This beginner's guide is an introduction to getting inferences from custom models on Vertex AI.
Learning Objectives
Vertex AI experience level: Beginner
Estimated reading time: 15 minutes
What you will learn:
- Benefits of using a managed inference service.
- How batch inferences work in Vertex AI.
- How online inferences work in Vertex AI.
Why use a managed inference service?
Imagine you've been tasked with creating a model that takes as input an image
of a plant, and predicts the species. You might start by training a model in
a notebook, trying out different hyperparameters and architectures. When you
have a trained model, you can call the predict method in your ML framework of choice and test the model quality.
This workflow is great for experimentation, but when you want to use the model to get inferences on lots of data, or get low latency inferences on the fly, you're going to need something more than a notebook. For example, suppose you're trying to measure the biodiversity of a particular ecosystem and instead of having humans manually identify and count plant species out in the wild, you want to use this ML model to classify large batches of images. If you're using a notebook, you might hit memory constraints. Additionally, getting inferences for all of that data is likely to be a long running job that might timeout in your notebook.
Or what if you wanted to use this model in an application where users could upload images of plants and have them identified immediately? You'll need some place to host the model that exists outside of a notebook that your application can call to for an inference. Additionally, it's unlikely you'll have consistent traffic to your model, so you'll want a service that can autoscale when necessary.
In all of these cases, a managed inference service will reduce the friction of hosting and using your ML models. This guide provides an introduction to getting inferences from ML models on Vertex AI. Note that there are additional customizations, features, and ways to interface with the service that are not covered here. This guide is intended to provide an overview. For more information, refer to the Vertex AI inferences documentation.
Overview of the managed inference service
Vertex AI supports batch and online inferences.
Batch inference is an asynchronous request. It's a good fit when you don't require an immediate response and want to process accumulated data in a single request. In the example discussed in the introduction, this would be the characterizing biodiversity use case.
If you want to get low latency inferences from data passed to your model on the fly, you can use Online inference. In the example discussed in the introduction, this would be the use case where you want to embed your model in an app that helps users identify plant species immediately.
Upload model to Vertex AI Model Registry
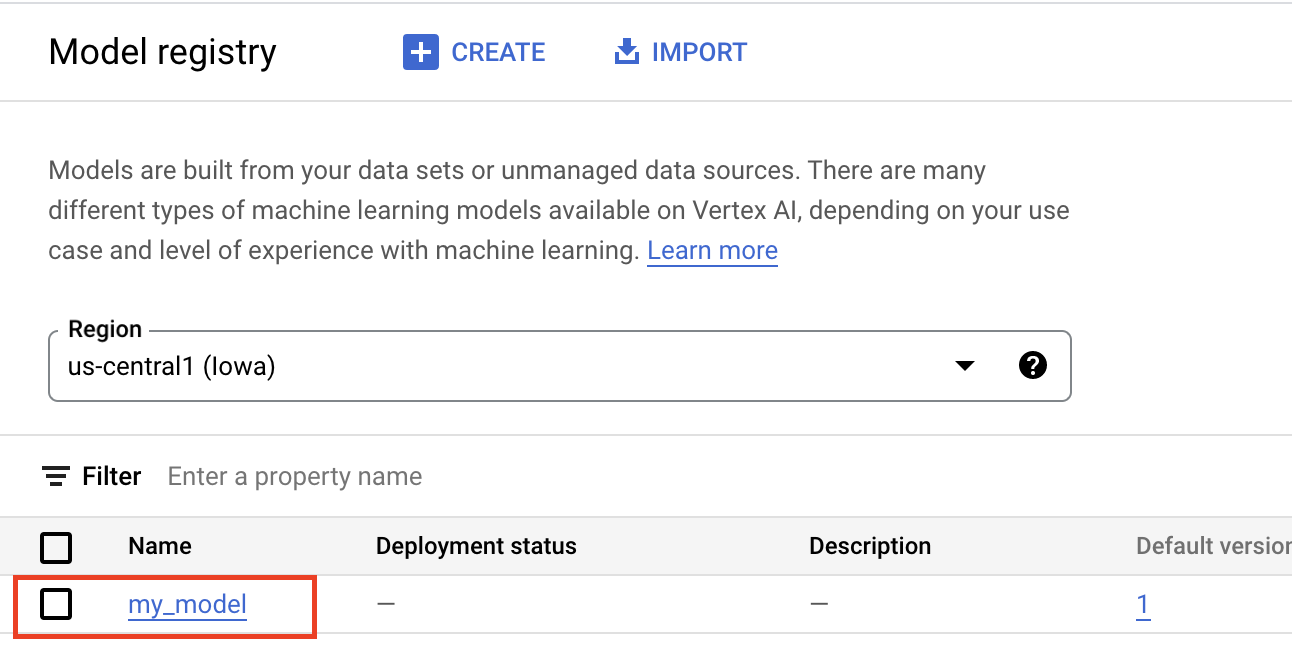
To use the inference service, the first step is uploading your trained ML model to the Vertex AI Model Registry. This is a registry where you can manage the lifecycle of your models.
Create a model resource
When training models with the Vertex AI custom training service, you can have your model automatically imported to the registry after the training job completes. If you skipped that step, or trained your model outside of Vertex AI, you can upload it manually using the Google Cloud console or Vertex AI SDK for Python by pointing to a Cloud Storage location with your saved model artifacts. The format of these model artifacts could be savedmodel.pb, model.joblib, etc, depending on what ML framework you're using.
Uploading artifacts to the Vertex AI Model Registry creates a Model resource, which is visible in the Google Cloud console:
Select a container
When you import a model to the Vertex AI Model Registry, you need to associate it with a container for Vertex AI to serve inference requests.
Prebuilt containers
Vertex AI provides prebuilt containers that you can use for inferences. The prebuilt containers are organized by ML framework and framework version and provide HTTP inference servers that you can use to serve inferences with minimal configuration. They only perform the inference operation of the machine learning framework so if you need to preprocess your data, that must happen before you make the inference request. Similarly, any postprocessing must happen after you perform the inference request. For an example of using a prebuilt container, see the notebook Serving PyTorch image models with prebuilt containers on Vertex AI.
Custom containers
If your use case requires libraries that aren't included in the prebuilt containers, or maybe you have custom data transformations you want to perform as part of the inference request, you can use a custom container that you build and push to Artifact Registry. While custom containers allow for greater customization, the container must run an HTTP server. Specifically, the container must listen and respond to liveness checks, health checks, and inference requests. In most cases, using a prebuilt container if possible is the recommended and simpler option. For an example of using a custom container, see the notebook PyTorch Image Classification Single GPU using Vertex Training with Custom Container
Custom inference routines
If your use case does require custom pre and post processing transformations, and you don't want the overhead of building and maintaining a custom container, you can use custom inference routines. With custom inference routines, you can provide your data transformations as Python code, and behind the scenes the Vertex AI SDK for Python will build a custom container that you can test locally and deploy to Vertex AI. For an example of using custom inference routines, see the notebook Custom inference routines with Sklearn
Get batch inferences
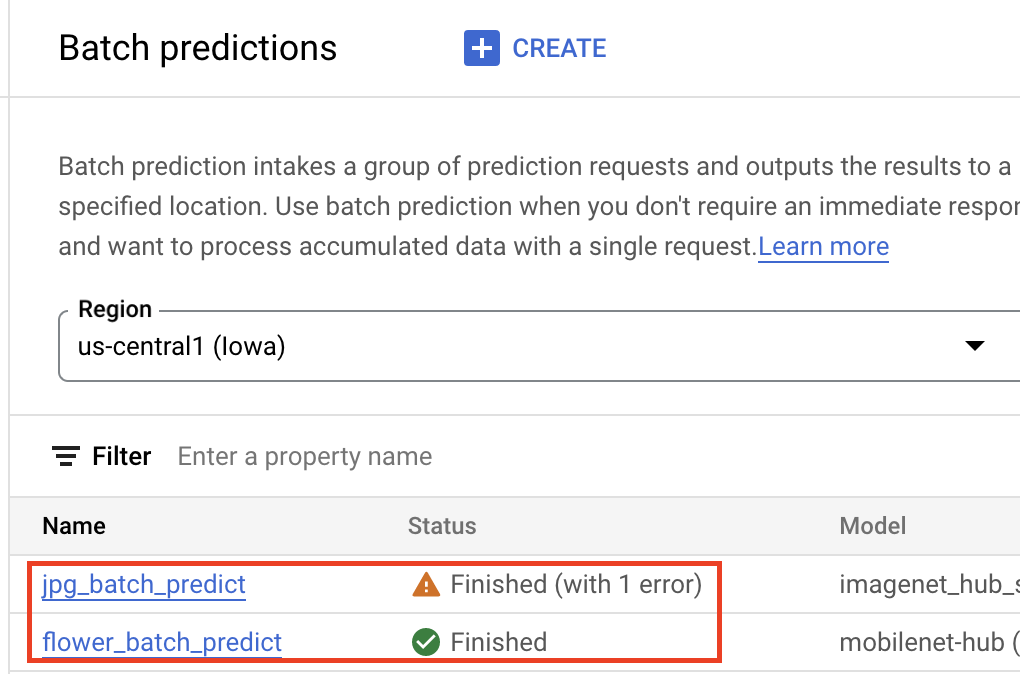
Once your model is in the Vertex AI Model Registry, you can submit a batch inference job from the Google Cloud console or the Vertex AI SDK for Python. You'll specify the location of the source data, as well as the location in Cloud Storage or BigQuery where you want the results to be saved. You can also specify the machine type you want this job to run on, and any optional accelerators. Because the inferences service is fully managed, Vertex AI automatically provisioned compute resources, perform the inference task, and make sure deletion of compute resources once the inference job is finished. The status of your batch inference jobs can be tracked in the Google Cloud console.
Get online inferences
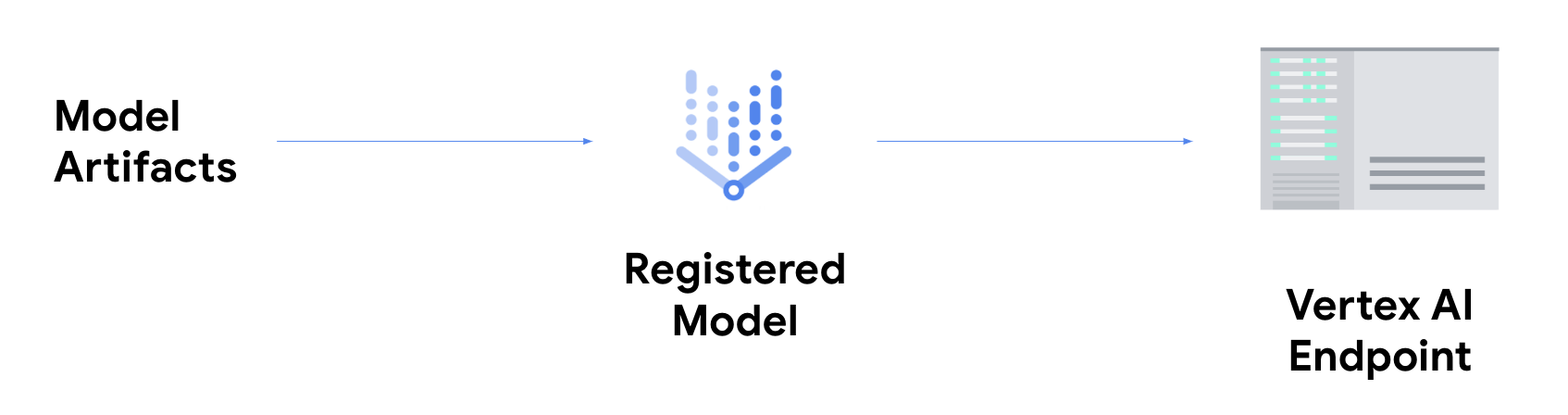
If you want to get online inferences, you need to take the extra step of
deploying your model
to a Vertex AI endpoint.
This associates the model artifacts with physical resources for low latency
serving and creates a
DeployedModelresource.
Once the model is deployed to an endpoint it accepts requests like any other REST endpoint, which means you can call it from a Cloud Run function, chatbot, a web app, etc. Note that you can deploy multiple models to a single endpoint, splitting traffic between them. This functionality is useful, for example, if you want to roll out a new model version but don't want to direct all traffic to the new model immediately. You can also deploy the same model to multiple endoints.
Resources for getting inferences from custom models on Vertex AI
To learn more about hosting and serving models on Vertex AI, see the following resources or refer to the Vertex AI Samples GitHub repo.
- Getting Predictions video
- Train and serve a TensorFlow model using a prebuilt container
- Serving PyTorch image models with prebuilt containers on Vertex AI
- Serve a Stable Diffusion model using a prebuilt container
- Custom inference routines with Sklearn