Explore and visualize data in BigQuery from within JupyterLab
This page shows you some examples of how to explore and visualize data that is stored in BigQuery from within the JupyterLab interface of your Vertex AI Workbench managed notebooks instance.
Open JupyterLab
In the Google Cloud console, go to the Managed notebooks page.
Next to your managed notebooks instance's name, click Open JupyterLab.
Your managed notebooks instance opens JupyterLab.
Read data from BigQuery
In the next two sections, you read data from BigQuery that you will use to visualize later. These steps are identical to those in Query data in BigQuery from within JupyterLab, so if you've completed them already, you can skip to Get a summary of data in a BigQuery table.
Query data by using the %%bigquery magic command
In this section, you write SQL directly in notebook cells and read data from BigQuery into the Python notebook.
Magic commands that use a single or double percentage character (% or %%)
let you use minimal syntax to interact with BigQuery within the
notebook. The BigQuery client library for Python is automatically
installed in a managed notebooks instance. Behind the scenes, the %%bigquery magic
command uses the BigQuery client library for Python to run the
given query, convert the results to a pandas DataFrame, optionally save the
results to a variable, and then display the results.
Note: As of version 1.26.0 of the google-cloud-bigquery Python package,
the BigQuery Storage API
is used by default to download results from the %%bigquery magics.
To open a notebook file, select File > New > Notebook.
In the Select Kernel dialog, select Python (Local), and then click Select.
Your new IPYNB file opens.
To get the number of regions by country in the
international_top_termsdataset, enter the following statement:%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Click Run cell.
The output is similar to the following:
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
In the next cell (below the output from the previous cell), enter the following command to run the same query, but this time save the results to a new pandas DataFrame that's named
regions_by_country. You provide that name by using an argument with the%%bigquerymagic command.%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
Note: For more information about available arguments for the
%%bigquerycommand, see the client library magics documentation.Click Run cell.
In the next cell, enter the following command to look at the first few rows of the query results that you just read in:
regions_by_country.head()Click Run cell.
The pandas DataFrame
regions_by_countryis ready to plot.
Query data by using the BigQuery client library directly
<
Get a summary of data in a BigQuery table
In this section, you use a notebook shortcut to get summary statistics and visualizations for all fields of a BigQuery table. This can be a fast way to profile your data before exploring further.
The BigQuery client library provides a magic command,
%bigquery_stats, that you can call with a specific table name to provide an
overview of the table and detailed statistics on each of the table's
columns.
In the next cell, enter the following code to run that analysis on the US
top_termstable:%bigquery_stats bigquery-public-data.google_trends.top_termsClick Run cell.
After running for some time, an image appears with various statistics on each of the 7 variables in the
top_termstable. The following image shows part of some example output: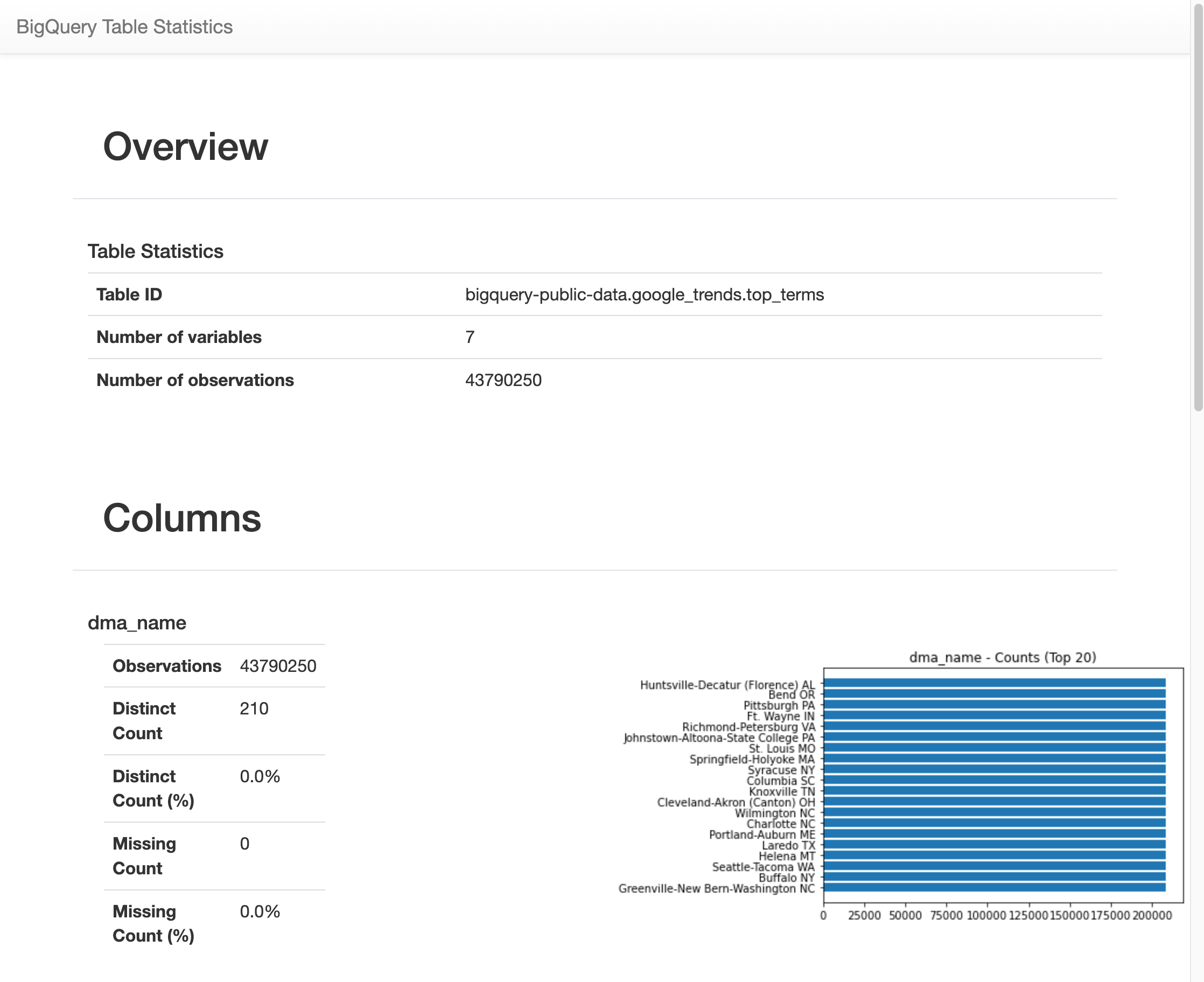
Visualize BigQuery data
In this section, you use plotting capabilities to visualize the results from the queries that you previously ran in your Jupyter notebook.
In the next cell, enter the following code to use the pandas
DataFrame.plot()method to create a bar chart that visualizes the results of the query that returns the number of regions by country:regions_by_country.plot(kind="bar", x="country_name", y="num_regions", figsize=(15, 10))Click Run cell.
The chart is similar to the following:
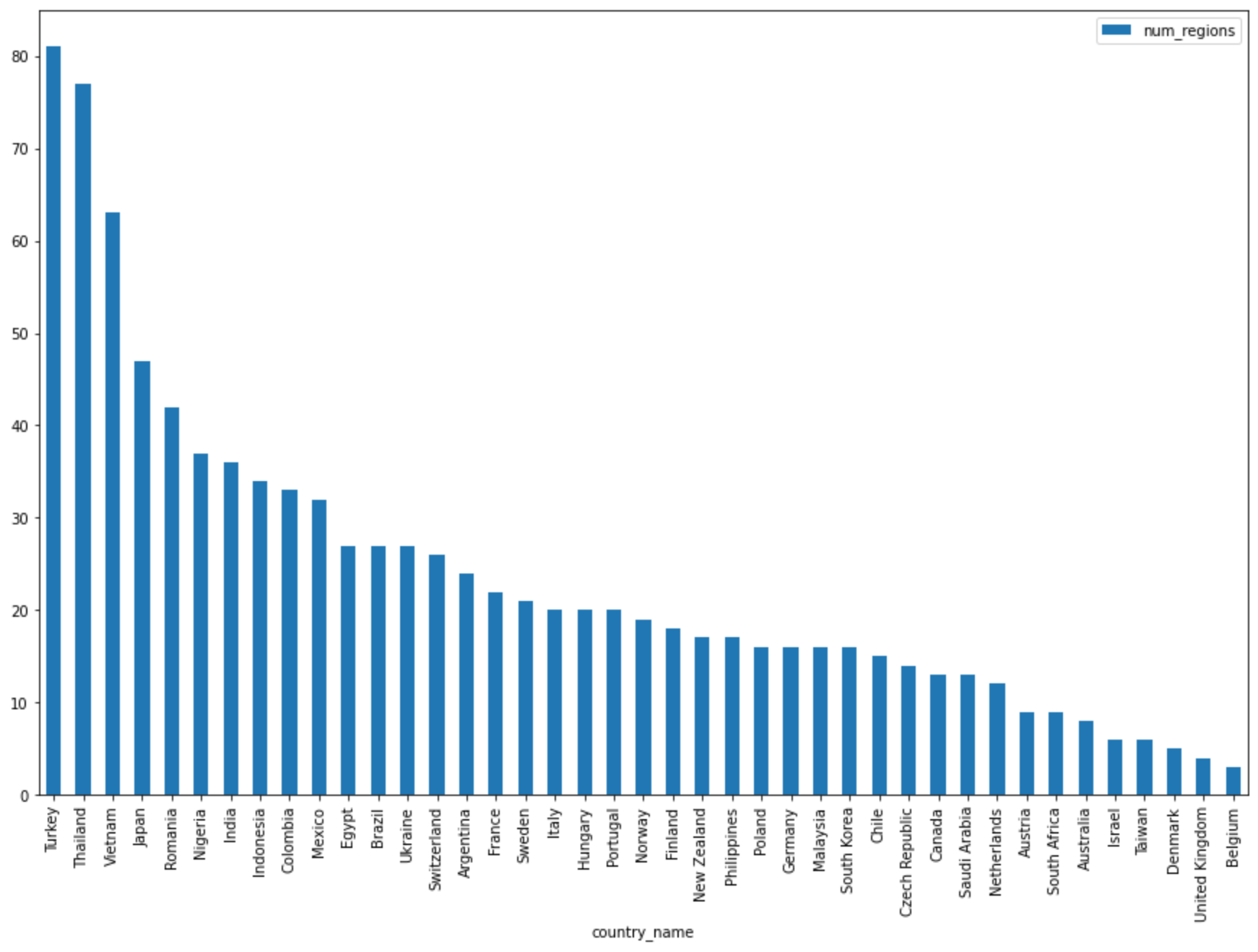
In the next cell, enter the following code to use the pandas
DataFrame.plot()method to create a scatter plot that visualizes the results from the query for the percentage of overlap in the top search terms by days apart:pct_overlap_terms_by_days_apart.plot( kind="scatter", x="days_apart", y="pct_overlap_terms", s=len(pct_overlap_terms_by_days_apart["num_date_pairs"]) * 20, figsize=(15, 10) )Click Run cell.
The chart is similar to the following. The size of each point reflects the number of date pairs that are that many days apart in the data. For example, there are more pairs that are 1 day apart than 30 days apart because the top search terms are surfaced daily over about a month's time.
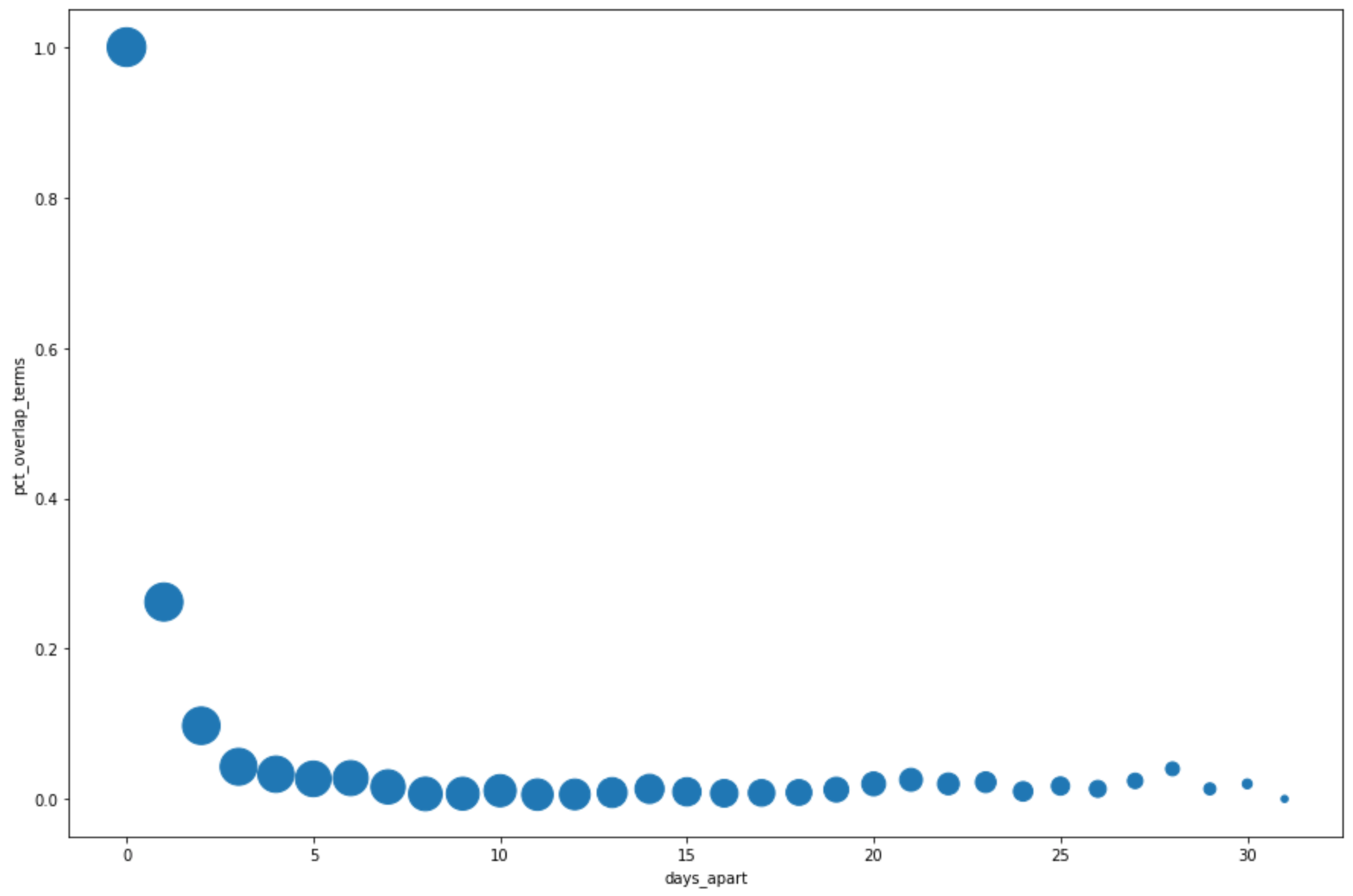
For more information about data visualization, see the pandas documentation.