Use the Google Cloud console to check your model performance. Analyze test errors to iteratively improve model quality by fixing data issues.
This tutorial has several pages:
Evaluate and analyze model performance.
Each page assumes that you have already performed the instructions from the previous pages of the tutorial.
1. Understand AutoML model evaluation results
After training is completed, your model is automatically evaluated against the test data split. The corresponding evaluation results are presented by clicking the model's name from either the Model Registry page or the Dataset page.
From there, you can find the metrics to measure the model's performance.
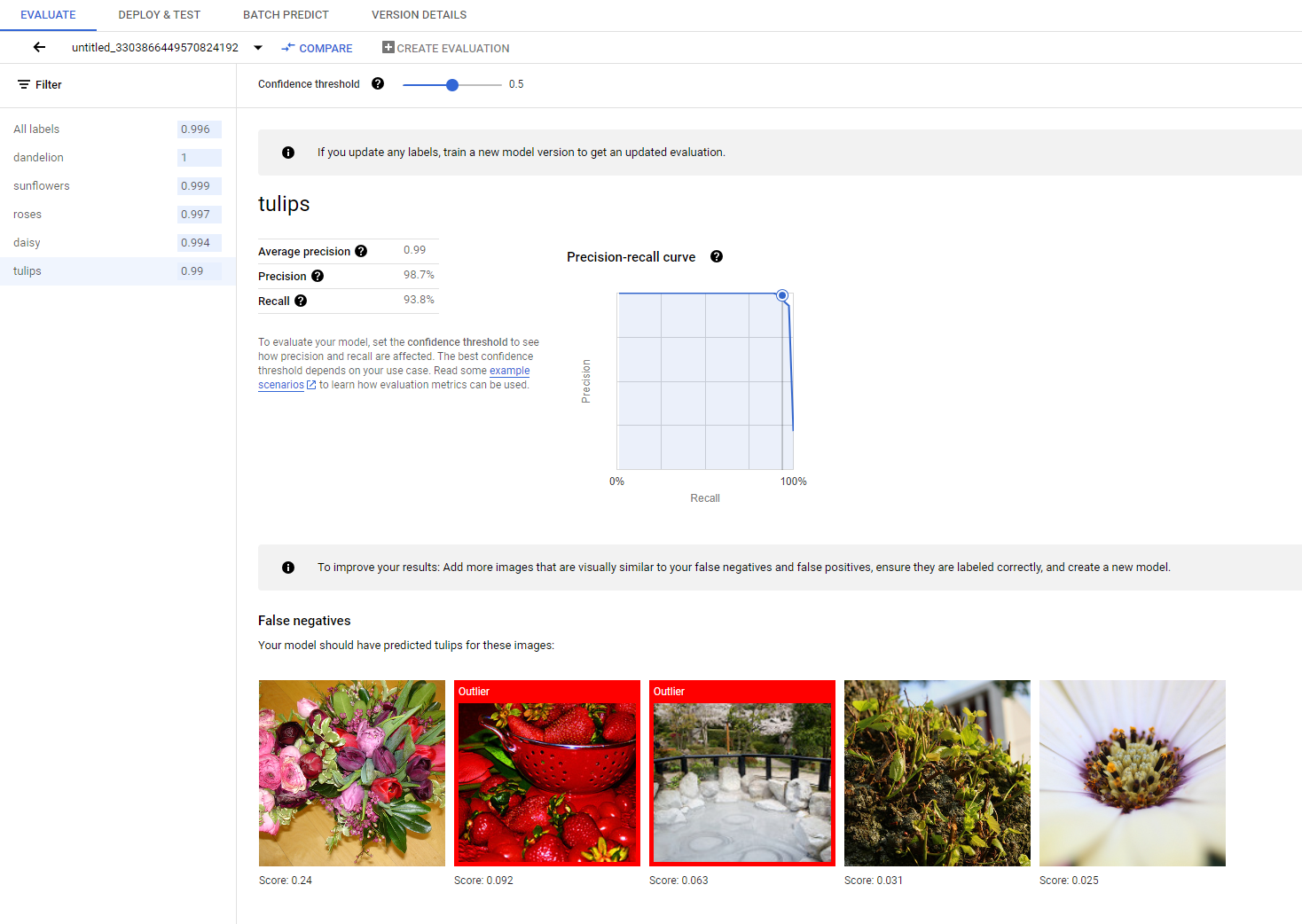
You can find a more detailed introduction to different evaluation metrics in the Evaluate, test, and deploy your model section.
2. Analyze test results
If you want to continue improving the model performance, the first step is often to examine the error cases and investigate the potential causes. The evaluation page of each class presents detailed test images of the given class categorized as false negatives, false positives, and true positives. The definition of each category can be found in the Evaluate, test, and deploy your model section.
For each image under every category, you can further check the prediction details by clicking the image and access the detailed analysis results. You will see the Review similar images panel on the right side of the page, where the closest samples from the training set are presented with distances measured in the feature space.
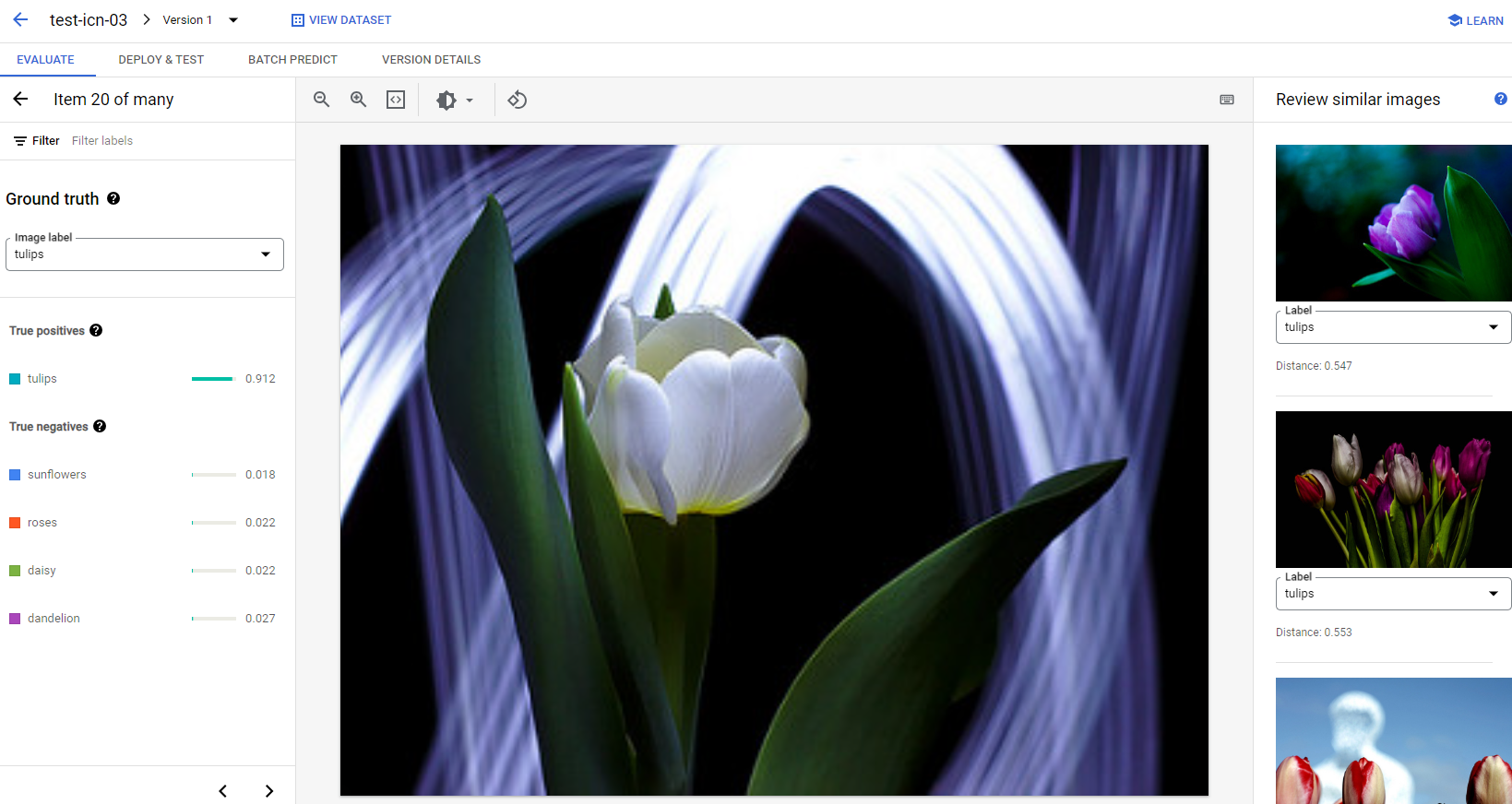
There are two types of data issues that you might want to pay attention:
Label inconsistency. If a visually similar sample from the training set has different labels from the test sample, it's possible that one of them is incorrect, or that the subtle difference requires more data for the model to learn from, or that the current class labels are simply not accurate enough to describe the given sample. Reviewing similar images can help you get the label information accurate by either correcting the error cases or excluding the problematic sample from the test set. You can conveniently change the label of either the test image or training images on the Review similar images panel on the same page.
Outliers. If a test sample is marked as an outlier, it's possible that there are no visually similar samples in the training set to help train the model. Reviewing similar images from the training set can help you identify these samples and add similar images into the training set to further improve the model performance on these cases.
What's next
If you're happy with the model performance, follow the next page of this tutorial to deploy your trained AutoML model to an endpoint and send an image to the model for prediction. Otherwise, if you make any corrections on the data, train a new model using the Training an AutoML image classification model tutorial.