Présentation du modèle de données unifié
Ce document fournit une présentation du modèle de données unifié (UDM, Unified Data Model). Pour en savoir plus sur les champs UDM, y compris une description de chacun d'eux, consultez la liste des champs UDM. Pour en savoir plus sur le mappage des analyseurs, consultez Champs UDM importants pour le mappage des analyseurs.
L'UDM est une structure de données standard Google Security Operations qui stocke des informations sur les données reçues des sources. On parle également de schéma. Google SecOps stocke les données d'origine qu'il reçoit dans deux formats : le journal brut d'origine et un enregistrement UDM structuré. L'enregistrement UDM est une représentation structurée du journal d'origine.
Si un analyseur existe pour le type de journal spécifié, le journal brut est utilisé pour créer un enregistrement UDM. Les clients peuvent également transformer les journaux bruts au format UDM structuré avant d'envoyer les données à Google SecOps à l'aide de l'API Ingestion.
Voici quelques-uns des avantages de l'UDM :
- Stocke le même type d'enregistrement provenant de différents fournisseurs à l'aide de la même sémantique.
- Il est plus facile d'identifier les relations entre les utilisateurs, les hôtes et les adresses IP, car les données sont normalisées dans le schéma UDM standard.
- Il est plus facile d'écrire des règles, car elles peuvent être indépendantes de la plate-forme.
- Il est plus facile de prendre en charge les types de journaux provenant de nouveaux appareils.
Bien que vous puissiez rechercher des événements avec une recherche de journaux bruts, une recherche UDM fonctionne plus rapidement et avec plus de précision en raison de sa spécificité. Google SecOps collecte les données de journaux brutes et stocke les détails des journaux d'événements dans le schéma UDM. L'UDM fournit un framework complet de milliers de champs permettant de décrire et de catégoriser différents types d'événements, par exemple les événements de processus de point de terminaison et les événements de communication réseau.
Structure UDM
Les événements UDM sont composés de plusieurs sections. La première section de chaque événement UDM est la section des métadonnées. Il fournit une description de base de l'événement, y compris l'horodatage de son occurrence et de son ingestion dans Google SecOps. Il inclut également les informations, la version et la description du produit. L'analyseur d'ingestion classe chaque événement en fonction d'un type d'événement prédéfini, indépendamment du journal de produit spécifique. Avec les seuls champs de métadonnées, vous pouvez rapidement commencer à rechercher des données.
En plus de la section sur les métadonnées, d'autres sections décrivent des aspects supplémentaires de l'événement. Si une section n'est pas nécessaire, elle n'est pas incluse, ce qui permet d'économiser de la mémoire.
principal: entité à l'origine de l'activité dans l'événement. Les sections qui font référence à la source (src) et à la destination (target) sont également incluses.intermediary: systèmes par lesquels transitent les événements, comme un serveur proxy ou un relais SMTP.observer: systèmes tels que les renifleurs de paquets qui surveillent passivement le trafic.
Exemples de recherches UDM
Cette section fournit des exemples de recherches UDM qui illustrent une partie de la syntaxe, des fonctionnalités et des capacités de la recherche UDM de base.
Exemple : rechercher les connexions Microsoft Windows 4624 réussies
La recherche suivante liste les événements de connexion réussie Microsoft Windows 4624, ainsi que la date de génération des événements, en fonction de deux champs UDM seulement :
metadata.event_type = "USER_LOGIN" AND metadata.product_event_type = "4624"
Exemple : rechercher toutes les connexions réussies
La recherche suivante liste tous les événements de connexion réussis, quels que soient le fournisseur ou l'application :
metadata.event_type = "USER_LOGIN" AND security_result.action = "ALLOW" AND
target.user.userid != "SYSTEM" AND target.user.userid != /.*$/
Exemple : rechercher les connexions utilisateur réussies
L'exemple suivant montre comment rechercher userid "fkolzig" et déterminer quand l'utilisateur avec cet ID d'utilisateur s'est connecté. Vous pouvez effectuer cette recherche à l'aide de la section "Cible". La section "Cible" comprend des sous-sections et des champs décrivant la cible. Par exemple, la cible dans ce cas est un utilisateur et possède un certain nombre d'attributs associés, mais la cible peut également être un fichier, un paramètre de registre ou un composant. Cet exemple recherche "fkolzig" à l'aide du champ target.user.userid.
metadata.event_type = "USER_LOGIN" AND metadata.product_event_type = "4624" AND
target.user.userid = "fkolzig"
Exemple : rechercher dans les données de votre réseau
L'exemple suivant recherche dans les données réseau les événements RDP avec un target.port de 3389 et un principal.ip de 35.235.240.5.
Il inclut également un champ UDM de la section "Réseau", ainsi que le sens des données (network.direction).
metadata.product_event_type = "3" AND target.port = 3389 AND network.direction =
"OUTBOUND" and principal.ip = "35.235.240.5"
Exemple : rechercher un processus spécifique
Pour examiner les processus créés sur vos serveurs, recherchez les instances de la commande net.exe et recherchez ce fichier spécifique dans son chemin d'accès prévu. Le champ que vous recherchez est target.process.file.full_path. Pour cette recherche, vous devez inclure la commande spécifique émise dans le champ target.process.command_line. Vous pouvez également ajouter un champ dans la section "À propos" qui correspond à la description du code d'événement Microsoft Sysmon 1 (ProcessCreate).
Voici la recherche UDM :
metadata.product_event_type = "1" AND target.process.file.full_path =
"C:\Windows\System32\net.exe"
Vous pouvez également ajouter les champs de recherche UDM suivants :
principal.user.userid: identifie l'utilisateur qui émet la commande.principal.process.file.md5: identifiez le hachage MD5.principal.process.command_line: ligne de commande.
Exemple : rechercher les connexions utilisateur réussies associées à un service spécifique
L'exemple suivant recherche les connexions des utilisateurs (metadata.event_type est USER_LOGIN) associés au service marketing (target.user.department est marketing) de votre entreprise. Bien que target.user.department ne soit pas directement lié aux événements de connexion des utilisateurs, il est toujours présent dans les données LDAP ingérées concernant vos utilisateurs.
metadata.event_type = "USER_LOGIN" AND target.user.department = "Marketing"
Objets logiques : événement et entité
Le schéma UDM décrit tous les attributs disponibles qui stockent des données. Chaque enregistrement UDM indique s'il décrit un événement ou une entité. Les données sont stockées dans différents champs selon que l'enregistrement décrit un événement ou une entité, et selon la valeur définie dans le champ metadata.event_type ou metadata.entity_type.
- Événement UDM : stocke les données d'une action qui s'est produite dans l'environnement. Le journal des événements d'origine décrit l'action telle qu'elle a été enregistrée par l'appareil, comme le pare-feu et le proxy Web.
- Entité UDM : représentation contextuelle d'éléments tels que les composants, les utilisateurs et les ressources de votre environnement. Elle est obtenue à partir d'une source de données source de vérité.
Vous trouverez ci-dessous deux représentations visuelles générales du modèle de données d'événement et du modèle de données d'entité.
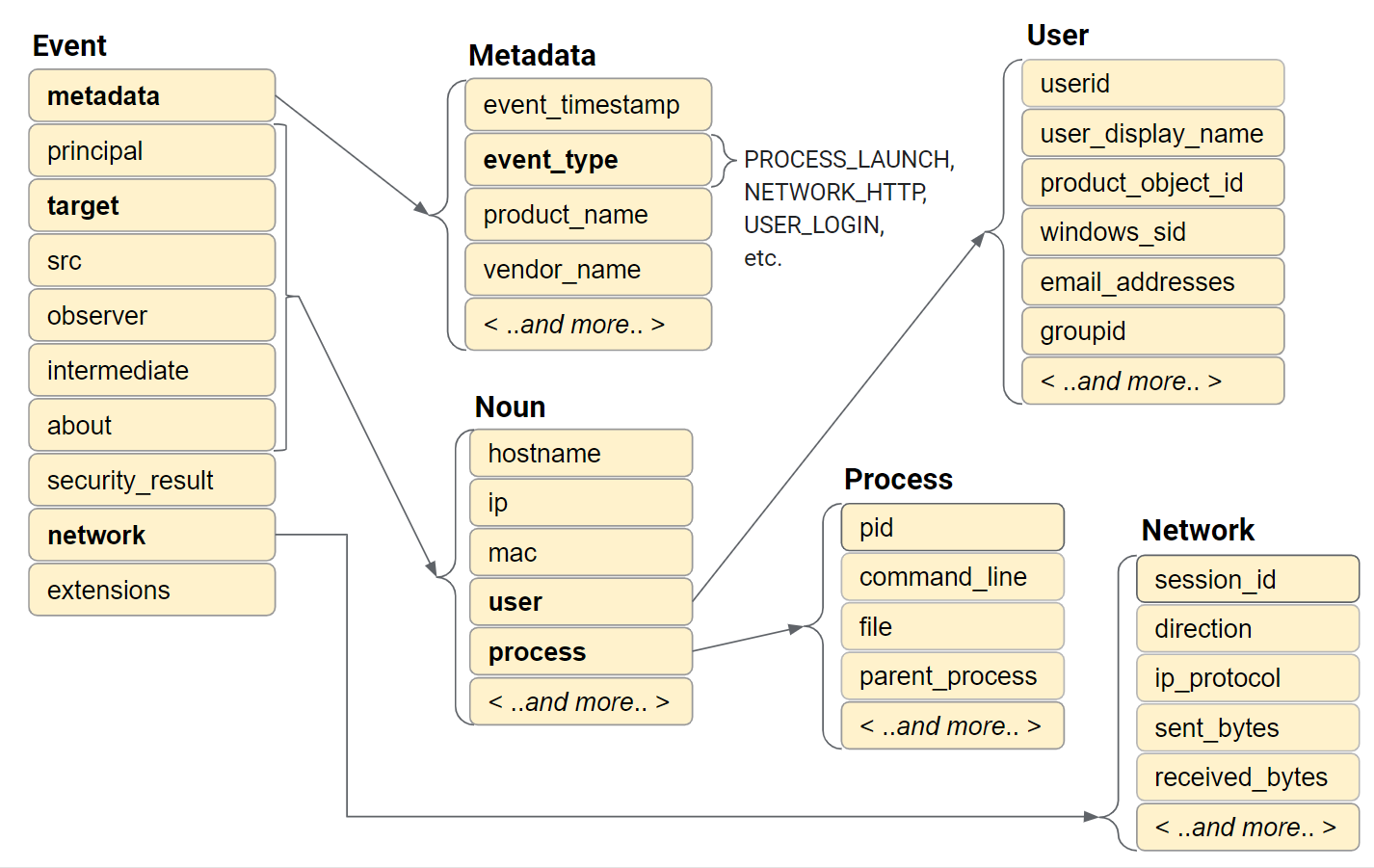
Figure : Modèle de données d'événement
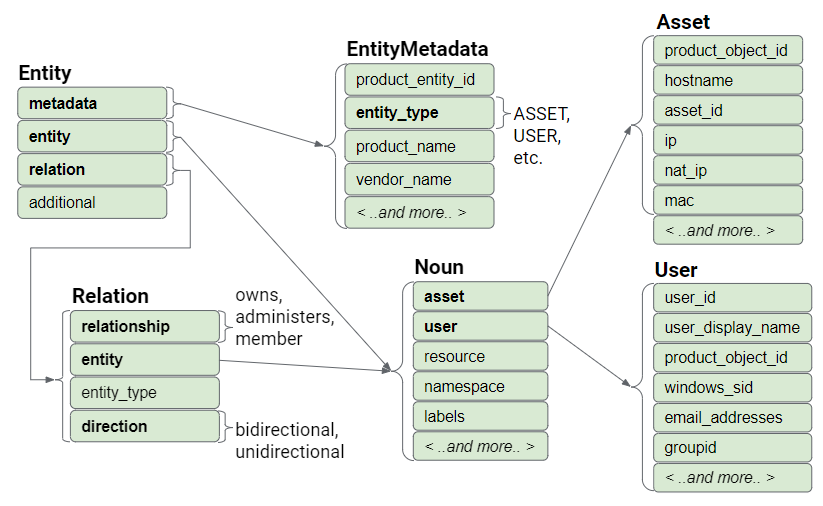
Figure : Modèle de données d'entité
Structure d'un événement UDM
L'événement UDM contient plusieurs sections qui stockent chacune un sous-ensemble des données d'un seul enregistrement. Voici les sections :
- métadonnées
- compte principal
- cible
- src
- observateur
- intermédiaire
- à propos de
- réseau
- security_result
extensions
Figure : Modèle de données d'événement
La section metadata stocke le code temporel, définit event_type et décrit l'appareil.
Les sections principal, target, src, observer et intermediary stockent des informations sur les objets impliqués dans l'événement. Un objet peut être un appareil, un utilisateur ou un processus. La plupart du temps, seule une partie de ces sections est utilisée. Les champs qui stockent les données sont déterminés par le type d'événement et le rôle que chaque objet joue dans l'événement.
La section Réseau stocke les informations liées à l'activité réseau, comme les communications par e-mail et celles liées au réseau.
- Données d'e-mails : informations figurant dans les champs
to,from,cc,bccet autres champs d'e-mails. - Données HTTP : par exemple,
method,referral_urletuseragent.
La section security_result stocke une action ou une classification enregistrée par un produit de sécurité, tel qu'un antivirus.
Les sections about et extensions stockent des informations supplémentaires sur les événements spécifiques aux fournisseurs qui ne sont pas capturées par les autres sections. La section extensions est un ensemble de paires clé/valeur au format libre.
Chaque événement UDM stocke les valeurs d'un événement de journal brut d'origine. En fonction du type d'événement, certains attributs sont obligatoires, tandis que d'autres sont facultatifs. Les attributs obligatoires et facultatifs sont déterminés par la valeur metadata.event_type. Google SecOps lit metadata.event_type et effectue la validation des champs spécifiques à ce type d'événement après la réception des journaux.
Si aucune donnée n'est stockée dans une section de l'enregistrement UDM (par exemple, la section "extensions"), cette section n'apparaît pas dans l'enregistrement UDM.
Champs de métadonnées
Cette section décrit les champs requis dans un événement UDM.
Champ event_timestamp
Les événements UDM doivent inclure des données pour metadata.event_timestamp, qui correspond au code temporel GMT de l'événement. La valeur doit être encodée à l'aide de l'une des normes suivantes : RFC 3339 ou Proto3 timestamp.
Les exemples suivants illustrent comment spécifier le code temporel au format RFC 3339, yyyy-mm-ddThh:mm:ss+hh:mm (année, mois, jour, heure, minute, seconde et décalage par rapport à l'heure UTC). Le décalage par rapport à l'heure UTC est de -8 heures, ce qui correspond à l'heure PST.
metadata {
"event_timestamp": "2019-09-10T20:32:31-08:00"
}
metadata {
event_timestamp: "2021-02-23T04:00:00.000Z"
}
Vous pouvez également spécifier la valeur au format epoch.
metadata {
event_timestamp: {
"seconds": 1588180305
}
}
Champ event_type
Le champ le plus important de l'événement UDM est metadata.event_type.
Cette valeur identifie le type d'action effectuée et est indépendante du fournisseur, du produit ou de la plate-forme. Par exemple, les valeurs PROCESS_OPEN, FILE_CREATION, USER_CREATION et NETWORK_DNS. Pour obtenir la liste complète, consultez le document Liste des champs UDM.
La valeur metadata.event_type détermine les champs obligatoires et facultatifs supplémentaires qui doivent être inclus dans l'enregistrement UDM. Pour savoir quels champs inclure pour chaque type d'événement, consultez le guide d'utilisation de l'UDM.
Attributs principal, target, src, intermediary, observer et about
Les attributs principal, target, src, intermediary et observer décrivent les composants impliqués dans l'événement. Chaque magasin contient des informations sur les objets impliqués dans l'activité, telles qu'enregistrées par le journal brut d'origine. Il peut s'agir de l'appareil ou de l'utilisateur qui a effectué l'activité, ou de l'appareil ou de l'utilisateur qui en est la cible. Il peut également décrire un dispositif de sécurité ayant observé l'activité, comme un proxy de messagerie ou un routeur réseau.
Voici les attributs les plus couramment utilisés :
principal: objet ayant effectué l'activité.src: objet qui lance l'activité, s'il est différent du principal.target: objet sur lequel l'action est effectuée.
Pour chaque type d'événement, au moins l'un de ces champs doit contenir des données.
Les champs auxiliaires sont les suivants :
intermediary: tout objet ayant servi d'intermédiaire lors de l'événement. Cela peut inclure des objets tels que des serveurs proxy et des serveurs de messagerie.observer: tout objet qui n'interagit pas directement avec le trafic en question. Il peut s'agir d'un scanner de failles ou d'un renifleur de paquets.about: tous les autres objets ayant joué un rôle dans l'événement (facultatif).
Attributs principaux
Représente l'entité ou l'appareil à l'origine de l'activité. Le principal doit inclure au moins un détail sur la machine (nom d'hôte, adresse MAC, adresse IP, identifiants spécifiques au produit comme un GUID de machine CrowdStrike) ou sur l'utilisateur (nom d'utilisateur, par exemple), et peut éventuellement inclure des détails sur le processus. Il ne doit inclure aucun des champs suivants : adresse e-mail, fichiers, clés ou valeurs de registre.
Si l'événement a lieu sur une seule machine, celle-ci est décrite uniquement dans l'attribut principal. Il n'est pas nécessaire de décrire la machine dans les attributs target ou src.
L'extrait de code JSON suivant montre comment l'attribut principal peut être renseigné.
"principal": {
"hostname": "jane_win10",
"asset_id" : "Sophos.AV:C070123456-ABCDE",
"ip" : "10.10.2.10",
"port" : 60671,
"user": { "userid" : "john.smith" }
}
Cet attribut décrit tout ce que l'on sait sur l'appareil et l'utilisateur qui ont été les principaux acteurs de l'événement. Cet exemple inclut l'adresse IP, le numéro de port et le nom d'hôte de l'appareil. Il inclut également un identifiant d'asset spécifique au fournisseur, Sophos, qui est un identifiant unique généré par le produit de sécurité tiers.
Attributs cibles
Représente un appareil cible référencé par l'événement ou un objet sur l'appareil cible. Par exemple, dans une connexion de pare-feu de l'appareil A à l'appareil B, l'appareil A est capturé en tant que principal et l'appareil B en tant que cible.
Dans le cas d'une injection de processus par le processus C dans le processus cible D, le processus C est le principal et le processus D est la cible.
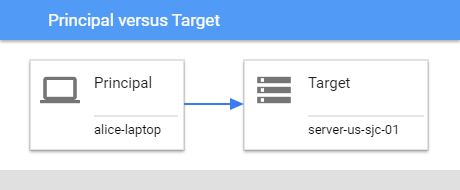
Figure : Principal par rapport à la cible
L'exemple suivant montre comment le champ cible peut être renseigné.
target {
ip: "192.0.2.31"
port: 80
}
Si des informations supplémentaires sont disponibles dans le journal brut d'origine, telles que le nom d'hôte, des adresses IP supplémentaires, des adresses MAC et des identifiants de ressources propriétaires, elles doivent également être incluses dans les champs "Cible" et "Principal".
Le principal et la cible peuvent représenter des acteurs sur la même machine. Par exemple, le processus A (principal) exécuté sur la machine X peut agir sur le processus B (cible) également sur la machine X.
Attribut src
Représente un objet source sur lequel l'utilisateur agit, ainsi que le contexte de l'appareil ou du processus pour l'objet source (la machine sur laquelle réside l'objet source). Par exemple, si l'utilisateur U copie le fichier A sur la machine X vers le fichier B sur la machine Y, le fichier A et la machine X seront spécifiés dans la partie "src" de l'événement UDM.
Attribut "intermediary"
Représente les détails d'un ou plusieurs appareils intermédiaires traitant l'activité décrite dans l'événement. Cela peut inclure des informations sur des appareils tels que les serveurs proxy et les serveurs de relais SMTP.
Attribut "observer"
Représente un appareil observateur qui n'est pas un intermédiaire direct, mais qui observe l'événement en question et en rend compte. Cela peut inclure un renifleur de paquets ou un outil d'analyse des failles basé sur le réseau.
L'attribut "about"
Ce magasin contient des informations sur un objet référencé par l'événement qui n'est pas décrit dans les champs "principal", "src", "target", "intermediary" ou "observer". Par exemple, il peut capturer les éléments suivants :
- Pièces jointes aux e-mails
- Domaines, URL ou adresses IP intégrés dans le corps d'un e-mail
- DLL chargées lors d'un événement PROCESS_LAUNCH.
Attribut "security_result"
Cette section contient des informations sur les risques et menaces de sécurité détectés par un système de sécurité, ainsi que sur les mesures prises pour les atténuer.
Voici les types d'informations qui seraient stockés dans l'attribut security_result :
- Un proxy de sécurité des e-mails a détecté une tentative d'hameçonnage (
security_result.category = MAIL_PHISHING) et a bloqué l'e-mail (security_result.action = BLOCK). - Un pare-feu proxy de sécurité des e-mails a détecté deux pièces jointes infectées (
security_result.category = SOFTWARE_MALICIOUS). Il les a mises en quarantaine et désinfectées (security_result.action = QUARANTINE or security_result.action = ALLOW_WITH_MODIFICATION), puis a transféré l'e-mail désinfecté. - Un système SSO autorise une connexion (
security_result.category = AUTH_VIOLATION) qui a été bloquée (security_result.action = BLOCK). - Un bac à sable de sécurité contre les logiciels malveillants a détecté un logiciel espion (
security_result.category = SOFTWARE_MALICIOUS) dans une pièce jointe cinq minutes après la distribution du fichier (security_result.action = ALLOW) à l'utilisateur dans sa boîte de réception.
L'attribut "Réseau"
Les attributs réseau stockent des données sur les événements liés au réseau et des détails sur les protocoles dans les sous-messages. Cela inclut l'activité, comme les e-mails envoyés et reçus, et les requêtes HTTP.
Attribut "extensions"
Les champs de cet attribut stockent des métadonnées supplémentaires sur l'événement enregistré dans le journal brut d'origine. Il peut contenir des informations sur les failles de sécurité ou des informations supplémentaires liées à l'authentification.
Structure d'une entité UDM
Un enregistrement d'entité UDM stocke des informations sur n'importe quelle entité d'une organisation.
Si metadata.entity_type est défini sur USER, l'enregistrement stocke des informations sur l'utilisateur sous l'attribut entity.user. Si metadata.entity_type est défini sur ASSET, l'enregistrement stocke des informations sur un composant, tel qu'un poste de travail, un ordinateur portable, un téléphone ou une machine virtuelle.
Figure : Modèle de données d'événement
Champs de métadonnées
Cette section contient les champs obligatoires dans une entité UDM, tels que :
collection_timestamp: date et heure de collecte de l'enregistrement.entity_type: type d'entité, tel qu'un composant, un utilisateur ou une ressource.
Attribut d'entité
Les champs de l'attribut d'entité stockent des informations sur l'entité spécifique, telles que le nom d'hôte et l'adresse IP s'il s'agit d'un composant, ou le windows_sid et l'adresse e-mail s'il s'agit d'un utilisateur. Notez que le nom du champ est entity, mais que le type de champ est un nom. Un nom est une structure de données couramment utilisée qui stocke des informations dans les entités et les événements.
- Si
metadata.entity_typeest défini sur USER, les données sont stockées sous l'attributentity.user. - Si
metadata.entity_typeest défini sur ASSET, les données sont stockées sous l'attributentity.asset.
Attribut de relation
Les champs de l'attribut "relation" stockent des informations sur les autres entités auxquelles l'entité principale est associée. Par exemple, si l'entité principale est un utilisateur et que celui-ci a reçu un ordinateur portable. L'ordinateur portable est une entité associée.
Les informations sur l'ordinateur portable sont stockées sous forme d'enregistrement entity avec metadata.entity_type = ASSET. Les informations sur l'utilisateur sont stockées sous forme d'enregistrement entity avec metadata.entity_type = USER.
L'enregistrement de l'entité utilisateur capture également la relation entre l'utilisateur et l'ordinateur portable, à l'aide des champs de l'attribut relation. Le champ relation.relationship stocke la relation de l'utilisateur avec l'ordinateur portable, en particulier le fait que l'utilisateur possède l'ordinateur portable. Le champ relation.entity_type stocke la valeur ASSET, car l'ordinateur portable est un appareil.
Les champs de l'attribut relations.entity stockent des informations sur l'ordinateur portable, telles que le nom d'hôte et l'adresse MAC. Notez à nouveau que le nom du champ est entity et que le type de champ est un nom. Un nom est une structure de données couramment utilisée.
Les champs de l'attribut relation.entity stockent des informations sur l'ordinateur portable.
Le champ relation.direction stocke la directionnalité de la relation entre l'utilisateur et l'ordinateur portable, en particulier si la relation est bidirectionnelle ou unidirectionnelle.
Vous avez encore besoin d'aide ? Obtenez des réponses de membres de la communauté et de professionnels Google SecOps.