Questo tutorial descrive una procedura completa di failover e fallback di ripristino di emergenza (RE) in Cloud SQL per MySQL utilizzando le repliche di lettura cross-region.
In questo tutorial, configurerai un'istanza Cloud SQL per MySQL ad alta disponibilità (HA) per il RE e simulerai un'interruzione. Quindi, segui la procedura di RE per recuperare la distribuzione iniziale dopo la risoluzione dell'interruzione.
Questo tutorial è rivolto ad architetti, amministratori e database engineer.
Per leggere una panoramica del funzionamento del ripristino di emergenza SQL, consulta Informazioni sul ripristino di emergenza in Cloud SQL.
Obiettivi
- Crea un'istanza Cloud SQL per MySQL HA.
- Esegui il deployment di una replica di lettura tra regioni su Google Cloud utilizzando Cloud SQL per MySQL.
- Simula un disastro e un failover con Cloud SQL per MySQL.
- Scopri i passaggi per recuperare il deployment iniziale utilizzando un fallback con Cloud SQL per MySQL.
Questo documento si concentra solo sulle procedure di failover e fallback di RE tra regioni. Per informazioni su una procedura di failover HA a singola regione, consulta Panoramica della configurazione ad alta disponibilità.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Al termine delle attività descritte in questo documento, puoi evitare l'addebito di ulteriori costi eliminando le risorse che hai creato. Per ulteriori informazioni, vedi Pulizia.
Prima di iniziare
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
Fase 1: configura un'istanza di database ad alta affidabilità per il RE
Le seguenti fasi (1-3) ti guidano attraverso una procedura completa di failover e fallback. Esegui tutti i comandi utilizzando il comando
gcloudin Cloud Shell. Per semplificare la procedura, il tutorial utilizza le impostazioni predefinite quando possibile (ad esempio, la versione predefinita di Cloud SQL). Nell'ambiente di produzione, potresti aggiungere altre configurazioni.Imposta le variabili di ambiente
Questa sezione fornisce esempi di variabili di ambiente che definiscono i vari nomi e regioni richiesti per i comandi eseguiti in questo tutorial. Puoi modificare queste variabili di esempio in base alle tue esigenze.
Le tabelle seguenti descrivono i nomi delle istanze, i relativi ruoli e le regioni di deployment per ogni fase della procedura di RE e di rollback in questo tutorial. Puoi anche fornire i tuoi nomi e le tue regioni.
Fase iniziale Nome istanza Role Regione instance-1Principale us-west1instance-2Standby us-west1instance-3Replica di lettura tra regioni us-west2Fase di disastro Nome istanza Role Regione instance-3Principale us-west2instance-4Standby us-west2instance-5Replica di lettura tra regioni us-west3instance-6Replica di lettura tra regioni us-west1Fase di fallback (finale) Nome istanza Role Regione instance-6Principale us-west1instance-7Standby us-west1instance-8Replica di lettura tra regioni us-west2I nomi delle istanze nelle tabelle precedenti non sono codificati con i relativi ruoli. In una situazione di RE, la funzione di un'istanza potrebbe cambiare. Ad esempio, una replica potrebbe diventare l'istanza primaria. Se il nome del nuovo dominio principale contiene la parola
replica, potrebbero verificarsi confusione e conflitti. Pertanto, ti consigliamo di non codificare i nomi delle istanze con la funzione o il ruolo che svolgono.Le tabelle precedenti elencano i nomi delle istanze di standby. Anche se questo tutorial non esegue un failover HA, include i nomi delle istanze di standby per completezza.
La fase di fallback ricrea il deployment originale della fase iniziale nelle stesse regioni originali. Tuttavia, in un fallback, i nomi delle istanze devono cambiare perché i nomi originali non sono immediatamente disponibili anche dopo l'eliminazione dell'istanza originale. Per supportare la creazione rapida di istanze nella fase di fallback, devi utilizzare nomi di istanze che non corrispondano ai nomi utilizzati nella fase iniziale.
In Cloud Shell, imposta le variabili di ambiente in base alle specifiche nelle tabelle precedenti:
export primary_name=instance-1 export primary_tier=db-n1-standard-2 export primary_region=us-west1 export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-3 export cross_region_replica_region=us-west2Se vuoi utilizzare un livello diverso per l'istanza principale, elenca i livelli a tua disposizione e poi assegna un valore diverso a primary_tier:
gcloud sql tiers listPer un elenco delle regioni in cui puoi eseguire il deployment di Cloud SQL, consulta la pagina Impostazioni delle istanze.
Crea un'istanza di database principale
In Cloud Shell, crea una singola istanza di Cloud SQL:
gcloud sql instances create $primary_name \ --tier=$primary_tier \ --region=$primary_regionIl comando
gcloudsi mette in pausa finché l'istanza non viene creata.Imposta la password root:
gcloud sql users set-password root \ --host=% \ --instance $primary_name \ --password $primary_root_password
Crea un database principale
In Cloud Shell, accedi alla shell MySQL e inserisci la password root al prompt:
gcloud sql connect $primary_name --user=rootAl prompt MySQL, crea un database e carica i dati di test:
CREATE DATABASE guestbook; USE guestbook; CREATE TABLE entries (guestName VARCHAR(255), content VARCHAR(255), entryID INT NOT NULL AUTO_INCREMENT, PRIMARY KEY(entryID)); INSERT INTO entries (guestName, content) values ("first guest", "I got here!"); INSERT INTO entries (guestName, content) values ("second guest", "Me too!");Verifica che il commit dei dati sia stato eseguito correttamente:
SELECT * FROM entries;Verifica che vengano restituite due righe di dati.
Esci dalla shell MySQL:
exit;
A questo punto, hai un singolo database che include una tabella e alcuni dati di test.
Modifica dell'istanza principale in un'istanza di database HA
Puoi configurare Cloud SQL solo come sistema ad alta disponibilità regionale, non come sistema interregionale. La configurazione di una replica di lettura tra regioni è diversa dalla configurazione di Cloud SQL come sistema multiregionale. Per ulteriori informazioni, vedi Abilitazione e disabilitazione della disponibilità elevata su un'istanza.
In Cloud Shell, crea un'istanza Cloud SQL abilitata per l'alta disponibilità:
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$primary_backup_start_time
Aggiungere una replica di lettura tra regioni per RE con aggiornamento automatico
I seguenti passaggi sono sufficienti per creare una replica di lettura tra regioni per questo tutorial:
In Cloud Shell, configura una replica di lettura tra regioni:
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_region(Facoltativo) Per verificare che il database sia stato replicato, nella consoleGoogle Cloud , vai alla pagina Istanze di Cloud SQL.
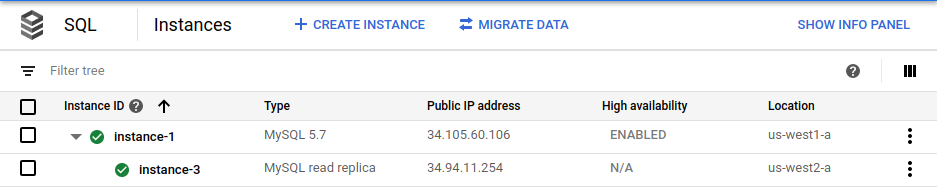
La console Google Cloud mostra che l'istanza principale (
instance-1) è abilitata per l'alta disponibilità e che esiste una replica di lettura tra regioni (instance-3).Utilizzando la stessa password di root per il primario, accedi alla replica di lettura tra regioni:
gcloud sql connect $cross_region_replica_name --user=rootAl prompt di MySQL, seleziona i dati per assicurarti che la replica funzioni:
USE guestbook; SELECT * FROM entries;Esci dalla shell MySQL:
exit;
Per informazioni dettagliate su come configurare una replica di lettura cross-region completa, consulta la documentazione di Cloud SQL.
Per i database di grandi dimensioni in un ambiente di produzione, ti consigliamo di eseguire il backup del database principale e creare la replica di lettura cross-region dal backup. Questo passaggio consente di ridurre il tempo necessario per la sincronizzazione della replica di lettura con il database principale. Questa procedura è descritta nella sezione successiva. Tuttavia, puoi scegliere di saltare questo passaggio e continuare con la fase 2.
Aggiungere una replica di lettura tra regioni in base a un file di dump
Un modo per ottimizzare la creazione di una replica di lettura cross-region è sincronizzare la replica da uno stato precedente e coerente del database principale anziché sincronizzare al momento dell'accesso al nuovo database principale. Questa ottimizzazione richiede la creazione di un file di dump che la replica utilizza come stato iniziale.
Per i passaggi per creare una replica basata su un file di dump, vedi Eseguire la replica da un server esterno a Cloud SQL (v1.1). Questo approccio può essere utile per i database di produzione di grandi dimensioni. Tuttavia, questo tutorial salta questo passaggio perché il set di dati di test è abbastanza piccolo per una replica completa.
Fase 2: simulazione di un disastro (interruzione del servizio a livello di regione)
In questa fase, simulerai l'interruzione del servizio di una regione primaria in un ambiente di produzione rendendo non disponibile il database primario.
Verifica il ritardo della replica di lettura tra regioni
Nei passaggi successivi, determini il ritardo di replica della replica di lettura cross-region:
Nella console Google Cloud , vai alla pagina Istanze di Cloud SQL.
Fai clic sulla replica di lettura (instance-3).
Nell'elenco a discesa delle metriche, fai clic su Ritardo di replica:
La metrica diventa Ritardo di replica. Il grafico non mostra alcun ritardo:
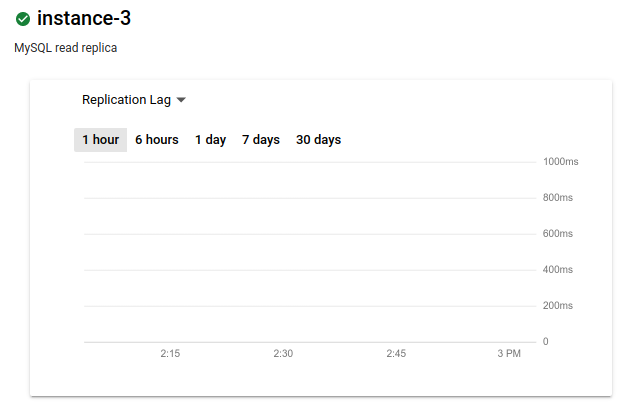
Idealmente, il ritardo di replica è pari a zero quando si verifica un'interruzione della regione primaria, in quanto un ritardo pari a zero garantisce la replica di tutte le transazioni. Se non è zero, alcune transazioni potrebbero non essere replicate. In questo caso, la replica di lettura tra regioni non conterrà tutte le transazioni di cui è stato eseguito il commit sul database primario.
Rendere non disponibile l'istanza principale
Nei passaggi successivi, simulerai un disastro arrestando il database primario. Se una replica di lettura multiregionale è collegata all'istanza principale, devi prima scollegarla, altrimenti non puoi arrestare l'istanza Cloud SQL.
In Cloud Shell, rimuovi la replica di lettura tra regioni dalla replica primaria:
gcloud sql instances patch $cross_region_replica_name \ --no-enable-database-replicationQuando ti viene chiesto, accetta l'opzione per continuare.
Arresta l'istanza di database principale:
gcloud sql instances patch $primary_name --activation-policy NEVER
Implementare il DR
In Cloud Shell, promuovi la replica di lettura tra regioni a un'istanza autonoma:
gcloud sql instances promote-replica $cross_region_replica_nameQuando ti viene chiesto, accetta l'opzione per continuare. La pagina Istanze di Cloud SQL mostra la precedente replica di lettura tra regioni (
instance-3) come nuova istanza principale e la precedente istanza principale (instance-1) come arrestata:
Dopo aver promosso la replica di lettura tra regioni come nuova istanza principale, attivala per l'alta disponibilità. Come best practice, devi aggiornare le variabili di ambiente con una denominazione corretta.
Aggiorna le variabili di ambiente:
export former_primary_name=$primary_name export primary_name=$cross_region_replica_name export primary_tier=db-n1-standard-2 export primary_region=$cross_region_replica_region export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-5 export cross_region_replica_region=us-west3Avvia la nuova istanza primaria:
gcloud sql instances patch $primary_name --activation-policy ALWAYSAbilita la nuova istanza principale come istanza regionale ad alta disponibilità:
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$backup_start_timeCrea una replica di lettura tra regioni in una terza regione:
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_regionIn un passaggio precedente, hai impostato la variabile di ambiente
cross_region_replica_regionsuus-west3.Al termine del failover, la pagina Istanze di Cloud SQL nella console Google Cloud mostra che la nuova istanza principale (
instance-3) è abilitata come HA e ha una replica di lettura cross-region (instance-5):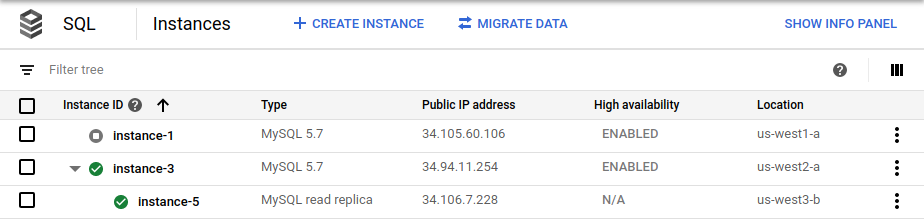
(Facoltativo) Se esegui backup regolari, segui la procedura descritta in precedenza per sincronizzare il nuovo primario con la versione di backup più recente.
(Facoltativo) Se utilizzi un proxy Cloud SQL, configura il proxy in modo che utilizzi il nuovo primario per riprendere l'elaborazione dell'applicazione.
Gestire un'interruzione del servizio di breve durata in una regione
È possibile che l'interruzione che attiva il failover venga risolta prima del completamento del failover. In questo caso, potrebbe essere opportuno annullare il failover e continuare a utilizzare l'istanza Cloud SQL primaria originale nella regione in cui si è verificata l'interruzione.
A seconda dello stato specifico del processo di failover, la replica di lettura tra regioni potrebbe essere già stata promossa. In questo caso, devi eliminarla e ricreare una replica di lettura tra regioni.
Elimina il primario originale per evitare una situazione di split-brain
Per evitare una situazione di split-brain, devi eliminare il primario originale (o renderlo inaccessibile ai client di database).
Dopo un failover, può verificarsi una situazione di split-brain quando i client scrivono contemporaneamente nel database principale originale e nel nuovo database principale. In questo caso, il contenuto dei due database non è coerente. Dopo un failover, il database primario originale non è aggiornato e non deve ricevere traffico di lettura o scrittura.
In Cloud Shell, elimina l'istanza primaria originale:
gcloud sql instances delete $former_primary_nameQuando ti viene chiesto, accetta l'opzione per continuare.
Nella console Google Cloud , la pagina Istanze Cloud SQL non mostra più l'istanza principale originale (
instance-1) come parte del deployment: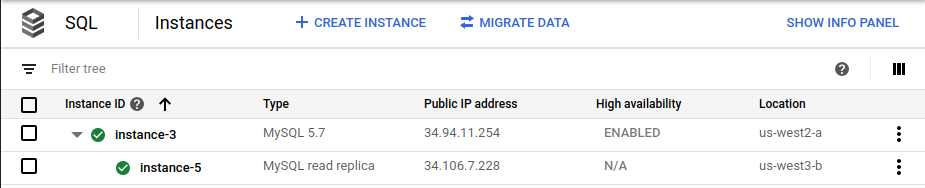
Fase 3: implementazione di un fallback
Per implementare un fallback alla regione originale (R1) dopo che è diventata disponibile, segui la stessa procedura descritta nella fase 2. Questo processo è riassunto come segue:
Crea una seconda replica di lettura tra regioni nella regione originale (R1). A questo punto, l'istanza primaria ha due repliche di lettura tra regioni, una nella regione R3 e una nella regione R1.
Promuovi la replica di lettura tra regioni in R1 come istanza principale finale.
Attiva l'alta disponibilità per il primario finale.
Crea una replica di lettura tra regioni della regione primaria finale in
us-west2.Per evitare una situazione di split-brain, elimina tutte le istanze non più necessarie (l'istanza principale originale e la replica di lettura tra regioni in R3).
Come discusso in precedenza, la best practice consiste nel creare un backup iniziale che contenga lo stato iniziale definito per il nuovo database principale.
Il deployment finale ora ha un database primario HA (con il nome
instance-6) e una replica di lettura multiregionale (con il nomeinstance-8).Confronto tra vantaggi e svantaggi di un RE manuale e automatico
La tabella seguente illustra i vantaggi e gli svantaggi dell'implementazione di una proceduraREP manuale o automatica. L'obiettivo non è determinare un approccio corretto rispetto a uno errato, ma fornire criteri per aiutarti a determinare l'approccio migliore per le tue esigenze.
Esecuzione manuale Esecuzione automatica Vantaggi:
- Hai il controllo completo di ogni passaggio.
- Puoi visualizzare, risolvere e documentare immediatamente qualsiasi problema durante la procedura.
- Puoi visualizzare ed esaminare ogni passaggio della procedura durante un failover.
Vantaggi:
- Puoi implementare e testare le procedure di failover.
- L'Automation offre l'implementazione più rapida e riduce al minimo i ritardi.
- L'implementazione è indipendente dagli operatori umani, dalle loro conoscenze e dalla loro disponibilità.
Svantaggi:
- L'implementazione manuale dei passaggi della procedura rallenta il processo.
- Gli errori di battitura umani possono causare problemi.
- Il test della procedura in genere coinvolge diversi ruoli e richiede tempo, il che potrebbe scoraggiare i test regolari.
Svantaggi:
- Se si verifica un errore imprevisto, devi eseguire il debug durante il failover di produzione.
- Se si verificano errori durante la procedura, sono necessari script per riprendere (recuperare) il processo da dove si era interrotto.
- Per comprendere il comportamento dello script, soprattutto in situazioni di errore, è necessaria una conoscenza sufficiente dello script e della sua implementazione.
Come best practice, ti consigliamo di iniziare con un'implementazione manuale. Quindi, esegui volontariamente l'implementazione regolarmente (preferibilmente in produzione) per assicurarti che il processo manuale funzioni e che tutti i membri del team conoscano i propri ruoli e responsabilità. Ti consigliamo di definire la procedura manuale in un documento con la procedura passo passo. Dopo ogni implementazione, devi confermare o perfezionare il documento della procedura.
Dopo aver perfezionato la procedura e aver verificato che sia affidabile, decidi se automatizzarla. Se selezioni e implementi un processo automatizzato, devi testarlo regolarmente in produzione per assicurarti di poterlo implementare in modo affidabile.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, puoi eliminare il progetto Google Cloud che hai creato per il tutorial.
Elimina il progetto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Scopri di più sul recupero di emergenza di Cloud SQL.
- Scopri di più sul disaster recovery per MySQL su Compute Engine.
- Scopri di più sulle architetture di disaster recovery per interruzioni dell'infrastruttura cloud.
- Esplora architetture, diagrammi e best practice di riferimento su Google Cloud. Consulta il nostro Cloud Architecture Center.