쿼리 실행
이 문서에서는 BigQuery에서 쿼리를 실행하고 테스트 실행을 통해 수행 전 쿼리가 처리할 데이터 양을 파악하는 방법을 보여줍니다.
쿼리 유형
다음 쿼리 작업 유형 중 하나를 사용하여 BigQuery 데이터를 쿼리할 수 있습니다.
대화형 쿼리 작업. 기본적으로 BigQuery는 가능한 한 빨리 실행되도록 설계된 대화형 쿼리 작업으로 쿼리를 실행합니다.
일괄 쿼리 작업. 일괄 쿼리는 대화형 쿼리보다 우선순위가 낮습니다. 프로젝트나 예약에서 사용 가능한 모든 컴퓨팅 리소스를 사용하는 경우 일괄 쿼리는 큐에 추가되어 큐에 남아 있을 가능성이 높습니다. 일괄 쿼리가 실행되기 시작하면 대화형 쿼리와 동일하게 실행됩니다. 자세한 내용은 쿼리 큐를 참조하세요.
연속 쿼리 작업. 이러한 작업을 사용하면 쿼리가 연속적으로 실행되므로 BigQuery에서 수신되는 데이터를 실시간으로 분석한 후 결과를 BigQuery 테이블에 쓰거나 결과를 Bigtable 또는 Pub/Sub로 내보낼 수 있습니다. 이 기능을 사용하여 통계를 만들어 즉시 조치, 실시간 머신러닝(ML) 추론 적용, 이벤트 기반 데이터 파이프라인 빌드 등 시간에 민감한 작업을 수행할 수 있습니다.
다음 메서드를 사용하여 쿼리 작업을 실행할 수 있습니다.
- Google Cloud 콘솔에서 쿼리를 작성하고 실행합니다.
- bq 명령줄 도구에서
bq query명령어를 실행합니다. - BigQuery REST API의
jobs.query또는jobs.insert메서드를 프로그래매틱 방식으로 호출합니다. - BigQuery 클라이언트 라이브러리를 사용합니다.
BigQuery는 쿼리 결과를 임시 테이블(기본값) 또는 영구 테이블에 저장합니다. 영구 테이블을 결과의 대상 테이블로 지정할 때 기존 테이블을 추가 또는 덮어쓸지, 아니면 고유한 이름으로 새 테이블을 만들지 선택할 수 있습니다.
필요한 역할
쿼리 작업을 실행하는 데 필요한 권한을 얻으려면 관리자에게 다음 IAM 역할을 부여해 달라고 요청하세요.
-
프로젝트에 대한 BigQuery 작업 사용자 (
roles/bigquery.jobUser)입니다. -
쿼리에서 참조하는 모든 테이블과 뷰에 대한 BigQuery 데이터 뷰어 (
roles/bigquery.dataViewer)입니다. 뷰를 쿼리하려면 모든 기본 테이블 및 뷰에도 이 역할이 필요합니다. 승인된 뷰 또는 승인된 데이터 세트를 사용하는 경우 기본 소스 데이터에 액세스할 필요가 없습니다.
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
이러한 사전 정의된 역할에는 쿼리 작업을 실행하는 데 필요한 권한이 포함되어 있습니다. 필요한 정확한 권한을 보려면 필수 권한 섹션을 펼치세요.
필수 권한
쿼리 작업을 실행하려면 다음 권한이 필요합니다.
-
데이터가 저장된 위치에 관계없이 쿼리를 실행 중인 프로젝트에 대한
bigquery.jobs.create권한 -
쿼리에서 참조하는 모든 테이블 및 뷰에 대한
bigquery.tables.getData권한. 뷰를 쿼리하려면 모든 기본 테이블 및 뷰에 대한 이 권한도 필요합니다. 승인된 뷰 또는 승인된 데이터 세트를 사용하는 경우 기본 소스 데이터에 액세스할 필요가 없습니다.
커스텀 역할이나 다른 사전 정의된 역할을 사용하여 이 권한을 부여받을 수도 있습니다.
문제 해결
Access Denied: Project [project_id]: User does not have bigquery.jobs.create
permission in project [project_id].
이 오류는 주 구성원에게 프로젝트에서 쿼리 작업을 만들 수 있는 권한이 없을 때 발생합니다.
해결 방법: 관리자가 쿼리 중인 프로젝트에 대한 bigquery.jobs.create 권한을 부여해야 합니다. 쿼리된 데이터에 액세스하는 데 필요한 권한 외에도 이 권한이 필요합니다.
BigQuery 권한에 대한 자세한 내용은 IAM으로 액세스 제어를 참조하세요.
대화형 쿼리 실행
대화형 쿼리를 실행하려면 다음 옵션 중 하나를 선택합니다.
콘솔
BigQuery 페이지로 이동합니다.
SQL 쿼리를 클릭합니다.
쿼리 편집기에서 유효한 GoogleSQL 쿼리를 입력합니다.
예를 들어 BigQuery 공개 데이터 세트
usa_names를 쿼리해 1910년부터 2013년까지 미국에서 가장 흔한 이름을 확인합니다.SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;또는 참조 패널을 사용하여 새 쿼리를 구성할 수 있습니다.
선택사항: 쿼리를 입력할 때 코드 추천을 자동으로 표시하려면 더보기를 클릭한 다음 SQL 자동 완성을 선택합니다. 자동 완성 제안이 필요하지 않으면 SQL 자동 완성을 선택 해제합니다. 이렇게 하면 프로젝트 이름 자동 완성 제안도 사용 중지됩니다.
(선택사항) 추가 쿼리 설정을 선택하려면 더보기를 클릭한 다음 쿼리 설정을 클릭합니다.
실행을 클릭합니다.
대상 테이블을 지정하지 않으면 쿼리 작업은 출력을 임시(캐시) 테이블에 씁니다.
이제 쿼리 결과 창의 결과 탭에서 쿼리 결과를 살펴볼 수 있습니다.
선택사항: 열별로 쿼리 결과를 정렬하려면 열 이름 옆에 있는 정렬 메뉴 열기를 클릭하고 정렬 순서를 선택합니다. 정렬에 처리되는 예상 바이트 수가 0보다 크면 메뉴 상단에 바이트 수가 표시됩니다.
선택사항: 쿼리 결과의 시각화를 보려면 시각화 탭으로 이동합니다. 차트를 확대 또는 축소하거나 차트를 PNG 파일로 다운로드하거나 범례 공개 상태를 전환할 수 있습니다.
시각화 구성 창에서 시각화 유형을 변경하고 시각화의 측정 및 측정기준을 구성할 수 있습니다. 이 창의 필드는 쿼리의 대상 테이블 스키마에서 추론된 초기 구성으로 미리 채워집니다. 동일한 쿼리 편집기에서는 다음 쿼리 실행 간에 구성이 보존됩니다.
선, 막대 또는 분산형 시각화의 경우 지원되는 측정기준은
INT64,FLOAT64,NUMERIC,BIGNUMERIC,TIMESTAMP,DATE,DATETIME,TIME,STRING데이터 유형이며 지원되는 측정값은INT64,FLOAT64,NUMERIC,BIGNUMERIC데이터 유형입니다.쿼리 결과에
GEOGRAPHY유형이 포함된 경우 지도가 기본 시각화 유형이므로 대화형 지도에 결과를 시각화할 수 있습니다.선택사항: JSON 탭에서 JSON 형식으로 쿼리 결과를 탐색할 수 있습니다. 여기서 키는 열 이름이고 값은 해당 열에 대한 결과입니다.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
bq query명령어를 사용합니다. 다음 예시에서는--use_legacy_sql=false플래그를 사용하여 GoogleSQL 구문을 사용할 수 있습니다.bq query \ --use_legacy_sql=false \ 'QUERY'
QUERY를 유효한 GoogleSQL 쿼리로 바꿉니다. 예를 들어 BigQuery 공개 데이터 세트
usa_names를 쿼리해 1910년부터 2013년까지 미국에서 가장 흔한 이름을 확인합니다.bq query \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'쿼리 작업이 출력을 임시(캐시) 테이블에 씁니다.
선택사항으로 쿼리 결과의 대상 테이블 및 위치를 지정할 수 있습니다. 기존 테이블에 결과를 쓰려면 적절한 플래그를 포함하여 테이블을 추가(
--append_table=true)하거나 덮어씁니다(--replace=true).bq query \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
다음을 바꿉니다.
LOCATION: 대상 테이블의 리전 또는 멀티 리전입니다(예:
US).이 예시에서
usa_names데이터 세트는 US 멀티 리전 위치에 저장됩니다. 이 쿼리의 대상 테이블을 지정하는 경우 대상 테이블이 포함된 데이터 세트도 US 멀티 리전에 있어야 합니다. 한 위치에서 데이터 세트를 쿼리하고 결과를 다른 위치에 있는 테이블에 기록할 수는 없습니다..bigqueryrc 파일을 사용하여 위치 기본값을 설정할 수 있습니다.
TABLE: 대상 테이블의 이름입니다(예:
myDataset.myTable).대상 테이블이 새 테이블이면 BigQuery는 쿼리를 실행할 때 테이블을 만듭니다. 하지만 기존 데이터 세트를 지정해야 합니다.
테이블이 현재 프로젝트에 없으면Google Cloud 프로젝트 ID를 추가합니다(예:
myProject:myDataset.myTable).PROJECT_ID:DATASET.TABLE--destination_table을 지정하지 않으면 임시 테이블에 출력을 쓰는 쿼리 작업이 생성됩니다.
API
API를 사용하여 쿼리를 실행하려면 새 작업을 삽입하고 query 작업 구성 속성을 채웁니다. (선택사항) 작업 리소스의 jobReference 섹션에 있는 location 속성에 사용자 위치를 지정합니다.
getQueryResults를 호출하여 결과를 폴링합니다.
jobComplete가 true가 될 때까지 폴링해야 합니다. 그런 다음 errors 목록에 오류나 경고가 있는지 확인합니다.
C#
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 C# 설정 안내를 따르세요. 자세한 내용은 BigQuery C# API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Go
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Go 설정 안내를 따르세요. 자세한 내용은 BigQuery Go API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Java
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
프록시를 사용하여 쿼리를 실행하려면 프록시 구성을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 BigQuery Node.js API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
PHP
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 PHP 설정 안내를 따르세요. 자세한 내용은 BigQuery PHP API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Python
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 BigQuery Python API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Ruby
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Ruby 설정 안내를 따르세요. 자세한 내용은 BigQuery Ruby API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
일괄 쿼리 실행
일괄 쿼리를 실행하려면 다음 옵션 중 하나를 선택합니다.
콘솔
BigQuery 페이지로 이동합니다.
SQL 쿼리를 클릭합니다.
쿼리 편집기에서 유효한 GoogleSQL 쿼리를 입력합니다.
예를 들어 BigQuery 공개 데이터 세트
usa_names를 쿼리해 1910년부터 2013년까지 미국에서 가장 흔한 이름을 확인합니다.SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;더보기를 클릭한 다음 쿼리 설정을 클릭합니다.
리소스 관리 섹션에서 일괄을 선택합니다.
선택사항: 쿼리 설정을 조정합니다.
저장을 클릭합니다.
실행을 클릭합니다.
대상 테이블을 지정하지 않으면 쿼리 작업은 출력을 임시(캐시) 테이블에 씁니다.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
bq query명령어를 사용하고--batch플래그를 지정합니다. 다음 예시에서는--use_legacy_sql=false플래그를 사용하여 GoogleSQL 구문을 사용할 수 있습니다.bq query \ --batch \ --use_legacy_sql=false \ 'QUERY'
QUERY를 유효한 GoogleSQL 쿼리로 바꿉니다. 예를 들어 BigQuery 공개 데이터 세트
usa_names를 쿼리해 1910년부터 2013년까지 미국에서 가장 흔한 이름을 확인합니다.bq query \ --batch \ --use_legacy_sql=false \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'쿼리 작업이 출력을 임시(캐시) 테이블에 씁니다.
선택사항으로 쿼리 결과의 대상 테이블 및 위치를 지정할 수 있습니다. 기존 테이블에 결과를 쓰려면 적절한 플래그를 포함하여 테이블을 추가(
--append_table=true)하거나 덮어씁니다(--replace=true).bq query \ --batch \ --location=LOCATION \ --destination_table=TABLE \ --use_legacy_sql=false \ 'QUERY'
다음을 바꿉니다.
LOCATION: 대상 테이블의 리전 또는 멀티 리전입니다(예:
US).이 예시에서
usa_names데이터 세트는 US 멀티 리전 위치에 저장됩니다. 이 쿼리의 대상 테이블을 지정하는 경우 대상 테이블이 포함된 데이터 세트도 US 멀티 리전에 있어야 합니다. 한 위치에서 데이터 세트를 쿼리하고 결과를 다른 위치에 있는 테이블에 기록할 수는 없습니다..bigqueryrc 파일을 사용하여 위치 기본값을 설정할 수 있습니다.
TABLE: 대상 테이블의 이름입니다(예:
myDataset.myTable).대상 테이블이 새 테이블이면 BigQuery는 쿼리를 실행할 때 테이블을 만듭니다. 하지만 기존 데이터 세트를 지정해야 합니다.
테이블이 현재 프로젝트에 없으면Google Cloud 프로젝트 ID를 추가합니다(예:
myProject:myDataset.myTable).PROJECT_ID:DATASET.TABLE--destination_table을 지정하지 않으면 임시 테이블에 출력을 쓰는 쿼리 작업이 생성됩니다.
API
API를 사용하여 쿼리를 실행하려면 새 작업을 삽입하고 query 작업 구성 속성을 채웁니다. (선택사항) 작업 리소스의 jobReference 섹션에 있는 location 속성에 사용자 위치를 지정합니다.
쿼리 작업 속성을 채울 때는 configuration.query.priority 속성을 포함하고 값을 BATCH로 설정합니다.
getQueryResults를 호출하여 결과를 폴링합니다.
jobComplete가 true가 될 때까지 폴링해야 합니다. 그런 다음 errors 목록에 오류나 경고가 있는지 확인합니다.
Go
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Go 설정 안내를 따르세요. 자세한 내용은 BigQuery Go API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
자바
일괄 쿼리를 실행하려면 QueryJobConfiguration을 만들 때 쿼리 우선순위를 QueryJobConfiguration.Priority.BATCH로 설정합니다.
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 BigQuery Node.js API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Python
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 BigQuery Python API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
연속 쿼리 실행
연속 쿼리 작업을 실행하려면 추가 구성이 필요합니다. 자세한 내용은 연속 쿼리 만들기를 참고하세요.
참조 패널 사용
쿼리 편집기에서 참조 패널은 테이블, 스냅샷, 뷰, 구체화된 뷰에 대한 컨텍스트 인식 정보를 동적으로 표시합니다. 이 패널을 사용하면 이러한 리소스의 스키마 세부정보를 미리 보거나 새 탭에서 열 수 있습니다. 참조 패널을 사용하여 쿼리 스니펫이나 필드 이름을 삽입하여 새 쿼리를 구성하거나 기존 쿼리를 수정할 수도 있습니다.
참조 패널을 사용하여 새 쿼리를 구성하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
SQL 쿼리를 클릭합니다.
quick_reference_all 참조를 클릭합니다.
최근 또는 별표표시된 테이블 또는 뷰를 클릭합니다. 검색창을 사용하여 테이블과 뷰를 찾을 수도 있습니다.
작업 보기를 클릭한 다음 쿼리 스니펫 삽입을 클릭합니다.
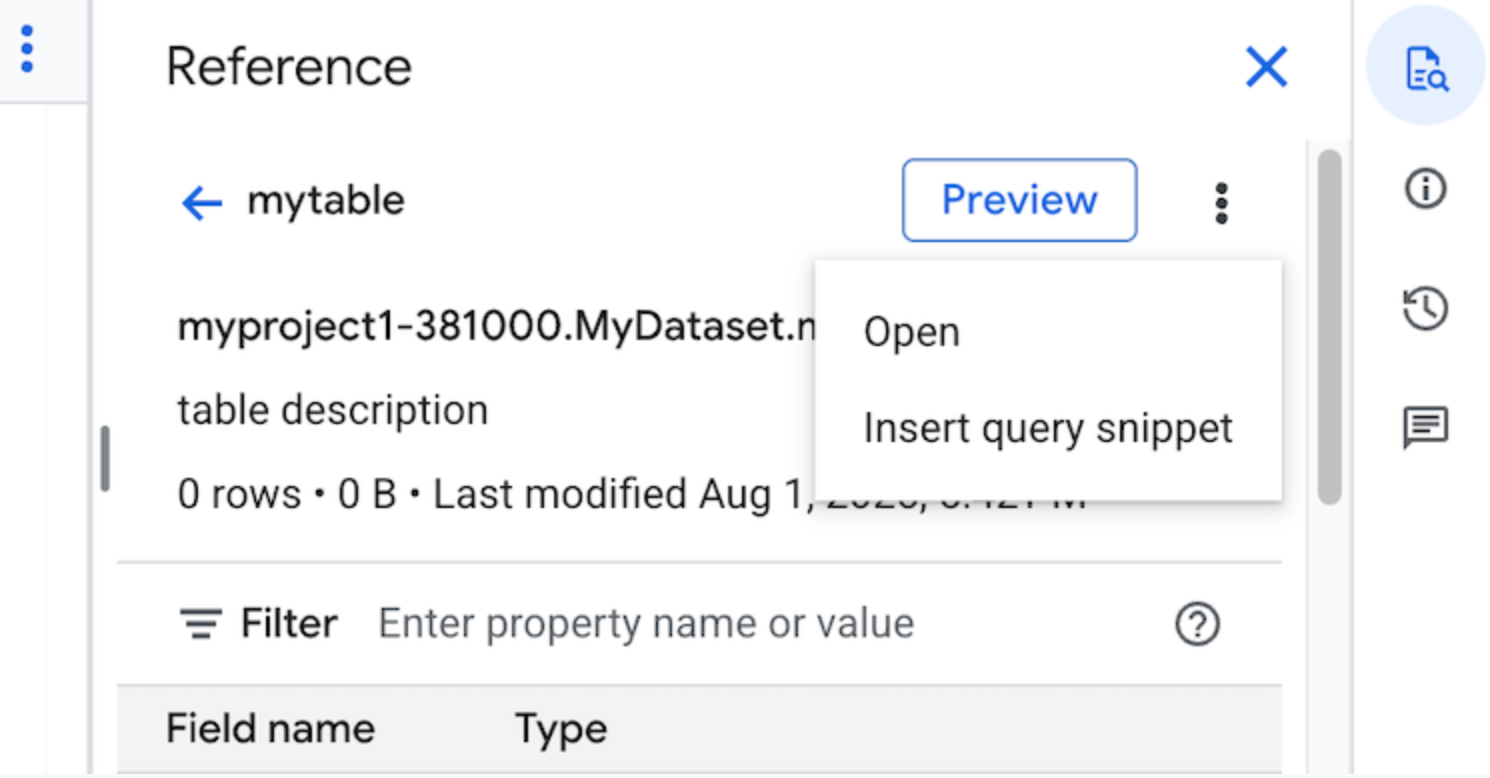
선택사항: 테이블의 스키마 세부정보를 미리 보거나 새 탭에서 세부정보를 보거나 열 수 있습니다.
이제 쿼리를 직접 수정하거나 필드 이름을 쿼리에 직접 삽입할 수 있습니다. 필드 이름을 삽입하려면 쿼리 편집기에서 필드 이름을 삽입할 위치를 가리키고 클릭한 다음 참조 패널에서 필드 이름을 클릭합니다.
쿼리 설정
쿼리를 실행할 때 다음 설정을 지정할 수 있습니다.
쿼리 결과의 대상 테이블입니다.
작업의 우선순위입니다.
캐시된 쿼리 결과를 사용할지 여부입니다.
작업 제한 시간(밀리초)입니다.
세션 모드를 사용할지 여부입니다.
사용할 암호화 유형입니다.
쿼리에 대해 청구된 최대 바이트 수입니다.
사용할 SQL 언어입니다.
쿼리를 실행할 위치입니다. 쿼리는 쿼리에서 참조하는 테이블과 동일한 위치에서 실행되어야 합니다.
선택적 작업 생성 모드
선택적 작업 생성 모드는 대시보드 또는 데이터 탐색 워크로드의 쿼리와 같이 짧은 시간 동안 실행되는 쿼리의 전체 지연 시간을 개선할 수 있습니다. 이 모드는 쿼리를 실행하고 SELECT 문의 결과를 인라인으로 반환하며, 결과를 가져오기 위해 jobs.getQueryResults를 사용할 필요가 없습니다. 선택적 작업 생성 모드를 사용하는 쿼리는 BigQuery에서 쿼리를 완료하는 데 작업 생성이 필요하다고 판단하지 않는 한 실행 시 작업을 생성하지 않습니다.
선택적 작업 생성 모드를 사용 설정하려면 jobs.query 요청 본문에서 QueryRequest 인스턴스의 jobCreationMode 필드를 JOB_CREATION_OPTIONAL로 설정합니다.
이 필드의 값이 JOB_CREATION_OPTIONAL로 설정되면 BigQuery는 쿼리에서 선택적 작업 생성 모드를 사용할 수 있는지 결정합니다. 사용할 수 있는 경우 BigQuery는 쿼리를 실행하고 응답의 rows 필드에 모든 결과를 반환합니다. 이 쿼리에 대해 작업이 생성되지 않으므로 BigQuery는 응답 본문에 jobReference를 반환하지 않습니다. 대신 INFORMATION_SCHEMA.JOBS 뷰를 사용하여 쿼리에 관한 인사이트를 가져오는 데 사용할 수 있는 queryId 필드를 반환합니다. 작업이 생성되지 않으므로 jobs.get 및 jobs.getQueryResults API에 전달하여 이러한 쿼리를 조회할 수 있는 jobReference가 없습니다.
BigQuery에서 쿼리를 완료하는 데 작업이 필요하다고 판단하면 jobReference가 반환됩니다. INFORMATION_SCHEMA.JOBS 보기에서 job_creation_reason 필드를 검사하여 쿼리에 대한 작업이 생성된 이유를 확인할 수 있습니다. 이 경우 쿼리가 완료되면 jobs.getQueryResults를 사용하여 결과를 가져와야 합니다.
JOB_CREATION_OPTIONAL 값을 사용하면 jobReference 필드가 응답에 없을 수도 있습니다. 액세스 전에 필드가 있는지 확인합니다.
멀티 문 쿼리 (스크립트)에 JOB_CREATION_OPTIONAL가 지정되면 BigQuery에서 실행 프로세스를 최적화할 수 있습니다. 이 최적화의 일환으로 BigQuery는 개별 문의 수보다 적은 수의 작업 리소스를 만들어 스크립트를 완료할 수 있다고 판단할 수 있으며, 작업을 전혀 만들지 않고 전체 스크립트를 실행할 수도 있습니다.
이 최적화는 BigQuery의 스크립트 평가에 따라 달라지며 모든 경우에 최적화가 적용되지 않을 수 있습니다. 최적화는 시스템에 의해 완전히 자동화됩니다. 사용자 제어나 조치는 필요하지 않습니다.
선택적 작업 생성 모드를 사용하여 쿼리를 실행하려면 다음 옵션 중 하나를 선택합니다.
콘솔
BigQuery 페이지로 이동합니다.
SQL 쿼리를 클릭합니다.
쿼리 편집기에서 유효한 GoogleSQL 쿼리를 입력합니다.
예를 들어 BigQuery 공개 데이터 세트
usa_names를 쿼리해 1910년부터 2013년까지 미국에서 가장 흔한 이름을 확인합니다.SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;더보기를 클릭한 다음 선택적 작업 생성 쿼리 모드를 선택합니다. 이 선택사항을 확인하려면 확인을 클릭합니다.
실행을 클릭합니다.
bq
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
bq query명령어를 사용하고--job_creation_mode=JOB_CREATION_OPTIONAL플래그를 지정합니다. 다음 예시에서는--use_legacy_sql=false플래그를 사용하여 GoogleSQL 구문을 사용할 수 있습니다.bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=LOCATION \ 'QUERY'
QUERY를 유효한 GoogleSQL 쿼리로 바꾸고 LOCATION을 데이터 세트가 있는 유효한 리전으로 바꿉니다. 예를 들어 BigQuery 공개 데이터 세트
usa_names를 쿼리해 1910년부터 2013년까지 미국에서 가장 흔한 이름을 확인합니다.bq query \ --rpc=true \ --use_legacy_sql=false \ --job_creation_mode=JOB_CREATION_OPTIONAL \ --location=us \ 'SELECT name, gender, SUM(number) AS total FROM `bigquery-public-data.usa_names.usa_1910_2013` GROUP BY name, gender ORDER BY total DESC LIMIT 10;'쿼리 작업이 응답에 인라인으로 출력을 반환합니다.
API
API를 사용하여 선택적 작업 생성 모드에서 쿼리를 실행하려면 동기식으로 쿼리를 실행하고 QueryRequest 속성을 채웁니다. jobCreationMode 속성을 포함하고 값을 JOB_CREATION_OPTIONAL로 설정합니다.
대답을 확인합니다. jobComplete가 true와 같고 jobReference가 비어 있으면 rows 필드에서 결과를 읽습니다. 응답에서 queryId를 가져올 수도 있습니다.
jobReference가 있는 경우 BigQuery에서 작업을 생성한 이유를 jobCreationReason에서 확인할 수 있습니다. getQueryResults를 호출하여 결과를 폴링합니다.
jobComplete가 true가 될 때까지 폴링해야 합니다. 그런 다음 errors 목록에 오류나 경고가 있는지 확인합니다.
자바
사용 가능한 버전: 2.51.0 이상
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
프록시를 사용하여 쿼리를 실행하려면 프록시 구성을 참조하세요.
Python
사용 가능한 버전: 3.34.0 이상
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 BigQuery Python API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
노드
사용 가능한 버전: 8.1.0 이상
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 BigQuery Node.js API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Go
사용 가능한 버전: 1.69.0 이상
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Go 설정 안내를 따르세요. 자세한 내용은 BigQuery Go API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
JDBC 드라이버
사용 가능한 버전: JDBC v1.6.1 이상
연결 문자열에 JobCreationMode=2를 설정해야 합니다.
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;JobCreationMode=2;Location=US;
ODBC 드라이버
사용 가능한 버전: ODBC v3.0.7.1016 이상
.ini 파일에서 JobCreationMode=2를 설정해야 합니다.
[ODBC Data Sources] Sample DSN=Simba Google BigQuery ODBC Connector 64-bit [Sample DSN] JobCreationMode=2
할당량
대화형 및 일괄 쿼리와 관련된 할당량에 대한 자세한 내용은 쿼리 작업을 참조하세요.
쿼리 모니터링
작업 탐색기를 사용하거나 INFORMATION_SCHEMA.JOBS_BY_PROJECT 뷰를 쿼리하여 쿼리가 실행될 때 쿼리에 관한 정보를 가져올 수 있습니다.
테스트 실행
BigQuery의 테스트 실행 기능은 다음 정보를 제공합니다.
테스트 실행은 쿼리 슬롯을 사용하지 않습니다. 테스트 실행 수행에 따른 요금이 부과되지 않습니다. 테스트 실행에서 반환된 추정값을 사용하여 가격 계산기에서 쿼리 비용을 계산할 수 있습니다.
테스트 실행 수행
시험 이전을 수행하려면 다음을 수행합니다.
콘솔
BigQuery 페이지로 이동합니다.
쿼리 편집기에 쿼리를 입력합니다.
쿼리가 유효하면 쿼리에서 처리할 데이터 양과 함께 체크표시가 자동으로 표시됩니다. 쿼리가 유효하지 않으면 느낌표가 오류 메시지와 함께 표시됩니다.
bq
--dry_run 플래그를 사용하여 다음과 같은 쿼리를 입력합니다.
bq query \ --use_legacy_sql=false \ --dry_run \ 'SELECT COUNTRY, AIRPORT, IATA FROM `project_id`.dataset.airports LIMIT 1000'
유효한 쿼리인 경우 이 명령어는 다음 응답을 생성합니다.
Query successfully validated. Assuming the tables are not modified, running this query will process 10918 bytes of data.
API
API를 사용하여 테스트 실행을 수행하려면 JobConfiguration 유형에서 dryRun을 true로 설정한 채로 쿼리 작업을 제출합니다.
Go
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Go 설정 안내를 따르세요. 자세한 내용은 BigQuery Go API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
자바
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Java 설정 안내를 따르세요. 자세한 내용은 BigQuery Java API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Node.js
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Node.js 설정 안내를 따르세요. 자세한 내용은 BigQuery Node.js API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
PHP
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 PHP 설정 안내를 따르세요. 자세한 내용은 BigQuery PHP API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
Python
QueryJobConfig.dry_run 속성을 True로 설정합니다.
테스트 실행 쿼리 구성을 제공하면 Client.query()는 항상 완료된 QueryJob을 반환합니다.
이 샘플을 사용해 보기 전에 BigQuery 빠른 시작: 클라이언트 라이브러리 사용의 Python 설정 안내를 따르세요. 자세한 내용은 BigQuery Python API 참고 문서를 확인하세요.
BigQuery에 인증하려면 애플리케이션 기본 사용자 인증 정보를 설정합니다. 자세한 내용은 클라이언트 라이브러리의 인증 설정을 참조하세요.
다음 단계
- 쿼리 작업 관리 방법 알아보기
- 쿼리 기록을 확인 방법 알아보기
- 쿼리 저장 및 공유 방법 알아보기
- 쿼리 큐 알아보기
- 쿼리 결과를 작성하는 방법 알아보기