Parser-Erweiterungen
In diesem Dokument wird beschrieben, wie Sie Parser-Erweiterungen erstellen, um Felder aus Logrohdaten zu extrahieren und den UDM-Zielfeldern (Unified Data Model) in der Google Security Operations-Plattform zuzuordnen.
Im Dokument wird der Prozess zum Erstellen von Parser-Erweiterungen beschrieben:
- Parser-Erweiterungen erstellen
- Voraussetzungen und Einschränkungen
- Quellfelder in den unformatierten Logdaten identifizieren:
- Wählen Sie die entsprechenden UDM-Zielfelder aus.
Geeigneten Ansatz für die Definition der Parser-Erweiterung auswählen:
Das Definieren einer Parser-Erweiterung umfasst das Entwerfen der Parsing-Logik zum Filtern von Rohlogdaten, das Transformieren der Daten und das Zuordnen der Daten zu UDM-Zielfeldern. Google SecOps bietet zwei Ansätze zum Erstellen von Parsererweiterungen:
- Parsererweiterungen mit dem No-Code-Ansatz (Datenfelder zuordnen) erstellen
- Erstellen Sie Parser-Erweiterungen mit dem Code-Snippet-Ansatz.
Beispiele für die Erstellung von Parsererweiterungen für verschiedene Logformate und ‑szenarien. Beispiele ohne Code mit JSON und Code-Snippets für komplexe Logik oder Nicht-JSON-Formate (CSV, XML, Syslog).
Parsererweiterungen erstellen
Parser-Erweiterungen bieten eine flexible Möglichkeit, die Funktionen vorhandener Standard- und benutzerdefinierter Parser zu erweitern. Parsererweiterungen bieten eine flexible Möglichkeit, die Funktionen vorhandener Standard- oder benutzerdefinierter Parser zu erweitern, ohne sie zu ersetzen. Mit den Erweiterungen können Sie die Parser-Pipeline anpassen, indem Sie neue Parsing-Logik hinzufügen, Felder extrahieren und transformieren sowie UDM-Feldzuordnungen aktualisieren oder entfernen.
Eine Parsererweiterung ist nicht dasselbe wie ein benutzerdefinierter Parser. Sie können einen benutzerdefinierten Parser erstellen für einen Logtyp, für den kein Standardparser vorhanden ist, oder Parser-Updates deaktivieren.
Parser-Extraktions- und ‑Normalisierungsprozess
Google SecOps empfängt Original-Logdaten als Rohlogs. Mit Standard- und benutzerdefinierten Parsern werden wichtige Logfelder extrahiert und in strukturierte UDM-Felder in UDM-Datensätzen normalisiert. Dies ist nur eine Teilmenge der ursprünglichen Rohprotokolldaten. Sie können Parsererweiterungen definieren, um Log-Werte zu extrahieren, die nicht von Standard-Parsern verarbeitet werden. Nach der Aktivierung werden Parser-Erweiterungen Teil des Google SecOps-Prozesses zum Extrahieren und Normalisieren von Daten.
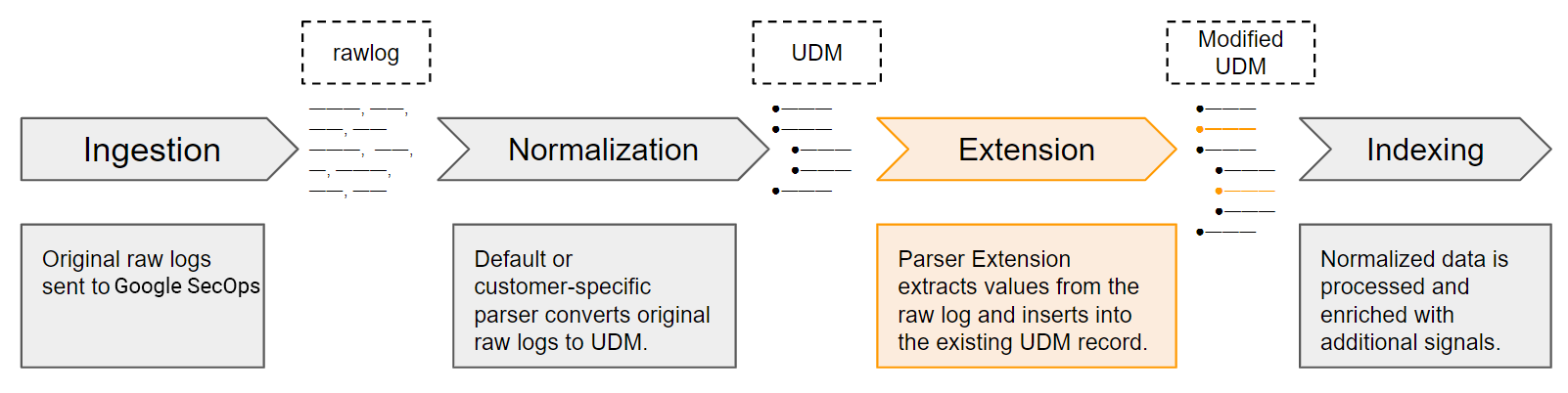
Neue Parser-Erweiterungen definieren
Standardparser enthalten vordefinierte Sätze von Zuordnungsanweisungen, die angeben, wie wichtige Sicherheitswerte extrahiert, transformiert und normalisiert werden. Sie können neue Parsererweiterungen erstellen, indem Sie Zuordnungsanweisungen entweder mit dem No-Code-Ansatz (Datenfelder zuordnen) oder mit dem Code-Snippet-Ansatz definieren:
No-Code-Ansatz
Der No-Code-Ansatz eignet sich am besten für einfache Extraktionen aus Rohlogs im nativen JSON-, XML- oder CSV-Format. Damit können Sie Rohlog-Quellfelder angeben und entsprechende UDM-Zielfelder zuordnen.
Sie können beispielsweise JSON-Logdaten mit bis zu 10 Feldern extrahieren, indem Sie einfache Gleichheitsvergleiche verwenden.
Code-Snippet-Ansatz
Mit dem Code-Snippet-Ansatz können Sie Anweisungen zum Extrahieren und Transformieren von Werten aus dem Rohlog definieren und sie UDM-Feldern zuweisen. Für Code-Snippets wird dieselbe Logstash-ähnliche Syntax wie für den Standardparser (oder einen benutzerdefinierten Parser) verwendet.
Dieser Ansatz gilt für alle unterstützten Logformate. Es eignet sich am besten für folgende Szenarien:
- Komplexe Datenextraktionen oder komplexe Logik.
- Unstrukturierte Daten, für die Grok-basierte Parser erforderlich sind.
- Nicht-JSON-Formate wie CSV und XML.
In den Code-Snippets werden Funktionen verwendet, um bestimmte Daten aus den Rohlogdaten zu extrahieren. Beispiele: Grok, JSON, KV und XML.
In den meisten Fällen empfiehlt es sich, die Datenzuordnungsmethode zu verwenden, die im Standardparser (oder benutzerdefinierten Parser) verwendet wurde.
Neu extrahierte Werte in UDM-Felder zusammenführen
Nach der Aktivierung werden neu extrahierte Werte gemäß vordefinierten Zusammenführungsprinzipien in die entsprechenden UDM-Felder im entsprechenden UDM-Datensatz eingefügt. Beispiel:
Vorhandene Werte überschreiben: Extrahierte Werte überschreiben vorhandene Werte in den UDM-Zielfeldern.
Die einzige Ausnahme sind wiederholte Felder. Hier können Sie die Parser-Erweiterung so konfigurieren, dass neue Werte angehängt werden, wenn Daten in ein wiederholtes Feld im UDM-Datensatz geschrieben werden.
Parser-Erweiterung hat Vorrang: Datenzuordnungsanweisungen in einer Parser-Erweiterung haben Vorrang vor denen im Standard- oder benutzerdefinierten Parser für diesen Logtyp. Bei einem Konflikt in den Zuordnungsanweisungen überschreibt die Parsererweiterung den Standardwert.
Wenn der Standardparser beispielsweise ein Rohlogfeld dem UDM-Feld
event.metadata.descriptionzuordnet und die Parser-Erweiterung ein anderes Rohlogfeld demselben UDM-Feld zuordnet, überschreibt die Parser-Erweiterung den vom Standardparser festgelegten Wert.
Beschränkungen
- Eine Parsererweiterung pro Logtyp: Sie können nur eine Parsererweiterung pro Logtyp erstellen.
- Nur ein Ansatz für die Datenzuordnung: Sie können eine Parser-Erweiterung entweder mit dem No-Code- oder dem Code-Snippet-Ansatz erstellen, aber nicht mit beiden Ansätzen zusammen.
- Log-Beispiele für die Validierung: Zur Validierung einer UDM-Parsererweiterung sind Log-Beispiele aus den letzten 30 Tagen erforderlich. Weitere Informationen finden Sie unter Sicherstellen, dass ein aktiver Parser für den Logtyp vorhanden ist.
- Fehler im Basis-Parser: Fehler im Basis-Parser können in Parser-Erweiterungen nicht identifiziert oder behoben werden.
- Wiederholte Felder in Code-Snippets: Seien Sie vorsichtig, wenn Sie ganze wiederholte Objekte in Code-Snippets ersetzen, um unbeabsichtigten Datenverlust zu vermeiden. Weitere Informationen finden Sie unter Selektor für wiederkehrende Felder.
- Eindeutige Ereignisse: Parsererweiterungen können keine Protokolle mit mehreren eindeutigen Ereignissen in einem einzelnen Datensatz verarbeiten, z. B. Google Drive-Arrays.
XML und No-Code: Der No-Code-Modus wird für XML nicht unterstützt. Verwenden Sie stattdessen die Methode mit dem Code-Snippet.
Keine rückwirkenden Daten: Rohprotokolldaten können nicht rückwirkend geparst werden.
Reservierte Keywords beim Ansatz ohne Programmierung: Wenn die Protokolle eines der folgenden reservierten Keywords enthalten, verwenden Sie den Code-Snippet-Ansatz anstelle des Ansatzes ohne Programmierung:
collectionTimestampcreateTimestampenableCbnForLoopeventfilenamemessagenamespaceoutputonErrorCounttimestamptimezone
Vorhandene Zuordnungen entfernen: Sie können vorhandene UDM-Feldzuordnungen nur mit dem Code-Snippet-Ansatz entfernen.
Zuordnungen für wiederholte IP-Felder entfernen: Sie können keine UDM-Feldzuordnungen für wiederholte IP-Felder entfernen.
Parserkonzepte
In den folgenden Dokumenten werden wichtige Parserkonzepte erläutert:
- Übersicht über das zentrale Datenmodell
- Übersicht über das Parsen von Logs
- Referenz zur Parser-Syntax
Vorbereitung
Voraussetzungen für das Erstellen von Parsererweiterungen:
- Für den Logtyp muss ein aktiver Standard- oder benutzerdefinierter Parser vorhanden sein.
- Google SecOps muss die Rohprotokolle mit einem Standard- oder benutzerdefinierten Parser aufnehmen und normalisieren können.
- Prüfen Sie, ob mit dem aktiven Standard- oder benutzerdefinierten Parser für den Ziellogtyp in den letzten 30 Tagen Rohlogdaten erfasst wurden. Diese Daten sollten eine Stichprobe der Felder enthalten, die Sie extrahieren oder zum Filtern der Log-Einträge verwenden möchten. Sie wird verwendet, um Ihre neuen Anweisungen zur Datenzuordnung zu validieren.
Jetzt starten
Führen Sie vor dem Erstellen einer Parsererweiterung die folgenden Schritte aus:
-
Prüfen Sie, ob ein aktiver Parser für den Protokolltyp vorhanden ist. Wenn noch kein Parser vorhanden ist, erstellen Sie einen benutzerdefinierten Parser.
Felder identifizieren, die aus den Rohlogs extrahiert werden sollen:
Geben Sie die Felder an, die Sie aus den Rohlogs extrahieren möchten.
Geeignete UDM-Felder auswählen:
Wählen Sie die entsprechenden UDM-Felder aus, um die extrahierten Rohlogfelder zuzuordnen.
Ansatz für die Definition der Parser-Erweiterung auswählen:
Wählen Sie einen der beiden Erweiterungsansätze (Ansätze für die Datenzuordnung) aus, um die Parsererweiterung zu erstellen.
Voraussetzungen prüfen
Achten Sie darauf, dass ein aktiver Parser für den Protokolltyp vorhanden ist, den Sie erweitern möchten, wie in den folgenden Abschnitten beschrieben:
Achten Sie darauf, dass ein aktiver Parser für den Protokolltyp vorhanden ist.
Achten Sie darauf, dass für den Logtyp, den Sie erweitern möchten, ein aktiver Standard- oder benutzerdefinierter Parser vorhanden ist.
Suchen Sie in diesen Listen nach Ihrem Logtyp:
Unterstützte Logtypen mit einem Standardparser.
- Wenn ein Standardparser für den Logtyp vorhanden ist, muss der Parser aktiv sein.
- Wenn kein Standardparser für den Logtyp vorhanden ist, muss ein benutzerdefinierter Parser für den Logtyp vorhanden sein.
Unterstützte Logtypen ohne Standardparser.
- Wenn kein Standardparser für den Logtyp vorhanden ist, muss ein benutzerdefinierter Parser für den Logtyp vorhanden sein.
Achten Sie darauf, dass ein benutzerdefinierter Parser für den Logtyp vorhanden ist.
So prüfen Sie, ob ein benutzerdefinierter Parser für einen Logtyp vorhanden ist:
- Wählen Sie in der Navigationsleiste SIEM Settings (SIEM-Einstellungen) > Parsers (Parser) aus.
Suchen Sie in der Tabelle Parser nach dem Logtyp, den Sie erweitern möchten.
- Wenn für diesen Logtyp noch kein Standard- oder benutzerdefinierter Parser vorhanden ist, klicken Sie auf PARSER ERSTELLEN und folgen Sie der Anleitung unter Benutzerdefinierten Parser anhand von Zuordnungsanweisungen erstellen.
- Wenn für diesen Logtyp bereits ein benutzerdefinierter Parser vorhanden ist, achten Sie darauf, dass der Parser aktiv ist.
Prüfen, ob der Parser für den Logtyp aktiv ist
So prüfen Sie, ob ein Parser für einen Logtyp aktiv ist:
- Wählen Sie in der Navigationsleiste SIEM Settings (SIEM-Einstellungen) > Parsers (Parser) aus.
Suchen Sie in der Tabelle Parser nach dem Logtyp, den Sie erweitern möchten.
Wenn der Parser für den Protokolltyp nicht aktiv ist, aktivieren Sie ihn:
- Informationen zu Standard-Parsern finden Sie unter Updates für integrierte Parser verwalten.
- Informationen zu benutzerdefinierten Parsern finden Sie unter Updates für benutzerdefinierte Parser verwalten.
Felder identifizieren, die aus den Rohlogs extrahiert werden sollen
Analysieren Sie das Rohlog, aus dem Sie Daten extrahieren möchten, um die Felder zu ermitteln, die vom Standardparser (oder benutzerdefinierten Parser) nicht extrahiert werden. Achten Sie darauf, wie der Standard- oder benutzerdefinierte Parser Rohlogfelder extrahiert und den entsprechenden UDM-Feldern zuordnet.
Um die spezifischen Felder zu ermitteln, die Sie aus den Rohlogs extrahieren möchten, können Sie die Suchtools verwenden:
Um auf das Suchtool zuzugreifen, gehen Sie zu Prüfung > SIEM-Suche. Geben Sie vor Ihrer Suchanfrage raw= ein. Weitere Informationen finden Sie unter Rohlog-Suche durchführen.
Wenn Sie auf das Legacy-Suchtool zugreifen möchten, klicken Sie oben auf der Seite SIEM Search (SIEM-Suche) auf Go to Legacy search (Zur Legacy-Suche). Weitere Informationen finden Sie unter Rohlogs mit der Rohlog-Analyse durchsuchen.
Weitere Informationen zum Suchen in den Rohlogs finden Sie in den folgenden Hilfeartikeln:
Geeignete UDM-Felder auswählen
Nachdem Sie die spezifischen Zielfelder für die Extraktion ermittelt haben, können Sie sie den entsprechenden UDM-Zielfeldern zuordnen. Richten Sie eine klare Zuordnung zwischen den Rohlogquellenfeldern und den zugehörigen UDM-Zielfeldern ein. Sie können Daten einem beliebigen UDM-Feld zuordnen, das die Standarddatentypen oder wiederholten Felder unterstützt.
Das richtige UDM-Feld auswählen
Die folgenden Ressourcen können Ihnen helfen, den Prozess zu vereinfachen:
- Mit den wichtigsten UDM-Konzepten vertraut machen
- Datenzuordnung des vorhandenen Parsers nachvollziehen
- Mit dem UDM-Suchtool können Sie potenzielle UDM-Felder finden, die Ihren Quellfeldern entsprechen.
- Der Leitfaden Wichtige UDM-Felder für die Zuordnung von Parserdaten enthält eine Zusammenfassung und Erläuterung der am häufigsten verwendeten Felder des UDM-Schemas.
- Die Liste der Felder für einheitliche Datenmodelle enthält eine Liste aller UDM-Felder und ihrer Beschreibungen. Wiederkehrende Felder sind in den Listen mit dem Label repeated gekennzeichnet.
- Wichtige Hinweise zum UDM, um Fehler zu vermeiden
Machen Sie sich mit den wichtigsten UDM-Konzepten vertraut.
Logische Objekte: Ereignis und Entität
Das UDM-Schema beschreibt alle verfügbaren Attribute, in denen Daten gespeichert werden. Jeder UDM-Datensatz beschreibt ein Ereignis oder eine Entität. Die Daten werden in verschiedenen Feldern gespeichert, je nachdem, ob der Datensatz ein Ereignis oder eine Einheit beschreibt.
- In einem UDM-Ereignis-Objekt werden Daten zur Aktion gespeichert, die in der Umgebung stattgefunden hat. Das ursprüngliche Ereignislog beschreibt die Aktion, wie sie vom Gerät aufgezeichnet wurde, z. B. von der Firewall oder dem Webproxy.
- In UDM Entity-Objekten werden Daten zu den Teilnehmern oder Entitäten gespeichert, die am UDM-Ereignis beteiligt sind, z. B. Assets, Nutzer oder Ressourcen in Ihrer Umgebung.
UDM-Substantive: Ein Substantiv steht für einen Teilnehmer oder eine Entität in einem UDM-Ereignis. Ein Nomen kann beispielsweise das Gerät oder der Nutzer sein, der die im Ereignis beschriebene Aktivität ausführt. Ein Nomen kann auch das Gerät oder der Nutzer sein, das bzw. der das Ziel der im Ereignis beschriebenen Aktivität ist.
UDM-Substantiv Beschreibung principalDie Entität, die für die Einleitung der im Ereignis beschriebenen Aktion verantwortlich ist. targetDie Entität, die Empfänger oder Objekt der Aktion ist. Bei einer Firewallverbindung wäre der Computer, der die Verbindung empfängt, das Ziel. srcEine Quellentität, auf die das Hauptkonto zugreift. Wenn ein Nutzer beispielsweise eine Datei von einem Computer auf einen anderen kopiert, werden die Datei und der Computer, von dem sie stammt, als „src“ dargestellt. intermediaryJede Entität, die als Vermittler im Ereignis fungiert, z. B. ein Proxyserver. Sie können die Aktion beeinflussen, z. B. eine Anfrage blockieren oder ändern. observerEine Einheit, die das Ereignis überwacht und darüber berichtet, aber nicht direkt mit dem Traffic interagiert. Beispiele hierfür sind Systeme zur Erkennung von Netzwerkeinbrüchen oder Systeme zur Verwaltung von Sicherheitsinformationen und Ereignissen. aboutAlle anderen am Ereignis beteiligten Rechtssubjekte, die nicht in die vorherigen Kategorien passen. Beispiele sind E‑Mail-Anhänge oder geladene DLLs beim Starten eines Prozesses. In der Praxis werden die Haupt- und Ziel-Noun-Objekte am häufigsten verwendet. Die vorangegangenen Beschreibungen stellen die empfohlene Verwendung von Nomen dar. Die tatsächliche Nutzung kann je nach Implementierung eines Standard- oder benutzerdefinierten Basis-Parsers variieren.
Datenzuordnung des vorhandenen Parsers verstehen
Es wird empfohlen, die vorhandene Datenzuordnung des Standard- oder benutzerdefinierten Parsers zwischen den Rohlog-Quellfeldern und den UDM-Zielfeldern zu verstehen.
So sehen Sie die Datenzuordnung zwischen den Quellfeldern für Rohlogs und den UDM-Zielfeldern, die im vorhandenen Standardparser (oder benutzerdefinierten Parser) verwendet werden:
- Wählen Sie in der Navigationsleiste SIEM Settings (SIEM-Einstellungen) > Parsers (Parser) aus.
- Suchen Sie in der Tabelle Parser nach dem Logtyp, den Sie erweitern möchten.
Klicken Sie in dieser Zeile auf das Menü > Anzeigen.
Auf dem Tab Parser Code sehen Sie die Datenzuordnung zwischen den Feldern der Rohlog-Quelle und den UDM-Zielfeldern, die im vorhandenen Standard- oder benutzerdefinierten Parser verwendet werden.
UDM-Lookup-Tool verwenden
Mit dem UDM Lookup-Tool können Sie UDM-Felder ermitteln, die den Feldern der Rohlog-Quelle entsprechen.
Google SecOps bietet das UDM Lookup tool, mit dem Sie schnell UDM-Zielfelder finden können. Um auf das UDM-Suchtool zuzugreifen, gehen Sie zu Untersuchung > SIEM-Suche.
Weitere Informationen zur Verwendung des UDM Lookup-Tools finden Sie in den folgenden Themen:
- UDM-Feld suchen
- UDM-Suchanfrage eingeben
- Zeitfilter für die Suche festlegen
- Beispiele für UDM-Suchanfragen
- UDM-Suchanfragen mit Gemini generieren
Beispiel für das UDM-Lookup-Tool
Wenn Sie beispielsweise ein Quellfeld im Rohlog mit dem Namen „packets“ haben, können Sie mit dem UDM-Lookup-Tool nach potenziellen UDM-Zielfeldern suchen, deren Name „packets“ enthält:
Klicken Sie auf Untersuchung > SIEM-Suche.
Geben Sie auf der Seite SIEM Search (SIEM-Suche) „packets“ (Pakete) in das Feld Look up UDM fields by value (Nach UDM-Feldern anhand des Werts suchen) ein und klicken Sie auf UDM Lookup (UDM-Suche).
Das Dialogfeld UDM Lookup wird geöffnet. Das Suchtool gleicht UDM-Felder entweder nach Feldname oder Feldwert ab:
- Suche nach Feldname: Der eingegebene Textstring wird mit Feldnamen abgeglichen, die diesen Text enthalten.
- Suche nach Feldwert: Der eingegebene Wert wird mit Feldern abgeglichen, die diesen Wert in ihren gespeicherten Logdaten enthalten.
Wählen Sie im Dialogfeld UDM Lookup (UDM-Suche) die Option UDM Fields (UDM-Felder) aus.
Die Suchfunktion zeigt eine Liste potenzieller UDM-Felder an, deren UDM-Feldnamen den Text „packets“ enthalten.
Klicken Sie nacheinander auf die einzelnen Zeilen, um die Beschreibung der einzelnen UDM-Felder aufzurufen.
Wichtige UDM-Aspekte zur Vermeidung von Fehlern
- Felder mit ähnlichem Aussehen: Die hierarchische Struktur von UDM kann zu Feldern mit ähnlichen Namen führen. Weitere Informationen finden Sie unter „Standardparser“. Weitere Informationen finden Sie unter Vom vorhandenen Parser verwendetes Daten-Mapping.
- Beliebige Feldzuordnung: Verwenden Sie das
additional-Objekt für Daten, die nicht direkt einem UDM-Feld zugeordnet werden. Weitere Informationen finden Sie unter Beliebige Felder in UDM zuordnen. - Wiederkehrende Felder: Seien Sie vorsichtig, wenn Sie in Code-Snippets mit wiederkehrenden Feldern arbeiten. Wenn Sie ein ganzes Objekt ersetzen, werden die Originaldaten möglicherweise überschrieben. Mit dem No-Code-Ansatz haben Sie mehr Kontrolle über wiederholte Felder. Weitere Informationen finden Sie unter Selektor für wiederkehrende Felder.
- Erforderliche UDM-Felder für UDM-Ereignistypen: Wenn Sie einem UDM-Datensatz ein UDM-
metadata.event_type-Feld zuweisen, ist für jedesevent_typeeine andere Gruppe zugehöriger Felder im UDM-Datensatz erforderlich. Weitere Informationen finden Sie unter UDM-Felder fürmetadata.event_typezuweisen. - Probleme mit dem Basisparser: Parser-Erweiterungen können keine Fehler des Basisparsers beheben. Der Basisparser ist der Standard- oder benutzerdefinierte Parser, mit dem der UDM-Datensatz erstellt wurde. Sie können beispielsweise die Parser-Erweiterung optimieren, den Basis-Parser ändern oder Logs vorfiltern.
Beliebige Feldzuordnung in UDM
Wenn Sie kein geeignetes Standard-UDM-Feld zum Speichern Ihrer Daten finden, verwenden Sie das additional-Objekt, um die Daten als benutzerdefiniertes Schlüssel/Wert-Paar zu speichern. So können Sie wertvolle Informationen im UDM-Datensatz speichern, auch wenn kein entsprechendes UDM-Feld vorhanden ist.
Ansatz für die Definition einer Parser-Erweiterung auswählen
Bevor Sie sich für eine Methode zur Definition von Parsererweiterungen entscheiden, müssen Sie die folgenden Abschnitte durchgearbeitet haben:
In den nächsten Schritten müssen Sie die Seite Parser-Erweiterungen öffnen und den Erweiterungsansatz auswählen, mit dem die Parser-Erweiterung definiert werden soll:
Seite „Parser-Erweiterungen“ öffnen
Auf der Seite Parser-Erweiterungen können Sie die neue Parser-Erweiterung definieren.
Sie haben folgende Möglichkeiten, die Seite Parser-Erweiterungen zu öffnen: über das Menü „Einstellungen“, über eine Rohlog-Suche oder über eine alte Rohlog-Suche:
Über das Einstellungsmenü öffnen
So öffnen Sie die Seite Parser-Erweiterungen über das Menü „Einstellungen“:
Wählen Sie in der Navigationsleiste SIEM Settings (SIEM-Einstellungen) > Parsers (Parser) aus.
In der Tabelle Parser wird eine Liste der Standardparser nach Logtyp angezeigt.
Suchen Sie den Logtyp, den Sie erweitern möchten, klicken Sie auf das Menü > Erweiterung erstellen.
Die Seite Parser-Erweiterungen wird geöffnet.
Über eine Rohlogsuche öffnen
So öffnen Sie die Seite Parser-Erweiterungen über eine Roh-Log-Suche:
- Klicken Sie auf Untersuchung > SIEM-Suche.
- Fügen Sie dem Suchargument im Suchfeld das Präfix
raw =hinzu und setzen Sie den Suchbegriff in Anführungszeichen. Beispiel:raw = "example.com". - Klicken Sie auf Suche ausführen. Die Ergebnisse werden im Bereich Rohlogs angezeigt.
- Klicken Sie im Bereich Rohdatenprotokolle auf ein Protokoll (eine Zeile). Der Bereich Ereignisansicht wird angezeigt.
- Klicken Sie im Bereich Ereignisansicht auf den Tab Rohlog. Das Rohdatenlog wird angezeigt.
Klicken Sie auf Parser verwalten > Erweiterung erstellen > Weiter.
Die Seite Parser-Erweiterungen wird geöffnet.
Über die alte Rohlogsuche öffnen
So öffnen Sie die Seite Parser-Erweiterungen über die alte Roh-Log-Suche:
- Verwenden Sie die alte Rohlog-Suche, um nach Datensätzen zu suchen, die denen ähneln, die geparst werden.
- Wählen Sie im Bereich Ereignisse > Zeitachse ein Ereignis aus.
- Maximieren Sie den Bereich Ereignisdaten.
Klicken Sie auf Parser verwalten > Erweiterung erstellen > Weiter.
Die Seite Parser-Erweiterungen wird geöffnet.
Seite „Parser-Erweiterungen“
Auf der Seite werden die Bereiche Rohlog und Erweiterungsdefinition angezeigt:
Bereich Rohlog:
Hier werden Beispiel-Rohlogdaten für den ausgewählten Logtyp angezeigt. Wenn Sie die Seite über die Rohlog-Suche geöffnet haben, sind die Beispieldaten das Ergebnis Ihrer Suche. Sie können das Beispiel über das Menü View as (Anzeigen als) (RAW, JSON, CSV, XML usw.) und das Kästchen Wrap Text (Text umbrechen) formatieren.
Prüfen Sie, ob die angezeigte Stichprobe der Rohprotokolldaten repräsentativ für die Protokolle ist, die von der Parsererweiterung verarbeitet werden.
Klicken Sie auf UDM-Ausgabe in der Vorschau ansehen, um die UDM-Ausgabe für die Beispiel-Rohlogdaten aufzurufen.
Bereich Erweiterungsdefinition:
So können Sie eine Parsererweiterung mit einem von zwei Mapping-Anweisungen definieren: Datenfelder zuordnen (ohne Code) oder Code-Snippet schreiben. Sie können nicht beide Ansätze in derselben Parsererweiterung verwenden.
Je nach Ansatz können Sie entweder die Quellfelder für Logdaten angeben, die aus den eingehenden Rohlogs extrahiert und den entsprechenden UDM-Feldern zugeordnet werden sollen, oder ein Code-Snippet schreiben, um diese und weitere Aufgaben auszuführen.
Erweiterungsansatz auswählen
Wählen Sie auf der Seite Parser-Erweiterungen im Bereich Erweiterungsdefinition im Feld Erweiterungsmethode eine der folgenden Methoden zum Erstellen der Parser-Erweiterung aus:
Datenfelder zuordnen (No-Code):
So können Sie die Felder im Rohlog angeben und den UDM-Zielfeldern zuordnen.
Dieser Ansatz funktioniert mit den folgenden Rohlogformaten:
- Natives JSON, natives XML oder CSV.
- Syslog-Header plus natives JSON, natives XML oder CSV. Sie können Anleitungen zum Zuordnen von Datentypen für Rohlogs in den folgenden Formaten erstellen:
JSON,XML,CSV,SYSLOG + JSON,SYSLOG + XMLundSYSLOG + CSV.
Anleitung zum Erstellen von Karten ohne Code (Kartendatenfelder zuordnen)
Code-Snippet schreiben:
Bei diesem Ansatz können Sie eine Logstash-ähnliche Syntax verwenden, um Anweisungen zum Extrahieren und Transformieren von Werten aus dem Rohlog anzugeben und sie UDM-Feldern im UDM-Datensatz zuzuweisen.
Code-Snippets verwenden dieselbe Syntax und dieselben Abschnitte wie Standard- oder benutzerdefinierte Parser. Weitere Informationen finden Sie unter Parser-Syntax.
Dieser Ansatz funktioniert mit allen unterstützten Datenformaten für diesen Logtyp.
Anleitungen ohne Code erstellen (Kartendatenfelder zuordnen)
Mit dem Ansatz ohne Code (auch Datenfelder zuordnen genannt) können Sie die Pfade der Rohlogfelder angeben und sie den entsprechenden UDM-Zielfeldern zuordnen.
Bevor Sie eine Parsererweiterung ohne Code erstellen, müssen Sie die folgenden Abschnitte durchgearbeitet haben:
- Parsererweiterungen erstellen
- Jetzt loslegen
- Wählen Sie den Erweiterungsansatz aus und dann die Option Datenfelder zuordnen.
Die nächsten Schritte zum Definieren der Parsererweiterung sind:
- Selektor für wiederkehrende Felder festlegen
- Für jedes Feld eine Datenzuordnungsanweisung definieren
- Parser-Erweiterung einreichen und aktivieren
Wiederkehrende Felder auswählen
Legen Sie im Bereich Erweiterungsdefinition im Feld Wiederholte Felder fest, wie die Parsererweiterung einen Wert in wiederholten Feldern speichern soll. Das sind Felder, die ein Array von Werten unterstützen, z. B. principal.ip:
- Werte anhängen: Der neu extrahierte Wert wird an den vorhandenen Satz von Werten angehängt, der im UDM-Arrayfeld gespeichert ist.
- Werte ersetzen: Der neu extrahierte Wert ersetzt die vorhandenen Werte im UDM-Arrayfeld, die zuvor vom Standardparser gespeichert wurden.
Einstellungen im Selektor Wiederholte Felder wirken sich nicht auf nicht wiederholte Felder aus.
Weitere Informationen finden Sie unter Weitere Informationen zur Auswahl für wiederkehrende Felder.
Für jedes Feld eine Datenzuordnungsanweisung definieren
Definieren Sie für jedes Feld, das Sie aus dem Rohlog extrahieren möchten, eine Datenzuordnungsanweisung. In der Anleitung sollte der Pfad des Ursprungsfelds im Rohlog angegeben und dem UDM-Zielfeld zugeordnet werden.
Wenn das im Bereich Rohlog angezeigte Rohlogbeispiel einen Syslog-Header enthält, werden die Felder Syslog und Ziel angezeigt. Einige Logformate enthalten keinen Syslog-Header, z. B. natives JSON, natives XML oder CSV.
Für Google SecOps sind die Felder Syslog und Target erforderlich, um den Syslog-Header vorab zu verarbeiten und den strukturierten Teil des Logs zu extrahieren.
Definieren Sie die folgenden Felder:
Syslog: Dies ist ein benutzerdefiniertes Muster, mit dem ein Syslog-Header aus dem strukturierten Teil eines Rohlogs vorverarbeitet und getrennt wird.
Geben Sie das Extraktionsmuster mit Grok und regulären Ausdrücken an, das den Syslog-Header und die Rohlog-Nachricht identifiziert. Weitere Informationen finden Sie unter Syslog-Extraktorfelder definieren.
Ziel: Variablenname im Syslog-Feld, in dem der strukturierte Teil des Logs gespeichert wird.
Geben Sie den Variablennamen im Extraktionsmuster an, in dem der strukturierte Teil des Logs gespeichert wird.
Dies ist ein Beispiel für ein Extraktionsmuster und einen Variablennamen für die Felder Syslog und Target.

Nachdem Sie Werte in die Felder Syslog und Ziel eingegeben haben, klicken Sie auf die Schaltfläche Validieren.
Bei der Validierung wird sowohl nach Syntax- als auch nach Parsing-Fehlern gesucht. Anschließend wird eines der folgenden Ergebnisse zurückgegeben:
- Erfolgreich: Die Felder für die Datenzuordnung werden angezeigt. Definieren Sie den Rest der Parsererweiterung.
- Fehler: Eine Fehlermeldung wird angezeigt. Beheben Sie den Fehler, bevor Sie fortfahren.
Definieren Sie optional eine Precondition-Anweisung.
Mit einer Precondition-Anweisung wird eine Teilmenge der Rohprotokolle angegeben, die von der Parsererweiterung verarbeitet werden. Dazu wird ein statischer Wert mit einem Feld im Rohprotokoll verglichen. Wenn ein eingehender Rohlog die Vorbedingungskriterien erfüllt, wendet die Parsererweiterung die Zuordnungsanweisung an. Wenn die Werte nicht übereinstimmen, wendet die Parsererweiterung die Zuordnungsanweisung nicht an.
Füllen Sie die folgenden Felder aus:
- Feld für Vorbedingung: Feld-ID im Rohlog, die den zu vergleichenden Wert enthält. Geben Sie entweder den vollständigen Pfad zum Feld ein, wenn das Logdatenformat JSON oder XML ist, oder die Spaltenposition, wenn das Datenformat CSV ist.
- Vorbedingungs-Operator: Wählen Sie
EQUALSoderNOT EQUALSaus. - Vorbedingungswert: Der statische Wert, der mit dem Vorbedingungsfeld im Rohlog verglichen wird.
Ein weiteres Beispiel für eine Precondition-Anweisung finden Sie unter No-Code – Felder mit Precondition-Wert extrahieren.
Ordnen Sie das Rohlogdatenfeld dem UDM-Zielfeld zu:
Rohdatenfeld: Geben Sie entweder den vollständigen Pfad zum Feld ein, wenn das Logdatenformat JSON (z. B.
jsonPayload.connection.dest_ip) oder XML (z. B./Event/Reason-Code) ist, oder die Spaltenposition, wenn das Datenformat CSV ist (Hinweis: Indexpositionen beginnen bei 1).Zielfeld: Geben Sie den vollqualifizierten UDM-Feldnamen ein, in dem der Wert gespeichert werden soll, z. B.
udm.metadata.collected_timestamp.seconds.
Wenn Sie weitere Felder hinzufügen möchten, klicken Sie auf Hinzufügen und geben Sie alle Details zur Zuordnungsanweisung für das nächste Feld ein.
Ein weiteres Beispiel für die Zuordnung der Felder finden Sie unter No-Code – Felder extrahieren.
Parser-Erweiterung einreichen und aktivieren
Nachdem Sie Datenzuordnungsanweisungen für alle Felder definiert haben, die Sie aus dem Rohlog extrahieren möchten, senden Sie die Parsererweiterung ein und aktivieren Sie sie.
Klicken Sie auf Senden, um die Zuordnungsanweisung zu speichern und zu validieren.
Google SecOps überprüft die Zuordnungsanweisungen:
- Wenn die Validierung erfolgreich ist, ändert sich der Status zu Live und die Mapping-Anweisungen beginnen mit der Verarbeitung eingehender Protokolldaten.
Wenn die Validierung fehlschlägt, ändert sich der Status zu Fehlgeschlagen und im Feld „Rohlog“ wird ein Fehler angezeigt.
Hier ein Beispiel für einen Validierungsfehler:
ERROR: generic::unknown: pipeline.ParseLogEntry failed: LOG_PARSING_CBN_ERROR: "generic::invalid_argument: pipeline failed: filter mutate (7) failed: copy failure: copy source field \"jsonPayload.dest_instance.region\" must not be empty (try using replace to provide the value before calling copy) "LOG: {"insertId":"14suym9fw9f63r","jsonPayload":{"bytes_sent":"492", "connection":{"dest_ip":"10.12.12.33","dest_port":32768,"protocol":6, "src_ip":"10.142.0.238","src_port":22},"end_time":"2023-02-13T22:38:30.490546349Z", "packets_sent":"15","reporter":"SRC","src_instance":{"project_id":"example-labs", "region":"us-east1","vm_name":"example-us-east1","zone":"us-east1-b"}, "src_vpc":{"project_id":"example-labs","subnetwork_name":"default", "vpc_name":"default"},"start_time":"2023-02-13T22:38:29.024032655Z"}, "logName":"projects/example-labs/logs/compute.googleapis.com%2Fvpc_flows", "receiveTimestamp":"2023-02-13T22:38:37.443315735Z","resource":{"labels": {"location":"us-east1-b","project_id":"example-labs", "subnetwork_id":"00000000000000000000","subnetwork_name":"default"}, "type":"gce_subnetwork"},"timestamp":"2023-02-13T22:38:37.443315735Z"}Lebenszyklusstatus einer Parsererweiterung
Parser-Erweiterungen haben die folgenden Lebenszyklusstatus:
DRAFT: Neu erstellte Parsererweiterung, die noch nicht eingereicht wurde.VALIDATING: Google SecOps validiert die Zuordnungsanweisungen anhand vorhandener Rohlogs, um sicherzustellen, dass Felder fehlerfrei geparst werden.LIVE: Die Parsererweiterung hat die Validierung bestanden und wird jetzt in der Produktion verwendet. Sie extrahiert und transformiert Daten aus eingehenden Rohlogs in UDM-Datensätze.FAILED: Die Parsererweiterung hat die Validierung nicht bestanden.
Weitere Informationen zur Auswahl für wiederkehrende Felder
In einigen UDM-Feldern wird ein Array mit Werten gespeichert, z. B. im Feld principal.ip. Mit der Auswahl Wiederholte Felder können Sie festlegen, wie Ihre Parsererweiterung neu extrahierte Daten in einem wiederholten Feld speichert:
Werte anhängen:
Die Parsererweiterung hängt den neu extrahierten Wert an das Array der vorhandenen Werte im UDM-Feld an.
Werte ersetzen:
Die Parsererweiterung ersetzt das Array mit vorhandenen Werten im UDM-Feld durch den neu extrahierten Wert.
Eine Parsererweiterung kann Daten nur dann einem wiederholten Feld zuordnen, wenn sich das wiederholte Feld auf der untersten Ebene der Hierarchie befindet. Beispiel:
- Das Zuordnen von Werten zu
udm.principal.ipwird unterstützt, da sich das wiederholte Feldipauf der untersten Ebene der Hierarchie befindet undprincipalkein wiederholtes Feld ist. - Das Zuordnen von Werten zu
udm.intermediary.hostnamewird nicht unterstützt, daintermediaryein wiederholtes Feld ist und sich nicht auf der niedrigsten Ebene der Hierarchie befindet.
In der folgenden Tabelle finden Sie Beispiele dafür, wie sich die Konfiguration der Auswahloption Wiederholte Felder auf den generierten UDM-Datensatz auswirkt.
| Auswahl von wiederkehrenden Feldern | Beispiellog | Konfiguration der Parser-Erweiterung | Generiertes Ergebnis |
|---|---|---|---|
| Werte anhängen | {"protoPayload":{"@type":"type.AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"1.1.1.1, 2.2.2.2"}}} |
Vorbedingungsfeld: protoPayload.requestMetadata.callerIp
Vorbedingungswert: " "
Vorbedingungsoperator: NOT_EQUALS
Rohdatenfeld: protoPayload.requestMetadata.callerIp
Zielfeld: event.idm.read_only_udm.principal.ip
|
metadata:{event_timestamp:{}.....}principal:{Ip:"1.1.1.1, 2.2.2.2"}
}
} |
| Werte anhängen | {"protoPayload":{"@type":"type.AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"2.2.2.2, 3.3.3.3", "name":"Akamai Ltd"}}} |
Vorbedingung 1:
Vorbedingungsfeld protoPayload.requestMetadata.callerIp:Vorbedingungswert " ": Vorbedingungsoperator NOT_EQUALS: Rohdatenfeld protoPayload.requestMetadata.callerIp: Zielfeld event.idm.read_only_udm.principal.ip:
Vorbedingung 2:
|
Ereignisse, die vom integrierten Parser generiert wurden, bevor die Erweiterung angewendet wurde.
metadata:{event_timestamp:{} ... principal:{ip:"1.1.1.1"}}}
Ausgabe nach Anwendung der Erweiterung.
|
| Werte ersetzen | {"protoPayload":{"@type":"type..AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"2.2.2.2"}}} |
Vorbedingungsfeld: protoPayload.authenticationInfo.principalEmail
Vorbedingungswert: " "
Vorbedingungsoperator: NOT_EQUALS
Rohdatenfeld: protoPayload.authenticationInfo.principalEmail
Zielfeld: event.idm.read_only_udm.principal.ip
|
UDM-Ereignisse, die vom integrierten Parser vor dem Anwenden der Erweiterung generiert wurden.timestamp:{} idm:{read_only_udm:{metadata:{event_timestamp:{} ... principal:{ip:"1.1.1.1"}}}
UDM-Ausgabe nach Anwendung der Erweiterung
|
Weitere Informationen zu den Syslog-Extractor-Feldern
Mit den Syslog-Extractor-Feldern können Sie den Syslog-Header von einem strukturierten Log trennen. Dazu definieren Sie den Grok-Ausdruck, den regulären Ausdruck und ein benanntes Token im Muster des regulären Ausdrucks, um die Ausgabe zu speichern.
Felder für Syslog-Extraktor definieren
Die Werte in den Feldern Syslog und Target definieren gemeinsam, wie die Parsererweiterung den Syslog-Header vom strukturierten Teil eines Rohlogs trennt. Im Feld Syslog definieren Sie einen Ausdruck mit einer Kombination aus Grok- und regulärer Ausdruckssyntax. Der Ausdruck enthält einen Variablennamen, der den strukturierten Teil des Rohlogs identifiziert. Im Feld Ziel geben Sie diesen Variablennamen an.
Das folgende Beispiel veranschaulicht, wie diese Felder zusammenwirken.
Hier ein Beispiel für ein Rohprotokoll:
<13>1 2022-09-14T15:03:04+00:00 fieldname fieldname - - - {"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
Das Rohlog enthält die folgenden Abschnitte:
Syslog-Header:
<13> 2022-09-14T15:03:04+00:00 fieldname fieldname - - -JSON-formatiertes Ereignis:
{"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
Um den Syslog-Header vom JSON-Teil des Rohlogs zu trennen, verwenden Sie den folgenden Beispielausdruck im Feld Syslog:
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg}
- Dieser Teil des Ausdrucks identifiziert den Syslog-Header:
%{TIMESTAMP\_ISO8601} %{WORD} %{WORD} ([- ]+)? - Dieser Teil des Ausdrucks erfasst das JSON-Segment des Rohlogs:
%{GREEDYDATA:msg}
Dieses Beispiel enthält den Variablennamen msg. Sie wählen den Variablennamen aus.
Die Parsererweiterung extrahiert das JSON-Segment des Rohlogs und weist es der Variablen msg zu.
Geben Sie im Feld Ziel den Variablennamen msg ein. Der in der Variablen msg gespeicherte Wert wird als Eingabe für die Anweisungen zur Zuordnung von Datenfeldern verwendet, die Sie in der Parsererweiterung erstellen.
Anhand des Beispiel-Rohlogs wird das folgende Segment in die Datenzuordnungsanweisung eingegeben:
{"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
Im Folgenden sehen Sie die ausgefüllten Felder Syslog und Ziel:
Die folgende Tabelle enthält weitere Beispiele mit Beispiellogs, dem Syslog-Extraktionsmuster, dem Namen der Ziel-Variablen und dem Ergebnis.
| Beispiel für ein Rohlog | Syslog-Feld | Zielfeld | Ergebnis |
|---|---|---|---|
<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}" |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg} |
msg | field_mappings {
field: "msg"
value: "{\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}"
}
|
<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\"} - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"} |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg1} ([- ]+)?%{GREEDYDATA:msg2} |
msg2 | field_mappings {
field: "msg2"
value: "{\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}"
} |
"<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\"} - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}" |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:message} ([- ]+)?%{GREEDYDATA:msg2} |
msg2 | Error - message already exists in state and not overwritable. |
Weitere Informationen zum Zuweisen von metadata.event_type-Feldern für UDM
Wenn Sie einem UDM-Datensatz ein UDM-Feld metadata.event_type zuweisen, wird es validiert, um sicherzustellen, dass die erforderlichen zugehörigen Felder im UDM-Datensatz vorhanden sind. Für jedes UDM-metadata.event_type sind unterschiedliche zugehörige Felder erforderlich. Ein USER_LOGIN-Ereignis ohne user ist beispielsweise nicht sinnvoll.
Wenn ein erforderliches zugehöriges Feld fehlt, gibt die UDM-Validierung einen Fehler zurück:
"error": {
"code": 400,
"message": "Request contains an invalid argument.",
"status": "INVALID_ARGUMENT"
}
Ein Grok-Parser gibt einen detaillierteren Fehler zurück:
generic::unknown:
invalid event 0: LOG_PARSING_GENERATED_INVALID_EVENT:
"generic::invalid_argument: udm validation failed: target field is not set"
Mit den folgenden Ressourcen können Sie die Pflichtfelder für eine UDM-event_type ermitteln, die Sie zuweisen möchten:
Google SecOps-Dokumentation: UDM Usage Guide - Required and optional UDM fields for each Event Type (UDM-Leitfaden – Erforderliche und optionale UDM-Felder für jeden Ereignistyp)
Inoffizielle Drittanbieterressourcen: UDM Event Validation
Wenn die UDM-Anleitung nicht detailliert genug ist, wird die offizielle Dokumentation in diesem Dokument ergänzt. Es enthält die erforderlichen UDM-Mindestfelder, die zum Ausfüllen eines bestimmten UDM-
metadata.event_typebenötigt werden.Öffnen Sie beispielsweise das Dokument und suchen Sie nach dem Ereignistyp
GROUP_CREATION.Sie sollten die folgenden UDM-Mindestfelder als UDM-Objekt sehen:
{ "metadata": { "event_timestamp": "2023-07-03T13:01:10.957803Z", "event_type": "GROUP_CREATION" }, "principal": { "user": { "userid": "pinguino" } }, "target": { "group": { "group_display_name": "foobar_users" } } }
Anleitung zum Erstellen von Code-Snippets
Mit dem Code-Snippet-Ansatz können Sie Logstash-ähnliche Syntax verwenden, um zu definieren, wie Werte aus dem Rohlog extrahiert und transformiert und UDM-Feldern im UDM-Datensatz zugewiesen werden.
Bevor Sie eine Parsererweiterung mit dem Code-Snippet-Ansatz erstellen, müssen Sie die folgenden Abschnitte durchgearbeitet haben:
- Parsererweiterungen erstellen
- Jetzt loslegen
- Wählen Sie den Erweiterungsansatz aus und dann die Option Code-Snippet schreiben.
Die nächsten Schritte zum Definieren der Parsererweiterung sind:
- Tipps und Best Practices finden Sie unter Tipps und Best Practices für das Schreiben von Anleitungen für Code-Snippets.
- Anleitung für Code-Snippet erstellen
- Anleitung für ein Code-Snippet einreichen
Tipps und Best Practices für das Schreiben von Anweisungen für Code-Snippets
Anleitungen für Code-Snippets können aufgrund von Problemen wie falschen Grok-Mustern, fehlgeschlagenen Umbenennungs- oder Ersetzungsvorgängen oder Syntaxfehlern fehlschlagen. Hier finden Sie Tipps und Best Practices:
Anleitung für Code-Snippet erstellen
Für Code-Snippet-Anweisungen werden dieselbe Syntax und dieselben Abschnitte wie für den Standardparser (oder einen benutzerdefinierten Parser) verwendet:
- Bereich 1. Daten aus dem Rohprotokoll extrahieren
- Bereich 2. Extrahierte Daten transformieren
- Bereich 3. Weisen Sie einem UDM-Feld einen oder mehrere Werte zu.
- Abschnitt 4. Binden Sie UDM-Ereignisfelder an den
@output-Schlüssel.
So erstellen Sie eine Parsererweiterung mit dem Code-Snippet-Ansatz:
- Geben Sie auf der Seite Parser-Erweiterungen im Bereich CBN-Snippet ein Code-Snippet ein, um die Parser-Erweiterung zu erstellen.
- Klicken Sie auf Validieren, um die Zuordnungsanweisungen zu validieren.
Beispiele für Anweisungen für Code-Snippets
Das folgende Beispiel veranschaulicht ein Code-Snippet.
Hier ein Beispiel für das Rohprotokoll:
{
"insertId": "00000000",
"jsonPayload": {
...section omitted for brevity...
"packets_sent": "4",
...section omitted for brevity...
},
"timestamp": "2022-05-03T01:45:00.150614953Z"
}
Hier sehen Sie ein Beispiel für ein Code-Snippet, mit dem der Wert in jsonPayload.packets_sent dem UDM-Feld network.sent_bytes zugeordnet wird:
filter {
mutate {
replace => {
"jsonPayload.packets_sent" => ""
}
}
# Section 1. extract data from the raw JSON log
json {
source => "message"
array_function => "split_columns"
on_error => "_not_json"
}
if [_not_json] {
drop {
tag => "TAG_UNSUPPORTED"
}
} else {
# Section 2. transform the extracted data
if [jsonPayload][packets_sent] not in ["", 0] {
mutate {
convert => {
"jsonPayload.packets_sent" => "uinteger"
}
on_error => "_exception1"
}
# Section 3. assign the value to a UDM field
mutate {
Replace => {
"event.idm.read_only_udm.network.sent_bytes" => "jsonPayload.packets_sent"
}
on_error => "_exception2"
}
if ![_exception1] and![_exception2] {
# Section 4. Bind the UDM fields to the @output key
mutate {
merge => {
"@output" => "event"
}
}
}
}
}
}
Anleitung für Code-Snippet senden
Klicken Sie auf Senden, um die Zuordnungsanleitung zu speichern.
Google SecOps überprüft die Zuordnungsanweisungen.
- Wenn die Validierung erfolgreich ist, ändert sich der Status zu Live und die Mapping-Anweisungen beginnen mit der Verarbeitung eingehender Protokolldaten.
- Wenn die Validierung fehlschlägt, ändert sich der Status zu Fehlgeschlagen und im Feld „Rohlog“ wird ein Fehler angezeigt.
Vorhandene Parsererweiterungen verwalten
Sie können vorhandene Parsererweiterungen aufrufen, bearbeiten, löschen und den Zugriff darauf steuern.
Vorhandene Parser-Erweiterung ansehen
- Wählen Sie in der Navigationsleiste SIEM Settings (SIEM-Einstellungen) > Parsers (Parser) aus.
- Suchen Sie in der Liste „Parser“ nach dem Parser (Logtyp), den Sie aufrufen möchten.
Parser mit einer Parsererweiterung werden durch den Text
EXTENSIONneben ihrem Namen gekennzeichnet. Klicken Sie in dieser Zeile auf das Dreipunkt-Menü Menü > Erweiterung ansehen.
Der Tab Erweiterung wird angezeigt. Klicken Sie auf Benutzerdefinierten/vorgefertigten Parser ansehen, um Details zur Parsererweiterung aufzurufen. Im Zusammenfassungsfeld wird standardmäßig die
LIVE-Parsererweiterung angezeigt.
Parser-Erweiterung bearbeiten
Öffnen Sie den Tab Erweiterung unter Benutzerdefinierten/vorgefertigten Parser ansehen, wie unter Vorhandene Parsererweiterung ansehen beschrieben.
Klicken Sie auf die Schaltfläche Erweiterung bearbeiten.
Die Seite Parser-Erweiterungen wird angezeigt.
Bearbeiten Sie die Parser-Erweiterung.
Wenn Sie die Bearbeitung abbrechen und die Änderungen verwerfen möchten, klicken Sie auf Entwurf verwerfen.
Wenn Sie die Parsererweiterung jederzeit löschen möchten, klicken Sie auf Fehlerhafte Erweiterung löschen.
Wenn Sie die Bearbeitung der Parsererweiterung abgeschlossen haben, klicken Sie auf Senden.
Der Validierungsprozess wird ausgeführt, um die neue Konfiguration zu validieren.
Parser-Erweiterung löschen
Öffnen Sie den Tab Erweiterung unter Benutzerdefinierten/vorgefertigten Parser ansehen, wie unter Vorhandene Parsererweiterung ansehen beschrieben.
Klicken Sie auf die Schaltfläche Erweiterung löschen.
Zugriff auf Parser-Erweiterungen steuern
Standardmäßig können Nutzer mit der Rolle Administrator auf Parser-Erweiterungen zugreifen. Sie können festlegen, wer Parsererweiterungen ansehen und verwalten darf. Weitere Informationen zum Verwalten von Nutzern und Gruppen oder zum Zuweisen von Rollen finden Sie unter Rollenbasierte Zugriffssteuerung.
Die neuen Rollen in Google SecOps sind in der folgenden Tabelle zusammengefasst.
| Feature | Aktion | Beschreibung |
|---|---|---|
| Parser | Löschen | Parser-Erweiterungen löschen |
| Parser | Bearbeiten | Parser-Erweiterungen erstellen und bearbeiten |
| Parser | Ansehen | Parser-Erweiterungen ansehen |
UDM-Feldzuordnungen mit Parsererweiterungen entfernen
Mit Parser-Erweiterungen können Sie eine vorhandene UDM-Feldzuordnung entfernen.
- Klicken Sie auf SIEM Settings > Parsers.
- Sie haben zwei Möglichkeiten, die Seite Parser-Erweiterung aufzurufen:
- Klicken Sie bei einer vorhandenen Erweiterung auf Menü > Parser erweitern > Erweiterung ansehen.
- Klicken Sie für neue Parser-Erweiterungen auf Menü > Parser erweitern > Erweiterung erstellen.
Wählen Sie Code-Snippet schreiben als Erweiterungsmethode aus, um ein benutzerdefiniertes Code-Snippet hinzuzufügen, mit dem Werte für bestimmte UDM-Felder entfernt werden.
Klicken Sie für eine vorhandene Erweiterung im Bereich Parser-Erweiterung auf Bearbeiten und fügen Sie dann den Code-Snippet hinzu.
Beispiel-Snippets finden Sie unter Code-Snippet – Vorhandene Zuordnungen entfernen.
Folgen Sie der Anleitung unter Anleitung für Code-Snippet einreichen, um die Erweiterung einzureichen.
Benötigen Sie weitere Hilfe? Antworten von Community-Mitgliedern und Google SecOps-Experten erhalten