从 Snowflake 迁移到 BigQuery:概览
本文档将介绍如何将数据从 Snowflake 迁移到 BigQuery。
如需了解从其他数据仓库迁移到 BigQuery 的一般框架,请参阅概览:将数据仓库迁移到 BigQuery。
从 Snowflake 迁移到 BigQuery 的概览
对于 Snowflake 迁移,我们建议设置一种对现有操作影响最小的迁移架构。以下示例展示了一种架构,您可以在其中重用现有工具和流程,同时将其他工作负载分流到 BigQuery。
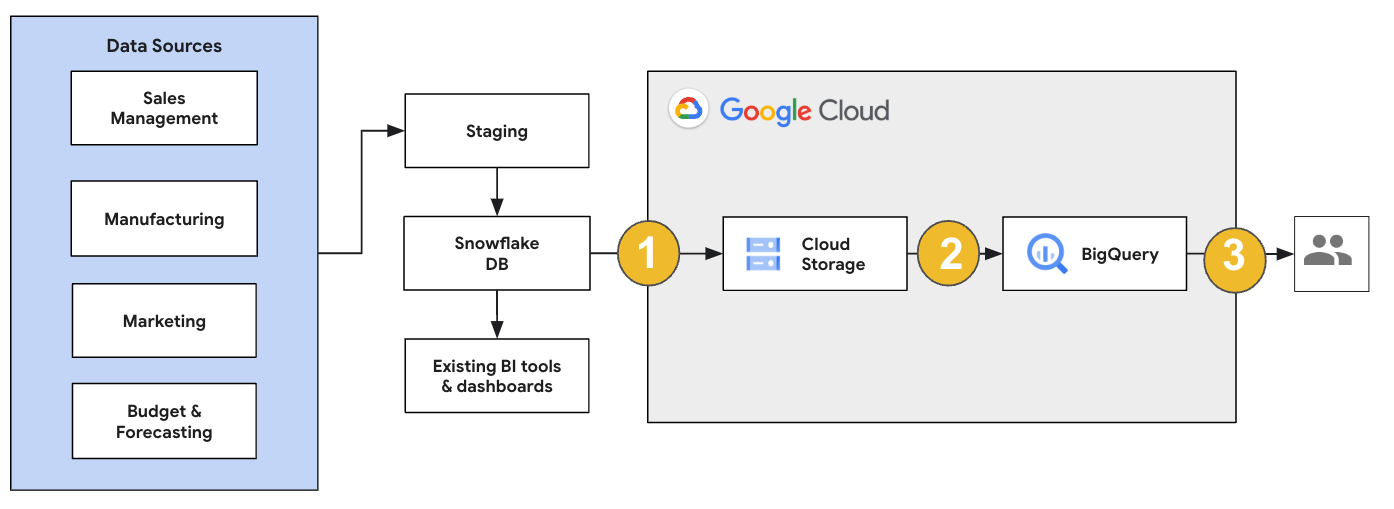
您还可以根据旧版本验证报告和信息中心。如需了解详情,请参阅将数据仓库迁移到 BigQuery:验证和确认。
迁移单个工作负载
在规划 Snowflake 迁移时,我们建议您按以下顺序单独迁移以下工作负载:
迁移架构
首先,将 Snowflake 环境中的必要架构复制到 BigQuery 中。我们建议您使用 BigQuery Migration Service 迁移架构。BigQuery Migration Service 支持各种数据模型设计模式,例如星型架构或雪花型架构,因此您无需更新上游数据流水线以适应新架构。BigQuery Migration Service 还提供自动架构迁移功能,包括架构提取和转换功能,以简化迁移流程。
迁移 SQL 查询
为了迁移 SQL 查询,BigQuery Migration Service 提供了各种 SQL 转换功能,可自动将 Snowflake SQL 查询转换为 GoogleSQL SQL,例如用于批量转换查询的批量 SQL 转换器、用于转换单个查询的交互式 SQL 转换器和 SQL 转换 API。这些翻译服务还包含 Gemini 增强型功能,可进一步简化 SQL 查询迁移流程。
在翻译 SQL 查询时,请仔细检查翻译后的查询,以验证数据类型和表结构是否得到正确处理。为此,我们建议创建各种包含不同场景和数据的测试用例。然后,在 BigQuery 上运行这些测试用例,将结果与原始 Snowflake 结果进行比较。如果存在任何差异,请分析并修正转换后的查询。
迁移数据
您可以通过多种方式设置数据迁移流水线,将数据转移到 BigQuery。一般来说,这些流水线遵循相同的模式:
从来源提取数据:将从来源提取的文件复制到本地环境中的暂存存储空间。如需了解详情,请参阅将数据仓库迁移到 BigQuery:提取源数据。
将数据转移到暂存 Cloud Storage 存储桶:从来源提取完数据后,将数据转移到 Cloud Storage 中的临时存储桶。根据要转移的数据量和可用的网络带宽,您有几个选项。
请务必验证 BigQuery 数据集的位置和外部数据源,或 Cloud Storage 存储桶是否位于相同区域。
将数据从 Cloud Storage 存储桶加载到 BigQuery:您的数据现在位于 Cloud Storage 存储桶中。将数据上传到 BigQuery 有多个选项可用。这些选项取决于需要的数据转换程度。或者,您可以按照 ELT 方法在 BigQuery 中转换数据。
当您从 JSON 文件、Avro 文件或 CSV 文件批量导入数据时,BigQuery 会自动检测架构,您无需预定义架构。如需详细了解 EDW 工作负载的架构迁移过程,请参阅架构和数据迁移过程。
如需查看支持 Snowflake 数据迁移的工具列表,请参阅迁移工具。
如需查看设置 Snowflake 数据迁移流水线的端到端示例,请参阅 Snowflake 迁移流水线示例。
优化架构和查询
架构迁移后,您可以测试性能并根据结果进行优化。例如,您可以引入分区来提高数据的管理和查询效率。通过按注入时间、时间戳或整数范围进行分区,您可以改善查询性能和费用控制。如需了解详情,请参阅分区表简介。
聚簇表是另一项架构优化。您可以对表进行聚簇,以根据表架构中的内容整理表数据,从而提高使用过滤条件子句的查询或汇总数据的查询的性能。如需了解详情,请参阅聚簇表简介。
支持的数据类型、属性和文件格式
Snowflake 和 BigQuery 支持的数据类型大部分相同,但有时使用不同的名称。如需查看 Snowflake 和 BigQuery 中支持的数据类型的完整列表,请参阅数据类型。您还可以使用 SQL 转换工具(例如交互式 SQL 转换器、SQL 转换 API 或批量 SQL 转换器)将不同的 SQL 方言转换为 GoogleSQL。
如需详细了解 BigQuery 中支持的数据类型,请参阅 GoogleSQL 数据类型。
Snowflake 可以导出以下文件格式的数据。您可以将以下格式直接加载到 BigQuery 中:
- 从 Cloud Storage 加载 CSV 数据。
- 从 Cloud Storage 加载 Parquet 数据。
- 从 Cloud Storage 加载 JSON 数据。
- 查询 Apache Iceberg 中的数据。
迁移工具
以下列表介绍了可用于将数据从 Snowflake 迁移到 BigQuery 的工具。如需查看如何在 Snowflake 迁移流水线中结合使用这些工具的示例,请参阅 Snowflake 迁移流水线示例。
COPY INTO <location>命令:在 Snowflake 中使用此命令,将数据从 Snowflake 表直接提取到指定的 Cloud Storage 存储桶中。如需查看端到端示例,请参阅 GitHub 上的 Snowflake to BigQuery (snowflake2bq)。- Apache Sqoop:如需将数据从 Snowflake 提取到 HDFS 或 Cloud Storage 中,请使用 Sqoop 和 Snowflake 的 JDBC 驱动程序提交 Hadoop 作业。Sqoop 在 Dataproc 环境中运行。
- Snowflake JDBC:将此驱动程序与大多数支持 JDBC 的客户端工具或应用搭配使用。
您可以使用以下通用工具将数据从 Snowflake 迁移到 BigQuery:
- 适用于 Snowflake 的 BigQuery Data Transfer Service 连接器 预览版:将 Cloud Storage 数据自动批量转移到 BigQuery。
- The Google Cloud CLI:使用此命令行工具将下载的 Snowflake 文件复制到 Cloud Storage 中。
- bq 命令行工具:使用此命令行工具与 BigQuery 进行交互。常见用例包括创建 BigQuery 表架构、将 Cloud Storage 数据加载到表中以及运行查询。
- Cloud Storage 客户端库:通过使用 Cloud Storage 客户端库的自定义工具将下载的 Snowflake 文件复制到 Cloud Storage。
- BigQuery 客户端库:使用基于 BigQuery 客户端库构建的自定义工具与 BigQuery 进行交互。
- BigQuery 查询调度器:使用此内置 BigQuery 功能安排周期性 SQL 查询。
- Cloud Composer:使用此全代管式 Apache Airflow 环境编排 BigQuery 加载作业和转换。
如需详细了解如何将数据加载到 BigQuery 中,请参阅将数据加载到 BigQuery 中。
Snowflake 迁移流水线示例
以下部分展示了如何使用三种不同的流程将数据从 Snowflake 迁移到 BigQuery:ELT、ETL 以及合作伙伴工具。
提取、加载和转换
您可以通过以下两种方法设置提取、加载和转换 (ELT) 流程:
- 使用流水线从 Snowflake 提取数据并将数据加载到 BigQuery
- 使用其他 Google Cloud 产品从 Snowflake 中提取数据。
使用流水线从 Snowflake 提取数据
如需从 Snowflake 提取数据并直接加载到 Cloud Storage,请使用 snowflake2bq 工具。
然后,您可以使用以下任一工具将数据从 Cloud Storage 加载到 BigQuery 中:
- 适用于 Cloud Storage 的 BigQuery Data Transfer Service 连接器
- 使用 bq 命令行工具的
LOAD命令 - BigQuery API 客户端库
从 Snowflake 提取数据的其他工具
您还可以使用以下工具从 Snowflake 提取数据:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Apache Spark BigQuery 连接器
- 适用于 Apache Spark 的 Snowflake 连接器
- Hadoop BigQuery 连接器
- Snowflake 和 Sqoop 的 JDBC 驱动程序,用于将数据从 Snowflake 提取到 Cloud Storage 中:
用于将数据加载到 BigQuery 的其他工具
您还可以使用以下工具将数据加载到 BigQuery 中:
- Dataflow
- Cloud Data Fusion
- Dataproc
- Dataprep by Trifacta
提取、转换和加载
如果您想在将数据加载到 BigQuery 之前转换数据,请考虑使用以下工具:
- Dataflow
- 克隆 JDBC to BigQuery 模板代码,并修改模板以添加 Apache Beam 转换。
- Cloud Data Fusion
- 创建可重复使用的流水线,并使用 CDAP 插件转换数据。
- Dataproc
- 使用 Spark SQL 或任何受支持的 Spark 语言(例如 Scala、Java、Python 或 R)的自定义代码来转换数据。
用于迁移的合作伙伴工具
有许多供应商专门提供 EDW 迁移空间。如需查看主要合作伙伴及其提供的解决方案的列表,请参阅 BigQuery 合作伙伴。
Snowflake 导出教程
以下教程展示了使用 COPY INTO <location> Snowflake 命令将数据从 Snowflake 导出到 BigQuery 的示例。如需查看包含代码示例的详细分步过程,请参阅 Google Cloud 专业服务 Snowflake to BigQuery 工具
准备导出
您可以按照以下步骤将 Snowflake 数据提取到 Cloud Storage 或 Amazon Simple Storage Service (Amazon S3) 存储桶中,从而为导出做好准备:
Cloud Storage
本教程会准备 PARQUET 格式的文件。
使用 Snowflake SQL 语句创建一个命名的文件格式规范。
create or replace file format NAMED_FILE_FORMAT type = 'PARQUET'
将
NAMED_FILE_FORMAT替换为文件格式的名称。例如my_parquet_unload_format。使用
CREATE STORAGE INTEGRATION命令创建一个集成。create storage integration INTEGRATION_NAME type = external_stage storage_provider = gcs enabled = true storage_allowed_locations = ('BUCKET_NAME')
替换以下内容:
INTEGRATION_NAME:存储集成名称。例如gcs_intBUCKET_NAME:Cloud Storage 存储桶的路径。例如gcs://mybucket/extract/
使用
DESCRIBE INTEGRATION命令检索 Snowflake 的 Cloud Storage 服务账号。desc storage integration INTEGRATION_NAME;
输出类似于以下内容:
+-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+ | property | property_type | property_value | property_default | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | gcs://mybucket1/path1/,gcs://mybucket2/path2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | gcs://mybucket1/path1/sensitivedata/,gcs://mybucket2/path2/sensitivedata/ | [] | | STORAGE_GCP_SERVICE_ACCOUNT | String | service-account-id@iam.gserviceaccount.com | | +-----------------------------+---------------+-----------------------------------------------------------------------------+------------------+
向列为
STORAGE_GCP_SERVICE_ACCOUNT的服务账号授予对存储集成命令中指定的存储桶的读写权限。在此示例中,向service-account-id@服务账号授予对<var>UNLOAD_BUCKET</var>存储桶的读写访问权限。创建一个外部 Cloud Storage 暂存区,该暂存区引用您之前创建的集成。
create or replace stage STAGE_NAME url='UNLOAD_BUCKET' storage_integration = INTEGRATION_NAME file_format = NAMED_FILE_FORMAT;
替换以下内容:
STAGE_NAME:Cloud Storage 暂存对象的名称。 例如my_ext_unload_stage
Amazon S3
以下示例展示了如何将数据从 Snowflake 表移至 Amazon S3 存储桶:
在 Snowflake 中配置存储集成对象,以允许 Snowflake 写入外部 Cloud Storage 暂存区中引用的 Amazon S3 存储桶。
此步骤涉及配置对 Amazon S3 存储桶的访问权限、创建 Amazon Web Services (AWS) IAM 角色以及使用
CREATE STORAGE INTEGRATION命令在 Snowflake 中创建存储集成:create storage integration INTEGRATION_NAME type = external_stage storage_provider = s3 enabled = true storage_aws_role_arn = 'arn:aws:iam::001234567890:role/myrole' storage_allowed_locations = ('BUCKET_NAME')
替换以下内容:
INTEGRATION_NAME:存储集成名称。例如s3_intBUCKET_NAME:要将文件加载到的 Amazon S3 存储桶的路径。例如s3://unload/files/
使用
DESCRIBE INTEGRATION命令检索 AWS IAM 用户。desc integration INTEGRATION_NAME;
输出类似于以下内容:
+---------------------------+---------------+================================================================================+------------------+ | property | property_type | property_value | property_default | +---------------------------+---------------+================================================================================+------------------| | ENABLED | Boolean | true | false | | STORAGE_ALLOWED_LOCATIONS | List | s3://mybucket1/mypath1/,s3://mybucket2/mypath2/ | [] | | STORAGE_BLOCKED_LOCATIONS | List | s3://mybucket1/mypath1/sensitivedata/,s3://mybucket2/mypath2/sensitivedata/ | [] | | STORAGE_AWS_IAM_USER_ARN | String | arn:aws:iam::123456789001:user/abc1-b-self1234 | | | STORAGE_AWS_ROLE_ARN | String | arn:aws:iam::001234567890:role/myrole | | | STORAGE_AWS_EXTERNAL_ID | String | MYACCOUNT_SFCRole=
| | +---------------------------+---------------+================================================================================+------------------+ 创建对架构具有
CREATE STAGE权限且对存储集成具有USAGE权限的角色:CREATE role ROLE_NAME; GRANT CREATE STAGE ON SCHEMA public TO ROLE ROLE_NAME; GRANT USAGE ON INTEGRATION s3_int TO ROLE ROLE_NAME;
将
ROLE_NAME替换为角色的名称。例如myrole。向 AWS IAM 用户授予 Amazon S3 存储桶的访问权限,并使用
CREATE STAGE命令创建外部暂存区:USE SCHEMA mydb.public; create or replace stage STAGE_NAME url='BUCKET_NAME' storage_integration = INTEGRATION_NAMEt file_format = NAMED_FILE_FORMAT;
替换以下内容:
STAGE_NAME:Cloud Storage 暂存对象的名称。 例如my_ext_unload_stage
导出 Snowflake 数据
准备好数据后,您可以将数据迁移到 Google Cloud。使用 COPY INTO 命令并指定外部暂存区对象 STAGE_NAME,以将数据从 Snowflake 数据库表复制到 Cloud Storage 或 Amazon S3 存储桶。
copy into @STAGE_NAME/d1 from TABLE_NAME;
将 TABLE_NAME 替换为您的 Snowflake 数据库表的名称。
执行此命令后,表数据会复制到与 Cloud Storage 或 Amazon S3 存储桶相关联的临时对象。文件包含 d1 前缀。
其他导出方法
如需使用 Azure Blob Storage 导出数据,请按照卸载到 Microsoft Azure 中详细介绍的步骤操作。 然后,使用 Storage Transfer Service 将导出的文件转移到 Cloud Storage。
价格
在规划 Snowflake 迁移时,请考虑在 BigQuery 中传输数据、存储数据和使用服务的费用。要了解详情,请参阅价格。
将数据移出 Snowflake 或 AWS 可能会产生出站费用。跨区域传输数据或跨不同云服务提供商传输数据时,也可能会产生额外费用。
后续步骤
- 迁移后的性能和优化。