Extensions d'analyseur
Ce document explique comment créer des extensions d'analyseur pour extraire des champs à partir de données de journaux brutes et les mapper sur des champs UDM (Unified Data Model) de destination dans la plate-forme Google Security Operations.
Le document décrit le processus de création d'une extension d'analyseur :
- Créer des extensions d'analyseur
- Conditions préalables et limites.
- Identifiez les champs sources dans les données brutes du journal.
- Sélectionnez les champs UDM de destination appropriés.
Choisissez l'approche de définition d'extension d'analyseur appropriée :
La définition d'une extension d'analyseur inclut la conception de la logique d'analyse pour filtrer les données de journaux brutes, transformer les données et les mapper aux champs UDM de destination. Google SecOps propose deux approches pour créer des extensions d'analyseur :
- Créez des extensions d'analyseur à l'aide de l'approche sans code (Mappage des champs de données).
- Créez des extensions d'analyseur à l'aide de l'approche extrait de code.
Exemples illustratifs de création d'extensions d'analyseur pour différents formats et scénarios de journaux. Par exemple, des exemples sans code utilisant JSON et des extraits de code pour une logique complexe ou des formats non JSON (CSV, XML, Syslog).
Créer des extensions d'analyseur
Les extensions d'analyseur offrent un moyen flexible d'étendre les capacités des analyseurs par défaut (et personnalisés) existants. Les extensions d'analyseur offrent un moyen flexible d'étendre les capacités des analyseurs par défaut (ou personnalisés) existants sans les remplacer. Les extensions vous permettent de personnaliser le pipeline de l'analyseur en ajoutant une nouvelle logique d'analyse, en extrayant et en transformant des champs, et en mettant à jour ou en supprimant les mappages de champs UDM.
Une extension d'analyseur est différente d'un analyseur personnalisé. Vous pouvez créer un analyseur personnalisé pour un type de journal qui ne dispose pas d'un analyseur par défaut ou désactiver les mises à jour de l'analyseur.
Processus d'extraction et de normalisation du parseur
Google SecOps reçoit les données de journaux d'origine sous forme de journaux bruts. Les analyseurs par défaut (et personnalisés) extraient et normalisent les champs de journaux principaux en champs UDM structurés dans les enregistrements UDM. Cela ne représente qu'un sous-ensemble des données brutes du journal d'origine. Vous pouvez définir des extensions d'analyseur pour extraire les valeurs de journaux non gérées par les analyseurs par défaut. Une fois activées, les extensions d'analyseur font partie du processus d'extraction et de normalisation des données Google SecOps.
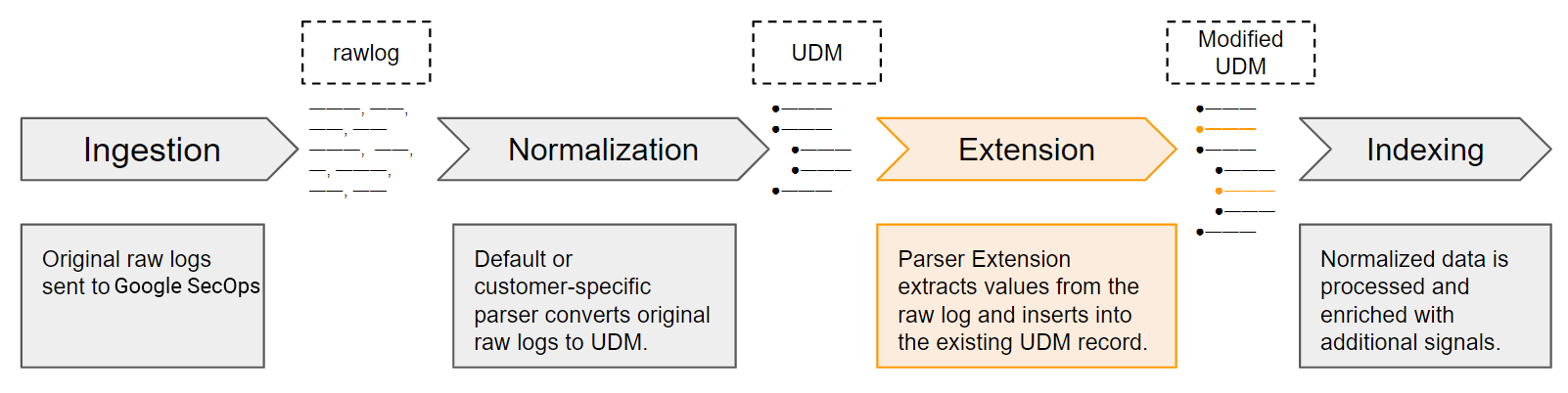
Définir de nouvelles extensions d'analyseur
Les analyseurs par défaut contiennent des ensembles prédéfinis d'instructions de mappage qui spécifient comment extraire, transformer et normaliser les valeurs de sécurité de base. Vous pouvez créer des extensions d'analyseur en définissant des instructions de mappage à l'aide de l'approche sans code (Mapper les champs de données) ou de l'approche par extrait de code :
Approche sans code
L'approche sans code est la plus adaptée aux extractions simples à partir de journaux bruts au format JSON, XML ou CSV natif. Il vous permet de spécifier les champs sources des journaux bruts et de mapper les champs UDM de destination correspondants.
Par exemple, pour extraire des données de journaux JSON avec un maximum de 10 champs, à l'aide de comparaisons d'égalité simples.
Approche par extrait de code
L'approche par extrait de code vous permet de définir des instructions pour extraire et transformer les valeurs du journal brut, puis de les attribuer à des champs UDM. Les extraits de code utilisent la même syntaxe de type Logstash que l'analyseur par défaut (ou personnalisé).
Cette approche s'applique à tous les formats de journaux compatibles. Il est idéal dans les scénarios suivants :
- Extractions de données complexes ou logique complexe.
- Données non structurées nécessitant des analyseurs basés sur Grok.
- Formats non JSON tels que CSV et XML.
Les extraits de code utilisent des fonctions pour extraire des données spécifiques des données de journaux brutes. Par exemple, Grok, JSON, KV et XML.
Dans la plupart des cas, il est préférable d'utiliser l'approche de mappage des données qui a été utilisée dans l'analyseur par défaut (ou personnalisé).
Fusionner les valeurs nouvellement extraites dans les champs UDM
Une fois activées, les extensions d'analyseur fusionnent les valeurs nouvellement extraites dans les champs UDM désignés de l'enregistrement UDM correspondant, selon des principes de fusion prédéfinis. Exemple :
Écraser les valeurs existantes : les valeurs extraites écrasent les valeurs existantes dans les champs UDM de destination.
La seule exception concerne les champs répétés, pour lesquels vous pouvez configurer l'extension de l'analyseur afin d'ajouter de nouvelles valeurs lors de l'écriture de données dans un champ répété de l'enregistrement UDM.
L'extension d'analyseur est prioritaire : les instructions de mappage des données dans une extension d'analyseur sont prioritaires sur celles de l'analyseur par défaut (ou personnalisé) pour ce type de journal. En cas de conflit dans les instructions de mappage, l'extension d'analyseur syntaxique remplacera la valeur définie par défaut.
Par exemple, si l'analyseur par défaut mappe un champ de journal brut au champ UDM
event.metadata.descriptionet que l'extension d'analyseur mappe un autre champ de journal brut à ce même champ UDM, l'extension d'analyseur remplace la valeur définie par l'analyseur par défaut.
Limites
- Une extension d'analyseur par type de journal : vous ne pouvez créer qu'une seule extension d'analyseur par type de journal.
- Une seule approche pour les instructions de mappage des données : vous pouvez créer une extension d'analyseur à l'aide de l'approche sans code ou de l'approche par extrait de code, mais pas les deux à la fois.
- Exemples de journaux pour la validation : des exemples de journaux des 30 derniers jours sont nécessaires pour valider une extension d'analyseur UDM. Pour en savoir plus, consultez S'assurer qu'un analyseur actif est disponible pour le type de journal.
- Erreurs de l'analyseur de base : les erreurs de l'analyseur de base ne peuvent pas être identifiées ni corrigées dans les extensions de l'analyseur.
- Champs répétés dans les extraits de code : soyez prudent lorsque vous remplacez des objets répétés entiers dans les extraits de code pour éviter toute perte de données involontaire. Pour en savoir plus, consultez À propos du sélecteur de champs répétés.
- Événements disambigués : les extensions d'analyseur ne peuvent pas gérer les journaux comportant plusieurs événements uniques dans un même enregistrement (par exemple, le tableau Google Drive).
XML et no-code : le mode no-code n'est pas compatible avec XML. Utilisez plutôt la méthode des extraits de code.
Pas de données rétroactives : vous ne pouvez pas analyser les données brutes des journaux de manière rétroactive.
Mots clés réservés avec l'approche sans code : si les journaux contiennent l'un des mots clés réservés suivants, utilisez l'approche avec extrait de code au lieu de l'approche sans code :
collectionTimestampcreateTimestampenableCbnForLoopeventfilenamemessagenamespaceoutputonErrorCounttimestamptimezone
Supprimer les mappages existants : vous ne pouvez supprimer les mappages de champs UDM existants qu'à l'aide de l'extrait de code.
Supprimer les mappages pour les champs d'adresse IP répétés : vous ne pouvez pas supprimer les mappages de champs UDM pour les champs d'adresse IP répétés.
Concepts relatifs aux analyseurs
Les documents suivants expliquent les concepts importants liés à l'analyseur :
- Présentation du modèle de données unifié
- Présentation de l'analyse des journaux
- Documentation de référence sur la syntaxe de l'analyseur
Prérequis
Conditions préalables à la création d'une extension d'analyseur :
- Un analyseur par défaut (ou personnalisé) actif doit exister pour le type de journal.
- Google SecOps doit pouvoir ingérer et normaliser les journaux bruts à l'aide d'un analyseur par défaut (ou personnalisé).
- Assurez-vous que l'analyseur actif par défaut (ou personnalisé) pour le type de journal cible a ingéré les données brutes du journal au cours des 30 derniers jours. Ces données doivent contenir un échantillon des champs que vous prévoyez d'extraire ou d'utiliser pour filtrer les enregistrements du journal. Il servira à valider vos nouvelles instructions de mappage des données.
Commencer
Avant de créer une extension d'analyseur, procédez comme suit :
Vérifiez les conditions préalables suivantes :
Assurez-vous qu'un analyseur actif est disponible pour le type de journal. S'il n'a pas encore d'analyseur, créez-en un personnalisé.
Identifiez les champs à extraire des journaux bruts :
Identifiez les champs que vous souhaitez extraire des journaux bruts.
Sélectionnez les champs UDM appropriés :
Sélectionnez les champs UDM correspondants appropriés pour mapper les champs de journaux bruts extraits.
Choisissez une approche de définition de l'extension de l'analyseur :
Choisissez l'une des deux approches d'extension (approches de mappage de données) pour créer l'extension d'analyseur.
Vérifier les conditions préalables
Assurez-vous qu'un analyseur actif existe pour le type de journal que vous souhaitez étendre, comme décrit dans les sections suivantes :
Assurez-vous qu'un analyseur actif existe pour le type de journal.
Assurez-vous qu'un analyseur par défaut (ou personnalisé) actif existe pour le type de journal que vous souhaitez étendre.
Recherchez votre type de journal dans les listes suivantes :
Types de journaux compatibles avec un analyseur par défaut.
- S'il existe un analyseur par défaut pour le type de journal, assurez-vous qu'il est actif.
- S'il n'existe aucun analyseur par défaut pour le type de journal, assurez-vous qu'il existe un analyseur personnalisé pour ce type de journal.
Types de journaux acceptés sans analyseur par défaut.
- S'il n'existe aucun analyseur par défaut pour le type de journal, assurez-vous qu'il existe un analyseur personnalisé pour ce type de journal.
Assurez-vous qu'il existe un analyseur personnalisé pour le type de journal.
Pour vous assurer qu'un analyseur personnalisé existe pour un type de journal :
- Dans la barre de navigation, sélectionnez Paramètres SIEM > Analyseurs.
Dans le tableau Analyseurs, recherchez le type de journal que vous souhaitez étendre.
- Si ce type de journal ne dispose pas encore d'un analyseur par défaut ou personnalisé, cliquez sur CRÉER UN ANALYSEUR et suivez les étapes décrites dans Créer un analyseur personnalisé basé sur des instructions de mappage.
- Si ce type de journal dispose déjà d'un analyseur personnalisé, assurez-vous qu'il est actif.
Assurez-vous que l'analyseur est actif pour le type de journal.
Pour vérifier si un analyseur est actif pour un type de journal, procédez comme suit :
- Dans la barre de navigation, sélectionnez Paramètres SIEM > Analyseurs.
Dans le tableau Analyseurs, recherchez le type de journal que vous souhaitez étendre.
Si l'analyseur du type de journal n'est pas actif, activez-le :
- Pour les analyseurs par défaut, consultez Gérer les mises à jour des analyseurs prédéfinis.
- Pour les analyseurs personnalisés, consultez Gérer les mises à jour des analyseurs personnalisés.
Identifier les champs à extraire des journaux bruts
Analysez le journal brut à partir duquel vous souhaitez extraire des données pour identifier les champs non extraits par l'analyseur par défaut (ou personnalisé). Faites attention à la façon dont l'analyseur par défaut (ou personnalisé) extrait les champs de journaux bruts et les mappe à leurs champs UDM correspondants.
Pour identifier les champs spécifiques que vous souhaitez extraire des journaux bruts, vous pouvez utiliser les outils de recherche :
Pour accéder à l'outil de recherche, accédez à Investigation > Recherche SIEM. Saisissez raw= avant votre requête de recherche. Pour en savoir plus, consultez Effectuer une recherche dans les journaux bruts.
Pour accéder à l'ancien outil de recherche, cliquez sur Accéder à l'ancienne recherche en haut de la page Recherche SIEM. Pour en savoir plus, consultez Rechercher dans les journaux bruts à l'aide de l'analyse des journaux bruts.
Pour en savoir plus sur la recherche dans les journaux bruts, consultez les ressources suivantes :
Sélectionner les champs UDM appropriés
Maintenant que vous avez identifié les champs cibles spécifiques à extraire, vous pouvez les faire correspondre aux champs UDM de destination correspondants. Établissez un mappage clair entre les champs de la source de journaux bruts et leurs champs UDM de destination. Vous pouvez mapper des données sur n'importe quel champ UDM compatible avec les types de données standards ou les champs répétés.
Choisir le bon champ UDM
Les ressources suivantes peuvent vous aider à simplifier le processus :
- Familiarisez-vous avec les principaux concepts de l'UDM.
- Comprendre le mappage des données utilisé par l'analyseur existant
- Utilisez l'outil de recherche UDM pour trouver les champs UDM potentiels qui correspondent à vos champs sources.
- Le guide Champs UDM importants pour le mappage des données de l'analyseur inclut un récapitulatif et une explication des champs les plus fréquemment utilisés du schéma UDM.
- La liste des champs du modèle de données unifié contient la liste de tous les champs UDM et leurs descriptions. Les champs répétés sont identifiés par le libellé repeated (répété) dans les listes.
- Points importants à prendre en compte concernant UDM pour éviter les erreurs
Familiarisez-vous avec les principaux concepts de l'UDM.
Objets logiques : événement et entité
Le schéma UDM décrit tous les attributs disponibles qui stockent des données. Chaque enregistrement UDM décrit un événement ou une entité. Les données sont stockées dans différents champs selon que l'enregistrement décrit un événement ou une entité.
- Un objet UDM Event stocke les données sur l'action qui s'est produite dans l'environnement. Le journal des événements d'origine décrit l'action telle qu'elle a été enregistrée par l'appareil, comme le pare-feu ou le proxy Web.
- Les objets Entité UDM stockent des données sur les participants ou les entités impliqués dans l'événement UDM, tels que les composants, les utilisateurs ou les ressources de votre environnement.
Noms communs UDM : un nom commun représente un participant ou une entité dans un événement UDM. Un nom peut être, par exemple, l'appareil ou l'utilisateur qui effectue l'activité décrite dans l'événement. Un nom peut également désigner l'appareil ou l'utilisateur qui est la cible de l'activité décrite dans l'événement.
Nom UDM Description principalEntité responsable du déclenchement de l'action décrite dans l'événement. targetEntité qui est le destinataire ou l'objet de l'action. Dans une connexion de pare-feu, la machine qui reçoit la connexion est la cible. srcEntité source sur laquelle le principal a agi. Par exemple, si un utilisateur copie un fichier d'une machine à une autre, le fichier et la machine d'origine sont représentés en tant que src. intermediaryToute entité servant d'intermédiaire dans l'événement, comme un serveur proxy. Ils peuvent influencer l'action, par exemple en bloquant ou en modifiant une requête. observerEntité qui surveille l'événement et en rend compte, mais qui n'interagit pas directement avec le trafic. Il peut s'agir, par exemple, de systèmes de détection des intrusions sur le réseau ou de systèmes de gestion des informations et des événements de sécurité. aboutToutes les autres entités impliquées dans l'événement qui ne correspondent pas aux catégories précédentes. Par exemple, les pièces jointes d'e-mails ou les fichiers DLL chargés lors du lancement d'un processus. En pratique, les objets Noun principaux et cibles sont ceux qui sont le plus souvent utilisés. Il est également important de noter que les descriptions précédentes constituent l'utilisation recommandée des Noms. L'utilisation réelle peut varier en fonction de l'implémentation d'un analyseur de base par défaut ou personnalisé.
Comprendre le mappage des données utilisé par l'analyseur syntaxique existant
Il est recommandé de comprendre le mappage de données existant utilisé par l'analyseur par défaut (ou personnalisé), entre les champs de la source de journaux bruts et leurs champs UDM de destination.
Pour afficher le mappage de données entre les champs de la source de journaux bruts et les champs UDM de destination utilisés dans l'analyseur par défaut (ou personnalisé) existant :
- Dans la barre de navigation, sélectionnez Paramètres SIEM > Analyseurs.
- Dans le tableau Analyseurs, recherchez le type de journal que vous souhaitez étendre.
Accédez à cette ligne, puis cliquez sur le menu > Afficher.
L'onglet Code du parseur affiche le mappage des données entre les champs de la source du journal brut et les champs UDM de destination utilisés dans le parseur par défaut (ou personnalisé) existant.
Utiliser l'outil de recherche UDM
Utilisez l'outil de recherche UDM pour identifier les champs UDM qui correspondent aux champs de la source du journal brut.
Google SecOps fournit l'outil de recherche UDM pour vous aider à trouver rapidement les champs UDM de destination. Pour accéder à l'outil de recherche UDM, accédez à Investigation > Recherche SIEM.
Consultez les rubriques suivantes pour savoir comment utiliser l'outil de recherche UDM :
- Rechercher un champ UDM
- Saisir une recherche UDM
- Définir un filtre temporel pour la recherche
- Exemples de recherches UDM
- Générer des requêtes de recherche UDM avec Gemini
Exemple d'outil de recherche UDM
Par exemple, si vous disposez d'un champ source nommé "packets" dans le journal brut, utilisez l'outil de recherche UDM pour trouver les champs UDM de destination potentiels dont le nom contient "packets" :
Accédez à Investigation > Recherche SIEM.
Sur la page Recherche SIEM, saisissez "packets" (paquets) dans le champ Rechercher des champs UDM par valeur, puis cliquez sur Recherche UDM.
La boîte de dialogue Recherche UDM s'ouvre. L'outil de recherche fait correspondre les champs UDM par nom de champ ou par valeur de champ :
- Recherche par nom de champ : fait correspondre la chaîne de texte que vous saisissez aux noms de champs contenant ce texte.
- Recherche par valeur de champ : la valeur que vous saisissez est mise en correspondance avec les champs qui contiennent cette valeur dans leurs données de journaux stockées.
Dans la boîte de dialogue Recherche UDM, sélectionnez Champs UDM.
La fonction de recherche affichera une liste de champs UDM potentiels contenant le texte "packets" dans leurs noms de champs UDM.
Cliquez sur chaque ligne pour afficher la description de chaque champ UDM.
Points importants à prendre en compte concernant UDM pour éviter les erreurs
- Champs d'apparence similaire : la structure hiérarchique de l'UDM peut entraîner la création de champs portant des noms similaires. Pour en savoir plus, consultez la section sur les analyseurs par défaut. Pour en savoir plus, consultez Comprendre le mappage de données utilisé par l'analyseur existant.
- Mappage de champs arbitraire : utilisez l'objet
additionalpour les données qui ne sont pas directement mappées sur un champ UDM. Pour en savoir plus, consultez Mappage de champs arbitraires dans l'UDM. - Champs répétés : soyez prudent lorsque vous utilisez des champs répétés dans des extraits de code. Le remplacement d'un objet entier peut écraser les données d'origine. L'approche sans code offre un meilleur contrôle sur les champs répétés. Pour en savoir plus, consultez À propos du sélecteur de champs répétés.
- Champs UDM obligatoires pour les types d'événements UDM : lorsque vous attribuez un champ
metadata.event_typeUDM à un enregistrement UDM, chaqueevent_typenécessite qu'un ensemble différent de champs associés soit présent dans l'enregistrement UDM. Pour en savoir plus, consultez En savoir plus sur l'attribution des champsmetadata.event_typede l'UDM. - Problèmes liés à l'analyseur de base : les extensions d'analyseur ne peuvent pas corriger les erreurs de l'analyseur de base. L'analyseur de base est l'analyseur par défaut (ou personnalisé) qui a créé l'enregistrement UDM. Envisagez des options telles que l'amélioration de l'extension d'analyseur, la modification de l'analyseur de base ou le préfiltrage des journaux.
Mappage de champs arbitraires dans UDM
Lorsque vous ne trouvez pas de champ UDM standard adapté pour stocker vos données, utilisez l'objet additional pour stocker les données sous forme de paire clé-valeur personnalisée. Cela vous permet de stocker des informations précieuses dans l'enregistrement UDM, même s'il ne comporte pas de champ UDM correspondant.
Choisir une approche de définition d'extension d'analyseur
Avant de choisir une approche de définition d'extension d'analyseur, vous devez avoir parcouru les sections suivantes :
Les étapes suivantes consistent à ouvrir la page Extensions d'analyseur et à sélectionner l'approche d'extension à utiliser pour définir l'extension d'analyseur :
Ouvrir la page "Extensions de l'analyseur"
La page Extensions de l'analyseur vous permet de définir la nouvelle extension de l'analyseur.
Vous pouvez ouvrir la page Extensions d'analyseur de différentes manières : depuis le menu "Paramètres", depuis une recherche de journaux bruts ou depuis une ancienne recherche de journaux bruts.
Ouvrir depuis le menu "Paramètres"
Pour ouvrir la page Extensions d'analyseur à partir du menu "Paramètres" :
Dans la barre de navigation, sélectionnez Paramètres SIEM > Analyseurs.
Le tableau Analyseurs affiche la liste des analyseurs par défaut par type de journal.
Recherchez le type de journal que vous souhaitez étendre, puis cliquez sur le menu > Créer une extension.
La page Extensions de l'analyseur s'ouvre.
Ouvrir à partir d'une recherche dans les journaux bruts
Pour ouvrir la page Extensions d'analyseur à partir d'une recherche de journaux bruts :
- Accédez à Investigation > Recherche SIEM.
- Dans le champ de recherche, ajoutez le préfixe
raw =à votre argument de recherche et placez le terme de recherche entre guillemets. Exemple :raw = "example.com" - Cliquez sur Exécuter la recherche. Les résultats s'affichent dans le panneau Journaux bruts.
- Cliquez sur un journal (ligne) dans le panneau Journaux bruts. Le panneau Vue des événements s'affiche.
- Cliquez sur l'onglet Journal brut dans le panneau Vue des événements. Le journal brut s'affiche.
Cliquez sur Gérer l'analyseur > Créer une extension > Suivant.
La page Extensions de l'analyseur s'ouvre.
Ouvrir l'ancienne Recherche dans les journaux bruts
Pour ouvrir la page Extensions d'analyseur à partir d'une recherche de journaux bruts ancienne :
- Utilisez l'ancienne recherche dans les journaux bruts pour rechercher des enregistrements semblables à ceux qui seront analysés.
- Sélectionnez un événement dans le panneau Événements > Chronologie.
- Développez le panneau Données d'événement.
Cliquez sur Gérer l'analyseur > Créer une extension > Suivant.
La page Extensions de l'analyseur s'ouvre.
Page des extensions d'analyseur
La page affiche les panneaux Journal brut et Définition de l'extension :
Panneau Journal brut :
Affiche des exemples de données brutes de journaux pour le type de journal sélectionné. Si vous avez ouvert la page à partir de la recherche de journaux bruts, les exemples de données sont le résultat de votre recherche. Vous pouvez mettre en forme l'échantillon à l'aide du menu Afficher sous forme de (RAW, JSON, CSV, XML, etc.) et de la case à cocher Retour à la ligne.
Vérifiez que l'échantillon de données de journaux bruts affiché est représentatif des journaux que l'extension d'analyseur traitera.
Cliquez sur Prévisualiser la sortie UDM pour afficher la sortie UDM des exemples de données brutes de journaux.
Panneau Définition de l'extension :
Cela vous permet de définir une extension d'analyseur à l'aide de l'une des deux approches d'instruction de mappage : Mapper les champs de données (sans code) ou Écrire un extrait de code. Vous ne pouvez pas utiliser les deux approches dans la même extension d'analyseur.
Selon l'approche que vous choisissez, vous pouvez spécifier les champs de données de journaux sources à extraire des journaux bruts entrants et les mapper aux champs UDM correspondants, ou vous pouvez écrire un extrait de code pour effectuer ces tâches et plus encore.
Sélectionnez l'approche d'extension.
Sur la page Extensions de l'analyseur, dans le panneau Définition de l'extension, dans le champ Méthode d'extension, sélectionnez l'une des approches suivantes pour créer l'extension de l'analyseur :
Approche sans code :
Cette approche vous permet de spécifier les champs du journal brut et de les mapper sur les champs UDM de destination.
Cette approche fonctionne avec les formats de journaux bruts suivants :
- JSON natif, XML natif ou CSV.
- En-tête Syslog plus JSON natif, XML natif ou CSV. Vous pouvez créer des instructions de mappage des types de champs de données pour les journaux bruts dans les formats suivants :
JSON,XML,CSV,SYSLOG + JSON,SYSLOG + XMLetSYSLOG + CSV.
Consultez les instructions de l'étape suivante : Créer des champs de données de carte sans code.
Approche Écrire un extrait de code :
Cette approche vous permet d'utiliser une syntaxe de type Logstash pour spécifier des instructions permettant d'extraire et de transformer des valeurs du journal brut, puis de les attribuer à des champs UDM dans l'enregistrement UDM.
Les extraits de code utilisent la même syntaxe et les mêmes sections que les analyseurs par défaut (ou personnalisés). Pour en savoir plus, consultez Syntaxe de l'analyseur.
Cette approche fonctionne avec tous les formats de données compatibles pour ce type de journal.
Consultez les instructions de la section Créer un extrait de code.
Créer des instructions sans code (mapper les champs de données)
L'approche sans code (également appelée méthode Mapper les champs de données) vous permet de spécifier les chemins d'accès aux champs de journaux bruts et de les mapper aux champs UDM de destination correspondants.
Avant de créer une extension d'analyseur à l'aide de l'approche sans code, vous devez avoir parcouru les sections suivantes :
- Créer des extensions d'analyseur
- Commencer
- Sélectionnez l'approche d'extension, puis l'option Mapper les champs de données.
Voici les étapes à suivre pour définir l'extension d'analyseur :
- Définir le sélecteur de champs répétés
- Définissez une instruction de mappage des données pour chaque champ.
- Envoyer et activer l'extension d'analyseur
Définir le sélecteur de champs répétés
Dans le panneau Définition de l'extension, dans le champ Champs répétés, définissez la façon dont l'extension d'analyseur doit enregistrer une valeur dans les champs répétés (champs qui acceptent un tableau de valeurs, par exemple principal.ip) :
- Ajouter des valeurs : la nouvelle valeur extraite est ajoutée à l'ensemble de valeurs existant stocké dans le champ de tableau UDM.
- Remplacer les valeurs : la nouvelle valeur extraite remplace l'ensemble de valeurs existant dans le champ de tableau UDM, précédemment stocké par l'analyseur par défaut.
Les paramètres du sélecteur Champs répétés n'affectent pas les champs non répétés.
Pour en savoir plus, consultez À propos du sélecteur de champs répétés.
Définir une instruction de mappage des données pour chaque champ
Définissez une instruction de mappage de données pour chaque champ que vous souhaitez extraire du journal brut. L'instruction doit spécifier le chemin d'accès du champ d'origine dans le journal brut et le mapper au champ UDM de destination.
Si l'exemple de journal brut affiché dans le panneau Journal brut contient un en-tête Syslog, les champs Syslog et Cible s'affichent. (Certains formats de journaux ne contiennent pas d'en-tête Syslog, par exemple JSON natif, XML natif ou CSV.)
Google SecOps aura besoin des champs Syslog et Cible pour prétraiter l'en-tête Syslog et extraire la partie structurée du journal.
Définissez les champs suivants :
Syslog : il s'agit d'un modèle défini par l'utilisateur qui prétraite et sépare un en-tête Syslog de la partie structurée d'un journal brut.
Spécifiez le modèle d'extraction à l'aide de Grok et d'expressions régulières, qui identifie l'en-tête Syslog et le message de journal brut. Pour en savoir plus, consultez Définir les champs de l'extracteur Syslog.
Cible : nom de la variable dans le champ Syslog qui stocke la partie structurée du journal.
Spécifiez le nom de la variable dans le modèle d'extraction qui stocke la partie structurée du journal.
Voici un exemple de modèle d'extraction et de nom de variable pour les champs Syslog et Target, respectivement.

Après avoir saisi des valeurs dans les champs Syslog et Cible, cliquez sur le bouton Valider.
Le processus de validation recherche les erreurs de syntaxe et d'analyse, puis renvoie l'un des éléments suivants :
- Test concluant : les champs de mappage de données s'affichent. Définissez le reste de l'extension d'analyseur.
- Échec : un message d'erreur s'affiche. Corrigez l'erreur avant de continuer.
Vous pouvez également définir une instruction de précondition.
Une instruction de précondition identifie un sous-ensemble des journaux bruts que l'extension d'analyseur traite en faisant correspondre une valeur statique à un champ du journal brut. Si un journal brut entrant répond aux critères de la condition préalable, l'extension d'analyseur applique l'instruction de mappage. Si les valeurs ne correspondent pas, l'extension d'analyseur n'applique pas l'instruction de mappage.
Remplissez les champs suivants :
- Champ de précondition : identifiant du champ dans le journal brut contenant la valeur à comparer. Saisissez le chemin d'accès complet au champ si le format de données de journal est JSON ou XML, ou la position de la colonne si le format de données est CSV.
- Opérateur de précondition : sélectionnez
EQUALSouNOT EQUALS. - Valeur de la condition préalable : valeur statique qui sera comparée au champ de la condition préalable dans le journal brut.
Pour obtenir un autre exemple d'instruction de précondition, consultez No-code : extraire des champs avec une valeur de précondition.
Mappez le champ de données de journaux brutes au champ UDM de destination :
Champ de données brutes : saisissez le chemin d'accès complet au champ si le format des données de journal est JSON (par exemple,
jsonPayload.connection.dest_ip) ou XML (par exemple,/Event/Reason-Code), ou la position de la colonne si le format des données est CSV (remarque : les positions d'index commencent à 1).Champ de destination : saisissez le nom de champ UDM complet où la valeur sera stockée, par exemple
udm.metadata.collected_timestamp.seconds.
Pour continuer à ajouter des champs, cliquez sur Ajouter, puis saisissez tous les détails des instructions de mappage pour le champ suivant.
Pour un autre exemple de mappage des champs, consultez No-code : extraire des champs.
Envoyer et activer l'extension de l'analyseur
Une fois que vous avez défini des instructions de mappage de données pour tous les champs que vous souhaitez extraire du journal brut, envoyez et activez l'extension de l'analyseur.
Cliquez sur Envoyer pour enregistrer et valider l'instruction de mappage.
Google SecOps valide les instructions de mappage :
- Si le processus de validation réussit, l'état passe à En ligne et les instructions de mappage commencent à traiter les données de journaux entrantes.
Si le processus de validation échoue, l'état passe à Échec et une erreur s'affiche dans le champ "Journal brut".
Voici un exemple d'erreur de validation :
ERROR: generic::unknown: pipeline.ParseLogEntry failed: LOG_PARSING_CBN_ERROR: "generic::invalid_argument: pipeline failed: filter mutate (7) failed: copy failure: copy source field \"jsonPayload.dest_instance.region\" must not be empty (try using replace to provide the value before calling copy) "LOG: {"insertId":"14suym9fw9f63r","jsonPayload":{"bytes_sent":"492", "connection":{"dest_ip":"10.12.12.33","dest_port":32768,"protocol":6, "src_ip":"10.142.0.238","src_port":22},"end_time":"2023-02-13T22:38:30.490546349Z", "packets_sent":"15","reporter":"SRC","src_instance":{"project_id":"example-labs", "region":"us-east1","vm_name":"example-us-east1","zone":"us-east1-b"}, "src_vpc":{"project_id":"example-labs","subnetwork_name":"default", "vpc_name":"default"},"start_time":"2023-02-13T22:38:29.024032655Z"}, "logName":"projects/example-labs/logs/compute.googleapis.com%2Fvpc_flows", "receiveTimestamp":"2023-02-13T22:38:37.443315735Z","resource":{"labels": {"location":"us-east1-b","project_id":"example-labs", "subnetwork_id":"00000000000000000000","subnetwork_name":"default"}, "type":"gce_subnetwork"},"timestamp":"2023-02-13T22:38:37.443315735Z"}États du cycle de vie d'une extension d'analyseur
Les extensions d'analyseur ont les états de cycle de vie suivants :
DRAFT: extension d'analyseur nouvellement créée et qui n'a pas encore été envoyée.VALIDATING: Google SecOps valide les instructions de mappage par rapport aux journaux bruts existants pour s'assurer que les champs sont analysés sans erreur.LIVE: l'extension de l'analyseur a été validée et est désormais en production. Il extrait et transforme les données des journaux bruts entrants en enregistrements UDM.FAILED: la validation de l'extension de l'analyseur a échoué.
En savoir plus sur le sélecteur de champs répétés
Certains champs UDM stockent un tableau de valeurs, comme le champ principal.ip. Le sélecteur Champs répétés vous permet de contrôler la façon dont votre extension d'analyseur stocke les données nouvellement extraites dans un champ répété :
Ajouter des valeurs :
L'extension d'analyseur ajoutera la valeur nouvellement extraite au tableau des valeurs existantes dans le champ UDM.
Remplacer des valeurs :
L'extension d'analyseur remplacera le tableau des valeurs existantes dans le champ UDM par la nouvelle valeur extraite.
Une extension d'analyseur peut mapper des données à un champ répété uniquement lorsque le champ répété se trouve au niveau le plus bas de la hiérarchie. Exemple :
- Le mappage des valeurs sur
udm.principal.ipest accepté, car le champ répétéipse trouve au niveau le plus bas de la hiérarchie et queprincipaln'est pas un champ répété. - Le mappage des valeurs sur
udm.intermediary.hostnamen'est pas accepté, carintermediaryest un champ répété et ne se trouve pas au niveau le plus bas de la hiérarchie.
Le tableau suivant fournit des exemples de l'impact de la configuration du sélecteur Champs répétés sur l'enregistrement UDM généré.
| Sélection Champs répétés | Exemple de journal | Configuration de l'extension de l'analyseur | Résultat généré |
|---|---|---|---|
| Ajouter des valeurs | {"protoPayload":{"@type":"type.AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"1.1.1.1, 2.2.2.2"}}} |
Champ de précondition : protoPayload.requestMetadata.callerIp
Valeur de précondition : " "
Opérateur de précondition : NOT_EQUALS
Champ de données brutes : protoPayload.requestMetadata.callerIp
Champ de destination : event.idm.read_only_udm.principal.ip
|
metadata:{event_timestamp:{}.....}principal:{Ip:"1.1.1.1, 2.2.2.2"}
}
} |
| Ajouter des valeurs | {"protoPayload":{"@type":"type.AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"2.2.2.2, 3.3.3.3", "name":"Akamai Ltd"}}} |
Condition préalable 1 :
Champ de condition préalable : protoPayload.requestMetadata.callerIp
Valeur de condition préalable : " "
Opérateur de condition préalable : NOT_EQUALS
Champ de données brutes : protoPayload.requestMetadata.callerIp
Champ de destination : event.idm.read_only_udm.principal.ip
Prérequis 2 :
|
Événements générés par l'analyseur prédéfini avant l'application de l'extension.
metadata:{event_timestamp:{} ... principal:{ip:"1.1.1.1"}}}
Résultat après application de l'extension.
|
| Remplacer des valeurs | {"protoPayload":{"@type":"type..AuditLog","authenticationInfo":{"principalEmail":"admin@cmmar.co"},"requestMetadata":{"callerIp":"2.2.2.2"}}} |
Champ de précondition : protoPayload.authenticationInfo.principalEmail
Valeur de précondition : " "
Opérateur de précondition : NOT_EQUALS
Champ de données brutes : protoPayload.authenticationInfo.principalEmail
Champ de destination : event.idm.read_only_udm.principal.ip
|
Événements UDM générés par l'analyseur prédéfini avant l'application de l'extension.timestamp:{} idm:{read_only_udm:{metadata:{event_timestamp:{} ... principal:{ip:"1.1.1.1"}}}
Sortie UDM après application de l'extension
|
En savoir plus sur les champs de l'extracteur Syslog
Les champs de l'extracteur Syslog vous permettent de séparer l'en-tête Syslog d'un journal structuré en définissant l'expression Grok ou régulière, ainsi qu'un jeton nommé dans le modèle d'expression régulière pour stocker la sortie.
Définir les champs de l'extracteur Syslog
Les valeurs des champs Syslog et Cible fonctionnent ensemble pour définir la façon dont l'extension d'analyseur sépare l'en-tête Syslog de la partie structurée d'un journal brut. Dans le champ Syslog, vous définissez une expression à l'aide d'une combinaison de syntaxe Grok et d'expression régulière. L'expression inclut un nom de variable qui identifie la partie structurée du journal brut. Dans le champ Cible, vous spécifiez le nom de cette variable.
L'exemple suivant illustre le fonctionnement de ces champs.
Voici un exemple de journal brut :
<13>1 2022-09-14T15:03:04+00:00 fieldname fieldname - - - {"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
Le journal brut contient les sections suivantes :
En-tête Syslog :
<13> 2022-09-14T15:03:04+00:00 fieldname fieldname - - -Événement au format JSON :
{"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
Pour séparer l'en-tête Syslog de la partie JSON du journal brut, utilisez l'exemple d'expression suivant dans le champ Syslog :
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg} .
- Cette partie de l'expression identifie l'en-tête Syslog :
%{TIMESTAMP\_ISO8601} %{WORD} %{WORD} ([- ]+)? - Cette partie de l'expression capture le segment JSON du journal brut :
%{GREEDYDATA:msg}
Cet exemple inclut le nom de variable msg. Vous choisissez le nom de la variable.
L'extension d'analyseur extrait le segment JSON du journal brut et l'attribue à la variable msg.
Dans le champ Target (Cible), saisissez le nom de la variable msg. La valeur stockée dans la variable msg est saisie dans les instructions de mappage des champs de données que vous créez dans l'extension d'analyseur.
En utilisant l'exemple de journal brut, le segment suivant est saisi dans l'instruction de mappage de données :
{"timestamp": "2021-03-14T14:54:40.842152+0000","flow_id": 1885148860701096, "src_ip": "10.11.22.1","src_port": 51972,"dest_ip": "1.2.3.4","dest_port": 55291,"proto": "TCP"}
Vous trouverez ci-dessous les champs Syslog et Cible complétés :
Le tableau suivant fournit d'autres exemples avec des journaux d'échantillon, le modèle d'extraction Syslog, le nom de la variable Target et le résultat.
| Exemple de journal brut | Champ Syslog | Champ cible | Résultat |
|---|---|---|---|
<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}" |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg} |
msg | field_mappings {
field: "msg"
value: "{\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}"
}
|
<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\"} - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"} |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:msg1} ([- ]+)?%{GREEDYDATA:msg2} |
msg2 | field_mappings {
field: "msg2"
value: "{\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}"
} |
"<13>1 2022-07-14T15:03:04+00:00 suricata suricata - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\"} - - - {\"timestamp\": \"2021-03-14T14:54:40.842152+0000\",\"flow_id\": 1885148860701096,\"in_iface\": \"enp94s0\",\"event_type\": \"alert\",\"vlan\": 522,\"src_ip\": \"1.1.2.1\",\"src_port\": 51972,\"dest_ip\": \"1.2.3.4\",\"dest_port\": 55291,\"proto\": \"TCP\"}" |
%{TIMESTAMP_ISO8601} %{WORD} %{WORD} ([- ]+)?%{GREEDYDATA:message} ([- ]+)?%{GREEDYDATA:msg2} |
msg2 | Error - message already exists in state and not overwritable. |
En savoir plus sur l'attribution de champs metadata.event_type UDM
Lorsque vous attribuez un champ metadata.event_type UDM à un enregistrement UDM, il est validé pour s'assurer que les champs associés requis sont présents dans l'enregistrement UDM. Chaque metadata.event_type UDM nécessite un ensemble différent de champs associés. Par exemple, un événement USER_LOGIN sans user n'est pas utile.
Si un champ associé obligatoire est manquant, la validation UDM renvoie une erreur :
"error": {
"code": 400,
"message": "Request contains an invalid argument.",
"status": "INVALID_ARGUMENT"
}
Un analyseur Grok renvoie une erreur plus détaillée :
generic::unknown:
invalid event 0: LOG_PARSING_GENERATED_INVALID_EVENT:
"generic::invalid_argument: udm validation failed: target field is not set"
Pour trouver les champs obligatoires d'un event_type UDM que vous souhaitez attribuer, utilisez les ressources suivantes :
Documentation Google SecOps : Guide d'utilisation de l'UDM : champs UDM obligatoires et facultatifs pour chaque type d'événement
Ressources tierces non officielles : Validation des événements UDM
Dans les cas où le Guide d'utilisation de l'UDM manque de détails, ce document complète la documentation officielle en fournissant les champs UDM obligatoires minimaux nécessaires pour remplir un
metadata.event_typeUDM donné.Par exemple, ouvrez le document et recherchez le type d'événement
GROUP_CREATION.Les champs UDM minimaux suivants doivent s'afficher sous la forme d'un objet UDM :
{ "metadata": { "event_timestamp": "2023-07-03T13:01:10.957803Z", "event_type": "GROUP_CREATION" }, "principal": { "user": { "userid": "pinguino" } }, "target": { "group": { "group_display_name": "foobar_users" } } }
Créer des instructions pour les extraits de code
L'approche par extrait de code vous permet d'utiliser une syntaxe semblable à celle de Logstash pour définir comment extraire et transformer les valeurs du journal brut, et les attribuer aux champs UDM dans l'enregistrement UDM.
Avant de créer une extension d'analyseur à l'aide de l'approche par extrait de code, vous devez avoir parcouru les sections suivantes :
- Créer des extensions d'analyseur
- Commencer
- Sélectionnez l'approche d'extension, puis l'option Écrire un extrait de code.
Voici les étapes à suivre pour définir l'extension d'analyseur :
- Pour obtenir des conseils et des bonnes pratiques, consultez Conseils et bonnes pratiques pour rédiger des instructions d'extrait de code.
- Créer une instruction d'extrait de code
- Envoyer une instruction d'extrait de code
Conseils et bonnes pratiques pour rédiger des instructions d'extrait de code
Les instructions relatives aux extraits de code peuvent échouer en raison de problèmes tels que des modèles Grok incorrects, des opérations de renommage ou de remplacement qui ont échoué, ou des erreurs de syntaxe. Pour obtenir des conseils et des bonnes pratiques, consultez les ressources suivantes :
- Pratiques courantes dans le code du parseur
- Analyser du texte non structuré à l'aide d'une fonction Grok
Créer une instruction d'extrait de code
Les instructions relatives aux extraits de code utilisent la même syntaxe et les mêmes sections que l'analyseur par défaut (ou personnalisé) :
- Section 1. Extrayez les données du journal brut.
- Section 2. Transformez les données extraites.
- Section 3. Attribuez une ou plusieurs valeurs à un champ UDM.
- Section 4. Liez les champs d'événement UDM à la clé
@output.
Pour créer une extension d'analyseur à l'aide de l'approche par extrait de code, procédez comme suit :
- Sur la page Extensions d'analyseur, dans le panneau Extrait CBN, saisissez un extrait de code pour créer l'extension d'analyseur.
- Cliquez sur Valider pour valider les instructions de mise en correspondance.
Exemples d'instructions pour les extraits de code
L'exemple suivant illustre un extrait de code.
Voici un exemple de journal brut :
{
"insertId": "00000000",
"jsonPayload": {
...section omitted for brevity...
"packets_sent": "4",
...section omitted for brevity...
},
"timestamp": "2022-05-03T01:45:00.150614953Z"
}
Voici un exemple d'extrait de code qui mappe la valeur de jsonPayload.packets_sent au champ UDM network.sent_bytes :
filter {
mutate {
replace => {
"jsonPayload.packets_sent" => ""
}
}
# Section 1. extract data from the raw JSON log
json {
source => "message"
array_function => "split_columns"
on_error => "_not_json"
}
if [_not_json] {
drop {
tag => "TAG_UNSUPPORTED"
}
} else {
# Section 2. transform the extracted data
if [jsonPayload][packets_sent] not in ["", 0] {
mutate {
convert => {
"jsonPayload.packets_sent" => "uinteger"
}
on_error => "_exception1"
}
# Section 3. assign the value to a UDM field
mutate {
Replace => {
"event.idm.read_only_udm.network.sent_bytes" => "jsonPayload.packets_sent"
}
on_error => "_exception2"
}
if ![_exception1] and![_exception2] {
# Section 4. Bind the UDM fields to the @output key
mutate {
merge => {
"@output" => "event"
}
}
}
}
}
}
Envoyer une instruction d'extrait de code
Cliquez sur Envoyer pour enregistrer les instructions de mappage.
Google SecOps valide les instructions de mappage.
- Si le processus de validation réussit, l'état passe à En ligne et les instructions de mappage commencent à traiter les données de journaux entrantes.
- Si le processus de validation échoue, l'état passe à Échec et une erreur s'affiche dans le champ "Journal brut".
Gérer les extensions d'analyseur existantes
Vous pouvez afficher, modifier, supprimer et contrôler l'accès aux extensions d'analyseur existantes.
Afficher une extension d'analyseur existante
- Dans la barre de navigation, sélectionnez Paramètres SIEM > Analyseurs.
- Dans la liste "Analyseurs", recherchez l'analyseur (type de journal) que vous souhaitez afficher.
Les analyseurs avec une extension d'analyseur sont indiqués par le texte
EXTENSIONà côté de leur nom. Accédez à cette ligne, puis cliquez sur Menu > Afficher l'extension.
L'onglet Afficher l'analyseur personnalisé/prédéfini > Extension s'affiche et contient des informations sur l'extension de l'analyseur. Le panneau récapitulatif affiche l'extension d'analyseur
LIVEpar défaut.
Modifier une extension de l'analyseur
Ouvrez Afficher l'analyseur personnalisé/prédéfini > Onglet "Extension", comme décrit dans Afficher une extension d'analyseur existante.
Cliquez sur le bouton Modifier l'extension.
La page Extensions d'analyseur s'affiche.
Modifiez l'extension de l'analyseur.
Pour annuler la modification et supprimer les modifications, cliquez sur Supprimer le brouillon.
Pour supprimer l'extension d'analyseur à tout moment, cliquez sur Supprimer l'extension ayant échoué.
Une fois l'extension d'analyseur modifiée, cliquez sur Envoyer.
Le processus de validation s'exécute pour valider la nouvelle configuration.
Supprimer une extension d'analyseur
Ouvrez Afficher l'analyseur personnalisé/prédéfini > Onglet "Extension", comme décrit dans Afficher une extension d'analyseur existante.
Cliquez sur le bouton Supprimer l'extension.
Contrôler l'accès aux extensions d'analyseur
Par défaut, les utilisateurs disposant du rôle Administrateur peuvent accéder aux extensions d'analyseur. Vous pouvez contrôler qui peut afficher et gérer les extensions d'analyseur. Pour en savoir plus sur la gestion des utilisateurs et des groupes, ou sur l'attribution de rôles, consultez Contrôle des accès basé sur les rôles.
Le tableau suivant récapitule les nouveaux rôles dans Google SecOps.
| Fonctionnalité | Action | Description |
|---|---|---|
| Analyseur | Supprimer | Supprimez les extensions d'analyseur. |
| Analyseur | Modifier | Créer et modifier des extensions d'analyseur |
| Analyseur | Afficher | Affichez les extensions d'analyseur. |
Supprimer les mappages de champs UDM à l'aide des extensions d'analyseur
Vous pouvez utiliser des extensions d'analyseur pour supprimer un mappage de champ UDM existant.
- Cliquez sur Paramètres SIEM > Analyseurs.
- Pour afficher la page de l'extension Parser, utilisez l'une des méthodes suivantes :
- Pour une extension existante, cliquez sur Menu > Étendre l'analyseur > Afficher l'extension.
- Pour les nouvelles extensions d'analyseur, cliquez sur Menu > Étendre l'analyseur > Créer une extension.
Sélectionnez Écrire un extrait de code comme méthode d'extension pour ajouter un extrait de code personnalisé qui supprime les valeurs de champs UDM spécifiques.
Pour une extension existante, dans le volet Extension d'analyseur, cliquez sur Modifier, puis ajoutez l'extrait de code.
Consultez Extrait de code : supprimer les mappages existants pour obtenir des exemples d'extraits.
Suivez les étapes de la section Envoyer un extrait de code pour envoyer l'extension.
Vous avez encore besoin d'aide ? Obtenez des réponses de membres de la communauté et de professionnels Google SecOps.