Introduzione
Questa guida per principianti è un'introduzione ad AutoML. Per comprendere le principali differenze tra AutoML e l'addestramento personalizzato, consulta Scegliere un metodo di addestramento.
Immagina:
- Sei l'allenatore di una squadra di calcio.
- Lavori nel reparto marketing di un rivenditore digitale.
- Stai lavorando a un progetto di architettura che identifica i tipi di edifici.
- La tua attività ha un modulo di contatto sul proprio sito web.
Il lavoro di cura manuale di video, immagini, testi e tabelle è noioso e richiede molto tempo. Non sarebbe più semplice insegnare a un computer a identificare e segnalare automaticamente i contenuti?
Immagine
Collabori con una commissione per la conservazione architettonica che sta tentando di identificare i quartieri della tua città che hanno uno stile architettonico coerente. Hai centinaia di migliaia di istantanee di case da esaminare. Tuttavia, è un processo laborioso e soggetto a errori se si tenta di classificare manualmente tutte queste immagini. Un stagista ne ha etichettate alcune centinaia qualche mese fa, ma nessun altro ha esaminato i dati. Sarebbe davvero utile se potessi insegnare al computer a eseguire questa revisione per te.
Tabulare
Lavori nel reparto marketing di un rivenditore digitale. Tu e il tuo team
state creando un programma email personalizzato in base ai clienti tipo. Hai creato le persone
e le email di marketing sono pronte per essere inviate. Ora devi creare un sistema che raggruppi i clienti
in ogni persona in base alle preferenze di acquisto e al comportamento di spesa, anche se si tratta di nuovi
clienti. Per massimizzare il coinvolgimento dei clienti, devi anche prevedere le loro abitudini di spesa in modo da ottimizzare il momento in cui inviare le email.
Poiché sei un rivenditore digitale, disponi di dati sui tuoi clienti e sugli acquisti che hanno effettuato. E i nuovi clienti? Gli approcci tradizionali possono calcolare questi valori per i clienti esistenti con lunghe cronologie acquisti, ma non sono efficaci per i clienti con pochi dati storici. E se potessi creare un sistema per prevedere questi valori e aumentare la velocità con cui offri programmi di marketing personalizzati a tutti i tuoi clienti?
Fortunatamente, il machine learning e Vertex AI sono ben posizionati per risolvere questi problemi.
Testo
La tua attività ha un modulo di contatto sul proprio sito web. Ogni giorno ricevi molti messaggi dal modulo, molti dei quali sono in qualche modo utili. Poiché arrivano tutte insieme, è facile rimanere indietro con la gestione. Dipendenti diversi gestiscono tipi di messaggi diversi.
Sarebbe fantastico se un sistema automatico potesse classificarli in modo che la persona giusta veda i commenti giusti.
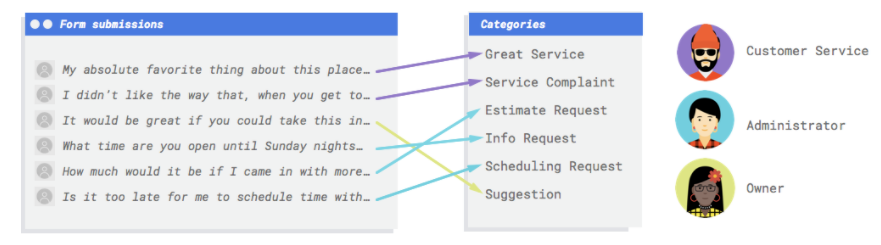
Devi avere un sistema per esaminare i commenti e decidere se rappresentano reclami, lodi per servizi passati, un tentativo di scoprire di più sulla tua attività, una richiesta di fissare un appuntamento o un tentativo di stabilire un rapporto.
Video
Hai una vasta raccolta di video di giochi che vorresti analizzare. Tuttavia, dobbiamo esaminare centinaia di ore di video. Guardare ogni video e contrassegnare manualmente i segmenti per evidenziare ogni azione è un lavoro tedioso e richiede molto tempo. E devi ripetere questa operazione ogni stagione. Ora immagina un modello di computer che possa identificare e segnalare automaticamente queste azioni ogni volta che appaiono in un video.
Di seguito sono riportati alcuni scenari specifici per gli obiettivi.
- Riconoscimento dell'azione: trova azioni come segnare un gol, commettere un fallo, eseguire un calcio di rigore. Utile per gli allenatori per studiare i punti di forza e i punti deboli della propria squadra.
- Classificazione: classifica ogni video girato come intervallo, visuale della partita, visuale del pubblico o visuale dell'allenatore. Utile per gli allenatori per sfogliare solo gli scatti video di loro interesse.
- Monitoraggio degli oggetti: consente di monitorare il pallone da calcio o i giocatori. Utile per gli allenatori per ottenere statistiche dei giocatori, come la mappa di calore in campo, il tasso di passaggi riusciti.
Questa guida illustra il funzionamento di Vertex AI per i set di dati e i modelli AutoML e illustra i tipi di problemi che Vertex AI è progettato per risolvere.
Una nota sull'equità
Google si impegna a fare progressi nell'adozione di pratiche di IA responsabile. Per raggiungere questo obiettivo, i nostri prodotti di ML, tra cui AutoML, sono progettati in base a principi fondamentali come equità e machine learning incentrato sull'uomo. Per ulteriori informazioni sulle best practice per ridurre i bias durante la creazione del tuo sistema di machine learning, consulta la guida al machine learning inclusivo: AutoML
Perché Vertex AI è lo strumento giusto per questo problema?
La programmazione classica richiede al programmatore di specificare istruzioni passo passo da seguire per un computer. Ma prendiamo in considerazione il caso d'uso dell'identificazione di azioni specifiche nelle partite di calcio. Esistono così tante varianti di colore, angolazione, risoluzione e illuminazione che sarebbe necessario codificare troppe regole per indicare a una macchina come prendere la decisione corretta. È difficile immaginare da dove iniziare. In alternativa, se i commenti dei clienti, che utilizzano un vocabolario e una struttura ampi e diversificati, sono troppo diversi per essere rilevati da un semplice insieme di regole. Se provassi a creare filtri manuali, scopriresti rapidamente di non essere in grado di classificare la maggior parte dei commenti dei clienti. È necessario un sistema in grado di generalizzare a una vasta gamma di commenti. In uno scenario in cui una sequenza di regole specifiche è destinata a espandersi in modo esponenziale, hai bisogno di un sistema in grado di apprendere dagli esempi.
Fortunatamente, il machine learning è in grado di risolvere questi problemi.
Come funziona Vertex AI?
 Vertex AI utilizza attività di apprendimento supervisionato per raggiungere un risultato scelto.
Le specifiche dell'algoritmo e dei metodi di addestramento variano in base al tipo di dati e al caso d'uso. Esistono molte sottocategorie diverse di machine learning, tutte le quali risolvono problemi diversi e operano in base a vincoli diversi.
Vertex AI utilizza attività di apprendimento supervisionato per raggiungere un risultato scelto.
Le specifiche dell'algoritmo e dei metodi di addestramento variano in base al tipo di dati e al caso d'uso. Esistono molte sottocategorie diverse di machine learning, tutte le quali risolvono problemi diversi e operano in base a vincoli diversi.
Immagine
Addestra, testa e convalida il modello di machine learning con immagini di esempio annotate con etichette per la classificazione o con etichette e riquadri di delimitazione per il rilevamento di oggetti. Con l'apprendimento supervisionato, puoi addestrare un modello a riconoscere gli schemi e i contenuti che ti interessano nelle immagini.
Tabulare
Addestrare un modello di machine learning con dati di esempio. Vertex AI
utilizza i dati tabulari (strutturati) per addestrare un modello di machine learning per fare
previsioni sulla base di nuovi dati. Il modello imparerà a fare previsioni sui dati di una singola colonna del set di dati, chiamata target. Alcune delle altre colonne di dati sono gli input (chiamati caratteristiche) da cui il modello apprenderà i pattern. Puoi
utilizzare le stesse caratteristiche di input per creare diversi tipi di modelli, semplicemente cambiando
la colonna target e le opzioni di addestramento. Nell'esempio di email marketing,
significa che puoi creare modelli con le stesse caratteristiche di input, ma con diverse
previsioni del target. Un modello potrebbe prevedere la persona di un cliente (un
target categorico), un altro la sua spesa mensile (un
target numerico) e un altro ancora la domanda giornaliera dei tuoi prodotti
per i tre mesi successivi (serie di target numerici).
Testo
Vertex AI ti consente di eseguire l'apprendimento supervisionato. Ciò comporta l'addestramento di un computer per riconoscere pattern dai dati etichettati. Con l'apprendimento supervisionato, puoi addestrare un modello AutoML a riconoscere i contenuti che ti interessano nel testo.
Video
Addestrare, testare e convalidare il modello di machine learning con i video che hai già etichettato. Con un modello addestrato, puoi inserire nuovi video, che verranno poi elaborati dal modello e daranno come output segmenti video con etichette. Un segmento video definisce l'offset dell'ora di inizio e di fine all'interno di un video. Il segmento può essere l'intero video, un segmento di tempo definito dall'utente, un'inquadratura video rilevata automaticamente o semplicemente un timestamp per quando l'ora di inizio corrisponde a quella di fine. Un'etichetta è una "risposta" prevista dal modello. Ad esempio, nei casi d'uso relativi al calcio menzionati in precedenza, per ogni nuovo video di calcio, a seconda del tipo di modello:
- un modello di riconoscimento delle azioni addestrato genera offset di tempo video con etichette che descrivono scatti d'azione come "gol", "fallo personale" e così via.
- un modello di classificazione addestrato genera segmenti di inquadrature rilevati automaticamente con etichette definite dall'utente come "vista del gioco", "vista del pubblico".
- un modello di tracciamento degli oggetti addestrato genera tracce della palla da calcio o dei giocatori tramite riquadri di delimitazione nei fotogrammi in cui appaiono gli oggetti.
Flusso di lavoro Vertex AI
Vertex AI utilizza un flusso di lavoro di machine learning standard:
- Raccogli i dati: determina i dati di cui hai bisogno per addestrare e testare il tuo modello in base al risultato che vuoi ottenere.
- Prepara i dati: assicurati che siano formattati e etichettati correttamente.
- Addestramento: imposta i parametri e crea il modello.
- Valuta: esamina le metriche del modello.
- Esegui il deployment e fai una previsione: rendi il tuo modello disponibile per l'utilizzo.
Tuttavia, prima di iniziare a raccogliere i dati, devi pensare al problema che stai cercando di risolvere. In questo modo, potrai definire i requisiti dei dati.
Preparazione dati
Valuta il tuo caso d'uso
Inizia dal problema: qual è il risultato che vuoi ottenere?
Immagine
Quando crei il set di dati, inizia sempre dal tuo caso d'uso. Puoi iniziare con le seguenti domande:
- Qual è il risultato che stai cercando di ottenere?
- Quali tipi di categorie o oggetti dovresti riconoscere per ottenere questo risultato?
- È possibile che gli esseri umani riconoscano queste categorie? Sebbene Vertex AI possa gestire un numero maggiore di categorie rispetto a quelle che gli esseri umani possono ricordare e assegnare contemporaneamente, se un essere umano non riesce a riconoscere una categoria specifica, anche Vertex AI avrà difficoltà.
- Quali tipi di esempi rifletterebbero al meglio il tipo e l'intervallo di dati che il sistema vedrà e tenterà di classificare?
Tabulare
Di che tipo di dati è composta la colonna di destinazione? A quanti dati hai accesso? A seconda delle tue risposte, Vertex AI crea il modello necessario per risolvere il tuo caso d'uso:
- Un modello di classificazione binaria prevede un esito binario (una di due classi). Utilizzalo per le domande con risposta sì o no, ad esempio per prevedere se un cliente acquisterà o meno un abbonamento. A parità di condizioni, un problema di classificazione binaria richiede meno dati rispetto ad altri tipi di modelli.
- Un modello di classificazione multi-classe prevede una classe da tre o più classi discrete. Utilizzalo per categorizzare gli elementi. Nell'esempio del settore vendita al dettaglio, è consigliabile creare un modello di classificazione multiclasse per segmentare i clienti in diversi profili.
- Un modello di previsione prevede una sequenza di valori. Ad esempio, in qualità di rivenditore, potresti voler prevedere la domanda giornaliera dei tuoi prodotti per i tre mesi successivi in modo da poter rifornire in anticipo gli inventari dei prodotti in modo appropriato.
- Un modello di regressione prevede un valore continuo. Nell'esempio di vendita al dettaglio, vorresti creare un modello di regressione per prevedere quanto spenderà un cliente il mese prossimo.
Testo
Quando crei il set di dati, inizia sempre dal tuo caso d'uso. Puoi iniziare con le seguenti domande:
- Quale risultato stai cercando di ottenere?
- Quali tipi di categorie devi riconoscere per ottenere questo risultato?
- È possibile che gli esseri umani riconoscano queste categorie? Sebbene Vertex AI possa gestire più categorie di quante un essere umano possa ricordare e assegnare contemporaneamente, se una persona non riesce a riconoscere una categoria specifica, anche Vertex AI avrà difficoltà.
- Quali tipi di esempi rifletterebbero al meglio il tipo e l'intervallo di dati che il tuo sistema classificherà?
Video
A seconda del risultato che stai cercando di ottenere, seleziona l'obiettivo del modello appropriato:
- Per rilevare i momenti di azione in un video, ad esempio l'identificazione di un gol, di un fallo o di un calcio di rigore, utilizza lo scopo Riconoscimento delle azioni.
- Per classificare gli scatti TV nelle seguenti categorie: pubblicità, notizie, programmi TV e così via, utilizza lo scopo Classificazione.
- Per individuare e monitorare gli oggetti in un video, utilizza lo scopo Monitoraggio degli oggetti.
Per le best practice per la preparazione dei set di dati, consulta queste pagine per gli scopi di riconoscimento azioni, classificazione e monitoraggio oggetti.
Raccogli i dati
Dopo aver stabilito il caso d'uso, devi raccogliere i dati che ti consentono di creare il modello che preferisci.
Immagine
 Dopo aver stabilito quali dati ti servono, devi trovare un modo per ottenerli. Puoi iniziare esaminando tutti i dati raccolti dalla tua organizzazione. Potresti scoprire di raccogliere già i dati pertinenti necessari per addestrare un modello. Se non disponi di questi dati,
puoi ottenerli manualmente o esternalizzarli a un fornitore di terze parti.
Dopo aver stabilito quali dati ti servono, devi trovare un modo per ottenerli. Puoi iniziare esaminando tutti i dati raccolti dalla tua organizzazione. Potresti scoprire di raccogliere già i dati pertinenti necessari per addestrare un modello. Se non disponi di questi dati,
puoi ottenerli manualmente o esternalizzarli a un fornitore di terze parti.
Includi esempi etichettati sufficienti in ogni categoria
 Il minimo richiesto da Vertex AI Training è di 100 esempi di immagini per categoria/etichetta per la classificazione.
La probabilità di riconoscere correttamente un'etichetta aumenta con il numero di esempi di alta qualità per ciascuna. In generale, più dati etichettati puoi fornire al processo di addestramento, migliore sarà il tuo modello. Scegli come target almeno 1000 esempi per etichetta.
Il minimo richiesto da Vertex AI Training è di 100 esempi di immagini per categoria/etichetta per la classificazione.
La probabilità di riconoscere correttamente un'etichetta aumenta con il numero di esempi di alta qualità per ciascuna. In generale, più dati etichettati puoi fornire al processo di addestramento, migliore sarà il tuo modello. Scegli come target almeno 1000 esempi per etichetta.
Distribuisci gli esempi in modo uniforme tra le categorie
È importante acquisire quantità approssimativamente simili di esempi di addestramento per ogni categoria. Anche se hai molti dati per un'etichetta, è meglio avere una distribuzione equa per ogni etichetta. Per capire perché, immagina che l'80% delle immagini che utilizzi per creare il tuo modello siano foto di case unifamiliari in stile moderno. Con una distribuzione così sbilanciata delle etichette, il tuo
modello ha molte probabilità di apprendere che è sicuro dirti sempre che una foto ritrae una casa singola moderna, piuttosto che rischiare di provare a prevedere un'etichetta molto meno comune.
È come scrivere un test a scelta multipla in cui quasi tutte le risposte corrette sono "C": presto il candidato esperto capirà che può rispondere "C" ogni volta senza nemmeno guardare la domanda.
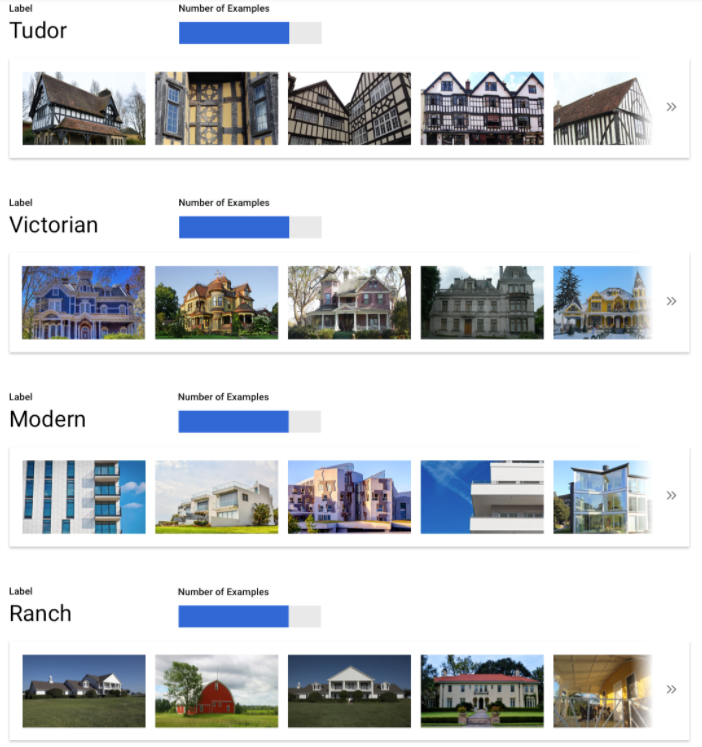
Siamo consapevoli che potrebbe non essere sempre possibile trovare un numero approssimativamente uguale di esempi per ogni etichetta. Potrebbe essere più difficile trovare esempi di alta qualità e non soggettivi per alcune categorie. In queste circostanze, puoi seguire questa regola empirica: l'etichetta con il numero più basso di esempi deve avere almeno il 10% degli esempi dell'etichetta con il numero più alto di esempi. Pertanto, se l'etichetta più grande ha 10.000 esempi, l'etichetta più piccola deve avere almeno 1000 esempi.
Cattura la variazione nello spazio del problema
Per motivi simili, cerca di assicurarti che i tuoi dati rappresentino la varietà e la diversità del tuo spazio di problemi. Più ampia è la selezione che il processo di addestramento del modello può vedere, più facilmente si generalizzerà a nuovi esempi. Ad esempio, se stai cercando di classificare le foto di prodotti di elettronica di consumo in categorie, maggiore è la varietà di prodotti di elettronica di consumo a cui viene esposto il modello durante l'addestramento, maggiori sono le probabilità che il modello sia in grado di distinguere un nuovo modello di tablet, smartphone o laptop, anche se non ha mai visto quel modello specifico prima.
Abbina i dati all'output previsto per il modello

Trova immagini visivamente simili a quelle su cui intendi fare previsioni. Se stai tentando di classificare le immagini di case che sono state tutte scattate in inverno con la neve, probabilmente non otterrai un rendimento eccezionale da un modello addestrato solo su immagini di case scattate in giornate soleggiate, anche se le hai taggate con i gruppi che ti interessano, poiché l'illuminazione e lo scenario potrebbero essere sufficientemente diversi da influire sul rendimento. Idealmente, gli esempi di addestramento sono dati reali ricavati dallo stesso set di dati che prevedi di utilizzare per la classificazione del modello.
Tabulare
Dopo aver stabilito il caso d'uso, dovrai raccogliere i dati per addestrare il modello.
L'acquisizione e la preparazione dei dati sono passaggi fondamentali per creare un modello di machine learning.
I dati a tua disposizione indicano il tipo di problemi che puoi risolvere. Quanti dati hai a disposizione? I tuoi dati sono pertinenti alle domande a cui stai cercando di rispondere? Durante la raccolta dei dati, tieni presente le seguenti considerazioni chiave.
Seleziona le funzionalità pertinenti
Una funzionalità è un attributo di input utilizzato per l'addestramento del modello. Le caratteristiche consentono al modello di identificare i pattern per fare previsioni, quindi devono essere pertinenti al problema. Ad esempio, per creare un modello che preveda se una transazione con carta di credito è fraudolenta o meno, devi creare un set di dati contenente i dettagli della transazione, come acquirente, venditore, importo, data e ora e articoli acquistati. Altre funzionalità utili potrebbero essere informazioni storiche sull'acquirente e sul venditore e la frequenza con cui l'articolo acquistato è stato coinvolto in attività fraudolente. Quali altre funzionalità potrebbero essere pertinenti?
Prendi in considerazione il caso d'uso di email marketing per la vendita al dettaglio riportato nell'introduzione. Ecco alcune colonne di funzionalità che potresti richiedere:
- Elenco di articoli acquistati (inclusi brand, categorie, prezzi, sconti)
- Numero di articoli acquistati (ultimo giorno, settimana, mese, anno)
- Somma di denaro spesa (ultimo giorno, settimana, mese, anno)
- Per ogni articolo, il numero totale di articoli venduti ogni giorno
- Per ogni articolo, il totale disponibile ogni giorno
- Se stai pubblicando una promozione per un giorno specifico
- Profilo demografico noto dello shopper
Includi dati sufficienti
In generale, più sono gli esempi di addestramento, migliore sarà il risultato. La quantità di dati di esempio richiesti varia anche in base alla complessità del problema che stai cercando di risolvere. Non
avrai bisogno di così tanti dati per ottenere un modello di classificazione binario accurato rispetto a un modello multi-classe
perché è meno complicato prevedere una classe da due anziché da molte.
Non esiste una formula perfetta, ma esistono quantità minime consigliate di dati di esempio:
- Problema di classificazione: 50 righe x il numero di funzionalità
- Problema di previsione:
- 5000 righe x il numero di elementi
- 10 valori univoci nella colonna dell'identificatore della serie temporale x il numero di elementi
- Problema di regressione: 200 x il numero di elementi
Acquisisci variante
Il set di dati deve rispecchiare la diversità dello spazio dei problemi. Più esempi diversi vengono mostrati a un modello durante l'addestramento, più facilmente può generalizzarsi a esempi nuovi o meno comuni. Immagina se il tuo modello di vendita al dettaglio fosse stato addestrato utilizzando solo i dati di acquisto invernali. Riuscirebbe a prevedere con successo le preferenze o i comportamenti di acquisto per l'abbigliamento estivo?
Testo
Dopo aver stabilito quali dati ti serviranno, devi trovare un modo per ottenerli. Puoi iniziare tenendo conto di tutti i dati raccolti dalla tua organizzazione. Potresti scoprire di raccogliere già i dati di cui hai bisogno per addestrare un modello. Se non disponi dei dati di cui hai bisogno, puoi ottenerli manualmente o esternalizzarli a un fornitore di terze parti.
Includi esempi etichettati sufficienti in ogni categoria
La probabilità di riconoscere correttamente un'etichetta aumenta con il numero di esempi di alta qualità per ciascuna. In generale, più dati etichettati puoi fornire al processo di addestramento, migliore sarà il tuo modello. Il numero di campioni necessari varia anche in base al grado di coerenza dei dati che vuoi prevedere e al livello di accuratezza target. Puoi utilizzare meno esempi per set di dati coerenti o per ottenere una precisione dell'80% anziché del 97%.
Addestra un modello e poi valuta i risultati. Aggiungi altri esempi e
esegui nuovamente l'addestramento fino a raggiungere i tuoi obiettivi di accuratezza, il che potrebbe richiedere centinaia o addirittura migliaia di
esempi per etichetta. Per ulteriori informazioni sui requisiti e sui consigli per i dati, consulta
Preparazione
dei dati di addestramento testo per i modelli AutoML.
Distribuisci gli esempi in modo uniforme tra le categorie
È importante acquisire un numero approssimativamente simile di esempi di addestramento per ogni categoria. Anche se hai molti dati per un'etichetta, è meglio avere una distribuzione equa per ogni etichetta. Per capire perché, immagina che l'80% dei commenti dei clienti che utilizzi per creare il tuo modello sia costituito da richieste di preventivo. Con una distribuzione così sbilanciata delle etichette, è molto probabile che il modello impari che è sicuro dirti sempre che un commento del cliente è una richiesta di preventivo, anziché provare a prevedere un'etichetta molto meno comune. È come scrivere un test a scelta multipla in cui quasi tutte le risposte corrette sono "C": presto il candidato esperto capirà che può rispondere "C" ogni volta senza nemmeno guardare la domanda.

Potrebbe non essere sempre possibile trovare un numero approssimativamente uguale di esempi per ogni etichetta. Potrebbe essere più difficile trovare esempi di alta qualità e non soggettivi per alcune categorie. In queste circostanze, l'etichetta con il numero più basso di esempi deve avere almeno il 10% degli esempi dell'etichetta con il numero più elevato di esempi. Pertanto, se l'etichetta più grande ha 10.000 esempi, l'etichetta più piccola deve avere almeno 1000 esempi.
Acquisisci la variazione nello spazio del problema
Per motivi simili, cerca di fare in modo che i dati rappresentino la varietà e la diversità del tuo spazio di problemi. Quando fornisci un insieme più ampio di esempi, il modello è in grado di generalizzare meglio ai nuovi dati. Supponiamo che tu stia cercando di classificare gli articoli sull'elettronica di consumo in base agli argomenti. Più nomi di brand e specifiche tecniche fornisci, più sarà facile per il modello capire l'argomento di un articolo, anche se l'articolo riguarda un brand che non è stato incluso nel set di addestramento. Per migliorare ulteriormente il rendimento del modello, ti consigliamo di includere anche un'etichetta"none_of_the_above" per i documenti che non corrispondono a nessuna delle etichette definite.
Abbina i dati all'output previsto per il modello

Trova esempi di testo simili a quelli su cui prevedi di fare previsioni. Se stai tentando di classificare i post sui social media sulla lavorazione del vetro, probabilmente non otterrai un ottimo rendimento da un modello addestrato su siti web di informazioni sulla lavorazione del vetro, poiché il vocabolario e lo stile potrebbero essere diversi. Idealmente, gli esempi di addestramento sono dati reali ricavati dallo stesso set di dati che prevedi di utilizzare per la classificazione del modello.
Video
Dopo aver stabilito il caso d'uso, dovrai raccogliere i dati video che ti consentiranno di creare il modello che preferisci. I dati raccolti per l'addestramento indicano il tipo di problemi che puoi risolvere. Quanti video puoi utilizzare? I video contengono esempi sufficienti per ciò che vuoi che il tuo modello preveda? Quando raccogli i dati dei tuoi video, tieni presenti le seguenti considerazioni.
Includi un numero sufficiente di video
In genere, più sono i video di addestramento nel set di dati, migliore sarà il risultato. Il numero di
video consigliati varia anche in base alla complessità del problema che stai cercando di risolvere. Ad esempio, per la classificazione, avrai bisogno di meno dati video per un problema di classificazione binaria (previsione di una classe da due) rispetto a un problema con più etichette (previsione di una o più classi da molte).
La complessità di ciò che stai cercando di fare determina anche la quantità di dati video di cui hai bisogno. Prendiamo in considerazione il caso d'uso per la classificazione del calcio, ovvero la creazione di un modello per distinguere gli scatti in azione, rispetto all'addestramento di un modello in grado di classificare diversi stili di nuotata. Ad esempio, per distinguere tra nuotata a rana, a delfino, a dorso e così via, sono necessari più dati di addestramento per identificare i diversi stili di nuotata e aiutare il modello a imparare a identificare con precisione ogni tipo. Consulta Preparazione dei dati video per informazioni su come capire le esigenze minime di dati video per il riconoscimento, la classificazione e il monitoraggio degli oggetti.
La quantità di dati video richiesta potrebbe essere superiore a quella di cui disponi al momento. Valuta la possibilità di ottenere altri video tramite un fornitore di terze parti. Ad esempio, potresti acquistare o ottenere altri video di colibrì se non ne hai abbastanza per il tuo modello di identificatore di azioni di gioco.
Distribuisci i video in modo uniforme tra i corsi
Cerca di fornire un numero simile di esempi di addestramento per ogni classe. Ecco perché: immagina che
l'80% del tuo set di dati di addestramento sia costituito da video di calcio che mostrano tiri in porta, ma solo il 20% dei video raffigura falli personali o calci di rigore. Con una distribuzione così diseguale delle classi, il tuo modello è più propenso a prevedere che una determinata azione sia un obiettivo. È simile alla stesura di un esame a scelta multipla in cui l'80% delle risposte corrette è "C": il modello esperto capirà rapidamente che "C" è una buona supposizione nella maggior parte dei casi.

Potrebbe non essere possibile trovare un numero uguale di video per ogni lezione. Anche esempi di alta qualità e imparziali possono essere difficili per alcuni corsi. Prova a seguire un rapporto di 1:10: se il corso più grande contiene 10.000 video, il più piccolo deve contenere almeno 1000 video.
Acquisisci variante
I dati video devono rispecchiare la diversità dello spazio dei problemi. Più esempi diversi vengono mostrati a un modello durante l'addestramento, più facilmente può generalizzarsi a esempi nuovi o meno comuni. Pensa al modello di classificazione delle azioni di calcio: assicurati di includere video con diversi angoli di ripresa, riprese di giorno e di notte e una varietà di movimenti dei giocatori. L'esposizione del modello a una diversità di dati migliora la sua capacità di distinguere un'azione da un'altra.
Abbina i dati all'output previsto

Trova video di addestramento visivamente simili ai video che prevedi di inserire nel modello per la previsione. Ad esempio, se tutti i video di addestramento sono stati girati in inverno o la sera, l'illuminazione e i motivi di colore in questi ambienti influiranno sul tuo modello. Se poi utilizzi questo modello per testare i video realizzati in estate o in pieno giorno, potresti non ricevere previsioni accurate.
Valuta questi fattori aggiuntivi: risoluzione video, frame al secondo, angolazione della videocamera, sfondo.
Preparare i dati
Immagine
 Dopo aver deciso quale sia la soluzione più adatta a te, una suddivisione manuale o quella predefinita, puoi aggiungere dati in Vertex AI utilizzando uno dei seguenti metodi:
Dopo aver deciso quale sia la soluzione più adatta a te, una suddivisione manuale o quella predefinita, puoi aggiungere dati in Vertex AI utilizzando uno dei seguenti metodi:
- Puoi importare i dati dal computer o da Cloud Storage in un formato disponibile (CSV o JSON Lines) con le etichette (e le caselle delimitanti, se necessario) in linea. Per saperne di più sul formato del file di importazione, consulta Preparare i dati di addestramento. Se vuoi suddividere manualmente il set di dati, puoi specificare le suddivisioni nel file di importazione CSV o righe JSON.
- Se i dati non sono stati annotati, puoi caricare immagini non etichettate e utilizzare la console Google Cloud per applicare le annotazioni. Puoi gestire queste annotazioni in più insiemi di annotazioni per lo stesso insieme di immagini. Ad esempio, per un singolo insieme di immagini puoi avere un set di annotazioni con informazioni su riquadri di delimitazione ed etichette per il rilevamento degli oggetti e un altro set di annotazioni con solo annotazioni delle etichette per la classificazione.
Tabulare
Dopo aver identificato i dati disponibili, devi assicurarti che siano pronti per l'addestramento.
Se i dati sono parziali o contengono valori mancanti o errati, la qualità del modello ne risente. Prendi in considerazione quanto segue prima di iniziare ad addestrare il modello.
Scopri di più.
Evita la fuga di dati e il disallineamento tra addestramento e distribuzione
La fuga di dati si verifica quando utilizzi le funzionalità di input durante l'addestramento che "rilasciano" informazioni sul target che stai cercando di prevedere e che non è disponibile quando il modello viene effettivamente pubblicato. Questo può essere rilevato quando una funzionalità altamente correlata alla colonna di destinazione è inclusa come una delle funzionalità di input. Ad esempio, se stai creando un modello per prevedere se un cliente sottoscriverà un abbonamento nel mese successivo e una delle funzionalità di input è un pagamento futuro dell'abbonamento da parte del cliente. Ciò può portare a un ottimo rendimento del modello durante i test, ma non quando viene implementato in produzione, poiché i dati di pagamento per gli abbonamenti futuri non sono disponibili al momento della pubblicazione.
Il disallineamento addestramento/produzione si verifica quando le funzionalità di input utilizzate durante l'addestramento sono diverse da quelle fornite al modello al momento della pubblicazione, causando una scarsa qualità del modello in produzione. Ad esempio, creare un modello per prevedere le temperature orarie, ma addestrarlo con dati che contengono solo temperature settimanali. Un altro esempio: fornire sempre i voti di uno studente nei dati di addestramento per prevedere l'abbandono scolastico, ma non fornire queste informazioni al momento della pubblicazione.
Comprendere i dati di addestramento è importante per evitare la fuga di dati e il disallineamento tra addestramento e distribuzione:
- Prima di utilizzare qualsiasi dato, assicurati di sapere cosa significano e se devi o meno utilizzarli come funzionalità
- Controlla la correlazione nella scheda Addestramento. Le correlazioni elevate devono essere segnalate per la revisione.
- Disallineamento addestramento/produzione: assicurati di fornire al modello solo le funzionalità di input disponibili nello stesso identico formato al momento della pubblicazione.
Pulire i dati mancanti, incompleti e incoerenti
È normale che nei dati di esempio siano presenti valori mancanti e inesatti. Prenditi il tempo di esaminare e, se possibile, migliorare la qualità dei dati prima di utilizzarli per l'addestramento. Maggiore è il numero di valori mancanti, meno utili saranno i dati per l'addestramento di un modello di machine learning.
- Controlla se nei dati sono presenti valori mancanti e correggili, se possibile, oppure lascia vuoto il valore se la colonna è impostata come nullable. Vertex AI può gestire i valori mancanti, ma è più probabile che tu ottenga risultati ottimali se sono disponibili tutti i valori.
- Per le previsioni, verifica che l'intervallo tra le righe di addestramento sia coerente. Vertex AI può imputare i valori mancanti, ma è più probabile che tu ottenga risultati ottimali se sono disponibili tutte le righe.
- Pulisci i dati correggendo o eliminando gli errori o il rumore. Rendi coerenti i dati: controlla l'ortografia, le abbreviazioni e la formattazione.
Analizzare i dati dopo l'importazione
Vertex AI fornisce una panoramica del set di dati dopo l'importazione. Esamina il set di dati importato per assicurarti che ogni colonna abbia il tipo di variabile corretto. Vertex AI rileverà automaticamente il tipo di variabile in base ai valori delle colonne, ma è meglio esaminarle tutte. Devi anche esaminare la nullabilità di ogni colonna, che determina se una colonna può avere valori mancanti o NULL.
Testo
Dopo aver deciso quale sia la soluzione più adatta a te, se una suddivisione manuale o quella predefinita, puoi aggiungere i dati in Vertex AI utilizzando uno dei seguenti metodi:
- Puoi importare i dati dal computer o da Cloud Storage nel formato CSV o Righe JSON con le etichette in linea, come specificato in Preparazione dei dati di addestramento. Se vuoi suddividere il set di dati manualmente, puoi specificare le suddivisioni nel file CSV o JSON Lines.
- Se i dati non sono stati etichettati, puoi caricare esempi di testo non etichettati e utilizzare la console Vertex AI per applicare le etichette.
Video
Dopo aver raccolto i video che vuoi includere nel set di dati, devi assicurarti che contengano etichette associate a segmenti di video o riquadri di delimitazione. Per il riconoscimento delle azioni, il segmento video è un timestamp, mentre per la classificazione può essere un'inquadratura video, un segmento o l'intero video. Per il monitoraggio degli oggetti, le etichette sono associate ai riquadri di delimitazione.
Perché i miei video hanno bisogno di caselle delimitanti ed etichette?
Per il monitoraggio degli oggetti, in che modo un modello Vertex AI impara a identificare gli schemi? È a questo scopo che servono i riquadri di delimitazione e le etichette durante l'addestramento. Prendiamo l'esempio del calcio: ogni video di esempio dovrà contenere riquadri di delimitazione intorno agli oggetti che ti interessa rilevare. A queste caselle devono essere assegnate anche etichette come "persona" e "palla". In caso contrario, il modello non saprà cosa cercare. Disegnare riquadri e assegnare etichette ai video di esempio può richiedere del tempo.
Se i tuoi dati non sono ancora stati etichettati, puoi anche caricare i video non etichettati e utilizzare la console Google Cloud per applicare caselle delimitanti ed etichette. Per ulteriori informazioni, consulta Etichettare i dati utilizzando la console Google Cloud.
Addestramento del modello
Immagine
Considera in che modo Vertex AI utilizza il tuo set di dati per creare un modello personalizzato
Il set di dati contiene set di addestramento, convalida e test. Se non specifichi le suddivisioni
(vedi Preparare i dati), Vertex AI utilizza automaticamente l'80% delle immagini per l'addestramento,
il 10% per la convalida e il 10% per i test.
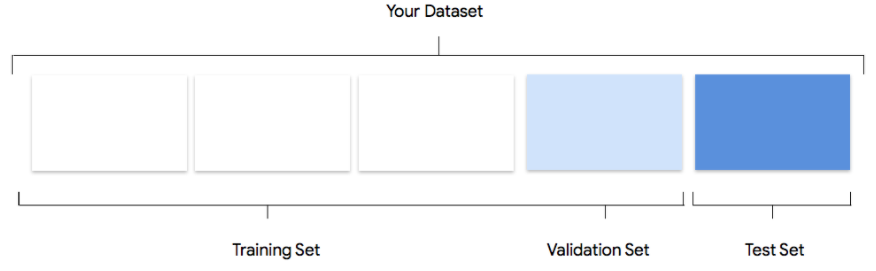
Set di addestramento
 La maggior parte dei dati dovrebbe essere presente nel set di addestramento. Questi sono i dati che il modello "vede"
durante l'addestramento: vengono utilizzati per apprendere i parametri del modello, ossia i pesi delle
connessioni tra i nodi della rete neurale.
La maggior parte dei dati dovrebbe essere presente nel set di addestramento. Questi sono i dati che il modello "vede"
durante l'addestramento: vengono utilizzati per apprendere i parametri del modello, ossia i pesi delle
connessioni tra i nodi della rete neurale.
Set di convalida
 Il set di convalida, talvolta chiamato anche set "dev", viene utilizzato anche durante il processo di addestramento.
Dopo che i dati di addestramento sono stati incorporati durante ogni iterazione del processo di addestramento, il framework di apprendimento del modello utilizza le prestazioni del modello sul set di convalida per ottimizzarne gli iperparametri, che sono variabili che specificano la struttura del modello. Se si cercasse di utilizzare il set di addestramento per ottimizzare gli iperparametri, è molto probabile che il modello finirebbe per concentrarsi eccessivamente sui dati di addestramento e avrebbe difficoltà a generalizzare in base a esempi che non corrispondono esattamente.
L'utilizzo di un set di dati nuovo per ottimizzare la struttura del modello consente una migliore generalizzazione da parte del modello.
Il set di convalida, talvolta chiamato anche set "dev", viene utilizzato anche durante il processo di addestramento.
Dopo che i dati di addestramento sono stati incorporati durante ogni iterazione del processo di addestramento, il framework di apprendimento del modello utilizza le prestazioni del modello sul set di convalida per ottimizzarne gli iperparametri, che sono variabili che specificano la struttura del modello. Se si cercasse di utilizzare il set di addestramento per ottimizzare gli iperparametri, è molto probabile che il modello finirebbe per concentrarsi eccessivamente sui dati di addestramento e avrebbe difficoltà a generalizzare in base a esempi che non corrispondono esattamente.
L'utilizzo di un set di dati nuovo per ottimizzare la struttura del modello consente una migliore generalizzazione da parte del modello.
Set di test
 Il set di test non è coinvolto in nessun modo nel processo di addestramento. Al termine dell'addestramento del modello, utilizziamo il set di test come risorsa di verifica completamente nuova per il modello. Le prestazioni del modello in base al set di test hanno lo scopo di dare un'idea abbastanza precisa di come il modello si comporterà utilizzando dati reali.
Il set di test non è coinvolto in nessun modo nel processo di addestramento. Al termine dell'addestramento del modello, utilizziamo il set di test come risorsa di verifica completamente nuova per il modello. Le prestazioni del modello in base al set di test hanno lo scopo di dare un'idea abbastanza precisa di come il modello si comporterà utilizzando dati reali.
Suddivisione manuale
 Puoi anche suddividere autonomamente il tuo set di dati. La suddivisione manuale dei dati è una buona scelta se
vuoi esercitare un maggiore controllo sul processo o se esistono esempi specifici che
vuoi includere in una determinata parte del ciclo di vita dell'addestramento del modello.
Puoi anche suddividere autonomamente il tuo set di dati. La suddivisione manuale dei dati è una buona scelta se
vuoi esercitare un maggiore controllo sul processo o se esistono esempi specifici che
vuoi includere in una determinata parte del ciclo di vita dell'addestramento del modello.
Tabulare
Dopo aver importato il set di dati, il passaggio successivo consiste nell'addestrare un modello. Vertex AI genererà un modello di machine learning affidabile con i valori predefiniti per l'addestramento, ma ti consigliamo di modificare alcuni dei parametri in base al tuo caso d'uso.
Cerca di selezionare il maggior numero possibile di colonne di funzionalità per l'addestramento, ma controllane ciascuna per assicurarti che sia appropriata per l'addestramento. Tieni presente quanto segue per la selezione delle funzionalità:
- Non selezionare colonne di funzionalità che generano rumore, ad esempio colonne di identificatori assegnati in modo casuale con un valore univoco per ogni riga.
- Assicurati di comprendere ogni colonna delle funzionalità e i relativi valori.
- Se stai creando più modelli da un set di dati, rimuovi le colonne di destinazione che non fanno parte del problema di previsione attuale.
- Ricorda i principi di equità: stai addestrando il tuo modello con una funzionalità che potrebbe portare a decisioni biased o ingiuste per i gruppi emarginati?
Come Vertex AI utilizza il tuo set di dati
Il set di dati verrà suddiviso in set di addestramento, convalida e test. La suddivisione predefinita applicata da Vertex AI dipende dal tipo di modello che stai addestrando. Se necessario, puoi anche specificare le suddivisioni (suddivisioni manuali). Per ulteriori informazioni, consulta Informazioni sulle suddivisioni di dati per i modelli AutoML.
Set di addestramento
La maggior parte dei dati dovrebbe essere presente nel set di addestramento. Questi sono i dati che il modello "vede"
durante l'addestramento: vengono utilizzati per apprendere i parametri del modello, ossia i pesi delle
connessioni tra i nodi della rete neurale.
Set di convalida
Il set di convalida, talvolta chiamato anche set "dev", viene utilizzato anche durante il processo di addestramento.
Dopo che i dati di addestramento sono stati incorporati durante ogni iterazione del processo di addestramento, il framework di apprendimento del modello utilizza le prestazioni del modello sul set di convalida per ottimizzarne gli iperparametri, che sono variabili che specificano la struttura del modello. Se si cercasse di utilizzare il set di addestramento per ottimizzare gli iperparametri, è molto probabile che il modello finirebbe per concentrarsi eccessivamente sui dati di addestramento e avrebbe difficoltà a generalizzare in base a esempi che non corrispondono esattamente.
L'utilizzo di un set di dati nuovo per ottimizzare la struttura del modello consente una migliore generalizzazione da parte del modello.
Set di test
Il set di test non è coinvolto in nessun modo nel processo di addestramento. Al termine dell'addestramento del modello, Vertex AI utilizza il set di test come risorsa di verifica completamente nuova per il modello.
Le prestazioni del modello in base al set di test hanno lo scopo di dare un'idea abbastanza precisa di come il modello si comporterà utilizzando dati reali.
Testo
Considera in che modo Vertex AI utilizza il tuo set di dati per creare un modello personalizzato
Il set di dati contiene set di addestramento, convalida e test. Se non specifichi le suddivisioni come spiegato in Preparare i dati, Vertex AI utilizza automaticamente l'80% dei documenti dei contenuti per l'addestramento, il 10% per la convalida e il 10% per i test.
Set di addestramento
La maggior parte dei dati dovrebbe essere presente nel set di addestramento. Questi sono i dati che il modello "vede"
durante l'addestramento: vengono utilizzati per apprendere i parametri del modello, ossia i pesi delle
connessioni tra i nodi della rete neurale.
Set di convalida
Il set di convalida, talvolta chiamato anche set "dev", viene utilizzato anche durante il processo di addestramento.
Dopo che i dati di addestramento sono stati incorporati durante ogni iterazione del processo di addestramento, il framework di apprendimento del modello utilizza le prestazioni del modello sul set di convalida per ottimizzarne gli iperparametri, che sono variabili che specificano la struttura del modello. Se si cercasse di utilizzare il set di addestramento per ottimizzare gli iperparametri, è molto probabile che il modello finirebbe per concentrarsi eccessivamente sui dati di addestramento e avrebbe difficoltà a generalizzare in base a esempi che non corrispondono esattamente.
L'utilizzo di un set di dati nuovo per ottimizzare la struttura del modello consente una migliore generalizzazione da parte del modello.
Set di test
Il set di test non è coinvolto in nessun modo nel processo di addestramento. Al termine dell'addestramento del modello, utilizziamo il set di test come risorsa di verifica completamente nuova per il modello. Le prestazioni del modello in base al set di test hanno lo scopo di dare un'idea abbastanza precisa di come il modello si comporterà utilizzando dati reali.
Suddivisione manuale
Puoi anche suddividere autonomamente il tuo set di dati. La suddivisione manuale dei dati è una buona scelta se
vuoi esercitare un maggiore controllo sul processo o se esistono esempi specifici che
vuoi includere in una determinata parte del ciclo di vita dell'addestramento del modello.
Video
Dopo aver preparato i dati dei video di addestramento, puoi creare un modello di machine learning. Tieni presente che puoi creare set di annotazioni per obiettivi del modello diversi nello stesso set di dati. Consulta Creare un set di annotazioni.
Uno dei vantaggi di Vertex AI è che i parametri predefiniti ti guideranno verso un modello di machine learning affidabile. Tuttavia, potresti dover modificare i parametri in base alla qualità dei dati e al risultato che stai cercando. Ad esempio:
- Il tipo di previsione indica il livello di granularità con cui vengono elaborati i tuoi video.
- La frequenza fotogrammi è importante se le etichette che stai cercando di classificare sono sensibili alle variazioni di movimento, come nel riconoscimento di azioni. Ad esempio, correre rispetto a camminare. Un clip di camminata con un numero basso di frame al secondo (FPS) potrebbe sembrare una corsa. Anche il monitoraggio degli oggetti è sensibile al frame rate. In sostanza, l'oggetto da monitorare deve avere una sovrapposizione sufficiente tra i fotogrammi adiacenti.
- La risoluzione per il monitoraggio degli oggetti è più importante che per il riconoscimento delle azioni o la classificazione video. Quando gli oggetti sono piccoli, assicurati di caricare video con una risoluzione più elevata. L'attuale pipeline utilizza 256 x 256 per l'addestramento regolare o 512 x 512 se nei dati utente sono presenti troppi oggetti di piccole dimensioni (la cui area è inferiore all'1% dell'area dell'immagine). Ti consigliamo di utilizzare video con una risoluzione minima di 256p. L'utilizzo di video a risoluzione più elevata potrebbe non contribuire a migliorare il rendimento del modello perché internamente i frame video vengono sottocampionati per aumentare la velocità di addestramento e di inferenza.
Valuta, testa ed esegui il deployment del modello
Valuta il modello
Immagine
Una volta addestrato il modello, riceverai un riepilogo delle relative prestazioni. Fai clic su Valuta o Vedi valutazione completa per visualizzare un'analisi dettagliata.
 Il debug di un modello riguarda più i dati che il modello stesso. Se in un determinato momento il tuo
modello inizia a comportarsi in modo imprevisto durante la valutazione del suo rendimento prima e
dopo l'implementazione in produzione, devi tornare indietro e controllare i dati per capire dove potrebbe essere
migliorato.
Il debug di un modello riguarda più i dati che il modello stesso. Se in un determinato momento il tuo
modello inizia a comportarsi in modo imprevisto durante la valutazione del suo rendimento prima e
dopo l'implementazione in produzione, devi tornare indietro e controllare i dati per capire dove potrebbe essere
migliorato.
Quali tipi di analisi posso eseguire in Vertex AI?
Nella sezione di valutazione di Vertex AI, puoi valutare le prestazioni del tuo modello personalizzato utilizzando l'output del modello sugli esempi di test e le metriche di machine learning comuni. In questa sezione spiegheremo il significato di ciascuno di questi concetti.
- L'output del modello
- La soglia di punteggio
- Veri positivi, veri negativi, falsi positivi e falsi negativi
- Precisione e richiamo
- Curve di precisione/richiamo
- Precisione media
Come faccio a interpretare l'output del modello?
Vertex AI estrae esempi dai dati di test per presentare sfide completamente nuove per il tuo
modello. Per ogni esempio, il modello genera una serie di numeri che indicano la forza con cui associa ogni etichetta all'esempio. Se il numero è elevato, il modello ha un'elevata certezza
che l'etichetta debba essere applicata al documento.

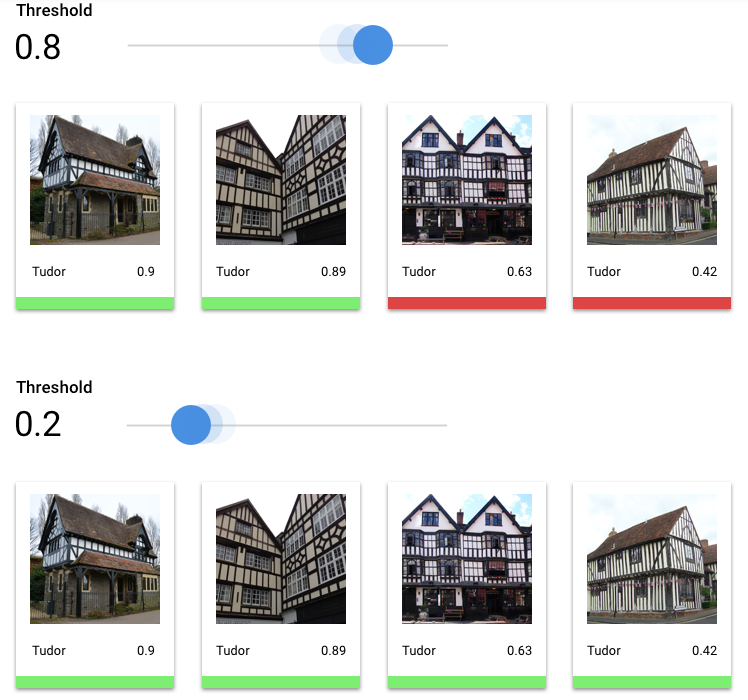
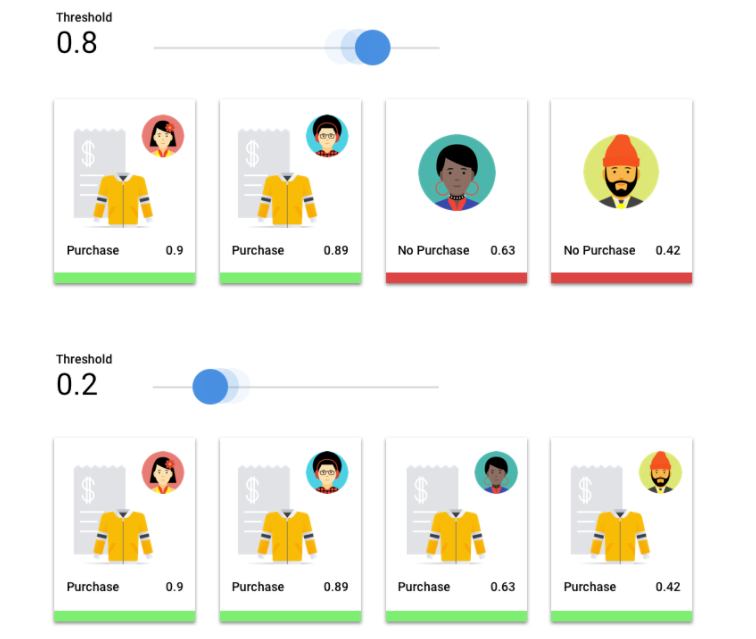
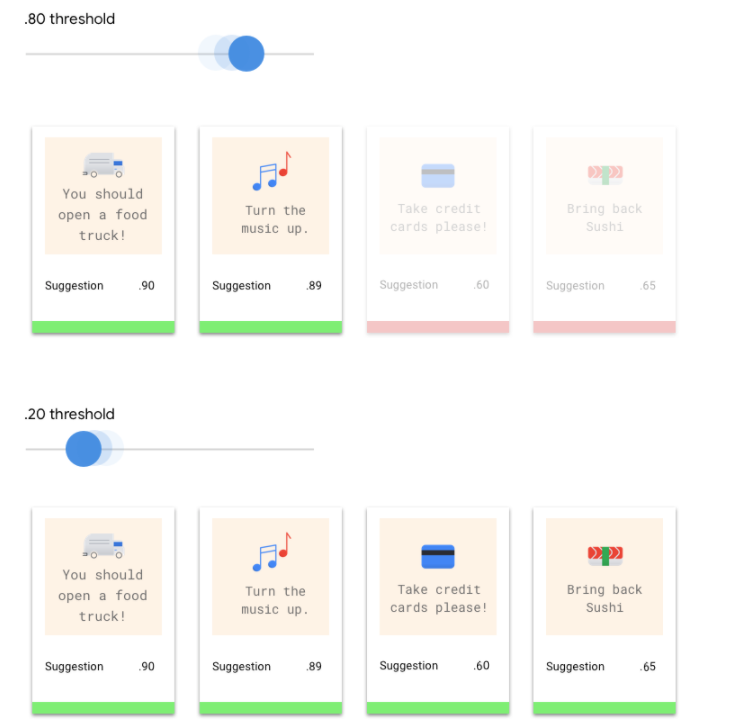
Che cos'è la soglia di punteggio?
Possiamo convertire queste probabilità in valori binari "on"/"off" impostando una soglia di punteggio.
La soglia di punteggio si riferisce al livello di confidenza che il modello deve avere per assegnare una categoria a un elemento di test. Il cursore della soglia del punteggio nella console Google Cloud è uno strumento visivo per testare
l'effetto di soglie diverse per tutte le categorie e le singole categorie nel tuo set di dati.
Se la soglia di punteggio è bassa, il modello classificherà più immagini, ma rischia di classificare erroneamente alcune immagini durante la procedura. Se la soglia di punteggio è elevata, il modello classifica meno immagini, ma ha un rischio inferiore di classificarle erroneamente. Per eseguire esperimenti, puoi modificare le soglie per categoria nella console Google Cloud. Tuttavia, quando utilizzi il modello in produzione, devi applicare le soglie che hai trovato ottimali.
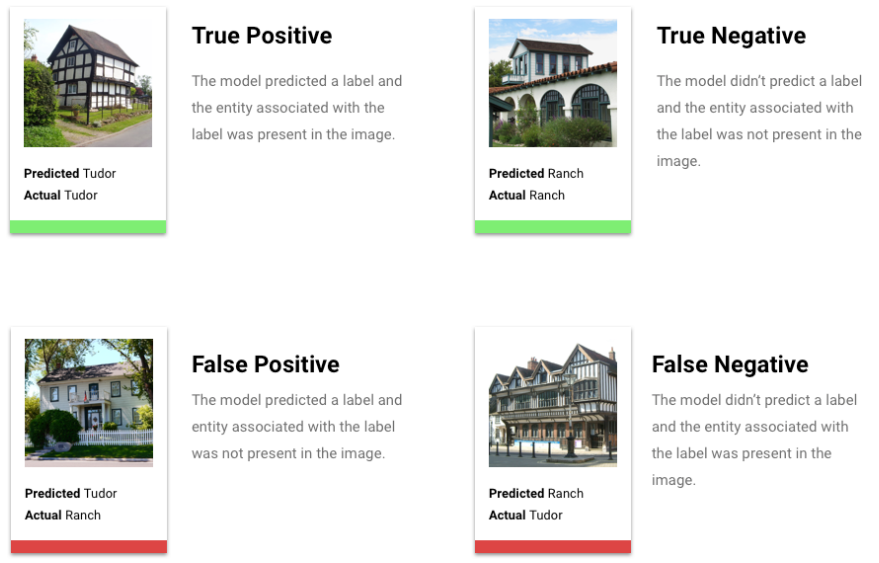
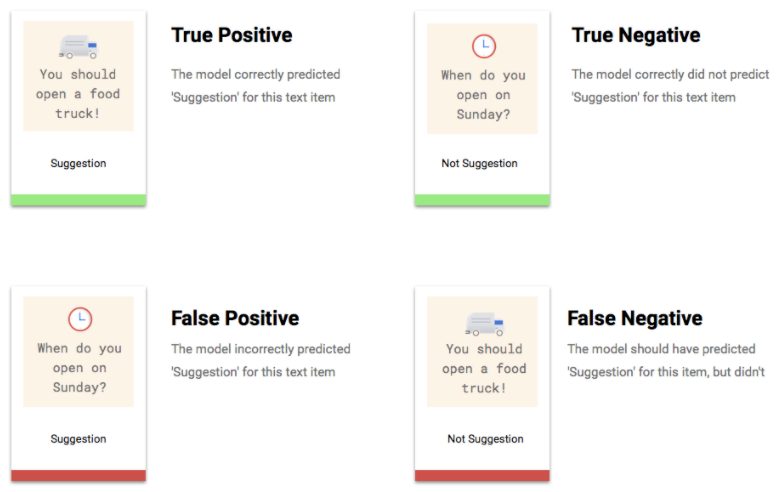
Che cosa sono i veri positivi, i veri negativi, i falsi positivi e i falsi negativi?
Dopo aver applicato la soglia di punteggio, le previsioni effettuate dal modello rientrano in una delle seguenti quattro categorie:
Le soglie che hai trovato ottimali per te.
Possiamo utilizzare queste categorie per calcolare la precisione e il richiamo, metriche che ci aiutano a valutare l'efficacia del nostro modello.
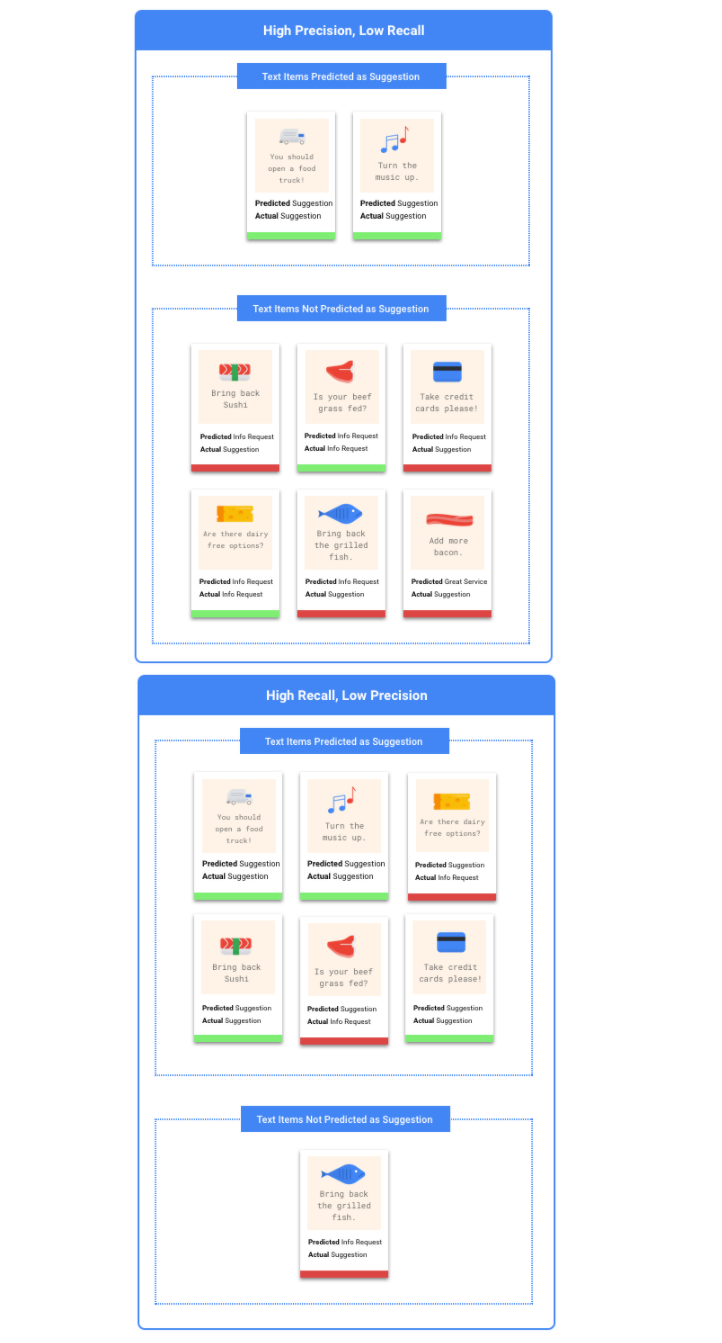
Che cosa sono la precisione e il richiamo?
La precisione e il richiamo ci aiutano a capire se il nostro modello sta acquisendo informazioni adeguate e quanto
sta tralasciando. La precisione ci dice, tra tutti gli esempi di test a cui è stata assegnata un'etichetta, quanti dovevano effettivamente essere classificati con quell'etichetta. Il richiamo ci dice, tra tutti gli esempi di test a cui avrebbe dovuto essere assegnata l'etichetta, a quanti è stata effettivamente assegnata.
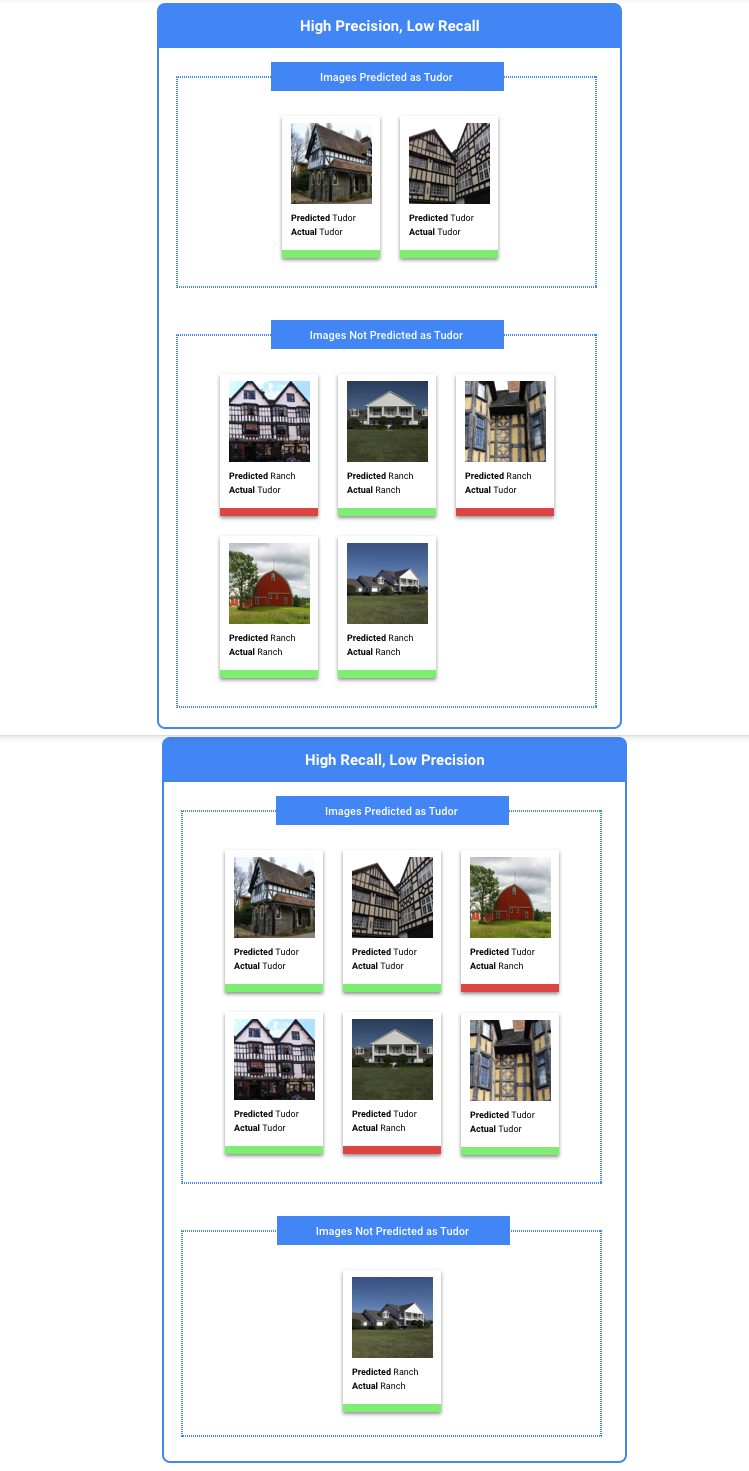
Devo ottimizzare per la precisione o il richiamo?
A seconda del caso d'uso, ti consigliamo di ottimizzare la precisione o il richiamo. Valuta i seguenti due casi d'uso per decidere quale approccio è più adatto alle tue esigenze.
Caso d'uso: privacy nelle immagini
Supponiamo che tu voglia creare un sistema che rileva automaticamente le informazioni sensibili e le offusca.

In questo caso, i falsi positivi sono elementi che non devono essere sfocati, ma lo sono,
il che può essere fastidioso, ma non dannoso.

In questo caso, i falsi negativi sono elementi che devono essere sfocati, ma non lo sono, come una carta di credito, il che può portare al furto d'identità.
In questo caso, ti consigliamo di ottimizzare per il recupero. Questa metrica misura, per tutte le predizioni effettuate, quanto viene omesso. Un modello con un alto valore di richiamo è probabile che etichetti esempi marginalmente pertinenti. Questo è utile nei casi in cui la categoria abbia dati di addestramento scarsi.
Caso d'uso: ricerca di foto stock
Supponiamo che tu voglia creare un sistema che trovi la foto stock migliore per una determinata parola chiave.

Un falso positivo in questo caso potrebbe essere la restituzione di un'immagine non pertinente. Poiché il tuo prodotto si vanta di restituire solo le immagini con la migliore corrispondenza, questo sarebbe un errore grave.

Un falso negativo in questo caso potrebbe essere il mancato ritorno di un'immagine pertinente per una ricerca per parole chiave.
Dato che molti termini di ricerca hanno migliaia di foto che rappresentano una potenziale corrispondenza, non c'è problema.
In questo caso, ti consigliamo di ottimizzare per la precisione. Questa metrica misura l'accuratezza di tutte le stime effettuate. Un modello ad alta precisione è probabile che etichetti solo gli esempi più pertinenti, il che è utile nei casi in cui la classe è comune nei dati di addestramento.
Come faccio a utilizzare la matrice di confusione?
Come faccio a interpretare le curve di precisione-richiamo?
Lo strumento Soglia di punteggio ti consente di esplorare l'impatto della soglia di punteggio scelta sulla precisione e sul richiamo. Mentre trascini il dispositivo di scorrimento sulla barra della soglia di punteggio, puoi vedere dove ti trovi con questa
soglia sulla curva di compromesso precisione-richiamo, nonché in che modo la soglia influisce sulla precisione e sul richiamo singolarmente (per i modelli multiclasse, su questi grafici, precisione
e richiamo indicano che l'unica etichetta utilizzata per calcolare le metriche di precisione e richiamo è l'etichetta con il punteggio più alto
nell'insieme di etichette restituite). In questo modo puoi trovare un buon equilibrio tra falsi positivi e falsi negativi.
Dopo aver scelto una soglia che sembra accettabile per il modello nel suo complesso, fai clic sulle singole etichette e controlla dove si trova la soglia sulla curva di precisione-richiamo per etichetta. In alcuni casi, potresti ottenere molte previsioni errate per alcune etichette, il che potrebbe aiutarti a decidere di scegliere una soglia per classe personalizzata per queste etichette. Ad esempio, supponiamo che tu esamini il tuo set di dati di case e noti che una soglia pari a 0,5 ha una precisione e un richiamo ragionevoli per ogni tipo di immagine tranne per "Tudor", forse perché si tratta di una categoria molto generica. Per questa categoria, vengono visualizzati molti falsi positivi. In questo caso, potresti decidere di utilizzare una soglia di 0,8 solo per "Tudor" quando chiami il classificatore per le previsioni.
Che cos'è la precisione media?
Una metrica utile per l'accuratezza del modello è l'area sotto la curva di precisione-richiamo. Misura il rendimento del modello per tutte le soglie di punteggio. In Vertex AI, questa metrica si chiama Precisione media. Più questo punteggio è vicino a 1,0, migliori sono le prestazioni del modello sul set di test. Un modello che indovina a caso per ogni etichetta otterrebbe una precisione media di circa 0,5.
Tabulare
Dopo l'addestramento del modello, riceverai un riepilogo delle relative prestazioni. Le metriche di valutazione del modello si basano sul rendimento del modello rispetto a un'estrazione del set di dati (il set di dati di test). Esistono alcune metriche e alcuni concetti chiave da considerare per determinare se il modello è pronto per essere utilizzato con dati reali.
Metriche di classificazione
Soglia punteggio
Prendiamo in considerazione un modello di machine learning che prevede se un cliente acquisterà una giacca nel prossimo anno. Quanto deve essere attendibile il modello prima di prevedere che un determinato cliente acquisterà un'ecopelle? Nei modelli di classificazione, a ogni previsione viene assegnato un punteggio di affidabilità, ovvero una valutazione numerica del livello di certezza del modello che la classe prevista sia corretta. La soglia di punteggio è il numero che determina quando un determinato punteggio viene convertito in una decisione di sì o no, ovvero il valore a cui il modello dice "sì, questo punteggio di attendibilità è sufficientemente elevato per concludere che questo cliente acquisterà un cappotto entro il prossimo anno".
Se la soglia del punteggio è bassa, il modello rischia di eseguire una classificazione errata. Per questo motivo, la soglia del punteggio deve essere basata su un determinato caso d'uso.
Risultati della previsione
Dopo aver applicato la soglia di punteggio, le previsioni effettuate dal modello rientrano in una delle quattro categorie. Per comprendere queste categorie, immagina di nuovo un modello di classificazione binaria per le giacche. In questo esempio, la classe positiva (ciò che il modello sta tentando di prevedere) è che il cliente acquisterà una giacca nel prossimo anno.
- Vero positivo: il modello prevede correttamente la classe positiva. Il modello ha previsto correttamente che un cliente ha acquistato una giacca.
- Falso positivo: il modello prevede erroneamente la classe positiva. Il modello ha previsto che un cliente ha acquistato una giacca, ma non l'ha fatto.
- Vero negativo: il modello prevede correttamente la classe negativa. Il modello ha previsto correttamente che un cliente non ha acquistato una giacca.
- Falso negativo: il modello prevede erroneamente una classe negativa. Il modello ha previsto che un cliente non ha acquistato una giacca, ma lo ha fatto.

Precisione e richiamo
Le metriche di precisione e richiamo ti aiutano a capire se il modello sta acquisendo informazioni adeguate e cosa sta tralasciando. Scopri di più su precisione e richiamo.
- Per precisione si intende la frazione delle previsioni positive che sono risultate corrette. Tra tutte le previsioni di acquisto di un cliente, qual è la frazione di acquisti effettivi?
- Per richiamo si intende la frazione delle righe con questa etichetta che sono state previste correttamente dal modello. Tra tutte le previsioni che un cliente potrebbe aver identificato, qual è la frazione prevista correttamente?
A seconda del caso d'uso, potrebbe essere necessario ottimizzare la precisione o il richiamo.
Altre metriche di classificazione
- AUC PR: l'area sotto la curva di precisione-richiamo (PR). Il valore va da zero a uno, dove un valore più elevato indica un modello di qualità superiore.
- AUC ROC: l'area sotto la curva della caratteristica operativa del ricevitore (ROC). L'intervallo varia da zero a uno, dove un valore più elevato indica un modello di qualità superiore.
- Precisione: la frazione delle previsioni di classificazione prodotte dal modello che sono risultate corrette.
- Perdita logaritmica: l'entropia incrociata tra le previsioni del modello e i valori target. L'intervallo va da zero a infinito, dove un valore inferiore indica un modello di qualità migliore.
- Punteggio F1: la media armonica di precisione e richiamo. F1 è una metrica utile per trovare un equilibrio tra precisione e richiamo qualora esista una distribuzione non uniforme delle classi.
Metriche di previsione e regressione
Una volta creato il modello, Vertex AI fornisce una serie di metriche standard da esaminare. Non esiste una risposta perfetta su come valutare il modello. Considera le metriche di valutazione nel contesto del tipo di problema e di ciò che vuoi ottenere con il modello. L'elenco seguente è una panoramica di alcune metriche che Vertex AI può fornire.
Errore assoluto medio (MAE)
Il MAE (Mean Absolute Error) indica la differenza media assoluta tra i valori target e quelli previsti. Misura la portata media degli errori (la differenza tra il valore target e quello previsto) in un insieme di previsioni. Inoltre, poiché utilizza valori assoluti, il MAE non prende in considerazione la direzione della relazione né indica se le prestazioni sono migliori o peggiori. Quando si valuta il MAE, un valore minore indica un modello di qualità superiore (in cui 0 rappresenta un predittore perfetto).
Errore quadratico medio (RMSE)
L'RMSE (errore quadratico medio) è la radice quadrata della media dei quadrati delle differenze tra i valori di destinazione e quelli previsti. L'RMSE è più sensibile agli outlier rispetto al MAE. Di conseguenza, se la preoccupazione principale riguarda gli errori di grande entità, l'RMSE può essere una metrica più utile da valutare. Analogamente al MAE, un valore minore indica un modello di qualità migliore (0 rappresenta un predittore perfetto).
Errore logaritmico quadratico medio (RMSLE)
L'RMSLE è l'equivalente in scala logaritmica dell'errore quadratico medio (RMSE). L'RMSLE è più sensibile agli errori relativi rispetto a quelli assoluti e tiene conto maggiormente del rendimento insoddisfacente rispetto a quello eccessivo.
Quantile osservato (solo previsione)
Per un determinato quantile target, il quantile osservato mostra la frazione effettiva dei valori osservati al di sotto dei valori di previsione del quantile specificati. Il quantile osservato mostra quanto il modello è lontano o vicino al quantile target. Una differenza minore tra i due valori indica un modello di qualità migliore.
Perdita di pinball scalata (solo previsione)
Misura la qualità di un modello in un determinato quantile target. Un numero più basso indica un modello di qualità migliore. Puoi confrontare la metrica della perdita di pinball scalata in quantili diversi per determinare l'accuratezza relativa del tuo modello tra questi quantili diversi.
Testo
Una volta addestrato il modello, riceverai un riepilogo delle relative prestazioni. Per visualizzare un'analisi dettagliata, fai clic su Valuta o Vedi valutazione completa.
Cosa devo tenere presente prima di valutare il mio modello?
Il debug di un modello riguarda più i dati che il modello stesso. Se il modello inizia a comportarsi in modo imprevisto durante la valutazione delle prestazioni prima e dopo l'implementazione in produzione, devi tornare indietro e controllare i dati per capire dove potrebbe essere migliorato.
Quali tipi di analisi posso eseguire in Vertex AI?
Nella sezione di valutazione di Vertex AI, puoi valutare le prestazioni del tuo modello personalizzato utilizzando l'output del modello su esempi di test e metriche di machine learning comuni. Questa sezione illustra il significato di ciascuno dei seguenti concetti:
- L'output del modello
- La soglia di punteggio
- Veri positivi, veri negativi, falsi positivi e falsi negativi
- Precisione e richiamo
- Curve di precisione/richiamo.
- Precisione media
Come faccio a interpretare l'output del modello?
Vertex AI estrae esempi dai dati di test per presentare nuove sfide al tuo
modello. Per ogni esempio, il modello genera una serie di numeri che indicano la forza con cui associa ogni etichetta all'esempio. Se il numero è elevato, il modello ha un'elevata certezza
che l'etichetta debba essere applicata al documento.
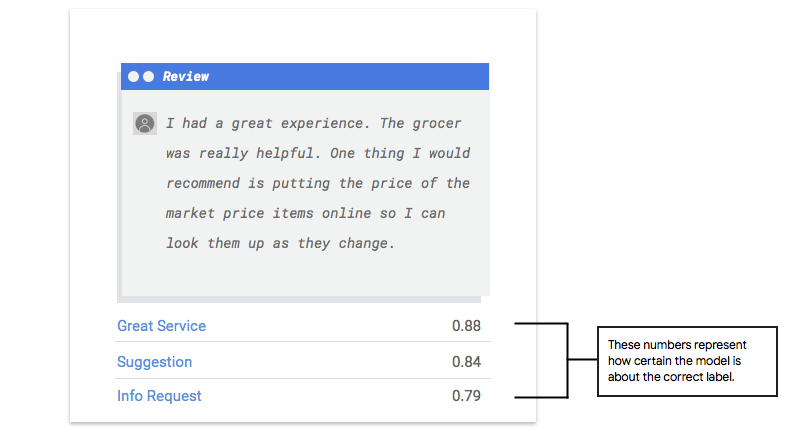
Che cos'è la soglia di punteggio?
La soglia di punteggio consente a Vertex AI di convertire le probabilità in valori binari "on"/"off". La soglia di punteggio si riferisce al livello di confidenza che il modello deve avere per assegnare una categoria a un elemento di test. Il cursore della soglia del punteggio nella console è uno strumento visivo per testare l'impatto di soglie diverse nel tuo set di dati. Nell'esempio precedente, se impostiamo la soglia del
punteggio su 0,8 per tutte le categorie, verranno assegnati "Ottimo servizio" e "Suggerimento", ma non
"Richiesta di informazioni". Se la soglia di punteggio è bassa, il modello classificherà più elementi di testo, ma rischia di classificare erroneamente più elementi di testo durante il processo. Se la soglia di punteggio è elevata, il modello classificherà meno elementi di testo, ma avrà un rischio inferiore di classificare erroneamente gli elementi di testo. Per eseguire esperimenti, puoi modificare le soglie per categoria nella console Google Cloud.
Tuttavia, quando utilizzi il tuo modello in produzione, devi applicare le soglie che hai trovato ottimali.
Che cosa sono i veri positivi, i veri negativi, i falsi positivi e i falsi negativi?
Dopo aver applicato la soglia di punteggio, le previsioni effettuate dal modello rientrano in una delle seguenti quattro categorie.
Puoi utilizzare queste categorie per calcolare la precisione e il richiamo, metriche che aiutano a valutare l'efficacia del tuo modello.
Che cosa sono la precisione e il richiamo?
La precisione e il richiamo ci aiutano a capire se il nostro modello sta acquisendo informazioni adeguate e quanto
sta tralasciando. La precisione ci dice, tra tutti gli esempi di test a cui è stata assegnata un'etichetta, quanti dovevano effettivamente essere classificati con quell'etichetta. Il richiamo ci dice, tra tutti gli esempi di test a cui avrebbe dovuto essere assegnata l'etichetta, a quanti è stata effettivamente assegnata.
Devo ottimizzare per la precisione o il richiamo?
A seconda del caso d'uso, ti consigliamo di ottimizzare la precisione o il richiamo. Valuta i seguenti due casi d'uso per decidere quale approccio è più adatto alle tue esigenze.
Caso d'uso: documenti urgenti
Supponiamo che tu voglia creare un sistema in grado di dare la priorità ai documenti urgenti rispetto a quelli non urgenti.

Un falso positivo in questo caso potrebbe essere un documento che non è urgente, ma viene contrassegnato come tale.
L'utente può ignorarli come non urgenti e passare oltre.

Un falso negativo in questo caso potrebbe essere un documento urgente, ma il sistema non riesce a segnalarlo come tale. Ciò potrebbe causare problemi.
In questo caso, ti consigliamo di ottimizzare per il recupero. Questa metrica misura, per tutte le predizioni effettuate, quanto viene omesso. Un modello con un alto valore di richiamo è probabile che etichetti esempi marginalmente pertinenti. Questo è utile nei casi in cui la categoria abbia dati di addestramento scarsi.
Caso d'uso: filtro antispam
Supponiamo che tu voglia creare un sistema che filtri automaticamente i messaggi email che sono spam da quelli che non lo sono.

Un falso negativo in questo caso potrebbe essere un'email di spam che non viene rilevata e che vedi nella Posta in arrivo. Di solito, si tratta solo di un piccolo fastidio.

Un falso positivo in questo caso potrebbe verificarsi se un'email viene contrassegnata erroneamente come spam e viene rimossa dalla Posta in arrivo. Se l'email era importante, l'utente potrebbe essere interessato negativamente.
In questo caso, ti consigliamo di ottimizzare per la precisione. Questa metrica misura l'accuratezza di tutte le stime effettuate. Un modello ad alta precisione è probabile che etichetti solo gli esempi più pertinenti, il che è utile nei casi in cui la tua categoria è comune nei dati di addestramento.
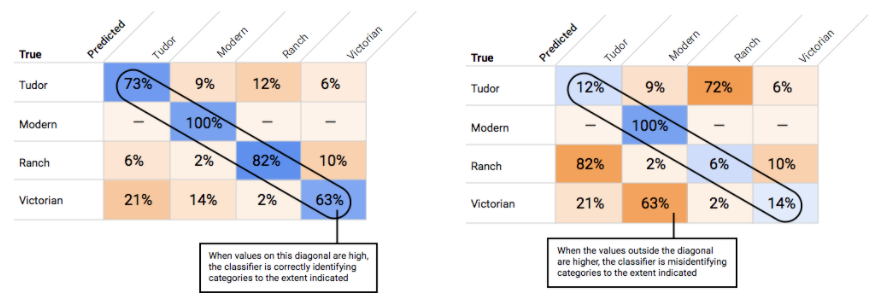
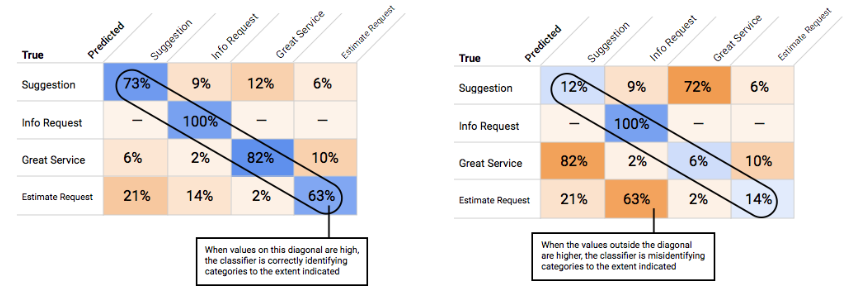
Come faccio a utilizzare la matrice di confusione?
Possiamo confrontare il rendimento del modello su ogni etichetta utilizzando una matrice di confusione. In un modello ideale, tutti i valori sulla diagonale saranno elevati e tutti gli altri saranno bassi. Ciò indica che le categorie desiderate vengono identificate correttamente. Se altri valori sono elevati, ci forniscono un indizio su come il modello sta assegnando una classificazione errata agli elementi di test.
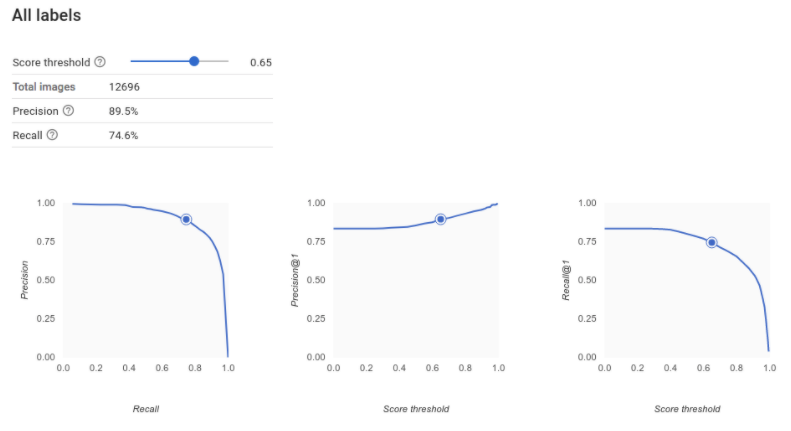
Come faccio a interpretare le curve di precisione-richiamo?
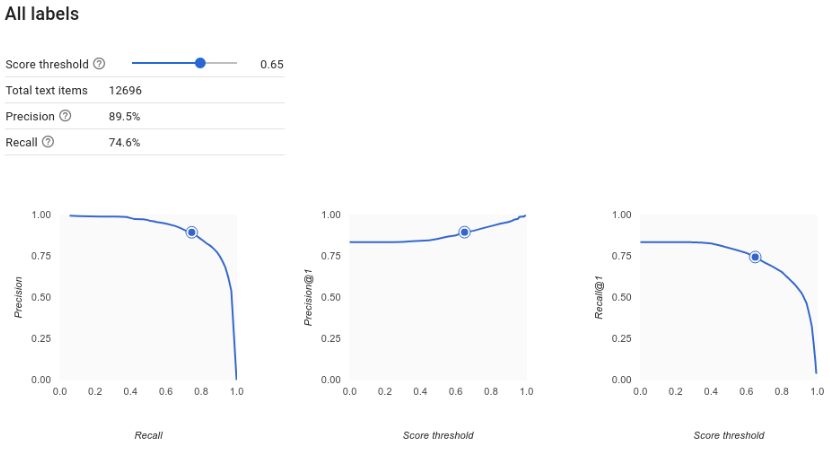
Lo strumento Soglia di punteggio ti consente di esplorare l'impatto della soglia di punteggio scelta sulla precisione e sul richiamo. Mentre trascini il dispositivo di scorrimento sulla barra della soglia di punteggio, puoi vedere dove ti trovi con questa
soglia sulla curva di compromesso precisione-richiamo, nonché in che modo la soglia influisce sulla precisione e sul richiamo singolarmente (per i modelli multiclasse, su questi grafici,
precisione e richiamo indicano che l'unica etichetta utilizzata per calcolare le metriche di precisione e richiamo è
l'etichetta con il punteggio più alto nell'insieme di etichette restituite). In questo modo potrai trovare un buon equilibrio tra falsi positivi e falsi negativi.
Dopo aver scelto una soglia che sembra accettabile per il tuo modello nel complesso, puoi fare clic sulle singole etichette e vedere dove si trova questa soglia nella curva di precisione-richiamo per etichetta. In alcuni casi, potresti ottenere molte previsioni errate per alcune etichette, il che potrebbe aiutarti a decidere di scegliere una soglia per classe personalizzata per queste etichette. Ad esempio, supponiamo che tu esamini il tuo set di dati dei commenti dei clienti e noti che una soglia di 0,5 ha una precisione e un richiamo ragionevoli per ogni tipo di commento tranne per "Suggerimento", forse perché si tratta di una categoria molto generica. Per questa categoria, vengono visualizzati molti falsi positivi. In questo caso, potresti decidere di utilizzare una soglia di 0,8 solo per "Suggerimento" quando chiami il classificatore per le previsioni.
Che cos'è la precisione media?
Una metrica utile per l'accuratezza del modello è l'area sotto la curva di precisione-richiamo. Misura il rendimento del modello per tutte le soglie di punteggio. In Vertex AI, questa metrica è chiamata Precisione media. Più questo punteggio è vicino a 1,0, migliori sono le prestazioni del modello sul set di test. Un modello che indovina a caso per ogni etichetta otterrebbe una precisione media di circa 0,5.
Video
Dopo l'addestramento del modello, riceverai un riepilogo delle relative prestazioni. Le metriche di valutazione del modello si basano sul rendimento del modello rispetto a un'estrazione del set di dati (il set di dati di test). Esistono alcuni concetti e metriche chiave da considerare per determinare se il modello è pronto per essere utilizzato con nuovi dati.
Soglia punteggio
In che modo un modello di machine learning sa quando un gol di calcio è davvero un gol? A ogni previsione viene assegnato un punteggio di affidabilità, ovvero una valutazione numerica del livello di certezza del modello che un determinato segmento di video contenga una classe. La soglia di punteggio è il numero che determina quando un determinato punteggio viene convertito in una decisione di sì o no, ovvero il valore a cui il modello dice "sì, questo numero di affidabilità è sufficientemente elevato per concludere che questo segmento video contiene un obiettivo".

Se la soglia di punteggio è bassa, il modello rischia di etichettare erroneamente i segmenti video. Per questo motivo, la soglia del punteggio deve essere basata su un determinato caso d'uso. Immagina un caso d'uso medico come il rilevamento del cancro, in cui le conseguenze di una classificazione errata sono maggiori rispetto a quelle di un video sportivo. Per il rilevamento del cancro, è appropriata una soglia di punteggio più elevata.
Risultati della previsione
Dopo aver applicato la soglia di punteggio, le previsioni effettuate dal modello rientrano in una delle quattro categorie. Per comprendere queste categorie, immagina di aver creato un modello per rilevare se un determinato segmento contiene o meno un gol di calcio. In questo esempio, un obiettivo è la classe positiva (ciò che il modello sta tentando di prevedere).
- Vero positivo: il modello prevede correttamente la classe positiva. Il modello ha previsto correttamente un gol nel segmento video.
- Falso positivo: il modello prevede erroneamente la classe positiva. Il modello ha previsto che nel segmento fosse presente un obiettivo, ma non era presente alcun obiettivo.
- Vero negativo: il modello prevede correttamente la classe negativa. Il modello ha previsto correttamente che non c'era un gol nel segmento.
- Falso negativo: il modello prevede erroneamente una classe negativa. Il modello ha previsto che non c'era un obiettivo nel segmento, ma ce n'era uno.

Precisione e richiamo
Le metriche di precisione e richiamo ti aiutano a capire se il modello sta acquisendo informazioni adeguate e cosa sta tralasciando. Scopri di più su precisione e richiamo
- Per precisione si intende la frazione delle previsioni positive che sono risultate corrette. Tra tutte le previsioni etichettate come "obiettivo", qual è la frazione che conteneva effettivamente un obiettivo?
- Il richiamo è la frazione di tutte le previsioni positive che sono state effettivamente identificate. Tra tutti i goal di calcio che potevano essere identificati, qual è la frazione di quelli identificati?
A seconda del caso d'uso, potrebbe essere necessario ottimizzare la precisione o il richiamo. Considera i seguenti casi d'uso.
Caso d'uso: informazioni private nei video
Immagina di creare un software che rileva automaticamente le informazioni sensibili in un video e le offusca. Le conseguenze di risultati falsi possono includere:
- Un falso positivo identifica qualcosa che non deve essere censurato, ma viene censurato
comunque. Potrebbe essere fastidioso, ma non dannoso.
- Un falso negativo non riesce a identificare le informazioni che devono essere censurate, come un numero di carta di credito. Si tratterebbe dello scenario peggiore, in quanto verrebbero divulgate informazioni private.
In questo caso d'uso, è fondamentale ottimizzare per il riconoscimento per assicurarsi che il modello trovi tutti i casi pertinenti. Un modello ottimizzato per il richiamo ha maggiori probabilità di etichettare esempi marginalmente pertinenti, ma anche di etichettare quelli errati (offuscando più del necessario).
Caso d'uso: ricerca di video di azioni
Supponiamo che tu voglia creare un software che consenta agli utenti di cercare una raccolta di video in base a una parola chiave. Considera i risultati errati:
- Un falso positivo restituisce un video irrilevante. Poiché il sistema cerca di fornire solo video pertinenti, il software non fa esattamente ciò per cui è stato progettato.
- Un falso negativo non restituisce un video pertinente. Poiché molte parole chiave hanno centinaia di
video, questo problema non è grave come restituire un video non pertinente.
In questo esempio, ti consigliamo di ottimizzare per la precisione per assicurarti che il modello fornisca risultati corretti e molto pertinenti. Un modello ad alta precisione è probabile che etichetti solo gli esempi più pertinenti, ma potrebbe escluderne alcuni. Scopri di più sulle metriche di valutazione del modello.
Testa il tuo modello
Immagine
Vertex AI utilizza automaticamente il 10% dei dati (o, se hai scelto autonomamente la suddivisione dei dati, la percentuale che hai scelto di utilizzare) per testare il modello e la pagina "Valuta" ti indica il risultato del modello sui dati di test. Tuttavia, se vuoi verificare l'affidabilità del tuo modello, esistono diversi modi per farlo. Il modo più semplice è caricare alcune immagini nella pagina "Deployment e test" e esaminare le etichette scelte dal modello per i tuoi esempi. Ci auguriamo che queste informazioni soddisfino le tue aspettative. Prova qualche esempio di ogni tipo di immagine che prevedi di ricevere.
Se invece vuoi utilizzare il modello nei tuoi test automatici, la pagina "Deployment e test" ti spiega anche come effettuare chiamate al modello in modo programmatico.
Tabulare
La valutazione delle metriche del modello è il modo principale per determinare se il modello è pronto per la distribuzione, ma è anche possibile testarlo con nuovi dati. Carica nuovi dati per vedere se le previsioni del modello corrispondono alle aspettative. In base alle metriche di valutazione o ai test con nuovi dati, potrebbe essere necessario continuare a migliorare le prestazioni del modello.
Testo
Vertex AI utilizza automaticamente il 10% dei dati (o, se hai scelto la suddivisione dei dati, la percentuale che hai scelto di utilizzare) per testare il modello e la pagina Valuta ti indica il rendimento del modello sui dati di test. Tuttavia, se vuoi controllare il tuo modello, esistono diversi modi per farlo. Dopo aver distribuito il modello, puoi inserire esempi di testo nel corrispondente campo della pagina Deployment e test e esaminare le etichette scelte dal modello per gli esempi. Ci auguriamo che questo sia in linea con le tue aspettative. Prova qualche esempio di ogni tipo di commento che prevedi di ricevere.
Se vuoi utilizzare il modello nei test automatici, la pagina Deployment e test fornisce un esempio di richiesta API che mostra come chiamare il modello in modo programmatico.
Se vuoi utilizzare il modello nei test automatici, la pagina Deployment e test fornisce un esempio di richiesta API che mostra come chiamare il modello in modo programmatico.
Nella pagina Previsioni batch, puoi creare una previsione batch, che raggruppa molte richieste di previsione in una sola. Una previsione batch è asincrona, il che significa che il modello attende di elaborare tutte le richieste di previsione prima di restituire i risultati.
Video
Vertex AI Video utilizza automaticamente il 20% dei tuoi dati oppure, se hai scelto autonomamente la suddivisione dei dati, la percentuale che hai scelto di utilizzare per testare il modello. La scheda Valuta nella console indica il rendimento del modello sui dati di test. Tuttavia, se vuoi controllare il tuo modello, esistono diversi modi per farlo. Un modo è fornire un file CSV con i dati video per i test nella scheda "Testa e utilizza" e esaminare le etichette previste dal modello per i video. Ci auguriamo che queste informazioni soddisfino le tue aspettative.
Puoi regolare la soglia per la visualizzazione delle previsioni e anche esaminare le stime su tre scale temporali: intervalli di 1 secondo, scatti della videocamera dopo il rilevamento automatico dei confini degli scatti e interi segmenti video.
Esegui il deployment del modello
Immagine
Se ritieni che le prestazioni del modello vadano bene, puoi iniziare a utilizzarlo. Potresti utilizzarlo in produzione o potrebbe essere una richiesta di previsione una tantum. In base al caso d'uso, puoi usare il modello in vari modi.
Previsione batch
La previsione batch è utile per fare molte richieste di previsione contemporaneamente. La previsione batch è asincrona, il che significa che il modello attende di elaborare tutte le richieste di previsione prima di restituire un file JSON Lines con i valori di previsione.
Previsione online
Usa un'API REST per distribuire il modello in modo da renderlo disponibile per le richieste di previsione. La previsione online è sincrona (in tempo reale), il che significa che restituirà rapidamente i risultati, ma accetta una sola richiesta di previsione per ogni chiamata API. La previsione online è utile se il modello fa parte di un'applicazione e alcune parti del tuo sistema dipendono da risposte rapide restituite dalle previsioni.
Tabulare
Se ritieni che le prestazioni del modello vadano bene, puoi iniziare a utilizzarlo. Potrebbe essere utilizzato in produzione o potrebbe essere una richiesta di previsione una tantum. In base al caso d'uso, puoi usare il modello in vari modi.
Previsione batch
La previsione batch è utile per fare molte richieste di previsione contemporaneamente. La previsione batch è asincrona, il che significa che il modello attende di elaborare tutte le richieste di previsione prima di restituire un file CSV o una tabella BigQuery con i valori della previsione.
Previsione online
Usa un'API REST per distribuire il modello in modo da renderlo disponibile per le richieste di previsione. La previsione online è sincrona (in tempo reale), il che significa che restituirà rapidamente i risultati, ma accetta una sola richiesta di previsione per ogni chiamata API. La previsione online è utile se il modello fa parte di un'applicazione e alcune parti del tuo sistema dipendono da risposte rapide restituite dalle previsioni.
Video
Se ritieni che le prestazioni del modello vadano bene, puoi iniziare a utilizzarlo. Vertex AI utilizza le previsioni in batch, che ti consentono di caricare un file CSV con i percorsi dei video ospitati su Cloud Storage. Il modello elaborerà ogni video e produrrà le previsioni in un altro file CSV. La previsione batch è asincrona, il che significa che il modello elabora prima tutte le richieste di previsione prima di produrre i risultati.
Esegui la pulizia
Per evitare addebiti indesiderati, annulla il deployment del modello quando non è in uso.
Al termine dell'utilizzo del modello, elimina le risorse che hai creato per evitare addebiti indesiderati sul tuo account.
- Introduzione ai dati di immagine: pulire il progetto
- Introduzione ai dati tabulari: pulizia del progetto
- Introduzione ai dati di testo: pulizia del progetto
- Hello Video Data: pulizia del progetto