本文提供 BigQuery 差異隱私權的一般資訊。如需語法,請參閱差異化隱私權條款。 如要查看可搭配這項語法使用的函式清單,請參閱差異隱私匯總函式。
什麼是差異化隱私?
差異化隱私是資料運算的標準,可限制輸出內容中的個人資訊量。這項技術經常用於分享資料,以及推論使用者群組,同時避免個人相關資訊外洩。
差異化隱私的用途:
- 存在重新識別化風險。
- 量化風險與分析實用性之間的取捨。
為了進一步瞭解差異化隱私,我們來看一個簡單的例子。
這張長條圖顯示某個晚上小型餐廳的忙碌程度。許多顧客會在晚上 7 點光臨,而餐廳在凌晨 1 點完全沒有顧客:
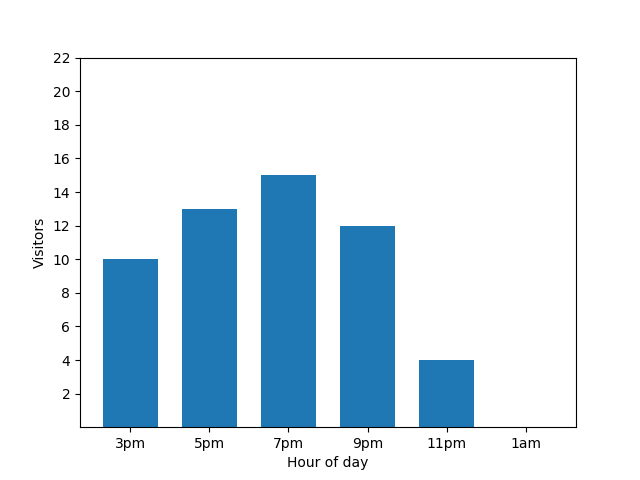
這張圖表看起來很實用,但有個問題。有新訪客抵達時,長條圖會立即顯示這項事實。從下圖可清楚看出有新訪客,且該訪客大約在凌晨 1 點抵達:
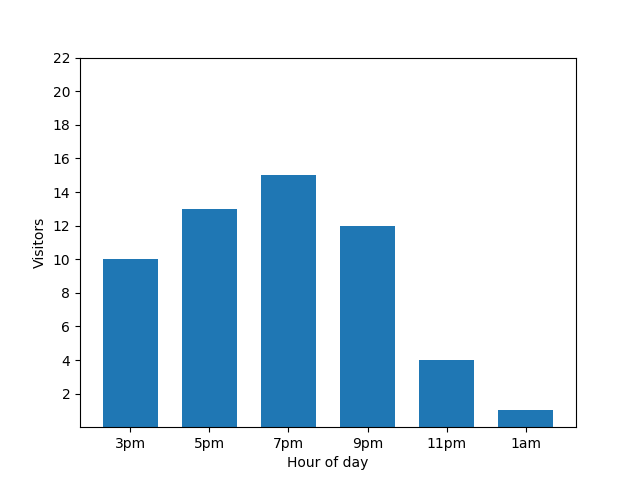
從隱私權角度來看,顯示這項詳細資料並不理想,因為匿名統計資料不應揭露個人貢獻。將這兩張圖表並列,會更加明顯:橘色長條圖多了一位在凌晨 1 點左右抵達的房客:
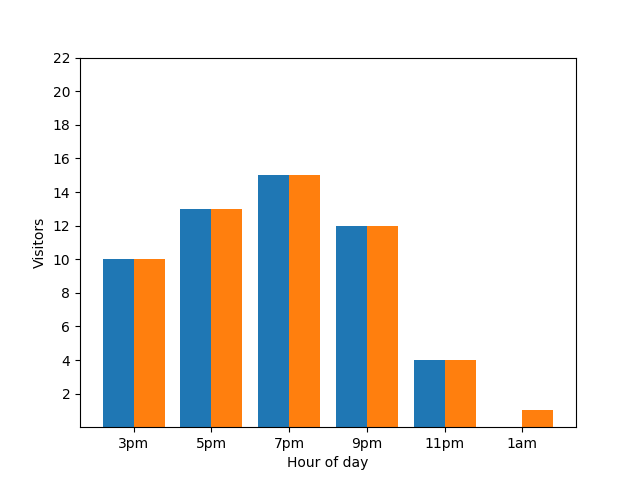
這同樣不是好現象。如要避免這類隱私權問題,可以使用差異隱私權,在長條圖中加入隨機雜訊。在下方的比較圖表中,結果會經過匿名處理,不再顯示個別貢獻。

查詢的差異化隱私權運作方式
差異化隱私的目標是降低揭露風險,也就是防止他人取得資料集中實體的資訊。差異化隱私權可兼顧隱私權保護和統計分析實用性。隱私權越高,統計分析實用性就越低,反之亦然。
您可以使用 BigQuery 的 GoogleSQL,透過差異隱私權匯總轉換查詢結果。執行查詢時,系統會進行下列操作:
- 如果使用
GROUP BY子句指定群組,系統會計算每個群組的實體匯總。根據max_groups_contributed差異化隱私權參數,限制每個實體可加入的群組數量。 - 取值範圍限制:將每個實體的匯總貢獻度限制在取值範圍內。如果未指定箝制界限,系統會以差異隱私權方式隱含計算。
- 匯總每個群組的實體匯總貢獻值,並限制取值範圍。
- 在每個群組的最終匯總值中加入雜訊。隨機雜訊的規模是所有限制取值範圍和隱私權參數的函式。
- 計算每個群組套用雜訊的實體數量,刪除實體數量較少的群組。有雜訊的實體計數有助於排除非決定性群組集。
最終結果是一個資料集,其中每個群組的匯總結果都套用雜訊,且刪除人數較少的群體。
如要進一步瞭解差異化隱私權及其用途,請參閱下列文章:
產生有效的差異隱私查詢
差異隱私權查詢必須符合下列規則,才算有效:
定義隱私權單位欄
隱私權單元是資料集中受保護的實體,使用差異化隱私權。實體可以是個人、公司、地點或您選擇的任何資料欄。
差異化隱私查詢必須包含一個且僅有一個隱私單位欄。隱私權單元資料欄是隱私權單元的專屬 ID,可存在於多個群組中。由於系統支援多個群組,隱私權單位欄的資料類型必須是可分組的類型。
您可以在差異隱私權子句的 OPTIONS 子句中,使用唯一 ID privacy_unit_column 定義隱私單位欄。
在下列範例中,隱私權單位欄會新增至差異隱私權子句。id 代表來自名為 students 的資料表資料欄。
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM students;
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=members.id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM (SELECT * FROM students) AS members;
從差異隱私權查詢中移除雜訊
如需「查詢語法」參考資料,請參閱「移除噪音」。
為差異隱私查詢加入雜訊
如需「查詢語法」參考資料,請參閱「新增雜訊」。
限制隱私權單元 ID 可存在的群組
在「查詢語法」參考資料中,請參閱「限制隱私權單元 ID 可存在的群組」。
限制
本節說明差異隱私權的限制。
差異化隱私對成效的影響
差異隱私權查詢的執行速度比標準查詢慢,因為系統會執行實體匯總,並套用 max_groups_contributed 限制。限制貢獻範圍有助於提升差異隱私權查詢的效能。
下列查詢的效能設定檔並不相似:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
造成成效差異的原因是,差異化隱私查詢會執行額外的細微粒度分組層級,因為也必須執行實體層級的匯總。
下列查詢的效能設定檔應類似,但差異化隱私查詢會稍微慢一點:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, id, COUNT(column_b)
FROM table_a
GROUP BY column_a, id;
差異化隱私查詢的執行速度較慢,因為隱私權單元資料欄有大量不重複值。
小型資料集的隱含邊界限制
使用大型資料集計算隱含邊界時,效果最佳。 如果資料集包含的隱私權單位數量較少,隱含界限可能會失敗,且不會傳回任何結果。此外,如果資料集隱私權單位數量較少,隱含的界限可能會限制大部分非離群值,導致匯總資料低報,且結果受限縮影響的程度大於新增雜訊。如果資料集的隱私權單位數量偏低或分割稀疏,應使用明確而非隱含的箝制。
隱私權漏洞
當分析師惡意行事時,任何差異化隱私演算法 (包括這個演算法) 都會面臨私密資料外洩的風險,尤其是在計算總和等基本統計資料時,更是如此,因為這類演算法有算術限制。
隱私權保障的限制
雖然 BigQuery 差異隱私權會套用差異隱私權演算法,但不會保證產生的資料集具有隱私權屬性。
執行階段錯誤
如果分析師心懷不軌,且有權編寫查詢或控管輸入資料,可能會在私人資料上觸發執行階段錯誤。
浮點噪音
使用差分隱私權前,請先考慮與四捨五入、重複四捨五入和重新排序攻擊相關的安全性漏洞。如果攻擊者可以控制資料集的部分內容或內容順序,這些安全漏洞就特別令人擔憂。
浮點資料類型差異化隱私雜訊的加入作業,會受到「Widespread Underestimation of Sensitivity in Differentially Private Libraries and How to Fix It」一文所述的安全性弱點影響。整數資料類型加入的雜訊不會受到論文中描述的安全性漏洞影響。
時序攻擊風險
惡意分析師可能會執行足夠複雜的查詢,根據查詢的執行時間推斷輸入資料。
分類錯誤
建立差異隱私權查詢時,系統會假設您的資料結構明確且易於理解。如果您對錯誤的 ID 套用差異化隱私權,例如代表交易 ID 而非個人 ID 的 ID,可能會洩漏私密資料。
如需瞭解資料的相關協助,建議使用下列服務和工具:
定價
使用差異隱私權功能不會產生額外費用,但分析作業仍適用標準 BigQuery 定價。