This beginner's guide is an introduction to custom training on Vertex AI. Custom training refers to training a model using an ML framework such as TensorFlow, PyTorch, or XGBoost.
Learning Objectives
Vertex AI experience level: Beginner
Estimated reading time: 15 minutes
What you'll learn:
- Benefits of using a managed service for custom training.
- Best practices for packaging training code.
- How to submit and monitor a training job.
Why use a managed training service?
Imagine you're working on a new ML problem. You open up a notebook, import your data, and run experimentation. In this scenario, you create a model with the ML framework of your choice, and execute notebook cells to run a training loop. When training completes, you evaluate the results of your model, make changes, and then re-run training. This workflow is useful for experimentation, but as you start to think about building production applications with ML, you might find that manually executing the cells of your notebook isn't the most convenient option.
For example, if your dataset and model are large you might want to try out distributed training. Additionally, in a production setting it's unlikely that you'll only need to train your model once. Over time, you'll retrain your model to make sure it stays fresh and keeps producing valuable results. When you want to automate experimentation at scale, or retrain models for a production application, utilizing a managed ML training service will simplify your workflows.
This guide provides an introduction to training custom models on Vertex AI. Because the training service is fully managed, Vertex AI automatically provisions compute resources, perform the training task, and ensure deletion of compute resources once the training job is finished. Note that there are additional customizations, features, and ways to interface with the service that are not covered here. This guide is intended to provide an overview. For more detail, refer to the Vertex AI Training documentation.
Overview of custom training
Training custom models on Vertex AI follows this standard workflow:
Package up your training application code.
Configure and submit custom training job.
Monitor custom training job.
Packaging training application code
Running a custom training job on Vertex AI is done with containers. Containers are packages of your application code, in this case your training code, together with dependencies such as specific versions of libraries required to run your code. In addition to helping with dependency management, containers are able to run virtually anywhere, allowing for increased portability. Packaging your training code with its parameters and dependencies into a container to create a portable component is an important step when moving your ML applications from protoype to production.
Before you can launch a custom training job, you'll need to package up your training application. Training application in this case refers to a file, or multiple files, that perform tasks like loading data, preprocessing data, defining a model, and executing a training loop. The Vertex AI training service runs whatever code you provide, so it's entirely up to you what steps you include in your training application.
Vertex AI provides prebuilt containers for TensorFlow, PyTorch, XGBoost, and Scikit-learn. These containers are updated regularly and include common libraries you might need in your training code. You can choose to run your training code with one of these containers, or create a custom container that has your training code and dependencies pre-installed.
There are three options for packaging your code on Vertex AI:
- Submit a single Python file.
- Create a Python source distribution.
- Use custom containers.
Python file
This option is suitable for quick experimentation. You can use this option if all of the code needed to execute your training application is in one Python file and one of the prebuilt Vertex AI training containers has all of the libraries needed to run your application. For an example of packaging your training application as a single Python file, see the notebook tutorial Custom training and batch inference.
Python Source Distribution
You can create a Python Source Distribution that contains your training application. You'll store your source distribution with the training code and dependencies in a Cloud Storage bucket. For an example of packaging your training application as a Python Source Distribution, see the notebook tutorial Training, tuning and deploying a PyTorch classification model.
Custom Container
This option is useful when you want more control over your application, or maybe you want to run code not written in Python. In this case you'll need to write a Dockerfile, build your custom image, and push it to Artifact Registry. For an example of containerizing your training application see the notebook tutorial Profile model training performance using Profiler.
Recommended training application structure
If you choose to package up your code as a Python source distribution or as a custom container, it's recommended that you structure your application as follows:
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
Create a directory to store all of your training application code, in this
case, training-application-dir. This directory will contain a setup.py file
if you're using a Python Source Distribution, or a Dockerfile if you're using
a custom container.
In both scenarios, this high level directory will also contain a subdirectory
trainer, that contains all the code to execute training. Within trainer,
task.py is the main entrypoint to your application. This file executes model
training. You can choose to put all of your code in this file, but for
production applications you're likely to have additional files, for example
model.py, data.py, utils.py to name a few.
Running custom training
Training jobs on Vertex AI automatically provisions compute resources, execute the training application code, and ensure deletion of compute resources once the training job is finished.
As you build out more complicated workflows, it's likely that you'll use the Vertex AI SDK for Python to configure, submit, and monitor your training jobs. However, the first time you run a custom training job it can be easier to use the Google Cloud console.
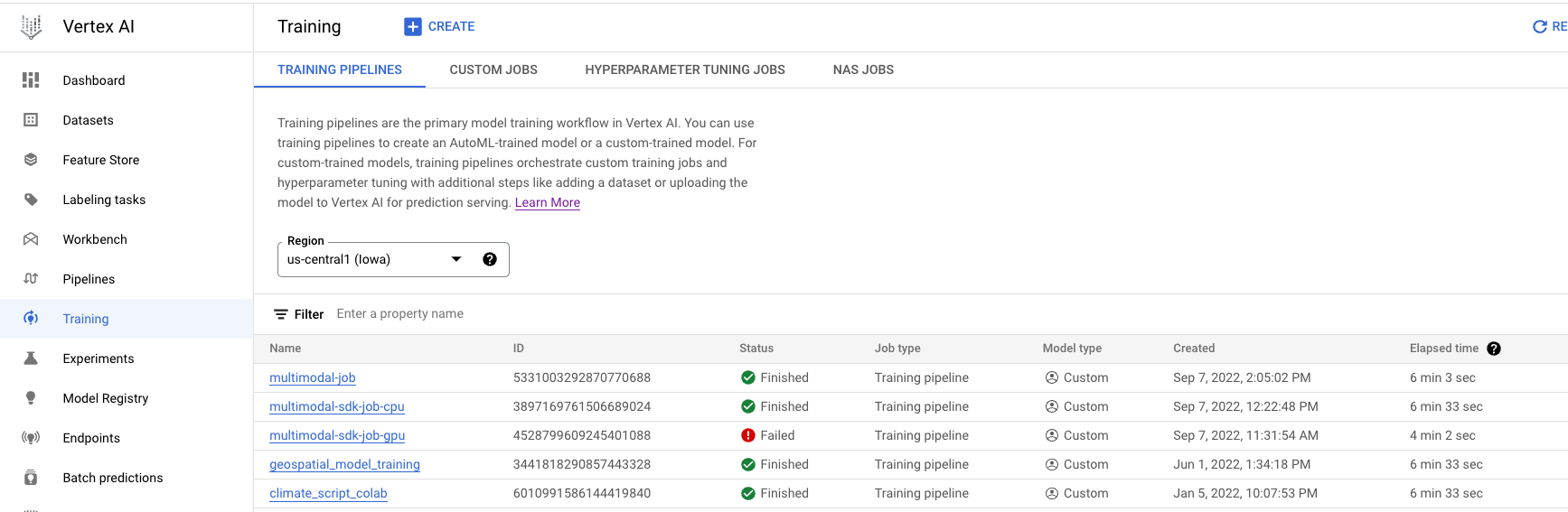
- Navigate to Training in the Vertex AI section of the Cloud Console. You can create a new training job by clicking the CREATE button.
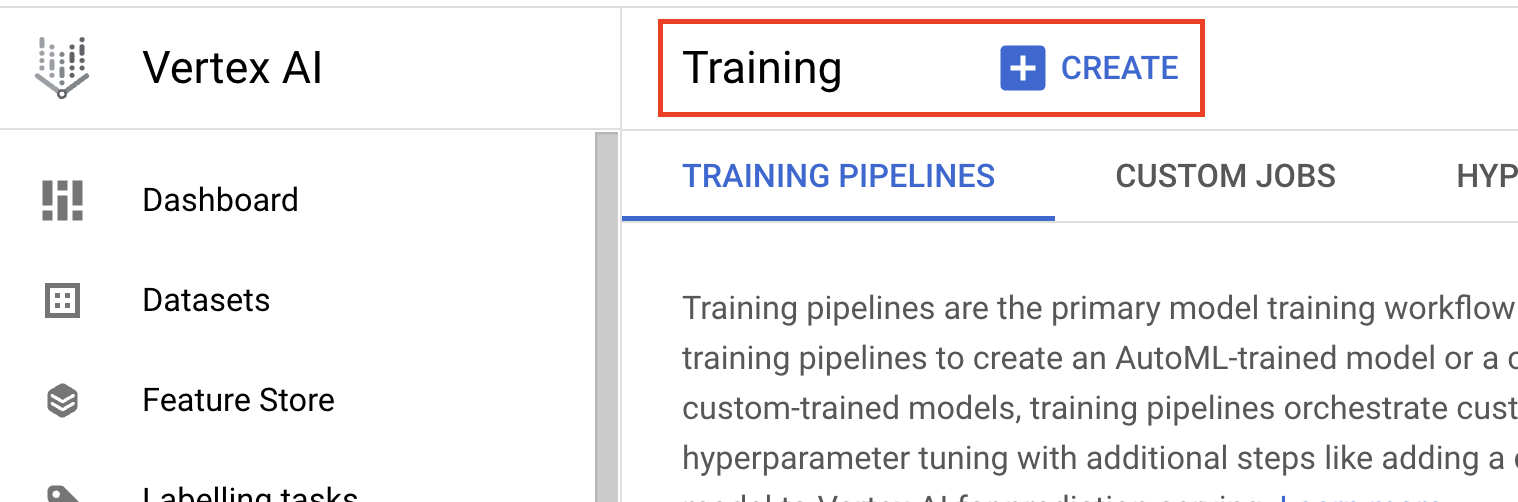
- Under model Training method, select Custom training (advanced).
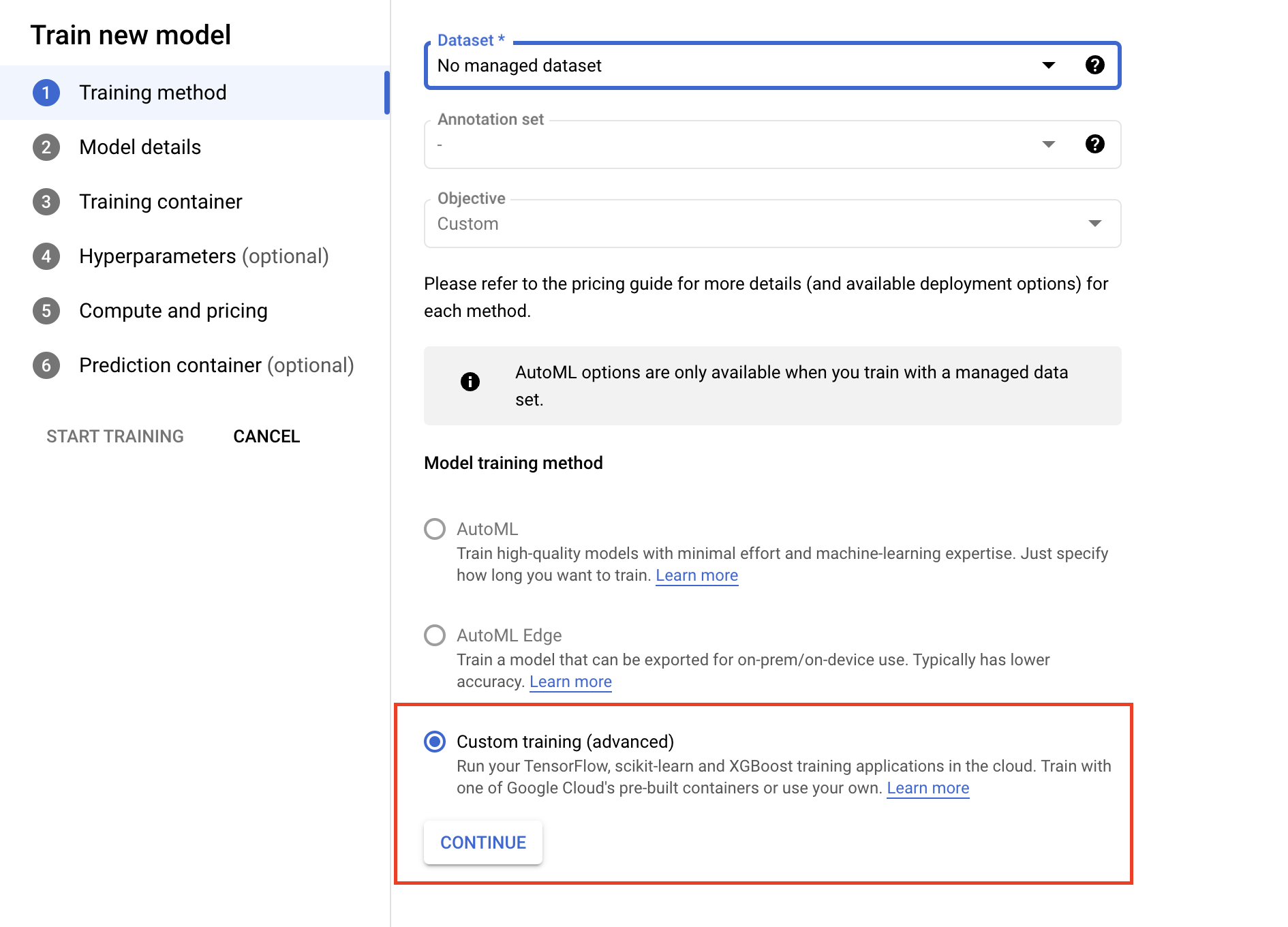
- Under the Training Container section, select either prebuilt or custom container, depending on how you packaged your application.
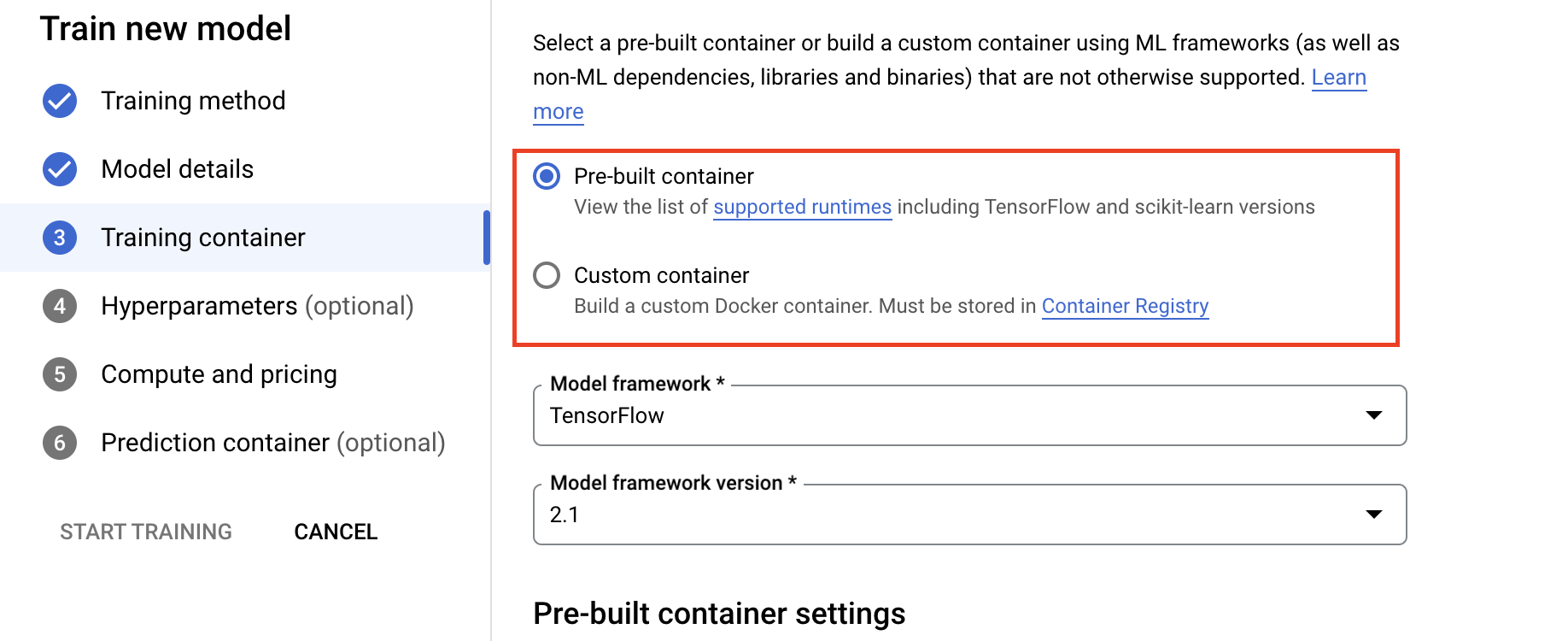
- Under Compute and pricing, specify the hardware for the training job. For single node training, you only need to configure Worker Pool 0. If you're interested in running distributed training, you'll need to understand the other worker pools, and you can learn more on Distributed training.
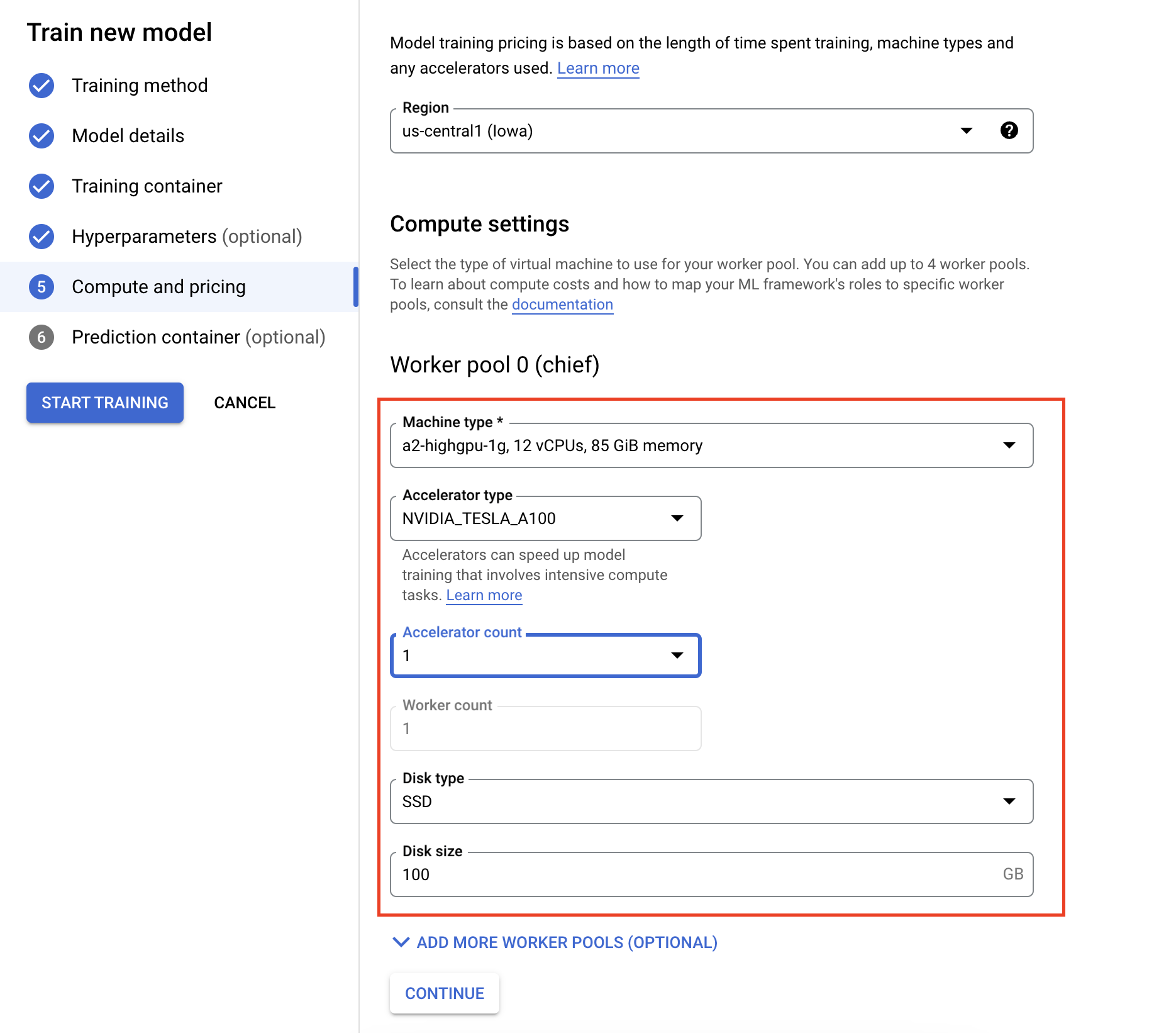
Configuring the inference container is optional. If you only want to train a model on Vertex AI and access the resulting saved model artifacts, you can skip this step. If you want to host and deploy the resulting model on the Vertex AI managed inference service, you'll need to configure an inference container. To learn more, see Get inferences from a custom trained model.
Monitoring Training jobs
You can monitor your training job in the Google Cloud console. You'll see a list of all the jobs that have run. You can click a particular job and examine the logs if something goes wrong.