テーブル スキーマでネストされた列と繰り返し列を指定する
このページでは、BigQuery でネストされた列と繰り返し列を使用してテーブル スキーマを定義する方法について説明します。テーブル スキーマの概要については、スキーマの指定をご覧ください。
ネストされた列と繰り返し列を定義する
ネストされたデータのある列を作成するには、列のデータ型をスキーマで RECORD に設定します。RECORD には、GoogleSQL の STRUCT 型としてアクセスできます。STRUCT は順序付きフィールドのコンテナです。
繰り返しデータが含まれる列を作成するには、スキーマでモードを REPEATED に設定します。繰り返しフィールドには、GoogleSQL の ARRAY 型としてアクセスできます。
RECORD 列には REPEATED モードを設定できます。このモードは STRUCT 型の配列として表されます。また、レコード内のフィールドを繰り返すこともできます。これは、ARRAY を含む STRUCT として表されます。配列には、他の配列を直接格納することはできません。詳細については、ARRAY 型を宣言するをご覧ください。
制限事項
ネストされた繰り返しスキーマには、次の制限事項があります。
- スキーマにネストレベルが 15 を超える
RECORDタイプを含めることはできません。 - 列には、ネストされた
RECORD型(子レコード)を含めることができます。ネストの深さは最大 15 レベルに制限されます。この制限は、RECORDがスカラーか配列ベース(繰り返し)かに依存しません。
RECORD 型のRECORD 型には、UNION、INTERSECT、EXCEPT DISTINCT、SELECT DISTINCT との互換性がありません。
サンプル スキーマ
次の例は、ネストされたデータと繰り返しデータの例を示しています。このテーブルには人に関する情報が含まれています。このテーブルは、次のフィールドで構成されています。
idfirst_namelast_namedob(生年月日)addresses(ネストと繰り返しのあるフィールド)addresses.status(現在または以前)addresses.addressaddresses.cityaddresses.stateaddresses.zipaddresses.numberOfYears(居住年数)
JSON データファイルは次のようになります。addresses 列には値の配列が含まれています([ ] によって示される)。配列内の複数のアドレスは繰り返しデータです。各アドレス内の複数のフィールドは、ネストされたデータです。
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
このテーブルのスキーマは次のようになります。
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
サンプルでネストされた繰り返し列を指定する
以前のネストされた列と繰り返し列を持つ新しいテーブルを作成するには、次のいずれかのオプションを選択します。
コンソール
ネストされた繰り返し addresses 列を以下のとおり指定します。
Google Cloud コンソールで、[BigQuery] ページを開きます。
左側のペインで、 [エクスプローラ] をクリックします。

左側のペインが表示されていない場合は、 左側のペインを開くをクリックしてペインを開きます。
[エクスプローラ] ペインでプロジェクトを開き、[データセット] をクリックして、データセットを選択します。
詳細ペインで [ テーブルを作成] をクリックします。
[テーブルを作成] ページで、次の詳細を指定します。
- [ソース] の [テーブルの作成元] フィールドで、[空のテーブル] を選択します。
[送信先] セクションで、次の詳細を指定します。
- [データセット] で、テーブルを作成するデータセットを選択します。
- [テーブル] に、作成するテーブルの名前を入力します。
[スキーマ] で、(フィールドを追加)をクリックし、次のテーブル スキーマを入力します。
- [フィールド名] に「
addresses」と入力します。 - [タイプ] で [RECORD] を選択します。
- [モード] で [REPEATED] を選択します。
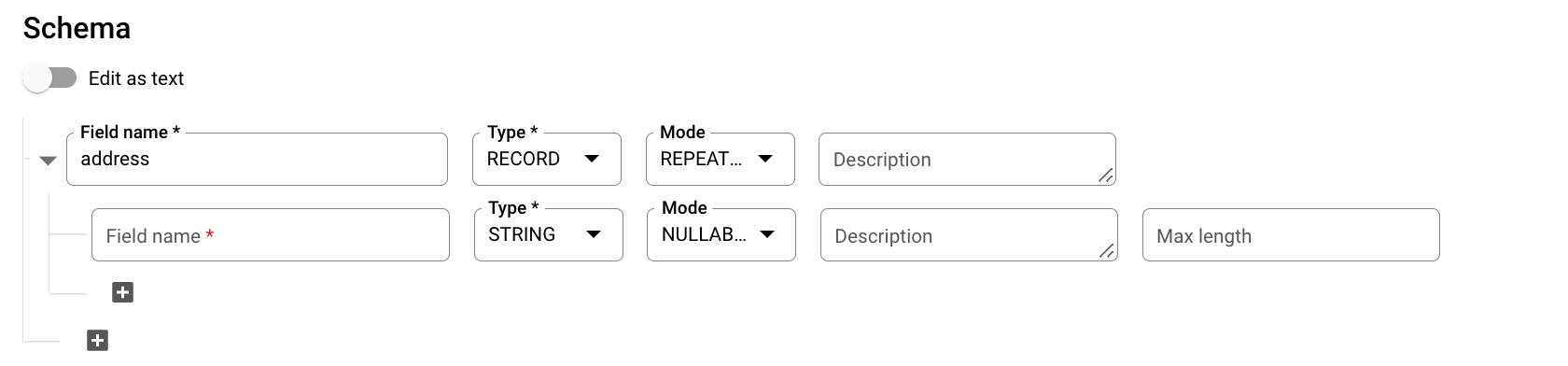
ネストされたフィールドには、次のフィールドを指定します。
- [フィールド名] フィールドに「
status」と入力します。 - [タイプ] で [STRING] を選択します。
- [モード] の値は [NULLABLE] のままにします。
(フィールドを追加)☆をクリックして、次のフィールドを追加します。
フィールド名 型 モード addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
また、[テキストとして編集] をクリックして、スキーマを JSON 配列として指定する方法もあります。
- [フィールド名] フィールドに「
- [フィールド名] に「
SQL
CREATE TABLE ステートメントを使用します。column オプションを使用してスキーマを指定します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
[実行] をクリックします。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
bq
JSON スキーマ ファイルでネストされた繰り返し addresses 列を指定するには、テキスト エディタを使用して新しいファイルを作成します。上のサンプル スキーマ定義を貼り付けます。
JSON スキーマ ファイルを作成したら、bq コマンドライン ツールを使用してそのファイルを提供できます。詳細については、JSON スキーマ ファイルの使用をご覧ください。
Go
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Go の設定手順を完了してください。詳細については、BigQuery Go API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Node.js の設定手順を完了してください。詳細については、BigQuery Node.js API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Python の設定手順を完了してください。詳細については、BigQuery Python API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
サンプルでネストされた列にデータを挿入する
次のクエリを使用して、RECORD データ型列を含むテーブルに、ネストされたデータレコードを挿入します。
例 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
例 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
ネストされた列と繰り返し列に対してクエリを実行する
特定の位置にある ARRAY の値を選択するには、配列添字演算子を使用します。STRUCT の要素にアクセスするには、ドット演算子を使用します。次の例では、addresses フィールドにリストされている名前、姓、最初の住所を選択します。
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
結果は次のようになります。
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
ARRAY のすべての要素を抽出するには、UNNEST 演算子と CROSS JOIN を使用します。次の例では、ニューヨーク以外のすべての住所に対応する名前、姓、住所を選択します。
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
結果は次のようになります。
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
ネストされた列と繰り返し列を変更する
ネストされた列やネストされた繰り返し列をテーブルのスキーマ定義に追加した後、他の型の列と同じように列を変更できます。BigQuery は、ネストされた新しいフィールドのレコードへの追加や、ネストされたフィールドのモードの緩和など、複数のスキーマ変更をネイティブにサポートしています。詳細については、テーブル スキーマの変更をご覧ください。
ネストされた列と繰り返し列を使用するタイミング
BigQuery は非正規化データに最適です。スタースキーマやスノーフレーク スキーマなどのリレーショナル スキーマを保存するのではなく、データを非正規化して、ネストされた列と繰り返し列を利用します。ネストされた列と繰り返し列は、リレーショナル(正規化)スキーマを維持することによるパフォーマンスへの影響なしで、リレーションシップを維持できます。
たとえば、図書館の書籍の追跡に使用されるリレーショナル データベースでは、すべての著者情報が別の表に保管されている可能性があります。author_id などのキーは、書籍を著者にリンクするために使用されます。
BigQuery では、別の著者テーブルを作成せずに書籍と著者の関係を維持できます。代わりに、著者の列を作成し、著者の名、姓、生年月日などのフィールドを入れ子にします。書籍に複数の著者がいる場合は、ネストされた著者列を繰り返すことができます。
次のテーブル mydataset.books があるとします。
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
また、次のテーブル mydataset.authors には、各著者 ID の完全な情報が含まれています。
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
テーブルが大きい場合は、定期的にテーブルを結合するとリソースを大量に消費する可能性があります。状況によっては、すべての情報を含む単一のテーブルを作成するほうが効果的な場合があります。
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
結果のテーブルは次のようになります。
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
BigQuery では、JSON ファイル、Avro ファイル、Firestore エクスポート ファイル、Datastore エクスポート ファイルなど、オブジェクトベースのスキーマをサポートするソース形式からネストされたデータと繰り返しデータを読み込むことができます。
テーブル内の重複レコードの重複を除去する
次のクエリでは row_number() 関数を使用して、使用例で last_name と first_name に同じ値を持つ重複レコードを特定し、dob で並べ替えます。
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
テーブルのセキュリティ
BigQuery でテーブルへのアクセスを制御するには、IAM を使用してリソースへのアクセスを制御するをご覧ください。
次のステップ
- ネストされた列と繰り返し列を使用して行を挿入および更新するには、データ操作言語の構文をご覧ください。