Ray is an open-source framework for scaling AI and Python applications. Ray provides the infrastructure to perform distributed computing and parallel processing for your machine learning (ML) workflow.
If you already use Ray, you can use the same open source Ray code to write programs and develop applications on Vertex AI with minimal changes. You can then use Vertex AI's integrations with other Google Cloud services such as Vertex AI Inference and BigQuery as part of your machine learning workflow.
If you already use Vertex AI and need a simpler way to manage compute resources, you can use Ray code to scale training.
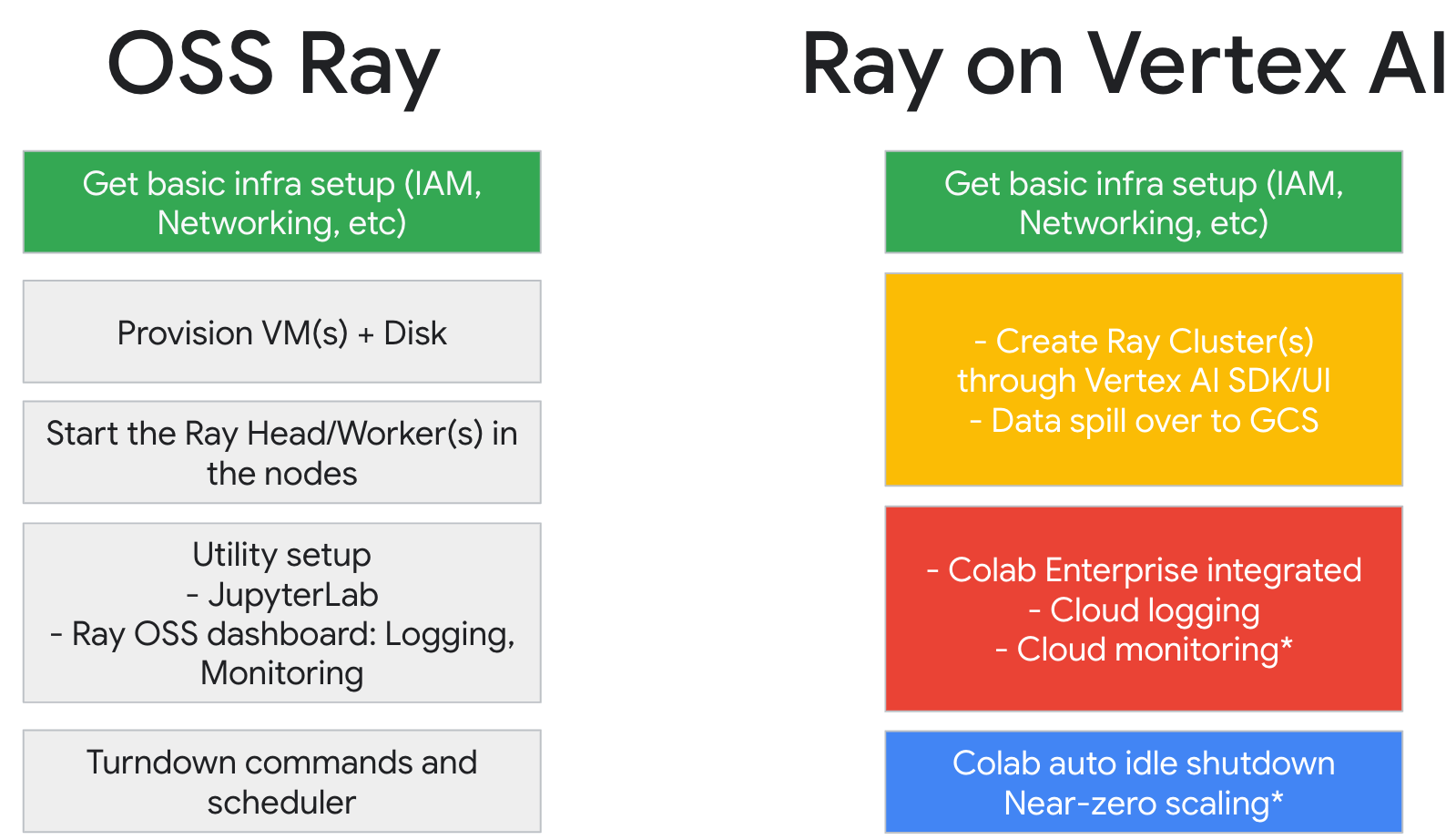
Workflow for using Ray on Vertex AI
Use Colab Enterprise and Vertex AI SDK for Python to connect to the Ray Cluster.
| Steps | Description |
|---|---|
| 1. Set up for Ray on Vertex AI | Set up your Google project, install the version of the Vertex AI SDK for Python that includes the functionality of the Ray Client, and set up a VPC peering network, which is optional. |
| 2. Create a Ray cluster on Vertex AI | Create a Ray cluster on Vertex AI. The Vertex AI Administrator role is required. |
| 3. Develop a Ray application on Vertex AI | Connect to a Ray cluster on Vertex AI and develop an application. Vertex AI User role is required. |
| 4. (Optional) Use Ray on Vertex AI with BigQuery | Read, write, and transform data with BigQuery. |
| 5. (Optional) Deploy a model on Vertex AI and get inferences | Deploy a model to a Vertex AI online endpoint and get inferences. |
| 6. Monitor your Ray cluster on Vertex AI | Monitor generated logs in Cloud Logging and metrics in Cloud Monitoring. |
| 7. Delete a Ray cluster on Vertex AI | Delete a Ray cluster on Vertex AI to avoid unnecessary billing. |
Overview
Ray clusters are built in to ensure capacity availability for critical ML workloads or during peak seasons. Unlike custom jobs, where the training service releases the resource after job completion, Ray clusters remain available until deleted.
Note: Use long running Ray clusters in these scenarios:
- If you submit the same Ray job multiple times, you can benefit from data and image caching by running the jobs on the same long-running Ray cluster.
- If you run many short-lived Ray jobs where the actual processing time is shorter than the job startup time, it may be beneficial to have a long-running cluster.
Ray clusters on Vertex AI can be set up either with public or private connectivity. The following diagrams show the architecture and workflow for Ray on Vertex AI. See Public or private connectivity for more information.
Architecture with public connectivity
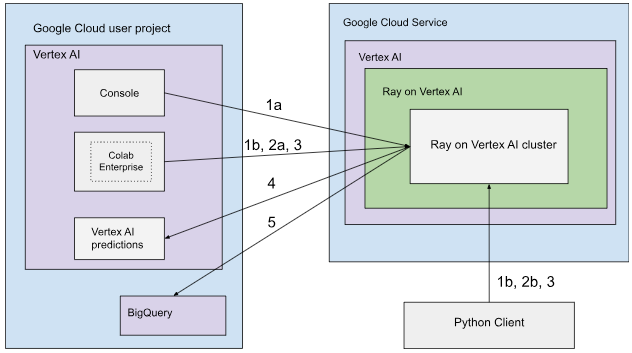
Create the Ray cluster on Vertex AI using the following options:
a. Use the Google Cloud console to create the Ray cluster on Vertex AI.
b. Create the Ray cluster on Vertex AI using the Vertex AI SDK for Python.
Connect to the Ray cluster on Vertex AI for interactive development using the following options:
a. Use Colab Enterprise in the Google Cloud console for seamless connection.
b. Use any Python environment accessible to the public internet.
Develop your application and train your model on the Ray cluster on Vertex AI:
Use the Vertex AI SDK for Python in your preferred environment (Colab Enterprise or any Python notebook).
Write a Python script using your preferred environment.
Submit a Ray Job to the Ray cluster on Vertex AI using the Vertex AI SDK for Python, Ray Job CLI, or Ray Job Submission API.
Deploy the trained model to an online Vertex AI endpoint for live inference.
Use BigQuery to manage your data.
Architecture with VPC
The following diagram shows the architecture and workflow for Ray on Vertex AI after you set up your Google Cloud project and VPC network, which is optional:
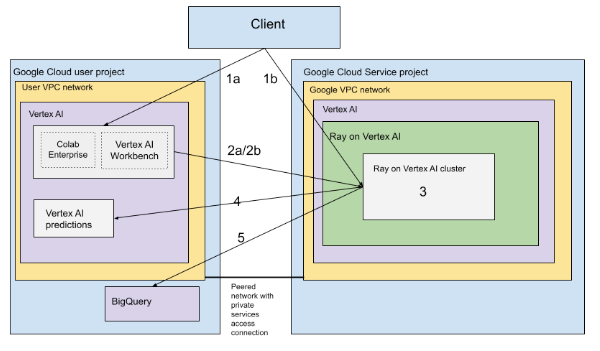
Set up your (a) Google project and (b) VPC network.
Create the Ray cluster on Vertex AI using the following options:
a. Use the Google Cloud console to create the Ray cluster on Vertex AI.
b. Create the Ray cluster on Vertex AI using the Vertex AI SDK for Python.
Connect to the Ray cluster on Vertex AI through a VPC peered network using the following options:
Use Colab Enterprise in the Google Cloud console.
Use a Vertex AI Workbench notebook.
Develop your application and train your model on the Ray cluster on Vertex AI using the following options:
Use the Vertex AI SDK for Python in your preferred environment (Colab Enterprise or a Vertex AI Workbench notebook).
Write a Python script using your preferred environment. Submit a Ray Job to the Ray cluster on Vertex AI using the Vertex AI SDK for Python, Ray Job CLI, or Ray dashboard.
Deploy the trained model to an online Vertex AI endpoint for inferences.
Use BigQuery to manage your data.
Terminology
For a full list of terms see the Vertex AI glossary for predictive AI.
-
autoscaling
- Autoscaling is the capability of a compute resource, like a Ray cluster's worker pool, to automatically adjust the number of nodes up or down based on the workload demands, optimizing resource utilization and cost. For more information, see Scale Ray clusters on Vertex AI: Autoscaling.
-
batch inference
- Batch inference takes a group of inference requests and outputs the results in one file. For more information, see Overview of getting inferences on Vertex AI.
-
BigQuery
- BigQuery is a fully managed, serverless, and highly scalable enterprise data warehouse provided by Google Cloud, designed for analyzing massive datasets using SQL queries at incredibly high speeds. BigQuery enables powerful business intelligence and analytics without requiring users to manage any infrastructure. For more information, see From data warehouse to autonomous data and AI platform.
-
Cloud Logging
- Cloud Logging is a fully managed, real-time logging service provided by Google Cloud that lets you collect, store, analyze, and monitor logs from all your Google Cloud resources, on-premises applications, and even custom sources. Cloud Logging centralizes log management, which makes it easier to troubleshoot, audit, and understand the behavior and health of your applications and infrastructure. For more information, see Cloud Logging overview.
-
Colab Enterprise
- Colab Enterprise is a collaborative, managed Jupyter notebook environment that brings the popular Google Colab user experience to Google Cloud, offering enterprise-level security and compliance capabilities. Colab Enterprise provides a notebook-centric, zero-configuration experience, with compute resources managed by Vertex AI, and integrates with other Google Cloud services like BigQuery. For more information, see Introduction to Colab Enterprise.
-
custom container image
- A custom container image is a self-contained, executable package that includes the user's application code, its runtime, libraries, dependencies, and environment configuration. In the context of Google Cloud, particularly Vertex AI, it lets the user package their machine learning training code or serving application with its exact dependencies, ensuring reproducibility and enabling the user to run a workload on managed services using specific software versions or unique configurations not provided by standard environments. For more information, see Custom container requirements for inference.
-
endpoint
- Resources to which you can deploy trained models to serve inferences. For more information, see Choose an endpoint type.
-
Identity and Access Management permissions (IAM)
- Identity and Access Management (IAM) permissions are specific granular capabilities that define who can do what on which Google Cloud resources. They are assigned to principals (like users, groups, or service accounts) through roles, allowing precise control over access to services and data within a Google Cloud project or organization. For more information, see Access control with IAM.
-
inference
- In the context of the Vertex AI platform, inference refers to the process of running data points through a machine learning model to calculate an output, such as a single numerical score. This process is also known as "operationalizing a machine learning model" or "putting a machine learning model into production." Inference is an important step in the machine learning workflow, since it enables models to be used to make inferences on new data. In Vertex AI, inference can be performed in various ways, including batch inference and online inference. Batch inference involves running a group of inference requests and outputting the results in one file, while online inference allows for real-time inferences on individual data points.
-
Network File System (NFS)
- A client/server system that lets users access files across a network and treat them as if they resided in a local file directory. For more information, see Mount an NFS share for custom training.
-
Online inference
- Obtaining inferences on individual instances synchronously. For more information, see Online inference.
-
persistent resource
- A type of Vertex AI compute resource, such as a Ray cluster, that remains allocated and available until explicitly deleted, which is beneficial for iterative development and reduces startup overhead between jobs. For more information, see Get persistent resource information.
-
pipeline
- ML pipelines are portable and scalable ML workflows that are based on containers. For more information, see Introduction to Vertex AI Pipelines.
-
Prebuilt container
- Container images provided by Vertex AI that come pre-installed with common ML frameworks and dependencies, simplifying the setup for training and inference jobs. For more information, see Prebuilt containers for custom training .
-
Private Service Connect (PSC)
- Private Service Connect is a technology that allows Compute Engine customers to map private IPs in their network to either another VPC network or to Google APIs. For more information, see Private Service Connect.
-
Ray cluster on Vertex AI
- A Ray cluster on Vertex AI is a managed cluster of compute nodes that can be used to run distributed machine learning (ML) and Python applications. It provides the infrastructure to perform distributed computing and parallel processing for your ML workflow. Ray clusters are built into Vertex AI to ensure capacity availability for critical ML workloads or during peak seasons. Unlike custom jobs, where the training service releases the resource after job completion, Ray clusters remain available until deleted. For more information, see Ray on Vertex AI overview.
-
Ray on Vertex AI (RoV)
- Ray on Vertex AI is designed so you can use the same open source Ray code to write programs and develop applications on Vertex AI with minimal changes. For more information, see Ray on Vertex AI overview.
-
Ray on Vertex AI SDK for Python
- Ray on Vertex AI SDK for Python is a version of the Vertex AI SDK for Python that includes the functionality of the Ray Client, Ray BigQuery connector, Ray cluster management on Vertex AI, and inferences on Vertex AI. For more information, see Introduction to the Vertex AI SDK for Python.
-
Ray on Vertex AI SDK for Python
- Ray on Vertex AI SDK for Python is a version of the Vertex AI SDK for Python that includes the functionality of the Ray Client, Ray BigQuery connector, Ray cluster management on Vertex AI, and inferences on Vertex AI. For more information, see Introduction to the Vertex AI SDK for Python.
-
service account
- Service accounts are special Google Cloud accounts used by applications or virtual machines to make authorized API calls to Google Cloud services. Unlike user accounts, they are not tied to an individual human but act as an identity for your code, enabling secure and programmatic access to resources without requiring human credentials. For more information, see Service accounts overview.
-
Vertex AI Workbench
- Vertex AI Workbench is a unified, Jupyter notebook-based development environment that supports the entire data science workflow, from data exploration and analysis to model development, training, and deployment. Vertex AI Workbench provides a managed and scalable infrastructure with built-in integrations to other Google Cloud services like BigQuery and Cloud Storage, enabling data scientists to perform their machine learning tasks efficiently without managing underlying infrastructure. For more information, see Introduction to Vertex AI Workbench.
-
worker node
- A worker node refers to an individual machine or computational instance within a cluster that's responsible for executing tasks or performing work. In systems like Kubernetes or Ray clusters, nodes are the fundamental units of compute. For more information, see What is high performance computing (HPC)?.
-
worker pool
- Components of a Ray cluster that execute distributed tasks. Worker pools can be configured with specific machine types and support both autoscaling and manual scaling. For more information, see Structure of the training cluster.
Pricing
Pricing for Ray on Vertex AI is calculated as follows:
The compute resources you use are charged based on the machine configuration you select when creating your Ray cluster on Vertex AI. For Ray on Vertex AI pricing, see the pricing page.
Regarding Ray clusters, you are only charged during RUNNING and UPDATING states. No other states are charged. The amount charged is based on the actual cluster size at the moment.
When you perform tasks using the Ray cluster on Vertex AI, logs are automatically generated and charged based on Cloud Logging pricing.
If you deploy your model to an endpoint for online inferences, see the "Prediction and explanation" section of the Vertex AI pricing page.
If you use BigQuery with Ray on Vertex AI, see BigQuery pricing.