BigQuery의 Apache Iceberg용 BigLake 테이블
BigQuery의 Apache Iceberg용 BigLake 테이블(이하 BigQuery의 BigLake Iceberg 테이블)은 Google Cloud에서 개방형 형식의 레이크하우스를 빌드하기 위한 기반을 제공합니다. BigQuery의 BigLake Iceberg 테이블은 표준 BigQuery 테이블과 동일한 완전 관리형 환경을 제공하지만 고객 소유 스토리지 버킷에 데이터를 저장합니다. BigQuery의 BigLake Iceberg 테이블은 단일 데이터 사본에서 오픈소스 및 서드 파티 컴퓨팅 엔진과의 상호 운용성을 개선하기 위해 오픈 Iceberg 테이블 형식을 지원합니다.
BigQuery의 Apache Iceberg용 BigLake 테이블은 Apache Iceberg 외부 테이블과 다릅니다. BigQuery의 Apache Iceberg용 BigLake 테이블은 BigQuery에서 직접 수정할 수 있는 완전 관리형 테이블인 반면, Apache Iceberg 외부 테이블은 고객이 관리하며 BigQuery에서 읽기 전용 액세스를 제공합니다.
BigQuery의 BigLake Iceberg 테이블은 다음 기능을 지원합니다.
- GoogleSQL DML을 사용하는 테이블 변형
- Spark, Dataflow, 기타 엔진용 BigLake 커넥터를 통해 Storage Write API를 사용하여 통합 일괄 처리 및 높은 처리량 스트리밍
- 오픈소스 및 서드 파티 쿼리 엔진을 사용한 직접 쿼리 액세스를 위해 각 테이블 변형에 대한 Iceberg V2 스냅샷 내보내기 및 자동 새로고침
- 스키마 혁신: 필요에 따라 열을 추가, 삭제, 이름을 바꿀 수 있음. 이 기능을 사용하면 기존 열의 데이터 유형과 열 모드도 변경할 수 있습니다. 자세한 내용은 유형 변환 규칙을 참조하세요.
- 적응형 파일 크기 조정, 자동 클러스터링, 가비지 컬렉션, 메타데이터 최적화를 비롯한 자동 스토리지 최적화
- BigQuery의 이전 데이터 액세스를 위한 시간 이동
- 열 수준 보안 및 데이터 마스킹
- 멀티 문 트랜잭션(미리보기)
아키텍처
BigQuery의 BigLake Iceberg 테이블은 자체 클라우드 버킷에 있는 테이블에 BigQuery 리소스 관리의 편리성을 제공합니다. 제어하는 버킷에서 데이터를 이동하지 않고도 이러한 테이블에서 BigQuery 및 오픈소스 컴퓨팅 엔진을 사용할 수 있습니다. BigQuery에서 BigLake Iceberg 테이블을 사용하기 전에 Cloud Storage 버킷을 구성해야 합니다.
BigQuery의 BigLake Iceberg 테이블은 모든 Iceberg 데이터의 통합 런타임 메타 스토어로 BigLake metastore를 활용합니다. BigLake metastore는 여러 엔진의 메타데이터를 관리하기 위한 단일 정보 소스를 제공하며 엔진 상호 운용성을 지원합니다.
다음 다이어그램은 관리형 테이블 아키텍처를 대략적으로 보여줍니다.
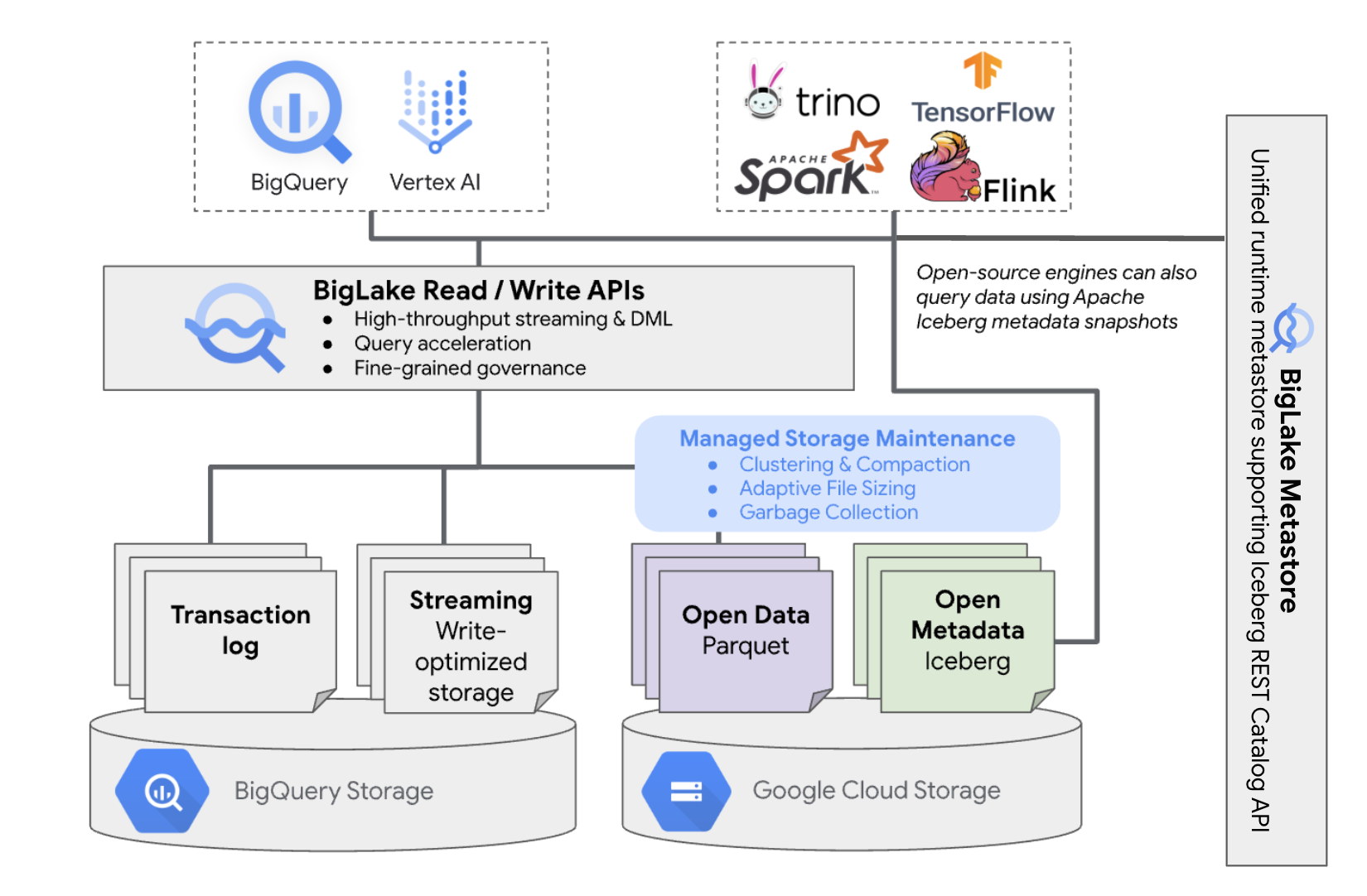
이 테이블 관리는 버킷에 다음과 같은 영향을 미칩니다.
- BigQuery는 쓰기 요청 및 DML 문, 스트리밍과 같은 백그라운드 스토리지 최적화에 응답하여 버킷에 새 데이터 파일을 만듭니다.
- BigQuery에서 관리형 테이블을 삭제하면 시간 이동 기간이 만료된 후 BigQuery에서 Cloud Storage의 연결된 데이터 파일을 가비지 수집합니다.
BigQuery에서 BigLake Iceberg 테이블을 만드는 방법은 BigQuery 테이블을 만드는 방법과 유사합니다. Cloud Storage에 개방형 형식으로 데이터를 저장하므로 다음을 수행해야 합니다.
WITH CONNECTION을 사용하여 Cloud 리소스 연결을 지정하여 BigLake가 Cloud Storage에 액세스할 수 있는 연결 사용자 인증 정보를 구성합니다.file_format = PARQUET문을 사용하여 데이터 스토리지의 파일 형식을PARQUET로 지정합니다.table_format = ICEBERG문을 사용하여 오픈소스 메타데이터 테이블 형식을ICEBERG로 지정합니다.
권장사항
BigQuery 외부에서 버킷에 파일을 직접 변경하거나 추가하면 데이터 손실 또는 복구할 수 없는 오류가 발생할 수 있습니다. 다음 표에서는 가능한 시나리오를 설명합니다.
| 작업 | 결과 | 예방 방법 |
|---|---|---|
| BigQuery 외부의 버킷에 새 파일을 추가합니다. | 데이터 손실: BigQuery 외부에 추가된 새 파일 또는 객체는 BigQuery에서 추적하지 않습니다. 추적되지 않은 파일은 백그라운드 가비지 컬렉션 프로세스에 의해 삭제됩니다. | BigQuery를 통해서만 데이터를 추가합니다. 이렇게 하면 BigQuery에서 파일을 추적하고 가비지 컬렉션을 방지할 수 있습니다. 실수로 추가 및 데이터 손실을 방지하려면 BigQuery의 BigLake Iceberg 테이블이 포함된 버킷에서 외부 도구 쓰기 권한을 제한하는 것이 좋습니다. |
| 비어 있지 않은 프리픽스에 BigQuery의 새 BigLake Iceberg 테이블을 만듭니다. | 데이터 손실: 기존 데이터는 BigQuery에서 추적하지 않으므로 이러한 파일은 추적되지 않는 것으로 간주되어 백그라운드 가비지 컬렉션 프로세스에 의해 삭제됩니다. | 빈 프리픽스에서만 BigQuery에 새 BigLake Iceberg 테이블을 만듭니다. |
| BigQuery 데이터 파일에서 BigLake Iceberg 테이블을 수정하거나 교체합니다. | 데이터 손실: 외부에서 수정하거나 교체하면 테이블이 일관성 검사를 통과하지 못하여 읽을 수 없게 됩니다. 테이블에 대한 쿼리가 실패합니다. 이 시점에서는 셀프 서비스로 복구할 수 없습니다. 데이터 복구 지원을 받으려면 지원팀에 문의하세요. |
BigQuery를 통해서만 데이터를 수정합니다. 이렇게 하면 BigQuery에서 파일을 추적하고 가비지 컬렉션을 방지할 수 있습니다. 실수로 추가 및 데이터 손실을 방지하려면 BigQuery의 BigLake Iceberg 테이블이 포함된 버킷에서 외부 도구 쓰기 권한을 제한하는 것이 좋습니다. |
| 동일하거나 중복되는 URI에 BigQuery의 BigLake Iceberg 테이블 2개를 만듭니다. | 데이터 손실: BigQuery는 BigQuery의 BigLake Iceberg 테이블의 동일한 URI 인스턴스를 브리징하지 않습니다. 각 테이블의 백그라운드 가비지 컬렉션 프로세스는 반대 테이블의 파일을 추적되지 않은 것으로 간주하고 삭제하여 데이터 손실이 발생합니다. | BigQuery의 각 BigLake Iceberg 테이블에 고유한 URI를 사용합니다. |
Cloud Storage 버킷 구성 권장사항
Cloud Storage 버킷의 구성과 BigLake와의 연결은 BigQuery의 BigLake Iceberg 테이블의 성능, 비용, 데이터 무결성, 보안, 거버넌스에 직접적인 영향을 미칩니다. 다음은 이 구성을 지원하는 권장사항입니다.
버킷이 BigQuery의 BigLake Iceberg 테이블 전용임을 명확하게 나타내는 이름을 선택합니다.
BigQuery 데이터 세트와 동일한 리전에 있는 단일 리전 Cloud Storage 버킷을 선택합니다. 이러한 조정은 데이터 전송 요금을 방지하여 성능을 개선하고 비용을 절감합니다.
기본적으로 Cloud Storage는 충분한 성능을 제공하는 Standard 스토리지 클래스에 데이터를 저장합니다. 데이터 스토리지 비용을 최적화하려면 자동 클래스를 사용 설정하여 스토리지 클래스 전환을 자동으로 관리하면 됩니다. 자동 클래스는 Standard Storage 클래스로 시작하여 스토리지 비용을 줄이기 위해 액세스하지 않는 객체를 점진적으로 사용량이 적은 클래스로 이동합니다. 객체를 다시 읽으면 Standard 클래스로 다시 이동됩니다.
균일한 버킷 수준 액세스 및 공개 액세스 방지를 사용 설정합니다.
필수 역할이 올바른 사용자 및 서비스 계정에 할당되었는지 확인합니다.
Cloud Storage 버킷에서 실수로 Iceberg 데이터가 삭제되거나 손상되지 않도록 조직의 대부분 사용자에 대한 쓰기 및 삭제 권한을 제한하세요.
PUT및DELETE요청을 거부하는 조건을 사용하여 버킷 권한 정책을 설정하면 됩니다. 단, 지정한 사용자는 제외됩니다.운영 투명성, 문제 해결, 데이터 액세스 모니터링을 위해 감사 로깅을 사용 설정합니다.
실수로 인한 삭제를 방지하려면 기본 소프트 삭제 정책 (7일 보관)을 유지합니다. 하지만 Iceberg 데이터가 삭제된 경우 객체를 수동으로 복원하지 말고 지원팀에 문의하세요. BigQuery 외부에서 추가되거나 수정된 객체는 BigQuery 메타데이터에서 추적하지 않기 때문입니다.
적응형 파일 크기 조정, 자동 클러스터링, 가비지 컬렉션은 자동으로 사용 설정되며 파일 성능과 비용을 최적화하는 데 도움이 됩니다.
다음 Cloud Storage 기능은 BigQuery의 BigLake Iceberg 테이블에서 지원되지 않으므로 사용하지 마세요.
- 계층적 네임스페이스
- 이중 리전 및 멀티 리전
- 객체 액세스 제어 목록 (ACL)
- 고객 제공 암호화 키
- 객체 버전 관리
- 객체 잠금
- 버킷 잠금
- BigQuery API 또는 bq 명령줄 도구를 사용하여 삭제된 객체 복원
다음 명령어를 사용하여 버킷을 만들어 이러한 권장사항을 구현할 수 있습니다.
gcloud storage buckets create gs://BUCKET_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --enable-autoclass \ --public-access-prevention \ --uniform-bucket-level-access
다음을 바꿉니다.
BUCKET_NAME: 새 버킷의 이름PROJECT_ID: 프로젝트의 IDLOCATION: 새 버킷의 위치
BigQuery 워크플로의 BigLake Iceberg 테이블
다음 섹션에서는 관리형 테이블을 만들고, 로드하고, 관리하고, 쿼리하는 방법을 설명합니다.
시작하기 전에
BigQuery에서 BigLake Iceberg 테이블을 만들고 사용하기 전에 저장소 버킷에 Cloud 리소스 연결을 설정했는지 확인하세요. 연결에는 다음 필수 역할 섹션에 지정된 대로 저장소 버킷에 대한 쓰기 권한이 필요합니다. 연결에 필요한 역할 및 권한에 대한 자세한 내용은 연결 관리를 참고하세요.
필요한 역할
BigQuery에서 프로젝트의 테이블을 관리하도록 허용하는 데 필요한 권한을 얻으려면 관리자에게 다음 IAM 역할을 부여해 달라고 요청하세요.
-
BigQuery에서 BigLake Iceberg 테이블을 만들려면 다음 단계를 따르세요.
-
프로젝트에 대한 BigQuery 데이터 소유자 (
roles/bigquery.dataOwner) -
프로젝트에 대한 BigQuery 연결 관리자 (
roles/bigquery.connectionAdmin)
-
프로젝트에 대한 BigQuery 데이터 소유자 (
-
BigQuery에서 BigLake Iceberg 테이블을 쿼리하려면 다음 단계를 따르세요.
-
프로젝트에 대한 BigQuery 데이터 뷰어 (
roles/bigquery.dataViewer) -
프로젝트에 대한 BigQuery 사용자 (
roles/bigquery.user)
-
프로젝트에 대한 BigQuery 데이터 뷰어 (
-
연결 서비스 계정이 Cloud Storage에서 데이터를 읽고 쓸 수 있도록 다음 역할을 부여합니다.
-
버킷에 대한 스토리지 객체 사용자 (
roles/storage.objectUser) -
버킷에 대한 스토리지 기존 버킷 리더 (
roles/storage.legacyBucketReader)
-
버킷에 대한 스토리지 객체 사용자 (
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
이러한 사전 정의된 역할에는 BigQuery에서 프로젝트의 테이블을 관리하도록 허용하는 데 필요한 권한이 포함되어 있습니다. 필요한 정확한 권한을 보려면 필수 권한 섹션을 펼치세요.
필수 권한
BigQuery에서 프로젝트의 테이블을 관리하도록 하려면 다음 권한이 필요합니다.
-
프로젝트에 대한
bigquery.connections.delegate권한 -
프로젝트에 대한
bigquery.jobs.create권한 -
프로젝트에 대한
bigquery.readsessions.create권한 -
프로젝트에 대한
bigquery.tables.create권한 -
프로젝트에 대한
bigquery.tables.get권한 -
프로젝트에 대한
bigquery.tables.getData권한 -
버킷에 대한
storage.buckets.get권한 -
버킷에 대한
storage.objects.create권한 -
버킷에 대한
storage.objects.delete권한 -
버킷에 대한
storage.objects.get권한 -
버킷에 대한
storage.objects.list권한
커스텀 역할이나 다른 사전 정의된 역할을 사용하여 이 권한을 부여받을 수도 있습니다.
BigQuery에서 BigLake Iceberg 테이블 만들기
BigQuery에서 BigLake Iceberg 테이블을 만들려면 다음 방법 중 하나를 선택합니다.
SQL
CREATE TABLE [PROJECT_ID.]DATASET_ID.TABLE_NAME ( COLUMN DATA_TYPE[, ...] ) CLUSTER BY CLUSTER_COLUMN_LIST WITH CONNECTION {CONNECTION_NAME | DEFAULT} OPTIONS ( file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'STORAGE_URI');
다음을 바꿉니다.
- PROJECT_ID: 데이터 세트가 포함된 프로젝트. 정의되지 않으면 명령어는 기본 프로젝트를 가정합니다.
- DATASET_ID: 기존 데이터 세트
- TABLE_NAME: 생성할 테이블의 이름
- DATA_TYPE: 열에 포함된 정보의 데이터 유형
- CLUSTER_COLUMN_LIST (선택사항): 최대 4개의 열을 포함하는 쉼표로 구분된 목록입니다. 최상위 수준의 반복되지 않는 열이어야 합니다.
CONNECTION_NAME: 연결의 이름. 예를 들면
myproject.us.myconnection입니다.기본 연결을 사용하려면 PROJECT_ID.REGION.CONNECTION_ID가 포함된 연결 문자열 대신
DEFAULT를 지정합니다.STORAGE_URI: 정규화된 Cloud Storage URI. 예를 들면
gs://mybucket/table입니다.
bq
bq --project_id=PROJECT_ID mk \ --table \ --file_format=PARQUET \ --table_format=ICEBERG \ --connection_id=CONNECTION_NAME \ --storage_uri=STORAGE_URI \ --schema=COLUMN_NAME:DATA_TYPE[, ...] \ --clustering_fields=CLUSTER_COLUMN_LIST \ DATASET_ID.MANAGED_TABLE_NAME
다음을 바꿉니다.
- PROJECT_ID: 데이터 세트가 포함된 프로젝트. 정의되지 않으면 명령어는 기본 프로젝트를 가정합니다.
- CONNECTION_NAME: 연결의 이름. 예를 들면
myproject.us.myconnection입니다. - STORAGE_URI: 정규화된 Cloud Storage URI.
예를 들면
gs://mybucket/table입니다. - COLUMN_NAME: 열 이름
- DATA_TYPE: 열에 포함된 정보의 데이터 유형
- CLUSTER_COLUMN_LIST (선택사항): 최대 4개의 열을 포함하는 쉼표로 구분된 목록입니다. 최상위 수준의 반복되지 않는 열이어야 합니다.
- DATASET_ID: 기존 데이터 세트의 ID입니다.
- MANAGED_TABLE_NAME: 생성할 테이블의 이름
API
다음과 같이 정의된 테이블 리소스를 사용하여 tables.insert 메서드를 호출합니다.
{ "tableReference": { "tableId": "TABLE_NAME" }, "biglakeConfiguration": { "connectionId": "CONNECTION_NAME", "fileFormat": "PARQUET", "tableFormat": "ICEBERG", "storageUri": "STORAGE_URI" }, "schema": { "fields": [ { "name": "COLUMN_NAME", "type": "DATA_TYPE" } [, ...] ] } }
다음을 바꿉니다.
- TABLE_NAME: 생성할 테이블의 이름
- CONNECTION_NAME: 연결의 이름. 예를 들면
myproject.us.myconnection입니다. - STORAGE_URI: 정규화된 Cloud Storage URI.
와일드 카드도 지원됩니다. 예를 들면
gs://mybucket/table입니다. - COLUMN_NAME: 열 이름
- DATA_TYPE: 열에 포함된 정보의 데이터 유형
BigQuery의 BigLake Iceberg 테이블로 데이터 가져오기
다음 섹션에서는 다양한 테이블 형식에서 BigQuery의 BigLake Iceberg 테이블로 데이터를 가져오는 방법을 설명합니다.
플랫 파일에서 표준 데이터 로드
BigQuery의 BigLake Iceberg 테이블은 BigQuery 로드 작업을 사용하여 외부 파일을 BigQuery의 BigLake Iceberg 테이블에 로드합니다. BigQuery에 기존 BigLake Iceberg 테이블이 있는 경우 bq load CLI 가이드 또는 LOAD SQL 가이드에 따라 외부 데이터를 로드합니다. 데이터를 로드하면 새 Parquet 파일이 STORAGE_URI/data 폴더에 쓰여집니다.
BigQuery에 기존 BigLake Iceberg 테이블 없이 이전 안내를 사용하면 대신 BigQuery 테이블이 생성됩니다.
관리형 테이블에 대한 일괄 로드의 도구별 예시는 다음을 참조하세요.
SQL
LOAD DATA INTO MANAGED_TABLE_NAME FROM FILES ( uris=['STORAGE_URI'], format='FILE_FORMAT');
다음을 바꿉니다.
- MANAGED_TABLE_NAME: BigQuery의 기존 BigLake Iceberg 테이블의 이름입니다.
- STORAGE_URI: 정규화된 Cloud Storage URI 또는 쉼표로 구분된 URI 목록.
와일드 카드도 지원됩니다. 예를 들면
gs://mybucket/table입니다. - FILE_FORMAT: 소스 테이블 형식. 지원되는 형식은
load_option_list의format행을 참조하세요.
bq
bq load \ --source_format=FILE_FORMAT \ MANAGED_TABLE \ STORAGE_URI
다음을 바꿉니다.
- FILE_FORMAT: 소스 테이블 형식. 지원되는 형식은
load_option_list의format행을 참조하세요. - MANAGED_TABLE_NAME: BigQuery의 기존 BigLake Iceberg 테이블의 이름입니다.
- STORAGE_URI: 정규화된 Cloud Storage URI 또는 쉼표로 구분된 URI 목록.
와일드 카드도 지원됩니다. 예를 들면
gs://mybucket/table입니다.
Hive 파티션을 나눈 파일에서 표준 로드
표준 BigQuery 로드 작업을 사용하여 BigQuery의 BigLake Iceberg 테이블에 Hive 파티션을 나눈 파일을 로드할 수 있습니다. 자세한 내용은 외부에서 파티션을 나눈 데이터 로드를 참조하세요.
Pub/Sub에서 스트리밍 데이터 로드
Pub/Sub BigQuery 구독을 사용하여 BigQuery의 BigLake Iceberg 테이블에 스트리밍 데이터를 로드할 수 있습니다.
BigQuery의 BigLake Iceberg 테이블에서 데이터 내보내기
다음 섹션에서는 BigQuery의 BigLake Iceberg 테이블에서 다양한 테이블 형식으로 데이터를 내보내는 방법을 설명합니다.
데이터를 플랫 형식으로 내보내기
BigQuery의 BigLake Iceberg 테이블을 플랫 형식으로 내보내려면 EXPORT DATA 문을 사용하고 대상 형식을 선택합니다. 자세한 내용은 데이터 내보내기를 참조하세요.
BigQuery 메타데이터 스냅샷에서 BigLake Iceberg 테이블 만들기
BigQuery 메타데이터 스냅샷에서 BigLake Iceberg 테이블을 만들려면 다음 단계를 따르세요.
EXPORT TABLE METADATASQL 문을 사용하여 메타데이터를 Iceberg V2 형식으로 내보냅니다.(선택사항) Iceberg 메타데이터 스냅샷 새로고침 예약 정해진 시간 간격에 따라 Iceberg 메타데이터 스냅샷을 새로고침하려면 예약 쿼리를 사용하세요.
선택사항: 프로젝트의 메타데이터 자동 새로고침을 사용 설정하여 각 테이블 변형 시 Iceberg 테이블 메타데이터 스냅샷을 자동으로 업데이트합니다. 메타데이터 자동 새로고침을 사용 설정하려면 bigquery-tables-for-apache-iceberg-help@google.com에 문의하세요. 새로고침 작업마다
EXPORT METADATA비용이 적용됩니다.
다음 예에서는 DDL 문 EXPORT TABLE METADATA FROM mydataset.test을 사용하여 My Scheduled Snapshot Refresh Query라는 예약된 쿼리를 만듭니다. DDL 문은 24시간마다 실행됩니다.
bq query \ --use_legacy_sql=false \ --display_name='My Scheduled Snapshot Refresh Query' \ --schedule='every 24 hours' \ 'EXPORT TABLE METADATA FROM mydataset.test'
BigQuery 메타데이터 스냅샷에서 BigLake Iceberg 테이블 보기
BigQuery 메타데이터 스냅샷에서 BigLake Iceberg 테이블을 새로고침하면 BigQuery의 BigLake Iceberg 테이블이 원래 생성된 Cloud Storage URI에서 스냅샷을 찾을 수 있습니다. /data 폴더에는 Parquet 파일 데이터 샤드가 포함되고 /metadata 폴더에는 BigQuery 메타데이터 스냅샷의 BigLake Iceberg 테이블이 포함됩니다.
SELECT table_name, REGEXP_EXTRACT(ddl, r"storage_uri\s*=\s*\"([^\"]+)\"") AS storage_uri FROM `mydataset`.INFORMATION_SCHEMA.TABLES;
mydataset 및 table_name은 실제 데이터 세트와 테이블의 자리표시자입니다.
Apache Spark를 사용하여 BigQuery에서 BigLake Iceberg 테이블 읽기
다음 샘플은 Apache Iceberg에서 Spark SQL을 사용하도록 환경을 설정한 다음, BigQuery에서 지정된 BigLake Iceberg 테이블에서 데이터를 가져오기 위한 쿼리를 실행합니다.
spark-sql \ --packages org.apache.iceberg:iceberg-spark-runtime-ICEBERG_VERSION_NUMBER \ --conf spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.CATALOG_NAME.type=hadoop \ --conf spark.sql.catalog.CATALOG_NAME.warehouse='BUCKET_PATH' \ # Query the table SELECT * FROM CATALOG_NAME.FOLDER_NAME;
다음을 바꿉니다.
- ICEBERG_VERSION_NUMBER: Apache Spark Iceberg 런타임의 현재 버전. Spark 출시 버전에서 최신 버전을 다운로드하세요.
- CATALOG_NAME: BigQuery에서 BigLake Iceberg 테이블을 참조할 카탈로그입니다.
- BUCKET_PATH: 테이블 파일이 포함된 버킷의 경로. 예를 들면
gs://mybucket/입니다. - FOLDER_NAME: 테이블 파일이 포함된 폴더.
예를 들면
myfolder입니다.
BigQuery에서 BigLake Iceberg 테이블 수정
BigQuery에서 BigLake Iceberg 테이블을 수정하려면 테이블 스키마 수정에 표시된 단계를 따르세요.
멀티 문 트랜잭션 사용
BigQuery의 BigLake Iceberg 테이블에 대한 멀티 문 트랜잭션에 액세스하려면 가입 양식을 작성하세요.
가격 책정
BigQuery의 BigLake Iceberg 테이블 가격은 스토리지, 스토리지 최적화, 쿼리 및 작업으로 구성됩니다.
스토리지
BigQuery의 BigLake Iceberg 테이블은 모든 데이터를 Cloud Storage에 저장합니다. 이전 테이블 데이터를 비롯하여 저장된 모든 데이터에 대해 요금이 청구됩니다. Cloud Storage 데이터 처리 및 전송 요금도 적용될 수 있습니다. BigQuery 또는 BigQuery Storage API를 통해 처리되는 작업의 경우 일부 Cloud Storage 작업 요금이 면제될 수 있습니다. BigQuery 전용 스토리지 요금은 없습니다. 자세한 내용은 Cloud Storage 가격 책정을 참고하세요.
스토리지 최적화
BigQuery의 BigLake Iceberg 테이블은 쿼리 성능을 최적화하고 스토리지 비용을 절감하기 위해 압축, 클러스터링, 가비지 수집, BigQuery 메타데이터 생성/새로고침을 비롯한 자동 테이블 관리를 실행합니다. BigLake 테이블 관리의 컴퓨팅 리소스 사용량은 시간 경과에 따라 초 단위로 데이터 컴퓨팅 단위 (DCU)로 청구됩니다. 자세한 내용은 BigQuery 가격 책정의 BigLake Iceberg 테이블을 참고하세요.
BigQuery Storage Write API를 통해 스트리밍하는 동안 실행되는 데이터 내보내기 작업은 Storage Write API 가격 책정에 포함되며 백그라운드 유지보수로 청구되지 않습니다. 자세한 내용은 데이터 수집 가격 책정을 참조하세요.
스토리지 최적화 및 EXPORT TABLE METADATA 사용량은 INFORMATION_SCHEMA.JOBS 뷰에 표시됩니다.
쿼리 및 작업
BigQuery 테이블과 마찬가지로 BigQuery 주문형 가격 책정을 사용하는 경우 쿼리 및 읽은 바이트 수(TiB당)에 따라 비용이 청구되며, BigQuery 용량 컴퓨팅 가격 책정을 사용하는 경우에는 슬롯 소비(슬롯 시간당)에 따라 비용이 청구됩니다.
BigQuery 가격 책정은 BigQuery Storage Read API 및 BigQuery Storage Write API에도 적용됩니다.
로드 및 내보내기 작업(예: EXPORT METADATA)은 Enterprise 버전 사용한 만큼만 지불 슬롯을 사용합니다.
이는 이러한 작업에 비용이 청구되지 않는 BigQuery 테이블과 다릅니다. Enterprise 또는 Enterprise Plus 슬롯이 있는 PIPELINE 예약을 사용할 수 있는 경우 로드 및 내보내기 작업은 이러한 예약 슬롯을 우선적으로 사용합니다.
제한사항
BigQuery의 BigLake Iceberg 테이블에는 다음과 같은 제한사항이 있습니다.
- BigQuery의 BigLake Iceberg 테이블은 이름 변경 작업 또는
ALTER TABLE RENAME TO문을 지원하지 않습니다. - BigQuery의 BigLake Iceberg 테이블은 테이블 복사본 또는
CREATE TABLE COPY문을 지원하지 않습니다. - BigQuery의 BigLake Iceberg 테이블은 테이블 클론 또는
CREATE TABLE CLONE문을 지원하지 않습니다. - BigQuery의 BigLake Iceberg 테이블은 테이블 스냅샷 또는
CREATE SNAPSHOT TABLE문을 지원하지 않습니다. - BigQuery의 BigLake Iceberg 테이블은 다음 테이블 스키마를 지원하지 않습니다.
- BigQuery의 BigLake Iceberg 테이블은 다음과 같은 스키마 개선 사례를 지원하지 않습니다.
NUMERIC에서FLOAT로 유형 강제 변환INT에서FLOAT로 유형 강제 변환- SQL DDL 문을 사용하여 기존
RECORD열에 새 중첩 필드 추가
- BigQuery의 BigLake Iceberg 테이블은 콘솔이나 API에서 쿼리할 때 0바이트 스토리지 크기를 표시합니다.
- BigQuery의 BigLake Iceberg 테이블은 구체화된 뷰를 지원하지 않습니다.
- BigQuery의 BigLake Iceberg 테이블은 승인된 뷰를 지원하지 않지만 열 수준 액세스 제어는 지원됩니다.
- BigQuery의 BigLake Iceberg 테이블은 변경 데이터 캡처 (CDC) 업데이트를 지원하지 않습니다.
- BigQuery의 BigLake Iceberg 테이블은 관리형 재해 복구를 지원하지 않습니다.
- BigQuery의 BigLake Iceberg 테이블은 파티셔닝을 지원하지 않습니다. 대안으로 클러스터링을 고려하세요.
- BigQuery의 BigLake Iceberg 테이블은 행 수준 보안을 지원하지 않습니다.
- BigQuery의 BigLake Iceberg 테이블은 장애 안전 기간을 지원하지 않습니다.
- BigQuery의 BigLake Iceberg 테이블은 추출 작업을 지원하지 않습니다.
INFORMATION_SCHEMA.TABLE_STORAGE뷰에는 BigQuery의 BigLake Iceberg 테이블이 포함되지 않습니다.- BigQuery의 BigLake Iceberg 테이블은 쿼리 결과 대상으로 지원되지 않습니다. 대신
AS query_statement인수로CREATE TABLE문을 사용하여 쿼리 결과 대상으로 테이블을 만들 수 있습니다. CREATE OR REPLACE는 BigQuery의 표준 테이블을 BigLake Iceberg 테이블로 또는 BigQuery의 BigLake Iceberg 테이블을 표준 테이블로 대체하는 것을 지원하지 않습니다.- 일괄 로드 및
LOAD DATA문은 BigQuery의 기존 BigLake Iceberg 테이블에 데이터를 추가하는 것만 지원합니다. - 일괄 로드 및
LOAD DATA문은 스키마 업데이트를 지원하지 않습니다. TRUNCATE TABLE는 BigQuery의 BigLake Iceberg 테이블을 지원하지 않습니다. 다음과 같은 두 가지 대안이 있습니다.CREATE OR REPLACE TABLE: 동일한 테이블 생성 옵션을 사용합니다.DELETE FROM테이블WHEREtrue
APPENDS테이블 값 함수 (TVF)는 BigQuery의 BigLake Iceberg 테이블을 지원하지 않습니다.- Iceberg 메타데이터에는 지난 90분 이내에 Storage Write API에 의해 BigQuery로 스트리밍된 데이터가 포함되지 않을 수 있습니다.
tabledata.list를 사용하는 레코드 기반 페이지로 구분된 액세스는 BigQuery의 BigLake Iceberg 테이블을 지원하지 않습니다.- BigQuery의 BigLake Iceberg 테이블은 연결된 데이터 세트를 지원하지 않습니다.
- BigQuery의 각 BigLake Iceberg 테이블에 대해 하나의 동시 변형 DML 문 (
UPDATE,DELETE,MERGE)만 실행됩니다. 추가 변형 DML 문은 큐에 추가됩니다.