idm:{read_only_udm:{metadata:{event_timestamp:{} ... principal:{ip:"1.1.1.1"}}}
Output UDM dopo l'applicazione dell'estensione
|
Scopri di più sui campi dell'estrattore Syslog
I campi dell'estrattore Syslog ti consentono di separare l'intestazione Syslog da un log strutturato definendo l'espressione Grok, l'espressione regolare e un token denominato nel pattern dell'espressione regolare per archiviare l'output.
Definisci i campi dell'estrattore Syslog
I valori nei campi Syslog e Destinazione funzionano insieme per definire in che modo l'estensione del parser separa l'intestazione Syslog dalla parte strutturata di un log non elaborato. Nel campo Syslog, definisci un'espressione utilizzando una combinazione di sintassi Grok ed espressioni regolari. L'espressione include un nome di variabile che identifica la parte strutturata del log non elaborato. Nel campo Destinazione, specifica il nome della variabile.
L'esempio seguente illustra il funzionamento combinato di questi campi.
Ecco un esempio di log non elaborato:
<13>1 2022-09-14T15:03:04+00:00 fieldname fieldname - - - {"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
Il log non elaborato contiene le seguenti sezioni:
Intestazione Syslog:
<13> 2022-09-14T15:03:04+00:00 fieldname fieldname - - -Evento formattato in JSON:
{"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
Per separare l'intestazione Syslog dalla parte JSON del log non elaborato, utilizza la
seguente espressione di esempio nel campo Syslog:
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg}
- Questa parte dell'espressione identifica l'intestazione Syslog:
%{TIMESTAMP\_ISO8601} %{WORD} %{WORD} ([- ]+)? - Questa parte dell'espressione acquisisce il segmento JSON del log non elaborato:
%{GREEDYDATA:msg}
Questo esempio include il nome della variabile msg. Scegli il nome della variabile.
L'estensione del parser estrae il segmento JSON del log non elaborato e lo assegna
alla variabile msg.
Nel campo Destinazione, inserisci il nome della variabile msg. Il valore memorizzato nella variabile
msg viene inserito nelle istruzioni di mappatura dei campi di dati che crei
nell'estensione del parser.
Utilizzando il log non elaborato di esempio, il seguente segmento viene inserito nell'istruzione di mappatura dei dati:
{"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
Di seguito sono riportati i campi Syslog e Destinazione completati:
La seguente tabella fornisce altri esempi con log di esempio, il pattern di estrazione Syslog, il nome della variabile Target e il risultato.
| Log grezzo di esempio | Campo Syslog | Campo target | Risultato |
|---|---|---|---|
<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}" |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg} |
msg | field_mappings {
field: "msg"
value: "{\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}"
}
|
<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\"} - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"} |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg1} ([- ]+)?%{GREEDYDATA:msg2} |
msg2 | field_mappings {
field: "msg2"
value: "{\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}"
} |
"<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\"} - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}" |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:message} ([- ]+)?%{GREEDYDATA:msg2} |
msg2 | Error - message already exists in state and not overwritable. |
Scopri di più sull'assegnazione dei campi metadata.event_type UDM
Quando assegni un campo UDM metadata.event_type a un record UDM, viene
convalidato per garantire che i campi correlati obbligatori siano presenti nel record UDM. Ogni UDM metadata.event_type richiede un insieme diverso di campi correlati. Ad esempio, un evento USER_LOGIN senza un user non è utile.
Se manca un campo correlato obbligatorio, la convalida UDM restituisce un errore:
"error": {
"code": 400,
"message": "Request contains an invalid argument.",
"status": "INVALID_ARGUMENT"
}
Un parser grok restituisce un errore più dettagliato:
generic::unknown:
invalid event 0: LOG_PARSING_GENERATED_INVALID_EVENT:
"generic::invalid_argument: udm validation failed: target field is not set"
Per trovare i campi obbligatori per un UDM event_type che vuoi assegnare, utilizza le seguenti risorse:
Documentazione di Google SecOps: Guida all'utilizzo di UDM - Campi UDM obbligatori e facoltativi per ogni tipo di evento
Risorse non ufficiali di terze parti: UDM Event Validation
Nei casi in cui la Guida all'utilizzo di UDM non fornisce dettagli, questo documento integra la documentazione ufficiale fornendo i campi UDM obbligatori minimi necessari per compilare un determinato
metadata.event_typeUDM.Ad esempio, apri il documento e cerca il tipo di evento
GROUP_CREATION.Dovresti visualizzare i seguenti campi UDM minimi, presentati come oggetto UDM:
{ "metadata": { "event_timestamp": "2023-07-03T13:01:10.957803Z", "event_type": "GROUP_CREATION" }, "principal": { "user": { "userid": "pinguino" } }, "target": { "group": { "group_display_name": "foobar_users" } } }
Creare istruzioni per gli snippet di codice
L'approccio con snippet di codice consente di utilizzare una sintassi simile a Logstash per definire come estrarre e trasformare i valori dal log non elaborato e assegnarli ai campi UDM nel record UDM.
Prima di creare un'estensione del parser utilizzando l'approccio dello snippet di codice, devi aver esaminato le seguenti sezioni:
- Creare estensioni del parser
- Inizia
- Seleziona l'approccio di estensione e l'opzione Scrivi snippet di codice.
I passaggi successivi per definire l'estensione del parser sono:
- Per suggerimenti e best practice, consulta Suggerimenti e best practice per la scrittura di istruzioni per gli snippet di codice.
- Creare un'istruzione per lo snippet di codice
- Inviare un'istruzione per lo snippet di codice
Suggerimenti e best practice per la scrittura delle istruzioni per gli snippet di codice
Le istruzioni dello snippet di codice possono non riuscire a causa di problemi come pattern Grok errati, operazioni di ridenominazione o sostituzione non riuscite o errori di sintassi. Per suggerimenti e best practice, consulta quanto segue:
- Pratiche comuni nel codice del parser
- Analizzare testo non strutturato utilizzando una funzione Grok
Creare un'istruzione per lo snippet di codice
Le istruzioni dello snippet di codice utilizzano la stessa sintassi e le stesse sezioni del parser predefinito (o personalizzato):
- Sezione 1. Estrai i dati dal log non elaborato.
- Sezione 2. Trasforma i dati estratti.
- Sezione 3. Assegna uno o più valori a un campo UDM.
- Sezione 4. Associa i campi evento UDM alla chiave
@output.
Per creare un'estensione del parser utilizzando l'approccio dello snippet di codice:
- Nella pagina Estensioni parser, nel riquadro Snippet CBN, inserisci uno snippet di codice per creare l'estensione parser.
- Fai clic su Convalida per convalidare le istruzioni di mappatura.
Esempi di istruzioni per gli snippet di codice
Il seguente esempio illustra uno snippet di codice.
Ecco un esempio del log non elaborato:
{
"insertId": "00000000",
"jsonPayload": {
...section omitted for brevity...
"packets_sent": "4",
...section omitted for brevity...
},
"timestamp": "2022-05-03T01:45:00.150614953Z"
}
Questo è un esempio di snippet di codice che mappa il valore in
jsonPayload.packets_sent al campo UDM network.sent_bytes:
filter {
mutate {
replace => {
"jsonPayload.packets_sent" => ""
}
}
# Section 1. extract data from the raw JSON log
json {
source => "message"
array_function => "split_columns"
on_error => "_not_json"
}
if [_not_json] {
drop {
tag => "TAG_UNSUPPORTED"
}
} else {
# Section 2. transform the extracted data
if [jsonPayload][packets_sent] not in ["", 0] {
mutate {
convert => {
"jsonPayload.packets_sent" => "uinteger"
}
on_error => "_exception1"
}
# Section 3. assign the value to a UDM field
mutate {
Replace => {
"event.idm.read_only_udm.network.sent_bytes" => "jsonPayload.packets_sent"
}
on_error => "_exception2"
}
if ![_exception1] and![_exception2] {
# Section 4. Bind the UDM fields to the @output key
mutate {
merge => {
"@output" => "event"
}
}
}
}
}
}
Inviare un'istruzione per lo snippet di codice
Fai clic su Invia per salvare le istruzioni di mappatura.
Google SecOps convalida le istruzioni di mappatura.
- Se la procedura di convalida ha esito positivo, lo stato cambia in Live e le istruzioni di mappatura iniziano a elaborare i dati dei log in entrata.
- Se la procedura di convalida non va a buon fine, lo stato viene modificato in Non riuscita e viene visualizzato un errore nel campo Log grezzo.
Gestisci le estensioni del parser esistenti
Puoi visualizzare, modificare, eliminare e controllare l'accesso alle estensioni del parser esistenti.
Visualizzare un'estensione parser esistente
- Nella barra di navigazione, seleziona Impostazioni SIEM > Parser.
- Nell'elenco Parser, individua il parser (tipo di log) che vuoi visualizzare.
I parser con un'estensione del parser sono indicati dal testo
EXTENSIONaccanto al nome. Vai alla riga e fai clic su Menu > Visualizza estensione.
Viene visualizzata la scheda Visualizza parser personalizzato/predefinito > Estensione che mostra i dettagli sull'estensione del parser. Per impostazione predefinita, nel riquadro del riepilogo viene visualizzata l'estensione del parser
LIVE.
Modificare un'estensione parser
Apri Visualizza parser personalizzato/predefinito > scheda Estensione, come descritto in Visualizzare un'estensione del parser esistente.
Fai clic sul pulsante Modifica estensione.
Viene visualizzata la pagina Estensioni dell'analizzatore sintattico.
Modifica l'estensione parser.
Per annullare la modifica e ignorare le modifiche, fai clic su Ignora bozza.
Per eliminare l'estensione del parser in qualsiasi momento, fai clic su Elimina estensione non riuscita.
Al termine della modifica dell'estensione del parser, fai clic su Invia.
Viene eseguita la procedura di convalida per convalidare la nuova configurazione.
Eliminare un'estensione parser
Apri Visualizza parser personalizzato/predefinito > scheda Estensione, come descritto in Visualizzare un'estensione del parser esistente.
Fai clic sul pulsante Elimina estensione.
Controllare l'accesso alle estensioni parser
Per impostazione predefinita, gli utenti con il ruolo Amministratore possono accedere alle estensioni del parser. Puoi controllare chi può visualizzare e gestire le estensioni del parser. Per ulteriori informazioni sulla gestione di utenti e gruppi o sull'assegnazione di ruoli, consulta Controllo dell'accesso basato sui ruoli.
I nuovi ruoli in Google SecOps sono riassunti nella tabella seguente.
| Funzionalità | Azione | Descrizione |
|---|---|---|
| Parser | Elimina | Elimina le estensioni del parser. |
| Parser | Modifica | Creare e modificare le estensioni del parser. |
| Parser | Visualizza | Visualizza le estensioni del parser. |
Rimuovere le mappature dei campi UDM utilizzando le estensioni del parser
Puoi utilizzare le estensioni del parser per rimuovere una mappatura dei campi UDM esistente.
- Fai clic su Impostazioni SIEM > Parser.
- Utilizza uno dei seguenti metodi per visualizzare la pagina Estensione parser:
- Per un'estensione esistente, fai clic su Menu > Estendi parser > Visualizza estensione.
- Per le nuove estensioni del parser, fai clic su Menu > Estendi parser > Crea estensione.
Seleziona Scrivi snippet di codice come metodo di estensione per aggiungere uno snippet di codice personalizzato che rimuova i valori per campi UDM specifici.
Per un'estensione esistente, nel riquadro Estensione parser, fai clic su Modifica e poi aggiungi lo snippet di codice.
Per esempi di snippet, vedi Snippet di codice - Rimuovi le mappature esistenti.
Segui i passaggi descritti in Inviare un'istruzione di snippet di codice per inviare l'estensione.
Hai bisogno di ulteriore assistenza? Ricevi risposte dai membri della community e dai professionisti di Google SecOps.