In dieser Anleitung visualisieren Sie Daten aus raumbezogenen Analysen aus BigQuery mit einem Colab-Notebook.
In dieser Anleitung werden die folgenden öffentlichen BigQuery-Datasets verwendet:
- San Francisco Ford GoBike Share
- Stadtteile von San Francisco
- Berichte des San Francisco Police Department (SFPD)
Informationen zum Zugriff auf diese öffentlichen Datasets finden Sie unter Auf öffentliche Datasets in der Google Cloud Console zugreifen.
Sie verwenden die öffentlichen Datasets, um die folgenden Visualisierungen zu erstellen:
- Ein Streudiagramm aller Bikesharing-Stationen aus dem Ford GoBike Share-Dataset
- Polygone im Dataset „San Francisco Neighborhoods“
- Eine Choroplethenkarte der Anzahl der Bikesharing-Stationen nach Stadtteil
- Eine Heatmap mit Vorfällen aus dem Datensatz „Polizeiberichte in San Francisco“
Ziele
- Richten Sie die Authentifizierung mit Google Cloud und optional mit Google Maps ein.
- Daten in BigQuery abfragen und die Ergebnisse in Colab herunterladen
- Python-Data-Science-Tools für Transformationen und Analysen verwenden
- Visualisierungen erstellen, z. B. Streudiagramme, Polygone, Choroplethenkarten und Heatmaps.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Google Maps JavaScript APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the BigQuery and Google Maps JavaScript APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Prüfen Sie, ob Sie die erforderlichen Berechtigungen haben, um die Aufgaben in diesem Dokument ausführen zu können.
- BigQuery User (
roles/bigquery.user) -
In the Google Cloud console, go to the IAM page.
Go to IAM - Select the project.
-
In the Principal column, find all rows that identify you or a group that you're included in. To learn which groups you're included in, contact your administrator.
- For all rows that specify or include you, check the Role column to see whether the list of roles includes the required roles.
-
In the Google Cloud console, go to the IAM page.
IAM aufrufen - Wählen Sie das Projekt aus.
- Klicken Sie auf Zugriffsrechte erteilen.
-
Geben Sie im Feld Neue Hauptkonten Ihre Nutzer-ID ein. Das ist in der Regel die E‑Mail-Adresse eines Google-Kontos.
- Wählen Sie in der Liste Rolle auswählen eine Rolle aus.
- Klicken Sie auf Weitere Rolle hinzufügen, wenn Sie weitere Rollen zuweisen möchten.
- Klicken Sie auf Speichern.
Öffnen Sie Colab.
Klicken Sie im Dialogfeld Notebook öffnen auf Neues Notebook.
Klicken Sie auf
Untitled0.ipynbund ändern Sie den Namen des Notebooks inbigquery-geo.ipynb.Wählen Sie Datei > Speichern aus.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um sich mit Ihrem Projekt zu authentifizieren:
# REQUIRED: Authenticate with your project. GCP_PROJECT_ID = "PROJECT_ID" #@param {type:"string"} from google.colab import auth from google.colab import userdata auth.authenticate_user(project_id=GCP_PROJECT_ID) # Set GMP_API_KEY to none GMP_API_KEY = None
Ersetzen Sie PROJECT_ID durch Ihre Projekt-ID.
Klicken Sie auf Zelle ausführen.
Wenn Sie dazu aufgefordert werden, klicken Sie auf Zulassen, um Colab Zugriff auf Ihre Anmeldedaten zu gewähren, sofern Sie damit einverstanden sind.
Wählen Sie auf der Seite Über Google anmelden Ihr Konto aus.
Klicken Sie auf der Seite Bei Notebook-Code von Drittanbietern anmelden auf Weiter.
Klicken Sie unter Select what third-party authored notebook code can access (Auswählen, worauf Notebook-Code von Drittanbietern zugreifen kann) auf Select all (Alle auswählen) und dann auf Continue (Weiter).
Nach Abschluss des Autorisierungsvorgangs wird in Ihrem Colab-Notebook keine Ausgabe generiert. Das Häkchen neben der Zelle gibt an, dass der Code erfolgreich ausgeführt wurde.
Rufen Sie Ihren Google Maps API-Schlüssel ab, indem Sie der Anleitung auf der Seite API-Schlüssel verwenden in der Google Maps-Dokumentation folgen.
Wechseln Sie zu Ihrem Colab-Notebook und klicken Sie dann auf Secrets.
Klicken Sie auf Neues Secret hinzufügen.
Geben Sie für Name
GMP_API_KEYein.Geben Sie unter Wert den zuvor generierten Maps API-Schlüsselwert ein.
Schließen Sie den Bereich Secrets.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um sich mit der Maps API zu authentifizieren:
# Authenticate with the Google Maps JavaScript API. GMP_API_SECRET_KEY_NAME = "GMP_API_KEY" #@param {type:"string"} if GMP_API_SECRET_KEY_NAME: GMP_API_KEY = userdata.get(GMP_API_SECRET_KEY_NAME) if GMP_API_SECRET_KEY_NAME else None else: GMP_API_KEY = None
Wenn Sie dazu aufgefordert werden, klicken Sie auf Zugriff gewähren, um dem Notebook Zugriff auf Ihren Schlüssel zu gewähren, sofern Sie damit einverstanden sind.
Klicken Sie auf Zelle ausführen.
Nach Abschluss des Autorisierungsvorgangs wird in Ihrem Colab-Notebook keine Ausgabe generiert. Das Häkchen neben der Zelle gibt an, dass der Code erfolgreich ausgeführt wurde.
geopandas, um die vonpandasverwendeten Datentypen zu erweitern und räumliche Vorgänge für geometrische Typen zu ermöglichen.shapelyfür die Bearbeitung und Analyse einzelner planarer geometrischer Objekte.brancazum Generieren von HTML- und JavaScript-Farbkarten.geemap.deckfür die Visualisierung mitpydeckundearthengine-api.Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um die Pakete
pydeckundh3zu installieren:# Install pydeck and h3. !pip install pydeck>=0.9 h3>=4.2
Klicken Sie auf Zelle ausführen.
Nach Abschluss der Installation wird in Ihrem Colab-Notebook keine Ausgabe generiert. Das Häkchen neben der Zelle gibt an, dass der Code erfolgreich ausgeführt wurde.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um die Python-Bibliotheken zu importieren:
# Import data science libraries. import branca import geemap.deck as gmdk import h3 import pydeck as pdk import geopandas as gpd import shapely
Klicken Sie auf Zelle ausführen.
Nachdem Sie den Code ausgeführt haben, wird in Ihrem Colab-Notebook keine Ausgabe generiert. Das Häkchen neben der Zelle gibt an, dass der Code erfolgreich ausgeführt wurde.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um
pandas-DataFrames zu aktivieren:# Enable displaying pandas data frames as interactive tables by default. from google.colab import data_table data_table.enable_dataframe_formatter()
Klicken Sie auf Zelle ausführen.
Nachdem Sie den Code ausgeführt haben, wird in Ihrem Colab-Notebook keine Ausgabe generiert. Das Häkchen neben der Zelle gibt an, dass der Code erfolgreich ausgeführt wurde.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um eine gemeinsame Routine zum Rendern von Layern auf einer Karte zu erstellen:
# Set Google Maps as the base map provider. MAP_PROVIDER_GOOGLE = pdk.bindings.base_map_provider.BaseMapProvider.GOOGLE_MAPS.value # Shared routine for rendering layers on a map using geemap.deck. def display_pydeck_map(layers, view_state, **kwargs): deck_kwargs = kwargs.copy() # Use Google Maps as the base map only if the API key is provided. if GMP_API_KEY: deck_kwargs.update({ "map_provider": MAP_PROVIDER_GOOGLE, "map_style": pdk.bindings.map_styles.GOOGLE_ROAD, "api_keys": {MAP_PROVIDER_GOOGLE: GMP_API_KEY}, }) m = gmdk.Map(initial_view_state=view_state, ee_initialize=False, **deck_kwargs) for layer in layers: m.add_layer(layer) return m
Klicken Sie auf Zelle ausführen.
Nachdem Sie den Code ausgeführt haben, wird in Ihrem Colab-Notebook keine Ausgabe generiert. Das Häkchen neben der Zelle gibt an, dass der Code erfolgreich ausgeführt wurde.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um das öffentliche Dataset „San Francisco Ford GoBike Share“ abzufragen. In diesem Code wird die Magic-Funktion
%%bigqueryverwendet, um die Abfrage auszuführen und die Ergebnisse in einem DataFrame zurückzugeben:# Query the station ID, station name, station short name, and station # geometry from the bike share dataset. # NOTE: In this tutorial, the denormalized 'lat' and 'lon' columns are # ignored. They are decomposed components of the geometry. %%bigquery gdf_sf_bikestations --project {GCP_PROJECT_ID} --use_geodataframe station_geom SELECT station_id, name, short_name, station_geom FROM `bigquery-public-data.san_francisco_bikeshare.bikeshare_station_info`
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um eine Zusammenfassung des DataFrames zu erhalten, einschließlich Spalten und Datentypen:
# Get a summary of the DataFrame gdf_sf_bikestations.info()
Klicken Sie auf Zelle ausführen.
Die Ausgabe sollte so aussehen:
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 472 entries, 0 to 471 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 station_id 472 non-null object 1 name 472 non-null object 2 short_name 472 non-null object 3 station_geom 472 non-null geometry dtypes: geometry(1), object(3) memory usage: 14.9+ KBWenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um sich die ersten fünf Zeilen des DataFrames als Vorschau anzeigen zu lassen:
# Preview the first five rows gdf_sf_bikestations.head()
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:

Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um die Längen- und Breitenwerte aus der Spalte
station_geomzu extrahieren:# Extract the longitude (x) and latitude (y) from station_geom. gdf_sf_bikestations["longitude"] = gdf_sf_bikestations["station_geom"].x gdf_sf_bikestations["latitude"] = gdf_sf_bikestations["station_geom"].y
Klicken Sie auf Zelle ausführen.
Nachdem Sie den Code ausgeführt haben, wird in Ihrem Colab-Notebook keine Ausgabe generiert. Das Häkchen neben der Zelle gibt an, dass der Code erfolgreich ausgeführt wurde.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um das Streudiagramm der Leihradstationen basierend auf den zuvor extrahierten Längen- und Breitengradwerten zu rendern:
# Render a scatter plot using pydeck with the extracted longitude and # latitude columns in the gdf_sf_bikestations geopandas.GeoDataFrame. scatterplot_layer = pdk.Layer( "ScatterplotLayer", id="bike_stations_scatterplot", data=gdf_sf_bikestations, get_position=['longitude', 'latitude'], get_radius=100, get_fill_color=[255, 0, 0, 140], # Adjust color as desired pickable=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([scatterplot_layer], view_state)
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:
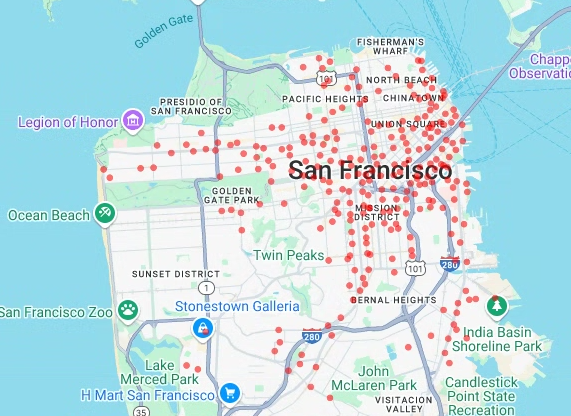
- Punkte
- Linien
- Polygone
- Multipolygone
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um die geografischen Daten aus der Tabelle
bigquery-public-data.san_francisco_neighborhoods.boundariesim Dataset „San Francisco Neighborhoods“ abzufragen. In diesem Code wird die%%bigquery-Magic-Funktion verwendet, um die Abfrage auszuführen und die Ergebnisse in einem DataFrame zurückzugeben:# Query the neighborhood name and geometry from the San Francisco # neighborhoods dataset. %%bigquery gdf_sanfrancisco_neighborhoods --project {GCP_PROJECT_ID} --use_geodataframe geometry SELECT neighborhood, neighborhood_geom AS geometry FROM `bigquery-public-data.san_francisco_neighborhoods.boundaries`
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um eine Zusammenfassung des DataFrames zu erhalten:
# Get a summary of the DataFrame gdf_sanfrancisco_neighborhoods.info()
Klicken Sie auf Zelle ausführen.
Die Ergebnisse sollten so aussehen:
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 117 entries, 0 to 116 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 neighborhood 117 non-null object 1 geometry 117 non-null geometry dtypes: geometry(1), object(1) memory usage: 2.0+ KBGeben Sie den folgenden Code ein, um die erste Zeile des DataFrames als Vorschau anzeigen zu lassen:
# Preview the first row gdf_sanfrancisco_neighborhoods.head(1)
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:

Die Daten in den Ergebnissen sind ein Polygon.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um die Polygone zu visualisieren. Mit
pydeckwird jedeshapely-Objektinstanz in der Geometriespalte in dasGeoJSON-Format konvertiert:# Visualize the polygons. geojson_layer = pdk.Layer( 'GeoJsonLayer', id="sf_neighborhoods", data=gdf_sanfrancisco_neighborhoods, get_line_color=[127, 0, 127, 255], get_fill_color=[60, 60, 60, 50], get_line_width=100, pickable=True, stroked=True, filled=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([geojson_layer], view_state)
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:
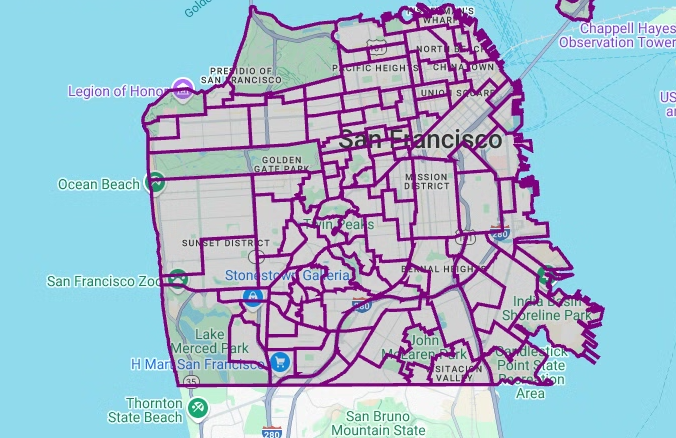
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um die Anzahl der Stationen pro Stadtteil zu aggregieren und zu zählen und eine Spalte
polygonzu erstellen, die ein Array von Punkten enthält:# Aggregate and count the number of stations per neighborhood. gdf_count_stations = gdf_sanfrancisco_neighborhoods.sjoin(gdf_sf_bikestations, how='left', predicate='contains') gdf_count_stations = gdf_count_stations.groupby(by='neighborhood')['station_id'].count().rename('num_stations') gdf_stations_x_neighborhood = gdf_sanfrancisco_neighborhoods.join(gdf_count_stations, on='neighborhood', how='inner') # To simulate non-GeoJSON input data, create a polygon column that contains # an array of points by using the pandas.Series.map method. gdf_stations_x_neighborhood['polygon'] = gdf_stations_x_neighborhood['geometry'].map(lambda g: list(g.exterior.coords))
Klicken Sie auf Zelle ausführen.
Nachdem Sie den Code ausgeführt haben, wird in Ihrem Colab-Notebook keine Ausgabe generiert. Das Häkchen neben der Zelle gibt an, dass der Code erfolgreich ausgeführt wurde.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um für jedes Polygon eine
fill_color-Spalte hinzuzufügen:# Create a color map gradient using the branch library, and add a fill_color # column for each of the polygons. colormap = branca.colormap.LinearColormap( colors=["lightblue", "darkred"], vmin=0, vmax=gdf_stations_x_neighborhood['num_stations'].max(), ) gdf_stations_x_neighborhood['fill_color'] = gdf_stations_x_neighborhood['num_stations'] \ .map(lambda c: list(colormap.rgba_bytes_tuple(c)[:3]) + [0.7 * 255]) # force opacity of 0.7
Klicken Sie auf Zelle ausführen.
Nachdem Sie den Code ausgeführt haben, wird in Ihrem Colab-Notebook keine Ausgabe generiert. Das Häkchen neben der Zelle gibt an, dass der Code erfolgreich ausgeführt wurde.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um die Polygonebene zu rendern:
# Render the polygon layer. polygon_layer = pdk.Layer( 'PolygonLayer', id="bike_stations_choropleth", data=gdf_stations_x_neighborhood, get_polygon='polygon', get_fill_color='fill_color', get_line_color=[0, 0, 0, 255], get_line_width=50, pickable=True, stroked=True, filled=True, ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([polygon_layer], view_state)
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:
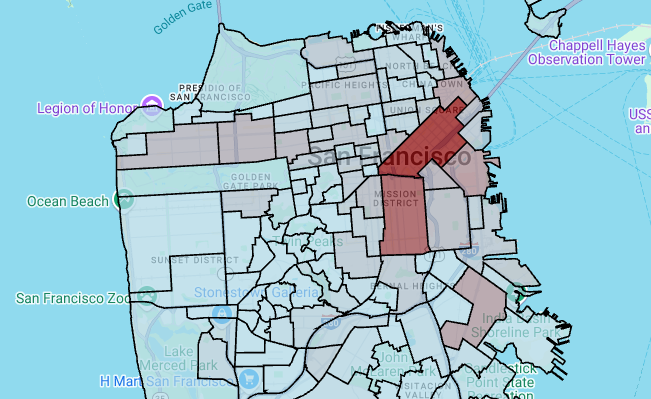
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um die Daten im Dataset „Polizeiberichte in San Francisco“ abzufragen. In diesem Code wird die
%%bigquery-Magic-Funktion verwendet, um die Abfrage auszuführen und die Ergebnisse in einem DataFrame zurückzugeben:# Query the incident key and location data from the SFPD reports dataset. %%bigquery gdf_incidents --project {GCP_PROJECT_ID} --use_geodataframe location_geography SELECT unique_key, location_geography FROM ( SELECT unique_key, SAFE.ST_GEOGFROMTEXT(location) AS location_geography, # WKT string to GEOMETRY EXTRACT(YEAR FROM timestamp) AS year, FROM `bigquery-public-data.san_francisco_sfpd_incidents.sfpd_incidents` incidents ) WHERE year = 2015
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:
Job ID 12345-1234-5678-1234-123456789 successfully executed: 100%Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Um die Zelle für den Breiten- und Längengrad jedes Vorfalls zu berechnen, aggregieren Sie die Vorfälle für jede Zelle, erstellen Sie einen
geopandas-DataFrame und fügen Sie den Mittelpunkt jedes Sechsecks für die Heatmap-Ebene hinzu. Geben Sie dazu den folgenden Code ein:# Compute the cell for each incident's latitude and longitude. H3_RESOLUTION = 9 gdf_incidents['h3_cell'] = gdf_incidents.geometry.apply( lambda geom: h3.latlng_to_cell(geom.y, geom.x, H3_RESOLUTION) ) # Aggregate the incidents for each hexagon cell. count_incidents = gdf_incidents.groupby(by='h3_cell')['unique_key'].count().rename('num_incidents') # Construct a new geopandas.GeoDataFrame with the aggregate results. # Add the center of each hexagon for the HeatmapLayer to render. gdf_incidents_x_cell = gpd.GeoDataFrame(data=count_incidents).reset_index() gdf_incidents_x_cell['h3_center'] = gdf_incidents_x_cell['h3_cell'].apply(h3.cell_to_latlng) gdf_incidents_x_cell.info()
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 969 entries, 0 to 968 Data columns (total 3 columns): # Column Non-Null Count Dtype -- ------ -------------- ----- 0 h3_cell 969 non-null object 1 num_incidents 969 non-null Int64 2 h3_center 969 non-null object dtypes: Int64(1), object(2) memory usage: 23.8+ KBWenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um sich die ersten fünf Zeilen des DataFrames als Vorschau anzeigen zu lassen:
# Preview the first five rows. gdf_incidents_x_cell.head()
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:

Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um die Daten in ein JSON-Format zu konvertieren, das von
HeatmapLayerverwendet werden kann:# Convert to a JSON format recognized by the HeatmapLayer. def _make_heatmap_datum(row) -> dict: return { "latitude": row['h3_center'][0], "longitude": row['h3_center'][1], "weight": float(row['num_incidents']), } heatmap_data = gdf_incidents_x_cell.apply(_make_heatmap_datum, axis='columns').values.tolist()
Klicken Sie auf Zelle ausführen.
Nachdem Sie den Code ausgeführt haben, wird in Ihrem Colab-Notebook keine Ausgabe generiert. Das Häkchen neben der Zelle gibt an, dass der Code erfolgreich ausgeführt wurde.
Wenn Sie eine Codezelle einfügen möchten, klicken Sie auf Code.
Geben Sie den folgenden Code ein, um die Heatmap zu rendern:
# Render the heatmap. heatmap_layer = pdk.Layer( "HeatmapLayer", id="sfpd_heatmap", data=heatmap_data, get_position=['longitude', 'latitude'], get_weight='weight', opacity=0.7, radius_pixels=99, # this limitation can introduce artifacts (see above) aggregation='MEAN', ) view_state = pdk.ViewState(latitude=37.77613, longitude=-122.42284, zoom=12) display_pydeck_map([heatmap_layer], view_state)
Klicken Sie auf Zelle ausführen.
Die Ausgabe sieht etwa so aus:
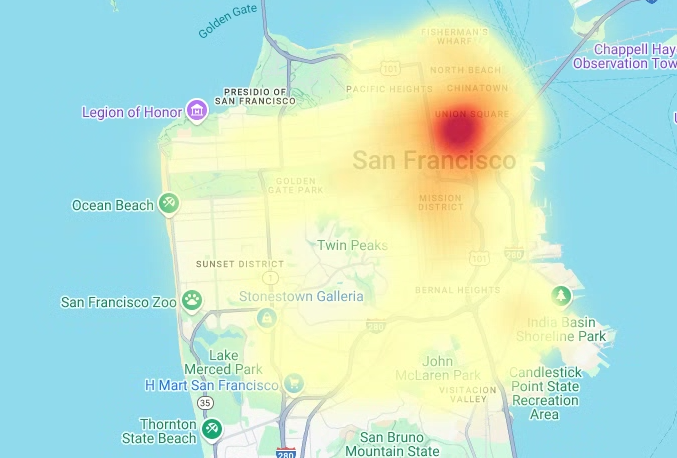
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Klicken Sie in Ihrem Colab auf Secrets.
Klicken Sie am Ende der Zeile
GMP_API_KEYauf Löschen.Optional: Wenn Sie das Notebook löschen möchten, klicken Sie auf Datei > In den Papierkorb verschieben.
- Weitere Informationen zu raumbezogenen Analysen in BigQuery finden Sie unter Einführung in raumbezogene Analysen in BigQuery.
- Eine Einführung in die Visualisierung raumbezogener Daten in BigQuery finden Sie unter Raumbezogene Daten visualisieren.
- Weitere Informationen zu
pydeckund anderendeck.gl-Diagrammtypen finden Sie in derpydeck-Galerie, imdeck.gl-Ebenenkatalog und imdeck.gl-GitHub-Quellcode. - Weitere Informationen zur Arbeit mit raumbezogenen Daten in DataFrames finden Sie auf der GeoPandas-Seite „Erste Schritte“ und im GeoPandas-Nutzerhandbuch.
- Weitere Informationen zur Bearbeitung geometrischer Objekte finden Sie im Shapely-Nutzerhandbuch.
- Informationen zur Verwendung von Google Earth Engine-Daten in BigQuery finden Sie in der Google Earth Engine-Dokumentation unter Nach BigQuery exportieren.
Erforderliche Rollen
Wenn Sie ein neues Projekt erstellen, sind Sie der Projektinhaber und erhalten alle erforderlichen IAM-Berechtigungen, die Sie für dieses Tutorial benötigen.
Wenn Sie ein vorhandenes Projekt verwenden, benötigen Sie die folgende Rolle auf Projektebene, um Abfragejobs auszuführen.
Make sure that you have the following role or roles on the project:
Check for the roles
Grant the roles
Weitere Informationen zu Rollen in BigQuery finden Sie unter Vordefinierte IAM-Rollen.
Colab-Notebook erstellen
In dieser Anleitung wird ein Colab-Notebook erstellt, um Daten aus raumbezogenen Analysen zu visualisieren. Sie können eine vorgefertigte Version des Notebooks in Colab, Colab Enterprise oder BigQuery Studio öffnen, indem Sie oben in der GitHub-Version des Tutorials auf die Links klicken: BigQuery Geospatial Visualization in Colab.
Mit Google Cloud und Google Maps authentifizieren
In dieser Anleitung werden BigQuery-Datasets abgefragt und die Google Maps JavaScript API verwendet. Um diese Ressourcen zu verwenden, authentifizieren Sie die Colab-Laufzeit mit Google Cloud und der Maps API.
Mit Google Cloudauthentifizieren
Optional: Mit Google Maps authentifizieren
Wenn Sie die Google Maps Platform als Kartenanbieter für Basiskarten verwenden, müssen Sie einen Google Maps Platform API-Schlüssel angeben. Das Notebook ruft den Schlüssel aus Ihren Colab Secrets ab.
Dieser Schritt ist nur erforderlich, wenn Sie die Maps API verwenden. Wenn Sie sich nicht bei der Google Maps Platform authentifizieren, wird in pydeck stattdessen die carto-Karte verwendet.
Python-Pakete installieren und Data-Science-Bibliotheken importieren
Zusätzlich zu den colabtools-Python-Modulen (google.colab) werden in dieser Anleitung mehrere andere Python-Pakete und Data-Science-Bibliotheken verwendet.
In diesem Abschnitt installieren Sie die Pakete pydeck und h3. pydeck bietet räumliches Rendering in großem Maßstab in Python, unterstützt von deck.gl.
h3-py bietet das H3-System von Uber zur hexagonalen hierarchischen geospatiale Indexierung in Python.
Anschließend importieren Sie die Bibliotheken h3 und pydeck sowie die folgenden räumlichen Python-Bibliotheken:
Nachdem Sie die Bibliotheken importiert haben, aktivieren Sie interaktive Tabellen für pandas-DataFrames in Colab.
Installieren Sie die Pakete pydeck und h3.
Python-Bibliotheken importieren
Interaktive Tabellen für pandas DataFrames aktivieren
Freigegebene Routine erstellen
In diesem Abschnitt erstellen Sie eine gemeinsame Routine, mit der Ebenen auf einer Basiskarte gerendert werden.
Streudiagramm erstellen
In diesem Abschnitt erstellen Sie ein Streudiagramm aller Bike-Sharing-Stationen im öffentlichen Dataset „San Francisco Ford GoBike Share“, indem Sie Daten aus der Tabelle bigquery-public-data.san_francisco_bikeshare.bikeshare_station_info abrufen. Das Streudiagramm wird mit einer Ebene und einer Streudiagrammebene aus dem deck.gl-Framework erstellt.
Streudiagramme sind nützlich, wenn Sie eine Teilmenge einzelner Punkte überprüfen müssen (auch als Stichprobenprüfung bezeichnet).
Im folgenden Beispiel wird gezeigt, wie Sie eine Ebene und eine Scatterplot-Ebene verwenden, um einzelne Punkte als Kreise darzustellen.
Zum Rendern der Punkte müssen Sie den Längengrad und den Breitengrad als x- und y-Koordinaten aus der Spalte station_geom im Datensatz für Leihfahrräder extrahieren.
Da gdf_sf_bikestations ein geopandas.GeoDataFrame ist, wird direkt über die Spalte station_geom der Geometrie auf die Koordinaten zugegriffen. Sie können den Längengrad mit dem Attribut .x der Spalte und den Breitengrad mit dem Attribut .y abrufen. Anschließend können Sie sie in neuen Spalten für Längen- und Breitengrad speichern.
Polygone visualisieren
Mit raumbezogenen Analysen können Sie raumbezogene Daten in BigQuery mithilfe von GEOGRAPHY-Datentypen und geografischen GoogleSQL-Funktionen analysieren und visualisieren.
Der Datentyp GEOGRAPHY in der raumbezogenen Analyse ist eine Sammlung von Punkten, LineStrings und Polygonen, die als Punktset oder als Teilmenge der Erdoberfläche dargestellt werden. Ein GEOGRAPHY-Typ kann Objekte wie die folgenden enthalten:
Eine Liste aller unterstützten Objekte finden Sie in der Dokumentation zum Typ GEOGRAPHY.
Wenn Sie Geodaten ohne Kenntnis der erwarteten Formen erhalten, können Sie die Daten visualisieren, um die Formen zu ermitteln. Sie können Formen visualisieren, indem Sie die geografischen Daten in das Format GeoJSON konvertieren. Anschließend können Sie die GeoJSON-Daten mit einer GeoJSON-Ebene aus dem deck.gl-Framework visualisieren.
In diesem Abschnitt fragen Sie geografische Daten im Dataset „San Francisco Neighborhoods“ ab und visualisieren dann die Polygone.
Choroplethenkarte erstellen
Wenn Sie Daten mit Polygonen untersuchen, die sich nur schwer in das GeoJSON-Format konvertieren lassen, können Sie stattdessen eine Polygonebene aus dem deck.gl-Framework verwenden. Eine Polygon-Ebene kann Eingabedaten bestimmter Typen verarbeiten, z. B. ein Array von Punkten.
In diesem Abschnitt verwenden Sie eine Polygonebene, um ein Array von Punkten zu rendern und die Ergebnisse zum Rendern einer Choroplethenkarte zu verwenden. Die Choroplethenkarte zeigt die Dichte der Leihfahrradstationen nach Stadtteil. Dazu werden Daten aus dem Dataset „San Francisco Neighborhoods“ mit dem Dataset „San Francisco Ford GoBike Share“ zusammengeführt.
Heatmap erstellen
Choroplethenkarten sind nützlich, wenn Sie aussagekräftige Grenzen haben, die bekannt sind. Wenn Sie Daten ohne bekannte sinnvolle Grenzen haben, können Sie eine Heatmap-Ebene verwenden, um die kontinuierliche Dichte darzustellen.
Im folgenden Beispiel fragen Sie Daten in der Tabelle bigquery-public-data.san_francisco_sfpd_incidents.sfpd_incidents im Dataset „SFPD Reports“ (Berichte der Polizei von San Francisco) ab. Die Daten werden verwendet, um die Verteilung der Vorfälle im Jahr 2015 zu visualisieren.
Für Heatmaps empfiehlt es sich, die Daten vor dem Rendern zu quantisieren und zu aggregieren. In diesem Beispiel werden die Daten mithilfe der räumlichen H3-Indexierung von Carto quantisiert und aggregiert.
Die Heatmap wird mit einer Heatmap-Ebene aus dem deck.gl-Framework erstellt.
In diesem Beispiel wird die Quantisierung mit der Python-Bibliothek h3 durchgeführt, um die Vorfallpunkte in Sechsecke zu aggregieren. Mit der Funktion h3.latlng_to_cell wird die Position des Vorfalls (Breiten- und Längengrad) einem H3-Zellenindex zugeordnet. Eine H3-Auflösung von 9 bietet genügend aggregierte Sechsecke für die Heatmap.
Mit der Funktion h3.cell_to_latlng wird der Mittelpunkt jedes Sechsecks bestimmt.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Projekt löschen
Konsole
gcloud
Google Maps API-Schlüssel und Notebook löschen
Wenn Sie die Google Maps API verwendet haben, löschen Sie nach dem Löschen des Google Cloud -Projekts den Google Maps API-Schlüssel aus Ihren Colab-Secrets und löschen Sie dann optional das Notebook.