このチュートリアルでは、多変量時系列モデルを使用して、複数の入力特徴の過去の値に基づいて、特定の列の将来の値を予測する方法について説明します。
このチュートリアルでは、単一の時系列を予測します。予測値は、入力データの各時点に対して 1 回ずつ計算されます。
このチュートリアルでは、bigquery-public-data.epa_historical_air_quality 一般公開データセットのデータを使用します。このデータセットには、米国の複数の都市から毎日収集された粒子状物質(PM2.5)、気温、風速に関する情報が含まれています。
データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。
[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。使用可能なパラメータの一覧については、bq mk --dataset コマンドのリファレンスをご覧ください。
データの場所が
USに設定され、BigQuery ML tutorial datasetという説明の付いた、bqml_tutorialという名前のデータセットを作成します。bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
このコマンドでは、
--datasetフラグの代わりに-dショートカットを使用しています。-dと--datasetを省略した場合、このコマンドはデフォルトでデータセットを作成します。データセットが作成されたことを確認します。
bq ls
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
入力データテーブルを作成する
モデルのトレーニングと評価に使用できるデータのテーブルを作成します。このテーブルは、bigquery-public-data.epa_historical_air_quality データセット内の複数のテーブルの列を結合して、日次データの天気データを提供します。また、モデルの入力変数として使用する次の列も作成します。
date: 観測日pm25: 各日の PM2.5 の平均値wind_speed: 各日の平均風速temperature: 各日の最高気温
次の GoogleSQL クエリでは、FROM bigquery-public-data.epa_historical_air_quality.*_daily_summary 句で epa_historical_air_quality データセット内の *_daily_summary テーブルに対してクエリを実行しています。これらのテーブルはパーティション分割テーブルです。
入力データテーブルを作成するには、次の操作を行います。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE TABLE `bqml_tutorial.seattle_air_quality_daily` AS WITH pm25_daily AS ( SELECT avg(arithmetic_mean) AS pm25, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass' GROUP BY date_local ), wind_speed_daily AS ( SELECT avg(arithmetic_mean) AS wind_speed, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.wind_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant' GROUP BY date_local ), temperature_daily AS ( SELECT avg(first_max_value) AS temperature, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.temperature_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature' GROUP BY date_local ) SELECT pm25_daily.date AS date, pm25, wind_speed, temperature FROM pm25_daily JOIN wind_speed_daily USING (date) JOIN temperature_daily USING (date);
入力データを可視化する
モデルを作成する前に、必要に応じて入力時系列データを可視化して分布を把握できます。これは、Looker Studio を使用して行います。
時系列データを可視化する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`;
クエリが完了したら、[データを探索] > [Looker Studio で調べる] をクリックします。Looker Studio が新しいタブで開きます。新しいタブで次の操作を行います。
Looker Studio で、[挿入] > [期間グラフ] をクリックします。
[グラフ] ペインで、[設定] タブを選択します。
[指標] セクションで、pm25、temperature、wind_speed の各フィールドを追加し、デフォルトの指標である [レコード数] を削除します。作成されたグラフは次のようになります。
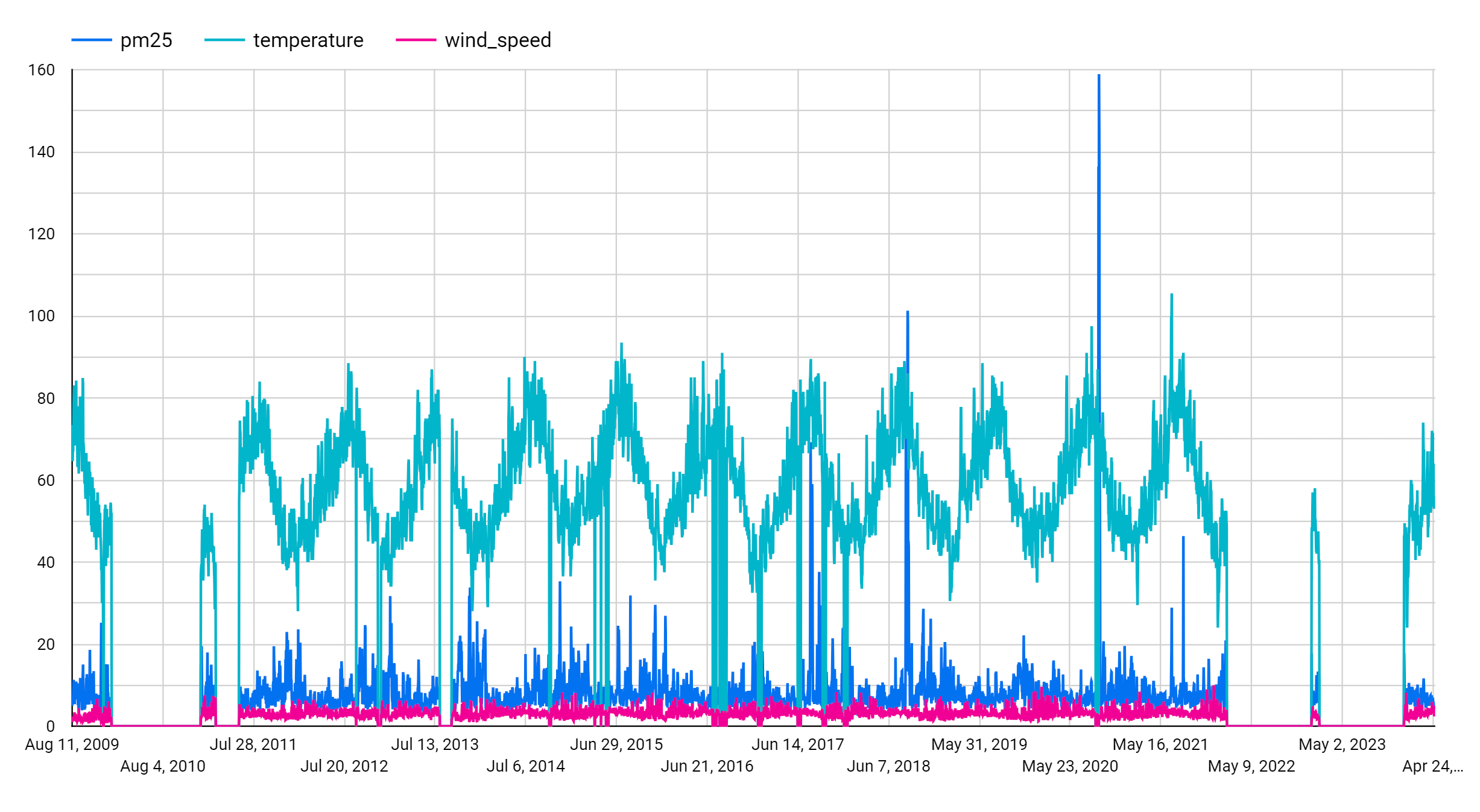
グラフを見ると、入力時系列には週ごとの季節パターンがあることがわかります。
時系列モデルを作成する
pm25、wind_speed、temperature 列の値を入力変数として使用し、pm25 列で表される粒子状物質の値を予測する時系列モデルを作成します。2012 年 1 月 1 日から 2020 年 12 月 31 日までに収集されたデータを選択し、bqml_tutorial.seattle_air_quality_daily テーブルの大気質データでモデルをトレーニングします。
次のクエリでは、OPTIONS(model_type='ARIMA_PLUS_XREG',
time_series_timestamp_col='date', ...) 句は、外部リグレッサー モデルの ARIMA を作成することを示します。CREATE MODEL ステートメントの auto_arima オプションはデフォルトで TRUE であるため、auto.ARIMA アルゴリズムによってモデルのハイパーパラメータが自動的にチューニングされます。アルゴリズムが多数の候補モデルを学習し、Akaike information criterion(AIC)が最も低い最適なモデルを選択します。CREATE MODEL ステートメントの data_frequency オプションはデフォルトで AUTO_FREQUENCY に設定されているため、トレーニング プロセスでは入力時系列のデータ頻度が自動的に推定されます。
次の手順でモデルを作成します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
CREATE OR REPLACE MODEL `bqml_tutorial.seattle_pm25_xreg_model` OPTIONS ( MODEL_TYPE = 'ARIMA_PLUS_XREG', time_series_timestamp_col = 'date', # Identifies the column that contains time points time_series_data_col = 'pm25') # Identifies the column to forecast AS SELECT date, # The column that contains time points pm25, # The column to forecast temperature, # Temperature input to use in forecasting wind_speed # Wind speed input to use in forecasting FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31');
クエリが完了するまでに約 20 秒かかります。完了後、
seattle_pm25_xreg_modelモデルにアクセスできます。クエリはCREATE MODELステートメントを使用してモデルを作成するため、クエリの結果は表示されません。
候補モデルを評価する
ML.ARIMA_EVALUATE 関数を使用して時系列モデルを評価します。ML.ARIMA_EVALUATE 関数は、自動ハイパーパラメータ チューニング プロセス中に評価されたすべての候補モデルの評価指標を表示します。
次の手順でモデルを評価します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
結果は次のようになります。

non_seasonal_p、non_seasonal_d、non_seasonal_q、has_driftの出力列は、トレーニング パイプラインの ARIMA モデルを定義します。log_likelihood、AIC、variance出力列は、ARIMA モデルの適合プロセスに関連するものです。auto.ARIMAアルゴリズムは KPSS テストを使用して、non_seasonal_dの最適値を決定します。この場合は1になります。non_seasonal_dが1の場合、auto.ARIMAアルゴリズムは 42 個の ARIMA 候補モデルを並行してトレーニングします。この例では、42 個の候補モデルがすべて有効であるため、出力には 42 行(ARIMA 候補モデルごとに 1 行)が含まれます。一部のモデルが無効な場合は、出力から除外されます。これらの候補モデルは、AIC の昇順で返されます。最初の行のモデルは AIC が最も低く、最適なモデルとみなされます。この最適モデルが最終モデルとして保存され、モデルでML.FORECASTなどの関数を呼び出すときに使用されます。seasonal_periods列には、時系列データで識別された季節パターンに関する情報が含まれます。ARIMA モデリングとは関係がないため、すべての出力行で同じ値になります。週単位でのパターンが報告され、これは入力データを可視化した場合の結果と一致します。has_holiday_effect、has_spikes_and_dips、has_step_changes列には入力時系列データに関する情報が含まれ、ARIMA モデリングとは関係ありません。これらの列が返されるのは、CREATE MODELステートメントのdecompose_time_seriesオプションの値がTRUEであるためです。また、これらの列の値はすべての出力行で同じになります。error_message列には、auto.ARIMAの適合プロセス中に発生したエラーが表示されます。エラーの原因として考えられるのは、選択したnon_seasonal_p、non_seasonal_d、non_seasonal_q、has_drift列で時系列が安定しないことです。すべての候補モデルのエラー メッセージを取得するには、モデルの作成時にshow_all_candidate_modelsオプションをTRUEに設定します。出力列の詳細については、
ML.ARIMA_EVALUATE関数をご覧ください。
モデルの係数を調べる
ML.ARIMA_COEFFICIENTS 関数を使用して、時系列モデルの係数を調べます。
モデルの係数を取得する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.seattle_pm25_xreg_model`);
結果は次のようになります。
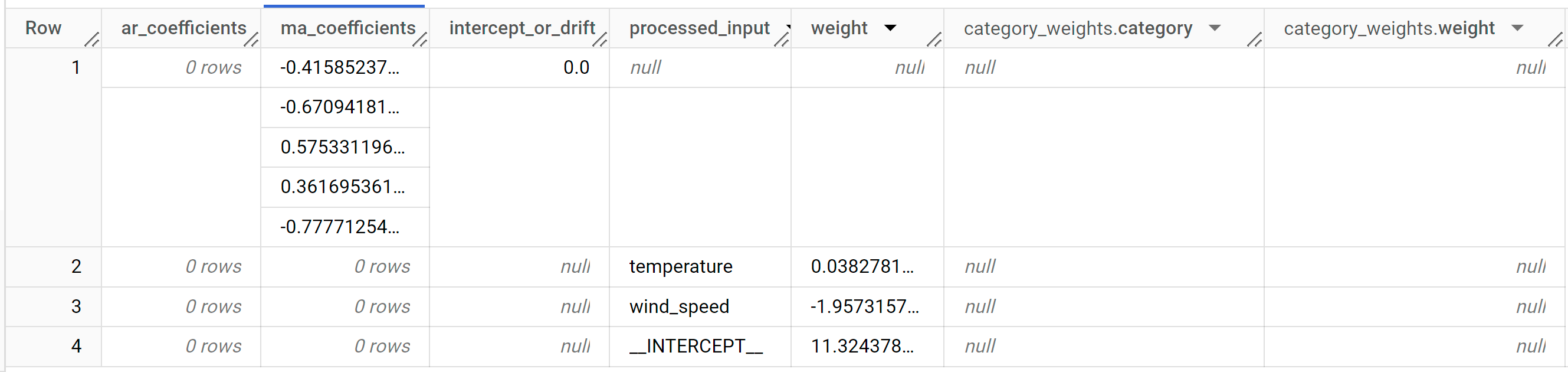
ar_coefficients出力列には、ARIMA モデルの自己回帰(AR)部分のモデル係数が表示されます。同様に、ma_coefficients出力列には、ARIMA モデルの移動平均(MA)部分のモデル係数が表示されます。どちらの列にも配列値が含まれ、長さはそれぞれnon_seasonal_pとnon_seasonal_qです。ML.ARIMA_EVALUATE関数の出力から、最適なモデルのnon_seasonal_p値は0、non_seasonal_q値は5となります。したがって、ML.ARIMA_COEFFICIENTSの出力では、ar_coefficients値は空の配列で、ma_coefficients値は 5 要素の配列です。intercept_or_drift値は、ARIMA モデルの定数項です。processed_input、weight、category_weightsの出力列には、線形回帰モデルの各特徴とインターセプトの重みが示されます。特徴が数値特徴である場合、重みはweight列にあります。特徴がカテゴリ特徴の場合、category_weights値は構造体の値の配列です。各構造体の値には、特定のカテゴリの名前と重みが含まれます。出力列の詳細については、
ML.ARIMA_COEFFICIENTS関数をご覧ください。
モデルを使用してデータを予測する
ML.FORECAST 関数を使用して、将来の時系列値を予測します。
次の GoogleSQL クエリの STRUCT(30 AS horizon, 0.8 AS confidence_level) 句は、30 個の将来の時点を予測し、信頼度レベル 80% の予測間隔を生成するように指示します。
次の手順でモデルを使用し、データを予測します。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
結果は次のようになります。
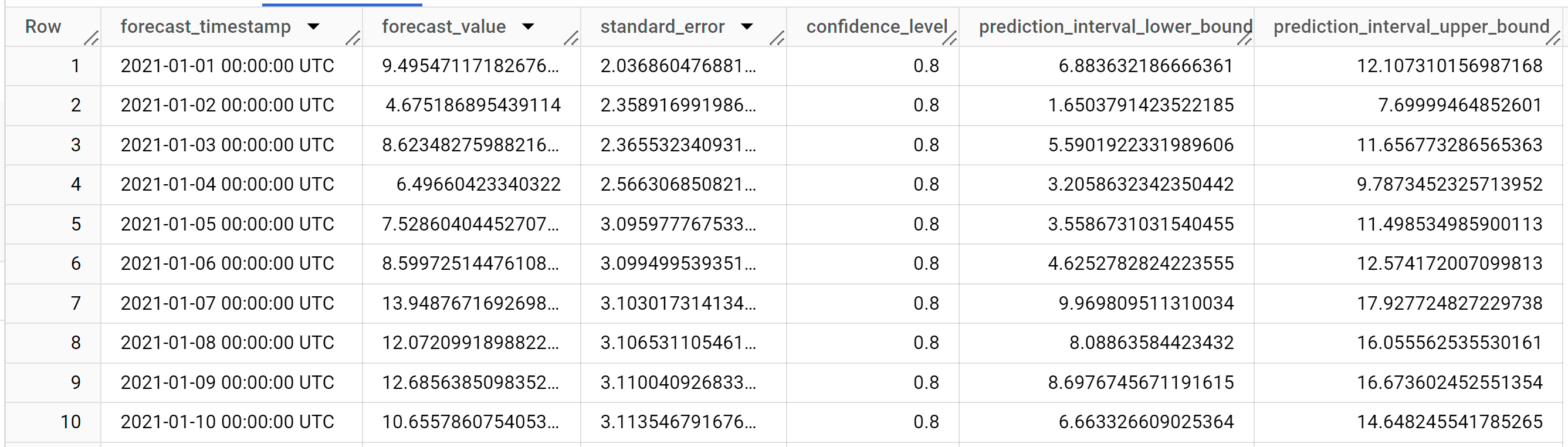
出力行は、
forecast_timestamp列の値で時系列順に並べ替えられます。時系列予測では、prediction_interval_lower_bound列とprediction_interval_upper_bound列の値で表される予測間隔は、forecast_value列の値と同じくらい重要です。forecast_value値は予測間隔の中間点です。予測間隔は、standard_error列とconfidence_level列の値によって異なります。出力列の詳細については、
ML.FORECAST関数をご覧ください。
予測の精度を評価する
ML.EVALUATE 関数を使用して、モデルの予測精度を評価します。
次の GoogleSQL クエリでは、2 番目の SELECT ステートメントで将来の特徴を含むデータを提供します。このデータは、実際のデータと比較して将来の値を予測するために使用されます。
モデルの精度を評価する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.EVALUATE( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, ( SELECT date, pm25, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ), STRUCT( TRUE AS perform_aggregation, 30 AS horizon));
結果は次のようになります。

出力列の詳細については、
ML.EVALUATE関数をご覧ください。
予測結果を説明する
ML.EXPLAIN_FORECAST 関数を使用すると、予測データに加えて説明可能性の指標を取得できます。ML.EXPLAIN_FORECAST 関数は、将来の時系列値を予測し、時系列の個別のコンポーネントをすべて返します。
ML.FORECAST 関数と同様に、ML.EXPLAIN_FORECAST 関数で使用される STRUCT(30 AS horizon, 0.8 AS confidence_level) 句は、30 個の将来の時点を予測し、信頼度 80% の予測間隔を生成するように指示します。
モデルの結果を説明する手順は次のとおりです。
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタに次のクエリを貼り付け、[実行] をクリックします。
SELECT * FROM ML.EXPLAIN_FORECAST( MODEL `bqml_tutorial.seattle_pm25_xreg_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level), ( SELECT date, temperature, wind_speed FROM `bqml_tutorial.seattle_air_quality_daily` WHERE date > DATE('2020-12-31') ));
結果は次のようになります。
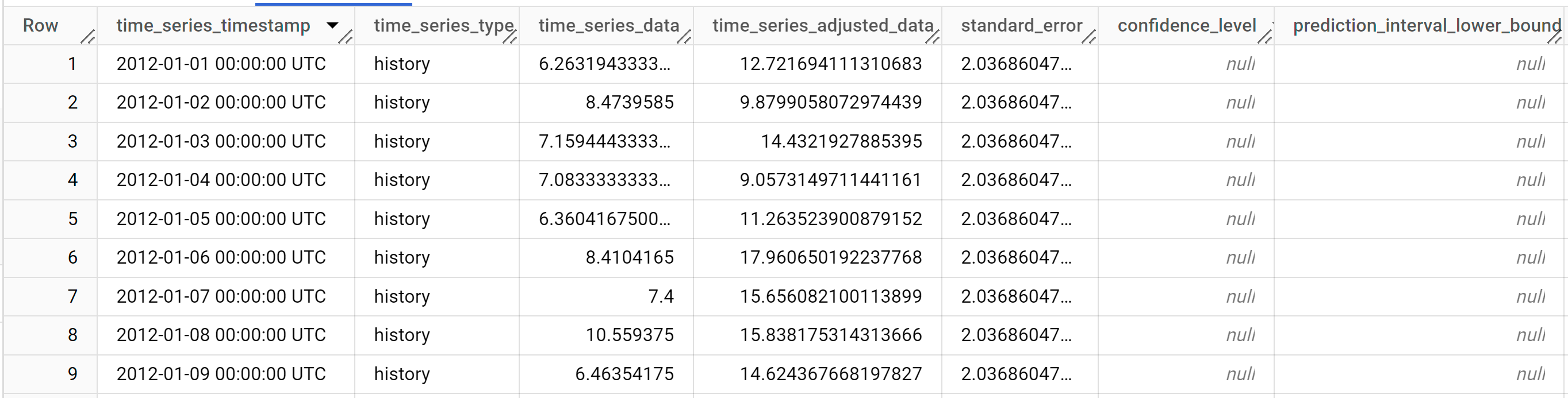
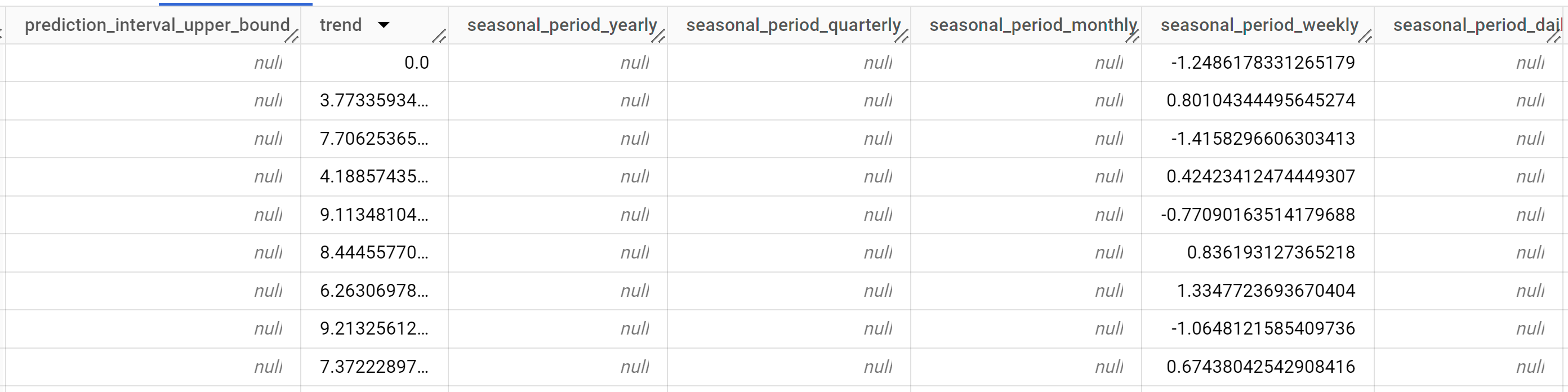
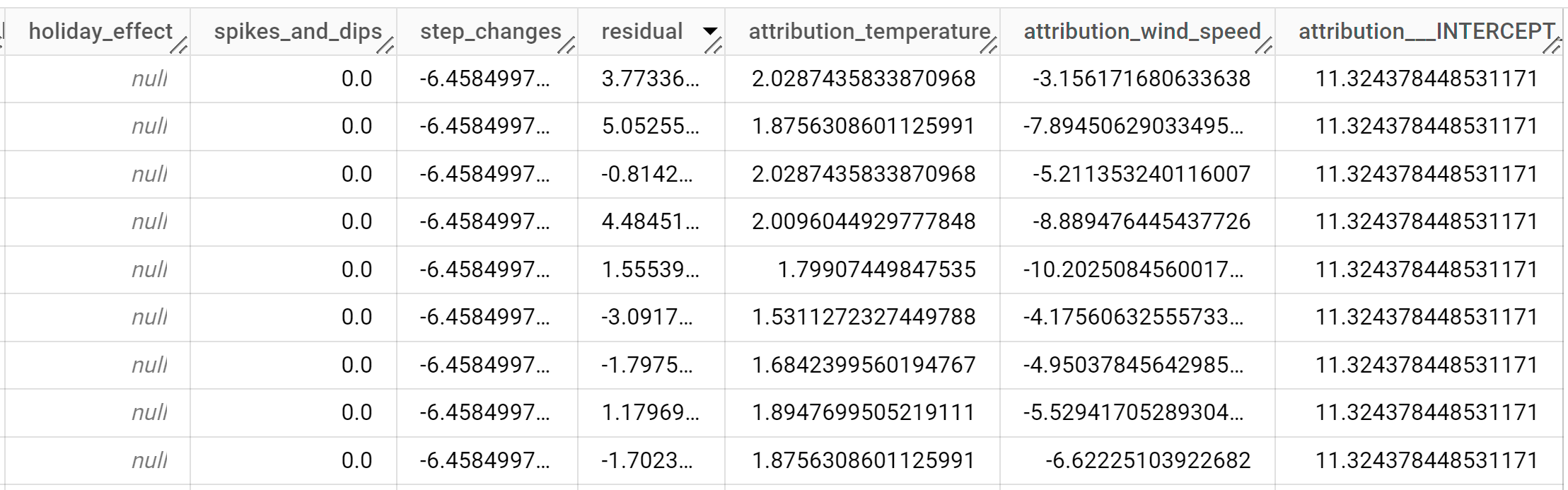
出力行は、
time_series_timestamp列の値で時系列順に表示されます。出力列の詳細については、
ML.EXPLAIN_FORECAST関数をご覧ください。