Introduction
This page provides a brief conceptual overview of the feature attribution methods available with Vertex AI. For an in-depth technical discussion, see our AI Explanations Whitepaper.
Global feature importance (model feature attributions) shows how each feature impacts a model. The values are a percentage for each feature: the higher the percentage, the more impact the feature had on model training. To view the global feature importance for your model, examine the evaluation metrics.
Local feature attributions for time series models indicate how much each feature in the data contributed to the predicted result. Use this information to verify that the model behaves as expected, recognize bias in your models, and get ideas for ways to improve your model and your training data. When you request inferences, you get predicted values as appropriate for your model. When you request explanations, you get the inferences along with feature attribution information.
Consider the following example: A deep neural network is trained to predict the duration of a bike ride, based on weather data and previous ride-sharing data. If you request only inferences from this model, you get predicted durations of bike rides in number of minutes. If you request explanations, you get the predicted bike trip duration, along with an attribution score for each feature in your explanations request. The attribution scores show how much the feature affected the change in inference value, relative to the baseline value that you specify. Choose a meaningful baseline that makes sense for your model - in this case, the median bike ride duration.
You can plot the feature attribution scores to see which features contributed most strongly to the resulting inference:
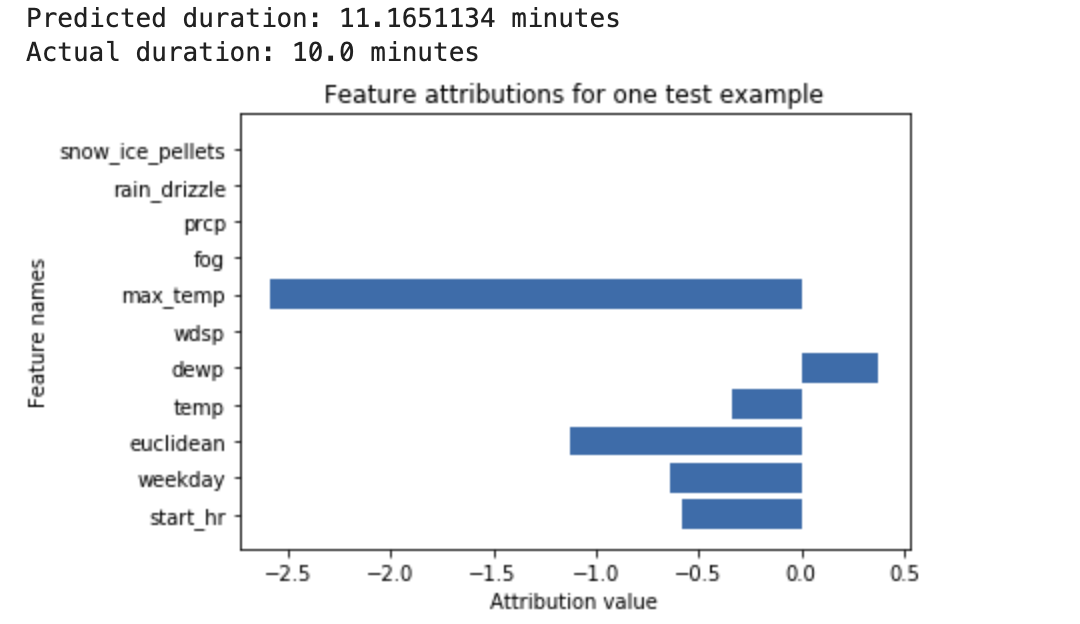
Generate and query local feature attributions when performing an online inference job or a batch inference job.
Advantages
If you inspect specific instances, and also aggregate feature attributions across your training dataset, you can get deeper insight into how your model works. Consider the following advantages:
Debugging models: Feature attributions can help detect issues in the data that standard model evaluation techniques would usually miss.
Optimizing models: You can identify and remove features that are less important, which can result in more efficient models.
Conceptual limitations
Consider the following limitations of feature attributions:
Feature attributions, including local feature importance for AutoML, are specific to individual inferences. Inspecting the feature attributions for an individual inference may provide good insight, but the insight may not be generalizable to the entire class for that individual instance, or the entire model.
To get more generalizable insight for AutoML models, refer to the model feature importance. To get more generalizable insight for other models, aggregate attributions over subsets over your dataset, or the entire dataset.
Each attribution only shows how much the feature affected the inference for that particular example. A single attribution might not reflect the overall behavior of the model. To understand approximate model behavior on an entire dataset, aggregate attributions over the entire dataset.
Although feature attributions can help with model debugging, they don't always indicate clearly whether an issue arises from the model or from the data that the model is trained on. Use your best judgment, and diagnose common data issues to narrow the space of potential causes.
The attributions depend entirely on the model and data used to train the model. They can only reveal the patterns the model found in the data, and can't detect any fundamental relationships in the data. The presence or absence of a strong attribution to a certain feature doesn't mean there is or is not a relationship between that feature and the target. The attribution merely shows that the model is or is not using the feature in its inferences.
Attributions alone cannot tell if your model is fair, unbiased, or of sound quality. Carefully evaluate your training data and evaluation metrics in addition to the attributions.
For more information about limitations, see the AI Explanations Whitepaper.
Improving feature attributions
The following factors have the highest impact on feature attributions:
- The attribution methods approximate the Shapley value. You can increase the precision of the approximation by increasing the number of paths for the sampled Shapley method. As a result, the attributions could change dramatically.
- The attributions only express how much the feature affected the change in inference value, relative to the baseline value. Be sure to choose a meaningful baseline, relevant to the question you're asking of the model. Attribution values and their interpretation might change significantly as you switch baselines.
Algorithm
Vertex AI provides feature attributions using Shapley Values, a cooperative game theory algorithm that assigns credit to each player in a game for a particular outcome. Applied to machine learning models, this means that each model feature is treated as a "player" in the game and credit is assigned in proportion to the outcome of a particular inference. For structured data models, Vertex AI uses a sampling approximation of exact Shapley Values called Sampled Shapley.
For in-depth information about how the sampled Shapley method works, read the paper Bounding the Estimation Error of Sampling-based Shapley Value Approximation.
What's next
The following resources provide further useful educational material: