Generative AI overview
This document describes the generative artificial intelligence (AI) features that BigQuery ML supports. These features let you perform AI tasks in BigQuery ML by using pre-trained Vertex AI models and built-in BigQuery ML models.
Supported tasks include the following:
- Generate text
- Generate structured data
- Generate values of a specific type by row
- Generate embeddings
- Forecast time series
You access a Vertex AI model to perform one of these functions by creating a remote model in BigQuery ML that represents the Vertex AI model's endpoint. Once you have created a remote model over the Vertex AI model that you want to use, you access that model's capabilities by running a BigQuery ML function against the remote model.
This approach lets you use the capabilities of these Vertex AI models in SQL queries to analyze BigQuery data.
Workflow
You can use remote models over Vertex AI models and remote models over Cloud AI services together with BigQuery ML functions in order to accomplish complex data analysis and generative AI tasks.
The following diagram shows some typical workflows where you might use these capabilities together:
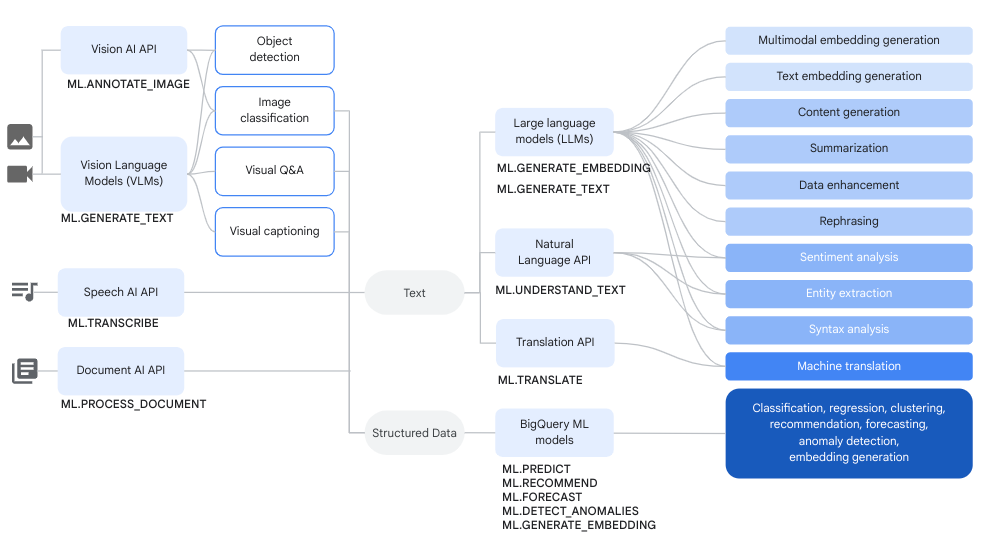
Generate text
Text generation is a form of generative AI in which text is generated based on either a prompt or on analysis of data. You can perform text generation using both text and multimodal data.
Some common use cases for text generation are as follows:
- Generating creative content.
- Generating code.
- Generating chat or email responses.
- Brainstorming, such as suggesting avenues for future products or services.
- Content personalization, such as product suggestions.
- Classifying data by applying one or more labels to the content to sort it into categories.
- Identifying the key sentiments expressed in the content.
- Summarizing the key ideas or impressions conveyed by the content.
- Identifying one or more prominent entities in text or visual data.
- Translating the content of text or audio data to a different language.
- Generating text that matches the verbal content in audio data.
- Captioning or performing Q&A on visual data.
Data enrichment is a common next step after text generation, in which you enrich
insights from the initial analysis by combining them with additional data. For
example, you might analyze images of home furnishings to generate text for a
design_type column, so that the furnishings SKU has an associated
description, such as mid-century modern or farmhouse.
Supported models
To perform generative AI tasks, you can use remote models in BigQuery ML to reference to models deployed to or hosted in Vertex AI. You can create the following types of remote models:
- Remote models over any of the generally available or preview Gemini models.
Remote models over the following partner models:
Using text generation models
After you create a remote model, you can use the
ML.GENERATE_TEXT function
to interact with that model:
For remote models based on Gemini models, you can do the following:
Use the
ML.GENERATE_TEXTfunction to generate text from a prompt that you specify in a query or pull from a column in a standard table. When you specify the prompt in a query, you can reference the following types of table columns in the prompt:STRINGcolumns to provide text data.STRUCTcolumns that use theObjectRefformat to provide unstructured data. You must use theOBJ.GET_ACCESS_URLfunction within the prompt to convert theObjectRefvalues toObjectRefRuntimevalues.
Use the
ML.GENERATE_TEXTfunction to analyze text, image, audio, video, or PDF content from an object table with a prompt that you provide as a function argument.
For all other types of remote models, you can use the
ML.GENERATE_TEXTfunction with a prompt that you provide in a query or from a column in a standard table.
Use the following topics to try text generation in BigQuery ML:
- Generate text by using a Gemini model and the
ML.GENERATE_TEXTfunction. - Generate text by using a Gemma model and the
ML.GENERATE_TEXTfunction. - Analyze images with a Gemini model.
- Generate text by using the
ML.GENERATE_TEXTfunction with your data. - Tune a model using your data.
Grounding and safety attributes
You can use
grounding
and
safety attributes
when you use Gemini models with the ML.GENERATE_TEXT function,
provided that you are using a standard table for input. Grounding lets the
Gemini model use additional information from the internet to
generate more specific and factual responses. Safety attributes let the
Gemini model filter the responses it returns based on the
attributes you specify.
Supervised tuning
When you create a remote model that references any of the following models, you can optionally choose to configure supervised tuning at the same time:
gemini-2.5-progemini-2.5-flash-litegemini-2.0-flash-001gemini-2.0-flash-lite-001
All inference occurs in Vertex AI. The results are stored in BigQuery.
Vertex AI Provisioned Throughput
For
supported Gemini models,
you can use
Vertex AI Provisioned Throughput
with the ML.GENERATE_TEXT function to provide consistent high throughput for
requests. For more information, see
Use Vertex AI Provisioned Throughput.
Generate structured data
Structured data generation is very similar to text generation, except you can additionally format the response from the model by specifying a SQL schema.
To generate structured data, create a remote model over any of the
generally available
or
preview
Gemini models. You can then use the
AI.GENERATE_TABLE
function to interact with that model. To try creating structured data, see
Generate structured data by using the AI.GENERATE_TABLE function.
You can specify
safety attributes
when you use Gemini models with the AI.GENERATE_TABLE function
in order to filter the model's responses.
Generate values of a specific type by row
You can use scalar generative AI functions with Gemini models to
analyze data in BigQuery standard tables. Data includes both
text data and unstructured data from
columns that contain ObjectRef values.
For each row in the table, these functions generate output containing a
specific type.
The following AI functions are available:
AI.GENERATE, which generates aSTRINGvalueAI.GENERATE_BOOLAI.GENERATE_DOUBLEAI.GENERATE_INT
When you use the AI.GENERATE function with
supported Gemini models,
you can use
Vertex AI Provisioned Throughput
to provide consistent high throughput for requests. For more information, see
Use Vertex AI Provisioned Throughput.
Generate embeddings
An embedding is a high-dimensional numerical vector that represents a given entity, like a piece of text or an audio file. Generating embeddings lets you capture the semantics of your data in a way that makes it easier to reason about and compare the data.
Some common use cases for embedding generation are as follows:
- Using retrieval-augmented generation (RAG) to augment model responses to user queries by referencing additional data from a trusted source. RAG provides better factual accuracy and response consistency, and also provides access to data that is newer than the model's training data.
- Performing multimodal search. For example, using text input to search images.
- Performing semantic search to find similar items for recommendations, substitution, and record deduplication.
- Creating embeddings to use with a k-means model for clustering.
Supported models
The following models are supported:
To create text embeddings, you can use the following Vertex AI models:
gemini-embedding-001(Preview)text-embeddingtext-multilingual-embedding- Supported open models (Preview)
To create multimodal embeddings, which can embed text, images, and videos into the same semantic space, you can use the Vertex AI
multimodalembeddingmodel.To create embeddings for structured independent and identically distributed random variables (IID) data, you can use a BigQuery ML Principal component analysis (PCA) model or an Autoencoder model.
To create embeddings for user or item data, you can use a BigQuery ML Matrix factorization model.
For a smaller, lightweight text embedding, try using a pretrained TensorFlow model, such as NNLM, SWIVEL, or BERT.
Using embedding generation models
After you create the model, you can use the
ML.GENERATE_EMBEDDING function
to interact with it. For all types of supported models, ML.GENERATE_EMBEDDING
works with structured data in
standard tables. For multimodal
embedding models, ML.GENERATE_EMBEDDING also works with visual content
from either standard table
columns that contain ObjectRef values,
or from object tables.
For remote models, all inference occurs in Vertex AI. For other model types, all inference occurs in BigQuery. The results are stored in BigQuery.
Use the following topics to try text generation in BigQuery ML:
- Generate text embeddings by using the
ML.GENERATE_EMBEDDINGfunction - Generate image embeddings by using the
ML.GENERATE_EMBEDDINGfunction - Generate video embeddings by using the
ML.GENERATE_EMBEDDINGfunction - Generate and search multimodal embeddings
- Perform semantic search and retrieval-augmented generation
Forecasting
Forecasting is a technique that lets you
analyze historical time series data in order to make an informed prediction
about future trends. You can use BigQuery ML's built-in
TimesFM time series model
(Preview) to perform forecasting without
having to create your own model. The built-in TimesFM model works with the
AI.FORECAST function
to generate forecasts based on your data.
Locations
Supported locations for text generation and embedding models vary based on the model type and version that you use. For more information, see Locations. Unlike other generative AI models, location support doesn't apply to the built-in TimesFM time series model. The TimesFM model is available in all BigQuery supported regions.
Pricing
You are charged for the compute resources that you use to run queries against models. Remote models make calls to Vertex AI models, so queries against remote models also incur charges from Vertex AI.
For more information, see BigQuery ML pricing.
What's next
- For an introduction to AI and ML in BigQuery, see Introduction to AI and ML in BigQuery.
- For more information about performing inference over machine learning models, see Model inference overview.
- For more information about supported SQL statements and functions for generative AI models, see End-to-end user journeys for generative AI models.